11.3 I/O类使用
由于在IO操作中,需要使用的数据源有很多,作为一个IO技术的初学者,从读写文件开始学习IO技术是一个比较好的选择。因为文件是一种常见的数据源,而且读写文件也是程序员进行IO编程的一个基本能力。本章IO类的使用就从读写文件开始。
11.3.1 文件操作
文件(File)是 最常见的数据源之一,在程序中经常需要将数据存储到文件中,例如图片文件、声音文件等数据文件,也经常需要根据需要从指定的文件中进行数据的读取。当然, 在实际使用时,文件都包含一个的格式,这个格式需要程序员根据需要进行设计,读取已有的文件时也需要熟悉对应的文件格式,才能把数据从文件中正确的读取出 来。
文件的存储介质有很多,例如硬盘、光盘和U盘等,由于IO类设计时,从数据源转换为流对象的操作由API实现了,所以存储介质的不同对于程序员来说是透明的,和实际编写代码无关。
11.3.1.1 文件的概念
文件是计算机中一种基本的数据存储形式,在实际存储数据时,如果对于数据的读写速度要求不是很高,存储的数据量不是很大时,使用文件作为一种持久数据存储的方式是比较好的选择。
存储在文件内部的数据和内存中的数据不同,存储在文件中的数据是一种“持久存储”,也就是当程序退出或计算机关机以后,数据还是存在的,而内存内部的数据在程序退出或计算机关机以后,数据就丢失了。
在不同的存储介质中,文件中的数据都是以一定的顺序依次存储起来,在实际读取时由硬件以及操作系统完成对于数据的控制,保证程序读取到的数据和存储的顺序保持一致。
每个文件以一个文件路径和文件名称进行表示,在需要访问该文件的时,只需要知道该文件的路径以及文件的全名即可。在不同的操作系统环境下,文件路径的表示形式是不一样的,例如在Windows操作系统中一般的表示形式为C:\windows\system,而Unix上的表示形式为/user/my。所以如果需要让Java程序能够在不同的操作系统下运行,书写文件路径时还需要比较注意。
11.3.1.1.1 绝对路径和相对路径
绝对路径是指书写文件的完整路径,例如d:\java\Hello.java,该路径中包含文件的完整路径d:\java以及文件的全名Hello.java。使用该路径可以唯一的找到一个文件,不会产生歧义。但是使用绝对路径在表示文件时,受到的限制很大,且不能在不同的操作系统下运行,因为不同操作系统下绝对路径的表达形式存在不同。
相对路径是指书写文件的部分路径,例如\test\Hello.java,该路径中只包含文件的部分路径\test和文件的全名Hello.java,部分路径是指当前路径下的子路径,例如当前程序在d:\abc下运行,则该文件的完整路径就是d:\abc\test。使用这种形式,可以更加通用的代表文件的位置,使得文件路径产生一定的灵活性。
在Eclipse项目中运行程序时,当前路径是项目的根目录,例如工作空间存储在d:\javaproject,当前项目名称是Test,则当前路径是:d:\javaproject\Test。在控制台下面运行程序时,当前路径是class文件所在的目录,如果class文件包含包名,则以该class文件最顶层的包名作为当前路径。
另外在Java语言的代码内部书写文件路径时,需要注意大小写,大小写需要保持一致,路径中的文件夹名称区分大小写。由于’\’是Java语言中的特殊字符,所以在代码内部书写文件路径时,例如代表“c:\test\java\Hello.java”时,需要书写成“c:\\test\\java\\Hello.java”或“c:/test/java/Hello.java”,这些都需要在代码中注意。
11.3.1.1.2 文件名称
文件名称一般采用“文件名.后缀名”的形式进行命名,其中“文件名”用来表示文件的作用,而使用后缀名来表示文件的类型,这是当前操作系统中常见的一种形式,例如“readme.txt”文件,其中readme代表该文件时说明文件,而txt后缀名代表文件时文本文件类型,在操作系统中,还会自动将特定格式的后缀名和对应的程序关联,在双击该文件时使用特定的程序打开。
其实在文件名称只是一个标示,和实际存储的文件内容没有必然的联系,只是使用这种方式方便文件的使用。在程序中需要存储数据时,如果自己设计了特定的文件格式,则可以自定义文件的后缀名,来标示自己的文件类型。
和文件路径一样,在Java代码内部书写文件名称时也区分大小写,文件名称的大小写必须和操作系统中的大小写保持一致。
另外,在书写文件名称时不要忘记书写文件的后缀名。
11.3.1.2 File类
为了很方便的代表文件的概念,以及存储一些对于文件的基本操作,在java.io包中设计了一个专门的类——File类。
在File类中包含了大部分和文件操作的功能方法,该类的对象可以代表一个具体的文件或文件夹,所以以前曾有人建议将该类的类名修改成FilePath,因为该类也可以代表一个文件夹,更准确的说是可以代表一个文件路径。
下面介绍一下File类的基本使用。
1、File对象代表文件路径
File类的对象可以代表一个具体的文件路径,在实际代表时,可以使用绝对路径也可以使用相对路径。
下面是创建的文件对象示例。
public File(String pathname)
该示例中使用一个文件路径表示一个File类的对象,例如:
File f1 = new File(“d:\\test\\1.txt”);
File f2 = new File(“1.txt”);
File f3 = new File(“e:\\abc”);
这里的f1和f2对象分别代表一个文件,f1是绝对路径,而f2是相对路径,f3则代表一个文件夹,文件夹也是文件路径的一种。
public File(String parent, String child)
也可以使用父路径和子路径结合,实现代表文件路径,例如:
File f4 = new File(“d:\\test\\”,”1.txt”);
这样代表的文件路径是:d:\test\1.txt。
2、File类常用方法
File类中包含了很多获得文件或文件夹属性的方法,使用起来比较方便,下面将常见的方法介绍如下:
a、createNewFile方法
public boolean createNewFile() throws IOException
该方法的作用是创建指定的文件。该方法只能用于创建文件,不能用于创建文件夹,且文件路径中包含的文件夹必须存在。
b、delect方法
public boolean delete()
该方法的作用是删除当前文件或文件夹。如果删除的是文件夹,则该文件夹必须为空。如果需要删除一个非空的文件夹,则需要首先删除该文件夹内部的每个文件和文件夹,然后在可以删除,这个需要书写一定的逻辑代码实现。
c、exists方法
public boolean exists()
该方法的作用是判断当前文件或文件夹是否存在。
d、getAbsolutePath方法
public String getAbsolutePath()
该方法的作用是获得当前文件或文件夹的绝对路径。例如c:\test\1.t则返回c:\test\1.t。
e、getName方法
public String getName()
该方法的作用是获得当前文件或文件夹的名称。例如c:\test\1.t,则返回1.t。
f、getParent方法
public String getParent()
该方法的作用是获得当前路径中的父路径。例如c:\test\1.t则返回c:\test。
g、isDirectory方法
public boolean isDirectory()
该方法的作用是判断当前File对象是否是目录。
h、isFile方法
public boolean isFile()
该方法的作用是判断当前File对象是否是文件。
i、length方法
public long length()
该方法的作用是返回文件存储时占用的字节数。该数值获得的是文件的实际大小,而不是文件在存储时占用的空间数。
j、list方法
public String[] list()
该方法的作用是返回当前文件夹下所有的文件名和文件夹名称。说明,该名称不是绝对路径。
k、listFiles方法
public File[] listFiles()
该方法的作用是返回当前文件夹下所有的文件对象。
l、mkdir方法
public boolean mkdir()
该方法的作用是创建当前文件文件夹,而不创建该路径中的其它文件夹。假设d盘下只有一个test文件夹,则创建d:\test\abc文件夹则成功,如果创建d:\a\b文件夹则创建失败,因为该路径中d:\a文件夹不存在。如果创建成功则返回true,否则返回false。
m、mkdirs方法
public boolean mkdirs()
该方法的作用是创建文件夹,如果当前路径中包含的父目录不存在时,也会自动根据需要创建。
n、renameTo方法
public boolean renameTo(File dest)
该方法的作用是修改文件名。在修改文件名时不能改变文件路径,如果该路径下已有该文件,则会修改失败。
o、setReadOnly方法
public boolean setReadOnly()
该方法的作用是设置当前文件或文件夹为只读。
3、File类基本示例
以上各方法实现的测试代码如下:
import java.io.File;
/**
* File类使用示例
*/
public class FileDemo {
public static void main(String[] args) {
//创建File对象
File f1 = new File("d:\\test");
File f2 = new File("1.txt");
File f3 = new File("e:\\file.txt");
File f4 = new File("d:\\","1.txt");
//创建文件
try{
boolean b = f3.createNewFile();
}catch(Exception e){
e.printStackTrace();
}
//判断文件是否存在
System.out.println(f4.exists());
//获得文件的绝对路径
System.out.println(f3.getAbsolutePath());
//获得文件名
System.out.println(f3.getName());
//获得父路径
System.out.println(f3.getParent());
//判断是否是目录
System.out.println(f1.isDirectory());
//判断是否是文件
System.out.println(f3.isFile());
//获得文件长度
System.out.println(f3.length());
//获得当前文件夹下所有文件和文件夹名称
String[] s = f1.list();
for(int i = 0;i < s.length;i++){
System.out.println(s[i]);
}
//获得文件对象
File[] f5 = f1.listFiles();
for(int i = 0;i < f5.length;i++){
System.out.println(f5[i]);
}
//创建文件夹
File f6 = new File("e:\\test\\abc");
boolean b1 = f6.mkdir();
System.out.println(b1);
b1 = f6.mkdirs();
System.out.println(b1);
//修改文件名
File f7 = new File("e:\\a.txt");
boolean b2 = f3.renameTo(f7);
System.out.println(b2);
//设置文件为只读
f7.setReadOnly();
}
}
4、File类综合示例
下面以两个示例演示File类的综合使用。第一个示例是显示某个文件夹下的所有文件和文件夹,原理是输出当前名称,然后判断当前File对 象是文件还是文件夹,如果则获得该文件夹下的所有子文件和子文件夹,并递归调用该方法实现。第二个示例是删除某个文件夹下的所有文件和文件夹,原理是判断 是否是文件,如果是文件则直接删除,如果是文件夹,则获得该文件夹下所有的子文件和子文件夹,然后递归调用该方法处理所有子文件和子文件夹,然后将空文件 夹删除。则测试时谨慎使用第二个方法,以免删除自己有用的数据文件。示例代码如下:
import java.io.File;
/**
* 文件综合使用示例
*/
public class AdvanceFileDemo {
public static void main(String[] args) {
File f = new File("e:\\Book");
printAllFile(f);
File f1 = new File("e:\\test");
deleteAll(f1);
}
/**
* 打印f路径下所有的文件和文件夹
* @param f 文件对象
*/
public static void printAllFile(File f){
//打印当前文件名
System.out.println(f.getName());
//是否是文件夹
if(f.isDirectory()){
//获得该文件夹下所有子文件和子文件夹
File[] f1 = f.listFiles();
//循环处理每个对象
int len = f1.length;
for(int i = 0;i < len;i++){
//递归调用,处理每个文件对象
printAllFile(f1[i]);
}
}
}
/**
* 删除对象f下的所有文件和文件夹
* @param f 文件路径
*/
public static void deleteAll(File f){
//文件
if(f.isFile()){
f.delete();
}else{ //文件夹
//获得当前文件夹下的所有子文件和子文件夹
File f1[] = f.listFiles();
//循环处理每个对象
int len = f1.length;
for(int i = 0;i < len;i++){
//递归调用,处理每个文件对象
deleteAll(f1[i]);
}
//删除当前文件夹
f.delete();
}
}
}
关于File类的使用就介绍这么多,其它的方法和使用时需要注意的问题还需要多进行练习和实际使用。
11.3.1.3 读取文件
虽然前面介绍了流的概念,但是这个概念对于初学者来说,还是比较抽象的,下面以实际的读取文件为例子,介绍流的概念,以及输入流的基本使用。
按照前面介绍的知识,将文件中的数据读入程序,是将程序外部的数据传入程序中,应该使用输入流——InputStream或Reader。而由于读取的是特定的数据源——文件,则可以使用输入对应的子类FileInputStream或FileReader实现。
在实际书写代码时,需要首先熟悉读取文件在程序中实现的过程。在Java语言的IO编程中,读取文件是分两个步骤:1、将文件中的数据转换为流,2、读取流内部的数据。其中第一个步骤由系统完成,只需要创建对应的流对象即可,对象创建完成以后步骤1就完成了,第二个步骤使用输入流对象中的read方法即可实现了。
使用输入流进行编程时,代码一般分为3个部分:1、创建流对象,2、读取流对象内部的数据,3、关闭流对象。下面以读取文件的代码示例:
import java.io.*;
/**
* 使用FileInputStream读取文件
*/
public class ReadFile1 {
public static void main(String[] args) {
//声明流对象
FileInputStream fis = null;
try{
//创建流对象
fis = new FileInputStream("e:\\a.txt");
//读取数据,并将读取到的数据存储到数组中
byte[] data = new byte[1024]; //数据存储的数组
int i = 0; //当前下标
//读取流中的第一个字节数据
int n = fis.read();
//依次读取后续的数据
while(n != -1){ //未到达流的末尾
//将有效数据存储到数组中
data[i] = (byte)n;
//下标增加
i++;
//读取下一个字节的数据
n = fis.read();
}
//解析数据
String s = new String(data,0,i);
//输出字符串
System.out.println(s);
}catch(Exception e){
e.printStackTrace();
}finally{
try{
//关闭流,释放资源
fis.close();
}catch(Exception e){}
}
}
}
在该示例代码中,首先创建一个FileInputStream类型的对象fis:
fis = new FileInputStream("e:\\a.txt");
这样建立了一个连接到数据源e:\a.txt的流,并将该数据源中的数据转换为流对象fis,以后程序读取数据源中的数据,只需要从流对象fis中读取即可。
读取流fis中的数据,需要使用read方法,该方法是从InputStream类中继承过来的方法,该方法的作用是每次读取流中的一个字节,如果需要读取流中的所有数据,需要使用循环读取,当到达流的末尾时,read方法的返回值是-1。
在该示例中,首先读取流中的第一个字节:
int n = fis.read();
并将读取的值赋值给int值n,如果流fis为空,则n的值是-1,否则n中的最后一个字节包含的时流fis中的第一个字节,该字节被读取以后,将被从流fis中删除。
然后循环读取流中的其它数据,如果读取到的数据不是-1,则将已经读取到的数据n强制转换为byte,即取n中的有效数据——最后一个字节,并存储到数组data中,然后调用流对象fis中的read方法继续读取流中的下一个字节的数据。一直这样循环下去,直到读取到的数据是-1,也就是读取到流的末尾则循环结束。
这里的数组长度是1024,所以要求流中的数据长度不能超过1024,所以该示例代码在这里具有一定的局限性。如果流的数据个数比较多,则可以将1024扩大到合适的个数即可。
经过上面的循环以后,就可以将流中的数据依次存储到data数组中,存储到data数组中有效数据的个数是i个,即循环次数。
其实截至到这里,IO操作中的读取数据已经完成,然后再按照数据源中的数据格式,这里是文件的格式,解析读取出的byte数组即可。
该示例代码中的解析,只是将从流对象中读取到的有效的数据,也就是data数组中的前n个数据,转换为字符串,然后进行输出。
在该示例代码中,只是在catch语句中输出异常的信息,便于代码的调试,在实际的程序中,需要根据情况进行一定的逻辑处理,例如给出提示信息等。
最后在finally语句块中,关闭流对象fis,释放流对象占用的资源,关闭数据源,实现流操作的结束工作。
上面详细介绍了读取文件的过程,其实在实际读取流数据时,还可以使用其它的read方法,下面的示例代码是使用另外一个read方法实现读取的代码:
import java.io.FileInputStream;
/**
* 使用FileInputStream读取文件
*/
public class ReadFile2 {
public static void main(String[] args) {
//声明流对象
FileInputStream fis = null;
try{
//创建流对象
fis = new FileInputStream("e:\\a.txt");
//读取数据,并将读取到的数据存储到数组中
byte[] data = new byte[1024]; //数据存储的数组
int i = fis.read(data);
//解析数据
String s = new String(data,0,i);
//输出字符串
System.out.println(s);
}catch(Exception e){
e.printStackTrace();
}finally{
try{
//关闭流,释放资源
fis.close();
}catch(Exception e){}
}
}
}
该示例代码中,只使用一行代码:
int i = fis.read(data);
就实现了将流对象fis中的数据读取到字节数组data中。该行代码的作用是将fis流中的数据读取出来,并依次存储到数组data中,返回值为实际读取的有效数据的个数。
使用该中方式在进行读取时,可以简化读取的代码。
当然,在读取文件时,也可以使用Reader类的子类FileReader进行实现,在编写代码时,只需要将上面示例代码中的byte数组替换成char数组即可。
使用FileReader读取文件时,是按照char为单位进行读取的,所以更适合于文本文件的读取,而对于二进制文件或自定义格式的文件来说,还是使用FileInputStream进行读取,方便对于读取到的数据进行解析和操作。
读取其它数据源的操作和读取文件类似,最大的区别在于建立流对象时选择的类不同,而流对象一旦建立,则基本的读取方法是一样,如果只使用最基本的read方法进行读取,则使用基本上是一致的。这也是IO类设计的初衷,使得对于流对象的操作保持一致,简化IO类使用的难度。
程。
基本的输出流包含OutputStream和Writer两个,区别是OutputStream体系中的类(也就是OutputStream的子类)是按照字节写入的,而Writer体系中的类(也就是Writer的子类)是按照字符写入的。
使用输出流进行编程的步骤是:
1、建立输出流
建立对应的输出流对象,也就是完成由流对象到外部数据源之间的转换。
2、向流中写入数据
将需要输出的数据,调用对应的write方法写入到流对象中。
3、关闭输出流
在写入完毕以后,调用流对象的close方法关闭输出流,释放资源。
在使用输出流向外部输出数据时,程序员只需要将数据写入流对象即可,底层的API实现将流对象中的内容写入外部数据源,这个写入的过程对于程序员来说是透明的,不需要专门书写代码实现。
在向文件中输出数据,也就是写文件时,使用对应的文件输出流,包括FileOutputStream和FileWriter两个类,下面以FileOutputStream为例子说明输出流的使用。示例代码如下:
import java.io.*;
/**
* 使用FileOutputStream写文件示例
*/
public class WriteFile1 {
public static void main(String[] args) {
String s = "Java语言";
int n = 100;
//声明流对象
FileOutputStream fos = null;
try{
//创建流对象
fos = new FileOutputStream("e:\\out.txt");
//转换为byte数组
byte[] b1 = s.getBytes();
//换行符
byte[] b2 = "\r\n".getBytes();
byte[] b3 = String.valueOf(n).getBytes();
//依次写入文件
fos.write(b1);
fos.write(b2);
fos.write(b3);
} catch (Exception e) {
e.printStackTrace();
}finally{
try{
fos.close();
}catch(Exception e){}
}
}
}
该示例代码写入的文件使用记事本打开以后,内容为:
Java语言
100
在该示例代码中,演示了将一个字符串和一个int类型的值依次写入到同一个文件中。在写入文件时,首先创建了一个文件输出流对象fos:
fos = new FileOutputStream("e:\\out.txt");
该对象创建以后,就实现了从流到外部数据源e:\out.txt的连接。说明:当外部文件不存在时,系统会自动创建该文件,但是如果文件路径中包含未创建的目录时将出现异常。这里书写的文件路径可以是绝对路径也可以是相对路径。
在 实际写入文件时,有两种写入文件的方式:覆盖和追加。其中“覆盖”是指清除原文件的内容,写入新的内容,默认采用该种形式写文件,“追加”是指在已有文件 的末尾写入内容,保留原来的文件内容,例如写日志文件时,一般采用追加。在实际使用时可以根据需要采用适合的形式,可以使用:
public FileOutputStream(String name, boolean append) throws FileNotFoundException
只需要使用该构造方法在构造FileOutputStream对象时,将第二个参数append的值设置为true即可。
流对象创建完成以后,就可以使用OutputStream中提供的wirte方法向流中依次写入数据了。最基本的写入方法只支持byte数组格式的数据,所以如果需要将内容写入文件,则需要把对应的内容首先转换为byte数组。
这里以如下格式写入数据:首先写入字符串s,使用String类的getBytes方法将该字符串转换为byte数组,然后写入字符串“\r\n”,转换方式同上,该字符串的作用是实现文本文件的换行显示,最后写入int数据n,首先将n转换为字符串,再转换为byte数组。这种写入数据的顺序以及转换为byte数组的方式就是流的数据格式,也就是该文件的格式。因为这里写的都是文本文件,所以写入的内容以明文的形式显示出来,也可以根据自己需要存储的数据设定特定的文件格式。
其实,所有的数据文件,包括图片文件、声音文件等等,都是以一定的数据格式存储数据的,在保存该文件时,将需要保存的数据按照该文件的数据格式依次写入即可,而在打开该文件时,将读取到的数据按照该文件的格式解析成对应的逻辑即可。
最后,在数据写入到流内部以后,如果需要立即将写入流内部的数据强制输出到外部的数据源,则可以使用流对象的flush方法实现。如果不需要强制输出,则只需要在写入结束以后,关闭流对象即可。在关闭流对象时,系统首先将流中未输出到数据源中的数据强制输出,然后再释放该流对象占用的内存空间。
使用FileWriter写入文件时,步骤和创建流对象的操作都和该示例代码一致,只是在转换数据时,需要将写入的数据转换为char数组,对于字符串来说,可以使用String中的toCharArray方法实现转换,然后按照文件格式写入数据即可。
对于其它类型的字节输出流/字符输出流来说,只是在逻辑上连接不同的数据源,在创建对象的代码上会存在一定的不同,但是一旦流对象创建完成以后,基本的写入方法都是write方法,也需要首先将需要写入的数据按照一定的格式转换为对应的byte数组/char数组,然后依次写入即可。
所以IO类的这种设计形式,只需要熟悉该体系中的某一个类的使用以后,就可以触类旁通的学会其它相同类型的类的使用,从而简化程序员的学习,使得使用时保持统一。

序言
本指南对Netty 进行了介绍并指出其意义所在。
1. 问题
现在,我们使用适合一般用途的应用或组件来和彼此通信。例如,我们常常使用一个HTTP客户端从远程服务器获取信息或者通过web services进行远程方法的调用。
然而,一个适合普通目的的协议或其实现并不具备其规模上的扩展性。例如,我们无法使用一个普通的HTTP服务器进行大型文件,电邮信息的交互,或者处理金 融信息和多人游戏数据那种要求准实时消息传递的应用场景。因此,这些都要求使用一个适用于特殊目的并经过高度优化的协议实现。例如,你可能想要实现一个对 基于AJAX的聊天应用,媒体流或大文件传输进行过特殊优化的HTTP服务器。你甚至可能想去设计和实现一个全新的,特定于你的需求的通信协议。
另一种无法避免的场景是你可能不得不使用一种专有的协议和原有系统交互。在这种情况下,你需要考虑的是如何能够快速的开发出这个协议的实现并且同时还没有牺牲最终应用的性能和稳定性。
2. 方案
Netty 是一个异步的,事件驱动的网络编程框架和工具,使用Netty 可以快速开发出可维护的,高性能、高扩展能力的协议服务及其客户端应用。
也就是说,Netty 是一个基于NIO的客户,服务器端编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户,服务端应用。Netty相当简化和流线化了网络应用的编程开发过程,例如,TCP和UDP的socket服务开发。
“快速”和“简单”并不意味着会让你的最终应用产生维护性或性能上的问题。Netty 是一个吸收了多种协议的实现经验,这些协议包括FTP,SMPT,HTTP,各种二进制,文本协议,并经过相当精心设计的项目,最终,Netty 成功的找到了一种方式,在保证易于开发的同时还保证了其应用的性能,稳定性和伸缩性。
一些用户可能找到了某些同样声称具有这些特性的编程框架,因此你们可能想问Netty 又有什么不一样的地方。这个问题的答案是Netty 项目的设计哲学。从创立之初,无论是在API还是在其实现上Netty 都致力于为你提供最为舒适的使用体验。虽然这并不是显而易见的,但你终将会认识到这种设计哲学将令你在阅读本指南和使用Netty 时变得更加得轻松和容易。
第一章. 开始
这一章节将围绕Netty的核心结构展开,同时通过一些简单的例子可以让你更快的了解Netty的使用。当你读完本章,你将有能力使用Netty完成客户端和服务端的开发。
如果你更喜欢自上而下式的学习方式,你可以首先完成 第二章:架构总览 的学习,然后再回到这里。
1.1. 开始之前
运行本章示例程序的两个最低要求是:最新版本的Netty程序以及JDK 1.5或更高版本。最新版本的Netty程序可在项目下载页 下载。下载正确版本的JDK,请到你偏好的JDK站点下载。
这就已经足够了吗?实际上你会发现,这两个条件已经足够你完成任何协议的开发了。如果不是这样,请联系Netty项目社区 ,让我们知道还缺少了什么。
最终但不是至少,当你想了解本章所介绍的类的更多信息时请参考API手册。为方便你的使用,这篇文档中所有的类名均连接至在线API手册。此外,如果本篇文档中有任何错误信息,无论是语法错误,还是打印排版错误或者你有更好的建议,请不要顾虑,立即联系Netty项目社区 。
1.2. 抛弃协议服务
在这个世界上最简化的协议不是“Hello,world!”而是抛弃协议 。这是一种丢弃接收到的任何数据并不做任何回应的协议。
实现抛弃协议(DISCARD protocol),你仅需要忽略接受到的任何数据即可。让我们直接从处理器(handler)实现开始,这个处理器处理Netty的所有I/O事件。
Java代码
package org.jboss.netty.example.discard;
@ChannelPipelineCoverage("all")1
public class DiscardServerHandler extends SimpleChannelHandler {2
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {3
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e) {4
e.getCause().printStackTrace();
Channel ch = e.getChannel();
ch.close();
}
}
代码说明
1)ChannelPipelineCoverage注解了一种处理器类型,这个注解标示了一个处理器是 否可被多个Channel通道共享(同时关联着ChannelPipeline)。DiscardServerHandler没有处理任何有状态的信息, 因此这里的注解是“all”。
2)DiscardServerHandler继承了SimpleChannelHandler,这也是一个ChannelHandler 的实现。SimpleChannelHandler提供了多种你可以重写的事件处理方法。目前直接继承SimpleChannelHandler已经足够 了,并不需要你完成一个自己的处理器接口。
3)我们这里重写了messageReceived事件处理方法。这个方法由一个接收了客户端传送数据的MessageEvent事件调用。在这个例子中,我们忽略接收到的任何数据,并以此来实现一个抛弃协议(DISCARD protocol)。
4)exceptionCaught 事件处理方法由一个ExceptionEvent异常事件调用,这个异常事件起因于Netty的I/O异常或一个处理器实现的内部异常。多数情况下,捕捉 到的异常应当被记录下来,并在这个方法中关闭这个channel通道。当然处理这种异常情况的方法实现可能因你的实际需求而有所不同,例如,在关闭这个连 接之前你可能会发送一个包含了错误码的响应消息。
目前进展不错,我们已经完成了抛弃协议服务器的一半开发工作。下面要做的是完成一个可以启动这个包含DiscardServerHandler处理器服务的主方法。
Java代码
package org.jboss.netty.example.discard;
import java.net.InetSocketAddress;
import java.util.concurrent.Executors;
public class DiscardServer {
public static void main(String[] args) throws Exception {
ChannelFactory factory =
new NioServerSocketChannelFactory (
Executors.newCachedThreadPool(),
Executors.newCachedThreadPool());
ServerBootstrap bootstrap = new ServerBootstrap (factory);
DiscardServerHandler handler = new DiscardServerHandler();
ChannelPipeline pipeline = bootstrap.getPipeline();
pipeline.addLast("handler", handler);
bootstrap.setOption("child.tcpNoDelay", true);
bootstrap.setOption("child.keepAlive", true);
bootstrap.bind(new InetSocketAddress(8080));
}
}
代码说明
1)ChannelFactory 是一个创建和管理Channel通道及其相关资源的工厂接口,它处理所有的I/O请求并产生相应的I/O ChannelEvent通道事件。Netty 提供了多种 ChannelFactory 实现。这里我们需要实现一个服务端的例子,因此我们使用NioServerSocketChannelFactory实现。另一件需要注意的事情是这个工 厂并自己不负责创建I/O线程。你应当在其构造器中指定该工厂使用的线程池,这样做的好处是你获得了更高的控制力来管理你的应用环境中使用的线程,例如一 个包含了安全管理的应用服务。
2)ServerBootstrap 是一个设置服务的帮助类。你甚至可以在这个服务中直接设置一个Channel通道。然而请注意,这是一个繁琐的过程,大多数情况下并不需要这样做。
3)这里,我们将DiscardServerHandler处理器添加至默认的ChannelPipeline通道。任何时候当服务器接收到一个新的连 接,一个新的ChannelPipeline管道对象将被创建,并且所有在这里添加的ChannelHandler对象将被添加至这个新的 ChannelPipeline管道对象。这很像是一种浅拷贝操作(a shallow-copy operation);所有的Channel通道以及其对应的ChannelPipeline实例将分享相同的DiscardServerHandler 实例。
4)你也可以设置我们在这里指定的这个通道实现的配置参数。我们正在写的是一个TCP/IP服务,因此我们运行设定一些socket选项,例如 tcpNoDelay和keepAlive。请注意我们在配置选项里添加的"child."前缀。这意味着这个配置项仅适用于我们接收到的通道实例,而不 是ServerSocketChannel实例。因此,你可以这样给一个ServerSocketChannel设定参数:
bootstrap.setOption("reuseAddress", true);
5)我们继续。剩下要做的是绑定这个服务使用的端口并且启动这个服务。这里,我们绑定本机所有网卡(NICs,network interface cards)上的8080端口。当然,你现在也可以对应不同的绑定地址多次调用绑定操作。
大功告成!现在你已经完成你的第一个基于Netty的服务端程序。
1.3. 查看接收到的数据
现在你已经完成了你的第一个服务端程序,我们需要测试它是否可以真正的工作。最简单的方法是使用telnet 命令。例如,你可以在命令行中输入“telnet localhost 8080 ”或其他类型参数。
然而,我们可以认为服务器在正常工作吗?由于这是一个丢球协议服务,所以实际上我们无法真正的知道。你最终将收不到任何回应。为了证明它在真正的工作,让我们修改代码打印其接收到的数据。
我们已经知道当完成数据的接收后将产生MessageEvent消息事件,并且也会触发messageReceived处理方法。所以让我在DiscardServerHandler处理器的messageReceived方法内增加一些代码。
Java代码
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
ChannelBuffer buf = (ChannelBuffer) e.getMessage();
while(buf.readable()) {
System.out.println((char) buf.readByte());
}
}
代码说明
1) 基本上我们可以假定在socket的传输中消息类型总是ChannelBuffer。ChannelBuffer是Netty的一个基本数据结构,这个数 据结构存储了一个字节序列。ChannelBuffer类似于NIO的ByteBuffer,但是前者却更加的灵活和易于使用。例如,Netty允许你创 建一个由多个ChannelBuffer构建的复合ChannelBuffer类型,这样就可以减少不必要的内存拷贝次数。
2) 虽然ChannelBuffer有些类似于NIO的ByteBuffer,但强烈建议你参考Netty的API手册。学会如何正确的使用ChannelBuffer是无障碍使用Netty的关键一步。
如果你再次运行telnet命令,你将会看到你所接收到的数据。
抛弃协议服务的所有源代码均存放在在分发版的org.jboss.netty.example.discard包下。
1.4. 响应协议服务
目前,我们虽然使用了数据,但最终却未作任何回应。然而一般情况下,一个服务都需要回应一个请求。让我们实现ECHO协议 来学习如何完成一个客户请求的回应消息,ECHO协议规定要返回任何接收到的数据。
与我们上一节实现的抛弃协议服务唯一不同的地方是,这里需要返回所有的接收数据而不是仅仅打印在控制台之上。因此我们再次修改messageReceived方法就足够了。
Java代码
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
Channel ch = e.getChannel();
ch.write(e.getMessage());
}
代码说明
1) 一个ChannelEvent通道事件对象自身存有一个和其关联的Channel对象引用。这个返回的Channel通道对象代表了这个接收 MessageEvent消息事件的连接(connection)。因此,我们可以通过调用这个Channel通道对象的write方法向远程节点写入返 回数据。
现在如果你再次运行telnet命令,你将会看到服务器返回的你所发送的任何数据。
相应服务的所有源代码存放在分发版的org.jboss.netty.example.echo包下。
1.5. 时间协议服务
这一节需要实现的协议是TIME协议 。这是一个与先前所介绍的不同的例子。这个例子里,服务端返回一个32位的整数消息,我们不接受请求中包含的任何数据并且当消息返回完毕后立即关闭连接。通过这个例子你将学会如何构建和发送消息,以及当完成处理后如何主动关闭连接。
因为我们会忽略接收到的任何数据而只是返回消息,这应当在建立连接后就立即开始。因此这次我们不再使用messageReceived方法,取而代之的是使用channelConnected方法。下面是具体的实现:
Java代码
package org.jboss.netty.example.time;
@ChannelPipelineCoverage("all")
public class TimeServerHandler extends SimpleChannelHandler {
@Override
public void channelConnected(ChannelHandlerContext ctx, ChannelStateEvent e) {
Channel ch = e.getChannel();
ChannelBuffer time = ChannelBuffers.buffer(4);
time.writeInt(System.currentTimeMillis() / 1000);
ChannelFuture f = ch.write(time);
f.addListener(new ChannelFutureListener() {
public void operationComplete(ChannelFuture future) {
Channel ch = future.getChannel();
ch.close();
}
});
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e) {
e.getCause().printStackTrace();
e.getChannel().close();
}
}
代码说明
1) 正如我们解释过的,channelConnected方法将在一个连接建立后立即触发。因此让我们在这个方法里完成一个代表当前时间(秒)的32位整数消息的构建工作。
2) 为了发送一个消息,我们需要分配一个包含了这个消息的buffer缓冲。因为我们将要写入一个32位的整数,因此我们需要一个4字节的 ChannelBuffer。ChannelBuffers是一个可以创建buffer缓冲的帮助类。除了这个buffer方 法,ChannelBuffers还提供了很多和ChannelBuffer相关的实用方法。更多信息请参考API手册。
另外,一个很不错的方法是使用静态的导入方式:
import static org.jboss.netty.buffer.ChannelBuffers.*;
...
ChannelBuffer dynamicBuf = dynamicBuffer(256);
ChannelBuffer ordinaryBuf = buffer(1024);
3) 像通常一样,我们需要自己构造消息。
但是打住,flip在哪?过去我们在使用NIO发送消息时不是常常需要调用 ByteBuffer.flip()方法吗?实际上ChannelBuffer之所以不需要这个方法是因为 ChannelBuffer有两个指针;一个对应读操作,一个对应写操作。当你向一个 ChannelBuffer写入数据的时候写指针的索引值便会增加,但与此同时读指针的索引值不会有任何变化。读写指针的索引值分别代表了这个消息的开 始、结束位置。
与之相应的是,NIO的buffer缓冲没有为我们提供如此简洁的一种方法,除非你调用它的flip方法。因此,当你忘记调用flip方法而引起发送错误 时,你便会陷入困境。这样的错误不会再Netty中发生,因为我们对应不同的操作类型有不同的指针。你会发现就像你已习惯的这样过程变得更加容易—一种没 有flippling的体验!
另一点需要注意的是这个写方法返回了一个ChannelFuture对象。一个ChannelFuture 对象代表了一个尚未发生的I/O操作。这意味着,任何已请求的操作都可能是没有被立即执行的,因为在Netty内部所有的操作都是异步的。例如,下面的代 码可能会关闭一 个连接,这个操作甚至会发生在消息发送之前:
Channel ch = ...;
ch.write(message);
ch.close();
因此,你需要这个write方法返回的ChannelFuture对象,close方法需要等待写操作异步完成之后的ChannelFuture通知/监听触发。需要注意的是,关闭方法仍旧不是立即关闭一个连接,它同样也是返回了一个ChannelFuture对象。
4) 在写操作完成之后我们又如何得到通知?这个只需要简单的为这个返回的ChannelFuture对象增加一个ChannelFutureListener 即可。在这里我们创建了一个匿名ChannelFutureListener对象,在这个ChannelFutureListener对象内部我们处理了 异步操作完成之后的关闭操作。
另外,你也可以通过使用一个预定义的监听类来简化代码。
f.addListener(ChannelFutureListener.CLOSE);
1.6. 时间协议服务客户端
不同于DISCARD和ECHO协议服务,我们需要一个时间协议服务的客户端,因为人们无法直接将一个32位的二进制数据转换一个日历时间。在这一节我们将学习如何确保服务器端工作正常,以及如何使用Netty完成客户端的开发。
使用Netty开发服务器端和客户端代码最大的不同是要求使用不同的Bootstrap及ChannelFactory。请参照以下的代码:
Java代码
package org.jboss.netty.example.time;
import java.net.InetSocketAddress;
import java.util.concurrent.Executors;
public class TimeClient {
public static void main(String[] args) throws Exception {
String host = args[0];
int port = Integer.parseInt(args[1]);
ChannelFactory factory =
new NioClientSocketChannelFactory (
Executors.newCachedThreadPool(),
Executors.newCachedThreadPool());
ClientBootstrap bootstrap = new ClientBootstrap (factory);
TimeClientHandler handler = new TimeClientHandler();
bootstrap.getPipeline().addLast("handler", handler);
bootstrap.setOption("tcpNoDelay" , true);
bootstrap.setOption("keepAlive", true);
bootstrap.connect (new InetSocketAddress(host, port));
}
}
代码说明
1) 使用NioClientSocketChannelFactory而不是NioServerSocketChannelFactory来创建客户端的Channel通道对象。
2) 客户端的ClientBootstrap对应ServerBootstrap。
3) 请注意,这里不存在使用“child.”前缀的配置项,客户端的SocketChannel实例不存在父级Channel对象。
4) 我们应当调用connect连接方法,而不是之前的bind绑定方法。
正如你所看到的,这与服务端的启动过程是完全不一样的。ChannelHandler又该如何实现呢?它应当负责接收一个32位的整数,将其转换为可读的格式后,打印输出时间,并关闭这个连接。
Java代码
package org.jboss.netty.example.time;
import java.util.Date;
@ChannelPipelineCoverage("all")
public class TimeClientHandler extends SimpleChannelHandler {
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
ChannelBuffer buf = (ChannelBuffer) e.getMessage();
long currentTimeMillis = buf.readInt() * 1000L;
System.out.println(new Date(currentTimeMillis));
e.getChannel().close();
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e) {
e.getCause().printStackTrace();
e.getChannel().close();
}
}
这看起来很是简单,与服务端的实现也并未有什么不同。然而,这个处理器却时常会因为抛出IndexOutOfBoundsException异常而拒绝工作。我们将在下一节讨论这个问题产生的原因。
1.7. 流数据的传输处理
1.7.1. Socket Buffer的缺陷
对于例如TCP/IP这种基于流的传输协议实现,接收到的数据会被存储在socket的接受缓冲区内。不幸的是,这种基于流的传输缓冲区并不是一个包队 列,而是一个字节队列。这意味着,即使你以两个数据包的形式发送了两条消息,操作系统却不会把它们看成是两条消息,而仅仅是一个批次的字节序列。因此,在 这种情况下我们就无法保证收到的数据恰好就是远程节点所发送的数据。例如,让我们假设一个操作系统的TCP/IP堆栈收到了三个数据包:
+-----+-----+-----+
| ABC | DEF | GHI |
+-----+-----+-----+
由于这种流传输协议的普遍性质,在你的应用中有较高的可能会把这些数据读取为另外一种形式:
+----+-------+---+---+
| AB | CDEFG | H | I |
+----+-------+---+---+
因此对于数据的接收方,不管是服务端还是客户端,应当重构这些接收到的数据,让其变成一种可让你的应用逻辑易于理解的更有意义的数据结构。在上面所述的这个例子中,接收到的数据应当重构为下面的形式:
+-----+-----+-----+
| ABC | DEF | GHI |
+-----+-----+-----+
1.7.2. 第一种方案
现在让我们回到时间协议服务客户端的例子中。我们在这里遇到了同样的问题。一个32位的整数是一个非常小的数据量,因此它常常不会被切分在不同的数据段内。然而,问题是它确实可以被切分在不同的数据段内,并且这种可能性随着流量的增加而提高。
最简单的方案是在程序内部创建一个可准确接收4字节数据的累积性缓冲。下面的代码是修复了这个问题后的TimeClientHandler实现。
Java代码
package org.jboss.netty.example.time;
import static org.jboss.netty.buffer.ChannelBuffers.*;
import java.util.Date;
@ChannelPipelineCoverage("one")
public class TimeClientHandler extends SimpleChannelHandler {
private final ChannelBuffer buf = dynamicBuffer();
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
ChannelBuffer m = (ChannelBuffer) e.getMessage();
buf.writeBytes(m);
if (buf.readableBytes() >= 4) {
long currentTimeMillis = buf.readInt() * 1000L;
System.out.println(new Date(currentTimeMillis));
e.getChannel().close();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e) {
e.getCause().printStackTrace();
e.getChannel().close();
}
}
代码说明
1) 这一次我们使用“one”做为ChannelPipelineCoverage的注解值。这是由于这个修改后的TimeClientHandler不在不 在内部保持一个buffer缓冲,因此这个TimeClientHandler实例不可以再被多个Channel通道或ChannelPipeline共 享。否则这个内部的buffer缓冲将无法缓冲正确的数据内容。
2) 动态的buffer缓冲也是ChannelBuffer的一种实现,其拥有动态增加缓冲容量的能力。当你无法预估消息的数据长度时,动态的buffer缓冲是一种很有用的缓冲结构。
3) 首先,所有的数据将会被累积的缓冲至buf容器。
4) 之后,这个处理器将会检查是否收到了足够的数据然后再进行真实的业务逻辑处理,在这个例子中需要接收4字节数据。否则,Netty将重复调用messageReceived方法,直至4字节数据接收完成。
这里还有另一个地方需要进行修改。你是否还记得我们把TimeClientHandler实例添加到了这个ClientBootstrap实例的默 认ChannelPipeline管道里?这意味着同一个TimeClientHandler实例将被多个Channel通道共享,因此接受的数据也将受 到破坏。为了给每一个Channel通道创建一个新的TimeClientHandler实例,我们需要实现一个 ChannelPipelineFactory管道工厂:
Java代码
package org.jboss.netty.example.time;
public class TimeClientPipelineFactory implements ChannelPipelineFactory {
public ChannelPipeline getPipeline() {
ChannelPipeline pipeline = Channels.pipeline();
pipeline.addLast("handler", new TimeClientHandler());
return pipeline;
}
}
现在,我们需要把TimeClient下面的代码片段:
Java代码
TimeClientHandler handler = new TimeClientHandler();
bootstrap.getPipeline().addLast("handler", handler);
替换为:
Java代码
bootstrap.setPipelineFactory(new TimeClientPipelineFactory());
虽然这看上去有些复杂,并且由于在TimeClient内部我们只创建了一个连接(connection),因此我们在这里确实没必要引入TimeClientPipelineFactory实例。
然而,当你的应用变得越来越复杂,你就总会需要实现自己的ChannelPipelineFactory,这个管道工厂将会令你的管道配置变得更加具有灵活性。
1.7.3. 第二种方案
虽然第二种方案解决了时间协议客户端遇到的问题,但是这个修改后的处理器实现看上去却不再那么简洁。设想一种更为复杂的,由多个可变长度字段组成的协议。你的ChannelHandler实现将变得越来越难以维护。
正如你已注意到的,你可以为一个ChannelPipeline添加多个ChannelHandler,因此,为了减小应用的复杂性,你可以把这个臃肿的 ChannelHandler切分为多个独立的模块单元。例如,你可以把TimeClientHandler切分为两个独立的处理器:
TimeDecoder,解决数据分段的问题。
TimeClientHandler,原始版本的实现。
幸运的是,Netty提供了一个可扩展的类,这个类可以直接拿过来使用帮你完成TimeDecoder的开发:
Java代码
package org.jboss.netty.example.time;
public class TimeDecoder extends FrameDecoder {
@Override
protected Object decode(
ChannelHandlerContext ctx, Channel channel, ChannelBuffer buffer) {
if (buffer.readableBytes() < 4) {
return null;
}
return buffer.readBytes(4);
}
}
代码说明
1) 这里不再需要使用ChannelPipelineCoverage的注解,因为FrameDecoder总是被注解为“one”。
2) 当接收到新的数据后,FrameDecoder会调用decode方法,同时传入一个FrameDecoder内部持有的累积型buffer缓冲。
3) 如果decode返回null值,这意味着还没有接收到足够的数据。当有足够数量的数据后FrameDecoder会再次调用decode方法。
4) 如果decode方法返回一个非空值,这意味着decode方法已经成功完成一条信息的解码。FrameDecoder将丢弃这个内部的累计型缓冲。请注 意你不需要对多条消息进行解码,FrameDecoder将保持对decode方法的调用,直到decode方法返回非空对象。
如果你是一个勇于尝试的人,你或许应当使用ReplayingDecoder,ReplayingDecoder更加简化了解码的过程。为此你需要查看API手册获得更多的帮助信息。
Java代码
package org.jboss.netty.example.time;
public class TimeDecoder extends ReplayingDecoder<VoidEnum> {
@Override
protected Object decode(
ChannelHandlerContext ctx, Channel channel,
ChannelBuffer buffer, VoidEnum state) {
return buffer.readBytes(4);
}
}
此外,Netty还为你提供了一些可以直接使用的decoder实现,这些decoder实现不仅可以让你非常容易的实现大多数协议,并且还会帮你避免某些臃肿、难以维护的处理器实现。请参考下面的代码包获得更加详细的实例:
org.jboss.netty.example.factorial for a binary protocol, and
org.jboss.netty.example.telnet for a text line-based protocol
1.8. 使用POJO代替ChannelBuffer
目前为止所有的实例程序都是使用ChannelBuffer做为协议消息的原始数据结构。在这一节,我们将改进时间协议服务的客户/服务端实现,使用POJO 而不是ChannelBuffer做为协议消息的原始数据结构。
在你的ChannelHandler实现中使用POJO的优势是很明显的;从你的ChannelHandler实现中分离从ChannelBuffer获 取数据的代码,将有助于提高你的ChannelHandler实现的可维护性和可重用性。在时间协议服务的客户/服务端代码中,直接使用 ChannelBuffer读取一个32位的整数并不是一个主要的问题。然而,你会发现,当你试图实现一个真实的协议的时候,这种代码上的分离是很有必要 的。
首先,让我们定义一个称之为UnixTime的新类型。
Java代码
package org.jboss.netty.example.time;
import java.util.Date;
public class UnixTime {
private final int value;
public UnixTime(int value) {
this.value = value;
}
public int getValue() {
return value;
}
@Override
public String toString() {
return new Date(value * 1000L).toString();
}
}
现在让我们重新修改TimeDecoder实现,让其返回一个UnixTime,而不是一个ChannelBuffer。
Java代码
@Override
protected Object decode(
ChannelHandlerContext ctx, Channel channel, ChannelBuffer buffer) {
if (buffer.readableBytes() < 4) {
return null;
}
return new UnixTime(buffer.readInt());
}
FrameDecoder和ReplayingDecoder允许你返回一个任何类型的对象。如果它们仅允许返回一个ChannelBuffer类 型的对象,我们将不得不插入另一个可以从ChannelBuffer对象转换 为UnixTime对象的ChannelHandler实现。
有了这个修改后的decoder实现,这个TimeClientHandler便不会再依赖ChannelBuffer。
Java代码
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
UnixTime m = (UnixTime) e.getMessage();
System.out.println(m);
e.getChannel().close();
}
更加简单优雅了,不是吗?同样的技巧也可以应用在服务端,让我们现在更新TimeServerHandler的实现:
Java代码
@Override
public void channelConnected(ChannelHandlerContext ctx, ChannelStateEvent e) {
UnixTime time = new UnixTime(System.currentTimeMillis() / 1000);
ChannelFuture f = e.getChannel().write(time);
f.addListener(ChannelFutureListener.CLOSE);
}
现在剩下的唯一需要修改的部分是这个ChannelHandler实现,这个ChannelHandler实现需要把一个UnixTime对象重新 转换为一个ChannelBuffer。但这却已是相当简单了,因为当你对消息进行编码的时候你不再需要处理数据包的拆分及组装。
Java代码
package org.jboss.netty.example.time;
import static org.jboss.netty.buffer.ChannelBuffers.*;
@ChannelPipelineCoverage("all")
public class TimeEncoder extends SimpleChannelHandler {
public void writeRequested(ChannelHandlerContext ctx, MessageEvent e) {
UnixTime time = (UnixTime) e.getMessage();
ChannelBuffer buf = buffer(4);
buf.writeInt(time.getValue());
Channels.write(ctx, e.getFuture(), buf);
}
}
代码说明
1) 因为这个encoder是无状态的,所以其使用的ChannelPipelineCoverage注解值是“all”。实际上,大多数encoder实现都是无状态的。
2) 一个encoder通过重写writeRequested方法来实现对写操作请求的拦截。不过请注意虽然这个writeRequested方法使用了和 messageReceived方法一样的MessageEvent参数,但是它们却分别对应了不同的解释。一个ChannelEvent事件可以既是一 个上升流事件(upstream event)也可以是一个下降流事件(downstream event),这取决于事件流的方向。例如:一个MessageEvent消息事件可以作为一个上升流事件(upstream event)被messageReceived方法调用,也可以作为一个下降流事件(downstream event)被writeRequested方法调用。请参考API手册获得上升流事件(upstream event)和下降流事件(downstream event)的更多信息。
3) 一旦完成了POJO和ChannelBuffer转换,你应当确保把这个新的buffer缓冲转发至先前的 ChannelDownstreamHandler处理,这个下降通道的处理器由某个ChannelPipeline管理。Channels提供了多个可 以创建和发送ChannelEvent事件的帮助方法。在这个例子中,Channels.write(...)方法创建了一个新的 MessageEvent事件,并把这个事件发送给了先前的处于某个ChannelPipeline内的 ChannelDownstreamHandler处理器。
另外,一个很不错的方法是使用静态的方式导入Channels类:
import static org.jboss.netty.channel.Channels.*;
...
