距离上一篇SpringSide 3 中的Struts 2已经有一段时间了,中间因为研究了一下Fedora 10,所以就把对SpringSide 3的学习搁置了下来。以目前的Web开发来看,主流的模式还是MVC,在SpringSide 3中,控制器使用的是Struts 2,前面我们已经探讨过了,接下来毫无疑问应该探讨Model层,也就是和数据库访问有关的内容。
在SpringSide 3 中,数据库访问层使用的是Hibernate,Hibernate是一个很优秀的ORM框架,是大家耳熟能详的东西了。关于Hibernate的内容,很多人是写了又写,我想我是很难写出新意了。不过我的思路是这样的,我从实际开发的过程出发,写出在SpringSide 3中使用Hibernate的步骤,在这些步骤中,探讨SpringSide 3对Hibernate的封装,探讨数据持久层的单元测试,探讨二级缓存和性能优化。
我创建一个虚拟的应用场景来做示范,假设我们开发的是一个简单的文章发布系统,实现对文章简单的增删查改功能。同时为了演示多个表之间的关联查询,假设每篇文章有多篇评论。这时,我们需要在数据库中创建两个表,如下:
create
table
articles(
id
int
primary
key
auto_increment,
subject
varchar
(
20
)
not
null
,
content
text
);
create
table
comments(
id
int
primary
key
auto_increment,
content
varchar
(
255
),
article_id
int
not
null
,
foreign
key
(article_id)
references
articles(id)
);
我的开发习惯是先写数据库Schema,再写Hibernate的Entity类,再写DAO类,最后在Action里面使用DAO类。这只是我个人的习惯,大家都知道,Hibernate有通过Entity类自动生成数据库Schema的工具,这说明很多人习惯先写Entity类而不关注数据库的细节。但是我从没有用过这样的工具,我喜欢了解数据库的细枝末节,所以我总是自己写数据库Schema。
在MySQL的客户端直接执行上面的SQL语句就可以创建这两个表了。这里需要额外提一下的是我使用的数据库是MySQL,而不是默认的Derby,要把SpringSide创建的项目的数据库更换为MySQL并不难,只需要如下几个步骤:
1、更改数据库地址、用户名、密码(MySQL需要在数据库地址中指定UTF-8编码);
2、更改数据库驱动、Dialect,同时,需要自己下载MySQL的JDBC驱动放到项目中;
3、SQL文件,因为Derby的语法和MySQL的有点不一样,比如MySQL中就应该使用AUTO_INCREMENT,而不是GENERATED ALWAYS as IDENTITY,并且Drop数据表的时候,MySQL可以加上IF EXISTS选项。
下一步,编写Entity类:
package
cn.puretext.entity.web;
import
java.util.LinkedHashSet;
import
java.util.Set;
import
javax.persistence.CascadeType;
import
javax.persistence.Entity;
import
javax.persistence.JoinColumn;
import
javax.persistence.OneToMany;
import
javax.persistence.OrderBy;
import
javax.persistence.Table;
import
org.hibernate.annotations.Cache;
import
org.hibernate.annotations.CacheConcurrencyStrategy;
import
org.hibernate.annotations.Fetch;
import
org.hibernate.annotations.FetchMode;
import
cn.puretext.entity.IdEntity;
@Entity
//
表名与类名不相同时重新定义表名.
@Table(name
=
"
articles
"
)
//
默认的缓存策略.
@Cache(usage
=
CacheConcurrencyStrategy.READ_WRITE)
public
class
Article
extends
IdEntity {
private
String subject;
private
String content;
private
Set
<
Comment
>
comments
=
new
LinkedHashSet
<
Comment
>
();
public
String getSubject() {
return
subject;
}
public
void
setSubject(String subject) {
this
.subject
=
subject;
}
public
String getContent() {
return
content;
}
public
void
setContent(String content) {
this
.content
=
content;
}
@OneToMany(cascade
=
{ CascadeType.ALL })
@JoinColumn(name
=
"
article_id
"
)
//
Fecth策略定义
@Fetch(FetchMode.SUBSELECT)
//
集合按id排序.
@OrderBy(
"
id
"
)
//
集合中对象id的缓存.
@Cache(usage
=
CacheConcurrencyStrategy.READ_WRITE)
public
Set
<
Comment
>
getComments() {
return
comments;
}
public
void
setComments(Set
<
Comment
>
comments) {
this
.comments
=
comments;
}
}
package
cn.puretext.entity.web;
import
javax.persistence.Entity;
import
javax.persistence.Table;
import
org.hibernate.annotations.Cache;
import
org.hibernate.annotations.CacheConcurrencyStrategy;
import
cn.puretext.entity.IdEntity;
@Entity
//
表名与类名不相同时重新定义表名.
