做个总结
linux服务器上做负载均衡
自己准备的:linux服务器(45.78.20.168),jdk1.7,nginx,redis,tomcat7两个,部署的项目;
1:jdk1.7安装,两个tomcat分别端口8080,8081;部署相同的项目;启动;
http://45.78.20.168:8080/redis3.2/getRedis.action2:安装nginx,添加负载的配置,安装目录下找
/etc/nginx/conf.d/default.conf文件(或/etc/nginx/nginx.conf);策略设置为默认轮询;
upstream www.nimenhaihaoma.com {
server 45.78.20.168:8080;
server 45.78.20.168:8081;
}
server{
listen 80;
server_name www.nimenhaihaoma.com;
location / {
proxy_pass http://www.nimenhaihaoma.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
3:配置session共享,方式很多,这里用的redis的session共享(兼容jdk版本至少1.7):
tomcat的lib包加
commons-pool2-2.0.jar,jedis-2.5.2.jar,tomcat-redis-session-manager1.2.jar;
tomcat配置文件context.xml,在标签<Context>内添加配置:
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager" host="localhost" port="6379" database="0" maxInactiveInterval="60" />
4:项目里面区分session的代码:
(1):放session的接口(执行一次);
(2):取session数据(不断刷新),看tomcat打印信息;
5:效果,
http://www.nimenhaihaoma.com/redis3.2/getRedis.action (狂刷session值相同)
posted @
2016-08-17 17:03 魏文甫 阅读(145) |
评论 (0) |
编辑 收藏
项目只是加载spring的几个定时任务,启动服务一直循环加载spring文件,问题的根节点:定时器类里面的service对象采取配置的方式注入,而这个定时器类的构造让我给加上了:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext*.xml");
myServiceImpl = context.getBean("XXXService");
加上这段为了方便测试,在该类里写main方法测试执行,把调用写到构造里;,spring定时器配置好时间后,此处构造忘了去掉;导致启动tomcat服务一直在加载spring注入文件;
同理,spring注入的方式,在action里同样有这样的效果,构造方法一定注意;
posted @
2015-04-25 11:09 魏文甫 阅读(201) |
评论 (0) |
编辑 收藏
是在build.xml编译的时候,包里有两个类名一样的java文件,我只是做了个备份,忘了改文件后缀,备份的文件也编译了,所以报的这个错
posted @
2014-08-28 20:18 魏文甫 阅读(871) |
评论 (0) |
编辑 收藏1,添加索引文件中的一条新的索引
Question addQ = new Question();//新添加的一条数据,对象id在索引文件中没有
addQ.setId("999999999");
addQ.setQuestionname("新添加的一条数据名称");
Analyzer sa = new SmartChineseAnalyzer(Version.LUCENE_40);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40, sa);
iwc.setOpenMode(OpenMode.APPEND);
IndexWriter writer = null;
try {
Directory dir1 = FSDirectory.open(new File("F:\\temp"));
writer = new IndexWriter(dir1, iwc);
FieldType ft = new FieldType();
ft.setIndexed(true);
ft.setStored(true);
ft.setTokenized(true);
FieldType ft2 = new FieldType();
ft2.setIndexed(true);
ft2.setStored(true);
ft2.setTokenized(false);
Document doc = new Document();
doc.add(new Field("id", addQ.getId(), ft2));
doc.add(new Field("questionname", addQ.getQuestionname(), ft));
writer.addDocument(doc);
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
if(writer!=null){
writer.close();
}
if(sa!=null){
sa.close();
}
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}执行完程序后,索引文件中已经添加新的索引数据。2,删除索引文件中的一条新的索引
Question delQ = new Question();//索引文件中有的一条数据,根据对象id删 delQ.setId("1111111"); delQ.setQuestionname("要删除的一条数据"); IndexWriter writer = null;
Analyzer sa = new SmartChineseAnalyzer(Version.LUCENE_40);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40, sa);
Directory dir1 = null;
try {
dir1 = FSDirectory.open(new File("F:\\temp"));
writer = new IndexWriter(dir1, iwc);
Term term = new Term("id", delQ.getId());
writer.deleteDocuments(term);
writer.commit();
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writer != null) {
writer.close();
sa.close();
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("索引删除完成");
3,更新索引文件中的一条索引
更新索引文件中的一条索引的理念是:先找到这条索引删除,然后再添加这条更新后的索引
posted @
2013-08-16 12:08 魏文甫 阅读(374) |
评论 (0) |
编辑 收藏 IndexReader reader = DirectoryReader.open(FSDirectory.open(new File("F:\\temp")));// 打开索引
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new SmartChineseAnalyzer(Version.LUCENE_40);
String[] fields = { "questionname","id" };
Occur[] occurs = new Occur[] { Occur.SHOULD,Occur.SHOULD };
Query query = MultiFieldQueryParser.parse(Version.LUCENE_40, "测试 的", fields,
occurs, analyzer);
TopDocs result = searcher.search(query, searcher.getIndexReader()
.maxDoc());
ScoreDoc[] hits = result.scoreDocs;
List<Document> list = new ArrayList<Document>();
for (int i = 0; i <hits.length; i++) {
Document doc = searcher.doc(hits[i].doc);
list.add(doc);
}
System.out.println("搜索list的长度\t→→→→\t"+list.size());
for (Document document : list) {
System.out.println(document.getField("questionname"));
}
analyzer.close();
注:红色字体是输入的检索条件,多个用空格隔开,找到的结果先匹配同时符合多个的结果,结果只是拿过来的document一个list集合,具体结果再解析就行了。
结果如图:
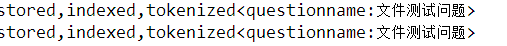
posted @
2013-08-12 17:26 魏文甫 阅读(1206) |
评论 (1) |
编辑 收藏 Connection conn = null;
Statement stat = null;
ResultSet rs = null;
Analyzer sa = new SmartChineseAnalyzer(Version.LUCENE_40);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40, sa);
iwc.setOpenMode(OpenMode.CREATE);
Directory dir1 = FSDirectory.open(new File("F:\\temp"));
IndexWriter writer = new IndexWriter(dir1, iwc);
int numIndexed = -1;
FieldType ft = new FieldType();
ft.setIndexed(true);
ft.setStored(true);
ft.setTokenized(true);
FieldType ft2 = new FieldType();
ft2.setIndexed(true);
ft2.setStored(true);
ft2.setTokenized(false);
Class.forName("com.mysql.jdbc.Driver");
conn = (Connection) DriverManager.getConnection(
"jdbc:mysql:///question", "root", "root");
stat = (Statement) conn.createStatement();
rs = stat.executeQuery("select id,questionname from question");
List<String> list = new ArrayList<String>();
while (rs.next()) {
String id = rs.getString("questionname");
String questionname = rs.getString("questionname");
list.add(id);
list.add(questionname);
}
rs.close();
stat.close();
conn.close();
for (String string : list) {
Document doc = new Document();
doc.add(new Field("questionname", string, ft2));
writer.addDocument(doc);
}
numIndexed = writer.maxDoc();
writer.close();
执行完这段程序f盘多一个文件夹temp,里面就是创建好的索引文件了,然后进行根据索引文件查询
posted @
2013-08-12 16:50 魏文甫 阅读(1441) |
评论 (0) |
编辑 收藏