ChannelPipeline pipeline = pipeline();
write(ctx, e.getFuture(), buf);
fireChannelDisconnected(ctx);
最后的任务是把这个TimeEncoder插入服务端的ChannelPipeline,这是一个很简单的步骤。
1.9. 关闭你的应用
如果你运行了TimeClient,你肯定可以注意到,这个应用并没有自动退出而只是在那里保持着无意义的运行。跟踪堆栈记录你可以发现,这里有一些运行 状态的I/O线程。为了关闭这些I/O线程并让应用优雅的退出,你需要释放这些由ChannelFactory分配的资源。
一个典型的网络应用的关闭过程由以下三步组成:
关闭负责接收所有请求的server socket。
关闭所有客户端socket或服务端为响应某个请求而创建的socket。
释放ChannelFactory使用的所有资源。
为了让TimeClient执行这三步,你需要在TimeClient.main()方法内关闭唯一的客户连接以及ChannelFactory使用的所有资源,这样做便可以优雅的关闭这个应用。
Java代码
package org.jboss.netty.example.time;
public class TimeClient {
public static void main(String[] args) throws Exception {
...
ChannelFactory factory = ...;
ClientBootstrap bootstrap = ...;
...
ChannelFuture future = bootstrap.connect(...);
future.awaitUninterruptible();
if (!future.isSuccess()) {
future.getCause().printStackTrace();
}
future.getChannel().getCloseFuture().awaitUninterruptibly();
factory.releaseExternalResources();
}
}
代码说明
1) ClientBootstrap对象的connect方法返回一个ChannelFuture对象,这个ChannelFuture对象将告知这个连接操 作的成功或失败状态。同时这个ChannelFuture对象也保存了一个代表这个连接操作的Channel对象引用。
2) 阻塞式的等待,直到ChannelFuture对象返回这个连接操作的成功或失败状态。
3) 如果连接失败,我们将打印连接失败的原因。如果连接操作没有成功或者被取消,ChannelFuture对象的getCause()方法将返回连接失败的原因。
4) 现在,连接操作结束,我们需要等待并且一直到这个Channel通道返回的closeFuture关闭这个连接。每一个Channel都可获得自己的closeFuture对象,因此我们可以收到通知并在这个关闭时间点执行某种操作。
并且即使这个连接操作失败,这个closeFuture仍旧会收到通知,因为这个代表连接的 Channel对象将会在连接操作失败后自动关闭。
5) 在这个时间点,所有的连接已被关闭。剩下的唯一工作是释放ChannelFactory通道工厂使用的资源。这一步仅需要调用 releaseExternalResources()方法即可。包括NIO Secector和线程池在内的所有资源将被自动的关闭和终止。
关闭一个客户端应用是很简单的,但又该如何关闭一个服务端应用呢?你需要释放其绑定的端口并关闭所有接受和打开的连接。为了做到这一点,你需要使用一种数据结构记录所有的活动连接,但这却并不是一件容易的事。幸运的是,这里有一种解决方案,ChannelGroup。
ChannelGroup是Java 集合 API的一个特有扩展,ChannelGroup内部持有所有打开状态的Channel通道。如果一个Channel通道对象被加入到 ChannelGroup,如果这个Channel通道被关闭,ChannelGroup将自动移除这个关闭的Channel通道对象。此外,你还可以对 一个ChannelGroup对象内部的所有Channel通道对象执行相同的操作。例如,当你关闭服务端应用时你可以关闭一个ChannelGroup 内部的所有Channel通道对象。
为了记录所有打开的socket,你需要修改你的TimeServerHandler实现,将一个打开的Channel通道加入全局的ChannelGroup对象,TimeServer.allChannels:
Java代码
@Override
public void channelOpen(ChannelHandlerContext ctx, ChannelStateEvent e) {
TimeServer.allChannels.add(e.getChannel());
}
代码说明
是的,ChannelGroup是线程安全的。
现在,所有活动的Channel通道将被自动的维护,关闭一个服务端应用有如关闭一个客户端应用一样简单。
Java代码
package org.jboss.netty.example.time;
public class TimeServer {
static final ChannelGroup allChannels = new DefaultChannelGroup("time-server" );
public static void main(String[] args) throws Exception {
...
ChannelFactory factory = ...;
ServerBootstrap bootstrap = ...;
...
Channel channel = bootstrap.bind(...);
allChannels.add(channel);
waitForShutdownCommand();
ChannelGroupFuture future = allChannels.close();
future.awaitUninterruptibly();
factory.releaseExternalResources();
}
}
代码说明
1) DefaultChannelGroup需要一个组名作为其构造器参数。这个组名仅是区分每个ChannelGroup的一个标示。
2) ServerBootstrap对象的bind方法返回了一个绑定了本地地址的服务端Channel通道对象。调用这个Channel通道的close()方法将释放这个Channel通道绑定的本地地址。
3) 不管这个Channel对象属于服务端,客户端,还是为响应某一个请求创建,任何一种类型的Channel对象都会被加入ChannelGroup。因此,你尽可在关闭服务时关闭所有的Channel对象。
4) waitForShutdownCommand()是一个想象中等待关闭信号的方法。你可以在这里等待某个客户端的关闭信号或者JVM的关闭回调命令。
5) 你可以对ChannelGroup管理的所有Channel对象执行相同的操作。在这个例子里,我们将关闭所有的通道,这意味着绑定在服务端特定地址的 Channel通道将解除绑定,所有已建立的连接也将异步关闭。为了获得成功关闭所有连接的通知,close()方法将返回一个 ChannelGroupFuture对象,这是一个类似ChannelFuture的对象。
1.10. 总述
在这一章节,我们快速浏览并示范了如何使用Netty开发网络应用。下一章节将涉及更多的问题。同时请记住,为了帮助你以及能够让Netty基于你的回馈得到持续的改进和提高,Netty社区 将永远欢迎你的问题及建议。
第二章. 架构总览
在这个章节,我们将阐述Netty提供的核心功能以及在此基础之上如何构建一个完备的网络应用。
2.1. 丰富的缓冲实现
Netty使用自建的buffer API,而不是使用NIO的ByteBuffer来代表一个连续的字节序列。与ByteBuffer相比这种方式拥有明显的优势。Netty使用新的 buffer类型ChannelBuffer,ChannelBuffer被设计为一个可从底层解决ByteBuffer问题,并可满足日常网络应用开发 需要的缓冲类型。这些很酷的特性包括:
如果需要,允许使用自定义的缓冲类型。
复合缓冲类型中内置的透明的零拷贝实现。
开箱即用的动态缓冲类型,具有像StringBuffer一样的动态缓冲能力。
不再需要调用的flip()方法。
正常情况下具有比ByteBuffer更快的响应速度。
更多信息请参考:org.jboss.netty.buffer package description
2.2. 统一的异步 I/O API
传统的Java I/O API在应对不同的传输协议时需要使用不同的类型和方法。例如:java.net.Socket 和 java.net.DatagramSocket它们并不具有相同的超类型,因此,这就需要使用不同的调用方式执行socket操作。
这种模式上的不匹配使得在更换一个网络应用的传输协议时变得繁杂和困难。由于(Java I/O API)缺乏协议间的移植性,当你试图在不修改网络传输层的前提下增加多种协议的支持,这时便会产生问题。并且理论上讲,多种应用层协议可运行在多种传输 层协议之上例如TCP/IP,UDP/IP,SCTP和串口通信。
让这种情况变得更糟的是,Java新的I/O(NIO)API与原有的阻塞式的I/O(OIO)API并不兼容,NIO.2(AIO)也是如此。由于所有的API无论是在其设计上还是性能上的特性都与彼此不同,在进入开发阶段,你常常会被迫的选择一种你需要的API。
例如,在用户数较小的时候你可能会选择使用传统的OIO(Old I/O) API,毕竟与NIO相比使用OIO将更加容易一些。然而,当你的业务呈指数增长并且服务器需要同时处理成千上万的客户连接时你便会遇到问题。这种情况下 你可能会尝试使用NIO,但是复杂的NIO Selector编程接口又会耗费你大量时间并最终会阻碍你的快速开发。
Netty有一个叫做Channel的统一的异步I/O编程接口,这个编程接口抽象了所有点对点的通信操作。也就是说,如果你的应用是基于Netty的某 一种传输实现,那么同样的,你的应用也可以运行在Netty的另一种传输实现上。Netty提供了几种拥有相同编程接口的基本传输实现:
NIO-based TCP/IP transport (See org.jboss.netty.channel.socket.nio),
OIO-based TCP/IP transport (See org.jboss.netty.channel.socket.oio),
OIO-based UDP/IP transport, and
Local transport (See org.jboss.netty.channel.local).
切换不同的传输实现通常只需对代码进行几行的修改调整,例如选择一个不同的ChannelFactory实现。
此外,你甚至可以利用新的传输实现没有写入的优势,只需替换一些构造器的调用方法即可,例如串口通信。而且由于核心API具有高度的可扩展性,你还可以完成自己的传输实现。
2.3. 基于拦截链模式的事件模型
一个定义良好并具有扩展能力的事件模型是事件驱动开发的必要条件。Netty具有定义良好的I/O事件模型。由于严格的层次结构区分了不同的事件类型,因 此Netty也允许你在不破坏现有代码的情况下实现自己的事件类型。这是与其他框架相比另一个不同的地方。很多NIO框架没有或者仅有有限的事件模型概 念;在你试图添加一个新的事件类型的时候常常需要修改已有的代码,或者根本就不允许你进行这种扩展。
在一个ChannelPipeline内部一个ChannelEvent被一组ChannelHandler处理。这个管道是拦截过滤器 模式的一种高级形式的实现,因此对于一个事件如何被处理以及管道内部处理器间的交互过程,你都将拥有绝对的控制力。例如,你可以定义一个从socket读取到数据后的操作:
Java代码
public class MyReadHandler implements SimpleChannelHandler {
public void messageReceived(ChannelHandlerContext ctx, MessageEvent evt) {
Object message = evt.getMessage();
// Do something with the received message.
...
// And forward the event to the next handler.
ctx.sendUpstream(evt);
}
}
同时你也可以定义一种操作响应其他处理器的写操作请求:
Java代码
public class MyWriteHandler implements SimpleChannelHandler {
public void writeRequested(ChannelHandlerContext ctx, MessageEvent evt) {
Object message = evt.getMessage();
// Do something with the message to be written.
...
// And forward the event to the next handler.
ctx.sendDownstream(evt);
}
}
有关事件模型的更多信息,请参考API文档ChannelEvent和ChannelPipeline部分。
2.4. 适用快速开发的高级组件
上述所提及的核心组件已经足够实现各种类型的网络应用,除此之外,Netty也提供了一系列的高级组件来加速你的开发过程。
2.4.1. Codec框架
就像“1.8. 使用POJO代替ChannelBuffer”一节所展示的那样,从业务逻辑代码中分离协议处理部分总是一个很不错的想法。然而如果一切从零开始便会遭遇 到实现上的复杂性。你不得不处理分段的消息。一些协议是多层的(例如构建在其他低层协议之上的协议)。一些协议过于复杂以致难以在一台主机(single state machine)上实现。
因此,一个好的网络应用框架应该提供一种可扩展,可重用,可单元测试并且是多层的codec框架,为用户提供易维护的codec代码。
Netty提供了一组构建在其核心模块之上的codec实现,这些简单的或者高级的codec实现帮你解决了大部分在你进行协议处理开发过程会遇到的问题,无论这些协议是简单的还是复杂的,二进制的或是简单文本的。
2.4.2. SSL / TLS 支持
不同于传统阻塞式的I/O实现,在NIO模式下支持SSL功能是一个艰难的工作。你不能只是简单的包装一下流数据并进行加密或解密工作,你不得不借助于 javax.net.ssl.SSLEngine,SSLEngine是一个有状态的实现,其复杂性不亚于SSL自身。你必须管理所有可能的状态,例如密 码套件,密钥协商(或重新协商),证书交换以及认证等。此外,与通常期望情况相反的是SSLEngine甚至不是一个绝对的线程安全实现。
在Netty内部,SslHandler封装了所有艰难的细节以及使用SSLEngine可能带来的陷阱。你所做的仅是配置并将该SslHandler插入到你的ChannelPipeline中。同样Netty也允许你实现像StartTlS 那样所拥有的高级特性,这很容易。
2.4.3. HTTP实现
HTTP无疑是互联网上最受欢迎的协议,并且已经有了一些例如Servlet容器这样的HTTP实现。因此,为什么Netty还要在其核心模块之上构建一套HTTP实现?
与现有的HTTP实现相比Netty的HTTP实现是相当与众不同的。在HTTP消息的低层交互过程中你将拥有绝对的控制力。这是因为Netty的 HTTP实现只是一些HTTP codec和HTTP消息类的简单组合,这里不存在任何限制——例如那种被迫选择的线程模型。你可以随心所欲的编写那种可以完全按照你期望的工作方式工作 的客户端或服务器端代码。这包括线程模型,连接生命期,快编码,以及所有HTTP协议允许你做的,所有的一切,你都将拥有绝对的控制力。
由于这种高度可定制化的特性,你可以开发一个非常高效的HTTP服务器,例如:
要求持久化链接以及服务器端推送技术的聊天服务(e.g. Comet )
需要保持链接直至整个文件下载完成的媒体流服务(e.g. 2小时长的电影)
需要上传大文件并且没有内存压力的文件服务(e.g. 上传1GB文件的请求)
支持大规模mash-up应用以及数以万计连接的第三方web services异步处理平台
2.4.4. Google Protocol Buffer 整合
Google Protocol Buffers 是快速实现一个高效的二进制协议的理想方案。通过使用ProtobufEncoder和ProtobufDecoder,你可以把Google Protocol Buffers 编译器 (protoc)生成的消息类放入到Netty的codec实现中。请参考“LocalTime ”实例,这个例子也同时显示出开发一个由简单协议定义 的客户及服务端是多么的容易。
2.5. 总述
在这一章节,我们从功能特性的角度回顾了Netty的整体架构。Netty有一个简单却不失强大的架构。这个架构由三部分组成——缓冲(buffer), 通道(channel),事件模型(event model)——所有的高级特性都构建在这三个核心组件之上。一旦你理解了它们之间的工作原理,你便不难理解在本章简要提及的更多高级特性。
你可能对Netty的整体架构以及每一部分的工作原理仍旧存有疑问。如果是这样,最好的方式是告诉我们 应该如何改进这份指南
bug描述:
parseInt("08")=0;
parseInt("09")=0;
这里先回顾一下parseInt的函数声明:
/*
* 将字符串解析成数字时,从左向右依此解析,解析到第一个非法字符即停止。
* 若指定radix为2-36之间的数字,则按相应的进制进行解析;
* 若radix指定为1,或大于36的数字,则直接返回NaN
* 若指定radix为0,或未指定radix,则根据字符串开头字符确定:
* 以'1-9'开头的字符串,按10进制解析;
* 以'0'开头的字符串,按8进制解析;
* 以'0x'或'0X'开头的字符串,按16进制解析。
*
* @param string 要被解析的字符串。
* @param radix 表示要解析的数字的基数。该值介于 2 ~ 36 之间。
*/
parseInt(string, radix)
‘01’到’07’,按8进制或10进制解析会得到相同的结果。 而’08’,’09’按8进制解析会得到’0’,因为’8’、’9’在8进制中是非法字符,不会被解析。由此导致上述的bug。
找到问题根源,修复就变得很简单了,显示指定radix为10.
parseInt("08",10);
在本教程中,我们将看到使用Eclipse调试Java应用程序。调试可以帮助我们识别和解决应用程序中的缺陷。我们将重点放在运行时间的问题,而不是编译时错误。有提供像gdb的命令行调试器。在本教程中,我们将集中在基于GUI的调试,我们把我们最喜爱的IDE Eclipse来运行,通过本教程。虽然我们说的Eclipse,点大多是通用的,适用于调试使用的IDE像NetBeans。
在看这篇文章前,我推荐你看一下Eclipse 快捷键手册,你也可以到这儿:下载PDF文件我的eclipse版本是4.2 Juno。
0.三点特别提醒:
- 不要使用System.out.println作为调试工具
- 启用所有组件的详细的日志记录级别
- 使用一个日志分析器来阅读日志
[
(System.out.println()对开发人员来说,有时候也许可以是一种调试手段,但是项目一旦完成他就没有什么用途了,就变成垃圾了,得必须注释或删除掉,这样会比较麻烦。启用所有组件的详细日志记录级别,运用日志分析器来记录详细系统运行状态,这对后期网站的优化和维护会有很多作用。)这仅仅是个人理解,仅供参考!
]
1.条件断点
想象一下我们平时如何添加断点,通常的做法是双击行号的左边。在debug视图中,BreakPoint View将所有断点都列出来,但是我们可以添加一个boolean类型的条件来决定断点是否被跳过。如果条件为真,在断点处程序将停止,否则断点被跳过,程序继续执行。

2.异常断点
在断点view中有一个看起来像J!的按钮,我们可以使用它添加一个基于异常的断点,例如我们希望当NullPointerException抛出的时候程序暂停,我们可以这样:

3.观察点
这是一个很好的功能,他允许当一个选定的属性被访问或者被更改的时候程序执行暂停,并进行debug。最简单的办法是在类中声明成员变量的语句行号左边双击,就可以加入一个观察点。

4.查看变量
在选中的变量上使用Ctrl+Shift+d 或者 Ctrl+Shift+i可以查看变量值,另外我们还可以在Expressions View中添加监视。

5.更改变量的值
我们可以在Debug的时候改变其中变量的值。在Variables View中可以按下图所示操作。

6.在主方法停止
在Run/Debug设置中,我们可以按如下图所示的启用这个特性。程序将会在main方法的第一行停住

7.环境变量
我们可以很方便的在Edit Conriguration对话框中添加环境变量

8.跳出函数到选定层
这个功能非常酷,是我第二个非常喜欢的功能,Drop to frame就是说,可以重新跳到当前方法的开始处重新执行,并且所有上下文变量的值也回到那个时候。不一定是当前方法,可以点击当前调用栈中的任何一个frame跳到那里(除了最开始的那个frame)。主要用途是所有变量状态快速恢复到方法开始时候的样子重新执行一遍,即可以一遍又一遍地在那个你关注的上下文中进行多次调试(结合改变变量值等其它功能),而不用重来一遍调试到哪里了。当然,原来执行过程中产生的副作用是不可逆的(比如你往数据库中插入了一条记录)。

9.分步过滤
当我们在调试的时候摁F5将进入方法的内部,但这有个缺点有的时候可能会进入到一些库的内部(例如JDK),可能并不是我们想要的,我们可以在Preferences中添加一个过滤器,排除指定的包。

10.跳入,跳过和返回
其实这个技巧是debug最基本的知识。
- F5-Step Into:移动到下一步,如果当前的行是一个方法调用,将进入这个方法的第一行。(可以通过第九条来排除)
- F6-Step Over:移动到下一行。如果当前行有方法调用,这个方法将被执行完毕返回,然后到下一行。
- F7-Step Return:继续执行当前方法,当当前方法执行完毕的时候,控制将转到当前方法被调用的行。
- F8-移动到下一个断点处。
<a href="itms-services://?action=download-manifest&url=http://test1.gc73.com.cn/hoho.plist"> http://test1.gc73.com.cn/hoho.plist 文件格式如下
<?xml version="1.0" encoding="gbk"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>items</key> <array> <dict> <key>assets</key> <array> <dict> <key>kind</key> <string>software-package</string> <key>url</key> <string>http://dlx1.gc73.com/pokerddzV2.1-7.20.iPad.ipa</string> </dict> <dict> <key>kind</key> <string>full-size-image</string> <key>needs-shine</key> <false/> <key>url</key> <string>http://test1.gc73.com.cn/ipad_tmp.png</string> </dict> <dict> <key>kind</key> <string>display-image</string> <key>needs-shine</key> <false/> <key>url</key> <string>http://test1.gc73.com.cn/ipad_tmp.png</string> </dict> </array> <key>metadata</key> <dict> <key>bundle-identifier</key> <string>com.pokercity.fightlordiPad</string> <key>kind</key> <string>software</string> <key>subtitle</key> <string>咱的测试</string> <key>title</key> <string>咱的测试(越狱版)</string> </dict> </dict> </array> </dict> </plist>
用tortoisehg下载google code时报错abort:error
解决方案:将https: 换成http 试一试
VisualVM是Sun的一个OpenJDK项目,其目的在于为Java应用创建一个整套的问题解决工具。它集成了多个JDK命令工具的一个可视化工具,它主要用来监控JVM的运行情况,可以用它来查看和浏览Heap Dump、Thread Dump、内存对象实例情况、GC执行情况、CPU消耗以及类的装载情况。 Java开发人员可以使用 VisualVM创建必要信息的日志,系统管理人员可用来监控及控制Java应用程序在网络中的运行状况。
下载页面 : https://visualvm.dev.java.net/download.html
文档地址 : https://visualvm.dev.java.net/docindex.html
入门文档 : https://visualvm.dev.java.net/zh_CN/gettingstarted.html
安装插件
通过安装 VisualVM 更新中心提供的插件,可以向 VisualVM 添加功能。
1. 从主菜单中选择“工具”>“插件”。
2. 在“可用插件”标签中,选中该插件的“安装”复选框。单击“安装”。
3. 逐步完成插件安装程序。
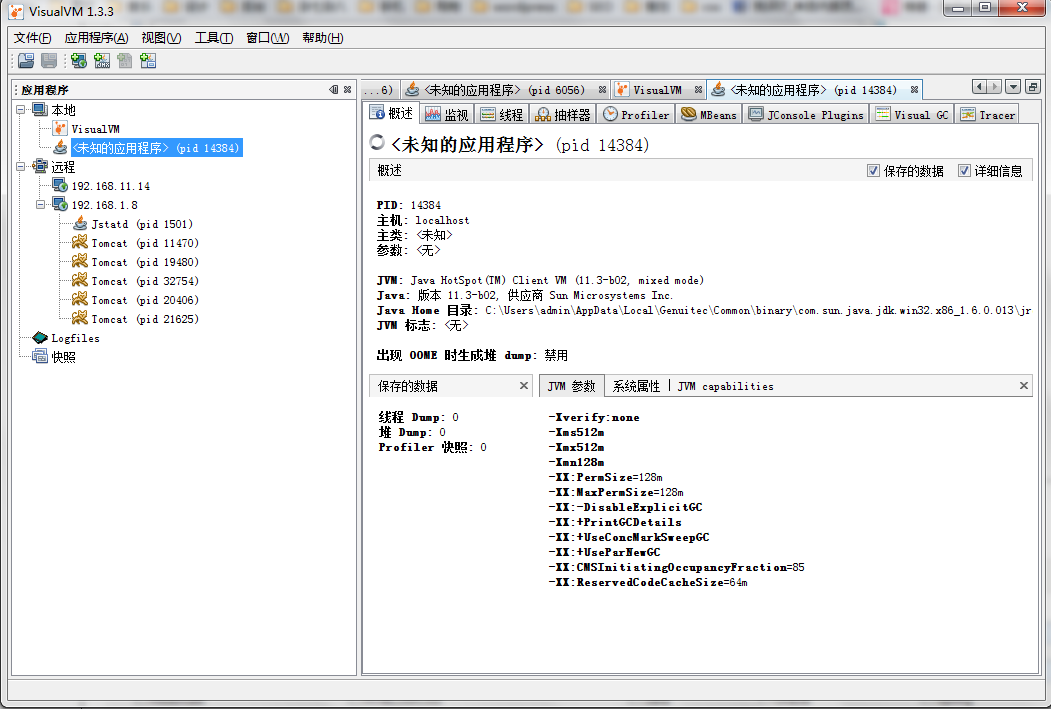
功能
1. 概述
查看jvm信息及系统配置
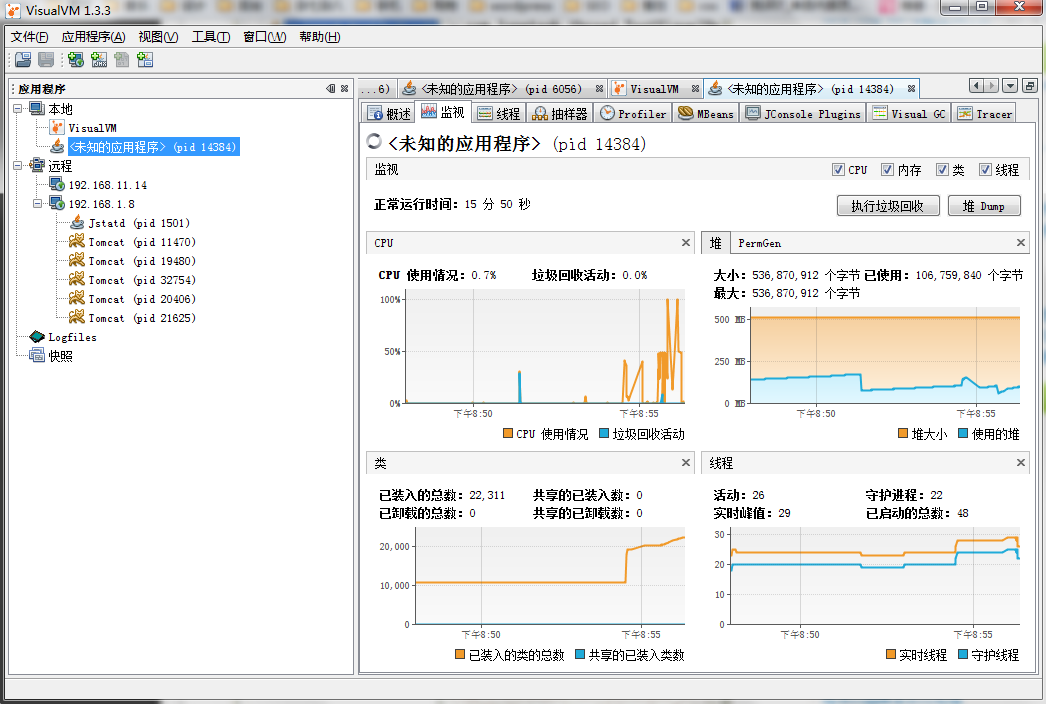
2. 监视
了解项目运动的概况
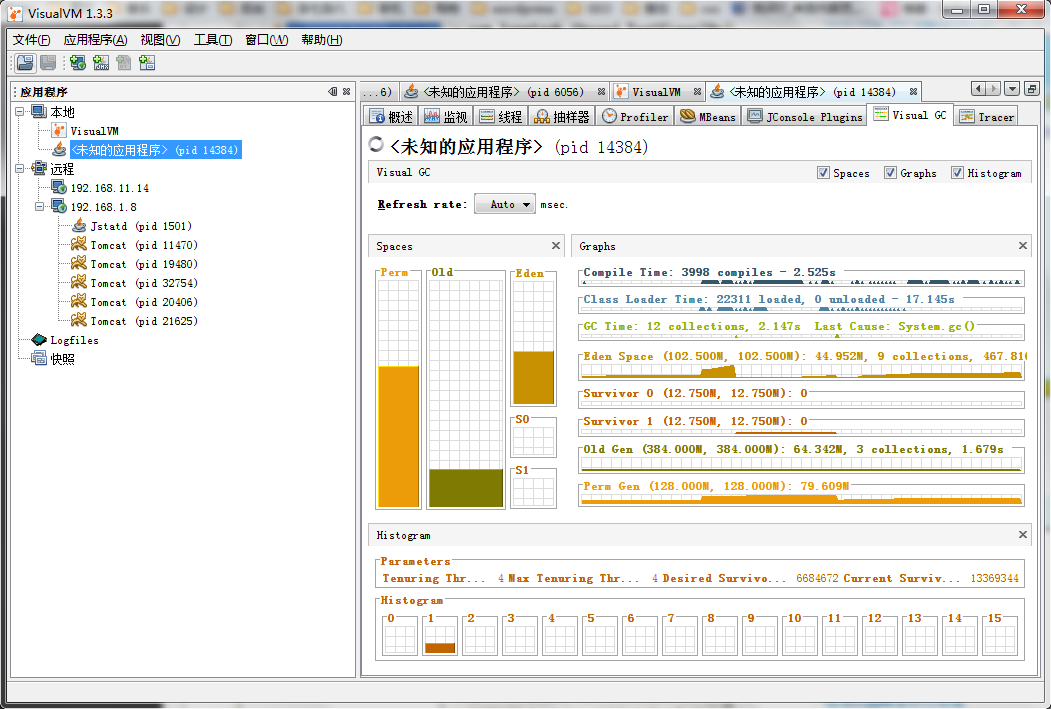
3. visual gc
可以看到内存gc的详细情况
远程监控
1. 通过jstatd启动RMI服务
配置java安全访问,将如下的代码存为文件 jstatd.all.policy,放到JAVA_HOME/bin中,其内容如下,
grant codebase "file:${java.home}/../lib/tools.jar" {
permission java.security.AllPermission;
};
执行命令jstatd -J-Djava.security.policy=jstatd.all.policy -J-Djava.rmi.server.hostname=192.168.1.8 &(192.168.1.8 为你服务器的ip地址,&表示用守护线程的方式运行)
jstatd命令详解 :http://hzl7652.iteye.com/blog/1183182
打开jvisualvm, 右键Remort,选择 "Add Remort Host...",在弹出框中输入你的远端IP,比如192.168.1.8. 连接成功.
2. 配置JMX管理tomcat
打开Tomcat的bin/catalina.bat,如果为linux或unix系统,则为catalina.sh文件 。
无限制访问
set JAVA_OPTS=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9008 -Dcom.sun.management.jmxremote.authenticate=false - Dcom.sun.management.jmxremote.ssl=false
需要用户名和密码访问
JAVA_OPTS='-Xms128m -Xmx256m -XX:MaxPermSize=128m
-Djava.rmi.server.hostname=192.168.1.8
-Dcom.sun.management.jmxremote.port=8088
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=true
-Dcom.sun.management.jmxremote.password.file=/usr/java/default/jre/lib/management/jmxremote.password
-Dcom.sun.management.jmxremote.access.file=/usr/java/default/jre/lib/management/jmxremote.access'
(jmxremote.access 在JAVA_HOME\jre\lib\management下有模板)
jmxremote.access 中显示
monitorRole readonly
controlRole readwrite
jmxremote.password中显示
monitorRole QED (QED为密码)
controlRole R&D
重新在visualvm中打开远程tomcat就可以使用JMX带来的功能了
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)
Ctrl+D: 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变味小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
Alt+Shift+R 重命名 (是我自己最爱用的一个了,尤其是变量和类的Rename,比手工方法能节省很多劳动力)
Alt+Shift+M 抽取方法 (这是重构里面最常用的方法之一了,尤其是对一大堆泥团代码有用)
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候)
Alt+Shift+F 把Class中的local变量变为field变量 (比较实用的功能)
Alt+Shift+I 合并变量(可能这样说有点不妥Inline)
Alt+Shift+V 移动函数和变量(不怎么常用)
Alt+Shift+Z 重构的后悔药(Undo)
编辑
作用域 功能 快捷键
全局 查找并替换 Ctrl+F
文本编辑器 查找上一个 Ctrl+Shift+K
文本编辑器 查找下一个 Ctrl+K
全局 撤销 Ctrl+Z
全局 复制 Ctrl+C
全局 恢复上一个选择 Alt+Shift+↓
全局 剪切 Ctrl+X
全局 快速修正 Ctrl1+1
全局 内容辅助 Alt+/
全局 全部选中 Ctrl+A
全局 删除 Delete
全局 上下文信息 Alt+?
Alt+Shift+?
Ctrl+Shift+Space
Java编辑器 显示工具提示描述 F2
Java编辑器 选择封装元素 Alt+Shift+↑
Java编辑器 选择上一个元素 Alt+Shift+←
Java编辑器 选择下一个元素 Alt+Shift+→
文本编辑器 增量查找 Ctrl+J
文本编辑器 增量逆向查找 Ctrl+Shift+J
全局 粘贴 Ctrl+V
全局 重做 Ctrl+Y
查看
作用域 功能 快捷键
全局 放大 Ctrl+=
全局 缩小 Ctrl+-
窗口
作用域 功能 快捷键
全局 激活编辑器 F12
全局 切换编辑器 Ctrl+Shift+W
全局 上一个编辑器 Ctrl+Shift+F6
全局 上一个视图 Ctrl+Shift+F7
全局 上一个透视图 Ctrl+Shift+F8
全局 下一个编辑器 Ctrl+F6
全局 下一个视图 Ctrl+F7
全局 下一个透视图 Ctrl+F8
文本编辑器 显示标尺上下文菜单 Ctrl+W
全局 显示视图菜单 Ctrl+F10
全局 显示系统菜单 Alt+-
导航
作用域 功能 快捷键
Java编辑器 打开结构 Ctrl+F3
全局 打开类型 Ctrl+Shift+T
全局 打开类型层次结构 F4
全局 打开声明 F3
全局 打开外部javadoc Shift+F2
全局 打开资源 Ctrl+Shift+R
全局 后退历史记录 Alt+←
全局 前进历史记录 Alt+→
全局 上一个 Ctrl+,
全局 下一个 Ctrl+.
Java编辑器 显示大纲 Ctrl+O
全局 在层次结构中打开类型 Ctrl+Shift+H
全局 转至匹配的括号 Ctrl+Shift+P
全局 转至上一个编辑位置 Ctrl+Q
Java编辑器 转至上一个成员 Ctrl+Shift+↑
Java编辑器 转至下一个成员 Ctrl+Shift+↓
文本编辑器 转至行 Ctrl+L
搜索
作用域 功能 快捷键
全局 出现在文件中 Ctrl+Shift+U
全局 打开搜索对话框 Ctrl+H
全局 工作区中的声明 Ctrl+G
全局 工作区中的引用 Ctrl+Shift+G
文本编辑
作用域 功能 快捷键
文本编辑器 改写切换 Insert
文本编辑器 上滚行 Ctrl+↑
文本编辑器 下滚行 Ctrl+↓
文件
作用域 功能 快捷键
全局 保存 Ctrl+X
Ctrl+S
全局 打印 Ctrl+P
全局 关闭 Ctrl+F4
全局 全部保存 Ctrl+Shift+S
全局 全部关闭 Ctrl+Shift+F4
全局 属性 Alt+Enter
全局 新建 Ctrl+N
项目
作用域 功能 快捷键
全局 全部构建 Ctrl+B
源代码
作用域 功能 快捷键
Java编辑器 格式化 Ctrl+Shift+F
Java编辑器 取消注释 Ctrl+\
Java编辑器 注释 Ctrl+/
Java编辑器 添加导入 Ctrl+Shift+M
Java编辑器 组织导入 Ctrl+Shift+O
Java编辑器 使用try/catch块来包围 未设置,太常用了,所以在这里列出,建议自己设置。
也可以使用Ctrl+1自动修正。
运行
作用域 功能 快捷键
全局 单步返回 F7
全局 单步跳过 F6
全局 单步跳入 F5
全局 单步跳入选择 Ctrl+F5
全局 调试上次启动 F11
全局 继续 F8
全局 使用过滤器单步执行 Shift+F5
全局 添加/去除断点 Ctrl+Shift+B
全局 显示 Ctrl+D
全局 运行上次启动 Ctrl+F11
全局 运行至行 Ctrl+R
全局 执行 Ctrl+U
重构
作用域 功能 快捷键
全局 撤销重构 Alt+Shift+Z
全局 抽取方法 Alt+Shift+M
全局 抽取局部变量 Alt+Shift+L
全局 内联 Alt+Shift+I
全局 移动 Alt+Shift+V
全局 重命名 Alt+Shift+R
全局 重做 Alt+Shift+Y
以字母或下划线开头!
今天找一个css的加载问题,class已经被浏览器加载到,但是属性值一直不显示出来,几经查找才发现className以数字开头命名的,导致浏览器不认可,整一个悲剧
BTrace的技术分析,本人暂没有这个技术能力,大家可以看
http://www.iteye.com/topic/1005918,
http://mgoann.iteye.com/blog/1409667 下面是个人写的一些简单实例,不过我一直没办法通过BTrace拿到局部变量的值,不知道哪位牛人帮帮解答下
Linux下:在http://kenai.com/projects/btrace下载btrace-bin.tar.gz,并解压,在/etc/profile设置环境变量: - export BTRACE_HOME=/home/workspace/btrace/
- export PATH=$BTRACE_HOME/bin:$PATH
设置完成后 source /etc/profile
给执行文件赋权限 chmod +x btrace
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
import java.lang.reflect.Field;
@BTrace
public class TracingScript {
/* put your code here */
//打印实例属性
@OnMethod(clazz = "com.gameplus.action.siteLobby.LobbyAction", method = "/.*bankPage/", location = @Location(value = Kind.ENTRY))
//clazz = "com.gameplus.action.siteLobby.LobbyAction" 表示监控的类,method = "/.*bankPage/"表示监控的方法 ,这两个参数都可以用正则匹配
//如果是接口用+号clazz = "+com.gameplus.action.siteLobby.LobbyAction"
public static void bufferMonitor(@Self Object self ){ // @Self 表示监控点实例
print(strcat(strcat(name(probeClass()), "."), probeMethod())); //probeClass()监控的类,probeMethod()监控的方法
println(self);
println(get(field(classOf(self), "money"))); //只能取值static变量
println(get(field(classOf(self), "money"),self)); //可以取值当前实例变量,static也可以取到
Field moneyField = field("com.gameplus.action.siteLobby.LobbyAction", "money"); //知道class的名称也可以取值
get(moneyField,self);
get(field("com.gameplus.action.siteLobby.LobbyAction", "money"), self);
Object montmp =get(field(getSuperclass(classOf(self)), "user"), self); //获取父类变量的方法
println(str(montmp));
long userId = (Long)get(field(classOf(montmp),"userId"),montmp); //获取superClass.Object.变量值
println(userId);
}
//打印运行时lineNumber
@OnMethod(clazz = "com.gameplus.action.siteLobby.LobbyAction", location=@Location(value=Kind.LINE, line=-1))
public static void online(@ProbeClassName String pcn, @ProbeMethodName String pmn, int line) {
print(Strings.strcat(pcn, ".")); //className
print(Strings.strcat(pmn, ":")); //methodName
println(line); //lineNumber
//结果为:com.gameplus.action.siteLobby.LobbyAction.bankPage:161
}
//打印传递的参数值
import com.sun.btrace.AnyType;
@OnMethod(clazz="com.gameplus.service.operateBankService.OperateBankService",method="/.*/")
public static void anyRead(@ProbeClassName String pcn, @ProbeMethodName String pmn, AnyType[] args) {
println(pcn);
println(pmn);
printArray(args);
}
//打印所有属性
@OnMethod(clazz = "com.gameplus.action.siteLobby.LobbyAction", method = "/.*bankPage/", location = @Location(value = Kind.RETURN))
public static void bufferMonitor(@Self Object self,@Return Object command ,@Duration long time){
printFields(self);
Object montmp =get(field(getSuperclass(classOf(self)), "user"), self);
printFields(montmp);
//{password=null, newPassword=null, rePassword=, bankPassword=, newBankPassword=, reBankPassword=, operateType=0, operateBankType=0, money=111, integral=0, dateStartQuery=, dateEndQuery=, isDefaultPasswd=0, }
//{userId=10918, username=titanaly11, realname=方法1, expTime=1146510, bankMoney=1317886229, bankPasswd=243b6503f2e3e83faccc89830aca1d91, ifAvailable=1, password=1bbd886460827015e5d605ed44252251, money=100000, }
}
//初始化时的变量参数
//public User(long userId,String playServerId) {
// this.userId = userId;
// this.playServerId = playServerId;
//}
@OnMethod(clazz = "com.gameplus.core.model.oracle.user.User", method="<init>")
public static void bufferMonitor(@Self Object self,long userId,String gameId){
printFields(self);
println(userId);
println(gameId);
//结果
//{userId=0, username=null, realname=null, expTime=0, bankMoney=0, bankPasswd=null, ifAvailable=0, password=null, money=0, nickName=null, iconNum=0, tim=null, infullCount=0, userToken=null, onlineTime=0,}
//10918
//222
}
//打印系统参数
static {
println("System Properties:");
printProperties();
println("VM Flags:");
printVmArguments();
println("OS Enviroment:");
printEnv();
exit(0);
}
//打印程序执行关系
//LobbyAction中所有方法执行的执行顺序
@OnMethod(clazz="com.gameplus.action.siteLobby.LobbyAction", method="/.*/",
location=@Location(value=Kind.CALL, clazz="/.*/", method="/.*/"))
public static void n(@Self Object self, @ProbeClassName String pcm, @ProbeMethodName String pmn,
@TargetInstance Object instance, @TargetMethodOrField String method){ // all calls to the methods with signature "(String)"
println(Strings.strcat("Context: ", Strings.strcat(pcm, Strings.strcat("#", pmn))));
println(instance); //被调用目标对象
println(Strings.strcat("",method)); //被调用方法
//Context: com/gameplus/action/siteLobby/LobbyAction#bankPage
//$Proxy18@807c31
//getBankPage
//Context: com/gameplus/action/siteLobby/LobbyAction#bankPage
//{userEx=10, leverRestriction=6, isDefaultPasswd=0, bankPassEqGamePass=0, moneyTransferMsg=S, isSimplePasswd=0, mobile=null}
//get
//Context: com/gameplus/action/siteLobby/LobbyAction#bankPage
//6
//intValue
//Context: com/gameplus/action/siteLobby/LobbyAction#bankPage
//{userEx=10, leverRestriction=6, isDefaultPasswd=0, bankPassEqGamePass=0, moneyTransferMsg=S, isSimplePasswd=0, mobile=null}
//get
}
最近在进行MyEclipse启动速度优化,优化发现MyEclipse报这个错误,关掉它的提示后不影响正常的使用.
用visualvm监控发现heap memory正常运转,查看了下配置参数,发现这个参数-XX:+DisableExplicitGC(禁止system.gc()的调用,gc过程完全有jvm控制),怀疑他就是报错的原因,去掉后一切正常.估计是MyEclipse在发现heap memory不足是显示调用了gc方法,然后gc方法不被jvm接受,当内存达到MyEclipse的报警值时报错提醒
http://suhuanzheng7784877.iteye.com/blog/1170585
“武林至尊,宝刀屠龙。号令天下,莫敢不从。倚天不出,谁与争锋。”。这个是我们的射雕英雄郭靖留给倚天屠龙年代的唯一财富,小说中,这笔财富在反元起义军中起到了很重要的作用。咱们不说新版的小说改动吧,就用经典版来说事。倚天剑里面是《九阴真经》,而屠龙刀里面是《武穆遗书》(最新版小说已经修改),单独来讲,倚天剑和屠龙刀都是利器,作为武器,十分锋利。紫衫龙王都说过,灭绝师太凭着倚天剑的锋利,战胜了她,所以她想用屠龙刀雪恨,这当然是紫衫龙王的一种自嘲了。之后还有张无忌决战光明顶时使用白眉鹰王的白虹剑与倚天剑对抗,白虹剑也是一柄罕见的利器了,不过还是玩完了,由此足见倚天剑的威力还是十分给力的!在倚天剑面前,其他的武器立刻成为了神马。但是很多人都不知道了藏在倚天剑的真正价值。
我们往往都是从即时反映出来的效应来发现一个东西的价值,就好比刚刚迈入软件领域的很多侠客们。记得当时笔者在校时身边就一直有很多消息宣传Java如何如何好,J2EE(当时叫J2EE)如何如何,然后很多人就去学习Java,报各种的培训班,买来很多入门书籍。后来又有一股风飘来说微软的.NET如何如何强悍,比Java优越在哪里哪里。后来又兴起PHP技术,这就是有名的3P争霸战,(当然ASP.NET和JavaEE不光是asp与jsp)。各个论坛的帖子争论也一直喋喋不休,甚至出现技术、公司、人身攻击。不仅仅是不同语言之间的斗争,就连相同语言内部也有这样的斗争,比如,Struts2、JSF、Spring Web MVC之间的竞争,为此笔者来写了一篇《Struts2与JSF的瑜亮之争》,当时没有涉及到Spring Web MVC,实事求是,因为笔者当时确实没接触过Spring Web MVC。再比如Hibernate与MyBatis(原先的IBatis)的争论,ExtJS与Jquery的争霸,咱们是用Tomcat还是Jetty,数据库到底用哪个产品啊等等。就连相同语言内部,相似功能软件之间都有这么多的争论。这对于软件使用者来说其实是好事,有争论,有非议,有批评,才更有生命力。
其实还是那句话,真正的高手其实不在乎是用什么技术,甚至不在乎使用什么语言实现软件。高手真正在乎的是如何将一个技术或者说语言发挥到极致,甚至着眼于大局,将各种技术提取优点,用它的优点,整合其他技术规避他的缺点。就比如说很多做电信行业系统的,做业务处理的时候仅仅将Java作为整个大系统的逻辑控制层,Java仅仅接收请求,负责一个业务分发的角色,而底层的核心业务的处理则采用中间件整合C++代码来完成整个业务的处理。
就像之后张无忌与赵敏手下的剑客——阿大进行剑术比试,阿大手中使用的就是之前咱们提到的——很给力的倚天剑啊,而张无忌手中拿的仅仅是一把木剑,张无忌规避倚天剑的锋芒,使用阴柔的太极剑法将阿大打败。张无忌那时候已经算是个顶级高手了,他知道如何让倚天剑发挥不了它的长处,他也知道如何利用太极剑法发挥自己手中这把小小木剑的长处。张无忌就是无论使用何种兵器对他来说都差不多,只能说如果是绝世兵器在他手中发挥得更加淋漓尽致罢了。关键还是他的修为在那里,基本上还是以武学修为做为胜负的关键因素。
从中也可以看出所谓编程语言、技术、中间件产品不过是实现某种商业目的的一种手段罢了,所有的技术幕后都是一桩桩充满铜臭味的商业运作罢了。当时年轻的笔者怀着崇敬的心等待着Java阵营将.NET阵营彻底打败,以证明当初自己的选择是正确的,谁能想到最先趴下缴械的居然就是咱们崇敬的Sun啊。被甲骨文收购后,逼迫JavaEye改名为ITEye,现在又向Google索取巨额的Java侵权费用,不得不让我们感叹,何时Java也充满了这种商业的铜臭味,没办法咱们只能接受,一切一切的技术推进都是商业巨头们的运作结果。所以技术仅仅是个手段工具罢了,如果将它作为一种崇拜对象,成为自己生命不可或缺的部分。哥们儿,姐们儿,随着时间的推移,可能会让你越来越心寒哦。
后来倚天剑和屠龙刀终于再次汇合,才将刀剑真正的价值体现出来,原来将他们的优点结合在一起,互相利用各自的锋芒,将潜藏里面的东东挖掘出来。我们再为客户做软件技术解决方案的时候也可以将不同技术、不同语言的优势融合进来,形成一个改造后的大融合系统,取长补短,将软件发挥到最极致的功能,有点瑕疵不怕,怕的是不能抛弃门户之见的执着,依然死守原有规矩,不肯也不敢进行技术思想上的大解放。
当然,可以理解一点的就是,可能对于比较感情化的朋友来说,对于第一门认真学习,并花了大把时间的技术抱有很深的感情,对于第一门认真下功夫学习的技术语言,程序员一般都有一种微妙的感情在里面。这种感情笔者称之为“技术的初恋”,“初恋”嘛,就意味着当事人想让这段感情更加持久,不希望,当然更不允许任何人对当事人的“初恋”对象说一点点不好,所以大家一般从各大论坛上看到的各种技术、语言之间的口水战都发生在刚刚进入某技术领域的朋友。这些朋友也不允许其他技术阵营的人来对自己的“技术初恋”进行所谓的评头论足,指指点点。这种感情是纯洁的,是高尚的。将心比心,大家都是从菜鸟一步步成长起来的,都是从不懂的时候慢慢找资源学习熬过来的。在学习的过程中大家或多或少有一些收获和小成就,这就好比这个“初恋情人”给你这个当事人一点点爱情的奖励似的。也有朋友将这种爱情“奖励”的过程和经验分享出来,就是我们看到很多技术Blog文章,无论怎样,都请看文章的朋友们尊重那些你们眼中的“菜鸟”,不要认为自己多么多么NB就随意践踏那些淳朴程序员们的感情,践踏这些人的劳动成果是十分残忍的事情,就和践踏别人的初恋一样。看得博客文章内容简单,你可以什么都不说,也可以对那些作者提一些自己的建议,给新人一些建设性的意见,分享一些自己的经历。开口就骂:什么“作者低能”、“这种问题都问”的人,这样恐怕不太好吧,因为请各位老鸟们记住,你也经历过那个阶段的人,只不过你比人家多长了几岁,比人家接触知识点的早一些罢了,没什么值得自豪和炫耀的。除非你投胎的时候没洗去前世的记忆,恰巧你前世又是个拿过诺贝尔奖的高手甚至是爱因斯坦转世,那另当别论,你一出生你就成功了……对新人,多一些鼓励,善莫大焉。
我只是要说,请各位纯情的程序员朋友们记住一首歌——《当爱已成往事》:只要有爱就有痛啊,有一天你会知道,人生没有它(当然指具体的技术实现或者编程语言了)并不会有什么不同。选择还是很多的,只要能顺应商业潮流,为客户解决问题,发挥自己所学东西的最大优势就好喽。无论您是刀狂还是剑痴,重要的是刀剑合一,无刀无剑,一枚绣花针也能挥洒自如,呵呵~
http://suhuanzheng7784877.iteye.com/blog/1115472
很多人认为我们程序员不会做人,至少认为我们在人际交际方面缺乏技巧。程序员一遇到人际方面的事情就发憷,和售前人员,领导,甚至是客户都不太会沟通,遇到非技术的事情,就慌了,往往作出的决定比较茫断!