@Table(name
=
"
comments
"
)
//
默认的缓存策略.
@Cache(usage
=
CacheConcurrencyStrategy.READ_WRITE)
public
class
Comment
extends
IdEntity {
private
String content;
public
String getContent() {
return
content;
}
public
void
setContent(String content) {
this
.content
=
content;
}
}
通过上面的代码,大家可以注意到如下的信息:
1、上面的Entity类都没有了id,为什么呢?因为白衣把它抽出来了,做了一个IdEntity基类让我们继承,所以,以后只要是数据库中含有id的表,编写Entity类的时候都可以从IdEntity继承。
2、Entity中使用的Annotation就不用多说了,JPA Annotation已经不是什么新东西,在上面的Entity中,我演示了一下@OneToMany,而白衣在项目里面大量演示了@ManyToMany,我以前写的一篇博文《打通数据持久层的任督二脉》中讨论了@OneToOne和@ManyToOne,这回算是补齐了。
3、上面的Entity中涉及到了抓取策略和缓存策略,使用注解设置起来也很简单。
下一步,编写DAO类:
package
cn.puretext.dao;
import
org.springframework.stereotype.Repository;
import
org.springside.modules.orm.hibernate.HibernateDao;
import
cn.puretext.entity.web.Article;
@Repository
public
class
ArticleDao
extends
HibernateDao
<
Article, Long
>
{
}
可以看到该类非常之简单,原因嘛,自然是因为SpringSide的基类做了大量的工作。这这里,该DAO类的继承层次是这样的:
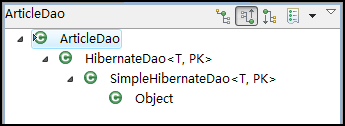
从截图中可以看出,SpringSide提供了HibernateDao和SimpleHibernateDao两个基类,在这两个基类中,封装了CRUD操作,而HibernateDao类更提供了分页查询函数。这个封装的思路和前一代的SpringSide是一样的,但是有几个区别:
1、可以不创建自己的DAO类,什么意思呢?举例说明,上面为Article创建了ArticleDao类,那么在Action中可以这样用:
ArticleDao articleDao = new ArticleDao();(这只是一个示范,事实上不需要显示创建,因为在SpringSide 3中,靠的都是注入)
但是也可以不要ArticleDao,而直接这样用:
HibernateDao<Article,Long> articleDao = new HibernateDao<Article,Long>();
这样做有什么好处呢?当然是可以有效减少Dao层类的数量,如果有的Dao类使用得比较少,那么就没有必要专门为它创造一个Dao类了。
写到这里,我又忍不住要评论一下江南白衣在项目架构方面的一些习惯了,他的层次太多,这应该是他在实际项目中锤炼出来的经验,但是和教科书上的就不大一样了,教科书上的三层就是三层,而白衣可以把它扩展到4层甚至5层,白衣的层次可以总结成Entity->DAO->Service(Manager)->Action->View,其中Service这一层命名还不统一,包名是Service,类名中用的是Manager。我觉得这个大家可以探讨探讨,也许白衣认为DAO里面不应该包含业务逻辑,只应该包含CRUD和分页操作,而Action里面也不应该包含业务逻辑,所以就单独抽出一层来了吧,所以这一层应该称为Bussiness层比较合适,而白衣也认为,有时候DAO层和Bussiness层可以合并在一起。另外,我认为白衣在项目中搞的package也太多了一点,在IDE里面不方便,所以我的实际项目中,我会对包重新进行整理。
2、在DAO类中可以使用Hibernate的原生API。我们来总结一下在Hibernate中通常采用的查询方式:一是使用HQL语言,它的过程基本上是先获取Session,然后创建Query对象,最后通过Query对象执行HQL语句;二是使用条件查询,它的过程基本上是先获取Session,然后创建Creteria对象,然后执行Creteria对象的list()方法。而在Dao类中,我们可以很简单的通过sessionFactory.getCurrentSession()来获得Session对象,进而很方便的使用到HQL或者Creteria。
3、在SpringSide 2中,我们可以对数据表中的数据不做物理删除,该特性得益于白衣提供的@Undeletable注解和HibernateEntityExtendDao类,在SpringSide 3中,该特性没有了。现在回想起来,我觉得该特性也没有什么存在的必要。
