MDA中模型的存储、表现与转换
最近一些朋友在我的blog上面留言或者给我写email讨论一些问题,本文希望能够一起解答他们的一些疑问,同时也整理一下自己的思路。
MDA是以模型为中心的,模型是其基本元素,所以关于模型的存储、查询、表现和转换是对于基本元素的操作。OMG已经有一些既定规范或者正在制订的规范是用来讨论这些问题的。例如XMI规范规定了模型的存储格式、QVT规范(正在制订中,已经有一个初步的版本)是规定模型的查询、视图和转换的。最近的QVT规范对于模型的查询尚未涉及,因此本篇中也不讨论模型查询。重点总结一下模型的存储、表现(视图)和转换。并力所能及的举例来说明。
模型的存储
我认为模型的存储按照其发展进程来看可以分为以下几种:自定义格式;基于XML的自定义格式;遵守XMI的格式;可以转换为其它格式的脚本格式;以及直接以代码存储的形式。
我对于软件建模的了解是从UML开始的,UML统一之前的各种建模方法并未研究,相信在UML统一之前,模型是没有一个统一的存储格式的。其必然是按照自定义的格式来存储的。不同的建模工具是按照自己定义的格式来存储模型,对于以下一个最简单的模型:
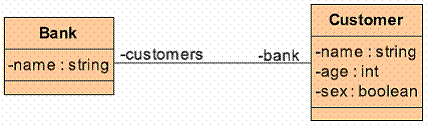
一个建模工具可以这样存储:
类:Bank
属性:name;类型:string
连接:customers;类型:Customer
类:Customer
属性:name;类型:string
属性:age;类型:int
属性sex;类型:boolean
连接:bank;类型:Bank
简而言之,只要建模工具能够识别,模型的存储格式是没有限制的。
但是,这种自定义的方式显然是有缺点的,最大的两个确定就是不具有可交互性,不能被其它工具识别。目前的建模工具已经不使用这样随意的方法了。
交互性好,能够广泛的被工具识别的XML技术恰好与建模技术的发展在同步进行。大概都在2000年左右,UML和XML几乎同时达到了最高点,因此现在的建模工具使用基于XML的模型存储格式也就不是一件意外的事情了。由于几乎所有的建模工具都采用了XML作为模型的存储方式,OMG特别制订了一个XMI规范,专门规定了模型的XML存储格式。XMI事实上是一个XML Schema,它规定了模型、对象等概念的存储格式。
目前很多建模工具都支持XMI2.0的存储,例如EMF、MagicDraw(RationalRose我没有看,估计支持,因为和EMF一样都是IBM的一母同胞)。下面是EMF的存储格式,同样是上面的那个模型:
<?xml version="1.0" encoding="UTF-8"?>
<ecore:EPackage xmi:version="2.0"
xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore" name="mypackage">
<eClassifiers xsi:type="ecore:EClass" name="Bank">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="name" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
<eStructuralFeatures xsi:type="ecore:EReference" name="customer" lowerBound="1"
upperBound="-1" eType="#//Customer"/>
</eClassifiers>
<eClassifiers xsi:type="ecore:EClass" name="Customer">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="name" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
<eStructuralFeatures xsi:type="ecore:EAttribute" name="age" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EInt"/>
<eStructuralFeatures xsi:type="ecore:EAttribute" name="sex" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EBoolean"/>
<eStructuralFeatures xsi:type="ecore:EReference" name="bank" eType="#//Bank"/>
</eClassifiers>
</ecore:EPackage>
可以看出来,EMF使用了XML1.0和XMI2.0,EMF的模型存储是比较简化的,可以人工阅读和修改。MaigicDraw以及Rose的模型存储则非常繁琐,包含了众多图信息(所谓图信息,就是定义了可视化模型元素的位置、大小、颜色等的信息)、自定义信息等,是不支持人工阅读的。例如上面那个模型的MagicDraw的模型存储文件如果不压缩的话有174kb。
也有一些工具使用类型于脚本的语言来定义和存储模型,这种脚本一般都类似java语言或者idl等语言,可以方便的定义模型元素。也能够被方便的转换为不同工具支持的模型。例如ATL自带的km3语言。当然,这样总是觉得有点怪怪的。明明使用模型就是为了避免从代码开始,但是定义模型竟然又使用了另一种代码。上面的模型使用km3的格式如下:
package mypackage {
class Bank {
attribute name[0-1] ordered : EString
reference customer[1-*] ordered : Customer;
}
class Customer {
attribute name[0-1] ordered : EString
attribute age[0-1] ordered : EInt
attribute sex[0-1] ordered : EBoolean
reference bank[0-1] ordered : Bank;
}
}
最后,用代码也可以存储模型,EMF的一种模型存储方式就是带有标记的java代码来存储模型,所以上面的模型也可以使用如下代码存储:
public class Bank {
private String name;
private Customer customers;
}
public class Customer {
private String name;
private int age;
private boolean sex;
private Bank bank;
}
Together这样的工具根本就把模型和代码看成同一件事物的两种外表,因此,用代码做为存储模型的格式也是自然而精确的。不过这样也是有缺点的,就是图信息无法保存,而且要确保代码生成是毫无疑义的。
模型的表现
在QVT(模型的查询、视图、转换)规范中使用的是View这个术语,它的含义是模型的表现或者视图。在最近的QVT规范中,还不支持视图的创建和管理。但是视图的概念类似与MVC中的视图概念。我试着下一个定义:模型的视图指的是对于软件模型的某个侧面在某种场景下的一种表现方式。例如,类图是对于某个软件的静态结构的视图,而对象图是软件运行时的某个时刻的视图。
视图的另外一层含义是,如何将存储好的模型以可视化的方式展现在用户面前。有人说,最好的建模工具是白纸和笔,这句话也是有一定道理的。用白纸和笔可以很快的画出可以用来交流的UML图。此时,白纸上的UML图就是模型的一个视图。UML为模型的视图提供了一组标准化的符号和概念,让用户可以使用不同的建模工具构建具有相同含义的软件模型,即使它们的颜色、大小、方位以及存储格式不同,它们指的是同样的内涵。
一个模型的信息只有一个,但是其表达方式是无穷的,每种表达方式都可以称为此模型的一个视图,它们通常是白纸上画出的模型,或者建模工具中的图形,或者规范的XML文件等等。
举例说明,上面例子模型中,其类图是一种视图,我们也可以规定另一种视图如下:
每个类用绿色的方块表示,方块中上部写类名称,中下部写属性名称,属性后面必须跟一个冒号,冒号后面是属性的类型……
模型的转换
在看透了模型存储和视图的本质以后,再来讨论模型的转换就比较容易了。模型的本质是什么呢?是其存储格式还是其表现形式呢?都可以!根据其存储格式或者视图都可以进行模型转换。
最简单的模型转换例子就是xslt了。以XML格式存储的模型,一个XSLT的入门者就可以写出模型转换的实例。
例如我们要将上面的EMF的XML存储文件转换一下,将Bank类的name属性名改为bankname,则使用下面的xsl文件可以转换:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format" xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore">
<xsl:template match="/">
<xsl:apply-templates select="ecore:EPackage"/>
</xsl:template>
<xsl:template match="ecore:EPackage">
<xsl:text disable-output-escaping="yes">
<ecore:EPackage xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore"
xmlns:fo="http://www.w3.org/1999/XSL/Format"
</xsl:text>
name= "<xsl:value-of select="@name"/>"
<xsl:text disable-output-escaping="yes">></xsl:text>
<xsl:apply-templates select="eClassifiers"/>
<xsl:text disable-output-escaping="yes">
</ecore:EPackage>
</xsl:text>
</xsl:template>
<xsl:template match="eClassifiers">
<xsl:choose>
<xsl:when test="@name[. = 'Bank']">
<eClassifiers xsi:type="ecore:EClass" name="Bank">
<xsl:for-each select="eStructuralFeatures ">
<xsl:choose>
<xsl:when test="@name[. = 'name']">
<eStructuralFeatures xsi:type="ecore:EAttribute" name="bankname" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"/>
</xsl:when>
<xsl:otherwise>
<xsl:copy-of select="."/>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</eClassifiers>
</xsl:when>
<xsl:otherwise>
<xsl:copy-of select="."/>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
其中<xsl:template match="ecore:EPackage">可以写得更简洁一点,直接使用源文件中的这个部分来代替,但是为了体现属性的读取功能,所以使用了xsl:value-of来读取属性,并填入ecore:EPackage的标记中,同时因为标记不能封闭,所以使用了xsl:text来输出。运行这个xsl转换源模型就可以得到目标模型。
源模型和目标模型在EMF中的显示如下:
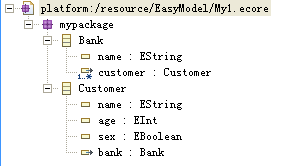
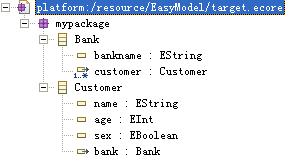
左边的是源模型,右边则是目标模型。从上面简单的例子可以看出,模型转换可以使用XSLT对以xml方式存储的模型进行转换。
但是,以XSLT来进行模型转换是不自然而且繁琐的。我们需要更好的模型转换方法。这时的一个思路就是能否把模型载入内存,然后用面向对象的方法以及语言来处理模型元素对象,然后生成目标模型。
(撰写中。。。)