反正笔者确确实实觉得是有这样的问题,不说大的方面吧,我们就看看在工作中如何做顺水人情。可能标题有点大,一般职场说不上什么恩德吧,但是总可以说得上是顺水人情吧。各位看过金庸小说的朋友觉得谁值得我们学习呢?笔者觉得做人际交流的典范就是韦小宝,他有很多值得我们学习的地方,以后比这还要说他,咱们这次只单看看他如何做顺水人情,施恩给别人的。从中我们以后遇到非技术事情要处理的时候是不是脑中多了一个Java监视器类,触发事件后时刻提醒我们:“如果是韦小宝,他会怎么做?他该怎么做?他会如何说话?”。
当康熙让韦小宝剿灭王屋山的时候,韦小宝特地找了个叫赵良栋的,第一,韦小宝不会打仗,即便是小规模的剿匪,他自己都说:“老子不是干这种事的人才”,但是康熙下令让他就得这么做。第二,他不想让第N个小老婆——曾柔受伤害,要不就亏大了。第三,王屋山和天地会(当然放到现在咱们叫反和谐社会的不法组织)有关联,如果让陈近南知道后果肯定会让韦小宝不爽。第四,王屋山本身和韦小宝本人的交情也不错,也算是以前建立起的人脉财富吧,如果干掉,那么意味着以前的人脉关系维系全他娘玩完了。韦小宝若是严格执行君令,那么,有三个损失,只有一个好处,不违背康熙的命令。好的,我们的韦爵爷才不会像Java虚拟机那么忠实,编译后class文件是什么样的,我们的编译器就怎么执行。韦小宝则更像是康熙的实现类,康熙是接口,下个命令(接口方法),很抽象,他只关心结果,不关心过程,那么韦小宝如何实现这个接口,完全由韦小宝负责具体的细节,之后康熙的目的达到了,王屋山这个匪政权确实没了,那康熙的目的就达到了(尽管康熙在实现类——韦小宝身边安装了监听器),韦小宝的人情也做足了,第一,执行命令的同时,收编曾柔小老婆,曾柔感觉韦小宝好很伟,很强大,既挽救了师兄弟,又救了自己,真帅啊,美人到手。第二,对于天地会那边也有交代,陈近南知道后只会向其他兄弟夸耀我这个徒弟有雄略,有义气,有侠气。只会更喜欢这个徒弟,后来陈近南也说了一句,“以后天地会就要靠你了”,完全有继承他衣钵的意思,师父面子上也有光,在反政府武装组织天地会中也更有声望,声誉,名望到手。第三,王屋山其他兄弟也是对他感激涕零,敢于冒死命,因为那时候反政府组织内部最讲究的就是个义气,大多数江湖反政府组织大多穷苦出身,都是哥们儿义气当先,咱们看《书剑恩仇录》中的红花会也能看得出来,那么这样韦小宝人心到手。
韦小宝这么做真叫一个高明,也是他小小年纪做事如此周详,实属难得,也许是官场的历练让他做什么事情都先权衡以下各方利弊,当然对于自己的利益权重是最大的。之后韦小宝还有很多案例都说明韦小宝做人情做到十足~不但自己的目的达到了,还为其他人某了本身不应该有的福利待遇。带领施琅炮轰神龙岛,不仅将自己最忌惮的神龙教弄得七零八落,还让一个军事人才施琅有了一展才华的机会,后来施琅也是为了还他人情,让韦小宝在通吃岛住了一段悠闲的日子。索额图、明珠、康亲王这些在政治官场上老油条也感怀韦小宝在官场上的照顾人情,当然这些人出于政治目的,但是韦小宝对官场政治着实不怎么看重,索性做顺水人情,他的潜台词就是:“你们这些人不必揣摩圣意了,不必为难。我和皇帝做个双簧戏,你们立刻知道皇上的意思了~”,主战派和主和派心里就有底了。
其实说了那么多,都是想提醒自己,假如这种非技术性质的事情到自己头上后该怎么办?我觉得第一还是先想到与此事相关的人,最好有个关系——角色映射图,一个事情的处理关系到哪些人,需要明确下来。第二就是一个事情该怎么做,有几条途径。如果只有想来想去一条路,不妨先将此事放放,转一下注意力,再回头来看看是否还有别的路可走(一般情况下应该会有另外的途径吧)。第三,就是根据每一条途径去看每一个关系人的受益和损失程度。根据每个人在此事件中担当的角色,最后找出一个最好的解决事情的途径出来。虽然很多读者都会说,照你这么做事,太麻烦了吧,不必吧,用得着吗?值得吗?笔者则认为哪怕是多么小的事情,这么做也不为过,虽然麻烦点,但是细节决定成败啊,厚人薄己得人心啊。
还有就是很多人有疑问,就是按照你这么做事情,过于麻烦,如果遇到即使就要做出决策的突发事情,比如就是上司、客户突然来了电话,那该怎么办?第一,遇到这种及时解决的问题,那么最起码“现在没有想好,需要和XXX商量商量才能决定”;“哦,不好意思,我现在电话说不清楚,环境比较杂乱”,稍后给您打过去;“容我想一想”这种缓兵之计的话总能说出口吧。总比那种脑子一热就做出决策的冲动选择要好得多吧。当然了,如果突发事件对事件关系的每个当事人都有好处,对于你来说又是十分有把握轻而易举就能完成,你当然就能及时应答下来了。这不是冲动,是自信!如果说遇到的客户,就必须要你当时做决策,笔者感觉利用以上方法经验比较多了,脑中的反应也会逐渐变快,作出的决策可能也比没有联想的决策付出的代价要小一些。说起来这个有点像咱们之前系统访问负载均衡中的最优化策略了。这样,事件的关系人也会对你怀有一种感怀的心,人情也做足了。你自己从中得到了下属的信任,上司的认可,明智客户的奖励(哪怕是口头上的夸赞呢,也行了),你自己从中也是得到了锻炼,经验,做事也越来越老练。这样各位朋友人生的路也会变得越来越宽,其他人也愿意和您这样能为他们利益着想的人公事。
执着能杀人,在执着杀死你之前,请将它杀死。看过《天龙八部》的人一定记得那经典的一段珍珑棋局吧。我们就从这盘棋局说起。逍遥掌门让苏星河布置珍珑棋局是为了替逍遥派清理门户,继承自己的衣钵。参与这场棋局的主要有四人(范百龄就算了吧),段誉、慕容复、段延庆、虚竹。其中,虚竹不怎么会下棋,假借段延庆的传音入耳和他的棋艺通过了面试,最终获得逍遥掌门的绝世内功。我们就看慕容复的执着是如何差点要他命的。慕容复胸怀大志,参与这个棋局其实目的也比较简单,扩大自己声望,结交江湖名士,为自己日后富国铺路。但是慕容复对于胜败结果太过于执着了,对胜负总是看得比谁都重要,就好像慕容复的心中就不允许失败一样,对武功的高低执着、对棋局的胜败执着,对复国的事业依然执着。看看他与段誉的区别,这个珍珑棋局变幻百端,因人而施,爱财者因贪失误,易怒者由愤坏事。段誉之前之所以败,是因为爱心太重,不肯弃子;慕容复之失,由于执着权势,虽然勇于弃子,却说什么也不肯失势。
棋局的胜败都看得如此重要,那对于其他方面的胜负就不必说了,在少林寺因为败于段誉的六脉神剑而羞愧得想自杀,这难道是一个想问鼎中原的未来复国君王应该做的事情?
过分的执着往往意味着急功近利,萧远山执着于他的报仇,却从没想到他的亲生儿子会因为他的滥杀而被整个武林误会,成为武林的公敌,才会有后来的少林寺混战。慕容复的父亲——慕容博也因为执着于他的复国之路,造成了武林的恩恩怨怨。鸠摩智执着于他的武功,功名,到最后留给后人的却不是他的独门武功,而是他的传教经典和佛法,直至今日给我们现代人,留下的究竟是丰碑还是悲风呢。段誉执着于王语嫣的痴情,其间路途也是坎坷万分,幸运的是金庸给了他一个美满的结局,换到真实世界恐怕就不那么幸运了。萧远山与慕容博到后来他们在少林遇到了无名曾,在无名曾的安排下先让萧远山看着慕容博死去,之后在自己动手让萧远山假死。等两个人醒来后,问他们:“你二人由生到死、由死到生的走了一遍,心中可还有甚么放不下?倘若适才就此死了,还有甚么兴复大燕、报复妻仇的念头?”。二人大彻大悟,终于不再执着于过去的恩恩怨怨,功名富贵,专心研究佛法,参禅。实际上无名曾杀死的不仅仅是过去的两个“大恶人”,更深的一层实际是借无名曾之手杀死了他们自己的执着。
不说《天龙八部》,比如《连城诀》中尔虞我诈的三个师兄弟;《射雕英雄传》的欧阳锋;《鹿鼎记》的陈近南;《笑傲江湖》的岳不群、左冷禅、任我行、林平之;《倚天屠龙记》的谢逊、成昆;《碧血剑》中的金蛇郎君……多少人因为过分的执着而掩盖了本应该光彩的人生?
那我们呢?我们在竞争激烈、追名逐利的今天是否也因为过分的执着而弯曲了我们原有的人生轨迹?虽然说在现代我们不会因为过于执着而献出宝贵的生命,但是回想一下,我们是不是也因为我们过分的执着于某些事情而错过了很多不应该错过的东西呢?或者还可以说,我们是不是因为执着导致我们原有的水平、能力、智慧、知识都打了折扣。张无忌在学《乾坤大挪移》的时候到最后有几句话不是很明白,如果他执着于弄明白,估计结果和阳顶天一样。当令狐冲和任盈盈同处大车之中,徜徉于青纱帐外的大路上时,对岳灵珊痴情的执着终于消失 了,他也得到心灵上的解脱。
一个项目苦战数月未有结果、一段程序苦苦调试很长时间问题依旧,这个时候我们是否可以先放一放,看看外面的风景,泡一杯茶,慢慢品味苦中有甜的滋味,过后调试程序换一种思路,项目管理大胆尝试一下新的管理方式,没准可以发现新的天地。如果一味的朝一个方向死走,一条道走到底,幸运的人可以走出去,祝贺你当时相对地选对了路,不幸运的人就会钻牛角尖了。搞研发的适时可能会去做manager的职位,也可以去搞product售前等等,就是因为很多开发人员自身很清高,不愿意,甚至说是不屑做人际、关系上的事情。那么你对人家不屑,人家对你也不屑。有时候咱们是要放下那些执念,勇于改变以前的想法和初衷。因为有可能当初的理想、志向、目标是不成熟的,而我们还依然一直执着下去……
当然笔者年龄、阅历、经验等等均有限,仅仅是将我个人的经历和心得分享出来,绝对不是站在一个教育者的高姿态来教育某某某,绝无此意。仅仅是下次看到自己曾经走过的弯路时多一份沉重,时刻提醒自己罢了,“执着会杀人,当它没有杀死你的时候趁早消灭它”。放弃执着,也许你会看到另一片你从未看到过的天地在迎接你。
http://suhuanzheng7784877.iteye.com/blog/1096125
用电影《东邪西毒》的台词作为开头,“任何人都可以狠毒,只要你尝试过什么是嫉妒,我不在乎别人怎么看我,我只是不想别人比我更开心。”。嫉妒心是人人都会有的,除非真正看破红尘的人,不在此列,哀莫大于心死,心死的人再无好胜之心,可以说嫉妒心也远离他而去,不过我们这些打工的就算了,肯定是个凡人吧。
《笑傲江湖》里面的林平之,刚开始是一个诚实、有正义感的年轻人。金庸刚开始把他写得也是有光彩的,就在福州小店,为假扮店老板的劳得诺和岳灵珊打抱不平,就能看出从骨子里他还是有正义感的。惨遭青城派灭门,林平之沿路到各个镖局分局去投奔。那个时候他也完全摒弃了富二代的架子,忍辱负重,惨遭众多磨难,终于拜了岳不群为师。可以说在《笑傲江湖》前面的章节,作者对林平之绝对是赞许的。试想一个富二代遭遇了如此重大的家庭变故,还能放下架子,忍辱负重。宁愿去给人家当小徒弟,也不去投靠外公。足可以看出,林平之前期有志气、有骨气、有侠气。而且林平之说过他只想靠一己之力报仇雪恨,绝不愿意假手其他人。如此光明磊落,说实话,没有看过笑傲江湖的读者,前期大家一定以为这应该就是《笑傲》的主角了吧。事宜愿为,林平之最后的下场大家是知道的,很多读者对他都是惋惜的态度。笔者对林平之的态度是:对他的遭遇感到同情,对他的毅力表示敬佩,对他的残忍表示愤怒。对于他的结果,我认为原因很多,但究其个人原因,我认为主要是因为林平之的嫉妒心。有人问,他嫉妒谁?毁了他的是余沧海、是木驼峰、是岳不群。林平之应该恨得是他们,何来嫉妒之心。是的!毁了福威镖局的是他们。林平之也是恨他们,但是他嫉妒的不是这些中年人,他嫉妒的是比他大不了几岁的令狐冲。笔者之前也确实有疑问,为何林平之对令狐冲如此恨得咬牙切齿。后来明白是嫉妒。
令狐冲出身不如林平之,就一个孤儿,没有什么家庭背景,和林平之家世相比甚远;令狐冲长相不如林平之俊俏,书中有描写,令狐冲是一个高大的男子,林平之是福建那边的人,长相比较像母亲,俊俏得很,真得是现在很多女孩子心目中的奶油小生;林平之教育良好,见过大世面,令狐冲就是一个穷小子,更谈不上什么高等文化了,识字,读书已经不错了,林平之的涵养在令狐冲之上。那么他到底有什么理由嫉妒他呢。正是因为以上原因,林平之就觉得自己有优越感,进入华山派后处处与令狐冲进行比较,从令狐冲初学独孤九剑打败封不平、成不忧后。林平之就开始不爽这个大师兄了,他嫉恨得不是别的,就是他的际遇不如令狐冲。之后祖千秋设酒,问令狐冲和其他华山弟子敢不敢喝就,只有林平之一个人敢站出来说:“有什么不敢的!”实际上暗中已经和大师兄较上了劲。更兼令狐冲剑法诡异,林平之不得不怀疑他的剑法从哪儿来的?虽然事后证明不是《辟邪剑谱》,但是他总是先入为主,认为令狐冲欠了他什么似的。
嫉妒心蒙蔽了他的双眼和原有的良知!使他疯狂的将一切罪过转移给了令狐冲。林平之杀了余沧海后其实仇人只剩下岳不群,但是林平之一直认为令狐冲才是他最大的对手,欲除之而后快。最后把真正的BOSS级的敌人忽略了。如果他摒弃一颗嫉妒心,目标会更明确,如果他学完辟邪剑法后继续韬光养晦,先故意输给余沧海(反正学完了辟邪剑法自保肯定没问题),之后回到岳不群身边伺机先干掉这个BOSS级人物,之后再除掉余沧海,估计林平之获得的东西会更多,最好的结果是岳不群辛苦半生的成果给了林平之做了嫁衣(哦,也许说嫁妆更合适)。
说了这么多咱们会过来看看自己的人生是不是也有过类似的现象,几个比较好的同事。刚开始大家都是怀着一颗纯真的心交往的。大家都是肝胆相照,有说有笑,像兄弟一样。尤其是那些背井离乡的同志们更有一种身在异乡,互相依赖,互相扶持的感情在里面。久而久之,因为公司的各种原因吧,将你不错的同事、同学、朋友的职位调了一级,工资翻了一倍。或者另一个同事跳槽了,各种待遇在你之上。那么你会不会心里有一丝不爽呢~呵呵,大家都不必否认,多多少少都有一点,这是人性,回避不了。在咱们这样一个和谐社会下的人们,正常思考的人们多多少少都有点嫉妒,嫉妒程度多少因人而异。我觉得有一点嫉妒心很正常,而且也是好事,它能刺激你进步,在自己的心里就会给自己一种压力:“他都到了那个程度,那我呢?大家是同一起点~”。积极的人,会因为这细微的嫉妒,自强、奋进、朝着自己的新目标前进。但是如果嫉妒心过重,就像林平之一样,迁怒旁人。典型的特点就是,坐在办公室里整天抱怨,怨天尤人。怨公司为何不给自己这样的待遇、怨机遇为何不降临自己头上、怨社会为何如此不公平、怨同事如此不和自己交心如此一来就会蒙蔽了自己的双眼,本来自己的规划也会因为种种嫉妒心引起的浮躁、不满而终究告吹。结果就是到了最后一无所有,连当初最好的朋友,这笔财富也都失去了。其实我们静下心来想想回头看看,是不是那个晋级的同事真的比咱强呢,我觉得肯定是有的。否则用人单位的领导应该不会傻到看不出来,这个地方请大家不要怀有偏激心理,以一种第三者旁观的身份审视你和你的朋友,看看他比你强在哪里,有时候嫉妒心蒙蔽了这个客观地角色,而很多时候从主观情感出发。相信以第三者的身份审视你们之间的差别,一定能找到你不足的地方。OK,这就达到目的了,这样我们找找平衡,就知道确实他比我高一筹,我应该吸取教训,自己还需努力啊。这样不仅仅是事业上没有什么损失,您的人生也进入了一个“吸星大法”的境界。
还有一点就是比较敏感的薪资问题,经常看到论坛上牛人晒自己的工资。更有39k女,43k男等贴盛行一时。其实套用一句网络上的话“网管上辈子都是折翼的天使,搞软件开发的上辈子都是身怀绝技的乞丐”。积极地一面是觉得很有希望,上面有牛人,看来还是有希望的,到不了人家那种牛级别的,退一步也能做小牛或者小小牛级别的也行啊。消极的一面则是很多人就产生了嫉妒心理,之后种种的谩骂、诋毁、诬陷等等动作一一招呼来了。嫉妒是一堵墙,他蒙蔽了你的良知、你的目标、你的修养。事业高潮时常想着居安思危,低调做人处事,事业低谷时,咱们就以一种平常心处事,但是学习的步伐不能停下,不能因为一时的状态影响了自己本该实现的目标。也许林平之心态平和一点,他的下场会更好一些。林平之的命运掌握在金老先生的笔下,只可惜金庸老先生没有给他这个机会,但是我们呢~我们的命运掌握在我们自己手中。我们的人生是我们自己给自己机会!摒弃我们强烈的嫉妒心,保留一点点可以起到积极的作用,太大了,我们就会失控。最终毁于我们自己创造出来的嫉妒心。
搞软件就像金庸小说中的侠客们闯荡江湖,快意恩仇,你死我活。有人问,职场真的就这么血雨腥风吗?职场就是江湖,用一句广播语说:“什么是江湖?有云的地方就有天下,有人的地方就有江湖。”出世前就好比闯荡江湖之前,对于大学生来说就是四年的大学学习生涯,对于专科生来说就是三年修炼。不过这也不是绝对,有人在高中,甚至是初中就接触了软件开发,不过国内比较少,我们以大多数人的情况说事儿。
我们就用射雕三部曲的主人公作比喻,郭靖好比受过传统高等教育的人士,杨过嘛~因为第一所大学不好,我们把他当做又回家重考的大学生吧,至于张无忌,因为没有明确的师门,我们就当做不屑于参加高考的90后的各位“爷“们。
郭靖为人忠厚,天资不好,学什么东西都比较慢。他的老师们都一度嫌弃他傻,学东西慢,没希望,但是呢,郭靖最大的优点就是有恒心、有毅力。笨不要紧,就怕停下脚步不前进。之后他的启蒙老师马钰就说过其实是老师教学方式有问题,学生学得方法也有问题。后来,马钰以循序渐进的方式对郭靖进行了疏导,郭靖慢慢开窍,后来有了更好的机遇,终成一代大侠。在学生时代能够赶上一个好老师和一个愿意下苦工学的学生都挺不容易的,我们作为学生无论有再好的天资也要下苦工,否则真的是浪费了自己的天资。如果没有一个好的老师进行疏导,没关系,互联网就是我们的老师,当然这需要我们进行取其精华去其糟粕。只要是想学的东西,想办法,下苦工,都是可以学到的。郭靖的例子告诉我们,是金子遇到一个机遇后总会发光的,哪怕刚起步的时候有各种各样的问题,只要找对了方式,再以良好的性格坚持下去,相信结果都会不错。我们搞软件开发也是一样的,遇到某些新技术的时候最好先自己看看怎么学习,切入点在哪里,刚开始研究一下学习一个新技术的方法其实是有效地,比如逼着觉得学习Swing和学习Hibernate的方法就不一样。虽然说都是Java领域的技术,Swing更偏向于UI的显示与事件监听机制的运用。那么笔者认为Swing学习方式就是掌握组件的使用场景和事件触发原理这些核心的即可,等需要构建不同需求的界面时我们按照组建模块的方式构建就可以了。Hibernate则更侧重于持久层对象的状态、持久层接口调用完成CRUD、优化使用缓存等等,所以根据不同业务设计实体配合研究Hibernate的源代码是最好的学习途径。两种技术侧重点不一样,因此不能以同一种方式和经验硬套。
杨过其实是一个天资甚高的家伙,从他后期能够自创武功就能看出来。第一个从师地方他看不上,选择了离开,之后为了争口气,在第二家学艺分外认真。出世前,杨过对武功就很感兴趣,再加上他的聪明、认真、又好学,想不成为高手都难。后来初现武林,也验证了这一点,黄药师就说他的境界比同等境界年轻时的黄药师提前了10年。这也验证了一个道理,长江后浪推前浪,不服老不行。尤其是IT届,新的东西一轮一轮涌过来,而我们的年龄一天天增长,精力一天不如一天,精神集中的能力也有所下降,所以得服老。杨过的经历告诉我们学东西还是要以兴趣为主,没有兴趣,学东西其实是应付别人,自己都不知道自己想要什么,对自己都敷衍了事的人,可能有太大进步吗?还有就是学生时代的我们可以任性,因为有爸爸妈妈老师宠着我们,但是一旦进入社会,还是要有所收敛,否则祸不远矣。人在江湖,什么事情都有可能发生。如果不收敛我们的个性,很难在社会,也就是江湖立足,尤其是软件开发,一山还有一山高在这个领域体现得淋漓尽致,让很多当初自以为高手的人唏嘘不已。没关系,收敛狂傲之心,兼收并蓄。像EJB学习,吸收Spring的优点,自成EJB3.0体系。让众多拥护者不至于失望。
张无忌其实并没有门派,他的父亲也没正经教过张无忌什么武功,只不过挂了一个武当派底子的虚名而已。再加上命运多舛,孩童时期就看淡了生死,这是同龄时期的郭靖、杨过没有经历过的。所以说在出世前,张无忌几乎没有学过什么像样的武功,连自保恐怕都有困难,历经种种磨难后,终于得上天的恩赐,赋予《九阳神功》终成一代“隐侠“。以张无忌作为我们学生时代出世前的例子恐怕不适合。李刚老师曾说过,武侠小说中主人公掉到一个山洞里,遇到世外高人传授武功在现实生活中是不可能的。我要说的是,人生的起点可以很低,但是我们不应该自己贬低自己,自我放弃。你看张无忌中了玄冥神掌,他可有一刻想到要自杀,他总是积极地面对人生,上天给了我什么,我就享受什么。人生的起点不代表人一生总是在这个起点,只能说自己绝不能放弃自己,认为就这样吧。我的人生就这么样得了。人生总会有机遇的,机遇总会出现的,不放弃的人,抓住了机遇,OK,人生的质变就发生了。往往在低谷期不放弃的人,他的路一般都是走得很远。张无忌后来的际遇,也是和他小时候看透人生冷暖、世代炎凉相关的。所以他格外珍惜对他好的人,当然也老受女人的骗(张无忌他妈的话全忘了,估计殷素素九泉之下得说:“这小子,他妈的,把他妈的临终遗言全忘了”)。无论学习何种技术,都是一条长远的路,任重而道远,不应该因为起点很低就一直持着消极的态度。搞软件开发起薪低,告诉自己:“没关系,只要坚持学习,增长经验,慢慢会质变的。”英雄不问出身,学历已经逐渐一年年弱化了。
三位主人公的成功多多少少都和他们出世前的经历相关。这里所谓的出世,实际上就是指我们毕业后刚踏入社会工作。个人认为,从业前的修炼因人而异,有人适合从一而终,找对了一个方向就一直往其更深层发展,直到摸透原理。代表人物就是郭靖,中年郭靖对敌一般都是降龙十八掌了,早年的那些花哨招式都不用了。有些人适合根据原有技术,挖掘优点进行改革创新,代表人物就是杨过的黯然销魂掌了,集各家之大成,配合自己的的心情,随心而发,随意而至。还有些同学喜欢摸着石头过河,公司让我做什么我就学什么,典型人物张无忌。张无忌学九阳神功是命运驱使,不学就得死!学乾坤大挪移是小昭驱使!学太极拳、太极剑也是形势所迫!硬着头皮赶上去。这就是工作需要什么,我就学什么。
笔者对杨过的态度是仰望,能在原有基础上有创新的东西,就像现在很多的开源项目不都是利用已有的资源解决现有问题吗。集大成而创新,说实话在中国的项目中不是一件容易的事。
对郭靖的态度是敬畏,能做到郭靖这种将一个东西用精、用细、用到原理中去的人真的凤毛麟角。
对张无忌的态度则是佩服,形势所迫,压力来了,硬着头皮也得顶上去。锻炼能力的时候到了。
出事前的各种修炼其实是锻炼自己的思维方式和学习习惯,良好的思维方式加上正确的学习习惯,就是出事前最大的财富。
出世前的各位同学们,你们想好你们要做什么样的侠客了吗?
http://avar.iteye.com/blog/163767
在做远程调试时,在windows系统和非windows系统下的配置,Tomcat中会有所差别,具体如下:
第一步、配置tomcat
一、在windows系统中:
打开%CATALINE_HOME%/bin下的文件catalina.bat,加入下面这行:
set CATALINA_OPTS=-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8787
其中address=8787是没被使用的端口号。连接方式有两种,为dt_shmem和dt_socket,分别表示本机调试和远程调试。
二、在非windows系统中:
还需要把% CATALINE_HOME %/bin/startup.sh中的最后一行exec "$PRGDIR"/"$EXECUTABLE" start "$@" 中的start改成jpda start。由于默认的端口是8000,所以如果8000端口已有他用的话,还需在catalina.sh文件中设置:JPDA_ADDRESS=8787。
输入命令sh catalina.sh jpda start就可启动tomcat。
第二步、配置eclipse
在Eclipse中选择RunDebug,在弹出的对话框中右击Remote Java Application新建一个远程调试项,如下如所示:
在“Name”输入框中输入远程调试的名称,在“Project”中选择要调试的项目,在“Host”中输入需要远程调试项目的IP,也就是tomcat所在的IP,在“Port”中输入设置的端口号,比如上面设置的8787,然后钩选“Allow termination of remote VM”,点击“Apply”即可。
设置完后就可以开始调试了,大概分一下几步:
1、启动tomcat(远程),如在控制台输出“Listening for transport dt_socket at address: 8787”,即说明在tomcat中设置成功;
2、在本机设置断点,即在需要监视的代码行前双击就会出现一个小圆点;
3、进入上图界面,选择要调试的项,点击“Debug”即可进行远程调试;
4、当运行到设置了断点的代码行处即可看到如下图所示的浅绿条。
按键操作:
1、F5键与F6键均为单步调试,F5是进入本行代码中执行,F6是执行本行代码,跳到下一行;
2、F7是跳出函数;
3、F8是执行到最后。
当然,为了方便,可以新建一个批处理文件,假如取名为debug.bat,在这个文件中加入下面几行:
cd %CATALINE_HOME%/bin
set JPDA_ADDRESS=8787
set JPDA_TRANSPORT=dt_socket
set CATALINA_OPTS=-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8787
startup
这样需要远程调试时,运行debug.bat即可;不需要远程调试时,还是运行startup.bat文件。
摘要: http://hain.iteye.com/blog/150875web.xml文件中配置<mime-mapping>下载文件类型TOMCAT在默认情况下下载.rar的文件是把文件当作text打开,以至于IE打开RAR文件为乱码,如果遇到这种情况时不必认为是浏览器的问题,大多数浏览器应该不会死皮赖脸地把二进制文件当作文本打开,一般都是服务器给什么浏览器就开什么.解决方法: &...
阅读全文
JAVA EXCEL API 简介
Java Excel 是一开放源码项目,通过它 Java 开发人员可以读取 Excel 文件的内容、创建新的 Excel 文件、更新已经存在的 Excel 文件。使用该 API 非 Windows 操作系统也可以通过纯 Java 应用来处理 Excel 数据表。因为是使用 Java 编写的,所以我们在 Web 应用中可以通过 JSP、Servlet 来调用 API 实现对 Excel 数据表的访问。
现在发布的稳定版本是 V2.0,提供以下功能:
- 从 Excel 95、97、2000 等格式的文件中读取数据;
- 读取 Excel 公式(可以读取 Excel 97 以后的公式);
- 生成 Excel 数据表(格式为 Excel 97);
- 支持字体、数字、日期的格式化;
- 支持单元格的阴影操作,以及颜色操作;
- 修改已经存在的数据表;
现在还不支持以下功能,但不久就会提供了:
- 不能够读取图表信息;
- 可以读,但是不能生成公式,任何类型公式最后的计算值都可以读出;
回页首
应用示例
1 从 Excel 文件读取数据表
Java Excel API 既可以从本地文件系统的一个文件 (.xls),也可以从输入流中读取 Excel 数据表。读取 Excel 数据表的第一步是创建 Workbook( 术语:工作薄 ),下面的代码片段举例说明了应该如何操作:( 完整代码见 ExcelReading.java)
import java.io.*; import jxl.*; … … … … try { // 构建 Workbook 对象 , 只读 Workbook 对象 // 直接从本地文件创建 Workbook // 从输入流创建 Workbook InputStream is = new FileInputStream(sourcefile); jxl.Workbook rwb = Workbook.getWorkbook(is); } catch (Exception e) { e.printStackTrace(); }
|
一旦创建了 Workbook,我们就可以通过它来访问 Excel Sheet( 术语:工作表 )。参考下面的代码片段:
// 获取第一张 Sheet 表 Sheet rs = rwb.getSheet(0);
|
我们既可能通过 Sheet 的名称来访问它,也可以通过下标来访问它。如果通过下标来访问的话,要注意的一点是下标从 0 开始,就像数组一样。
一旦得到了 Sheet,我们就可以通过它来访问 Excel Cell( 术语:单元格 )。参考下面的代码片段:
// 获取第一行,第一列的值 Cell c00 = rs.getCell(0, 0); String strc00 = c00.getContents(); // 获取第一行,第二列的值 Cell c10 = rs.getCell(1, 0); String strc10 = c10.getContents(); // 获取第二行,第二列的值 Cell c11 = rs.getCell(1, 1); String strc11 = c11.getContents(); System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " + c00.getType()); System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " + c10.getType()); System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " + c11.getType());
|
如果仅仅是取得 Cell 的值,我们可以方便地通过 getContents() 方法,它可以将任何类型的 Cell 值都作为一个字符串返回。示例代码中 Cell(0, 0) 是文本型,Cell(1, 0) 是数字型,Cell(1,1) 是日期型,通过 getContents(),三种类型的返回值都是字符型。
如果有需要知道 Cell 内容的确切类型,API 也提供了一系列的方法。参考下面的代码片段:
String strc00 = null; double strc10 = 0.00; Date strc11 = null; Cell c00 = rs.getCell(0, 0); Cell c10 = rs.getCell(1, 0); Cell c11 = rs.getCell(1, 1); if(c00.getType() == CellType.LABEL) { LabelCell labelc00 = (LabelCell)c00; strc00 = labelc00.getString(); } if(c10.getType() == CellType.NUMBER) { NmberCell numc10 = (NumberCell)c10; strc10 = numc10.getValue(); } if(c11.getType() == CellType.DATE) { DateCell datec11 = (DateCell)c11; strc11 = datec11.getDate(); } System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " + c00.getType()); System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " + c10.getType()); System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " + c11.getType());
|
在得到 Cell 对象后,通过 getType() 方法可以获得该单元格的类型,然后与 API 提供的基本类型相匹配,强制转换成相应的类型,最后调用相应的取值方法 getXXX(),就可以得到确定类型的值。API 提供了以下基本类型,与 Excel 的数据格式相对应,如下图所示:

每种类型的具体意义,请参见 Java Excel API Document。
当你完成对 Excel 电子表格数据的处理后,一定要使用 close() 方法来关闭先前创建的对象,以释放读取数据表的过程中所占用的内存空间,在读取大量数据时显得尤为重要。参考如下代码片段:
// 操作完成时,关闭对象,释放占用的内存空间 rwb.close();
|
Java Excel API 提供了许多访问 Excel 数据表的方法,在这里我只简要地介绍几个常用的方法,其它的方法请参考附录中的 Java Excel API Document。
Workbook 类提供的方法
1. int getNumberOfSheets()
获得工作薄(Workbook)中工作表(Sheet)的个数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); int sheets = rwb.getNumberOfSheets();
|
2. Sheet[] getSheets()
返回工作薄(Workbook)中工作表(Sheet)对象数组,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); Sheet[] sheets = rwb.getSheets();
|
3. String getVersion()
返回正在使用的 API 的版本号,好像是没什么太大的作用。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); String apiVersion = rwb.getVersion();
|
Sheet 接口提供的方法
1) String getName()
获取 Sheet 的名称,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); String sheetName = rs.getName();
|
2) int getColumns()
获取 Sheet 表中所包含的总列数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); int rsColumns = rs.getColumns();
|
3) Cell[] getColumn(int column)
获取某一列的所有单元格,返回的是单元格对象数组,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); Cell[] cell = rs.getColumn(0);
|
4) int getRows()
获取 Sheet 表中所包含的总行数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); int rsRows = rs.getRows();
|
5) Cell[] getRow(int row)
获取某一行的所有单元格,返回的是单元格对象数组,示例子:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); Cell[] cell = rs.getRow(0);
|
6) Cell getCell(int column, int row)
获取指定单元格的对象引用,需要注意的是它的两个参数,第一个是列数,第二个是行数,这与通常的行、列组合有些不同。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile)); jxl.Sheet rs = rwb.getSheet(0); Cell cell = rs.getCell(0, 0);
|
2 生成新的 Excel 工作薄
下面的代码主要是向大家介绍如何生成简单的 Excel 工作表,在这里单元格的内容是不带任何修饰的 ( 如:字体,颜色等等 ),所有的内容都作为字符串写入。( 完整代码见 ExcelWriting.java)
与读取 Excel 工作表相似,首先要使用 Workbook 类的工厂方法创建一个可写入的工作薄 (Workbook) 对象,这里要注意的是,只能通过 API 提供的工厂方法来创建 Workbook,而不能使用 WritableWorkbook 的构造函数,因为类 WritableWorkbook 的构造函数为 protected 类型。示例代码片段如下:
import java.io.*; import jxl.*; import jxl.write.*; … … … … try { // 构建 Workbook 对象 , 只读 Workbook 对象 //Method 1:创建可写入的 Excel 工作薄 jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile)); //Method 2:将 WritableWorkbook 直接写入到输出流 /* OutputStream os = new FileOutputStream(targetfile); jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(os); */ } catch (Exception e) { e.printStackTrace(); }
|
API 提供了两种方式来处理可写入的输出流,一种是直接生成本地文件,如果文件名不带全路径的话,缺省的文件会定位在当前目录,如果文件名带有全路径的话,则生成的 Excel 文件则会定位在相应的目录;另外一种是将 Excel 对象直接写入到输出流,例如:用户通过浏览器来访问 Web 服务器,如果 HTTP 头设置正确的话,浏览器自动调用客户端的 Excel 应用程序,来显示动态生成的 Excel 电子表格。
接下来就是要创建工作表,创建工作表的方法与创建工作薄的方法几乎一样,同样是通过工厂模式方法获得相应的对象,该方法需要两个参数,一个是工作表的名称,另一个是工作表在工作薄中的位置,参考下面的代码片段:
// 创建 Excel 工作表 jxl.write.WritableSheet ws = wwb.createSheet("Test Sheet 1", 0);
|
"这锅也支好了,材料也准备齐全了,可以开始下锅了!",现在要做的只是实例化 API 所提供的 Excel 基本数据类型,并将它们添加到工作表中就可以了,参考下面的代码片段:
//1. 添加 Label 对象 jxl.write.Label labelC = new jxl.write.Label(0, 0, "This is a Label cell"); ws.addCell(labelC); // 添加带有字型 Formatting 的对象 jxl.write.WritableFont wf = new jxl.write.WritableFont(WritableFont.TIMES, 18, WritableFont.BOLD, true); jxl.write.WritableCellFormat wcfF = new jxl.write.WritableCellFormat(wf); jxl.write.Label labelCF = new jxl.write.Label(1, 0, "This is a Label Cell", wcfF); ws.addCell(labelCF); // 添加带有字体颜色 Formatting 的对象 jxl.write.WritableFont wfc = new jxl.write.WritableFont(WritableFont.ARIAL, 10, WritableFont.NO_BOLD, false, UnderlineStyle.NO_UNDERLINE, jxl.format.Colour.RED); jxl.write.WritableCellFormat wcfFC = new jxl.write.WritableCellFormat(wfc); jxl.write.Label labelCFC = new jxl.write.Label(1, 0, "This is a Label Cell", wcfFC); ws.addCell(labelCF); //2. 添加 Number 对象 jxl.write.Number labelN = new jxl.write.Number(0, 1, 3.1415926); ws.addCell(labelN); // 添加带有 formatting 的 Number 对象 jxl.write.NumberFormat nf = new jxl.write.NumberFormat("#.##"); jxl.write.WritableCellFormat wcfN = new jxl.write.WritableCellFormat(nf); jxl.write.Number labelNF = new jxl.write.Number(1, 1, 3.1415926, wcfN); ws.addCell(labelNF); //3. 添加 Boolean 对象 jxl.write.Boolean labelB = new jxl.write.Boolean(0, 2, false); ws.addCell(labelB); //4. 添加 DateTime 对象 jxl.write.DateTime labelDT = new jxl.write.DateTime(0, 3, new java.util.Date()); ws.addCell(labelDT); // 添加带有 formatting 的 DateFormat 对象 jxl.write.DateFormat df = new jxl.write.DateFormat("dd MM yyyy hh:mm:ss"); jxl.write.WritableCellFormat wcfDF = new jxl.write.WritableCellFormat(df); jxl.write.DateTime labelDTF = new jxl.write.DateTime(1, 3, new java.util.Date(), wcfDF); ws.addCell(labelDTF);
|
这里有两点大家要引起大家的注意。第一点,在构造单元格时,单元格在工作表中的位置就已经确定了。一旦创建后,单元格的位置是不能够变更的,尽管单元格的内容是可以改变的。第二点,单元格的定位是按照下面这样的规律 (column, row),而且下标都是从 0 开始,例如,A1 被存储在 (0, 0),B1 被存储在 (1, 0)。
最后,不要忘记关闭打开的 Excel 工作薄对象,以释放占用的内存,参见下面的代码片段:
// 写入 Exel 工作表 wwb.write(); // 关闭 Excel 工作薄对象 wwb.close();
|
这可能与读取 Excel 文件的操作有少少不同,在关闭 Excel 对象之前,你必须要先调用 write() 方法,因为先前的操作都是存储在缓存中的,所以要通过该方法将操作的内容保存在文件中。如果你先关闭了 Excel 对象,那么只能得到一张空的工作薄了。
3 拷贝、更新 Excel 工作薄
接下来简要介绍一下如何更新一个已经存在的工作薄,主要是下面二步操作,第一步是构造只读的 Excel 工作薄,第二步是利用已经创建的 Excel 工作薄创建新的可写入的 Excel 工作薄,参考下面的代码片段:( 完整代码见 ExcelModifying.java)
// 创建只读的 Excel 工作薄的对象 jxl.Workbook rw = jxl.Workbook.getWorkbook(new File(sourcefile)); // 创建可写入的 Excel 工作薄对象 jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile), rw); // 读取第一张工作表 jxl.write.WritableSheet ws = wwb.getSheet(0); // 获得第一个单元格对象 jxl.write.WritableCell wc = ws.getWritableCell(0, 0); // 判断单元格的类型 , 做出相应的转化 if(wc.getType() == CellType.LABEL) { Label l = (Label)wc; l.setString("The value has been modified."); } // 写入 Excel 对象 wwb.write(); // 关闭可写入的 Excel 对象 wwb.close(); // 关闭只读的 Excel 对象 rw.close();
|
之所以使用这种方式构建 Excel 对象,完全是因为效率的原因,因为上面的示例才是 API 的主要应用。为了提高性能,在读取工作表时,与数据相关的一些输出信息,所有的格式信息,如:字体、颜色等等,是不被处理的,因为我们的目的是获得行数据的值,既使没有了修饰,也不会对行数据的值产生什么影响。唯一的不利之处就是,在内存中会同时保存两个同样的工作表,这样当工作表体积比较大时,会占用相当大的内存,但现在好像内存的大小并不是什么关键因素了。
一旦获得了可写入的工作表对象,我们就可以对单元格对象进行更新的操作了,在这里我们不必调用 API 提供的 add() 方法,因为单元格已经于工作表当中,所以我们只需要调用相应的 setXXX() 方法,就可以完成更新的操作了。
尽单元格原有的格式化修饰是不能去掉的,我们还是可以将新的单元格修饰加上去,以使单元格的内容以不同的形式表现。
新生成的工作表对象是可写入的,我们除了更新原有的单元格外,还可以添加新的单元格到工作表中,这与示例 2 的操作是完全一样的。
最后,不要忘记调用 write() 方法,将更新的内容写入到文件中,然后关闭工作薄对象,这里有两个工作薄对象要关闭,一个是只读的,另外一个是可写入的。
回页首
小结
本文只是对 Java Excel API 中常用的方法作了介绍,要想更详尽地了解 API,请大家参考 API 文档,或源代码。Java Excel API 是一个开放源码项目,请大家关注它的最新进展,有兴趣的朋友也可以申请加入这个项目,或者是提出宝贵的意见。
使用Junit4.4测试
在类上的配置Annotation
@RunWith(SpringJUnit4ClassRunner.class) 用于配置spring中测试的环境
@ContextConfiguration(Locations="../applicationContext.xml") 用于指定配置文件所在的位置
@Test标注在方法前,表示其是一个测试的方法 无需在其配置文件中额外设置属性.
多个配置文件时{"/applic","/asas"} 可以导入多个配置文件
测试中的事务配置 ,
AbstractTransactionalJUnit38SpringContextTests、 AbstractTransactionalJUnit4SpringContextTests
AbstractTransactionalTestNGSpringContextTests
已经在类级别预先配置了好了事物支持
在普通spring的junit环境中配置事务
在类之前加入注解
@TransactionConfiguration(transactionManagert="txMgr",defaultRollback=false)
@Transactional
在方法中主要使用的Annotation包括
@TestExecutionListeners({})---用于禁用默认的监听器 否着需要通过@contextconfiguration配置一个ApplicationContext;
@BeforeTransaction
@Before
@Rollback(true)
@AfterTransaction
@NotTransactional
Junit4.4下支持类,方便基于junit4.4的测试
AbstractJUnit4SpringContextTests:
AbstractTransactionalJUnit4SpringContextTests:
需要在applicationContext中定义一个datasource
2009年3月9日
目前Spring2.5只支持4.4的Junit进行测试
下面是一个简单的测试Demo
1 package com.gameplus.service.webService;
2
3 import javax.annotation.Resource;
4
5 import org.junit.Test;
6 import org.junit.runner.RunWith;
7 import org.springframework.test.context.ContextConfiguration;
8 import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
9
10 @RunWith(SpringJUnit4ClassRunner.class)
11 @ContextConfiguration(locations={"../../../../applicationContext.xml","../../../../applicationDatasource.xml"})
12 public class UserServiceTest {
13 @Resource
14 private IUserService userService;
15
16 @Test
17 public void testAddOpinion1() {
18 userService.downloadCount(1);
19 System.out.println(1);
20 }
21 @Test
22 public void testAddOpinion2() {
23 userService.downloadCount(2);
24 System.out.println(2);
25 }
26 }
27
注意需要新的Jar包如下
javassist-3.4.GA.jar
hibernate3.jar
hibernate-annotations.jar
尤其注意用新版的,旧版会出现类未找到的异常
版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本声明
http://ralf0131.blogbus.com/logs/55701639.html
参考:http://www.javaeye.com/topic/14631
关于JUnit4: http://www.ibm.com/developerworks/cn/java/j-junit4.html
背景:
如果在Hibernate层采用lazy=true的话,有的时候会抛出LazyInitializationException,这时一种解决办法是用OpenSessionInViewFilter,但是如果通过main方法来运行一些测试程序,那么上述方法就没有用武之地了。这里提供了一种方法,来达到实现和OpenSessionInViewFilter相同作用的目的。这里的应用场景是采用JUnit4来编写测试用例。
JUnit4的好处是:采用annotation来代替反射机制,不必写死方法名.
首先添加一个abstract class(AbstractBaseTestCase.class), 做一些准备性的工作:
(可以看到@Before和@After两个annotation的作用相当于setUp()和tearDown()方法,但是,显然更灵活)
package testcase;
import org.hibernate.FlushMode;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.junit.After;
import org.junit.Before;
import org.springframework.context.support.FileSystemXmlApplicationContext;
import org.springframework.orm.hibernate3.SessionFactoryUtils;
import org.springframework.orm.hibernate3.SessionHolder;
import org.springframework.transaction.support.TransactionSynchronizationManager;
/***
* An abstract base class for TestCases.