后面再继续探讨分页查询和性能优化。现在的任务是赶紧确认一下这Entity层和Dao层能否正常工作,完成该任务的最佳途径,当然是单元测试了。
在SpringSide 3中,编写单元测试非常方便,只需要继承白衣提供的SpringContextTestCase类或者SpringTxTestCase类即可,事实上,只有继承SpringTxTestCase类才能正常工作,因为我们的项目的配置无法让我们工作在非事务的环境下。继承这个类有什么用处呢?它的用处就是可以读取项目中的applicationContext.xml文件,自动建立数据源、Dao对象,并把Dao对象注入到测试用例中,所以,测试类的代码非常简洁,如下:
package
cn.puretext.unit.service;
import
java.util.List;
import
org.junit.Test;
import
org.springframework.beans.factory.annotation.Autowired;
import
org.springside.modules.orm.Page;
import
org.springside.modules.test.junit4.SpringTxTestCase;
import
cn.puretext.dao.ArticleDao;
import
cn.puretext.entity.web.Article;
public
class
DaoTest
extends
SpringTxTestCase {
@Autowired
private
ArticleDao articleDao;
public
ArticleDao getArticleDao() {
return
articleDao;
}
public
void
setArticleDao(ArticleDao articleDao) {
this
.articleDao
=
articleDao;
}
@Test
public
void
addArticle() {
Article article
=
new
Article();
article.setSubject(
"
article test
"
);
article.setContent(
"
article test
"
);
articleDao.save(article);
}
}
因为该单元测试工作在事务环境下,所以运行单元测试不会改变数据库中的数据。白衣提供的这两个类事实上只是在Spring 2.5的测试框架上做了一点点改进。关于Spring 2.5测试框架的详细介绍,大家可以到“IBM DeveloperWorks 中国”上去看这一篇文章:
http://www.ibm.com/developerworks/cn/java/j-lo-spring25-test/
但是白衣自己的做法却完全不同,在白衣写的单元测试中,他偏偏用的是EasyMock,关于EasyMock的使用方法,大家可以到“IMB DeveloperWorks 中国”上去看这一篇文章:
http://www.ibm.com/developerworks/cn/opensource/os-cn-easymock/
再让大家看一下截图,我特地把测试类的代码、JUnit著名的绿条和Hibernate输出的SQL语句放到了一起,如下:

代码比较简单,只是为了证明上面写的Entity和Dao能够正常运行。在下面的内容里,随着我们的探讨,测试代码的内容会逐渐增加。
上文的内容演示了SpringSide 3中Hibernate的使用过程和单元测试,也提到了SpringSide 3提供的CRUD封装,这些都很简单。在SpringSide 3对Hibernate的封装中,还有一个重点,那就是分页查询。
分页查询有HibernateDao类实现,要配合Page类来使用。Page类一般用来设置查询条件,并返回查询结果,举例说明,如果对Articles表中的数据进行分页显示,每一页10条记录,那么查询第二页应该怎么办呢?代码如下:
@Test
public
void
pageQuery() {
Page
<
Article
>
page
=
new
Page
<
Article
>
();
page.setPageSize(
10
);
page.setPageNo(
2
);
page
=
articleDao.getAll(page);
List
<
Article
>
articles
=
page.getResult();
}
以上代码在单元测试中进行,这个过程很容易理解,就是先创建一个Page对象,然后设置该页的大小和序号,就可以直接查找该页的数据了。同时,Page类还有很多辅助方法,如获取总的记录条数,获取页的总数,获取是否有下一页等等。
Page只是一个辅助类,真正的查询操作是在HibernateDao类中完成的,具体代码如下:
/**
* 按Criteria分页查询.
*
*
@param
page 分页参数.
*
@param
criterions 数量可变的Criterion.
*
*
@return
分页查询结果.附带结果列表及所有查询时的参数.
