
摘要: 一. 捕获方法调用
使用call(Signature)切入点。其语法:
pointcut <pointcut name>(<any values to be picked u...
阅读全文
一.归并排序的思路
①把 n 个记录看成 n 个长度为 l 的有序子表;
②进行两两归并使记录关键字有序,得到 n/2 个长度为 2 的有序子表;
③重复第②步直到所有记录归并成一个长度为 n 的有序表为止。
二.归并排序算法实例
对于归并排序算法这类的分治算法,其核心就是"分解"和"递归求解"。对于"分解"实例,会在下面分析msort()方法中给出。我们先看合并的过程。
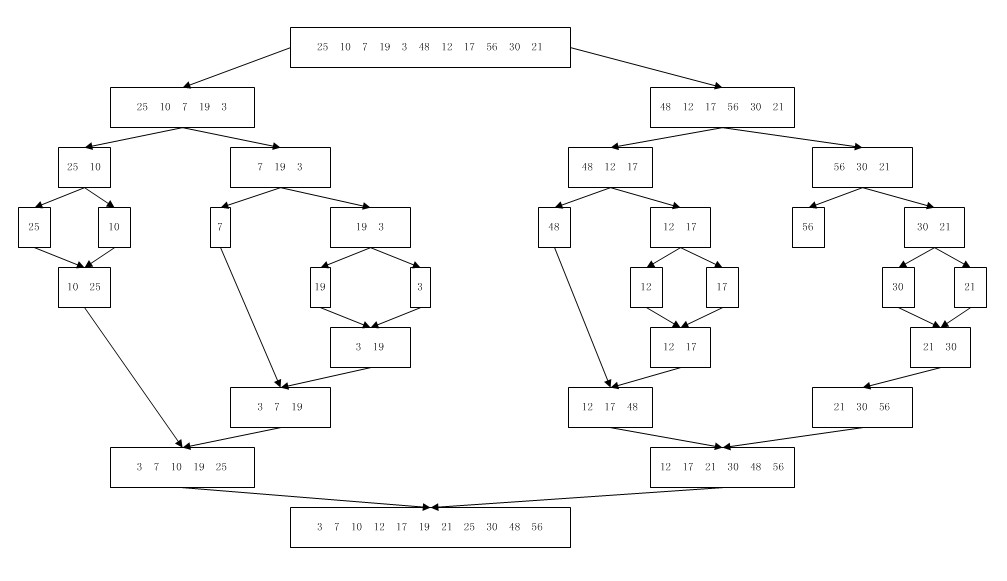
以下面描述的序列为例,在索引范围内[first , last)的序列还有九个整数元素,它由索引范围为[first , mid]的四个元素有序子列表A和索引范围[mid , last]的五个元素有序子列表B组成。

步骤1:比较arr[indexA]=7与arr[indexB]=12。将较小的元素7复制到数组tempArr的索引indexC处。并将indexA和indexC都指向下一个位置。
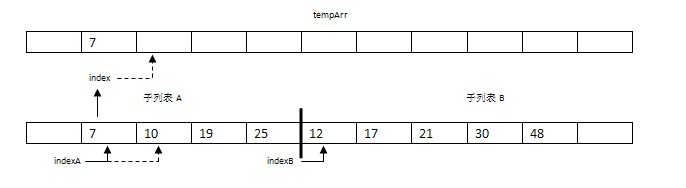
步骤2:比较arr[indexA]=10与arr[indexB]=12。将较小的元素10复制到数组tempArr的索引indexC处。并将indexA和indexC都指向下一个位置。

步骤3:比较arr[indexA]=19与arr[indexB]=12。将较小的元素12复制到数组tempArr的索引indexC处。并将indexB和indexC都指向下一个位置。
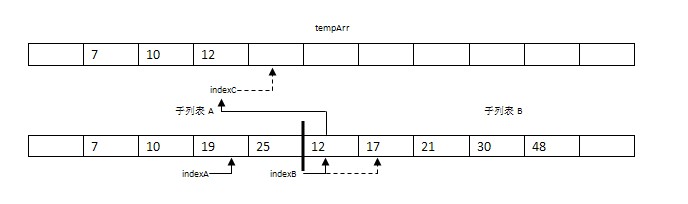
步骤4-7:依次成对比较两子表的元素将17,19,21,25复制到数组tempArr。此时,indexA到达子表A的未尾(indexA = mid),indexB引用的值为30。

步骤8-9:将未到尾部的子表剩余数据复制到tempArr中。
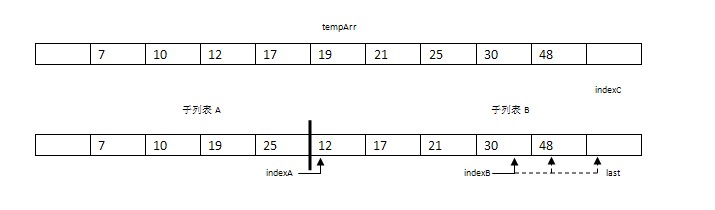
步骤10:将tempArr复制到原始数据arr中。
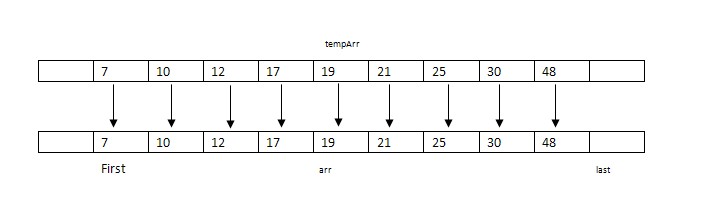
三.归并排序算法的实现
了解了合并过程,那么理解下面的代码并不是一件难事。下面提供了归并算法的非泛型版本和泛型版本。

