本篇内容主要来自Introduction to Collections (
http://java.sun.com/docs/books/tutorial/collections/intro/index.html),仅为个人学习和参考之用
集合框架主要包括三部分内容:接口,实现,算法。下面分别来介绍
一. 接口
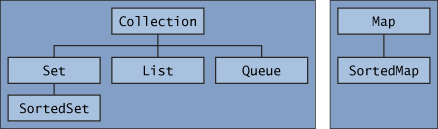
上图所示即为java中集合框架所包含的各种接口。可以发现Map(包括SortedMap)是不继承自Collection的,这是因为Map不同于一
般的Collection,只是一堆元素的结合,Map的特点在于他存储的是一个个“键-值”对,因此他不继承Collection。但是,Map本身还
是提供了很多Collection-views的方法,从而使其能像其他Collection一样进行各种操作。具体将在后面介绍。
下面来简要介绍一下各个接口:
·Collection:是整个collection
hierarchy的root,一个Collection代表一组对象的集合,这些对象称为该Collection的元素(element)。
Collection根据不同的性质可以进行不同的划分,比如允许有重复元素的,不允许的;元素有顺序的,没有顺序的……等等。当时Java
platform并不提供Collection的直接实现类,而是根据上面提到的不同性质,定义了继承自Collection的多个子接口,比如下面将要
提到的Set,List等
·Set:不允许有重复元素的Collection。这个接口是以数学中的集合概念抽象出来的。
·List:允许有重复元素,并且元素有顺序的Collection
·Queue:除了提供基本的Collection操作外,还提供了插入、提取、检查操作。Queue通常采用FIFO机制,但也有特例,比如
priority queue,就支持通过提供的Comparator或者元素自己的natural
ordering(指实现了Comparable接口)对内部元素进行排序。
·Map:存储“键-值”对。Map不允许重复的key,同时一个key最多指向一个value。
·SortedSet:对内部元素进行升序排列的Set。当然了,既然本身已经排好序,那么SortedSet也就相应的提供了一些额外的操作来利用排好的序列。
·SortedMap:对键值进行升序排列的Map。典型的例子:字典,电话簿
下面就来详细介绍各个接口。
1. Collection
下面是Collection接口的代码:
public interface Collection<E> extends Iterable<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
Collection定义了身为一个集合类所应实现的所有方法。当然,其中一些是optional的,可以根据自己的情况选择是否实现。但Java platform所提供的general-purpose的Collection实现类,是实现了这里定义的所有方法的。
遍历一个Collection的方法有两种:
·使用for循环
for (Object o : collection)
System.out.println(o);
·使用Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
void remove(); //optional
}
在每个Collection的实现类内部都有一个非静态成员类来实现Iterator接口。
有两种情况,是必须使用Iterator而不能用for循环的:
·当需要在遍历的同时删除元素时。因为Iterator的remove()方法是遍历过程中修改Collection的唯一安全的方法。
·Iterate over multiple collections in parallel. - 这种情况我没见过
下面一段代码展示了如何在遍历期间删除元素:
static void filter(Collection<?> c) {
for (Iterator<?> it = c.iterator(); it.hasNext(); )
if (!cond(it.next()))
it.remove();
}
关于Collection接口定义的批量处理操作,没什么特别的,知道就行了,需要的时候拿来用:
containsAll — returns true if the target
Collection contains all of the elements in the specified
Collection.
addAll — adds all of the elements in the specified
Collection to the target Collection.
removeAll — removes from the target Collection all
of its elements that are also contained in the specified
Collection.
retainAll — removes from the target Collection all
its elements that are not also contained in the specified
Collection. That is, it retains only those elements in the target
Collection that are also contained in the specified
Collection.
clear — removes all elements from the Collection.
将Collection转换为数组有两种方式:
Object[] a = c.toArray();
String[] a = c.toArray(new String[0]);
第二种方式其实是对
<T> T[] toArray(T[] a);的一种特殊用法。具体参加API doc。
2. Set
首先还是要强调的是Set不允许有重复的元素。
下面是Set接口的代码:
public interface Set<E> extends Collection<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array Operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
你会发现Set的接口内容和Collection是一样的,的确一样,因为Set只包含从Collection继承过来的方法,并不包含其他方法;不仅没加什么东西,反而还多了一个限制:不允许有重复的元素。
除此之外,Set还对equals和hashCode操作有严格的规定。要求即使是两个不同的Set实现类,也能用equals来进行有意义的比较。比如,如果有两个不同的Set实现类的实例,他们包含的元素相同,那么equals比较的结果就是这两个实例也是相等的。
Java platform提供了三种general-purpose的Set实现类:
·HashSet:用Hash Table来存放元素。效率最高(在这三个里面)。在遍历时不能保证元素的顺序。
·TreeSet:用红-黑树来存放元素,有顺序,元素按照值来排列。
·LinkedHashSet:Hash table + linked list存放元素。按照元素的插入顺序来排列元素。牺牲了一些空间,但保证了元素顺序。
由于Set具有的不允许有重复元素的特性,我们可以用下面两种方法来去除某Collection实例中的重复元素:
Collection<Type> noDups = new HashSet<Type>(c);
Collection<Type> noDups = new LinkedHashSet<Type>(c);
第二种方法不仅去除重复元素,而且还保证元素的顺序不会被打乱。
举一个例子来说明Set的基本用法:
public class FindDups {
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
for (String a : args)
if (!s.add(a))
System.out.println("Duplicate detected: " + a);
System.out.println(s.size() + " distinct words: " + s);
}
}
这个例子的关键在于 if(!s.add(a))这句,由于Set不允许有重复元素,因此当要加入的a在Set里已经存在时,将不会被再次加入,此时add方法将返回false。
如果我们使用如下命令进行测试:
java FindDups i came i saw i left
将得到下列结果:
Duplicate detected: i
Duplicate detected: i
4 distinct words: [i, left, saw, came]
额外提一句,用Set来定义s而不是具体的实现类HashSet,是一个比较好的编程习惯,它是我们能够不受约束的改变具体的实现类。
比如,如果我们需要按字母顺序输出的话,那么就可以使用TreeSet来代替HashSet,从而得到下面结果:
java FindDups i came i saw i left
Duplicate detected: i
Duplicate detected: i
4 distinct words: [came, i, left, saw]
关于Set的批量操作,更加显示了Set是作为数学概念上集合的抽象的特性:
s1.containsAll(s2) — returns true if
s2 is a subset of s1. (s2 is a
subset of s1 if set s1 contains all of the elements in
s2.)
s1.addAll(s2) — transforms s1 into the
union of s1 and s2. (The union of two sets is
the set containing all of the elements contained in either set.)
s1.retainAll(s2) — transforms s1 into the
intersection of s1 and s2. (The intersection of two
sets is the set containing only the elements common to both sets.)
s1.removeAll(s2) — transforms s1 into the
(asymmetric) set difference of s1 and s2. (For
example, the set difference of s1 minus s2 is the set
containing all of the elements found in s1 but not in
s2.)
如果我们需要得到这样一个结果:找出在Set s1或者Set s2中存在,但是不在二者中都存在的元素,下面的代码可以完成这样的任务:
Set<Type> symmetricDiff = new HashSet<Type>(s1);
symmetricDiff.addAll(s2);
Set<Type> tmp = new HashSet<Type>(s1);
tmp.retainAll(s2));
symmetricDiff.removeAll(tmp);
注意在上面的代码段中,我们没有破坏s1、s2中的元素。这也是编程中的一个小技巧。
关于Set转换成数组的操作,与Collection接口是完全一样的,不需再介绍。