*/
@SuppressWarnings(
"
unchecked
"
)
public
Page
<
T
>
find(
final
Page
<
T
>
page,
final
Criterion criterions) {
criterions) {
Assert.notNull(page,
"
page不能为空
"
);
Criteria c
=
createCriteria(criterions);
if
(page.isAutoCount()) {
int
totalCount
=
countCriteriaResult(c);
page.setTotalCount(totalCount);
}
setPageParameter(c, page);
List result
=
c.list();
page.setResult(result);
return
page;
}
可以看到,白衣的实现用的是Hibernate中的条件查询,从上面的代码可以看出,该过程是先创建Criteria对象,然后查询记录的总数,并将记录的总数填入到Page对象中,然后再调用setPageParameter方法将Page对象中的信息填入到Criteria对象中,最后调用Criteria对象的list()方法来获取结果。
下面跟踪到setPageParameter方法中,其代码如下:
protected
Criteria setPageParameter(
final
Criteria c,
final
Page
<
T
>
page) {
//
hibernate的firstResult的序号从0开始
c.setFirstResult(page.getFirst()
-
1
);
c.setMaxResults(page.getPageSize());
/*
以下代码省略
*/
}
可以看到,该方法中只是简单地调用了Criteria对象的setFirstResult和setMaxResults方法,这都是Hibernate的原生API,没有什么需要特殊说明的。我比较关心的是分页查询所生成的SQL语句及其正确性。
讲到这里,我得提一下我的技术背景:在使用MySQL之前,我有很长一段时间使用的是MS SQL Server 2000。为什么要提这个问题呢?那是因为站在SQL Server 2000的角度,处理分页问题是比较困难的。在SQL Server 2000中,如果要获取指定条数的记录,只能使用top关键字,也就是说要获取10条数据,就应该使用select * top 10 from articles,那么怎么定位到第二页呢?就必须知道第二页的第一条数据的ID是多少,然后用这样的语句select * top 10 from articles where id >= ?,那怎么知道第二页的第一条记录的ID是多少呢?免不了又要多一次查询如select id top 20 from articles order by id desc。
所以在SQL Server 2000中,要实现分页查询比较困难,不是思考起来困难,而是提高效率困难,必须得避免多次查询。解决的办法当然有,要么使用存储过程,要么在前面的select语句中加入子查询。但是不管采取哪种办法,SQL语句写起来都不简单。
在MySQL中,该问题就简单多了,MySQL不提供top,但提供limit,更重要的是limit接受两个参数,而不是像top只接受一个参数。limit后面的参数可以是{[offset,] row_count | row_count OFFSET offset},其中的offset就代表了第2页的第一条数据所在的位置,大家请注意,这里说的是位置,而不是SQL Server 2000中的ID,这两者是有区别的,因为ID可能不连续,而位置肯定是连续的,所以位置是可以通过简单的数学计算来获得的,这样,MySQL就只需要生成一个简单的SQL语句select * from articles limit 10,10。
下面是Hibernate自己生成的SQL语句:
select
this_.id as id4_0_,
this_.content as content4_0_,
this_.subject as subject4_0_
from
articles this_ limit ?,
?
为了和SQL Server 2000对比,我把配置文件中的Dialect改为org.hibernate.dialect.SQLServerDialect,得到的SQL语句如下:
select
top 20 this_.id as id4_0_,
this_.content as content4_0_,
this_.subject as subject4_0_
from
articles this_
2009-07-09 22:22:53,950 [main] WARN [org.hibernate.util.JDBCExceptionReporter] - SQL Error: 1064, SQLState: 42000
2009-07-09 22:22:53,969 [main] ERROR [org.hibernate.util.JDBCExceptionReporter] - You have an error in your SQL syntax;
因为我没有把数据库迁移到SQL Server,所以该语句一运行就出错了,不过从该语句中的top 20也可以看出,要么该语句的作用是为了得到第二页的第一条记录的ID,然后后面再跟一条SQL语句,只不过因为出现错误,所以后面的语句没有显示出来,要么是直接取出20条记录,并抛弃10条,只留下第二页的数据。总之,和我之前预想的一样,性能得不到保证。
通过搜索引擎我还查出,Oracle也不支持limit语句,所以说,我们不能完全相信Hibernate,必要的时候,还是得靠自己写存储过程。
Fetch策略也是影响性能的一个方面,Fetch策略主要是针对Entity中的集合数据,正如白衣所说,很多人多只知道使用默认的Lazy策略,我就是这很多人中的一个,以前我还因为Lazy策略出现过问题,什么问题呢,那就是我先获取一个Entity的数据,然后把在Entity保存到HttpSession中,然后在使用该对象中的集合数据时,就报错了,为什么呢,因为这个时候Hibernate的Session早就关闭了,所以出错。
关于Fetch策略的选择,SpringSide的文档和Hibernate的文档上面都写得很清楚,我就不罗嗦了,至于在代码中怎么设置Fetch策略,代码的注释很清楚,一看就会。
最后谈一谈二级缓存,Session中的缓存是一级缓存,ehcache提供二级缓存,关于二级缓存的配置,主要涉及到两个地方,一个是xml配置文件,另一个是Entity类中的注解,xml配置文件中配置的是ehcache的属性,而Entity中的注解设置了隔离级别,具体内容请参阅SpringSide 3 的文档。