* All test cases should extend this class.
*/
public class AbstractBaseTestCase {
private SessionFactory sessionFactory;
private Session session;
protected FileSystemXmlApplicationContext dsContext;
private String []configStr = {"/WebRoot/WEB-INF/applicationContext.xml"};
@Before
public void openSession() throws Exception {
dsContext = new FileSystemXmlApplicationContext(configStr);
sessionFactory = (SessionFactory) dsContext.getBean("sessionFactory");
session = SessionFactoryUtils.getSession(sessionFactory, true);
session.setFlushMode(FlushMode.MANUAL);
TransactionSynchronizationManager.bindResource(sessionFactory, new SessionHolder(session));
}
@After
public void closeSession() throws Exception {
TransactionSynchronizationManager.unbindResource(sessionFactory);
SessionFactoryUtils.releaseSession(session, sessionFactory);
}
}
接下来继承上述基类,实现测试逻辑:
(注意import static用于引用某个类的静态方法)
(@Test注解表明该方法是一个测试方法)
package testcase;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.fail;
import org.junit.Before;
import org.junit.Test;
public class testCase1 extends AbstractBaseTestCase {
private YourManager manager;
@Before
public void prepare(){
manager = (YourManager)dsContext.getBean("YourManager");
}
@Test
public void test1(){
try {
String result = manager.do_sth();
System.out.println(result);
assertEquals(result, EXPECTED_RESULT);
} catch (Exception e) {
e.printStackTrace();
fail("Exception thrown.");
}
}
}
document.getElementById(obj).style.backgroundPosition="10px 0px";
window.onload =function() {
(function(b)
{
var a=document.createElement("script");
a.setAttribute("charset","utf-8");
a.setAttribute("type","text/javascript");
a.setAttribute("src",b);
document.getElementsByTagName("head")[0].appendChild(a)
}
)("1.js");
}
String[] userData = "1######".split("#");
System.out.println(userData.length);
输出:userData.length = 1
- // Construct result
- int resultSize = matchList.size();
- if (limit == 0)
- while (resultSize > 0 && matchList.get(resultSize-1).equals(""))
- resultSize--;
- String[] result = new String[resultSize];
- return matchList.subList(0, resultSize).toArray(result);
split方法是调用Pattern的split实现的,看上面代码中的
while (resultSize > 0 && matchList.get(resultSize-1).equals(""))
resultSize--;
可见。字符串末尾的空字符串将从匹配结果中去除
idCard.js部分*******************************************************
//****************************************************************************
// 构造函数,变量为15位或者18位的身份证号码
function clsIDCard(CardNo) {
this.Valid=false;
this.ID15='';
this.ID18='';
this.Local='';
if(CardNo!=null)this.SetCardNo(CardNo);
}
// 设置身份证号码,15位或者18位
clsIDCard.prototype.SetCardNo = function(CardNo) {
this.ID15='';
this.ID18='';
this.Local='';
CardNo=CardNo.replace(" ","");
var strCardNo;
if(CardNo.length==18) {
pattern= /^\d{17}(\d|x|X)$/;
if (pattern.exec(CardNo)==null)return;
strCardNo=CardNo.toUpperCase();
} else {
pattern= /^\d{15}$/;
if (pattern.exec(CardNo)==null)return;
strCardNo=CardNo.substr(0,6)+'19'+CardNo.substr(6,9)
strCardNo+=this.GetVCode(strCardNo);
}
this.Valid=this.CheckValid(strCardNo);
}
// 校验身份证有效性
clsIDCard.prototype.IsValid = function() {
return this.Valid;
}
// 返回生日字符串,格式如下,1981-10-10
clsIDCard.prototype.GetBirthDate = function() {
var BirthDate='';
if(this.Valid)BirthDate=this.GetBirthYear()+'-'+this.GetBirthMonth()+'-'+this.GetBirthDay();
return BirthDate;
}
// 返回生日中的年,格式如下,1981
clsIDCard.prototype.GetBirthYear = function() {
var BirthYear='';
if(this.Valid)BirthYear=this.ID18.substr(6,4);
return BirthYear;
}
// 返回生日中的月,格式如下,10
clsIDCard.prototype.GetBirthMonth = function() {
var BirthMonth='';
if(this.Valid)BirthMonth=this.ID18.substr(10,2);
if(BirthMonth.charAt(0)=='0')BirthMonth=BirthMonth.charAt(1);
return BirthMonth;
}
// 返回生日中的日,格式如下,10
clsIDCard.prototype.GetBirthDay = function() {
var BirthDay='';
if(this.Valid)BirthDay=this.ID18.substr(12,2);
return BirthDay;
}
// 返回性别,1:男,0:女
clsIDCard.prototype.GetSex = function() {
var Sex='';
if(this.Valid)Sex=this.ID18.charAt(16)%2;
return Sex;
}
// 返回15位身份证号码
clsIDCard.prototype.Get15 = function() {
var ID15='';
if(this.Valid)ID15=this.ID15;
return ID15;
}
// 返回18位身份证号码
clsIDCard.prototype.Get18 = function() {
var ID18='';
if(this.Valid)ID18=this.ID18;
return ID18;
}
// 返回所在省,例如:上海市、浙江省
clsIDCard.prototype.GetLocal = function() {
var Local='';
if(this.Valid)Local=this.Local;
return Local;
}
clsIDCard.prototype.GetVCode = function(CardNo17) {
var Wi = new Array(7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2,1);
var Ai = new Array('1','0','X','9','8','7','6','5','4','3','2');
var cardNoSum = 0;
for (var i=0; i<CardNo17.length; i++)cardNoSum+=CardNo17.charAt(i)*Wi[i];
var seq = cardNoSum%11;
return Ai[seq];
}
clsIDCard.prototype.CheckValid = function(CardNo18) {
if(this.GetVCode(CardNo18.substr(0,17))!=CardNo18.charAt(17))return false;
if(!this.IsDate(CardNo18.substr(6,8)))return false;
var aCity={11:"北京",12:"天津",13:"河北",14:"山西",15:"内蒙古",21:"辽宁",22:"吉林",23:"黑龙江 ",31:"上海",32:"江苏",33:"浙江",34:"安徽",35:"福建",36:"江西",37:"山东",41:"河南",42:"湖北 ",43:"湖南",44:"广东",45:"广西",46:"海南",50:"重庆",51:"四川",52:"贵州",53:"云南",54:"西藏 ",61:"陕西",62:"甘肃",63:"青海",64:"宁夏",65:"新疆",71:"台湾",81:"香港",82:"澳门",91:"国外"};
if(aCity[parseInt(CardNo18.substr(0,2))]==null)return false;
this.ID18=CardNo18;
this.ID15=CardNo18.substr(0,6)+CardNo18.substr(8,9);
this.Local=aCity[parseInt(CardNo18.substr(0,2))];
return true;
}
clsIDCard.prototype.IsDate = function(strDate) {
var r = strDate.match(/^(\d{1,4})(\d{1,2})(\d{1,2})$/);
if(r==null)return false;
var d= new Date(r[1], r[2]-1, r[3]);
return (d.getFullYear()==r[1]&&(d.getMonth()+1)==r[2]&&d.getDate()==r[3]);
}
页面部分**************************************************************
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>身份证验证</title>
<script src="idCard.js"></script>
</head>
<body>
<script>
function valiIdCard(idCard){
var checkFlag = new clsIDCard(idCard);
if (!checkFlag.IsValid()) {
alert("输入的身份证号无效,请输入真实的身份证号!");
document.getElementByIdx("idCard").focus();
return false;
}else{
alert("正确!");
}
}
</script>
<input id="idCard" type="text" onblur="valiIdCard(this.value)"/>
</body>
该骗子诈骗短信内容:“温馨提示,现已从您帐上支出1300元,,工行客服:021—60512737。
第一步:加入log4j-1.2.8.jar到lib下。
第二步:在CLASSPATH下建立log4j.properties。内容如下:
1 log4j.rootCategory=INFO, stdout , R
2
3 log4j.appender.stdout=org.apache.log4j.ConsoleAppender
4 log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
5 log4j.appender.stdout.layout.ConversionPattern=[QC] %p [%t] %C.%M(%L) | %m%n
6
7 log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
8 log4j.appender.R.File=D:\Tomcat 5.5\logs\qc.log
9 log4j.appender.R.layout=org.apache.log4j.PatternLayout
10 log4j.appender.R.layout.ConversionPattern=%d-[TS] %p %t %c - %m%n
11
12 log4j.logger.com.neusoft=DEBUG
13 log4j.logger.com.opensymphony.oscache=ERROR
14 log4j.logger.net.sf.navigator=ERROR
15 log4j.logger.org.apache.commons=ERROR
16 log4j.logger.org.apache.struts=WARN
17 log4j.logger.org.displaytag=ERROR
18 log4j.logger.org.springframework=DEBUG
19 log4j.logger.com.ibatis.db=WARN
20 log4j.logger.org.apache.velocity=FATAL
21
22 log4j.logger.com.canoo.webtest=WARN
23
24 log4j.logger.org.hibernate.ps.PreparedStatementCache=WARN
25 log4j.logger.org.hibernate=DEBUG
26 log4j.logger.org.logicalcobwebs=WARN
第三步:相应的修改其中属性,修改之前就必须知道这些都是干什么的,在第二部分讲解。
第四步:在要输出日志的类中加入相关语句:
定义属性:protected final Log log = LogFactory.getLog(getClass());
在相应的方法中:
if (log.isDebugEnabled())
{
log.debug(“System …..”);
}
二、Log4j说明
1 log4j.rootCategory=INFO, stdout , R
此句为将等级为INFO的日志信息输出到stdout和R这两个目的地,stdout和R的定义在下面的代码,可以任意起名。等级可分为OFF、 FATAL、ERROR、WARN、INFO、DEBUG、ALL,如果配置OFF则不打出任何信息,如果配置为INFO这样只显示INFO, WARN, ERROR的log信息,而DEBUG信息不会被显示,具体讲解可参照第三部分定义配置文件中的logger。
3 log4j.appender.stdout=org.apache.log4j.ConsoleAppender
此句为定义名为stdout的输出端是哪种类型,可以是
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
具体讲解可参照第三部分定义配置文件中的Appender。
4 log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
此句为定义名为stdout的输出端的layout是哪种类型,可以是
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
具体讲解可参照第三部分定义配置文件中的Layout。
5 log4j.appender.stdout.layout.ConversionPattern= [QC] %p [%t] %C.%M(%L) | %m%n
如果使用pattern布局就要指定的打印信息的具体格式ConversionPattern,打印参数如下:
%m 输出代码中指定的消息
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
%r 输出自应用启动到输出该log信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。
[QC]是log信息的开头,可以为任意字符,一般为项目简称。
输出的信息
[TS] DEBUG [main] AbstractBeanFactory.getBean(189) | Returning cached instance of singleton bean 'MyAutoProxy'
具体讲解可参照第三部分定义配置文件中的格式化日志信息。
7 log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
此句与第3行一样。定义名为R的输出端的类型为每天产生一个日志文件。
8 log4j.appender.R.File=D:\Tomcat 5.5\logs\qc.log
此句为定义名为R的输出端的文件名为D:\Tomcat 5.5\logs\qc.log
可以自行修改。
9 log4j.appender.R.layout=org.apache.log4j.PatternLayout
与第4行相同。
10 log4j.appender.R.layout.ConversionPattern=%d-[TS] %p %t %c - %m%n
与第5行相同。
12 log4j.logger.com. neusoft =DEBUG
指定com.neusoft包下的所有类的等级为DEBUG。
可以把com.neusoft改为自己项目所用的包名。
13 log4j.logger.com.opensymphony.oscache=ERROR
14 log4j.logger.net.sf.navigator=ERROR
这两句是把这两个包下出现的错误的等级设为ERROR,如果项目中没有配置EHCache,则不需要这两句。
15 log4j.logger.org.apache.commons=ERROR
16 log4j.logger.org.apache.struts=WARN
这两句是struts的包。
17 log4j.logger.org.displaytag=ERROR
这句是displaytag的包。(QC问题列表页面所用)
18 log4j.logger.org.springframework=DEBUG
此句为Spring的包。
24 log4j.logger.org.hibernate.ps.PreparedStatementCache=WARN
25 log4j.logger.org.hibernate=DEBUG
此两句是hibernate的包。
以上这些包的设置可根据项目的实际情况而自行定制。
三、log4j详解
1、定义配置文件
Log4j支持两种配置文件格式,一种是XML格式的文件,一种是Java特性文件log4j.properties(键=值)。下面将介绍使用log4j.properties文件作为配置文件的方法:
①、配置根Logger
Logger 负责处理日志记录的大部分操作。
其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, …
其中,level 是日志记录的优先级,分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL或者自定义的级别。Log4j建议只使用四个级别,优 先级从高到低分别是ERROR、WARN、INFO、DEBUG。通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关。比如在这里定 义了INFO级别,只有等于及高于这个级别的才进行处理,则应用程序中所有DEBUG级别的日志信息将不被打印出来。ALL:打印所有的日志,OFF:关 闭所有的日志输出。 appenderName就是指定日志信息输出到哪个地方。可同时指定多个输出目的地。
②、配置日志信息输出目的地 Appender
Appender 负责控制日志记录操作的输出。
其语法为:
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.optionN = valueN
这里的appenderName为在①里定义的,可任意起名。
其中,Log4j提供的appender有以下几种:
org.apache.log4j.ConsoleAppender(控制台),
org.apache.log4j.FileAppender(文件),
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件),
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件),可通过 log4j.appender.R.MaxFileSize=100KB设置文件大小,还可通过 log4j.appender.R.MaxBackupIndex=1设置为保存一个备份文件。
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
例如:log4j.appender.stdout=org.apache.log4j.ConsoleAppender
定义一个名为stdout的输出目的地,ConsoleAppender为控制台。
③、配置日志信息的格式(布局)Layout
Layout 负责格式化Appender的输出。
其语法为:
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.optionN = valueN
其中,Log4j提供的layout有以下几种:
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
2、格式化日志信息
Log4J采用类似C语言中的printf函数的打印格式格式化日志信息,打印参数如下:
%m 输出代码中指定的消息
%p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL
%r 输出自应用启动到输出该log信息耗费的毫秒数
%c 输出所属的类目,通常就是所在类的全名
%t 输出产生该日志事件的线程名
%n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
%d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%l 输出日志事件的发生位置,包括类目名、发生的线程,以及在代码中的行数。
3、在代码中使用Log4j
我们在需要输出日志信息的类中做如下的三个工作:
1、导入所有需的commongs-logging类:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
2、在自己的类中定义一个org.apache.commons.logging.Log类的私有静态类成员:
private final Log log = LogFactory.getLog(getClass());
LogFactory.getLog()方法的参数使用的是当前类的class。
3、使用org.apache.commons.logging.Log类的成员方法输出日志信息:
if (log.isDebugEnabled())
{
log.debug("111");
}
if (log.isInfoEnabled())
{
log.info("222");
}
if (log.isWarnEnabled())
{
log.warn("333");
}
if (log.isErrorEnabled())
{
log.error("444");
}
if (log.isFatalEnabled())
{
log.fatal("555")
}
log4j中关闭memcached日志
log4j.logger.com.danga.MemCached.MemCachedClient=ERROR
一、连接池概述
数据库连接池概述:
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个
应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而再不是重新建立一个;释放空闲时
间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些
数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接
数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。数据库连接池的最小连接数和最大连接数的设
置要考虑到下列几个因素:
1) 最小连接数是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费;
2) 最大连接数是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之
后的数据库操作。
3) 如果最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库
连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
目前常用的连接池有:C3P0、DBCP、Proxool
网上的评价是:
C3P0比较耗费资源,效率方面可能要低一点。
DBCP在实践中存在BUG,在某些种情会产生很多空连接不能释放,Hibernate3.0已经放弃了对其的支持。
Proxool的负面评价较少,现在比较推荐它,而且它还提供即时监控连接池状态的功能,便于发现连接泄漏的情况。
配置如下:
1、在spring配置文件中,一般在applicationContext.xml中
<bean id="proxoolDataSource" class="org.logicalcobwebs.proxool.ProxoolDataSource">
<property name="driver" value="${jdbc.connection.driverClassName}"/>
<property name="driverUrl" value="${jdbc.connection.url}"/>
<property name="user" value="${jdbc.connection.username}"/>
<property name="password" value="${jdbc.connection.password}"/>
<!-- 测试的SQL执行语句 -->
<property name="houseKeepingTestSql" value="${proxool.houseKeepingTestSql}"/>
<!-- 最少保持的空闲连接数 (默认2个) -->
<property name="prototypeCount" value="${proxool.prototypeCount}"/>
<!-- proxool自动侦察各个连接状态的时间间隔(毫秒),侦察到空闲的连接就马上回收,超时的销毁 默认30秒) -->
<property name="houseKeepingSleepTime" value="${proxool.hourseKeepingSleepTime}"/>
<!-- 最大活动时间(超过此时间线程将被kill,默认为5分钟) -->
<property name="maximumActiveTime" value="${proxool.maximumActiveTime}"/>
<!-- 连接最长时间(默认为4个小时) -->
<property name="maximumConnectionLifetime" value="${proxool.maximumConnectionLifetime}"/>
<!-- 最小连接数 (默认2个) -->
<property name="minimumConnectionCount" value="${proxool.minimumConnectionCount}"/>
<!-- 最大连接数 (默认5个) -->
<property name="maximumConnectionCount" value="${proxool.maximumConnectionCount}"/>
<!-- -->
<property name="statistics" value="${proxool.statistics}"/>
<!-- 别名 -->
<property name="alias" value="${proxool.alias}"/>
<!-- -->
<property name="simultaneousBuildThrottle" value="${proxool.simultaneous-build-throttle}"/>
</bean>
然后注入到sessionFactory中
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="proxoolDataSource"/>
</bean>
Porxool 配置文件
--==--==--==--==--==<proxool.xml>==--==--==--==--==--==--==
<?xml version="1.0" encoding="UTF-8"?>
<proxool>
<alias>WMS</alias>
<driver-url>jdbc:postgresql://192.168.210.184:5432/wms</driver-url>
<driver-class>org.postgresql.Driver</driver-class>
<driver-properties>
<property name="user" value="wms_user" />
<property name="password" value="wms" />
</driver-properties>
<minimum-connection-count>2</minimum-connection-count>
<maximum-connection-count>40</maximum-connection-count>
<simultaneous-build-throttle>20</simultaneous-build-throttle>
<prototype-count>2</prototype-count>
<house-keeping-test-sql>select CURRENT_DATE</house-keeping-test-sql>
</proxool>
--==--==--==--==--==<proxool.xml>==--==--==--==--==--==--==
配置说明:
alias -〉数据库连接别名(程序中需要使用的名称)
driver-url -〉数据库驱动
driver-class -〉驱动程序类
driver-properties -〉联机数据库的用户和密码
minimum-connection-count -〉最小连接数量,建议设置0以上,保证第一次连接时间
maximum-connection-count -〉最大连接数量,如果超过最大连接数量则会抛出异常。连接数设置过多,服务器CPU和内存性能消耗很
大。
simultaneous-build-throttle -〉同时最大连接数
prototype-count -〉一次产生连接的数量。
例:如果现在prototype-count设置为4个,但是现在已经有2个可以获得的连接,那么
将会试图再创建2个连接。
但不能超过最大连接数。
maximum-active-time -〉连接最大时间活动 默认5分钟
maximum-connection-lifetime -〉连接最大生命时间 默认4小时
/**
*作者:张荣华(ahuaxuan)
*2007-8-15
*转载请注明出处及作者
*/
前两天在看Spring内置的拦截器的时候,发现了一个之前没有注意的类:org.springframework.aop.interceptor.JamonPerformanceMonitorInterceptor,好奇心促使我上网查了一下这个jamon。大概看了一下之后发现这个玩意还真挺好用的而且挺重要的,而且现在国内对它的介绍也很少,所以写了一篇文章和大家分享。
一,Jamon简介:
Jamon的全名是:Java Application Monitor。它是一个小巧的,免费的,高性能的,线程安全的性能监测工具。它可以用来测定系统的性能瓶颈,也可以用来监视用户和应用程序之间的交互情况。 Jamon主要是用来检测jee的应用程序。它最新的版本是2.1,可以用在1.4以上的jdk上。
二,将jamon导入到你的应用程序中去
首先下载jamon的开发包,见我的附件,同时你也可以去Sourceforge上自己下载。Sourceforge的下载地址为http://jamonapi.sourceforge.net。解压之后可以得到一个jar包和一个war包。jar包是自己会用到的,而war包是一个例子(不要小看这个例子,待会也要把它导入到项目中)。把war包之间丢到服务器上,访问:localhost:8080/jamon就可以看到这个例子了,这个例子是一个简单的性能监控系统。
接着把例子中的所有的包都导入到项目中,并把war包中的jsp和images还有css都考到项目中,比如新建一个目录叫monitor(它和WEB-INF是同级目录)。
三,正确配置自己的应用
我们在性能监测的时候最监测的就是页面的访问率和类中方法的访问率。所以在这一部分主要讲解一下如何监测自己的页面和类中方法的访问。
1, 检测自己的页面访问率
首先我们需要在web.xml中添加一个filter,这个filter就是用来判断哪些页面需要被监视的,如下所示:
- <filter>
- <filter-name>JAMonFilter</filter-name>
- <filter-class>com.easywebwork.filter.EasyPageMonFilter</filter-class>
- </filter>
- <filter-mapping>
- <filter-name>JAMonFilter</filter-name>
- <url-pattern>/*</url-pattern>
- </filter-mapping>
<filter>
<filter-name>JAMonFilter</filter-name>
<filter-class>com.easywebwork.filter.EasyPageMonFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>JAMonFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
接下来我们看看这个filter的写法:
-
-
-
-
-
- public class PageMonFilter extends JAMonFilter{
-
- private static final long serialVersionUID = 5746197114960908454L;
-
- public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
- Monitor allPages = MonitorFactory.start(new MonKeyImp("org.easywebwork.allPages",getURI(request),"ms."));
-
- Monitor monitor = MonitorFactory.start(getURI(request));
-
- try {
- filterChain.doFilter(request, response);
- } finally {
- monitor.stop();
- allPages.stop();
- }
- }
-
- protected String getURI(ServletRequest request) {
- if (request instanceof HttpServletRequest) {
- return ((HttpServletRequest) request).getRequestURI();
- } else {
- return "Not an HttpServletRequest";
- }
- }
-
- private FilterConfig filterConfig = null;
-
- }}
/**
* @author 张荣华(ahuaxuan)
*
* @since 2007-8-13
*/
public class PageMonFilter extends JAMonFilter{
private static final long serialVersionUID = 5746197114960908454L;
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
Monitor allPages = MonitorFactory.start(new MonKeyImp("org.easywebwork.allPages",getURI(request),"ms."));
//这里就是我们要监视的所有的页面的配置
Monitor monitor = MonitorFactory.start(getURI(request));
//这里就是我们要监视的某个页面的配置
try {
filterChain.doFilter(request, response);
} finally {
monitor.stop();
allPages.stop();
}
}
protected String getURI(ServletRequest request) {
if (request instanceof HttpServletRequest) {
return ((HttpServletRequest) request).getRequestURI();
} else {
return "Not an HttpServletRequest";
}
}
private FilterConfig filterConfig = null;
}}
这个类看上去很简单,其实也挺简单的,就是得到uri,然后把它注册到MonitorFactory类中。这样只要我们去访问刚才创建的monitor目录下的jsp就可以看到性能监测页面了。
2, ,接下来我们看看在使用spring的情况下如何监测一个bean的方法调用。Spring也提供了对Jamon的支持(spring支持的东西还真多啊),也就是文章开头提出的那个拦截器,为了给我们的bean加上拦截器,我们在spring的applicationcontext配置文件中加入如下语句:
- <bean class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
- <property name="beanNames">
- <list>
- <value>userService</value>
- </list>
- </property>
- <property name="interceptorNames">
- <list>
- <value>jamonInterceptor</value>
- </list>
- </property>
- </bean>
-
- <bean id="jamonInterceptor" class="org.springframework.aop.interceptor.JamonPerformanceMonitorInterceptor">
- </bean>
<bean class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="beanNames">
<list>
<value>userService</value>
</list>
</property>
<property name="interceptorNames">
<list>
<value>jamonInterceptor</value>
</list>
</property>
</bean>
<bean id="jamonInterceptor" class="org.springframework.aop.interceptor.JamonPerformanceMonitorInterceptor">
</bean>
上面这个是典型的spring的aop的配置,如果对spring的aop配置不了解的可以去看一下spring中文文档,当然如果不想了解的话即使直接把这段配置拷到自己的项目中也是可以直接使用的。
还有一个步骤就是在你的log4j.properties中加入这句代码:
- log4j.logger.org.springframework.aop.interceptor.JamonPerformanceMonitorInterceptor = TRACE
log4j.logger.org.springframework.aop.interceptor.JamonPerformanceMonitorInterceptor = TRACE
如果没有这一行,那么这个拦截器是不会把方法调用的信息向MonitorFactory注册的。
只需要这些步骤,userservice中的方法在调用的时候就可以被拦截,然后将其注册到MonitorFactory中去了。
所有的配置完成之后我们来看一下效果吧:
http://www.javaeye.com/topics/download/b2bac96e-6c18-4340-b7e0-f84c7bb6adca从这个图上我们可以看到,所有页面被访问的次数,UserService中的getAllUsers被调用的次数,最右边的是访问时间。这只是整个图的一部分,当然这个页面中也包括每一个页面被访问的次数和第一次访问的时间等等。下载附件运行,就可以看到所有的页面了。
三,总结
根据以上的步骤,我们就可以监测我们的程序了,应用程序中哪些页面被访问的多,哪些页面被访问的少,哪些方法被访问的多,哪些方法被访问的少,以及访问高峰期集中在什么时间等等,有了这些参数,我们更可以有针对性的对应用程序进行优化了,比如说某个页面访问比较频繁,我就可以用ehcache或oscache给这个页面做一个缓存。如果某个方法的访问比较频繁那就看看这个方法能否进一步优化,是需要异步,还是需要缓存,还是需要其他等等,总之有了jamon可以给我们带来更多的便捷,既可以让我们知道我们的客户的行为,也可以让我们知道我们开发的程序的“能力”。
其实本文提供的只是对页面和方法调用的监控,但是jamon可以提供更多功能,比如说sql语句的监控等等,这就需要我们共同去发掘了。
附件中包括了一个easywebwork的例子,我把jamon导入到这个例子工程中去,大家可以直接下载运行观看效果。Easywebwork是一个旨在减少webwork2.2.x系列的xml配置文件的项目,
如果对这个主题感兴趣请到
http://www.javaeye.com/topic/91614
http://www.javaeye.com/topic/93814
参加讨论。
之前有一篇文章讲到如何使用jamon来监控请求以及方法得调用(原文地址见:[url]http://www.javaeye.com/post/354575 [/url]),本文属于其姊妹篇,使用jamon监控系统的sql调用及其调用效率。
需求:
1我们知道在使用hibernate得时候,我们可以打开show sql选项,可以直接查看sql语句调用的情况,那么当我们使用其他持久技术的时候我们也需要这个功能怎么办呢,没有关系,jamon能够帮我们做到。
2 很多时候,不同的程序员会写出不同的性能的sql,有时候可能会不小心或者因为不知道而写出性能很差的sql,我自己曾经就发生过这种事情,在500w条数据的表里使用了一个limit来分页,到后面,执行一条sql都需要几分钟,诸如此类的时候可能大家都有碰到过,如果能有监控sql性能的工具嵌在应用里该多好,当然有jamon就可以帮我们做到。
对于jamon来说,每一个query的执行之后的统计结果都会被保存下来,这些概要统计都以MonProxy-SQL开头。这些统计中包括查询执行的时间,有比如平均时间,执行总时间,最小执行时间,最大执行时间,这些东西难道不是我们正想要的吗。
那么让我们开始吧,我们知道,这些query执行的统计应该是在connection中被统计的,也就是说我们要代理一般的connection,而connection又是由datasource产生的,所以我们可以代理datasource,说干就干。
一个datasource接口中关于connection的方法只有两个:
-
-
-
-
-
-
-
- Connection getConnection() throws SQLException;
-
-
-
-
-
-
-
-
-
-
-
-
- Connection getConnection(String username, String password)
- throws SQLException;
/**
* <p>Attempts to establish a connection with the data source that
* this <code>DataSource</code> object represents.
*
* @return a connection to the data source
* @exception SQLException if a database access error occurs
*/
Connection getConnection() throws SQLException;
/**
* <p>Attempts to establish a connection with the data source that
* this <code>DataSource</code> object represents.
*
* @param username the database user on whose behalf the connection is
* being made
* @param password the user's password
* @return a connection to the data source
* @exception SQLException if a database access error occurs
* @since 1.4
*/
Connection getConnection(String username, String password)
throws SQLException;
也就是说我们只要override这两个方法即可。
根据这个思路我写了以下代码:
-
-
-
-
-
- public class MonitorDataSource implements DataSource {
- public DataSource realDataSource;
-
- public void setRealDataSource(DataSource realDataSource) {
- this.realDataSource = realDataSource;
- }
-
- public DataSource getRealDataSource() {
- return realDataSource;
- }
- public Connection getConnection() throws SQLException {
-
- return MonProxyFactory.monitor(realDataSource.getConnection());
- }
-
- public Connection getConnection(String username, String password)
- throws SQLException {
-
-
- return MonProxyFactory.monitor(realDataSource.getConnection(username,
- password));
- }
- }
/**
* @author ahuaxuan(aaron zhang)
* @since 2008-2-25
* @version $Id$
*/
public class MonitorDataSource implements DataSource {
public DataSource realDataSource;
public void setRealDataSource(DataSource realDataSource) {
this.realDataSource = realDataSource;
}
public DataSource getRealDataSource() {
return realDataSource;
}
public Connection getConnection() throws SQLException {
//表示由jamon来代理realDataSource返回的Connection
return MonProxyFactory.monitor(realDataSource.getConnection());
}
public Connection getConnection(String username, String password)
throws SQLException {
//表示由jamon来代理realDataSource返回的Connection
return MonProxyFactory.monitor(realDataSource.getConnection(username,
password));
}
}
显然这个一个代理模式。接下来就是生成这个代理类,我是在spring中注册了这么一个类:
- <bean id="writeMonitorDataSource" class="org.ahuaxuan.MonitorDataSource" destroy-method="close">
- <property name="realDataSource" ref="writeDataSource"/>
- </bean>
<bean id="writeMonitorDataSource" class="org.ahuaxuan.MonitorDataSource" destroy-method="close">
<property name="realDataSource" ref="writeDataSource"/>
</bean>
writeMonitorDataSource 所依赖的writeDataSource就是我们真正配置的datasource,比如:
- <bean id="writeDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
- <property name="driverClassName">
- <value>${jdbc.driverClassName}</value>
- </property>
- <property name="url">
- <value>${jdbc.url}</value>
- </property>
- <property name="username">
- <value>${jdbc.username}</value>
- </property>
- <property name="password">
- <value>${jdbc.password}</value>
- </property>
- <property name="maxActive">
- <value>${jdbc.maxActive}</value>
- </property>
- <property name="maxIdle">
- <value>${jdbc.maxIdle}</value>
- </property>
- <property name="maxWait">
- <value>${jdbc.maxWait}</value>
- </property>
- </bean>
<bean id="writeDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName">
<value>${jdbc.driverClassName}</value>
</property>
<property name="url">
<value>${jdbc.url}</value>
</property>
<property name="username">
<value>${jdbc.username}</value>
</property>
<property name="password">
<value>${jdbc.password}</value>
</property>
<property name="maxActive">
<value>${jdbc.maxActive}</value>
</property>
<property name="maxIdle">
<value>${jdbc.maxIdle}</value>
</property>
<property name="maxWait">
<value>${jdbc.maxWait}</value>
</property>
</bean>
好了,那么在使用datasource的时候,我们应该用哪个呢,当然是writeMonitorDataSource这个里,我们可以把它注入给jdbcTemplate,或者sessionfactory,或者其他需要用到datasource的地方。
到这里,就一切准备完毕了,我们可以看看我们sql语句的执行效率了(这个页面的地址为sql.jsp):
见图1
当然要我们的应用能够显示这个页面,我们需要把jamon的一组页面拷到我们的应用中,这一组页面包含在我提供下载的包中,最新的jamon版本是2.7。
我们可以看到id为153的那条sql语句执行了78ms,我要去看看这条sql语句是不是有点什么问题或者是否有优化的可能性。
当然,刚才说到每一条sql语句都是有统计平均时间,最大最小执行时间等等,没错,在另外一个页面jamonadmin.jsp上就包含这些内容
见图2
上面的图片代表hits表示执行次数,avg表示sql执行的平均时间,后面的min和max表示sql执行的最小耗时和最大耗时。从这里我们能够更直观的看到我们每条sql语句执行的情况。很有用的一个功能。
而且在上面那两个页面上,我们还可以选择把sql执行的结果导出来,可以导成xml或excel格式。
总结:使用jamon来监控我们的sql语句我觉得很有使用意义,而且使用jamon对我们的应用来说完全是松耦合的,根本不需要更改我们的业务逻辑代码,完全是可插拔的,我们也可以开发时使用jamon,部署时拔掉jamon。有了它能够使一些程序员能够更多一点的关注自己所写的sql的效率,当然如果之前开发的时候没有使用jamon也没有关系,即使上线后也可以查看一下sql语句是否有问题,比如哪些sql语句执行得比较频繁,是否存在给其做缓存得可能性等等。总之使用jamon在应用程序中来监控我们得sql语句具有很强得实用意义,
再次总结:jamon,很好,很强大。
我在解析XML文件中出现如下错误:
org.xml.sax.SAXParseException: The reference to entity "Stars" must end with the ';' delimiter.
经查实发现,xml文件里有&的字眼
把其中的"&"转义字符& 代替,就OK了
var check=function(e){
e=e||window.event;
if((e.which||e.keyCode)==116 || (e.ctrlKey && (e.which||e.keyCode)==82)){
if(e.preventDefault){
e.preventDefault();
}
else{
event.keyCode = 0;
e.returnValue=false;
}
}
}
if(document.addEventListener){
document.addEventListener("keydown",check,false);
}
else{
document.attachEvent("onkeydown",check);
}
function inti(){
var temp="6668913&dflkewiofsdlfhewjl";
var ByteCount =0;
for (i=0;i<temp.length;i++){
ByteCount = temp.charCodeAt(i);
if(ByteCount.length==1){
ByteCount ="0"+ByteCount
}
ByteCount = ByteCount.toString(16).toUpperCase();
document.getElementById('result').innerHTML +=ByteCount ;
}
}
1. Java语言基础
谈到Java语言基础学习的书籍,大家肯定会推荐Bruce Eckel的《Thinking in Java》。它是一本写的相当深刻的技术书籍,Java语言基础部分基本没有其它任何一本书可以超越它。该书的作者Bruce Eckel在网络上被称为天才的投机者,作者的《Thinking in C++》在1995年曾获SoftwareDevelopment Jolt Award最佳书籍大奖,《Thinking in Java》被评为1999年Java World“最爱读者欢迎图书”,并且赢得了编辑首选图书奖。作者从1986年至今,已经发表了超过150篇计算机技术文章,出版了6本书(其中4本是关 于C++的),并且在全世界做了数百次演讲。他是《Thinking in Java》、《Thinking in C++》、《C++ Inside & Out》《Using C++》和《Thinking in Patterns》的作者,同时还是《Black Belt C++》文集的编辑。他的书被读者称为“最好的Java参考书……绝对让人震惊”;“购买Java参考书最明智的选择”;“我见过的最棒的编程指南”。作 者的非凡才华,极其跨越语言的能力,使作者被选为Java发展10年间与Java关系最密切的10个人物之一。
《Thinking in Java》讲述了Java语言的方方面面,很多Java语言的老手都评价“这是一本将Java语言讲得相当丑陋的书”。该书谈及了java语言的很多细节,每一个方面都是相当深刻的。通过本书你可以看到“丑陋的”java语言。
网络上关于java语言讲解的视频很多很多,其中不凡有垃圾。《翁恺—JAVA语言》可能是你学习java语言基础的唯一选择,该讲座基本按照 《Thinking in Java》这本书讲解,其中不凡有翁老师的很多有意思的笑话。我很幸运学习就是从此视频开始的。内容包括30讲,我总共看了3遍。
不过,对于初学者我不太推荐使用《Thinking in Java》,我比较推荐Prentice Hall PTR 的《Core Java 2》国内称为《Java 2 核心技术》,目前是第七版。网络上大家都可以下载到电子版。Oreilly的《Java in a nutshell》也是一个不错的选择。读完以上两本后,你可以看看翁恺老师的视频,接着可以研究《Thinking in Java》了。
2. Java数据结构
市面上关于Java数据结构的书本身就很少很少。大致有APress 的《Java Collections》,Jones 和Bartlett 的《Data Structures in Java》、《Object-oriented Data Structures Using Java》以及Prentice Hall 出版的《Data Structures and Algorithms in Java》 (Dec 19, 2005)还有一本就是《Data Structures And Algorithms With Object-oriented Design Patterns In Java》。很幸运我的第一本英文书就是APress 的《Java Collections》(本书在国内可能根本就没有中文版――只能下载英文版了),很不错,讲得很有条例、很简单,是一本完完全全Java Collections API介绍的书籍,其中不凡有扩展API的例子。这是我推荐你学习java数据结构的唯一一本好书。其它的Jones 和Bartlett的那两本国内好像有一本中文版,想看你也可以看看。
在学习完API后,你可以看看java.util包中对应的类了。不过只有在学习过设计模式后你才有可能完全理解整个Java Collections Framework。Java Collections Framework使用了很多著名的设计模式如:迭代器(Iterator)模式,工厂方法模式、装饰器模式、适配器模式等等。通过研究 java.util包中数据结构的源代码,你可以知道臭名昭著的Properties类的设计了,同时可能基本具备设计简单的数据结构的能力了。
所谓学习无止境,学习完Sun提供了Java Collections Framework后,你可以研究Apche的另一个Java Collections Framework,很有意思哦。互为补充的两个Framework。
在大家学习、研究Java Collections之前,我提示一下Java Collections主要包括以下三部分:接口(Interface)、实现(Implemention)和算法(Algorithm)。
1. 接口主要有List、Set、Queue和 Map。List 、Se t和Queue是 Collection接口的子接口。
2. 实现主要是实现这些接口的具体类。如实现List接口的ArrayList、LinkedList、Stack和Vector;实现Set接口的 HashSet、TreeSet 和LinkedHashSet;实现Queue接口的PriorityQueue、SynchronousQueue等等;实现Map接口的 HashMap、TreeMap、Hashtable、Properties、WeakHashMap等等。
3. 算法主要是由Arrays类和Collections类提供的,它是整个Java Collection Framework算法的核心。支持各种类型的排序,查找等常用操作。
Java Collections中包含两个版本的数据结构,主要是原先的支持同步的数据结构和后来不支持同步的数据结构。
Java Collection Framework在使用Comparator和Comparable接口支持排序。同时提供新旧两个版本的迭代器Iterator和Enumeraton,以及它们如何转换等等。
在java.util包中的Obserable接口和Observer类是考察者模式的核心。
……
3. Java IO
市面上关于IO的书籍也仅仅只有Oreilly出版社的两本,都是Elliotte Rusty Harold的著作。两本书的风格基本一致,推荐阅读是第一版的《Jvava I/O》,讲得比较浅显,内容相对比较集中,实例也很多。第二版今年5月国外才出版,很有幸我在网络上下载了第二版,讲得极其详细――726页的大块头(我化了两个星期),这次将NIO和IO和在一起,还包括J2ME部分的,不过串口、并口通信部分好像类库支持不够,自己不能实际操作。
与第一版的《Jvava I/O》一起的Oreilly还有一本《Jvava NIO》,也是很不错的哦。
大家在依次阅读完《Jvava I/O》以及《Jvava NIO》后,可以研究java.io包中的源代码了。在大家研究源代码前我给点提示:
Java的io包主要包括:
1. 两种流:字节流(byte Stream)和字符流(character stream),这两种流不存在所谓的谁代替谁、谁比谁高级之说,它们互为补充,只是侧重点不同而已。
2. 两种对称:1.字节流、字符流的对称;2.输入、输出的对称。
3. 一个桥梁:将字节流转变为字符流的InputStreamReader和OutputStreamWriter。
其中必须注意:
1. PipedInputStream和PipedOutputStrem是两个比较有趣的类。
2. 支持Buffered的流是我们经常使用的类。
3. 装饰器(Decorator)模式在java最著名的应用就是用于io的设计。仔细研究各个Filter流与具体流的关系,多看设计模式的书籍。相信你会有所所获。
4. 学习好io包,是研究net包,rmi包……的基础哦!
4 . Java数据库
数据库的书籍太多太多了,也是太烂太烂了!这方面的书我基本都研究过,推荐的你就看看Apress的《JDBC Recipes A Problem Solution Approach 》很不错,国外2005年底才出版,(国内好像没有中文版,不过出了中文版也不一定值得看――国内经常将国外的书翻译得一塌糊涂、不堪入目)不过我们真的很幸运,网络上有电子版的。值得一看。推荐我看的第一本比较满意的――Wiley出版的《Java Database Bible》,讲得很不错!Sun公司自己的关于JDBC API介绍的那一本《JDBC API Tutorial andRefernece》也不错。我第二本JDBC的就是研究的这套API。
不过目前这些书都是一些相对比较浮浅的API应用的书籍。有机会我会给大家带来介绍JDBC API以及JDBC实现内部细节的书!我尽快努力,同时希望得到大家的支持!
顺便给学习JDBC的朋友一点提示:
JDBC的学习和使用主要是这套API,其使用过程也是极其简单,下面是使用JDBC的一般流程:
1. 加载某个数据库的驱动(Driver类),通常使用Class.forName(“驱动的类名“);
2. 连接数据库――
Connection con = DriverManager.getConnection(url,username,password);
3. 得到会话――Statement stmt = con.createStatement();
4. 执行操作――Result rs = stmt.executeQuery(“SQL查询语句”);
5. 处理结果――
while(rs.next()){
String col1 = rs.getString(1);
……
}
简单吧!整个JDBC中可以变化的一般是:
1. 可以由Connection对象创建Statement、PreparedStatement和CallableStatement创建三种类型的Statement。
2. 可以创建多种类型的ResultSet:支持单向移动和个自由移动;可更新的和不可更新的;支持不同等级的交易的…..
3. 数据输入的批处理。
4. 结果集中特殊类型(Blob、Clob、Arrary和Ref、Struct)列的操作。
5. 这些特殊类型的录入数据库。
6. javax.sql包中特殊结果集(CachedRowSet、JdbcRowSet、WebRowSet)的操作。
7. 其它的就是一个DataSource了,也很简单!一个J2EE中的被管理对象
简单吧!相信大家很快就会征服JDBC。
5. Java 网络编程
网络编程――一个神秘的、充满挑战的方向。不过在谈Java网络编程之前首先感谢Sun公司的开发人员,因为它们天才的设想,充满智慧的架构,使广大java程序员学习java网络编程变得异常简单。
Java网络编程方面的书,我推荐O'Reilly的《Java Network Programming》,目前已经第三版了,以前的版本市面上肯定有!网络上早有第三版的电子版,国外2004年出版,706页哦!讲得很全,比较深入,太深入的可能由于Sun有些东西没有完全公开,所以也就不好讲了,有兴趣的可以下载看看!第二本还是O'Reilly 1998年出版的《Java distributed computing 》,基础部分写得比较详细,后面的实例还是值得研究的。
在大家阅读这些书之前,给大家一点提示:
java网络编程其实相对比较简单,入门也很快很快。java网络编程主要包括两个部分:1.Socket;2.URL部分。不过第二部分也完全建立在第一部分的基础上。
1. Socket包括客户端的Socket和服务器端的ServerSocket。还有就是DatagramSocket和DatagramPacket,它对应于UDP通信协议。 总之,Socket部分是建立其它高级协议的基础。
2. URL类是一个网络资源定位器,通常和具体的网络协议如HTTP,FTP,Telnet……相关。通过该类可以连接网络上的资源,通过其 openStream可以以io包中的流(InputStream)的形式读取网络资源;通过其OpenConnection方法,可以打开一个连接,在此连接上可以不仅可以完成读的操作,还可以完成写的操作。
Java的网络编程大体包括以上两部分。网络编程和IO以及多线程部分非常密切,在学习此部分前大家一定对这两部分了解比较透彻。
学习了以上部分你可以研究java.net 包中的与此相关的源代码了!研究所有的源代码还为时尚早。在整个net包中包含: ContentHandlerFactory、URLStreamHandlerFactory、URLStreamHandler、 URLClassLoader等辅助类,它们构成了java.net网络编程的框架,通过研究其源代码,你不仅可以快速理解java.net包,还可以为 以后扩展该包打下基础,甚至可以将此思维方式运用到自己的项目中。
到此为止你对java.net 包应该才了解60%,还有一部分你可以使用JDecompiler之类的反编译软件打开你JDK安装目录下\jdkxxx\ jre\lib目录中的rt.jar,用WinRAR之类的软件打开它的sun.net包,反编译所有的文件,它是URL类工作的细节。当研究完该 sun.net包,你就会对整个网络编程很熟悉很熟悉了。
一切看起来我们已经对网络编程很精通了。其实不然,刚刚开始而已,要想深入,请继续吧!网络上很多优秀的网络编程库甚至软件可以为我们“添加功力”。如 Apache的HttpCore和HTTPConnection 是两个和HTTP协议相关库;JGroups是研究分布式通信、群组通信的必读库;接着我们可以研究P2P的软件包,如Sun公司的JXTA,它可能是 java平台点对点通信未来的标准哦!接着你可以研究成熟得不得了,使用极其广泛得P2P软件Azureus!www.sourceforge.net可以下载到!
千里之行始于足下!Just do it !(目前我也只研究了net包,其它的会在不久的将来继续深入。Sun公司因为某些原因没有公开net的其它实现细节,在其允许将其源代码以文字的形式加 以研究,以及允许将其没有公开的实现写入书中时,我很希望能出一本java网络编程的书籍,以飧广大读者!!)
6. Servlet和JSP
Servlet、JSP的书也是满地都是!值得推荐的也仅仅两三本。实推Addison Wiley的《Servlets and JavaServer pages :The J2EE Technology Web Tier》,又是一本很厚的哦!国外2003年出版、784页,讲得比较全,例子也很多,特别是第八章Filter,举了几个不错的例子。其它所有我看到的关于Servlet和JSP的书都没有如此深入的!(可能有我没有看到而已)。O’reilly的《Java Servlet Programming》和《Java Server Pages》相对比较好懂一些,可以读读!
在大家学习Servlet和Jsp之前我还是要提醒一下:
本质上说Servlet就是一个实现Servlet接口的、部署于服务器端的服务器端的程序罢了!它可以象写其它任何java应用程序一样编写,它可以操作数据库、可以操作本地文件、可以连接本地EJB……编写Servlet程序的一般流程为:
1. 继承一个HttpServlet类;
2. 覆盖其doGet、doPost方法;
3. 在覆盖方法的内部操作方法参数HttpServletRequest和HttpServletResponse。
4. 读取请求利用HttpServletRequest。利用HttpServletRequest你可以操作Http协议的协议头、可以得到请求的操作方法、可以得到请求的路径、可以得到请求的字符串、以及和请求客户相关的信息,更主要的你可以得到Cookie和HttpSession这两个对象。
5. 利用Cookie你可以操作“甜心”对象或者将其写入HttpServletResponse中。
6. 向客户输出信息可以使用HttpServletResponse。使用HttpServletResponse可以写入各种类型的协议头、可以增加Cookie、可以重定向其它URL、可以向客户发送Http协议的状态码。
7. 利用HttpSession在会话内完成你想实现的任何功能。
同时Servlet还提供了一些事件和事件监听器(简单的观察者模式而已)。还有就是过滤器(Filter)和包装器(ServletRequestWrapper、ServletResponseWrapper)――简单的流的使用和装饰器模式的使用。
学习Sevlet、JSP必然要部署到服务器中,记住通常文件部署的步骤和参数的设置以及在程序中如何使用就可以了。
完全理解Servlet后,学习jsp相对比较容易了!Jsp完全建立在Servlet的基础上,它是为了迎合那些喜欢在Html文档中嵌入脚本(如:PHP之类的网页编程语言)的程序员的需要罢了!学起来也相当的容易!