 public class MergeSort
public class MergeSort  {
{


 public static void sort(Object[] arr) {
public static void sort(Object[] arr) {
//create a temporary array to store partitioned elements
Object[] tempArr = arr.clone();
//call msort with arrays arr and tempArr along
//with the index range
msort(arr, tempArr, 0, arr.length);
 }
}
public static <T extends Comparable<? super T>> void sort(T[] arr) {
//create a temporary aray to store partitioned elements
T[] tempArr = (T[]) arr.clone();
//call msort with arrays arr and tempArr along
//with the index range
msort(arr, tempArr, 0, arr.length);
}
private static void msort(Object[] arr, Object[] tempArr, int first,
int last) {
//if the sublist has more than 1 element continue
if (first + 1 < last) {
//for sublists of size 2 or more, call msort()
//for the left and right sublists and than
//merge the sorted sublists using merge()
int midpt = (last + first) / 2;
msort(arr, tempArr, first, midpt);
msort(arr, tempArr, midpt, last);
//if list is already sorted, just copy src to
//dest; this is an optimization that results in faster
//sorts for nearly ordered lists
if (((Comparable) arr[midpt - 1]).compareTo(arr[midpt]) <= 0)
return;
//the elements in the ranges [first,mid] and
//[mid,last] are ordered;merge the ordered sublists
//into an ordered sequence in the range [first , last]
//using the temporary array
int indexA, indexB, indexC;
//set indexA to scan sublist A with rang [first , mid]
//and indexB to scan sublist B with rang [mid , last]
indexA = first;
indexB = midpt;
indexC = first;
//while both sublists are not exhausted, compare
//arr[indexA] and arr[indexB]; copy the smaller
//to tempArr
while (indexA < midpt && indexB < last) {
if (((Comparable) arr[indexA]).compareTo(arr[indexB]) < 0) {
tempArr[indexC] = arr[indexA]; //copyto tempArr
indexA++; //increment indexA
} else {
tempArr[indexC] = arr[indexB]; //copyto tempArr
indexB++; //increment indexB
}
indexC++; //increment indexC
}
//copy the tail of the sublist that is not exhausted
while (indexA < midpt) {
tempArr[indexC++] = arr[indexA++]; //copy to tempArr
} while (indexB < last) {
tempArr[indexC++] = arr[indexB++]; //copy to tempArr
}
//copy elements form temporary array to original array
for (int i = first; i < last; i++)
arr[i] = tempArr[i];
}
}
 }
}
上述代码中最核心的msort()方法是一递归算法。下图说明了msort()方法中子列表的分割与合并。
四.归并排序算法的效率
归并排序的最坏情况与平均情况运行时间都为O(nlog
2n)。假定数组具有n=2
k个元素。如下图:
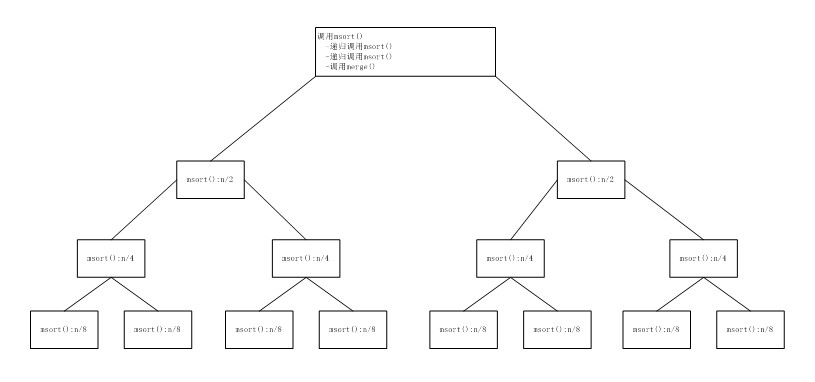
在层数0上对msort()方法的第一个调用会产生两个递归调用,这两个递归调用产生长度为n/2的两个半部分列表,而merge()方法将上述两个半部分列表组合的一个有序的n元素列表;在层数1上存在两个msort()方法的调用,每个调用又会产生另外两个对长度为n/4的列表的递归调用。每个合并会将两个长度为n/4的子列表连接为一个长度为n/2的有序列表;在层数2上存在对merge()方法的4=2
2个调用,每个调用会创建一个长度为n/4的有序列表。通常,在层数i上存在对merge()方法的2
i个调用,每个调用会创建一个长度为n/2
i的有序子列表。
层数0:存在对merge()方法的1=2
0次调用。这个调用对n个元素排序。
层数1:存在对merge()方法的2=2
1次调用。这个调用对n/2个元素排序。
层数2:存在对merge()方法的4=2
2次调用。这个调用对n/4个元素排序。
......
层数i:存在对merge()方法的2
i次调用。这个调用对n/i个元素排序。
在树中的每一层,合并涉及具有线性运行时间的n/2
i个元素,这个线性运行时间需要少于n/2
i次的比较。在层数i上组合的2
i个合并操作需要少于2
i*n/2
i=n次的比较。假定n=2
k,分割过程会在n/2
k=1的k层数上终止。那么所有层上完成的工作总量为:k*n = nlog
2n。因此msort()方法的最坏情况效率为O(nlog
2n)。