一切看起来似乎那么的风平浪静,简单好学!简单的表象背后有其复杂的机理。要想对Servlet和Jsp彻底研究,你得研究Tomcat等开源软件的具体实现。它无非就是一个服务器,在客户利用网页通过HTTP协议向服务器发送请求后,服务器将此HTTP请求转化为相应的 HttpServletRequest对象,调用你编写的Servlet罢了,在你的Servlet中你肯定操作了此 HttpServletRequest了吧,同时操作了HttpServletResponse了吧,服务器就将此 HttpServletResponse按照HTTP协议的要求利用HTTP协议发送给你的浏览器了!在服务器端的Jsp网页在被客户请求后, Tomcat会利用编译软件,使用javax.servlet.jsp包中的模板,编译此jsp文件,编译后就是一个Servlet!以后的操作和 Servlet完全一样哦!
在Servlet和Jsp的基础上出现了,所谓的高级技术:JSTL,Struts……无非就是一些标签和MVC模式的使用。
继续前进吧!胜利就在前方!!
7. 多线程
一个看起来很神秘,却很容易上手、很难精通的方向!
我推荐两本我感觉很好的书籍。首先是我第一本能上手看的这方面的书,Sams 1998年出版的《Java Thread Programming》,写得暴好,很容易读懂,我有空还时常看当时的笔记!要知道怎么好你自己看吧!第二本OReilly三次出版的《Java Threads》,最新是2004版,国内好像有中文版,推荐你还是看英文版的吧!书中谈到了与多线程相关的N个方向,如IO、Swing、 Collection等等。
给大家一点提示吧!java类库中与多线程相关的类不是很多,主要有:Thread、ThreadGroup以及ThreadLocal和 InheritableThreadLocal四个类和一个Runnable接口;关键字synchronize、volatile ;以及Object对象的wait、notify、notifyAll方法!
1 Thread是多线程的核心类,提供了一系列创建和操作多线程的方法。
2 ThreadGroup是一个管理Thread的工具类。
3 ThreadLocal和InheritableThreadLocal为Thread提供了一个类似保险箱功能的存储线程对象的类!
4 Runnable不用说了吧!
5 synchronize是同步方法和同步块的核心哦!多个线程调用此方法时,只有一个线程可以使用此方法,其它方法阻塞,从而保证被操作对象内部状态完整性。某个线程调用带有synchronize的方法或块时会得到该对象的对象锁,完成块中的操作后释放此对象锁,从而其它对象可以继续操作。
6 wait、notify、notifyAll提供了有效的等待/通知机制。Java语言中每一个对象都有一个休息室,任何线程在其操作的对象的状态不满足 的情况下,在该对象的休息室中休息,释放对象锁;当其它线程操作该对象后,唤醒休息室中的线程,它们再检查条件,当条件满足后,执行相应的操作。
多线程大致就这么多基础的!简单吗!这对于一个真正的程序员应该是不够的,真正对多线程要有所掌握,请您研究java.util.concurrent包 吧!大师Doug Lea的作品,原先是一个开源的一致性编程的库,后来被Sun公司并入java类库。作者的网站上也有另外一个版本的该类库!值得研究的好东西! Hibernation、OpenJMS等开源软件都使用了此包!
8. 设计模式
谈到设计模式很多人多会推荐GOF的那本,该书在Amzon上是五星级的推荐书籍。不过对于学习java没多久的、特别是java初学者,我很不推荐这本书。主要是该书的例子基本都是C++的,很多细节没有讲述得足够清楚。
我给大家推荐的第一本是阎宏博士的《Java 与模式》,它是第一本中国人自己写的关于设计模式的书籍,写的比较有趣,融合了很多中华民族的文化和观念,例子、类图都比较多,且相对简单!非常不错的入门书籍――又是大块头哦!
其次我推荐Wiley出版社出版的《Pattern In Java》一套三本,我才看了第一本,好像第二本不怎么样,第三本还不错!
第三本是中文翻译版的关于多线程模式的(很难得的中文翻译版)中国铁道出版社2003年出版的《Java多线程设计模式》,将多线程模式讲得非常浅显,配有大量的图例,每章都有习题,最后有答案!我研究多线程模式就是由它开始的!
第四本,今年出版的Head First系列的《Head First Design Pattern》,秉承Head First系列图书的优点,大量的类图、丰富的实例、有趣的注解,值得购买!
其次在J2EE方向你可以研究阅读Addison Wesley 2002年出版的《Patterns of Enterprise Application Architecture》,众多大腕的作品,讲企业消息集成的!Sun提供的《J2EE PATTERNS SL500》也很好!晚了推荐那一本Amzon 4星半的《Holub on patterns》,大师的作品,提供了,很值得研究的例子,不过对上面四本不是很熟悉的读者,最好不要读它!可能会让你比较累!
我学习设计模式经过一段很曲折的路线,前前后后大约看了20本,阎宏博士的《Java 与模式》我看了4遍,还排除我第一次基本没看懂的看!记得研一时老师给我们讲了GOF的那本,作为选修课,我和它们计算机系的硕士、博士们一起,到最后一个班40-50个人,不超过3个人明白,我也没有明白任何一点(基础差吧――主要我对C++语言一点都不了解),凭我不伏输的性格,我认为我对java语 言理解还可以,我就借了《Java 与模式》,结果还是基本没看懂。很有幸的是读研三时,听过了上交大饶若楠老师关于Java OOP语言的讲座,我懂了组合书籍模式等三种设计模式后,对其它模式有了强烈的兴趣和要征服它的愿望!工作后我买的第一本就是《Java 与模式》,第一遍花了2个月研究了这个1000多页的大块头,后来第三遍15天左右就可以搞定,笔记记了一大本!从此一发不可收拾。
选对书、埋头研究。相信很快就会入门的!
学习Java语言8个简单的部分,这只是我们研究Java语言的开始!这些都懂了充其量一个java程序员而已,后面的路很长很长!我们可以继续研究数据库实现的源代码、Servlet服务器的源代码、RMI、EJB、JNDI、面向方面编程、重构、ANT工具、Eclipse工具、Spring工具、 JBoss、JOnAS、Apache Geronimo等J2EE服务器!研究了这些你可能会成为一个出色的J2EE Architecture!你可以继续研究剖析器、编译器、JNODE(java写的操作系统)……
感谢大家有此耐心,听我罗罗嗦嗦大半天!感谢大家的阅读,感谢群里的朋友!这篇文章主要应群里朋友的呼声――不知道如何选书、不知道从何看起!大半天的功夫完成赶此文章,字句上难免有失误,同时由于能力有限不凡有错误!请阅读后批评指正!
上面基本是我研究java语言的顺序,以上书籍都是我阅读过的,不存在替任何出版社宣传的成分!有的方法可能不适合你,假如你能收获一点,两点甚至更多,请你不要吝啬推荐给你的朋友――共同学习!
感谢大家的阅读;感谢互联网的设计者;感谢java的设计师;感谢www.open-open.com和www.sourceforge.net网站!
上海,我的奋斗岁月(非常精彩) 作者:蓝色づ忧郁
看了论坛里有的兄弟越来越多对现实不满,工作压力大,想起自己在上海这五年的经历,不由感慨颇多。这位兄弟的这些苦恼,曾几何时也占据了我的头脑,让我痛苦不堪。然而,如今回
首看来,这五年来也这是这些苦恼最终成为我前进的机遇,让我拥有了目前还算可以生活境遇-700万身价,对有些兄弟来说可能是微不足道,但是我想大多数朋友还可能,暂时没有达到这个状态---没有半点炫耀的意思,我知道朋友们很多都会成功,会比我
强得多---所以会对我的经历感兴趣,我决定定下心来,好好写点文字,希望不会让朋
友们失望。
今天我的心里有一个想法更加清晰,那就是:爱,只有爱,才是一个男人成功的最好动
力、最合适的动力。而绝不是自己的虚荣心,或者所谓的雄心壮志。作为一个男人,首
要的一件事是你要有你的真正所爱。它会像原子弹一样激发你的能力,让你爆发无穷的
动力,上帝也会为你感动。这样的状态,就是每个人梦寐以求的状态。
朋友们,也许你们不同意我的看法,我们先不忙争论,您先看看我的经历,看看是不是
有道理。
1,上海
1999年中,我辞去了刚刚分配的国家机关的工作,从***来到了上海。当时我踌躇满
志,认为凭借自己的力量和努力一定能够在这个大都市里站稳脚跟,创下一片属于自己
的天空。
我是1976年出生在***,***的日照和高原气候,让我的身材像白杨一样挺拔,相貌虽
不敢说英俊非凡,但也让绝大多数人不讨厌。我从小学习可以说是优异的,大学考上了
国家排名前5的重点大学,当时分配是98年,父亲害怕工作难找,一定要我回去做个清
闲稳定的机关公务员。我觉得自己也可以历练以下为人处事,就回到了***自治区政
府。工作了几个月后,和本部门的同事混得极熟,喝酒、吹牛、查颜观色的本领提高飞
快,但是觉得工作实在是研磨青春,浪费生命,就决定辞职,去上海打拼一下。呵呵,
现在我的同学在***的也都混得很好。这是个性不同了。
我的专业是经济管理类的,当时不懂事,自视颇高,到了上海我就傻了:这种人企业根
本不要,他们要的是有一定技能的人,能干事的人,像我这种实际工作没做过的人根本
没人提供培训的机会。同学和朋友一个个工作都找到了,就我搞不成低不就的,眼看带
来的钱慢慢要见底了,这心里越来越急-难道这里还真没有我的用武之地了吗?
3个月后,我终于找到了一个让自己暂时满意的工作,但远远不是自己的专业了。我这
个人兴趣比较广泛,精力也充沛,大学里涉猎很多领域,想法也多,文字功底还可以。
正好有一个广告公司招策划文案,我觉得自己能行,结果一试,公司面试者说我虽然没
有做过,但是思路和功底还不错,再说毕业的学校名声不错,就留下我了---现在我还
是很感激那位前辈,后面的工作也证明了他的眼光。月薪3500,还好,生活问题暂时解
决了。
很快我的生活进入了工作状态,我觉得很快乐。2个月过后,一件让我猝不及防发生
了,没想到由此开始,我的生活发生了这么大的变化。
2,邂逅
上班后我对工作极其热忱,也非常努力,一两个月后我已经做过了3个Case,客户和老
板还有上司都比较满意。当时我一则是刚从机关出来,一心想好好干个工作,二则是想
报公司识人用人之恩,做事情时即不惜努力,又谦虚肯学,另外因为经过机关的历练,
做人上路又大方,经常请同事喝酒吃饭,他们也愿意帮我,所以很快上手成为部门的骨
干。到现在我还在劝年轻的朋友们,工作是应该用全身心来投入的,这项投入从理财的
角度说对任何人来说都不会亏本。呵呵,不过,那段时间存款为0。
有一天我去上班,那天早上下小雨,从住的地方要打车去公司那里,要车的人多,根本
打不到车。刚刚轮到我就要上车的时候,一个女孩子从路边冲过来,头发已经淋得不像
话了,拉开后门就要上车。我回头刚想出口请她下车,看看她淋得那样,再说让一个女
孩子出去我还说真不出来,她也好像也实在没办法了,看着我脸红红的。我就对她笑了
一下,退了出去。
第二天早上,我们又在同一个地方见面了。那天是晴天,大家都在等公交车,她一见我
就主动向我报以歉意的笑容,我指着快来的公交车笑着说:"你不会把这辆车也抢走
吧?",她呵呵笑了,说:"今天就让给你了!"。
就这样,我们认识了。
3,热恋
她叫芸,来自湖南。她不仅有湘妹子的美丽温婉,也有湖南女子的泼辣和善解人意。她
也是刚到上海,在一家贸易公司工作。
我们迅速的认识,相知,然后热恋。也许热恋还在相知之前。我至今也有点不明白,为
什么会忽然爱的一塌糊涂。也许是刚到一个陌生的地方,刚刚脱离了生存的威胁,也许
是我工作后一直嘻嘻哈哈惯了,忽然有个好女孩出现了,也有了真实的感情我就缴械
了。
我们因为住的近,下班后每天都在一起,芸说我第一次拥抱她时,她就离不开我了,她
说我的体味让她无比迷恋。热恋时我感觉我的精力无穷,每天陪我的芸到夜里11点12
点,灵感来了还去公司加班,那段时间工作效率也很高。朋友们都说我的眼睛熠熠闪
光。我们一天不见就如隔三秋。看着她的眼睛我会忘了饥饿,有很多次我心里碰碰跳着
回到住所时,忽然发现自己已经饿得受不了了,呵呵。
有一次我去崇明跟项目,因为晚了船班次停了回不来,所以给她打电话说不回来了。我
们一晚上竟然通了50多个电话,不是她打过来就是我打过去。第二天一早我一下船,居
然在码头上发现了我的芸---要知道那里打车也要1个小时的路,她流着眼泪说一夜没
睡,一早就来等我了。我们相拥而泣,幸福异常。
很快我们双方都认为对方是自己未来家庭里的另一半。到年底的时候,芸说让我去她家
见见她家人。我很紧张,但是很高兴,开始准备见面礼。呵呵,那时我们都爱昏了头,
根本没有存钱的想法。好在我的薪水涨到了5500,她也有2500,我们还够花。
然而没多久,一个消息把我的心情打入了十八层地狱。
4,彩礼
到年底了,我的礼物也准备的差不多了,一共花了大概4000多。半年多来,我已经成为
公司的干将,老板也比较看好我。因为我一直是西北人的性格,豪爽但不失明智,工作
从不计较加班,补助什么的。年底老板还多发了不少,买好礼物手边已经有1万了,感觉
自己有钱了,所以根本没想到钱的事。
这时候她的一个表妹从她的老家来了,说是来看看。我想可能主要是她家里人让她来看
看我这个未上门的女婿的。她早就给我说过,她家里她妈市老大,决定一切事宜。我们
不敢怠慢,带她表妹在上海好好的玩来一遍。最后我感到她表妹对我还是比较满意,我
的心也放下来了。
到了临走的前几天,芸忽然告诉我说,这次上门可能比较正式,语言有些闪烁其词。我
有点不明白,心里想可能她妈已经初步考察通过了吧。一天,我们三个人在的时候,她
表妹开玩笑的样子对她说,姐,你这么好的条件,彩礼可不能少要啊!姨说了,前街的
老李家的闺女都要了男方8万呢,我们决不能少于15万的。说着还看看我。
天啊,我像被电打一下,呆住了。说实话,我从小在***长大,风气很开明的,结婚男
方有送钱的一般不过4~5万了不起了,而且还是说明给孩子的。彩礼这个概念只有读小
说时接触过,万万没有想到会有朝一日到自己头上。她家里人现在说出这个话,绝对是
当真的,说话的方式都掌握的这么有技巧。我该怎么办?让她嫁改变做法想法?省省
吧!凭什么?家里的底子我清楚,决不能向家里伸手。那该怎么办?我还是笑着看看芸
和她表妹,芸有点紧张,我心里更不忍了。"呵呵!看来我要表现诚意了。",我笑着
不置可否的回答。
我该怎么办?回去后我翻来覆去地想这个问题。
5,诺言
这是痛苦的3天,我几乎没怎么睡觉。芸也看出来了,她小心翼翼地不敢惹我。我心里
很憋火:怎么弄得嫁女儿跟卖女儿一样?有时候想干脆吹了算了,可是一想到我们要分
开,心里就像刀割一样,眼泪就不由自主的下来。家里一直是清贫的家庭,弟弟还在上
大学,不可能向家里伸手的;自己的工资?天啊,我现在都觉得钱不够话,手边只有1
万块钱,这次去还要准备出血,再说我就是攒钱,也要为我们结婚买房作准备啊,15万
给了她家,我们将来怎么办?。。。
这么多年来,我对自己的了解是,我喜欢出奇招。想了3天,我有了一个办法,心就定
了。芸有时看着我,不知所措-她知道我的脾气,家境和经济状况,可是,她也知道
她无力改变她妈的想法,而且关键的是,她还有一点想法是彩礼是应该给的。我告诉
她,别担心,我有办法了。
很快,到了她家了,见面,递上礼物,聊天。。。她母亲和蔼而精明,父亲稳重而慈
爱。很快两天过去了,我们也该走了,这时该来的也该来了。最后的晚餐,她的母亲说
话了:"小D,你在我们这里已经2天了,我们对你还是比较满意的。你是个不错的孩
子。如果没有意外,希望你们能今年(新的一年)把婚定了。你看什么时候把礼节办
了?你们商量一下,也和你家里商量一下,好吗?对了,我们这边的风俗你可能还不清
楚,也不知阿芸小月给你讲了没有。"
我马上接住了话题,笑着说:"谢谢阿姨,伯父,小月和我说了。"这时我看到阿芸紧
张的脸都变了,看着我怕得要命。是啊,最后一段千万别搞砸了。我笑笑让她放心。
"阿姨,伯父,你们的心情我我理解,养女儿不容易,再说只有一个女儿,我觉得15万
如果比比投入,不算多,甚至还根本不够。这个钱我们家应该给。"
"我想阿芸也把我家里的情况告诉二位老人了,我是这么想的,也不一定合适,您二位
先听听。
"15万应该给。但是我觉得既然我工作了,我自食其力了,而且是我娶阿芸,同时你们
也觉得我合适,那么这个15万应该由我来给,而不是我家里来给。
"你们和阿芸看中的人,不应该仅仅需要家里有15万,还要有能力,有能力给阿芸将来
的生活带来幸福。我想,我有这个能力。我自己不仅要有15万,而且应该向你们证明,
我有能力给阿芸幸福。
"我只有一个要求,就是给我不长的时间,两年吧。我们还小(阿芸比我小2岁),晚
一点结婚也没关系。两年后,我会拿出15万,而且会证明给你们看,我和阿芸有能力生
活的幸福。"
其实,当天晚上我的语言远远比我的文字精彩,因为有爱在心里,我打动了她家所有
人,阿芸的脸也红扑扑的。我们走的时候,他家里人很开心,当然也许只是表面上是,
但是至少他妈默认了我的要求。当然从此后,我感觉有个巨大的大山压在了我的心里,
我的生活改变了。
6,开端
回到上海以后,我的心情没有低落,反而有种大战来临时的平静和激动。我心里暗暗下
定决心,为了我的爱人,我的未来幸福生活,我要付出比别人几倍的努力,实现我的诺
言。我全身心地渴望这样做,而且相信自己一定能够成功。
芸反而很担心,她和我说要不我们搬到一起,生活上可以节省一些,她和我一起攒钱。
我拒绝了她。虽然我们早就有了肌肤之亲,但是我不想让她家里人知道,这样对她不
好。而且我也不愿让她一起攒钱,毕竟我说了,这是我的事。我知道一个女孩,生活、
衣服、化妆品等等,每个月的花费怎么说也要2000块左右的。我说,芸这段时间我可能
就不能给你买很多衣服和化妆品了,她郑重地点点头。我不知道,以后我是否会为这个
决定而后悔。
我的初步想法是这样的:因为我只工作了7个月,而我的薪水已经涨到了5500。如果依
照这个速度,半年后我的薪岁至少应该到8000,一年后最不济也应该到10000左右。我
可以什么都作,而且可以往管理方面发展,这样,我每月存下70%的工资,2年下来加上
年终奖,也就差不多了。而且,那时候即便把15万都"上供"了,我的年收入也能够让
我们生活的小康。
现在回想我那时候想法,心里只有两个字:幼稚。事态的发展果然证实了那句话:计划
在现实面前永远是无用的。
7,失败
很快,现实给了我重重一击。一个偶然的机会,我和大老板聊起来,他告诉我策划和创
意人才可以很快赢得中等偏上的薪资,但是要达到5位数,只有2年的工作经历基本不可
能。因为国内的商业条件还不成熟,客户的能力也有限。所有的公司愿意付出一些成本
搞定客户,在策划和创意上达到80%的满意就可以了。而且,公司愿意把高薪给业务人
员和管理人员,一个只有2年工作经历的人基本不具备它所需要的人脉资源、操作能力
和管理能力。
我明白了老板的意思。我开始在市场上寻找其他的公司。但是现实很快让我失望,要在
一年内获得万元以上的月薪根本是不可能的。好的公司有,但都说2到3年内有希望,如
果做得好的话。老天,我的时间不够了!同时,公司知道了我在外面找工作的事情,老
板们很不开心,因为平心而论公司觉得已经待我不薄了。说实话,这条路成功的可能
性很大,但是时间不够啊!
怎么办?
我决定辞职。
8,艰辛
既然已经证明此路不通,再留下去就是浪费时间。我的时间不多了。而且我认为自己如
果辞职,就有的是大块的时间,能够接触更多更深的社会,机会也相应的多了。阿芸不
同意,她说这样太不稳定了。我没法说服她,她也没办法说服我。这件事我还是做了,
我知道,只能破釜沉舟了。
临走时和老板深谈了一次,请他原谅。也把我的处境部分告诉了他。我们谈得很好。老
板很惋惜,让我以后有可能还回来工作,我也很依依不舍,但是我已经没有退路了。
我开始了在上海滩到处漫游的经历,骑着一辆破自行车到处在上海转,到处找有限的熟
人,问有没有项目做。我身边有1万2千多块钱,觉得还可以支撑半年吧。我想,这半年
里如果有策划项目做,我就辛苦点,把所有的事情都自己做了,应该可以挣个2到3万,
多做几个项目就比打工好了。呵呵,如果朋友们谁有我那时一样的想法,今天我一定劝
你千万别!事后想,我太自信了太着急了,真是应该边工作边找机会,时机成熟再干
的,否则下海99%是被淹死。我就这样风里来雨里去,跑了2个月,一个单子也没有跑
到,加上有一次丢了包,损失了1000多块钱和手机。住宿、吃饭、交通花了3500块钱,
身边只剩7000多块钱了。可是一点没有转机的迹象出现。
9,机遇
就在这时候,一个令人不敢相信的、非常好的机会出现了。我以前的一个客户找到我,
说是他的一个朋友在上海嘉定那边的一个镇里做镇长,他们镇上3个月后要办一个"水
乡情思"的活动,主要是吸引港台和外籍人士的资金投资。他们要我构思起草一个大型
活动的策划书,价格是4万元。这个客户说以前在我们公司和我合作过,觉得我有这个
能力,而且拿到公司去做策划,价格一般要到8万以上。我们合作空间更大,而且如果
策划书做的好的话,活动组织和制作我们还有机会。我很开心,明白他是想自己也赚一
些,立刻给了他2000元的好处费。不知道这个习惯有没有影响我,直到现在我都认为机
会来了一定要投入,而不是大多数人认为的不见兔子不撒鹰。
我废寝忘食地工作了20多天,每天夜里干到2点,稿子改了4次。然后又自己贴了400多
块钱制作了3本样本。交给那朋友的时候,他非常赞赏,连声说做的太好了,看来后面
的制作也没问题了,一周之内我就等着拿钱吧。我也心里感叹投入没有白投,连忙把这
个好消息告诉了芸,她也非常开心。毕竟这是我的第一笔收入啊!而且金额还算不少。
10,被骗
我万万没有想到,这次看起来不错的机会竟然实际上是碰上了一个骗子。这个客户拿到
了我的方案以后,竟然人间蒸发了!我苦苦等了一周以后,这家伙死活不再和我联系
了。我打电话,手机已经停机,跑到他原来公司去找他,公司的人说他早就不做了,现
在在和一个人合作开公司。我又跑到嘉定的那个镇上去找我们以前一起见过的他的镇长
朋友,镇长说这个项目早就签约了,他和我那个客户也不是朋友,只是签约公司说策划
书部分包给他,他又找到了我,说我是他的助手。现在策划书已经通过,钱都已经付
了。我马上又找到了那家公司,公司说我那个客户不是他们公司的人,只是他让公司把
策划书部分包给他,钱公司和他刚结清了。知道我的情况后,他们表示同情,但没办
法:现在他们也找不到人,钱也结清了。
这个打击对那时的我是致命的,让我的处境雪上加霜。我已经花了大量的精力不说,原
来剩下的7000多块钱已经被我花去了大半,只剩3000多了。更可怕的是我的时间又用去
了一个多月。
这是后话:那个客户我这几年就再也没有见过。后来听说他过得很不好,很多人都在找
他,他又让合作伙伴坑了一次,基本上就再也没有听说在这个行业里做过什么了。
11,灰心
万分沮丧的我把情况告诉了芸,告诉她的时候我分明听到了一个美丽的泡沫在她心里破
碎的声音。她表面上没有说什么,但我知道她失望极了。我们相拥无言,我只能从她这
里得到一丝温暖和安慰。她说,你别急,没关系,我们从头再来。可是,我的爱人,你
知道吗,这个打击甚至让我回头审视自己,怀疑自己:我这样的一个北方人,是不是适
合在上海打拼?
尽管万分失落和失望,可我不能让我的女孩对我失望。第二天我强打精神对阿芸说我要
重新开始。我考虑了一夜,因为我已经没钱了,不能再租原来的房子了,我必须去找一
个民房住,每个月可以省7~800元左右。但是这样就不能和芸象以前那样离的那么近
了。我说我不能停下来,时间不多了。芸哭着抱着我说,我一定要多来看她,她会很想
我,我有经济困难一定要来找她。我笑着说,你有经济困难也要来找我啊。
朋友们,尽管时间已经过去了那么久,可是今天我回忆到这里的时候仍然泪流不止。那
时候我已经处于最低谷,生存也成问题,可是我仍然愿意回忆那时的事情。我怎么可能
想到,命运老人会让以后的我和她发生那么大的变化?
12,初醒
我搬到的一个民居是个私房,就是农民自己盖的房子,房子里面夏天热冬天冷,而且只
有10个平房大小。我已经很满足了,这里每个月租金才200元,比以前我已经省了800块
钱了。
搬过来以后,我有很长一段日子不知自己干什么好。我想这是载过跟头的人的通病吧,
相信有过类似经历的朋友会有同感。可是不做事情我心里又焦急万分。这种矛盾的感觉
真是让我每天心里都不好受。
转眼一个月就要过去了,这个月里我基本上是馒头就咸菜,肚子里油水实在缺的厉害。
我决定去买点熟肉解解馋。我这个民房周围有几个新改成的小区,因为离市区比较远,
基本上是一些市内动迁户迁到这里来的,真的购买这里房子的人也都没什么钱,但是这
样的人在上海很多,小区外人气还是不错的。这里不像高价房,高价房是开盘很久了还
没见几个人烟。小区之间有条街,人很多但大都是些老人孩子在转悠。熟肉店生意好象
不是很好,我要了一些肉又买了一瓶啤酒,在旁边小店的简易桌上坐下来吃。
多年以后我回想那个时刻,还是认为那是上帝给处于绝境的我的一个机遇。就在那时,
忽然有人和熟食店老板说话,在说老板,你这生意不行啊!是啊,那老板说,我下礼拜
农忙,准备回家了,不做了。那人说,那你这店怎么办?那老板说,转了呗,这半年没
赚什么钱,还不如做点别的。忽然我有一种苏醒的感觉,我到处找钱赚,可是好高骛
远,忽视了这身边的机会,难道自己一直没看见?我马上站起来,让老板再给我一点牛
肉,然后漫不经心地问他转让店面的情况。
不过十分钟,我就清楚了:这个店也就10个平方左右,月租金1200,租金他多付了两个
月。转让费他要求不高,不亏就行,带一点简单的设施,2万块钱吧。我说我想接手,
但是价格太高,他降到了1万8。我说1万5我今天就要,他回去和他老婆商量了以下,同
意了。我立刻回房拿了我仅剩的3000块钱作为订金付给他,然后当晚立下转让书,当然
他同意我7天内把余款付清。
13,努力
我找到以前公司的老板,请他借给我钱。我还带去了我做的那份策划书,说我送给公司
的。老板也多少听说了我的事情,他详细地了解了我的境况,二话没说借给了我1万5千
块钱。我笑着说:"老板,我把身份证押在你这里吧?",老板也笑着说:"你要不要
我的身份证,1万5我押在你那里?"其实到现在我都一直敬佩我的老板。他的事业现在
也做得很好,家资3000多万了。
拿到店面前的3天我一直在苦苦思考,怎么能让我的店面生意大为改观呢?首先,我回
忆到以前的鸡粥店,觉得上海人爱吃鸡,特别是白斩鸡,还有烤鸭,决定经营品种适当
变化;另外,饮食业最重要的是卫生(卫生许可证一年一办,已经有了),我决定彻底
打扫店面一天,店面重新贴开业标志,另外买了一个二手的消毒柜,特意摆到台面上让
客户看到消毒设施的过程;然后,我找了一个上海老师傅来指导制作工艺(退休了返
聘,很便宜的),再找了2个勤快的四川妹帮忙,允诺给他们业绩5%的提成,但是不行
我就换人;等等大概有20多条措施吧,我当时可是写满了2页纸的,全部做完已经过了
近10天了。最后,我买了一些鞭炮,噼哩啪啦一放,人气立刻被我吸引过来了。呵呵,
当天忙到夜里11点,一盘点营业额居然有500多!
14,曙光
做过生意的朋友都知道,开业的当天生意好不见得以后生意一直会好。因为刚开始客户
是好奇,试一试,一旦没有什么特别吸引之处,他们就会立刻忘了你。而你要再吸引他
们的注意力就困难得多了。
我明白这个道理,所以第二天开始就在店面前不停的拉人聊天,问味道怎么样,然后不
由分说要送他们一些熟食。上海人内外分的很清楚,他们决不会白要别人的东西,绝大
多数都付点钱,当然他们也不会白给别人东西。当然我明白,生意的关键是我的货品要
合客户的口味。慢慢的我的小店人气就有了。我还请人在几个小区里张贴了我们店的广
告,也请人故意拎我们的烤鸭在几个小区人多的地方走动,相互之间含喧,巧妙吸引人
们注意。通过很多这样的方法,一个月后我的店每天的营业额可以达到800元左右,而
且还在不断上升中。呵呵,我以前的策划功底全部用在这上面了。
我这样起早贪黑的忙碌,每天大概干14、5个小时吧,完全把心思扑在了店面上。作了
第一个月的生意后,我盘点了一下,我一共赚了9000元钱;第二个月我赚了12000。把
欠的债还掉后,我又没钱了。但是我感到,我生命中久违的曙光已经来了。说实话,这
种感觉真的很美妙。
15,做梦
我就这样经营着自己的小店,时间又过了3~4个月。其间我忙得每天只睡5、6个小时,
一躺下就昏迷不醒的样子。我和阿芸通过几次电话,她也忙,因为她升职为资深业务
了。我们见过几次面,她都让我好好休息一下,我笑着说,把你娶回来再说吧。她说你
靠那个门脸赚到钱了?我笑笑,决定几个月后给她一个惊喜。
4个月后,我已经攒了5万块钱,可是也快到年底了。算算我的时间只剩13个月多一点
了。如果按照现在这个模式发展下去,我完成目标15万的可能性是稳稳的。我每个月只
要保持现在的状态,那么一年以后我应该用18~20万。钱是够了,还可以办个像样的婚
礼,不过买房子是暂时不用想的。呵呵,看到这里,不知道又有多少朋友在笑我-楼
主的幼稚病又犯了!是啊,如果没有房东的收租事件,我想我会把这样的梦做下去吧。
房东来收过几个月租后,就到年底了。有一天房东忽然出现说是要签明年的租房合同,
但是价格贵了一倍。气得我差点翻脸,这分明是看我生意好了眼红嘛!可是我知道人在
屋檐下,不能不低头啊。再说我现在可是一点问题也不能出。我和他好说歹说,又送给
他了一些熟食,房东还是加了我1000块钱。
这件事让我意识到危机已经显现。生意做得好了以后,第一房东的房租会涨价,不可能
再跌价,各种费用也会涨;第二,很快竞争者就会出现,出现以后和我的小店是同样规
模,势必会分流客户。所以这种赚钱的状态是不会持久的。如果我不动作,最后的结果
我想也想得出:小店几个月后就回到维持生计的地步。那么我该怎么办呢?我一夜没
睡,苦思对策。
第二天一早,我下定了决心,决定孤注一掷,冒一把大险!
16,冒险
我的计划是这样的:第一步,在附近的小区再开几家这样的熟食店。地段只要和我现在
的店面地段差不多就行了,但是不能太近了,然后用一样的装修、一样的名字、一样的
策划手段,建立起小区居民心目中品牌形象,这样进货价格会便宜很多,还可以逼迫后
来者提高投入。这个计划实施的越快越好。第二步,我觉得现在这个商铺的价格不高,
2000多交租不如我把它买下来。上海的朋友都知道,2000年底上海郊区的房子价格只有
2000多,商铺也只有3000多。这一步必须稳步实施,一个一个来。但是这样我就是必须
投入我现在所有的5万块钱,如果一旦失败,我的时间、金钱投入可能会让我的目标彻
底无法实现。但是我又想,我不去做,就把希望寄托在别人别来抢生意上,我去做了,
希望在我自己身上。相比一下,我愿意把希望寄托在自己身上。
但是我以前所想的给我的芸一个惊喜的计划只能延时了。我心里对自己说,为了她,拿
出你所有的劲吧!那是无比艰辛的一个月。我不仅要照顾一号店的生意,又要为二号
店、三号店选址、选人、买设施、店面布置等等。后来我提高了一个一号店店员的提成
比例,封他为店长,告诉他1个月后店里的营业额如果下降5%以上,立刻换店长。这样
我就全身心投入到新店的开张。1个月过后,我的二号店、三号店相继开张,我还是无
法清闲,又开始了以前那样的策划造势,而且开始了四号店的准备工作。
后面的一个月,我一号店的盈利状况还是不错,达到了12000元,二号店5000元,3号店
最好,居然有10000!要知道这是头一个月,人员还不熟呢!我发现原因是一个女孩店
员做生意很有天赋,也会招睐客户,我二话没说给她工资翻倍,直接提升为店长。
年底如期到来,我和芸只在一起度过了半天,就不得不忙着自己的店面了。芸要回家
去,我不能走,目标没有完成我怎么能见她家人呢?不过我和她妈通了一个电话,她妈
笑着说:"小D,我们知道你是个好样的孩子,我们都盼着你把我家芸芸早点娶走
呢!"我知道这话里的意思,也笑着回答说:"我会的,谢谢阿姨和伯父的信任。"
年底年头的2个月,因为过年,节日也多,我的生意好的一塌糊涂。四号店也赶在春节
前开了。这两个月每个店平均一月能赚15000,2个月后我身边的现金达到了12万。元旦
前还有一件事,原来的老板给我打电话说,他公司还有一个转入户口的名额,问我要不
要,我说要。他说我什么都不用管了,把资料给他就行了。为了好好感谢他,过年时我
去他家给他的孩子送了一个5000块的红包。年后不久我的户口办下来了。我开始逐步的
和各个东房谈要购买铺面,如果他们不卖,我就找别的房东谈,那是很多房子是物业
的,比较好拿。而且那时候房价低,再说我找房子前就打的有伏笔,另外我价格给的稍
高一些,前面3家都谈的很顺利,单价大概在3700一个平方吧,一共13万,我全部给的
是现金。第四家以一共要5万(生意好啊,房东要挟我),我没钱了,但是抵押了前面
的一家店作为3万先签了意向书,等到一个月后,资金回笼了,把钱凑齐了把店拿了下
来。
这时候已经是3月底了,我还剩8个月。生意好象在稳步进行,目标好像越来越近。可是
我没想到,一个足以摧毁我的重创也越来越近了。直到今天我回想到这个让我记忆深刻
的时间段,还觉得眼眶里泪水未干。
17,重创
时间又过了3个半月,马上要到7月10日了,我之所以记得这个日子,因为这是芸的生
日。我决定在这个日子之前攒足15万,并把这个消息作为生日礼物送给她。想到她得到
这个礼物时候的开心,我的心里别提多激动了。这几个月店面也争气,每个店都能够达
到10000多的利润,这是因为我店多了,进货成本低了,而且房租也不用交了,还有一
个最主要的原因就是我用了一个很好的店长-小成。
小成就是我前面破格提拔为店长的那个女孩子。这女孩是从浙江来的,只有19岁,人长
的清秀漂亮(因为要招徕客户,这是一个比较重要的因素,招人的时候我就特别注意要
找看着舒服的女孩)。因为一般的外来妹大多不是浙江来的,所以我特别留意她。没想
到这个女孩在做生意方面真的很有天赋,她一直是很开心的样子,从没见过她烦过,会
说话,人很甜,客户缘很好。而且她很有脑子,开业没几天就把所有的常客的名字记熟
了(我估计她是问周围的店主和客户的),还建议我,天气热了,店面里配点素菜,啤
酒,买点简易桌椅,晚上让客户边吃边纳凉。她还把周围的几家饭店的电话弄到了,把
饭店的生意也拉了进来。后来我们熟食店里的生意饭店进货居然占了30%!
不过她也有一点不好,就是好像身体太单薄,力气活干不了多久就累得脸发白、出虚
汗。小店生意好的时候,这也挺影响的。我考虑了几天,决定扬其长,避其短,在店里
又招了一个身强力壮的小伙子给她打下手,告诉她只管招徕客户,管理帐务。
这时候我的一个朋友打电话给我。原来他不知道从什么地方得知我开了几个店,做得
还行,而他正在做房产销售,代理一个别墅的盘子,非要我去看看。上海的朋友都知
道,2001年的时候上海的房产还远远不热,房产销售尤其是高价房的销售很难做。他代
理的那个别墅房型有180多个平方,周边的配套还不完善,再说总价要80万朝上,我不
想买,就告诉他没那么多钱。他说,你来看看吧,看了肯定喜欢,再说钱的事情好办,
贷款就行了。我说那还要首付呢,我首付也没有。他说没关系,他可以在合同上做点手
脚,让我零首付,全部贷款。我没办法只好去看看,没想到看了以后特别喜欢别墅下面
的花园,因为我记得芸曾经告诉我说,她的梦想就是住在花园的上面,每天早上打开窗
户就能闻到花的清香。朋友看我有意,就拼命鼓动我说,买了这个房子这个优惠,那个
免费的,每月只要付6000多就可以了。我还是有点犹豫,说我不想每月跑银行。他说,
我帮你办,每月自动划款,不用你操心的。我没什么再挑的了,想想就定了一套。不过
后来知道,这小子还是打了埋伏,有些言过其实:窗户就不是他说的双层的,车位也不
是免费的,呵呵。
7月9日,我拿着那份15万元的存折卡,兴冲冲地拿着一束花,拎着一品瓶红酒(蛋糕明
天叫人送来)赶往芸的住处。之前,我已经给她妈打了一个电话,向她父母亲问好。同
时告诉他们,我已经提前5个月实现了诺言,很快就会娶她家女儿了。我决定先给芸一
个惊喜,然后今晚就住在她那里。我特意赶在她下班前一点赶到,准备突然出现,吓得
她快乐的大叫。
可是让我始料不及的事情出现了,芸下车时不是一个人,而是和一个男孩一起。他们手
拉着手,好像很亲昵。我一下傻了,不知道怎么办好,他们一起进了小区,我傻乎乎地
跟在后面。在光线阴暗处,那男的还一把搂住芸亲了一下。我的脑袋轰的一下,再也受
不了了。我大叫着芸的名字,冲上前去一把抓住芸,然后就要打那个男的。芸吓了一
跳,拼命地拉住我,对那个男人说快走,你先走,我跟他解释。男的走了,芸还是拉住
我不放,我叫到解释什么?解释什么?一边眼泪就快下来了。芸看着我,很冷静,冷静
的我们好像不认识。她对我说对不起,早该告诉我。但是我今天太不冷静,她希望我先
冷静下来,现在的气氛我们没法谈。我没办法冷静,说不行,今天你就必须给我一个说
法。她被我纠缠的没办法了,对我说,D,一直以来,我以为你的素质很高,你今天这
样会让我很失望。我停了下来,看着她,眼泪慢慢地流下来,最后对她说,好,我走,
明天来再谈。出了小区,发现花和红酒居然还在手中,一把把他们扔进了垃圾箱。
那夜我一夜无眠,盯着外面发呆,怎么也想不明白事情怎么会到这种地步。第二天一早
我在芸的楼下等着。芸下来说我们找个地方吧。我们到了一家茶室,我呆呆坐下,等她
解释。那天她说了很多,我都有些记不清了。她说,其实从我搬走我们就很少在一起
了。她知道我很努力,很辛苦,但是经历那么多波折,真的很怀疑我是不是能够实现15
万的诺言。她心里开始很怕,但是又没机会和我说。我的压力又不和她分担。在上海这
么长时间,她和我一样做得很辛苦也都没有归宿感,觉得很累。这时候她的上司,就是
那个男孩出现在她身边,男孩是上海人,比她大4岁,在公司职位不错,家里条件也
好。芸说和他在一起,她会觉得很安心,很安定,很有安全感,不像和我在一起,虽然
感情曾经很热烈,但是总是不知道我们的将来在那里。她说对不起,真的对不起。我激
动的浑身乱颤,说不出话来。好容易稍微平静一些,我告诉她说,我现在有15万了,你
还会爱我吗?她说,对不起,我觉得现在很好,我不能再对不起他了,我们不会再在一
起了,希望你将来幸福。出门的时候我发现了那个男孩,心里又一阵刺痛。约在这里,
一定是他们商量的结果。
18,怀疑
这真是一个巨大的讽刺。一直以来,我以她为努力奋斗的动力,可是等我奋斗到了目标
跟前,却发现目标忽然消失了。我记得那时候,我开始失眠,希望自己赶快入睡,然后
梦见芸。可是我一次也没有梦见她,倒是我清醒的时候一刻也没有停止想她。我经常觉
得心里刺痛,头皮发麻。一直以来,我那么小心翼翼地把她放到我心里的一个最温暖、
最柔软的地方,没想到最痛苦的打击却由这里产生。
有一个朋友曾经回贴问我,怎样才能获得不爱你的女孩的爱,我没有回答。不是我不愿
回答,而是我不知道怎样回答。我真的不是这方面的专家,我也曾痛苦无比,希望能够
改变我爱的女孩的心。可是我没有什么办法,只有自己默默地退回,独自一人舔着自己
的伤口。
那段时间我对自己过去的所作所为产生了怀疑,我这么做到底有什么意义?如果我还在
公司工作,每天还有时间,情况就不会这样。如果我不搬家,事情也不会这样。如果我
不开店,就有时间陪她,情况也不会这样。就是开店了,如果我不开分店,也有时间去
看她,应该也能阻止她情变。每天我这样乱七八糟的想法充斥了我的脑海,让我对生意
根本提不起兴趣。
店里的员工都看出来了,他们小心翼翼的不敢惹我。几个店长都很称职,生怕店里的事
情会引得我大发雷霆。尤其是小成,她主动找到我说她来每天到个家店里盘点,让我忙
我自己的事。我很感激她,也相信她的能力,就告诉几个店以后由她来查店。我知道自
己这个状态如果硬让我去,非出事不可。小成很有手段,也有能力,查店每天要多做2
个小时,她很快让其他人服服帖帖。还好,有小成和他们的帮助,我的生意没有什么影
响。
但是我自己知道,我已经迷失了前进的方向。我不知道怎么再找到这个方向。
19,迷失
有人说工作累的时候,家里压力大的时候很辛苦,我却不是这样认为。我觉得一个人迷
失方向的时候最痛苦,因为你不知道自己应该做什么,这种状态每天无时无刻不深刻地
提醒你不过是一具行尸走肉罢了。那个时候就是我迷失方向的时候。我就像一个被抽去
发条的时钟钟摆,每天不过是由惯性推动我在摆动。我不知道什么时候会停摆。也许在
我的内心深处还在暗暗期盼那停摆的时刻。
芸的妈妈给我打了一个电话,接到电话知道是她,我心里真的不知道是什么滋味。她妈
对我说,孩子,阿姨知道你很难过。你们年轻人的事真不知怎么搞的。但是阿姨告诉
你,你是个好孩子。你的前途还很远大。阿芸不能和你在一起,是她没福。好好的,我
们全家都祝福你。听了这话,我的眼泪又留下来了。以前觉得她是那么固执和势力,今
天怎么觉得她的话那么温暖。我终于能够真正站到一个父母的角度上来看彩礼这件事,
是啊,那是要把自己女儿未来幸福生活尽量多地抓到手里的感觉。
在这里我要感谢我的一位大学同学枫,如果不是他凑巧来到上海,要我陪同的话,我不
知道我这种状态要持续多久。枫来上海玩,指定我陪,而且说陪得不好当即给所有哥们
打电话说上海没我。我强打精神,枫还是有所察觉。枫一见我就说,你小子怎么减肥减
的那么明显,不行不行,我们不能一起照相,否则班花见了照片,我一点想头都没了。
他就是这样,那几天逗得我开心了一些。要走的时候,枫说,说说吧,怎么了。我这才
知道,他早看出我有事,所以一直在让我开心。从芸变心以来,我从没有向人倾诉过。
枫听过了之后,很久没有说话。后来一开口就是一句:"好!这是好事!"我听的愣
了。
枫接着解释说,我和芸现在分开始好事。因为就是现在不分开,我们早晚要分开。因为
我们不是一路人。芸的内心深处时那种安分守己的人,经不起动荡,分开的时间主要视
我波动的强度而定;而我是那种不安分守己的人,越是不利、越是艰难,越能激发我的
能力。我适宜在变数中求生存,求发展。而且我不是很在乎物质,所以要的感情是非常
纯粹的,女孩子大多到了要结婚的关键时刻,生活现实和抚育后代的本能让她们不得不
物质起来。这不能说不对。这也是为什么当初芸自己也不反对彩礼的原因。他说,我这
样的人,只有物质生活到了一个水准后,交往的女孩子才会有安稳的感觉。现在还不
行。但是我应该感谢芸,她激发了我,她放了我是我的幸运,否则我们在一起,芸一定
会成为我的桎梏。他还说,你的奋斗动力就是她?那你的家人,朋友呢?我们呢?你以
前的老板呢?你的员工呢?我们还一直以为你能成大气,为了我们这份信任,你也不应
该放弃。而且,说实话,你的这点家业还很小很小,一不小心,很快就败了。
他还告诉我要留意小成,这小姑娘太聪明。我就是对女的太迟钝了才栽的跟头。以后绝
对不能让她独掌财务大权,我一定要控制住她。最后,他拍拍我说,兄弟,醒过来吧,
外面的世界很残酷,也很精彩,但是绝对不是为这个样子的你准备的。
枫,今天的你也在看这份贴子吗?如果是的话,我想对你说:哥们,真的谢谢你!
20,心意
因为那一场直抒胸臆的倾诉和枫的精到劝慰,我终于慢慢开始摆脱失恋的阴影。我特地
给家里打了电话,给弟弟也打了电话,同时也和同学朋友纷纷联系,又去拜访了以前的
老板,他们都为我在上海的奋斗状态和所得高兴。我之所以这样做是想提醒自己,我的
世界还在,我的生活还在,我要主动地让他们把我拉回到我的世界里。他们对我的爱也
会成为我的动力,这是更绵绵不绝,更持久的动力。
同时我也听取了枫的建议,重新收回了店面的管理权限和财务权限。我把小成和另外一
个店长互换了位置,然后仔细的查询了最近的账目,还悄悄地私下和其他人谈了谈,侧
面问了问他们对小成的看法,大家都没说什么有价值的话,除了一号店店长,他的资格
最老。一号店长说小成太跋扈,太不尊重人,什么事情都自己定,也不和老板商量,更
别说其他人了。每天的财务帐、现金全是她管,根本不让别人插手,也不知道她是怎么
想的。因为我暂时没有查到什么小成的把柄,所以只能安慰一下他,也没有做什么动
作。
这时候4号店的小徐(他就是我招的为小成打下手的伙计)找到我,要求要换地方,他
要跟小成到一个店里去,否则就辞职。我一开始很奇怪,后来恍然大悟,明白了小徐的
心意:原来小徐已经喜欢上了小成。我同意了小徐的要求,同时更为警惕,因为公司里
有一对的话,容易形成小集体,而且他们容易一起跳槽,成为我新的竞争对手。我不得
不暗自多留心小成和小徐。
21,真爱
我的心意逐渐回到了生意上。不得不承认,小成有一套。她总结出一些管理规范和待客
方法很有用处。她的做法比我原来的做法更细,我比较倾向于策划一些活动和办法,短
期效应比较明显,但长期的发展还是需要细化的管理。生意还是缓步发展,我们基本上
每半年利润提升20%,这一方面因为管理的细化,人员的熟悉;另一方面还是得益于这
里的人气渐渐旺起来了。这样过了年,到了2002年4月份,我的手头已经有了超过50万
的资金。经过和小成交谈,了解了她的很多想法,我觉得我暂时还时离不开小成。这段
时间我发现小成对小徐也是淡淡的,他们的关系好像并没有变得密切起来。
因为对小成的留心,我发现了小成身上的越来越多的细节:她一个人住,爱干净,爱
笑,爱看书,很怕冷,尤其害怕感冒,不喜欢猫狗等等。因为生意的缘故,我和小成的
交流越来越多,也就越来越了解她的聪明和能干。有时候我想,这么聪明的女孩因为家
庭的原因不能上大学真是可惜了!又转念一想,就是上了大学又怎么样呢?大学生我自
己不就是吗?我见得还少吗?原来戒备心理也可以让人如此留意一个人。
有一天我去查店,发现小成没来上班。我们一般上班很晚,下班也相应晚一些,因为生
意一般是在下半天。写到这里,我想到有的朋友怀疑一个10几平方的熟食店一个月的利
润怎么会有10000块钱,我想说,生意人人做,关键看你怎么做。我们的每个店周围都
有1000户左右的小区,很多是租户,他们不愿开伙。我们每天晚饭时段一般要做50笔生
意,每笔十几元,这样营业额就有700元左右。食品行业一般利润率一半左右。节假日
更好做,还不算饭店的生意。当然,我们不用交房租。而且现在的生意也不如那时了,
这是后话。言归正传,我发现小成没来,就问了一下,有员工说她不舒服,今天不来
了。小成没来,小徐也没来,我想想反正上午每什么事,应该去看看小成是不是病得很
严重,就向他们问了地址,出来买了点水果,打车往小成住的地方赶去。
小成住的地方我没有来过,到了小区门口我才发现是个比较高档的小区,这里一室一厅
的房子一个月要1000块吧,我边走边想,一边又很不解为什么小成会把月收入的一小半
用来租房,尤其是想想自己才刚从私房里搬出不久,现在的房子也不过是1000元左右。
正在胡思乱想,忽然发现小徐从一个门洞里出来,急匆匆的样子,我连忙回避在一旁,
看着小徐跨上自行车往店面的方向赶去。
忽然在这里看见了小徐的片刻,我的心里产生了一种很奇怪的滋味。一种很不舒服、心
头微酸--好像是吃醋的感觉,同时觉得一阵懊恼。这种感觉没有经过理智,完全好像是
自然而然产生的,只是片刻之后,我忽然一阵震惊---难道我如此在意小成?难道我不
知不觉已经爱上了她?这是一个连我自己都吃惊的发现,因为失恋的很久以来,我一直
觉得自己好像已经不会爱、不能爱了,有时候我会接触到一些女孩,可是我根本无法提
起感觉。没想到,我爱的感觉会在小成这里复苏?小成可是我一直提防的人啊!
刹那之间,我的脑海里风起云涌,万种思路好像被同时激活:是我失去了芸,把小成作
为一个感情的替代者了吗?不是,和小成在一起的感觉完全和芸不同,我们的交流更平
和,因而更交融,我也感到更轻松。和芸在一起完全是被激情和冲动淹没,我们心灵层
面的交流显得更少---如果更多的话,也不致有那样的结果;是我因为她病了而怜惜她
吗?不,怜悯和爱我是分得清的,现在我的心里分明有一种心痛而且甜蜜的感觉;难道
是见到小徐引起的男人本能的异性排他性不满?也不是,因为我清清楚楚的知道,我决
不是一个把身边所有女孩都看成情人的情圣…..你呀你呀,你经历过感情的痛苦,所以
你一定要分辨清楚,这是你的真感情,你的真爱吗?你不要糊里糊涂的再带给自己或别
人痛苦了!
可是我越是想,小成的笑脸、话语和我们交流的场景等等印象就越清晰,我就越觉得小
成是真正适合我的女孩。她的开朗,她的平和,她的聪明能干,她的善解人意,还有她
为我的事业作的努力和成效,当然还有她可爱的、惹人怜惜的样子---这些我以前都没
有明显地感觉到,可是今天我感觉对我来说就象空气一样不可缺少!
爱情的幼苗一旦破土,成长的速度真是惊人!在我伫立楼下不到30分钟的之后,我已经
感到我的心胸开始无法承受它的奔涌,必须要向她倾诉才能缓解。可是我不是一个语言
表达爱意的能手,尤其是现在这个令人激动的时刻,我觉得我现在激动的别说讲话了,
连一口气都不能顺畅的呼出。我忐忑不安,但又决定立刻向她说出来-就是现在!
敲开她的房门的时候,她的脸色有些苍白,可是她的目光那么平静,柔和,一点也不吃
惊。我反而更加慌张,不管了,我必须要说---"我,我……你,你,你病了……我
发现我离不开你!我发现我爱你!小成,你听我说,我爱你。我喜欢你。我要给你说,
我离不开你了!"
那天我说了很多吧?不知道,记不得了。可是结果我却记得,小成拒绝了我。
(周一请看:22,原因
各位,21这一节和理财关系不大,可是对我的人生却关系重大,所以我把它写的很细。
希望你们喜欢。)
22,原因
在感情方面,我是一个脸皮很薄的人。小成不声不响地听完我语无伦次的表白后,低着
头平静地摇头表示不能接受,我就不知道该怎么做了。为什么?因为你和小徐?我问。
她摇摇头,没有说话,但我看到她有眼泪流下。呆了一会,我不知该怎么做,一直惶惶
惑惑地。最后,我还是离开了她的住处。再见到小成,是2天后了。她来上班,我早早
等在店里,远处一见她的身影,心里就怦怦跳个不停,可是见了她的面又不知该怎么说
话。她看见我,好像脸红了一下,就再没和我说话。说实话,我觉得她是喜欢我的,尤
其是回忆到她以前帮我时那种自告奋勇和尽心尽力,我越发这样认为,但是她为什么拒
绝我呢?我想不明白,哎,真不理解女孩子的心思啊。她工作起来还是那样井井有条效
率很高。我不愿打扰,就去其他店了。
到了4,5月份,天气有点热了,因为刚过了年,生意是属于淡季。我们希望再热一些,
这样人们愿意出来吃饭;不过因为天热,食品行业风险很大,绝对不能出现食品变质,
否则对生意的伤害是很大的。我们这时候一般加紧和饭店联系,因为饭店要量大,而且
可以预知,这样风险小。因为这方面一直是小成负责,所以现在淡季反而她会比较忙,
我也比较放心。没想到,不久小成忽然出了事情---她累得晕倒在了店里。
当时我接到电话飞速赶到店里,小徐已经把小成扶在椅子上坐着,根据小成的指点正在
给她味药。小成坚决不同意去医院,小徐他们也没办法,看见我来了,都像看到救星一
样。我不由分说,对小徐说:你出去打车,我们两把她送医院!小徐一出门,我一把抱
起小成就走。小成在边挣边说不去,我根本不停。我知道,不让小徐他会和我急的,但
是我也要和小徐公平竞争。很快送到了市八院---离我们那儿打车要30分钟吧,我们
等在旁边,护士就要开始测血压、测血、停诊了,对站在旁边谁都不肯离去的我和小徐
说:"女孩子脱衣服你们小伙子也在旁边吗?"没办法,我们只好出去。
我们等在外面,小徐一直不和我说话。大概他感觉出我对小成的意思,他有些戒备吧。
大概过了几十分钟吧,医生出来小声说:"成**,同事还是家属?"我们都站了起来,
医生责备的对我们说,小成有先天性心脏病,根本不能工作劳累、激动,更不能感冒。
她的心脏已经比普通人大了,因为小时候没有手术治疗,现在手术的可能性很小,只能
静养。
这时候我的脑海里如电光火石一般,一下明白了为什么她一累就脸色发白;为什么她不
能干体力活;为什么她怕冷,不能感冒;为什么她住那样的房子---因为医院近;甚
至,我也明白了---为什么她拒绝我。小徐显然也不知道这个真相,他愣在一旁一时有
些不知所措。我抢先冲进急诊室,小成也看见了我,她显然也听见了医生叫我们。她的
目光平静,柔和,还有---期待。我走到小成身边,抓住她的手,对她轻声说:我知
道了。你该早点告诉我。我和你一起,我们一起面对,好吗?说着把她的手贴在了自己
脸上,小成的眼泪刷地下来了。这时候,小徐进来正好看见。护士着急地说,她不能激
动的,你们出去!出去!
我终于得到了小成的认可。她后来对我说,其实她开始是觉得我失恋了,很可怜,愿意
帮我多做点事,后来就慢慢喜欢上了我;可是后来她发现我在防她,很让她伤心;她拒
绝我一方面是因为这个---女孩子的报复心,她也有;另一方面,她早知道自己的
病,也不想拖累我。最后她在病床边倚着我,泪光闪闪的对我说:"你知道吗?一个女
孩子在外面,很多时候真累啊。我晕倒的时候,心里想,真去了,别的没什么,就是好
后悔啊,我应该和你爱一场啊。我是不是好自私?我真的是不甘心。"我什么也没说,
只是把她紧紧的搂在怀里。
小成还告诉我,其实她是出生就有这个病了,他父母亲一直在做生意,家里人其实不缺
钱。家里人让她读书读到高中,考大学已经考上了,但是担心远没人照顾,死活不让她
去上。小成很不愿意自己成为家里人的累赘,自己跑了出来打工,决心自己养活自己。
她以前就和家里人耳濡目染,所以对生意很在行。正好我把她招了进来。她说,小徐一
直对她很好,她加班小徐一直陪着,可是她知道他们不可能。
没几天小成坚持要出院,她说住了多少次院了,还是家里舒服---不就是静养吗。我
们搬在了一起。这是我的坚持要求,我说我一定要照顾好你。小徐要辞职,我没说什么
同意了。最后,我和他一起吃了顿晚饭。他深情黯然的说,没想到她有那么严重的病,
我就是愣了一会,哎,你先跑进去了。后来喝了点酒,他又说,你比我有钱,她当然选
你。我一般抓住他,对他说,你胡说,小成不是那种看重钱的人。至于钱,小徐,好好
努力,你还年轻,你也会有钱,也许比我还有钱。到那时也许你会明白小成。
3年以后的一个偶然的机会,我又在闵行体育公园附近见到了小徐。不过他早已今昔非
比,他对我说,他一直没忘我的话,也自己憋了一口气。辞职了以后,他先是自己骑三
轮车从七宝蔬菜批发市场批蔬菜到小区卖,后来自己租了个摊位,后来卖猪肉,再后来
自己买了一辆二手嘉宝,自己去江苏进猪肉卖。3年以后,刚刚挣了50万,在附近买了
一套80平方的房子。他最后说,还是要谢谢你。我想起身边和网上很多朋友不停地抱怨
房价飞涨,抱怨没有工作,抱怨辛苦赚不到钱,抱怨这里抱怨那里---其实他们连一
个高中都没有读完的小徐都不如!
23,乏术
我看到有人在怀疑我的经历的真实性,想要向他们争辩,想想又算了。每个人的生活轨
迹不同,想法不同,就是向他们证实了又能怎么样呢?能改变生活现状吗?我还是写下
去,就算是经历了这么多的总结吧。但愿有朋友在看的时候能够获得共鸣,获得激励,
产生力量,进而改变你们自己的人生。如果不信,也没什么,因为我们生活不同,而且
都要继续。
小成和我的关系定了以后,我们会经常长时间的交谈。她读书很多,尤其喜欢古诗词。
我们很多事情都谈的津津有味,可以就一个事件谈上几个小时。现在我在想,谈恋爱谈
恋爱,说谈是有道理的吧。她有时候会从梦里醒来,一声不响地看我半天。我问她为什
么,她说她高兴,睡不着。有时候她会流泪,说是想家了。我要和她家联系,她又不
让。我不再让她查店,每天带着她看看就行了。可是她闲不住,对我说,我要闲着就在
家耗着,跑这来干嘛?我也没办法。本想生意就这么发展下去,我们也不会担心未来钱
的事。可是这时候生意忽然被一件没有料到的事情影响了。
过了几个月,我们这里要听说要修路了,要打通和大马路接上。因为我们有2家店面是
属于临时房,肯定会被拆掉。临时商业房拆掉,市政会补一点钱,但是对我们来说并不
划算,因为附近的铺面已经涨价了,客户也熟悉了。我考虑了很久,也没有什么办法。
为了不让小成知道担心,我并没有在她面前表现的压力很大。
同时我也暗暗留心小成的病情,我觉得好像越来越严重了。我也到处查找她的这个病的
原因,治疗方式和注意事项。大夫给我说的是对的,这个病一般不能结婚,更禁止生
育,因为她的心脏会受不了。一般在婴儿时期手术解决,成人后手术成功率很低。目前
除了静养,不能劳累,尤其不能感冒。除此之外,还没有比较好的治疗办法。我觉得这
个障碍比我以前碰到的任何一个都艰巨、困难,有一种一筹莫展的感觉。
24,诀别
也许很多朋友的感情经历比我复杂的多,但是一直以来我都认为命运待我不公,一直以
来我也在问上苍:为什么不给我一段长一点的真爱,比如说一辈子。直到不久以前,我
才解开这个心结(请看后续章节)。看到这一节的标题,朋友们想必已经知到了结果。
原谅我写得这么慢,我不能平静自己的心情。
小成自己也有感觉。她有时候会搂住我说,真不想把你交给另一个人,我让她别胡说。
有时候她会说,我走了以后,你一定要找一个好的。你看,她在不停的矛盾。我觉得她
真是普通人,一个平凡女孩的心思和想法她都有,正是这些让我觉得她一个让我无比怜
惜的人。她的心跳越来越快,也不规则了。我不再让她跟我去店里,还找了一个阿姨照
顾她。有一天,她对我说,不行,我帮你赚了那么多钱,从来没有做过主妇的感觉,你
要把钱都交出来,我要管钱,做做主妇。我笑着把存折、密码、身份证、房产证都交给
了她。有什么不能呢?这些我失去了相信还可以赚回。
到了秋天,天气冷了,小成好象更不好了。她脸色不好,心跳过快,我还是把她送进了
医院。我觉得一定要把她的家人叫来。她这次没有拒绝,但是她说她先和家里人打个电
话,不让我听。电话不到2天,她的父母亲就赶来了。不知道她和她的父母说了什么,
她的父母见了我特别的亲,一个劲在我面前流泪,还说这孩子脾气太倔了。我们3个人
的时候,她的父母亲会象我自己的父母一样,不停的让我注意身体,多吃一些,多穿一
些。
我真的不愿意回忆那个日子,12月21号,她住进医院2个月半月的时候。其实她走的时
候,心脏已经很大了。医生说,这样的病一般是心脏忽停,突然死亡,象她这样的比较
少,她也属于比较严重的了。我留着泪在她床前听到最后的一句话是:难受,胸好闷。
谢谢。
25,礼物
我送走了小成。我不知道怎样描述当时我的悲痛欲绝的心情。因为我不能在她的父母面
前表现出来,否则她的母亲根本没有办法控制自己的感情。想起前面有个朋友问我,如
果用我的全部身家去换取真爱,我会怎样选择?我想我在这里可以回答了:朋友,如果
你的一只手要离你而去,代价是你的全部身家,你会怎样选择?如果你有犹豫,那答案
很简单---这不是你的真爱。我感觉到我的心已经是不再完整的了。
在她的遗物中我发现了以前给她的存折,但是已经少了一个房产证---我的别墅的房产
证。当然,我还发现了一封信。其实我早就知道她在写遗书,只是不忍在内心承认罢
了。她这么聪明的女孩,一定会想到这些的。
遗书里说:对不起,我不能和你一起忙下去了。别太难过,以后就是你要经常想我。遇
见你很好,我本来害怕就这样糊里糊涂地走了,现在知道我的生命比我以前的想法好多
了,我不那么遗憾了。就是会带给你和我父母痛苦……
……
你要坚强,要挺住,你还要走很长的路吧。我把你的别墅给卖了---这是你给另外一
个女孩买的,是吗?我做主了,你会怪我吗?因为我们的熟食店不是长久之计,你也不
会甘心一辈子卖肉,是吧?我去定了一个商铺,首付就用别墅卖的钱,剩下的2个店,
卖了吧,还有拆迁的店,拿到了补偿,和我们(我用了我们,你愿意吗?)以前的钱,
不少了吧,别乱花。然后到我家去,和我爸交流一下,也许你能够找到机会。他会帮你
的,我和他们说过了。你应该有更大的事业。
如果我这样替你做主,真的赚了钱,就算是我留给你的礼物吧。亏了,就当我以前为你
忙碌卖命,我应得的钱我又拿走了。呵呵,我不想要钱,只想你过的快乐一些,就看你
自己的努力了……
26,转型
小成的事情之后,我的生意大不如前了,可能也和我的心情有关。2003年1月底,我卖
掉了我的2个店。又过了3个月,我拿到了市政补助的资金。加上我手里的钱,一共109.
5万。我的别墅,小成以8500左右的单价卖出,用80万左右做首付买了一个300平方左右
的商铺,但是要4个月以后交房。这个地方的商铺,近一年后我在2003年12月时以每平
方每天7元出租,一个月能收回6万多块钱,扣除还款我每月还能剩余4万块钱。这已经
基本相当于我以前4个店一个月的盈利了,今年年初,我让评估师估了一下价格,已经
到19000左右每平方了。小成,你又一次让我见识了你的聪慧。
想到以前小成每天那么开心,那么充实的样子,现在我明白了:其实她一直处在生命随
时会停止的阴影下,所以她的生活态度反而那么豁达,开朗,而又忙碌充实。这才是生
命本来应该有的态度。我也应该这样生活。而且我不能仅靠收租为生。我又开始想着新
的事业了,我决定如小成所说,到她家里去一次。我和她父母联系了一下,他们很热
情,让我随时都可以去。我虽然比以前多了100万现金,可是我心里面一点也不轻松,
因为这一次我面临着从饮食业到其他行业的转型,其实也是一种重头再来。
2003年4月,我去了小成家。小成的父母在做皮革生意,他们一直在为国外的汽车和家
具提供定制的真皮座椅和包垫。真没想到,他们生意做得很大。而且他们那里家家是作
坊,户户是工厂,浙江真是让我见识了民营经济的力量。和她的父母交流之后,我才知
道自己这100万现金根本不够做这个方面。她家人对我说,可以提供资金帮助,我也可
以和他们合股做,我愿意留下来也行。但是我拒绝了。我有种感觉,这不是我要找的那
个行业,另外我还是愿意自己奋斗。她的父母认了我为干儿子,我走的那一天,在她家
吃饭,我喝醉了。她的母亲又哭了。
27,尝试
我最终没有接受小成父母的美意,不知道远在天国的小成知道我的这个选择后是满意还
是不满意。我想她是理解我的吧,我一直那么独立,一直以为自己的事情要自己做。虽
然没有做她父母的那个行业,但是她父母临走时说的一句话倒是让我思索很久。她父母
说,现在他们的产品慢慢地国内的汽车厂家也开始要货了,这是不是说明这个大行业内
还是有机会的呢?
2003年4月底我回到上海以后,又以70万总价70%贷款买了一套商品房,毕竟自己也要住
的,付房租不如付贷款了。然后我就主要在考虑下一步的努力方向了。饮食业我是不再
考虑了,可能有点伤心的原因在里面吧。我希望有个崭新的事业,崭新的我。IT业我也
认为不好,原因是我看到这几年身边的年轻人开公司有80%选择IT业,竞争太激烈了,
而且经营状况并不理想,我估计还要至少几年淘汰这个行业才会正常。电子加工,服务
业什么的,我都考虑过。想来想去比较了很长时间,我决定尝试代理国外品牌做汽车机
油和高档润滑油。我觉得小成的父母给我的启示还是有几分道理的:国内的汽车市场现
在才刚刚开始,还会有10几年的高速发展期,这个行业就像10几年前做计算机行业一
样,是值得我投入的。
我的习惯是:想法一经决定,行动决不迟疑。5月初,我找好了办公地点,开始招人;5
月底,办公家具和人员进场;6月份,我拿到了营业执照和发票。我开始熟悉这个市场
的渠道、客户、产品。那个时候我几乎每天都去吴中路,每天都上网查资料,每天都向
国外写电子邮件询问产品性能,报价,索要样品等等信息。到了8月份的时候,我公司
终于定下了一个全权代理和4项一级代理的产品。然后我开始在江浙一带的城市里不停
地奔波,寻找、拜访代理和零售商,以及和他们洽谈。我是这样认为,以我目前的实力
在上海的这个行业里撕开口子太难了,我应该先从周边入手。开始我是租车开,后来10
月份的时候,我自己贷款卖了一辆马自达-福美来。我的现金我认为还是应该留着公司
发展用。
虽然2003年下半年我做的很辛苦,但是到了年底一算,我的这个公司并没有赚钱,反而
亏损了12万-平均每个月2万的亏损。可能有的朋友会问,汽车行业2003年是最热
了,你怎么还亏了呢?这个亏损我却一点也没有心痛和意外,一方面是因为我已经经历
了很多生意上的风雨,更重要的是因为这都在我的预想之内。
做生意有很多种,有的人是以长时间积累的技巧、经验、关系和渠道挣钱-这是以时间
换空间;有的人是一招鲜、吃遍天-这是垄断或是以技术制胜;还有的人是用钱换取技
巧、经验、关系和生意流通的渠道,这是以空间换时间-我就是这么做的。我刚进入
这个行业,经验、关系、客户基础和渠道都不行,一进来就赚钱是不太可能的。但是更
不能害怕花钱而停止脚步,生意一定要走出去,开发的流程不能停止。这半年来,虽然
我出货不多,远远不能养活公司,但是我一是组织了团队,熟悉了团队,锻炼了团队的
力量;二是建立了销售渠道,江浙一带我们开发了70多家下级代理,我们让他们试用先
打开市场,还要熟悉竞争对手,客户公关等等,这一切都进展顺利。2003年汽车销售是
很热,但是我认为我们这一块属于汽车保养和维修类会有一个滞后期。我们2003年底的
业绩已经大大好于8月份。对于即将到来的2004年,我胸有成竹。
28,归宿
公司的实际经营果然是按照我的预想发展。2004年1月份,我们的销量获得了突破,我
们已经有些许的盈利了。2月份因为过节,生意比1月份下降5%。3月份获得30%的大幅增
长,这样我们已经净盈利4万了。我加大了激励力度,我的团队志气如虹,一个个宣称
今年底要比3月份的销量翻番。我知道,这是有可能的。因为我们前期搭就的平台完全
可以承载这个销量----70~100个有规模的下级代理,每个月每个代理的销量达到
8000~10000元并非难事。
我的公司里招了几个上海的女孩子。原来我很少和上海女孩打交道---其实我就很少
和女孩打交道,阿芸和小成而已。但是通过和我们公司的上海女孩沟通,合作,熟悉
之后,她们让我以前对上海女孩的看法大为改观-----我以前是心里有偏见了。她们
初看打扮时髦而又干练,说话快而利落,脑子清楚毫不拖泥带水,对价格非常敏感,你
以为她们很势力很在乎金钱。是的,对普通人陌生人是的。可是交往久了,我觉得她们
工作尽职尽责----加班从来都是自己要求的,自己的事自己做完;做事很有责任心
----对公司的财物,以及用水用电完全像对自己家的一样;很重感情----我们公司
有不只一个女孩为了男朋友、同学而付出了金钱,时间,甚至家庭的埋怨。也许,外人
对他们的误解只是因为大家做事情的方法不同罢了,毕竟,人更重要的是心灵和思想。
可是我的感情生活依旧空白。我觉得现在的我不可能再发展一段恋情---在我的心里
小成一刻也不曾离开。每天我都会看小成给我的那封信,那信其实写得很长。看了之后
我总觉得她离我不远,我的心里也觉得很温暖。小成,你的心灵和思维脱离了肉体的羁
绊,应该飞的更快更远了吧。这段时间由于小成的离去,我每天努力的工作回家之后,
会觉得失去了归宿感。有时候我会忽然想,我来这里干什么?哪里是我的归宿呢?我努
力奋斗,努力挣钱,挣了很多钱又怎么样呢?
这是我第一次考虑这个问题----金钱对我意味着什么。以前生存和事业的压力,以及
一个接着一个的打击和磨砺让我始终无暇顾及这个具有终极意义的话题。是啊,虽然我
现在还不是很有钱,但是我有钱了以后怎么办?以前我国传统的精神也只讲过:君子爱
财,取之有道。可是如果取到了有怎么样呢?原谅我的陋学,我没有看到这方面的阐
述。很多中国人有钱了以后,生活奢靡、大讲排场、意志低落、胡乱花钱,很多还丧失
了生活的动力,多少人在贫贱时坚持的修身养性,成仁取义,在富贵来临时烟消云散。
更有很少的人捐钱给慈善事业和救助他人,我想这一切也和我们的传统文化有关。我坚
决不要这样的生活。可是为什么西方人有那么多有钱人,给慈善事业捐钱呢?而且他们
一些穷人也有给慈善事业捐钱的习惯呢?
一个偶然的机会我看到了《圣经-马太福音》,里面的阐述让我如梦初醒。那里面
说,虽然富人因为上帝给予的机会和能力获得了财富,但是那财富并不是富人的,只是
上帝因为看到财富由于在富人手中增值而让那些富人代为保管的,一旦有需要,应该把
财富还给所有人。这就是我所要寻找的原因。我于是如饥似渴地每天看《圣经》,那里
面的文字让我的安静,安定,安心。在这里面,我找到了和我心灵合拍的仁爱心、慈悲
心、谦卑心和使命心。我进一步了解到我以前毫无信仰,或者以自己为信仰时的无知、
自以为是、狂妄自大和故步自封。朋友,也许你和我信仰不同,请不要在这里争执孰是
孰非。也许只有每个人只有经历苦苦思索和重重磨砺,才能接近你所认为的真理。最终
我在这里找到了归宿,也找到了问题的答案。
我在徐家汇教堂受了洗,成为主的信徒。受洗之后,我每周都要去教堂坐坐。我知道,
小成一定会成为天使,主一定也会指引我。我以前认为的爱是我前进的动力,这爱字,
今天我才体会到更广泛更宏大的意义。它已经成为了我的使命。
29,疑问
2005年的1月,我在徐家汇附近,漕溪路旁的那块大空地上停好车出来的时候,忽然意
外地发现了芸和她的男朋友----现在应该已经是老公了吧,因为他们手里还抱着一个2
岁大小的孩子。他们显然也发现了我,但是显然双方都有点错谔。我先打招呼,笑着
说,这是你们的孩子啊?真漂亮!我们之间的气氛一下融洽了。交谈中我得知,他们
2001年底结婚,2002年底有了这个可爱的女儿。他们的生活不错,买车买房也是2004年
的事。我衷心的祝福他们。他们问我的情况,我也告诉了他们,我也得到了他们的祝
福。我们还约好下次一起吃饭。
我曾经以为,如果我再见到芸,我绝对不会保持平静,甚至我不知道怎么见她。可是我
做到了,我不仅做到了心情平静,还做到了如常交流,更做到了绝对真心地祝福他们,
理解他们。经历了那么多,看到了那么多,失去了那么多,我也得到了那么多。穿破围
墙,我的心灵获得了更大的空间和放飞的舞台。
我公司的生意到了2004年的9月份已经能够保持每个月70万左右的营业额,12万左右的
利润了。10,11,12三个月我们又在原来的基础上开拓了30家左右的零售店面,基本能
够实现每个月15万左右的利润。到年底的时候,我手上的资金加上商铺出租收入,公司
原有资金和盈利,已经达到了180万。我的一个专门做公司投资的朋友说,像我们这样
的小公司,只要我能保持公司连续盈利36个月,那么公司的价值一般就是公司60个月的
利润总和。他笑着说,算算你的公司也值四五百万了吧,如果你保持现在的盈利状况。
我的心中不相信"保持现状"这句话,以前的经历屡屡说明这一点:没有人能够保持现
状。只有改变现状,才能保持不败。可是我经过粗粗一算之后,心里产生了疑问。因为
我要提升目前的经营水准,势必重新打造一个更大更快速的经营平台,管理要上新台
阶,还要进行更严密更系统的市场推广计划---我叫它"重生"计划。这个计划我粗粗
算了一下,要求我投入300万左右的资金。我陷入了思考:这样的计划风险是否太大?
如果失败,我会失去现有的所有公司盈利和手上资金,还有我部分的不动产。那么我应
该保持现状,这也没什么不好,这样总有其他竞争者先做,然后我再静观事变吗?如果
我实施"重生"计划,完成后如果发挥100%的效果,我9~10个月可以收回成本,公司随
后还有应该有更大的发展。如果发挥70%的效果,我15~18个月可以收回成本。如果发挥
50%以下的效果,那就是失败。
可是奋斗这种东西已经进入了我的血液,变成了我的基因。我实在不能忍受自己什么也
不做而失去这个成为自己领域内前几位的机会。为主,为小成,为我,为我所有的朋友
和家人,还有我的员工,我决定放手一博。我把买的商品房(现在已经涨价了,达到
150万了)和汽车做了二次抵押,贷了120万资金,这样我手上的资金已经有300万了。
2004年12月21日夜里11点,我终于完成了17万字的详细的"重生计划"的策划报告。我
没有忘了这一天,我一定要在这一天完成这报告。
半夜里我开车从主干道下来,到了以前我和小成三号店的旧址----她是在这里爱上
我,我也是在这里爱上她的。这里一切已经今昔非比,再也见不到路边的临时房了,全
部都是宽宽的马路和人行道,谁也不会再关心这里曾经发生的事情了。我停下车,下车
来靠着车点燃一只烟。看着天边半满的月亮,我清清楚楚地看见了小成妍妍的笑脸。我
也笑了,只是脸上已经流满了泪水。
朋友们,我在上海的奋斗岁月-----结束了吗?不,我心里知道,一切才刚刚开始!
30,经验(大结局)
下面是我自己的感悟和我的经验,权做参考:
1,人生就是投资和收益的人生。如果你有钱,就投入金钱;如果你没有金钱,而有经
验和能力,就投入经验和能力;如果你既没有金钱,也没有经验和能力,但是你有热
情、勤奋和努力,那就投入热情、勤奋和努力。如果你既没有金钱,也没有经验和能
力,连热情、勤奋和努力也没有,那就别想这些了。
2,比赚钱更重要的是找到你自己的赚钱动力;
3,比金钱重要的是时间,比时间重要的是时机,比时机重要的是你要抓住时机的决
心,动力和准备!
4,别好高骛远,机会一般都在你看不起眼的角落里藏着;
5,舍得投入;
6,决定一下,行动要快;
7,永远尽可能准备好资源,随时准备抓住机会,要快!
8,待人以诚,对人以善。有时候,机会是别人给的;
9,给别人的比别人期待的多一些(这是我抄李嘉诚的,我很喜欢);
10,赚钱有个普遍的法则:多做,快做,动脑筋变着花样做,就是别跟着别人一样
做。
11,合理规划有钱以后的日子,会让你走的更远;
12,有信仰,有原则,有爱心。
select * from mytable where to_char(install_date,'YYYYMMDD')
> '20050101'
select * from mytable where install_date >
to_date('20050101','yyyymmdd');
取得当前日期是本月的第几周
SQL> select to_char(sysdate,'YYYYMMDD W HH24:MI:SS') from
dual;
TO_CHAR(SYSDATE,'YY
-------------------
20030327 4
18:16:09
SQL> select to_char(sysdate,'W') from dual;
T
-
4
№2:取得当前日期是一个星期中的第几天,注意星期日是第一天
SQL> select sysdate,to_char(sysdate,'D') from dual;
SYSDATE T
--------- -
27-MAR-03 5
类似:
select to_char(sysdate,'yyyy') from dual; --年
select
to_char(sysdate,'Q' from dual; --季
select
to_char(sysdate,'mm') from dual; --月
select
to_char(sysdate,'dd') from dual; --日
ddd 年中的第几天
WW
年中的第几个星期
W 该月中第几个星期
DAY 周中的星期几
D 今天对映的NUMBER
'1','星期日', '2','星期一',
'3','星期二', '4','星期三',
'5','星期四', '6','星期五', '7','星期六'
hh 小时(12)
hh24 小时(24)
Mi 分
ss 秒
№3:取当前日期是星期几中文显示:
SQL> select to_char(sysdate,'day') from dual;
TO_CHAR(SYSDATE,'DAY')
----------------------
星期四
№4:如果一个表在一个date类型的字段上面建立了索引,如何使用
alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'
№5: 得到当前的日期
select sysdate from dual;
№6: 得到当天凌晨0点0分0秒的日期
select trunc(sysdate) from dual;
-- 得到这天的最后一秒
select trunc(sysdate) + 0.99999 from dual;
-- 得到小时的具体数值
select trunc(sysdate) + 1/24 from dual;
select trunc(sysdate) + 7/24 from dual;
№7:得到明天凌晨0点0分0秒的日期
select trunc(sysdate+1) from dual;
select trunc(sysdate)+1 from dual;
№8: 本月一日的日期
select trunc(sysdate,'mm') from dual;
№9:得到下月一日的日期
select trunc(add_months(sysdate,1),'mm') from dual;
№10:返回当前月的最后一天?
select last_day(sysdate) from dual;
select
last_day(trunc(sysdate)) from dual;
select trunc(last_day(sysdate)) from
dual;
select trunc(add_months(sysdate,1),'mm') - 1 from dual;
№11: 得到一年的每一天
select trunc(sysdate,'yyyy')+ rn -1
date0
from
(select rownum rn from all_objects
where rownum<366);
№12:今天是今年的第N天
SELECT TO_CHAR(SYSDATE,'DDD') FROM DUAL;
№13:如何在给现有的日期加上2年
select add_months(sysdate,24) from dual;
№14:判断某一日子所在年分是否为润年
select
decode(to_char(last_day(trunc(sysdate,'y')+31),'dd'),'29','闰年','平年') from
dual;
№15:判断两年后是否为润年
select
decode(to_char(last_day(trunc(add_months(sysdate,24),'y')+31),'dd'),'29','闰年','平年')
from dual;
№16:得到日期的季度
select ceil(to_number(to_char(sysdate,'mm'))/3) from dual;
select to_char(sysdate, 'Q') from dual;
获取本周一,周日的日期
select trunc(sysdate,'d')+1,trunc(sysdate,'d')+7 from dual;
1.
概述
最近论坛很多人提的问题都与行列转换有关系,所以我对行列转换的相关知识做了一个总结,希望对大家有所帮助,同时有何错疏,恳请大家指出,我也是在写作过程中学习,算是一起和大家学习吧!
行列转换包括以下六种情况:
1)
列转行
2)
行转列
3)
多列转换成字符串
4)
多行转换成字符串
5)
字符串转换成多列
6)
字符串转换成多行
下面分别进行举例介绍。
首先声明一点,有些例子需要如下10g及以后才有的知识:
A.
掌握model子句
B.
正则表达式
C.
加强的层次查询
讨论的适用范围只包括8i,9i,10g及以后版本。
2.
列转行
CREATE TABLE t_col_row(
ID INT,
c1 VARCHAR2(10),
c2 VARCHAR2(10),
c3 VARCHAR2(10));
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');
INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);
INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');
INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');
INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');
INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);
COMMIT;
SELECT * FROM t_col_row;
2.1
UNION ALL
适用范围:8i,9i,10g及以后版本
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
若空行不需要转换,只需加一个where条件,
WHERE COLUMN IS NOT NULL 即可。
2.2
MODEL
适用范围:10g及以后
SELECT id, cn, cv FROM t_col_row
MODEL
RETURN UPDATED ROWS
PARTITION BY (ID)
DIMENSION BY (0 AS n)
MEASURES ('xx' AS cn,'yyy' AS cv,c1,c2,c3)
RULES UPSERT ALL
(
cn[1] = 'c1',
cn[2] = 'c2',
cn[3] = 'c3',
cv[1] = c1[0],
cv[2] = c2[0],
cv[3] = c3[0]
)
ORDER BY ID,cn;
2.3
COLLECTION
适用范围:8i,9i,10g及以后版本
要创建一个对象和一个集合:
CREATE TYPE cv_pair AS OBJECT(cn VARCHAR2(10),cv VARCHAR2(10));
CREATE TYPE cv_varr AS VARRAY(8) OF cv_pair;
SELECT id, t.cn AS cn, t.cv AS cv
FROM t_col_row,
TABLE(cv_varr(cv_pair('c1', t_col_row.c1),
cv_pair('c2', t_col_row.c2),
cv_pair('c3', t_col_row.c3))) t
ORDER BY 1, 2;
3.
行转列
CREATE TABLE t_row_col AS
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
SELECT * FROM t_row_col ORDER BY 1,2;
3.1
AGGREGATE FUNCTION
适用范围:8i,9i,10g及以后版本
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1,
MAX(decode(cn, 'c2', cv, NULL)) AS c2,
MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col
GROUP BY id
ORDER BY 1;
MAX聚集函数也可以用sum、min、avg等其他聚集函数替代。
被指定的转置列只能有一列,但固定的列可以有多列,请看下面的例子:
SELECT mgr, deptno, empno, ename FROM emp ORDER BY 1, 2;
SELECT mgr,
deptno,
MAX(decode(empno, '7788', ename, NULL)) "7788",
MAX(decode(empno, '7902', ename, NULL)) "7902",
MAX(decode(empno, '7844', ename, NULL)) "7844",
MAX(decode(empno, '7521', ename, NULL)) "7521",
MAX(decode(empno, '7900', ename, NULL)) "7900",
MAX(decode(empno, '7499', ename, NULL)) "7499",
MAX(decode(empno, '7654', ename, NULL)) "7654"
FROM emp
WHERE mgr IN (7566, 7698)
AND deptno IN (20, 30)
GROUP BY mgr, deptno
ORDER BY 1, 2;
这里转置列为empno,固定列为mgr,deptno。
还有一种行转列的方式,就是相同组中的行值变为单个列值,但转置的行值不变为列名:
ID CN_1 CV_1 CN_2 CV_2 CN_3 CV_3
1 c1 v11 c2 v21 c3 v31
2 c1 v12 c2 v22 c3
3 c1 v13 c2 c3 v33
4 c1 c2 v24 c3 v34
5 c1 v15 c2 c3
6 c1 c2 c3 v35
7 c1 c2 c3
这种情况可以用分析函数实现:
SELECT id,
MAX(decode(rn, 1, cn, NULL)) cn_1,
MAX(decode(rn, 1, cv, NULL)) cv_1,
MAX(decode(rn, 2, cn, NULL)) cn_2,
MAX(decode(rn, 2, cv, NULL)) cv_2,
MAX(decode(rn, 3, cn, NULL)) cn_3,
MAX(decode(rn, 3, cv, NULL)) cv_3
FROM (SELECT id,
cn,
cv,
row_number() over(PARTITION BY id ORDER BY cn, cv) rn
FROM t_row_col)
GROUP BY ID;
3.2
PL/SQL
适用范围:8i,9i,10g及以后版本
这种对于行值不固定的情况可以使用。
下面是我写的一个包,包中
p_rows_column_real用于前述的第一种不限定列的转换;
p_rows_column用于前述的第二种不限定列的转换。
CREATE OR REPLACE PACKAGE pkg_dynamic_rows_column AS
TYPE refc IS REF CURSOR;
PROCEDURE p_print_sql(p_txt VARCHAR2);
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
END;
/
CREATE OR REPLACE PACKAGE BODY pkg_dynamic_rows_column AS
PROCEDURE p_print_sql(p_txt VARCHAR2) IS
v_len INT;
BEGIN
v_len := length(p_txt);
FOR i IN 1 .. v_len / 250 + 1 LOOP
dbms_output.put_line(substrb(p_txt, (i - 1) * 250 + 1, 250));
END LOOP;
END;
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2 IS
v_first INT;
v_last INT;
BEGIN
IF p_seq < 1 THEN
RETURN NULL;
END IF;
IF p_seq = 1 THEN
IF instr(p_str, p_division, 1, p_seq) = 0 THEN
RETURN p_str;
ELSE
RETURN substr(p_str, 1, instr(p_str, p_division, 1) - 1);
END IF;
ELSE
v_first := instr(p_str, p_division, 1, p_seq - 1);
v_last := instr(p_str, p_division, 1, p_seq);
IF (v_last = 0) THEN
IF (v_first > 0) THEN
RETURN substr(p_str, v_first + 1);
ELSE
RETURN NULL;
END IF;
ELSE
RETURN substr(p_str, v_first + 1, v_last - v_first - 1);
END IF;
END IF;
END f_split_str;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_pivot_cnt INT;
v_max_cols INT;
v_partition VARCHAR2(4000);
v_partition1 VARCHAR2(4000);
v_partition2 VARCHAR2(4000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) + 1;
v_pivot_cnt := length(p_pivot_cols) -
length(REPLACE(p_pivot_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
FOR j IN 1 .. v_pivot_cnt LOOP
v_pivot(j) := f_split_str(p_pivot_cols, ',', j);
END LOOP;
v_sql := 'select max(count(*)) from ' || p_table || ' group by ';
FOR i IN 1 .. v_keep.LAST LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
EXECUTE IMMEDIATE v_sql
INTO v_max_cols;
v_partition := 'select ';
FOR x IN 1 .. v_keep.COUNT LOOP
v_partition1 := v_partition1 || v_keep(x) || ',';
END LOOP;
FOR y IN 1 .. v_pivot.COUNT LOOP
v_partition2 := v_partition2 || v_pivot(y) || ',';
END LOOP;
v_partition1 := rtrim(v_partition1, ',');
v_partition2 := rtrim(v_partition2, ',');
v_partition := v_partition || v_partition1 || ',' || v_partition2 ||
', row_number() over (partition by ' || v_partition1 ||
' order by ' || v_partition2 || ') rn from ' || p_table;
v_partition := rtrim(v_partition, ',');
v_sql := 'select ';
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
FOR i IN 1 .. v_max_cols LOOP
FOR j IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(rn,' || i || ',' || v_pivot(j) ||
',null))' || v_pivot(j) || '_' || i || ',';
END LOOP;
END LOOP;
IF p_where IS NOT NULL THEN
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition || ' ' ||
p_where || ') group by ';
ELSE
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition ||
') group by ';
END IF;
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_group_by VARCHAR2(2000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
v_sql := 'select ' || 'cast(' || p_pivot_col ||
' as varchar2(200)) as ' || p_pivot_col || ' from ' || p_table ||
' group by ' || p_pivot_col;
EXECUTE IMMEDIATE v_sql BULK COLLECT
INTO v_pivot;
FOR i IN 1 .. v_keep.COUNT LOOP
v_group_by := v_group_by || v_keep(i) || ',';
END LOOP;
v_group_by := rtrim(v_group_by, ',');
v_sql := 'select ' || v_group_by || ',';
FOR x IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(' || p_pivot_col || ',' || chr(39) ||
v_pivot(x) || chr(39) || ',' || p_pivot_val ||
',null)) as "' || v_pivot(x) || '",';
END LOOP;
v_sql := rtrim(v_sql, ',');
IF p_where IS NOT NULL THEN
v_sql := v_sql || ' from ' || p_table || p_where || ' group by ' ||
v_group_by;
ELSE
v_sql := v_sql || ' from ' || p_table || ' group by ' || v_group_by;
END IF;
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
END;
/
4.
多列转换成字符串
CREATE TABLE t_col_str AS
SELECT * FROM t_col_row;
这个比较简单,用||或concat函数可以实现:
SELECT concat('a','b') FROM dual;
4.1
|| OR CONCAT
适用范围:8i,9i,10g及以后版本
SELECT * FROM t_col_str;
SELECT ID,c1||','||c2||','||c3 AS c123
FROM t_col_str;
5.
多行转换成字符串
CREATE TABLE t_row_str(
ID INT,
col VARCHAR2(10));
INSERT INTO t_row_str VALUES(1,'a');
INSERT INTO t_row_str VALUES(1,'b');
INSERT INTO t_row_str VALUES(1,'c');
INSERT INTO t_row_str VALUES(2,'a');
INSERT INTO t_row_str VALUES(2,'d');
INSERT INTO t_row_str VALUES(2,'e');
INSERT INTO t_row_str VALUES(3,'c');
COMMIT;
SELECT * FROM t_row_str;
5.1
MAX + DECODE
适用范围:8i,9i,10g及以后版本
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
5.2
ROW_NUMBER + LEAD
适用范围:8i,9i,10g及以后版本
SELECT id, str
FROM (SELECT id,
row_number() over(PARTITION BY id ORDER BY col) AS rn,
col || lead(',' || col, 1) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 2) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 3) over(PARTITION BY id ORDER BY col) AS str
FROM t_row_str)
WHERE rn = 1
ORDER BY 1;
5.3
MODEL
适用范围:10g及以后版本
SELECT id, substr(str, 2) str FROM t_row_str
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY(row_number() over(PARTITION BY ID ORDER BY col) AS rn)
MEASURES (CAST(col AS VARCHAR2(20)) AS str)
RULES UPSERT
ITERATE(3) UNTIL( presentv(str[iteration_number+2],1,0)=0)
(str[0] = str[0] || ',' || str[iteration_number+1])
ORDER BY 1;
5.4
SYS_CONNECT_BY_PATH
适用范围:8i,9i,10g及以后版本
SELECT t.id id, MAX(substr(sys_connect_by_path(t.col, ','), 2)) str
FROM (SELECT id, col, row_number() over(PARTITION BY id ORDER BY col) rn
FROM t_row_str) t
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1
AND id = PRIOR id
GROUP BY t.id;
适用范围:10g及以后版本
SELECT t.id id, substr(sys_connect_by_path(t.col, ','), 2) str
FROM (SELECT id, col, row_number() over(PARTITION BY id ORDER BY col) rn
FROM t_row_str) t
WHERE connect_by_isleaf = 1
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1
AND id = PRIOR id;
5.5
WMSYS.WM_CONCAT
适用范围:10g及以后版本
这个函数预定义按','分隔字符串,若要用其他符号分隔可以用,replace将','替换。
SELECT id, REPLACE(wmsys.wm_concat(col), ',', '/') str
FROM t_row_str
GROUP BY id;
6.
字符串转换成多列
其实际上就是一个字符串拆分的问题。
CREATE TABLE t_str_col AS
SELECT ID,c1||','||c2||','||c3 AS c123
FROM t_col_str;
SELECT * FROM t_str_col;
6.1
SUBSTR + INSTR
适用范围:8i,9i,10g及以后版本
SELECT id,
c123,
substr(c123, 1, instr(c123 || ',', ',', 1, 1) - 1) c1,
substr(c123,
instr(c123 || ',', ',', 1, 1) + 1,
instr(c123 || ',', ',', 1, 2) - instr(c123 || ',', ',', 1, 1) - 1) c2,
substr(c123,
instr(c123 || ',', ',', 1, 2) + 1,
instr(c123 || ',', ',', 1, 3) - instr(c123 || ',', ',', 1, 2) - 1) c3
FROM t_str_col
ORDER BY 1;
6.2
REGEXP_SUBSTR
适用范围:10g及以后版本
SELECT id,
c123,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 1), ',') AS c1,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 2), ',') AS c2,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 3), ',') AS c3
FROM t_str_col
ORDER BY 1;
7.
字符串转换成多行
CREATE TABLE t_str_row AS
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
SELECT * FROM t_str_row;
7.1
UNION ALL
适用范围:8i,9i,10g及以后版本
SELECT id, 1 AS p, substr(str, 1, instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
2 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
3 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
ORDER BY 1, 2;
适用范围:10g及以后版本
SELECT id, 1 AS p, rtrim(regexp_substr(str||',', '.*?' || ',', 1, 1), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id, 2 AS p, rtrim(regexp_substr(str||',', '.*?' || ',', 1, 2), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id, 3 AS p, rtrim(regexp_substr(str||',', '.*?' || ',',1,3), ',') AS cv
FROM t_str_row
ORDER BY 1, 2;
7.2
VARRAY
适用范围:8i,9i,10g及以后版本
要创建一个可变数组:
CREATE OR REPLACE TYPE ins_seq_type IS VARRAY(8) OF NUMBER;
SELECT * FROM TABLE(ins_seq_type(1, 2, 3, 4, 5));
SELECT t.id,
c.column_value AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.column_value) + 1,
instr(t.ca, ',', 1, c.column_value + 1) -
(instr(t.ca, ',', 1, c.column_value) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t
INNER JOIN TABLE(ins_seq_type(1, 2, 3)) c ON c.column_value <=
t.cnt
ORDER BY 1, 2;
7.3
SEQUENCE SERIES
这类方法主要是要产生一个连续的整数列,产生连续整数列的方法有很多,主要有:
CONNECT BY,ROWNUM+all_objects,CUBE等。
适用范围:8i,9i,10g及以后版本
SELECT t.id,
c.lv AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.lv) + 1,
instr(t.ca, ',', 1, c.lv + 1) -
(instr(t.ca, ',', 1, c.lv) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 5) c
WHERE c.lv <= t.cnt
ORDER BY 1, 2;
SELECT t.id,
c.rn AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.rn) + 1,
instr(t.ca, ',', 1, c.rn + 1) -
(instr(t.ca, ',', 1, c.rn) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT rownum rn FROM all_objects WHERE rownum <= 5) c
WHERE c.rn <= t.cnt
ORDER BY 1, 2;
SELECT t.id,
c.cb AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.cb) + 1,
instr(t.ca, ',', 1, c.cb + 1) -
(instr(t.ca, ',', 1, c.cb) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT rownum cb FROM (SELECT 1 FROM dual GROUP BY CUBE(1, 2))) c
WHERE c.cb <= t.cnt
ORDER BY 1, 2;
适用范围:10g及以后版本
SELECT t.id,
c.lv AS p,
rtrim(regexp_substr(t.str || ',', '.*?' || ',', 1, c.lv), ',') AS cv
FROM (SELECT id,
str,
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL)) AS cnt
FROM t_str_row) t
INNER JOIN (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 5) c ON c.lv <= t.cnt
ORDER BY 1, 2;
7.4
HIERARCHICAL + DBMS_RANDOM
适用范围:10g及以后版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = PRIOR id
AND PRIOR dbms_random.VALUE IS NOT NULL
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1, 2;
7.5
HIERARCHICAL + CONNECT_BY_ROOT
适用范围:10g及以后版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = connect_by_root id
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1, 2;
7.6
MODEL
适用范围:10g及以后版本
SELECT id, p, cv FROM t_str_row
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY( 0 AS p)
MEASURES( str||',' AS cv)
RULES UPSERT
(cv
[ FOR p
FROM 1 TO length(regexp_replace(cv[0],'[^'||','||']',null))
select 'select * from '||wl.table1||' where rowid= ''' || wl.aa||''';' from
(select o.object_name table1 ,dbms_rowid.rowid_create(1,s.row_wait_obj#,s.row_wait_file#,s.row_wait_block#,s.row_wait_row#) aa
from v$session s , dba_waiters w , v$locked_object l , dba_objects o
where w.waiting_session=s.SID
and w.mode_held='Exclusive'
and w.waiting_session=l.SESSION_ID
and l.OBJECT_ID=o.object_id ) wl;
最近在做一个工资核算的系统,所有的运算全部在前台进行,因此用了的是JS来做。
做完以后,经手工核算,发现一个奇怪的问题。就是JS算出来的结果跟用计算器算出来的结果有差距。
想了很久,也没有想出问题出在哪里。
问题这样的:
37.5*5.5=206.08 (JS算出来是这样的一个结果,我四舍五入取两位小数)
我先怀疑是四舍五入的问题,就直接用JS算了一个结果为:206.08499999999998
怎么会这样,两个只有一位小数的数字相乘,怎么可能多出这么小数点出来。
我Google了一下,发现原来这是JavaScript浮点运算的一个bug。
比如:7*0.8 JavaScript算出来就是:5.6000000000000005
网上找到了一些解决办法,就是重新写了一些浮点运算的函数。
下面就把这些方法摘录下来,以供遇到同样问题的朋友参考:
程序代码
//除法函数,用来得到精确的除法结果
//说明:javascript的除法结果会有误差,在两个浮点数相除的时候会比较明显。这个函数返回较为精确的除法结果。
//调用:accDiv(arg1,arg2)
//返回值:arg1除以arg2的精确结果
function accDiv(arg1,arg2){
var t1=0,t2=0,r1,r2;
try{t1=arg1.toString().split(".")[1].length}catch(e){}
try{t2=arg2.toString().split(".")[1].length}catch(e){}
with(Math){
r1=Number(arg1.toString().replace(".",""))
r2=Number(arg2.toString().replace(".",""))
return (r1/r2)*pow(10,t2-t1);
}
}
//给Number类型增加一个div方法,调用起来更加方便。
Number.prototype.div = function (arg){
return accDiv(this, arg);
}
//乘法函数,用来得到精确的乘法结果
//说明:javascript的乘法结果会有误差,在两个浮点数相乘的时候会比较明显。这个函数返回较为精确的乘法结果。
//调用:accMul(arg1,arg2)
//返回值:arg1乘以arg2的精确结果
function accMul(arg1,arg2)
{
var m=0,s1=arg1.toString(),s2=arg2.toString();
try{m+=s1.split(".")[1].length}catch(e){}
try{m+=s2.split(".")[1].length}catch(e){}
return Number(s1.replace(".",""))*Number(s2.replace(".",""))/Math.pow(10,m)
}
//给Number类型增加一个mul方法,调用起来更加方便。
Number.prototype.mul = function (arg){
return accMul(arg, this);
}
//加法函数,用来得到精确的加法结果
//说明:javascript的加法结果会有误差,在两个浮点数相加的时候会比较明显。这个函数返回较为精确的加法结果。
//调用:accAdd(arg1,arg2)
//返回值:arg1加上arg2的精确结果
function accAdd(arg1,arg2){
var r1,r2,m;
try{r1=arg1.toString().split(".")[1].length}catch(e){r1=0}
try{r2=arg2.toString().split(".")[1].length}catch(e){r2=0}
m=Math.pow(10,Math.max(r1,r2))
return (arg1*m+arg2*m)/m
}
//给Number类型增加一个add方法,调用起来更加方便。
Number.prototype.add = function (arg){
return accAdd(arg,this);
}
在你要用的地方包含这些函数,然后调用它来计算就可以了。
比如你要计算:7*0.8 ,则改成 (7).mul(8)
其它运算类似,就可以得到比较精确的结果。
mssql Server中的日期与时间函数
1. 当前系统日期、时间
select getdate()
2. dateadd 在向指定日期加上一段时间的基础上,返回新的 datetime 值
例如:向日期加上2天
select dateadd(day,2,'2004-10-15') --返回:2004-10-17 00:00:00.000
3. datediff 返回跨两个指定日期的日期和时间边界数。
select datediff(day,'2004-09-01','2004-09-18') --返回:17
4. datepart 返回代表指定日期的指定日期部分的整数。
SELECT DATEPART(month, '2004-10-15') --返回 10
5. datename 返回代表指定日期的指定日期部分的字符串
SELECT datename(weekday, '2004-10-15') --返回:星期五
6. day(), month(),year() --可以与datepart对照一下
select 当前日期=convert(varchar(10),getdate(),120)
,当前时间=convert(varchar(8),getdate(),114)
select datename(dw,'2004-10-15')
select 本年第多少周=datename(week,'2004-10-15')
,今天是周几=datename(weekday,'2004-10-15')
函数 参数/功能
GetDate( ) 返回系统目前的日期与时间
DateDiff (interval,date1,date2) 以interval 指定的方式,返回date2 与date1两个日期之间的差值 date2-date1
DateAdd (interval,number,date) 以interval指定的方式,加上number之后的日期
DatePart (interval,date) 返回日期date中,interval指定部分所对应的整数值
DateName (interval,date) 返回日期date中,interval指定部分所对应的字符串名称
参数 interval的设定值如下:
值 缩 写(Sql Server) (Access 和 ASP) 说明
Year Yy yyyy 年 1753 ~ 9999
Quarter Qq q 季 1 ~ 4
Month Mm m 月1 ~ 12
Day of year Dy y 一年的日数,一年中的第几日 1-366
Day Dd d 日,1-31
Weekday Dw w 一周的日数,一周中的第几日 1-7
Week Wk ww 周,一年中的第几周 0 ~ 51
Hour Hh h 时0 ~ 23
Minute Mi n 分钟0 ~ 59
Second Ss s 秒 0 ~ 59
Millisecond Ms - 毫秒 0 ~ 999
access 和 asp 中用date()和now()取得系统日期时间;其中DateDiff,DateAdd,DatePart也同是能用于Access和asp中,这些函数的用法也类似
举例:
1.GetDate() 用于sql server :select GetDate()
2.DateDiff('s','2005-07-20','2005-7-25 22:56:32')返回值为 514592 秒
DateDiff('d','2005-07-20','2005-7-25 22:56:32')返回值为 5 天
3.DatePart('w','2005-7-25 22:56:32')返回值为 2 即星期一(周日为1,周六为7)
DatePart('d','2005-7-25 22:56:32')返回值为 25即25号
DatePart('y','2005-7-25 22:56:32')返回值为 206即这一年中第206天
DatePart('yyyy','2005-7-25 22:56:32')返回值为 2005即2005年
1、一个年轻人,如果三年的时间里,没有任何想法,他这一生,就基本这个样子,没有多大改变了。
2、成功者就是胆识加魄力,曾经在火车上听人谈起过温州人的成功,说了这么三个字,“胆子大”。这其实,就是胆识,而拿得起,放得下,就是魄力。
3、这个世界,有这么一小撮的人,打开报纸,是他们的消息,打开电视,是他们的消息,街头巷尾,议论的是他们的消息,仿佛世界是为他们准备的,他们能够呼风唤雨,无所不能。你的目标,应该是努力成为这一小撮人。
4、如果,你真的爱你的爸妈,爱你的女朋友,就好好的去奋斗,去拼搏吧,这样,你才有能力,有经济条件,有自由时间,去陪他们,去好好爱他们。
5、这个社会,是快鱼吃慢鱼,而不是慢鱼吃快鱼。
6、这个社会,是赢家通吃,输者一无所有,社会,永远都是只以成败论英雄。
7、如果你问周围朋友词语,如果十个人,九个人说不知道,那么,这是一个机遇,如果十个人,就个人都知道了,就是一个行业。
8、任何一个行业,一个市场,都是先来的有肉吃,后来的汤都没的喝。
9、这个世界上,一流的人才,可以把三流项目做成二流或更好,但是,三流人才,会把一流项目,做的还不如三流。
10、趁着年轻,多出去走走看看。读万卷书,不如行万里路,行万里路,不如阅人无数。
11、与人交往的时候,多听少说。这就是,上帝为什么给我们一个嘴巴两个耳朵的原因。
12、日常工作之外应当多注意自身修养的提高及自身技能的培训。随着计算机技术的广泛应用,为了不被社会所淘汰,就必须加强计算机技术的培训与提高。无论是企业培训还是个人培训都是不可或缺的,我个人推荐一个很好的培训机构:中科院计算所培训中心。
13、不要装大,对于装大的人,最好的办法就是,捡块砖头,悄悄跟上去,一下子从背后放倒他。
14、不要随便说脏话,这会让别人觉得你没涵养,不大愿意和你交往。即使交往,也是敷衍。因为他内心认定你素质很差。
15、想要抽烟的时候,先问下周围的人可不可以,要学会尊重别人。少在女生面前耍酷抽烟,你不知道,其实她们内心很反感。
16、买衣服的时候,要自己去挑,不要让家人给你买,虽然你第一第二次买的都不怎么样,可是,你会慢慢有眼光的。
17、要想进步,就只有吸取教训,成功的经验都是歪曲的,成功了,想怎么说都可以,失败者没有发言权,可是,你可以通过他的事例反思,总结。教训,不仅要从自己身上吸取,还要从别人身上吸取。
18、学习,学习,再学习,有事没事,去书店看看书,关于管理,金融,营销,人际交往,未来趋势等这些,你能获得很多。这个社会竞争太激烈了,你不学习,就会被淘汰。中国2008底,有一百多万大学生找不到工作。竞争这么激烈,所以,一定要认识一点,大学毕业了,不是学习结束了,而是学习刚刚开始。还有,我个人推荐一个很好的视频节目,《谁来一起午餐》。
19、如果你不是歌手,不是画家,也不是玩行为艺术的,那么,请在平时注意你的衣着。现在这个社会,衣着能表现出你属于哪一个群体,哪一个圈子。
20、记住,平均每天看电视超过三个小时以上的,一定都是那些月收入不超过两千元的,如果你想要月收入超过两千,请不要把时间浪费在电视上。同样的道理,那些平均每天玩网络游戏或聊天超过三个小时以上的,也都是那些月收入不超过两千的。
21、因为穷人很多,并且穷人没有钱,所以,他们才会在网络上聊天抱怨,消磨时间。你有见过哪个企业老总或主管经理有事没事经常在QQ群里闲聊的?
22、无论你以后是不是从事销售部门,都看一下关于营销的书籍。因为,生活中,你处处都是在向别人推销展示你自己。
23、平时的时候,多和你的朋友沟通交流一下,不要等到需要朋友的帮助时,才想到要和他们联系,到了社会,你才会知道,能够认识一个真正的朋友,有多难?
24、如果你想知道自己将来的年收入如何。找你最经常来往的六个朋友,把他们的年收入加起来,除以六,就差不多是你的了。这个例子,可以充分的说明一点,物以类聚。
25、不要听信身边人的话,大一不谈恋爱,好的女孩子就被别人都挑走了。想想,刚上大一就耐不住寂寞,受不住诱惑,而去谈恋爱的女孩子,值得自己去追吗?大学里,可以有一场爱情,可是,不要固执地认为,刚上大一,就必须要谈恋爱。
26、记得,要做最后出牌的人,出让别人觉得出其不意的牌,在他们以为你要输掉的时候,这样,你才能赢得牌局。
27、关于爱情,有这么一句话,没有面包,怎么跳舞?无论什么时候,你决定去好好爱一个人的时候,一定要考虑给她你能给予的最好的物质生活。
28、给自己定一个五年的目标,然后,把它分解成一年一年,半年半年的,三个月的,一个月的。这样,你才能找到自己的目标和方向。
29、无论什么时候,记住尊严这两个字,做人是要有尊严,有原则,有底线的。否则,没有人会尊重你。
30、如果,我只能送你一句忠告,那就是,这个世界上没有免费的午餐,永远不要走捷径!
我身边我认为的好男人基本上都是单身,很多大都还没谈过恋爱。另外我熟悉的人中,很多人品好,工作优秀,被大家公认为的好男人的妻子却很一般。经过和朋友的交流和自己的分析,我得出了中国好男人娶不到好女人的几点原因。
首先我要说一下我眼中的好男人具有的一些品质:待人好,诚信,重情义;有进取心,有胸怀,事业心强;负责任,重承诺,有爱心。
现在我发现正是因为他们具有这些品质而导致了他们娶不到好女人,我也体会到了大家常说的一些话的深刻道理。
“男人不坏,女人不爱”,以前我想不通这句话的道理,现在发现现实的确是这样的。女人大都想找个好男人,然而她们往往找到的是会讨好她们的男人。好男人往往不会讨好女人,他们太实在,太负责任,太重承诺,他们不会随便地对他们喜欢的女人表示爱意。而坏男人则不同,他们“既有色心,又有色胆”,为了得到他们心目中的女人,他们可以伪装,伪装成好男人,百般讨好女人,甜言蜜语,花前月下,酒吧电影院……
我在网上看到一个网友的话:“经过这几场恋爱,我只能这样说了,不“色”不知道,一“色”准会让你得到你想得到的一切。”我们不妨比较一下刘德华和陈冠希就明白了他说的话很有道理。坏男人的伪装是有一定时间限度的,等他们得到女人后,他们便会慢慢地显露出真实的面目。如果有一天他们又有了新的目标,或着把女人玩腻了,便会把她们甩了。而女人这时只能流着泪说:“世上的男人没一个好东西!”
美女往往和野兽在一起”,大部分的年轻人谈恋爱时总是会在乎一下容貌的,这一点无可厚非,因为追求美是人的本性。现在我发现美女和野兽在一起是“最安全”的。美女就像一只羔羊,如果她的男友也像一只善良的羔羊,或者老实的黄牛,即使他们结了婚,美女也有可能被很多“色狼”盯着,这些“色狼”一旦惦记上美女,便会使用各种办法伪装自己,最终可能把自己伪装成一只“披着羊皮的狼”,美女最终往往成为了他们的“猎物”。而狼的猎物往往是最安全的,因为很少有其它的动物敢去抢狼的东西。
其实总结一下上面的分析,可以得出一条结论:中国的好男人娶不到好女人,最重要的原因是他们在爱情面前不够主动。
不主动主要有以下几个原因:
第一,他们想的总是太多,他们可能觉得自己现在没有恋爱的资本,不能在物质上满足女孩;
第二,他们太负责任,太重承诺,所以他们不会随便地对一个女孩说“我爱你”,因为他们觉得爱是一种责任,一种承诺,有时候他们对女孩的爱意可能会让女孩觉察不出来。
第三,好男人总是会有女人喜欢的,这会让他们有优越感,而好女人也会有更多的男人去追,她们也会更有优越感,两种有优越感的人往往因为这种优越感而不肯“屈服”于对方,男的不会很主动,女的更不会主动。
第四,
好男人也许以前主动地追求过自己心目中的女人,但那个女人却没有对男人表示出爱意,这让好男人心里会产生失落感,他们可能会因此对爱情很失望,所以以后即使心目中的好女人再次出现的时候他们也不会像以前那样主动了。
当然也有好男人和好女人走在了一起,但是这样的非常少,至少我发现是这样的。
当美和丑相遇的时候,受欺骗的首先是美,因为它叫美,但丑最终会暴露出它丑陋的嘴脸,因为它叫丑;当善与恶相遇的时候,受伤害的首先是善,因为它叫善,但恶最终会显现出它恶的本性,因为它叫恶。所以美与丑,善与恶有时候经常在一起,但不会长久;好女人也经常和坏男人在一起,他们的关系也不会长久。
世间存在着太多的不完美,太多的不尽人意,而我们往往抱着追求完美的态度,可到后来却往往被现实打击的心灰意冷。
好男人如果想娶到好女人,还是要主动一些,因为你们毕竟是个男人;好女人如果想嫁个好男人,还是要擦亮眼睛,因为你们往往被你们看到的表象所欺骗。
之所以要在男人前加中国二字,是因为其它国家的好男人是不是和中国的好男人一样娶不到好女人,我不清楚,不了解就没有发言权
男人不坏,女人不爱。这句话在现实中非常准确。虽然很多女人会矢口否认这一点甚至对此嗤之以鼻。但实际上,坏男人的求爱方式的确比好男人的方式有效得多。
坏男人的特点是:脸皮厚,大胆,善于撒谎,不太受道德约束,花招诡计多,一旦有机会“日”后再说,不负责任。而这些特点恰恰击中了女人的软肋。
假设硬件条件相似的好男人和坏男人遇到同一个女人,坏男人的杀伤力要强出N倍。
首先,好男人的出手概率要小得多,因为好男人开始追求之前就要考虑负责任的问题,所以不完全中意的不会去追,条件不成熟的目前不能追,对方已有男友的不能追,未来前景不看好(例:在不同城市)的不能追,限制极多。而坏男人反正也没打算负责任,只要对方有点姿色,或是触手可得,一概先追了再说。
第二,好男人诚实,没钱没关系就实话实说,对女方的缺点也坦诚相告,往往让女人很失望。而坏男人随便编两个故事就可以显得自己实力超群;对女人花言巧语又很容易让她们心花怒放,认为找到了知己伯乐。在这个浮躁的社会背景下,好男人多年的辛苦努力换来的成果多半还不如一个坏男人用3分钟时间编出来的故事更能让女人心动。
第三,好男人总想着尊重对方,不会找机会调戏非礼。而坏男人通过调笑,酒精,跳舞等方式随时刺激女人的荷尔蒙,一有机会就把对方占为己有。女人的快感一旦被调动起来,反而很快会爱上这个男人。坏男人一次嘿咻的效果往往超过好男人默默的多次付出。有些傻女人认为男人上了她就是爱上了她;更傻的女人认为一旦被男人上了,她就必须爱上这个男人。女人的本性中隐含着逆来顺受的基因。
第四,好男人真心付出,把双方的感情看得很重,心态容易不平衡,为一些小事和女友争吵。而坏男人心想:反正我不过是做一场游戏,找点刺激罢了,哄哄她得了,生个什么气啊?心态更平和,反而显得成熟个性好。
第五,坏男人的约会经验通常比好男人多得多。参照第一条,坏男人一有机会就出手,即使不成功也积累了经验,逐渐了解了女人的心理。女人大多不理智,有种种莫名其妙完全不合逻辑的偏见(比如:一个鞋上有污点的男人一定***不住)。坏男人通过大量的实战经验在约会时把这些表面工作做得很好,而好男人却懵然不知,被唰了都不明白为什么,还以为是自己实力不够。
第六,双方发生争执时,好男人自尊心,原则性强,不会轻易迁就对方,往往为些小事谁都不让步,最后只能分手。而坏男人脸皮厚,认个错比喝稀饭都容易,往往轻而易举就能哄得对方回心转意;当然,那是在他还没有玩腻的时候,否则即使女方让步他也能找出借口分手,有时候女人反而会一再让步,彻底沦为坏男人的玩物。
第七,好男人原则性强,循规蹈矩,往往显得乏味。而坏男人一心追求刺激,变化多端,常常给女人以新鲜感。不知不觉中,女人就被坏男人迷惑住,控制住了。
第八,如果女人认识到双方不合适,提出主动分手。好男人只会采取光明正大的手段,实际效果有限;而坏男人可以不择手段,死缠滥打,威逼利诱。女人的惰性强,情感多变,又容易向强势低头,常常摆脱不了坏男人的下三滥手段。
大部分女人虚荣心、自尊心很强,喜欢甜言蜜语,对生活的期望值不现实
1、 染料渍的去除
染料弄到了衣物上,可先用稀醋酸擦拭,然后再用双氧水漂洗。也可以用松节油刷洗后,再用汽油擦拭。最后都要用清水漂净。
2、红墨水渍的去除
新染上的红墨水渍可先水洗,然后放入温热的皂液中浸泡,待色渍去掉后,再用清水漂亮洗干净。污染时间较长的红墨水渍,先用 水洗后,再用10%的酒精水溶液擦拭去除。
3、蓝墨水渍的去除
新沾污的蓝墨水渍可用肥皂,洗衣粉等洗涤剂搓洗去除。污染时间较长的蓝墨水渍,可用草酸溶液浸泡后搓洗,然后再用洗涤剂清洗 去除。
4、红药水渍的去除
衣物上染上红药水,先用温热的洗涤剂溶液洗后,接着分别用草酸和高锰酸钾溶液顺次浸泡、搓洗,最后再用草酸溶液脱色,再进行水洗,红药水渍即除。
5、紫药水渍的去除
紫药水中的主要成分是从龙胆草中提取出来的,所以紫药水又叫龙胆紫,是常用的外用药剂,沾在衣物上,青紫颜色,非常显眼。
去除方法是:把衣物用水浸泡后,稍加拧干,用棉签蘸上20%的草酸水溶液由里向外涂抹污渍。稍浸片刻后即可用清水反复漂洗、揉搓, 污渍便可去除。 另外,对一些沾染上紫药水的白色织物,也可先用溶剂酒精除去浮色,再用氧化剂次氯酸钠或双氧水溶液进行漂白处理,经水洗后就 能达到预想的效果。
6、黄药水渍的去除
浅色的尤其是白色的衣物洒上了黄药水,要除黄药水渍是比较麻烦的,首先用醋酸滴在污染处,如见效不大,可放在酒精中洗涤。
如果仍不能彻底除掉,就要依据衣物的质料纤维性质选用适合的氧化剂,进行去渍或漂白。
7、碘酒渍的去除
衣物染上碘酒,可以选用酒精或碘化钾来去除。在100毫升的水中要加5~7克碘化钾,用碘化钾溶液去渍后的衣物一定要用清水漂洗干净。 也可把染上碘的衣物放入热水或15%~20%浓度的大苏打(硫代硫酸钠)热溶液中浸泡2小时,使污渍彻底溶解而脱离衣物。 还可以用水淀粉浆糊涂在污渍之处,当污处出现黑色时,再用洗涤剂洗涤,最后漂洗干净即可。
8、药膏渍的去除
先用溶剂汽油或酒精刷洗后,再用四氯化碳或苯刷洗,最后再用优质洗涤剂清洗干净。
也可以先用三氯钾烷刷洗,再用洗涤剂洗涤,最后用清水漂净。 还可以把加热后的食用面碱撒在污处,再加些温水进行揉搓,即可除去。
9、新染上的酒精或啤酒渍
可用清水洗涤去除。时间较长的酒渍,可先用水洗,再用2%的氨水和硼水混合液搓洗去除。去渍后的衣物必须要用清水漂洗干净。
10、铁锈渍的去除
衣物上的铁锈渍,可用1%温热的草酸水溶液浸泡后,再用清水漂洗干净。 也可用15%的醋酸水溶液擦拭污渍,或者将沾污部分浸泡在该溶液里,次日再用清水漂洗干净。 也可用10%的柠檬酸水溶液或10%的草酸水溶液将污处润湿,然后浸泡在浓盐水中,次日再用清水洗涤漂净。 白色纯棉或棉混纺织物沾上了铁锈,可取一粒草酸放在污渍处,用温水润湿,轻轻揉搓,然后再用清水漂洗干净。在操作中,为了防止 草酸腐蚀织物,操作动作要迅速。 也可用鲜柠檬汁滴在锈渍上,用手揉搓,反复几次,直到锈渍除去再经洗涤液洗涤后用清水漂净利。
11、铜绿锈的去除
铜绿有毒,衣物被污染上时要小心处理。其渍可用20%~30%的碘化钾水溶液或10%的醋酸水溶液热焖,并要立刻用温热的食盐水擦拭,最后用清水洗净。
12、硝酸银渍的去除
硝酸银在医药及感光材料中应用广泛。这种物质接触到皮肤或织物上,呈黑色斑点污渍。
除掉方法如下: 用氯化铵和氯化汞各2份,溶液在15份水中制成混合溶液。用棉团蘸上这种混合液擦拭污渍处,污渍即可除去。
还可以将沾有硝酸银污渍的衣物浸入微热的10%大苏打(硫打硫酸钠)的水溶液中,然后用洗涤剂水洗后,再用清水漂洗干净。
13、高锰酸钾渍的去除
高锰酸钾俗称灰锰氧,人们常用它来做外科手术器具和水果消毒剂。当衣物上沾染了高锰酸钾,可维生素C药片蘸上水,涂在污渍处轻轻 擦拭,边蘸水边擦,一会就能将污渍去除。
手上沾染高锰酸钾污渍,也要用此方法去除。
也可以用柠檬酸或2%的草酸水溶液浸泡,通过化学反应,污渍即可除去。
这种方法适用于各种质料和颜色的衣物去渍。
14、酱油渍的去除
衣物上沾染了酱油渍可用冷水搓洗,再用洗涤剂洗涤。
被酱油污染时间较长的衣物,要在洗涤液中加入适量的氨水( 4 份洗涤溶液中加 入 1 份氨水)进行洗涤。
丝、毛织物可用10%的柠檬酸水溶液进行洗涤。
最后都要用清水漂净。
15、黄泥渍的去除
衣物染上了黄泥渍,待黄泥渍晾干后,用手搓或用刷子刷去浮土,然后用生姜涂擦污渍处,最后用清水漂洗,黄泥渍即可去除。
16、尿渍的去除
儿童尿巾上的新尿渍可用清水洗净。干透的旧尿渍需用洗涤剂清洗。如有痕迹,自然纤维丝绸织物,可用氨水和醋酸1:1的混合液洗涤, 最后用清水漂净。
17、衣物上的汗渍
可用25%浓度的氨气水水溶液洗涤。也可以先将衣物放在3%浓度的盐水里浸泡几分钟,用清水漂洗净,再用洗涤剂洗涤。
丝、毛及其混纺织物上的汗渍,可用柠檬酸洗除。最后都要用清水漂洗。 清除汗渍霉斑时,新渍可先用软刷刷去表面霉斑,再用酒精擦除。
MySQL 字符串函数大全
对于针对字符串位置的操作,第一个位置被标记为1。
ASCII(str)
返回字符串str的最左面字符的ASCII代码值。如果str是空字符串,返回0。如果str是NULL,返回NULL。
mysql> select ASCII('2');
-> 50
mysql> select ASCII(2);
-> 50
mysql> select ASCII('dx');
-> 100
也可参见ORD()函数。
ORD(str)
如果字符串str最左面字符是一个多字节字符,通过以格式((first byte ASCII code)*256+(second byte ASCII code))[*256+third byte ASCII code...]返回字符的ASCII代码值来返回多字节字符代码。如果最左面的字符不是一个多字节字符。返回与ASCII()函数返回的相同值。
mysql> select ORD('2');
-> 50
CONV(N,from_base,to_base)
在不同的数字基之间变换数字。返回数字N的字符串数字,从from_base基变换为to_base基,如果任何参数是NULL,返回NULL。参数N解释为一个整数,但是可以指定为一个整数或一个字符串。最小基是2且最大的基是36。如果to_base是一个负数,N被认为是一个有符号数,否则,N被当作无符号数。 CONV以64位点精度工作。
mysql> select CONV("a",16,2);
-> '1010'
mysql> select CONV("6E",18,8);
-> '172'
mysql> select CONV(-17,10,-18);
-> '-H'
mysql> select CONV(10+"10"+'10'+0xa,10,10);
-> '40'
BIN(N)
返回二进制值N的一个字符串表示,在此N是一个长整数(BIGINT)数字,这等价于CONV(N,10,2)。如果N是NULL,返回NULL。
mysql> select BIN(12);
-> '1100'
OCT(N)
返回八进制值N的一个字符串的表示,在此N是一个长整型数字,这等价于CONV(N,10,8)。如果N是NULL,返回NULL。
mysql> select OCT(12);
-> '14'
HEX(N)
返回十六进制值N一个字符串的表示,在此N是一个长整型(BIGINT)数字,这等价于CONV(N,10,16)。如果N是NULL,返回NULL。
mysql> select HEX(255);
-> 'FF'
CHAR(N,...)
CHAR()将参数解释为整数并且返回由这些整数的ASCII代码字符组成的一个字符串。NULL值被跳过。
mysql> select CHAR(77,121,83,81,'76');
-> 'MySQL'
mysql> select CHAR(77,77.3,'77.3');
-> 'MMM'
CONCAT(str1,str2,...)
返回来自于参数连结的字符串。如果任何参数是NULL,返回NULL。可以有超过2个的参数。一个数字参数被变换为等价的字符串形式。
mysql> select CONCAT('My', 'S', 'QL');
-> 'MySQL'
mysql> select CONCAT('My', NULL, 'QL');
-> NULL
mysql> select CONCAT(14.3);
-> '14.3'
LENGTH(str)
OCTET_LENGTH(str)
CHAR_LENGTH(str)
CHARACTER_LENGTH(str)
返回字符串str的长度。
mysql> select LENGTH('text');
-> 4
mysql> select OCTET_LENGTH('text');
-> 4
注意,对于多字节字符,其CHAR_LENGTH()仅计算一次。
LOCATE(substr,str)
POSITION(substr IN str)
返回子串substr在字符串str第一个出现的位置,如果substr不是在str里面,返回0.
mysql> select LOCATE('bar', 'foobarbar');
-> 4
mysql> select LOCATE('xbar', 'foobar');
-> 0
该函数是多字节可靠的。
LOCATE(substr,str,pos)
返回子串substr在字符串str第一个出现的位置,从位置pos开始。如果substr不是在str里面,返回0。
mysql> select LOCATE('bar', 'foobarbar',5);
-> 7
这函数是多字节可靠的。
INSTR(str,substr)
返回子串substr在字符串str中的第一个出现的位置。这与有2个参数形式的LOCATE()相同,除了参数被颠倒。
mysql> select INSTR('foobarbar', 'bar');
-> 4
mysql> select INSTR('xbar', 'foobar');
-> 0
这函数是多字节可靠的。
LPAD(str,len,padstr)
返回字符串str,左面用字符串padstr填补直到str是len个字符长。
mysql> select LPAD('hi',4,'??');
-> '??hi'
RPAD(str,len,padstr)
返回字符串str,右面用字符串padstr填补直到str是len个字符长。
mysql> select RPAD('hi',5,'?');
-> 'hi???'
LEFT(str,len)
返回字符串str的最左面len个字符。
mysql> select LEFT('foobarbar', 5);
-> 'fooba'
该函数是多字节可靠的。
RIGHT(str,len)
返回字符串str的最右面len个字符。
mysql> select RIGHT('foobarbar', 4);
-> 'rbar'
该函数是多字节可靠的。
SUBSTRING(str,pos,len)
SUBSTRING(str FROM pos FOR len)
MID(str,pos,len)
从字符串str返回一个len个字符的子串,从位置pos开始。使用FROM的变种形式是ANSI SQL92语法。
mysql> select SUBSTRING('Quadratically',5,6);
-> 'ratica'
该函数是多字节可靠的。
SUBSTRING(str,pos)
SUBSTRING(str FROM pos)
从字符串str的起始位置pos返回一个子串。
mysql> select SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> select SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
该函数是多字节可靠的。
SUBSTRING_INDEX(str,delim,count)
返回从字符串str的第count个出现的分隔符delim之后的子串。如果count是正数,返回最后的分隔符到左边(从左边数) 的所有字符。如果count是负数,返回最后的分隔符到右边的所有字符(从右边数)。
mysql> select SUBSTRING_INDEX('www.mysql.com', '.', 2);
-> 'www.mysql'
mysql> select SUBSTRING_INDEX('www.mysql.com', '.', -2);
-> 'mysql.com'
该函数对多字节是可靠的。
LTRIM(str)
返回删除了其前置空格字符的字符串str。
mysql> select LTRIM(' barbar');
-> 'barbar'
RTRIM(str)
返回删除了其拖后空格字符的字符串str。
mysql> select RTRIM('barbar ');
-> 'barbar'
该函数对多字节是可靠的。
TRIM([[BOTH | LEA
DING | TRAILING] [remstr] FROM] str)
返回字符串str,其所有remstr前缀或后缀被删除了。如果没有修饰符BOTH、LEADING或TRAILING给出,BOTH被假定。如果remstr没被指定,空格被删除。
mysql> select TRIM(' bar ');
-> 'bar'
mysql> select TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx'
mysql> select TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar'
mysql> select TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx'
该函数对多字节是可靠的。
SOUNDEX(str)
返回str的一个同音字符串。听起来“大致相同”的2个字符串应该有相同的同音字符串。一个“标准”的同音字符串长是4个字符,但是SOUNDEX()函数返回一个任意长的字符串。你可以在结果上使用SUBSTRING()得到一个“标准”的同音串。所有非数字字母字符在给定的字符串中被忽略。所有在A-Z之外的字符国际字母被当作元音。
mysql> select SOUNDEX('Hello');
-> 'H400'
mysql> select SOUNDEX('Quadratically');
-> 'Q36324'
SPACE(N)
返回由N个空格字符组成的一个字符串。
mysql> select SPACE(6);
-> ' '
REPLACE(str,from_str,to_str)
返回字符串str,其字符串from_str的所有出现由字符串to_str代替。
mysql> select REPLACE('www.mysql.com', 'w', 'Ww');
-> 'WwWwWw.mysql.com'
该函数对多字节是可靠的。
REPEAT(str,count)
返回由重复countTimes次的字符串str组成的一个字符串。如果count <= 0,返回一个空字符串。如果str或count是NULL,返回NULL。
mysql> select REPEAT('MySQL', 3);
-> 'MySQLMySQLMySQL'
REVERSE(str)
返回颠倒字符顺序的字符串str。
mysql> select REVERSE('abc');
-> 'cba'
该函数对多字节可靠的。
INSERT(str,pos,len,newstr)
返回字符串str,在位置pos起始的子串且len个字符长得子串由字符串newstr代替。
mysql> select INSERT('Quadratic', 3, 4, 'What');
-> 'QuWhattic'
该函数对多字节是可靠的。
ELT(N,str1,str2,str3,...)
如果N= 1,返回str1,如果N= 2,返回str2,等等。如果N小于1或大于参数个数,返回NULL。ELT()是FIELD()反运算。
mysql> select ELT(1, 'ej', 'Heja', 'hej', 'foo');
-> 'ej'
mysql> select ELT(4, 'ej', 'Heja', 'hej', 'foo');
-> 'foo'
FIELD(str,str1,str2,str3,...)
返回str在str1, str2, str3, ...清单的索引。如果str没找到,返回0。FIELD()是ELT()反运算。
mysql> select FIELD('ej', 'Hej', 'ej', 'Heja', 'hej', 'foo');
-> 2
mysql> select FIELD('fo', 'Hej', 'ej', 'Heja', 'hej', 'foo');
-> 0
FIND_IN_SET(str,strlist)
如果字符串str在由N子串组成的表strlist之中,返回一个1到N的值。一个字符串表是被“,”分隔的子串组成的一个字符串。如果第一个参数是一个常数字符串并且第二个参数是一种类型为SET的列,FIND_IN_SET()函数被优化而使用位运算!如果str不是在strlist里面或如果 strlist是空字符串,返回0。如果任何一个参数是NULL,返回NULL。如果第一个参数包含一个“,”,该函数将工作不正常。
mysql> SELECT FIND_IN_SET('b','a,b,c,d');
-> 2
MAKE_SET(bits,str1,str2,...)
返回一个集合 (包含由“,”字符分隔的子串组成的一个字符串),由相应的位在bits集合中的的字符串组成。str1对应于位0,str2对应位1,等等。在str1, str2, ...中的NULL串不添加到结果中。
mysql> SELECT MAKE_SET(1,'a','b','c');
-> 'a'
mysql> SELECT MAKE_SET(1 | 4,'hello','nice','world');
-> 'hello,world'
mysql> SELECT MAKE_SET(0,'a','b','c');
-> ''
EXPORT_SET(bits,on,off,[separator,[number_of_bits]])
返回一个字符串,在这里对于在“bits”中设定每一位,你得到一个“on”字符串,并且对于每个复位(reset)的位,你得到一个“off”字符串。每个字符串用“separator”分隔(缺省“,”),并且只有“bits”的“number_of_bits” (缺省64)位被使用。
mysql> select EXPORT_SET(5,'Y','N',',',4)
-> Y,N,Y,N
LCASE(str)
LOWER(str)
返回字符串str,根据当前字符集映射(缺省是ISO-8859-1 Latin1)把所有的字符改变成小写。该函数对多字节是可靠的。
mysql> select LCASE('QUADRATICALLY');
-> 'quadratically'
UCASE(str)
UPPER(str)
返回字符串str,根据当前字符集映射(缺省是ISO-8859-1 Latin1)把所有的字符改变成大写。该函数对多字节是可靠的。
mysql> select UCASE('Hej');
-> 'HEJ'
该函数对多字节是可靠的。
LOAD_FILE(file_name)
读入文件并且作为一个字符串返回文件内容。文件必须在服务器上,你必须指定到文件的完整路径名,而且你必须有file权限。文件必须所有内容都是可读的并且小于max_allowed_packet。如果文件不存在或由于上面原因之一不能被读出,函数返回NULL。
mysql> UPDATE table_name
SET blob_column=LOAD_FILE("/tmp/picture")
WHERE id=1;
MySQL必要时自动变换数字为字符串,并且反过来也如此:
mysql> SELECT 1+"1";
-> 2
mysql> SELECT CONCAT(2,' test');
-> '2 test'
如果你想要明确地变换一个数字到一个字符串,把它作为参数传递到CONCAT()。
如果字符串函数提供一个二进制字符串作为参数,结果字符串也是一个二进制字符串。被变换到一个字符串的数字被当作是一个二进制字符串。这仅影响比较 .
本文来自: 脚本之家(www.jb51.net) 详细出处参考:http://www.jb51.net/article/19437.htm
将excel数据导入oracle中
http://www.douzhe.com/docs/bbsjh/8/3383.html 这个帖子的讨论,整理如下:
A、有一个比较麻烦但保证成功的方法。
1、在本地创建一个Access数据库,将Excel数据先导入到Access。可直接导入点击鼠标右键,选择导入,文件类型选择要导入的Excel文件,也可通过创建宏用TransferSpreadsheet函数实现。
2、在本地创建ODBC,链接oracle数据库。将oracle中需要导入数据的表以链接表的方式在本地Access中创建(千万不要使用导入表)。
3、在Access数据库中创建插入查询将导入好的Excel数据导入到oracle中。
此方法保证成功。
B、也可以导入sql server 用它的导出工具导入oracle 但对一些image字段支持不好,你如果
没这种字段就行。
用MS_sqlserver 提供的数据导出导入功能可以方便的把excel方便的导入oracle数据库
C、一种方法:
先把Excel另存为.csv格式文件,如test.csv,再编写一个insert.ctl
用sqlldr进行导入!
insert.ctl内容如下:
load data --1、控制文件标识
infile 'test.csv' --2、要输入的数据文件名为test.csv
append into table table_name --3、向表table_name中追加记录
fields terminated by ',' --4、字段终止于',',是一个逗号
(field1,
field2,
field3,
...
fieldn)-----定义列对应顺序
注意括号中field排列顺序要与csv文件中相对应
然后就可以执行如下命令:
sqlldr user/password control=insert.ctl
有关SQLLDR的问题
控制文件:input.ctl,内容如下:
load data --1、控制文件标识
infile 'test.txt' --2、要输入的数据文件名为test.txt
append into table test --3、向表test中追加记录
fields terminated by X'09' --4、字段终止于X'09',是一个制表符(TAB)
(id,username,password,sj) -----定义列对应顺序
其中append为数据装载方式,还有其他选项:
a、insert,为缺省方式,在数据装载开始时要求表为空
b、append,在表中追加新记录
c、replace,删除旧记录,替换成新装载的记录
d、truncate,同上
问题:SQLLDR能不能保留表中原有的数据,如果发现KEY重复时,再UPDATE对应的记录?
D、先?EXCEL文件??成TXT文件
再使用SQLLOADER
E、将EXCEL文件保存成*.csv格式. 然后用sqlload来导入表中.
sqlload是Oracle自带的数据倒入工具,应该是没有可视化工具的(至少我一直用命令行)。
直接在命令行下敲入sqlldr即可得到帮助。
F、如果你的单个文件不大的情况下(少于100000行), 可以全选COPY ,然后用PL/SQL.:
select * from table for update. 然后打开锁, 再按一下加号. 鼠标点到第一个空格然后粘贴. COMMIT即可.(小窍门, ORACLE不支持的, 但很好用, 不会有问题)
G、Golden的imp/exp工具可以直接导入文本文件,非常简单
下面这个不知道是针对以上哪种方法的:
放心:excel文件最多只有65536条记录
不放心:曾经如此导过,但当有中文字段时可能出现异常(PL/SQL DEV5)
我用的是A,OK,时间仓促,其他的没有试过。
http://www.itpub.net/101803.html 这个帖子如是说:
你用的方法可能是:
1. 存成txt文件, 再用sql*loader
2. 存成txt文件, 再用第三方工具(如pb, delphi, toad, pl/sql dev等)导入.
sql*loader用起来费劲, 为了小小的需求, 装一个第三方工具麻烦.
看看我的方法.
比如文件中有id, name两列(分别为A列和B列), 要导入的表为person(person_id, person_name)
在excel 文件的sheet的最右列, 添加一列, 对应第一行数据的单元格写入以下内容:
= "INSERT INTO PERSON(PERSON_ID, PERSON_NAME) VALUES('" & A1 & "', '" & B1 & "');"
然后把这一行复制到所有数据行对应的列中.
这一列的内容拷贝出去保存, 即成为可以直接在sql*plus下运行的脚本.
方法一?日期型?位不适用
A、把Excel文件导到Acess里,然后打开要导数据的表。
打开 PLSQL DEV,打开一个SQL窗口,执行
select * from [tab] for update
然后一列一列的从Acess里copy & paste 。
B、excel->copy->pl/sql developer>paste
实际操作时发现,使用 copy / paste 经常会发生莫其妙的问题。尤其是通过 access ( ODBC) copy 入 oracle 时。
EXECL -->SAVE AS *.CSV(COMMA DELIMITED). THEN LOAD IT DIRECTLY.
CTL FILE EXAMPLE
------------
Load Data
INFILE 'E:\AA.csv'
TRUNCATE
INTO TABLE AA
FIELDS TERMINATED BY ','
(A,
B)
C、在ACCESS中将ORACLE TABLE 映射,然后直接插入即可。很方便,也没发现有数据错误问题。
曾经有一个很麻烦的LONG RAW问题,用这个办法也解决了
D、用SQL*XL就可以直接将EXCEL文件导入ORACLE,很方便的,我一直用SQL*XL。
E、我常用的办法是从excel中copy到ultraEdit中,然后用列编辑功能加上insert into ....等等,也挺好用
F、用plsql developer,很好用的,直接copy就可以了
在pl/sql developer 中选择表的多个字段名,然后就可以paste 了
G、用odbc加pb的数据管道可以在不同的数据库(文本)之间传输数据
H、odbc+pb
用不同的odbc驱动程序连接不通的数据库
然后在pb环境中启动数据管道,利用数据管道传输数据
I、先倒成。DBF的文件,再用DELPHI DATABASE DESKTOP 导入ORACLE很方便的,也且也可以支持空值导入。
http://www.itpub.net/showthread.php?s=7f7b57ea130ab71a3fdad57a71d8f8a1&threadid=97652&perpage=15&pagenumber=2
帖子很长,有空再整理。
人只有两种清晰的状态。
醒与睡。
在精神上是一种对峙。
在时间上是一个颠倒。
习惯在子夜时候入睡的一群人,
还有深夜或黎明入睡的一群人。
他们拥有两种完全不一样的眼神。
茫然的,困顿的,涣散的。
清晰的,锋利的,脆弱的。
人还有两种模糊的状态。
生与死。
一种人努力的想该如何活着。
另一种人思考着该如何死去。
一种从不放弃,
有着阳光的气息和温和的表情。
一种冷漠孤离,
在光怪陆离的夜晚里整理思绪。
他们在那些大大的城市里,
小小的生活着。
伴随着轻微的喘息,和疲惫的背影。
之后,生活遍体鳞伤。
可那些年华,
从来都不被阻挡。
那些虚度的光阴被时针拖成狭长的阴影。
沉重的荡在身后。
如果你看的见。
明天的之后还有明天,
要勇敢的过
缺点:
1、可移植性是存储过程和触发器最大的缺点。
2、占用服务器端太多的资源,对服务器造成很大的压力
3、不能做DDL。
4、触发器排错困难,而且数据容易造成不一致,后期维护不方便。
优点:
1、预编译,已优化,效率较高。避免了SQL语句在网络传输然后再解释的低效率。
2、存储过程可以重复使用,减少开发人员的工作量。
3、业务逻辑封装性好,修改方便。
4、安全。不会有SQL语句注入问题存在。
aa.htm是参数输入界面
bb.htm是参数接收处理界面
aa.htm
<html>
<head>
</head>
<body>
<script>
function submit()
{
var input1 = document.getElementById("inputid");
window.open("b.html?inputStr=" + input1.value);//传入参数
}
</script>
<input type = "text" id = "inputid">
<input type = "button" onclick = "submit()" value = "提交">
</body>
</html>
bb.htm:
<html>
<head>
<script>
//获得参数的方法
var request =
{
QueryString : function(val)
{
var uri = window.location.search;
var re = new RegExp("" +val+ "=([^&?]*)", "ig");
return ((uri.match(re))?(uri.match(re)[0].substr(val.length+1)):null);
}
}
</script>
</head>
<body>
<script>
//调用方法获得参数
var rt = request.QueryString("inputStr");
alert(rt);
</script>
</body>
</html>
MySQL:MySQL日期数据类型、MySQL时间类型使用总结 MySQL 日期类型:日期格式、所占存储空间、日期范围 比较。
日期类型 存储空间 日期格式 日期范围
------------ --------- --------------------- -----------------------------------------
datetime 8 bytes YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
timestamp 4 bytes YYYY-MM-DD HH:MM:SS 1970-01-01 00:00:01 ~ 2038
date 3 bytes YYYY-MM-DD 1000-01-01 ~ 9999-12-31
year 1 bytes YYYY 1901 ~ 2155
在 MySQL 中创建表时,对照上面的表格,很容易就能选择到合适自己的数据类型。不过到底是选择 datetime 还是 timestamp,可能会有点犯难。这两个日期时间类型各有优点:datetime 的日期范围比较大;timestamp 所占存储空间比较小,只是 datetime 的一半。
另外,timestamp 类型的列还有个特性:默认情况下,在 insert, update 数据时,timestamp 列会自动以当前时间(CURRENT_TIMESTAMP)填充/更新。“自动”的意思就是,你不去管它,MySQL 会替你去处理。
一般情况下,我倾向于使用 datetime 日期类型。
MySQL 时间类型:时间格式、所占存储空间、时间范围。
时间类型 存储空间 时间格式 时间范围
------------ --------- --------------------- -----------------------------------------
time 3 bytes HH:MM:SS -838:59:59 ~ 838:59:59
time 时间范围居然有这么大的范围,特别是 time 可以取负值,有点奇怪。后来,看了 MySQL 手册才知道这是为了满足两个日期时间相减才这样设计的。
select timediff('2000:01:31 23:59:59', '2000:01:01 00:00:00'); -- 743:59:59
select timediff('2000:01:01 00:00:00', '2000:01:31 23:59:59'); -- -743:59:59
select timediff('23:59:59', '12:00:00'); -- 11:59:59
注意,timediff 的两个参数只能是 datetime/timestamp, time 类型的,并且这两个参数类型要相同。即:datetime/timestamp 和 datetime/timestamp 比较;time 和 time 相比较。
虽然 MySQL 中的日期时间类型比较丰富,但遗憾的是,目前(2008-08-08)这些日期时间类型只能支持到秒级别,不支持毫秒、微秒。也没有产生毫秒的函数。
《MySQL:MySQL日期数据类型、MySQL时间类型使用总结》适用于 MySQL 5.X 及以上版本。
一、MySQL 获得当前日期时间 函数
1.1 获得当前日期+时间(date + time)函数:now()
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2008-08-08 22:20:46 |
+---------------------+
除了 now() 函数能获得当前的日期时间外,MySQL 中还有下面的函数:
current_timestamp()
,current_timestamp
,localtime()
,localtime
,localtimestamp -- (v4.0.6)
,localtimestamp() -- (v4.0.6)
这些日期时间函数,都等同于 now()。鉴于 now() 函数简短易记,建议总是使用 now() 来替代上面列出的函数。
1.2 获得当前日期+时间(date + time)函数:sysdate()
sysdate() 日期时间函数跟 now() 类似,不同之处在于:now() 在执行开始时值就得到了, sysdate() 在函数执行时动态得到值。看下面的例子就明白了:
mysql> select now(), sleep(3), now();
+---------------------+----------+---------------------+
| now() | sleep(3) | now() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:21 | 0 | 2008-08-08 22:28:21 |
+---------------------+----------+---------------------+
mysql> select sysdate(), sleep(3), sysdate();
+---------------------+----------+---------------------+
| sysdate() | sleep(3) | sysdate() |
+---------------------+----------+---------------------+
| 2008-08-08 22:28:41 | 0 | 2008-08-08 22:28:44 |
+---------------------+----------+---------------------+
可以看到,虽然中途 sleep 3 秒,但 now() 函数两次的时间值是相同的; sysdate() 函数两次得到的时间值相差 3 秒。MySQL Manual 中是这样描述 sysdate() 的:Return the time at which the function executes。
sysdate() 日期时间函数,一般情况下很少用到。
2. 获得当前日期(date)函数:curdate()
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2008-08-08 |
+------------+
其中,下面的两个日期函数等同于 curdate():
current_date()
,current_date
3. 获得当前时间(time)函数:curtime()
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 22:41:30 |
+-----------+
其中,下面的两个时间函数等同于 curtime():
current_time()
,current_time
4. 获得当前 UTC 日期时间函数:utc_date(), utc_time(), utc_timestamp()
mysql> select utc_timestamp(), utc_date(), utc_time(), now()
+---------------------+------------+------------+---------------------+
| utc_timestamp() | utc_date() | utc_time() | now() |
+---------------------+------------+------------+---------------------+
| 2008-08-08 14:47:11 | 2008-08-08 | 14:47:11 | 2008-08-08 22:47:11 |
+---------------------+------------+------------+---------------------+
因为我国位于东八时区,所以本地时间 = UTC 时间 + 8 小时。UTC 时间在业务涉及多个国家和地区的时候,非常有用。
二、MySQL 日期时间 Extract(选取) 函数。
1. 选取日期时间的各个部分:日期、时间、年、季度、月、日、小时、分钟、秒、微秒
set @dt = '2008-09-10 07:15:30.123456';
select date(@dt); -- 2008-09-10
select time(@dt); -- 07:15:30.123456
select year(@dt); -- 2008
select quarter(@dt); -- 3
select month(@dt); -- 9
select week(@dt); -- 36
select day(@dt); -- 10
select hour(@dt); -- 7
select minute(@dt); -- 15
select second(@dt); -- 30
select microsecond(@dt); -- 123456
2. MySQL Extract() 函数,可以上面实现类似的
功能:
set @dt = '2008-09-10 07:15:30.123456';
select extract(year from @dt); -- 2008
select extract(quarter from @dt); -- 3
select extract(month from @dt); -- 9
select extract(week from @dt); -- 36
select extract(day from @dt); -- 10
select extract(hour from @dt); -- 7
select extract(minute from @dt); -- 15
select extract(second from @dt); -- 30
select extract(microsecond from @dt); -- 123456
select extract(year_month from @dt); -- 200809
select extract(day_hour from @dt); -- 1007
select extract(day_minute from @dt); -- 100715
select extract(day_second from @dt); -- 10071530
select extract(day_microsecond from @dt); -- 10071530123456
select extract(hour_minute from @dt); -- 715
select extract(hour_second from @dt); -- 71530
select extract(hour_microsecond from @dt); -- 71530123456
select extract(minute_second from @dt); -- 1530
select extract(minute_microsecond from @dt); -- 1530123456
select extract(second_microsecond from @dt); -- 30123456
MySQL Extract() 函数除了没有date(),time() 的功能外,其他功能一应具全。并且还具有选取‘day_microsecond’ 等功能。注意这里不是只选取 day 和 microsecond,而是从日期的 day 部分一直选取到 microsecond 部分。够强悍的吧!
MySQL Extract() 函数唯一不好的地方在于:你需要多敲几次键盘。
3. MySQL dayof... 函数:dayofweek(), dayofmonth(), dayofyear()
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
日期 '2008-08-08' 是一周中的第 6 天(1 = Sunday, 2 = Monday, ..., 7 = Saturday);一月中的第 8 天;一年中的第 221 天。
4. MySQL week... 函数:week(), weekofyear(), dayofweek(), weekday(), yearweek()
set @dt = '2008-08-08';
select week(@dt); -- 31
select week(@dt,3); -- 32
select weekofyear(@dt); -- 32
select dayofweek(@dt); -- 6
select weekday(@dt); -- 4
select yearweek(@dt); -- 200831
MySQL week() 函数,可以有两个参数,具体可看手册。 weekofyear() 和 week() 一样,都是计算“某天”是位于一年中的第几周。 weekofyear(@dt) 等价于 week(@dt,3)。
MySQL weekday() 函数和 dayofweek() 类似,都是返回“某天”在一周中的位置。不同点在于参考的标准, weekday:(0 = Monday, 1 = Tuesday, ..., 6 = Sunday); dayofweek:(1 = Sunday, 2 = Monday, ..., 7 = Saturday)
MySQL yearweek() 函数,返回 year(2008) + week 位置(31)。
5. MySQL 返回星期和月份名称函数:dayname(), monthname()
set @dt = '2008-08-08';
select dayname(@dt); -- Friday
select monthname(@dt); -- August
思考,如何返回中文的名称呢?
6. MySQL last_day() 函数:返回月份中的最后一天。
select last_day('2008-02-01'); -- 2008-02-29
select last_day('2008-08-08'); -- 2008-08-31
MySQL last_day() 函数非常有用,比如我想得到当前月份中有多少天,可以这样来计算:
mysql> select now(), day(last_day(now())) as days;
+---------------------+------+
| now() | days |
+---------------------+------+
| 2008-08-09 11:45:45 | 31 |
+---------------------+------+
三、MySQL 日期时间计算函数
1. MySQL 为日期增加一个时间间隔:date_add()
set @dt = now();
select date_add(@dt, interval 1 day); -- add 1 day
select date_add(@dt, interval 1 hour); -- add 1 hour
select date_add(@dt, interval 1 minute); -- ...
select date_add(@dt, interval 1 second);
select date_add(@dt, interval 1 microsecond);
select date_add(@dt, interval 1 week);
select date_add(@dt, interval 1 month);
select date_add(@dt, interval 1 quarter);
select date_add(@dt, interval 1 year);
select date_add(@dt, interval -1 day); -- sub 1 day
MySQL adddate(), addtime()函数,可以用 date_add() 来替代。下面是 date_add() 实现 addtime() 功能示例:
mysql> set @dt = '2008-08-09 12:12:33';
mysql>
mysql> select date_add(@dt, interval '01:15:30' hour_second);
+------------------------------------------------+
| date_add(@dt, interval '01:15:30' hour_second) |
+------------------------------------------------+
| 2008-08-09 13:28:03 |
+------------------------------------------------+
mysql> select date_add(@dt, interval '1 01:15:30' day_second);
+-------------------------------------------------+
| date_add(@dt, interval '1 01:15:30' day_second) |
+-------------------------------------------------+
| 2008-08-10 13:28:03 |
+-------------------------------------------------+
date_add() 函数,分别为 @dt 增加了“1小时 15分 30秒” 和 “1天 1小时 15分 30秒”。建议:总是使用 date_add() 日期时间函数来替代 adddate(), addtime()。
2. MySQL 为日期减去一个时间间隔:date_sub()
mysql> select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second);
+----------------------------------------------------------------+
| date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second) |
+----------------------------------------------------------------+
| 1997-12-30 22:58:59 |
+----------------------------------------------------------------+
MySQL date_sub() 日期时间函数 和 date_add() 用法一致,不再赘述。另外,MySQL 中还有两个函数 subdate(), subtime(),建议,用 date_sub() 来替代。
3. MySQL 另类日期函数:period_add(P,N), period_diff(P1,P2)
函数参数“P” 的格式为“YYYYMM” 或者 “YYMM”,第二个参数“N” 表示增加或减去 N month(月)。
MySQL period_add(P,N):日期加/减去N月。
mysql> select period_add(200808,2), period_add(20080808,-2)
+----------------------+-------------------------+
| period_add(200808,2) | period_add(20080808,-2) |
+----------------------+-------------------------+
| 200810 | 20080806 |
+----------------------+-------------------------+
MySQL period_diff(P1,P2):日期 P1-P2,返回 N 个月。
mysql> select period_diff(200808, 200801);
+-----------------------------+
| period_diff(200808, 200801) |
+-----------------------------+
| 7 |
+-----------------------------+
在 MySQL 中,这两个日期函数,一般情况下很少用到。
4. MySQL 日期、时间相减函数:datediff(date1,date2), timediff(time1,time2)
MySQL datediff(date1,date2):两个日期相减 date1 - date2,返回天数。
select datediff('2008-08-08', '2008-08-01'); -- 7
select datediff('2008-08-01', '2008-08-08'); -- -7
MySQL timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值。
select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08
select timediff('08:08:08', '00:00:00'); -- 08:08:08
注意:timediff(time1,time2) 函数的两个参数类型必须相同。
四、MySQL 日期转换函数、时间转换函数
1. MySQL (时间、秒)转换函数:time_to_sec(time), sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605
select sec_to_time(3605); -- '01:00:05'
2. MySQL (日期、天数)转换函数:to_days(date), from_days(days)
select to_days('0000-00-00'); -- 0
select to_days('2008-08-08'); -- 733627
select from_days(0); -- '0000-00-00'
select from_days(733627); -- '2008-08-08'
3. MySQL Str to Date (字符串转换为日期)函数:str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09
select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09
select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09
select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30
select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30
可以看到,str_to_date(str,format) 转换函数,可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。“format” 可以参看 MySQL 手册。
4. MySQL Date/Time to Str(日期/时间转换为字符串)函数:date_format(date,format), time_format(time,format)
mysql> select date_format('2008-08-08 22:23:00', '%W %M %Y');
+------------------------------------------------+
| date_format('2008-08-08 22:23:00', '%W %M %Y') |
+------------------------------------------------+
| Friday August 2008 |
+------------------------------------------------+
mysql> select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s');
+----------------------------------------------------+
| date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s') |
+----------------------------------------------------+
| 20080808222301 |
+----------------------------------------------------+
mysql> select time_format('22:23:01', '%H.%i.%s');
+-------------------------------------+
| time_format('22:23:01', '%H.%i.%s') |
+-------------------------------------+
| 22.23.01 |
+-------------------------------------+
MySQL 日期、时间转换函数:date_format(date,format), time_format(time,format) 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str,format) 函数的 一个逆转换。
5. MySQL 获得国家地区时间格式函数:get_format()
MySQL get_format() 语法:
get_format(date|time|datetime, 'eur'|'usa'|'jis'|'iso'|'internal'
MySQL get_format() 用法的全部示例:
select get_format(date,'usa') ; -- '%m.%d.%Y'
select get_format(date,'jis') ; -- '%Y-%m-%d'
select get_format(date,'iso') ; -- '%Y-%m-%d'
select get_format(date,'eur') ; -- '%d.%m.%Y'
select get_format(date,'internal') ; -- '%Y%m%d'
select get_format(datetime,'usa') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'jis') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'iso') ; -- '%Y-%m-%d %H:%i:%s'
select get_format(datetime,'eur') ; -- '%Y-%m-%d %H.%i.%s'
select get_format(datetime,'internal') ; -- '%Y%m%d%H%i%s'
select get_format(time,'usa') ; -- '%h:%i:%s %p'
select get_format(time,'jis') ; -- '%H:%i:%s'
select get_format(time,'iso') ; -- '%H:%i:%s'
select get_format(time,'eur') ; -- '%H.%i.%s'
select get_format(time,'internal') ; -- '%H%i%s'
MySQL get_format() 函数在实际中用到机会的比较少。
6. MySQL 拼凑日期、时间函数:makdedate(year,dayofyear), maketime(hour,minute,second)
select makedate(2001,31); -- '2001-01-31'
select makedate(2001,32); -- '2001-02-01'
select maketime(12,15,30); -- '12:15:30'
五、MySQL 时间戳(Timestamp)函数
1. MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
mysql> select current_timestamp, current_timestamp();
+---------------------+---------------------+
| current_timestamp | current_timestamp() |
+---------------------+---------------------+
| 2008-08-09 23:22:24 | 2008-08-09 23:22:24 |
+---------------------+---------------------+
2. MySQL (Unix 时间戳、日期)转换函数:
unix_timestamp(),
unix_timestamp(date),
from_unixtime(unix_timestamp),
from_unixtime(unix_timestamp,format)
下面是示例:
select unix_timestamp(); -- 1218290027
select unix_timestamp('2008-08-08'); -- 1218124800
select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800
select from_unixtime(1218290027); -- '2008-08-09 21:53:47'
select from_unixtime(1218124800); -- '2008-08-08 00:00:00'
select from_unixtime(1218169800); -- '2008-08-08 12:30:00'
select from_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August 12:30:00 2008'
3. MySQL 时间戳(timestamp)转换、增、减函数:
timestamp(date) -- date to timestamp
timestamp(dt,time) -- dt + time
timestampadd(unit,interval,datetime_expr) --
timestampdiff(unit,datetime_expr1,datetime_expr2) --
请看示例部分:
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00
select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01
select timestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-18 09:01:01
select timestampadd(day, 1, '2008-08-08 08:00:00'); -- 2008-08-09 08:00:00
select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00
MySQL timestampadd() 函数类似于 date_add()。
select timestampdiff(year,'2002-05-01','2001-01-01'); -- -1
select timestampdiff(day ,'2002-05-01','2001-01-01'); -- -485
select timestampdiff(hour,'2008-08-08 12:00:00','2008-08-08 00:00:00'); -- -12
select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7
MySQL timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。
六、MySQL 时区(timezone)转换函数
convert_tz(dt,from_tz,to_tz)
select convert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-08 04:00:00
时区转换也可以通过 date_add, date_sub, timestampadd 来实现。
select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00
select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00
select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
<
c3p0-config>
<default-config>
<!--当连接池中的连接耗尽的时候
c3p0一次同时获取的连接数。Default: 3 -->
<property name="acquireIncrement">3</property>
<!--定义在从数据库获取新连接失败后重复尝试的次数。Default: 30 -->
<property name="acquireRetryAttempts">30</property>
<!--两次连接中间隔时间,单位毫秒。Default: 1000 -->
<property name="acquireRetryDelay">1000</property>
<!--连接关闭时默认将所有未提交的操作回滚。Default: false -->
<property name="autoCommitOnClose">false</property>
<!--
c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么
属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供
c3p0测试
使用。Default: null-->
<property name="automaticTestTable">Test</property>
<!--获取连接失败将会引起所有等待连接池来获取连接的线程抛出异常。但是数据源仍有效
保留,并在下次调用getConnection()的时候继续尝试获取连接。如果设为true,那么在尝试
获取连接失败后该数据源将申明已断开并永久关闭。Default: false-->
<property name="breakAfterAcquireFailure">false</property>
<!--当连接池用完时客户端调用getConnection()后等待获取新连接的时间,超时后将抛出
SQLException,如设为0则无限期等待。单位毫秒。Default: 0 -->
<property name="checkoutTimeout">100</property>
<!--通过实现ConnectionTester或QueryConnectionTester的类来测试连接。类名需制定全路径。
Default: com.mchange.v2.
c3p0.impl.DefaultConnectionTester-->
<property name="connectionTesterClassName"></property>
<!--指定
c3p0 libraries的路径,如果(通常都是这样)在本地即可获得那么无需设置,默认null即可
Default: null-->
<property name="factoryClassLocation">null</property>
<!--Strongly disrecommended. Setting this to true may lead to subtle and bizarre bugs.
(文档原文)作者强烈建议不使用的一个属性-->
<property name="forceIgnoreUnresolvedTransactions">false</property>
<!--每60秒检查所有连接池中的空闲连接。Default: 0 -->
<property name="idleConnectionTestPeriod">60</property>
<!--初始化时获取三个连接,取值应在minPoolSize与maxPoolSize之间。Default: 3 -->
<property name="initialPoolSize">3</property>
<!--最大空闲时间,60秒内未使用则连接被丢弃。若为0则永不丢弃。Default: 0 -->
<property name="maxIdleTime">60</property>
<!--连接池中保留的最大连接数。Default: 15 -->
<property name="maxPoolSize">15</property>
<!--JDBC的标准参数,用以控制数据源内加载的PreparedStatements数量。但由于预缓存的statements
属于单个connection而不是整个连接池。所以设置这个参数需要考虑到多方面的因素。
如果maxStatements与maxStatementsPerConnection均为0,则缓存被关闭。Default: 0-->
<property name="maxStatements">100</property>
<!--maxStatementsPerConnection定义了连接池内单个连接所拥有的最大缓存statements数。Default: 0 -->
<property name="maxStatementsPerConnection"></property>
<!--
c3p0是异步操作的,缓慢的JDBC操作通过帮助进程完成。扩展这些操作可以有效的提升性能
通过多线程实现多个操作同时被执行。Default: 3-->
<property name="numHelperThreads">3</property>
<!--当用户调用getConnection()时使root用户成为去获取连接的用户。主要用于连接池连接非
c3p0
的数据源时。Default: null-->
<property name="overrideDefaultUser">root</property>
<!--与overrideDefaultUser参数对应使用的一个参数。Default: null-->
<property name="overrideDefaultPassword">password</property>
<!--密码。Default: null-->
<property name="password"></property>
<!--定义所有连接测试都执行的测试语句。在使用连接测试的情况下这个一显著提高测试速度。注意:
测试的表必须在初始数据源的时候就存在。Default: null-->
<property name="preferredTestQuery">select id from test where id=1</property>
<!--用户修改系统配置参数执行前最多等待300秒。Default: 300 -->
<property name="propertyCycle">300</property>
<!--因性能消耗大请只在需要的时候使用它。如果设为true那么在每个connection提交的
时候都将校验其有效性。建议使用idleConnectionTestPeriod或automaticTestTable
等方法来提升连接测试的性能。Default: false -->
<property name="testConnectionOnCheckout">false</property>
<!--如果设为true那么在取得连接的同时将校验连接的有效性。Default: false -->
<property name="testConnectionOnCheckin">true</property>
<!--用户名。Default: null-->
<property name="user">root</property>
<!--早期的
c3p0版本对JDBC接口采用动态反射代理。在早期版本用途广泛的情况下这个参数
允许用户恢复到动态反射代理以解决不稳定的故障。最新的非反射代理更快并且已经开始
广泛的被使用,所以这个参数未必有用。现在原先的动态反射与新的非反射代理同时受到
支持,但今后可能的版本可能不支持动态反射代理。Default: false-->
<property name="usesTraditionalReflectiveProxies">false</property>
<property name="automaticTestTable">con_test</property>
<property name="checkoutTimeout">30000</property>
<property name="idleConnectionTestPeriod">30</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">25</property>
<property name="minPoolSize">10</property>
<property name="maxStatements">0</property>
<user-overrides user="swaldman">
</user-overrides>
</default-config>
<named-config name="dumbTestConfig">
<property name="maxStatements">200</property>
<user-overrides user="poop">
<property name="maxStatements">300</property>
</user-overrides>
</named-config>
</
c3p0-config>
最近的一个项目在Hibernate使用C3P0的连接池,数据库为Mysql。开发测试没有问题,在运行中每个一段长的空闲时间就出现异常:
- org.hibernate.exception.JDBCConnectionException: could not execute query
- at org.hibernate.exception.SQLStateConverter.convert(SQLStateConverter.java:74)
- at org.hibernate.exception.JDBCExceptionHelper.convert(JDBCExceptionHelper.java:43)
- .......
- Caused by: com.mysql.jdbc.exceptions.MySQLNonTransientConnectionException: No operations allowed after connection closed.Connection was implicitly closed due to underlying exception/error:
-
-
- ** BEGIN NESTED EXCEPTION **
-
- com.mysql.jdbc.CommunicationsException
- MESSAGE: Communications link failure due to underlying exception:
-
- ** BEGIN NESTED EXCEPTION **
-
- java.net.SocketException
- MESSAGE: Broken pipe
-
- STACKTRACE:
-
- java.net.SocketException: Broken pipe
- at java.net.SocketOutputStream.socketWrite0(Native Method)
- ......
- ** END NESTED EXCEPTION **
查看了Mysql的文档,以及Connector/J的文档以及在线说明发现,出现这种异常的原因是:
Mysql服务器默认的“wait_timeout”是8小时,也就是说一个connection空闲超过8个小时,Mysql将自动断开该connection。这就是问题的所在,在C3P0 pools中的connections如果空闲超过8小时,Mysql将其断开,而C3P0并不知道该connection已经失效,如果这时有Client请求connection,C3P0将该失效的Connection提供给Client,将会造成上面的异常。
解决的方法有3种:
- 增加wait_timeout的时间。
- 减少Connection pools中connection的lifetime。
- 测试Connection pools中connection的有效性。
当然最好的办法是同时综合使用上述3种方法,下面就DBCP和C3P0分别做一说明,假设wait_timeout为默认的8小时
DBCP增加以下配置信息:
validationQuery = "SELECT 1"
testWhileIdle = "true"
timeBetweenEvictionRunsMillis = 3600000
minEvictableIdleTimeMillis = 18000000
testOnBorrow = "true"
C3P0增加以下配置信息:
testConnectionOnCheckin = true
//自动测试的table名称
automaticTestTable=C3P0TestTable
idleConnectionTestPeriod = 18000
maxIdleTime = 25000
testConnectionOnCheckout = true
在配置文件中要写成 <property name="minPoolSize"><value>1</value></property> 格式
不能写成 这样<property name="properties">
<props>
<prop key="c3p0.initialPoolSize">1</prop>
</props>
</property>
c3p0不能完全识别!!
摘要: import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.Fi... 阅读全文
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。
主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1、用dba权限的用户查看数据库都有哪些锁
select t2.username,t2.sid,t2.serial#,t2.logon_time
from v$locked_object t1,v$session t2
where t1.session_id=t2.sid order by t2.logon_time;
如:testuser 339 13545 2009-3-5 17:40:05
知道被锁的用户testuser,sid为339,serial#为13545
2、根据sid查看具体的sql语句,如果sql不重要,可以kill
select sql_text from v$session a,v$sqltext_with_newlines b
where DECODE(a.sql_hash_value, 0, prev_hash_value, sql_hash_value)=b.hash_value
and a.sid=&sid order by piece;
查出来的sql,如: begin :id := sys.dbms_transaction.local_transaction_id; end;
3、kill该事务
alter system kill session '339,13545';
4、这样就可以执行其他的事务sql语句了
如增加表的主键:
alter table test
add constraint PK_test primary key (test_NO);
Oracle数据库系统根据初始化参数文件init.ora中设置的参数来配置自身的启动,每个实例在启动之前,首先读取这些参数文件中设置的不同参数。Oracle系统中的参数,根据系统使用情况可以简单分为两大类,普通参数,也就是Oracle系统正常使用的一些参数,另外一类就是特殊参数,包括三种,过时参数、强调参数和隐藏参数。随着Oracle数据库新版本的发布,相应每次都会增加或者删除一些参数。如何查询当前版本数据库系统的参数情况以及当前系统版本相对于以前版本增加或者丢弃的那些参数呢?本文将详细介绍如何查询当前系统版本中的各种参数情况。
一、过时参数和强调参数
Oracle数据库中,系统提供了几个视图可以查看系统参数的情况。视图V$OBSOLETE_PARAMETER中含有所有的过时(obsolete)和强调(underscored)参数。这里首先说明一下什么是Oracle的过时(obsolote)和强调(underscored)参数,过时参数,顾名思义就是在Oracle以前的版本中存在,但在新版本中已经淘汰了的参数,已经不再使用;而强调参数,是指那些在新版本中保留了下来,但是除非特殊需要不希望用户使用的那些参数。在视图V$OBSOLETE_PARAMETER中,包含这些参数的名称和一个标志字ISSPECIFIED,该标志字用来指出这个参数是否在init.ora文件中已实际设置。
下面的SQL脚本列出了当前系统中所有的过时参数名称以及它们是否在当前系统中设定。
SQL> COL name format a50;
SQL> SELECT name, isspecified FROM v$obsolete_parameter; |
上面谈到,Oracle系统并没有将V$OBSOLETE_PARAMETER视图中的所有参数均丢弃,而是将其中的一部分转换为强调参数,下面就来讨论如何查看这些参数是已被丢弃还是被转换。这可以通过系统视图X$KSPPO来查看,该视图中包含一个名为KSPPOFLAG的字段,用来指明该参数在当前版本中是被丢弃还是被强调,如果该值为1,则表示该参数已被丢弃,该值为2,则表明该参数现为强调参数。
SELECT kspponm,
DECODE(ksppoflg, 1,'Obsolete', 2, 'Underscored')
FROM x$ksppo
ORDER BY kspponm; |
注:该视图只在sys用户下可以看到。
二、隐藏参数
Oracle系统中还有一类参数称之为隐藏参数(hidden parameters),是系统中使用,但Oracle官方没有公布的参数,这些参数可能是那些还没有成熟或者是系统开发中使用的参数。这些参数在所有Oracle官方提供的文档中都没有介绍,他们的命名有一个共同特征就是都以'_'作为参数的首字符,诸如Oracle 8i中的_trace_files_public和_lock_sga_areas等等。
下面的查询可以得到当前系统中的所有隐藏参数(以sys身份登录):
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppcv y
WHERE x.indx = y.indx
AND translate(ksppinm,'_','#') like '#%'; |
三、系统当前参数
下面的脚本以英文字母顺序列出了系统当前使用的所有参数。在列出的参数中,如果参数名称前面有#这个符号,则表示该参数没有明确指定,采用了系统中的默认参数。一般在一个新的Oracle版本安装完成后,首先运行该脚本,则可以生成该版本数据库的标准init.ora文件。
SET pagesize 9000
SET head OFF
SET term OFF
SELECT
DECODE(isdefault, 'TRUE', '# ') ||
DECODE(isdefault, 'TRUE', RPAD(name,43), RPAD(name,45)) ||
' = ' || value
FROM v$parameter
ORDER BY name; |
注意:上面的SQL脚本没有列出系统中的隐藏参数
SVRMGR> select * from dba_jobs;
初始化相关参数job_queue_processes
alter system set job_queue_processes=39 scope=spfile;//最大值不能超过1000 ;job_queue_interval = 10 //调度作业刷新频率秒为单位
DBA_JOBS describes all jobs in the database.
USER_JOBS describes all jobs owned by the current user
1 select job,what,to_char(last_date,'yyyy-mm-dd HH24:mi:ss'),to_char(next_date,'yyyy-mm-dd HH24:m),interval from dba_jobs where job in (325,295)
2 select job,what,last_date,next_date,interval from dba_jobs where job in (1,3);
查询job的情况。
show paramter background_dump_dest.
看alter.log 和trace
SVRMGR> select * from dba_jobs;
初始化相关参数job_queue_processes
alter system set job_queue_processes=39 scope=spfile;//最大值不能超过1000
job_queue_interval = 10 //调度作业刷新频率秒为单位
DBA_JOBS describes all jobs in the database.
USER_JOBS describes all jobs owned by the current user
1 select job,what,to_char(last_date,'yyyy-mm-dd HH24:mi:ss'),to_char(next_date,'yyyy-mm-dd HH24:m),interval from dba_jobs where job in (325,295)
2 select job,what,last_date,next_date,interval from dba_jobs where job in (1,3);
查询job的情况。
show paramter background_dump_dest.
看alter.log 和trace
请问我如何停止一个JOB
SQL> exec dbms_job.broken(1,true)
PL/SQL 过程已成功完成。
SQL>commit //必须提交否则无效
启动作业
SQL> exec dbms_job.broken(1,false)
PL/SQL 过程已成功完成。
停其他用户的job
SQL>exec sys.dbms_ijob.broken(98,true);
SQL>commit;
============================
exec dbms_job.broken(:job) 停止
exec dbms_job.broken(186,true) //标记位broken
exec dbms_job.broken(186,false)//标记为非broken
exec dbms_job.broken(186,false,next_day(sysdate,'monday')) //标记为非broken,指定执行时间
exec dbms_job.remove(:job);删除
exec dbms_job.remove(186);
commit;
把一个broken job重新运行
三、查看相关job信息
1、相关视图
dba_jobs
all_jobs
user_jobs
dba_jobs_running 包含正在运行job相关信息
创建JOB
variable jobno number;
begin
dbms_job.submit(:jobno, 'statspack.snap;', trunc(sysdate+1/24,'HH'), 'trunc(SYSDATE+1/24,''HH'')', TRUE, :instno);
commit;
end;
print jobno
例如,我们已经建立了一个存储过程,其名称为my_job,在sql/plus中以scott用户身份登录,执行如下命令:
sql> variable n number;
sql> begin
dbms_job.submit(:n‘my_job;’,sysdate,
‘sysdate+1/360’);
commit;
end;
Sql> print :n;
系统提示执行成功。
Sql> print :n;
系统打印此任务的编号,例如结果为300。
简单例子
一个简单例子:
创建测试表
SQL> create table TEST(a date);
表已创建。
创建一个自定义过程
SQL> create or replace procedure MYPROC as
2 begin
3 insert into TEST values(sysdate);
4 end;
5 /
过程已创建。
创建JOB
SQL> variable job1 number;
SQL>
SQL> begin
2 dbms_job.submit(:job1,'MYPROC;',sysdate,'sysdate+1/1440'); --每天1440分钟,即一分钟运行test过程一次
3 end;
4 /
PL/SQL 过程已成功完成。
运行JOB
SQL> begin
2 dbms_job.run(:job1);
3 end;
4 /
PL/SQL 过程已成功完成。
SQL> select to_char(a,'yyyy/mm/dd hh24:mi:ss') 时间 from TEST;
时间
-------------------
2001/01/07 23:51:21
2001/01/07 23:52:22
2001/01/07 23:53:24
删除JOB
SQL> begin
2 dbms_job.remove(:job1);
3 end;
4 /
PL/SQL 过程已成功完成。
=======================================
a、利用dbms_job.run()立即执行该job
sql>begin
sql>dbms_job.run(:jobno) 该jobno为submit过程提交时返回的job number
sql>end;
sql>/
b、利用dbms_job.broken()重新将broken标记为false
sql>begin
sql>dbms_job.broken (:job,false,next_date)
sql>end;
sql>/
========================================
SQL> create table a(a date);
Table created
创建一个过程
SQL> create or replace procedure test as
2 begin
3 insert into a values(sysdate);
4 end;
5 /
Procedure created
提交作业
SQL> declare
2 job1 number; //定义一个数字型变量
3 begin
4 dbms_job.submit(:job1,'test;',sysdate,'sysdate+1/1440'); //按分钟算一天1440分钟
5 end;
6 /
PL/SQL procedure successfully completed
job1
---------
4
SQL> commit;
Commit complete
运行作业
SQL> begin
2 dbms_job.run(4);
3 end;
4 /
PL/SQL procedure successfully completed
删除作业
SQL> begin
2 dbms_job.remove(4);
3 end;
4 /
PL/SQL procedure successfully completed
SQL> commit;
Commit complete
job change//修改作业
execute dbms_job.change(186,null,null,'sysdate+3');
execute dbms_job.change(186,'scott.test(update)');
DBA_JOBS
===========================================
字段(列) 类型 描述
JOB NUMBER 任务的唯一标示号
LOG_USER VARCHAR2(30) 提交任务的用户
PRIV_USER VARCHAR2(30) 赋予任务权限的用户
SCHEMA_USER VARCHAR2(30) 对任务作语法分析的用户模式
LAST_DATE DATE 最后一次成功运行任务的时间
LAST_SEC VARCHAR2(8) 如HH24:MM:SS格式的last_date日期的小时,分钟和秒
THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null
THIS_SEC VARCHAR2(8) 如HH24:MM:SS格式的this_date日期的小时,分钟和秒
NEXT_DATE DATE 下一次定时运行任务的时间
NEXT_SEC VARCHAR2(8) 如HH24:MM:SS格式的next_date日期的小时,分钟和秒
TOTAL_TIME NUMBER 该任务运行所需要的总时间,单位为秒
BROKEN VARCHAR2(1) 标志参数,Y标示任务中断,以后不会运行
INTERVAL VARCHAR2(200) 用于计算下一运行时间的表达式
FAILURES NUMBER 任务运行连续没有成功的次数
WHAT VARCHAR2(2000) 执行任务的PL/SQL块
CURRENT_SESSION_LABEL RAW MLSLABEL 该任务的信任Oracle会话符
CLEARANCE_HI RAW MLSLABEL 该任务可信任的Oracle最大间隙
CLEARANCE_LO RAW MLSLABEL 该任务可信任的Oracle最小间隙
NLS_ENV VARCHAR2(2000) 任务运行的NLS会话设置
MISC_ENV RAW(32) 任务运行的其他一些会话参数
描述 INTERVAL参数值
每天午夜12点 'TRUNC(SYSDATE + 1)'
每天早上8点30分 'TRUNC(SYSDATE + 1) + (8*60+30)/(24*60)'
每星期二中午12点 'NEXT_DAY(TRUNC(SYSDATE ), ''TUESDAY'' ) + 12/24'
每个月第一天的午夜12点 'TRUNC(LAST_DAY(SYSDATE ) + 1)'
每个季度最后一天的晚上11点 'TRUNC(ADD_MONTHS(SYSDATE + 2/24, 3 ), 'Q' ) -1/24'
每星期六和日早上6点10分 'TRUNC(LEAST(NEXT_DAY(SYSDATE, ''SATURDAY"), NEXT_DAY(SYSDATE, "SUNDAY"))) + (6×60+10)/(24×60)'
Oracle9i 中job_queue_interval已经废弃(obsoleted),job_queue_processes=10默认,实际上,job_queue_interval的值为5,假如实在要修改interval的值,可以使用_job_queue_interval的隐藏参数。
转:http://java.ccidnet.com/art/3539/20070802/1164285_1.html
在Hibernate中处理批量更新和批量删除
发布时间:2007.08.03 06:06 来源:赛迪网 作者:dxaw
批量更新是指在一个事务中更新大批量数据,批量删除是指在一个事务中删除大批量数据。以下程序直接通过Hibernate API批量更新CUSTOMERS表中年龄大于零的所有记录的AGE字段:
tx = session.beginTransaction();
Iterator customers=session.find("from Customer c where c.age>0").iterator();
while(customers.hasNext()){
Customer customer=(Customer)customers.next();
customer.setAge(customer.getAge()+1);
}
tx.commit();
session.close();
如果CUSTOMERS表中有1万条年龄大于零的记录,那么Session的find()方法会一下子加载1万个Customer对象到内存。当执行tx.commit()方法时,会清理缓存,Hibernate执行1万条更新CUSTOMERS表的update语句:
update CUSTOMERS set AGE=? …. where ID=i;
update CUSTOMERS set AGE=? …. where ID=j;
……
update CUSTOMERS set AGE=? …. where ID=k;
以上批量更新方式有两个缺点:
(1) 占用大量内存,必须把1万个Customer对象先加载到内存,然后一一更新它们。
(2) 执行的update语句的数目太多,每个update语句只能更新一个Customer对象,必须通过1万条update语句才能更新一万个Customer对象,频繁的访问数据库,会大大降低应用的性能。
为了迅速释放1万个Customer对象占用的内存,可以在更新每个Customer对象后,就调用Session的evict()方法立即释放它的内存:
tx = session.beginTransaction();
Iterator customers=session.find("from Customer c where c.age>0").iterator();
while(customers.hasNext()){
Customer customer=(Customer)customers.next();
customer.setAge(customer.getAge()+1);
session.flush();
session.evict(customer);
}
tx.commit();
session.close();
在以上程序中,修改了一个Customer对象的age属性后,就立即调用Session的 flush()方法和evict()方法,flush()方法使Hibernate立刻根据这个Customer对象的状态变化同步更新数据库,从而立即执行相关的update语句;evict()方法用于把这个Customer对象从缓存中清除出去,从而及时释放它占用的内存。
但evict()方法只能稍微提高批量操作的性能,因为不管有没有使用evict()方法,Hibernate都必须执行1万条update语句,才能更新1万个Customer对象,这是影响批量操作性能的重要因素。假如Hibernate能直接执行如下SQL语句:
update CUSTOMERS set AGE=AGE+1 where AGE>0;
那么以上一条update语句就能更新CUSTOMERS表中的1万条记录。但是Hibernate并没有直接提供执行这种update语句的接口。应用程序必须绕过Hibernate API,直接通过JDBC API来执行该SQL语句:
tx = session.beginTransaction();
Connection con=session.connection();
PreparedStatement stmt=con.prepareStatement("update CUSTOMERS set AGE=AGE+1 "
+"where AGE>0 ");
stmt.executeUpdate();
tx.commit();
以上程序演示了绕过Hibernate API,直接通过JDBC API访问数据库的过程。应用程序通过Session的connection()方法获得该Session使用的数据库连接,然后通过它创建 PreparedStatement对象并执行SQL语句。值得注意的是,应用程序仍然通过Hibernate的Transaction接口来声明事务边界。
如果底层数据库(如Oracle)支持存储过程,也可以通过存储过程来执行批量更新。存储过程直接在数据库中运行,速度更加快。在Oracle数据库中可以定义一个名为batchUpdateCustomer()的存储过程,代码如下:
create or replace procedure batchUpdateCustomer(p_age in number) as
begin
update CUSTOMERS set AGE=AGE+1 where AGE>p_age;
end;
以上存储过程有一个参数p_age,代表客户的年龄,应用程序可按照以下方式调用存储过程:
tx = session.beginTransaction();
Connection con=session.connection();
String procedure = "{call batchUpdateCustomer(?) }";
CallableStatement cstmt = con.prepareCall(procedure);
cstmt.setInt(1,0); //把年龄参数设为0
cstmt.executeUpdate();
tx.commit();
从上面程序看出,应用程序也必须绕过Hibernate API,直接通过JDBC API来调用存储过程。
Session的各种重载形式的update()方法都一次只能更新一个对象,而delete()方法的有些重载形式允许以HQL语句作为参数,例如:
session.delete("from Customer c where c.age>0");
如果CUSTOMERS表中有1万条年龄大于零的记录,那么以上代码能删除一万条记录。但是Session的delete()方法并没有执行以下delete语句:
delete from CUSTOMERS where AGE>0;
Session的delete()方法先通过以下select语句把1万个Customer对象加载到内存中:
select * from CUSTOMERS where AGE>0;
接下来执行一万条delete语句,逐个删除Customer对象:
delete from CUSTOMERS where ID=i;
delete from CUSTOMERS where ID=j;
……
delete from CUSTOMERS where ID=k;
由此可见,直接通过Hibernate API进行批量更新和批量删除都不值得推荐。而直接通过JDBC API执行相关的SQL语句或调用相关的存储过程,是批量更新和批量删除的最佳方式,这两种方式都有以下优点:
(1) 无需把数据库中的大批量数据先加载到内存中,然后逐个更新或修改它们,因此不会消耗大量内存。
(2) 能在一条SQL语句中更新或删除大批量的数据。
1、Windows NT4.0+ORACLE 8.0.4
2、ORACLE安装路径为:C:ORANT
含义解释:
问:什么是NULL?
答:在我们不知道具体有什么数据的时候,也即未知,可以用NULL,我们称它为空,ORACLE中,含有空值的表列长度为零。
ORACLE允许任何一种数据类型的字段为空,除了以下两种情况:
1、主键字段(primary key),
2、定义时已经加了NOT NULL限制条件的字段
说明:
1、等价于没有任何值、是未知数。
2、NULL与0、空字符串、空格都不同。
3、对空值做加、减、乘、除等运算操作,结果仍为空。
4、NULL的处理使用NVL函数。
5、比较时使用关键字用“is null”和“is not null”。
6、空值不能被索引,所以查询时有些符合条件的数据可能查不出来,count(*)中,用nvl(列名,0)处理后再查。
7、排序时比其他数据都大(索引默认是降序排列,小→大),所以NULL值总是排在最后。
使用方法:
SQL> select 1 from dual where null=null;
没有查到记录
SQL> select 1 from dual where null='';
没有查到记录
SQL> select 1 from dual where ''='';
没有查到记录
SQL> select 1 from dual where null is null;
1
---------
1
SQL> select 1 from dual where nvl(null,0)=nvl(null,0);
1
---------
1
对空值做加、减、乘、除等运算操作,结果仍为空。
SQL> select 1+null from dual;
SQL> select 1-null from dual;
SQL> select 1*null from dual;
SQL> select 1/null from dual;
查询到一个记录.
注:这个记录就是SQL语句中的那个null
设置某些列为空值
update table1 set 列1=NULL where 列1 is not null;
现有一个商品销售表sale,表结构为:
month char(6) --月份
sell number(10,2) --月销售金额
create table sale (month char(6),sell number);
insert into sale values('200001',1000);
insert into sale values('200002',1100);
insert into sale values('200003',1200);
insert into sale values('200004',1300);
insert into sale values('200005',1400);
insert into sale values('200006',1500);
insert into sale values('200007',1600);
insert into sale values('200101',1100);
insert into sale values('200202',1200);
insert into sale values('200301',1300);
insert into sale values('200008',1000);
insert into sale(month) values('200009');(注意:这条记录的sell值为空)
commit;
共输入12条记录
SQL> select * from sale where sell like '%';
MONTH SELL
------ ---------
200001 1000
200002 1100
200003 1200
200004 1300
200005 1400
200006 1500
200007 1600
200101 1100
200202 1200
200301 1300
200008 1000
查询到11记录.
结果说明:
查询结果说明此SQL语句查询不出列值为NULL的字段
此时需对字段为NULL的情况另外处理。
SQL> select * from sale where sell like '%' or sell is null;
SQL> select * from sale where nvl(sell,0) like '%';
MONTH SELL
------ ---------
200001 1000
200002 1100
200003 1200
200004 1300
200005 1400
200006 1500
200007 1600
200101 1100
200202 1200
200301 1300
200008 1000
200009
查询到12记录.
Oracle的空值就是这么的用法,我们最好熟悉它的约定,以防查出的结果不正确。
以上来自http://www.cnoug.org/viewthread.php?tid=15087
但对于char 和varchar2类型的数据库字段中的null和空字符串是否有区别呢?
作一个测试:
create table test (a char(5),b char(5));
SQL> insert into test(a,b) values('1','1');
SQL> insert into test(a,b) values('2','2');
SQL> insert into test(a,b) values('3','');--按照上面的解释,b字段有值的
SQL> insert into test(a) values('4');
SQL> select * from test;
A B
---------- ----------
1 1
2 2
3
4
SQL> select * from test where b='';----按照上面的解释,应该有一条记录,但实际上没有记录
未选定行
SQL> select * from test where b is null;----按照上面的解释,应该有一跳记录,但实际上有两条记录。
A B
---------- ----------
3
4
SQL>update table test set b='' where a='2';
SQL> select * from test where b='';
未选定行
SQL> select * from test where b is null;
A B
---------- ----------
2
3
4
测试结果说明,对char和varchar2字段来说,''就是null;但对于where 条件后的'' 不是null。
对于缺省值,也是一样的!
http://yseraphi.itpub.net/post/720/114646
当页面上的控件同名且多个的时候,你首先做的是什么?判断长度?的确,从程序的严密角度出发,我们是需要判断长度,而且有长度和没长度是两种引用方法.我们来看:
oEle= document.all.aaa ;//这里有一个aaa的对象,但我们不知道它现在长度是多少,所以没办法对它操作.因此,我们要先做判断长度的过程.如下:
if(oEle.length){}else{};
在两种情况下,花括号里面的内容写法也是不一样的:
if(oEle.length){
for(var i = 0 ;i<oEle.length;i++){
oEle[i].value........
}
}
else{
oEle.value........
};
但是这样写是不是太复杂了点?而且当花括号里面的代码比较多的时候,我们要写两遍代码,晕了先~
还好有document.getElementsByName()这个方法.它对一个和多个的处理是一样的,我们可以用:
oEle = document.getElementsByName('aaa')来引用
当oEle只有1个的时候,那么就是oEle[0],有多个的时候,用下标法oEle[i]循环获取,是不是很简单?
值得一提的是它对Name和ID的同样有效的.
但是它只能应用到document对象.相对应的,还有另一个方法,可以应用的对象会更广一点:
getElementsByTagName,比如我知道了一个<DIV ID='aaa'><input/><input/>......</DIV>
我要取DIV里面的所有input,这样写就可以了:aaa.getElementsByTagName('INPUT'),这样就有效的可以和别的DIV(比如说有个叫bbb的DIV,里面的也是一样的input)相区别.
同getElementsByTagName相对应,还有一个document.body.all.tags(),能用这个方法的对象比getElementsByTagName要小得多.但比getElementsByName要多.
到这里我们还要提一下getElementById,它也是只有document对象才能使用,而且返回的是数组的第一个元素,呵呵,它的方法名都写明了是getElement而不是getElements,所以,千万不要搞浑了.
- oracle
-
- select * from table where rownum<20
- minus
- select * from table where rownum<10
-
-
- select * from (select rownum r,a.* from blog a where rownum<=20) where r>=10;
-
-
-
- mysql> SELECT * FROM table LIMIT 5,10;
-
-
- mysql> SELECT * FROM table LIMIT 95,-1;
-
-
- mysql> SELECT * FROM table LIMIT 5;
-
-
-
-
-
- mysql limit查询优化[转载],由于limit经常用到,却没有注意,因为平时做的项目都比较小,所以也没有考虑去怎么优化,今天看了一篇关于mysql limit优化的文章,感觉很好 于是转载过来
-
- 原文地址在这里
- http:
-
- MYSQL的优化是非常重要的。其他最常用也最需要优化的就是limit。mysql的limit给分页带来了极大的方便,但数据量一大的时候,limit的性能就急剧下降。
- 同样是取10条数据
-
- select * from yanxue8_visit limit 10000,10 和
-
-
-
- select * from yanxue8_visit limit 0,10
-
-
- 就不是一个数量级别的。
-
- 网上也很多关于limit的五条优化准则,都是翻译自mysql手册,虽然正确但不实用。今天发现一篇文章写了些关于limit优化的,很不错。原文地址:http:
-
- 文中不是直接使用limit,而是首先获取到offset的id然后直接使用limit size来获取数据。根据他的数据,明显要好于直接使用limit。这里我具体使用数据分两种情况进行测试。(测试环境win2033+p4双核 (3GHZ) +4G内存 mysql 5.0.19)
-
- 1、offset比较小的时候。
-
- select * from yanxue8_visit limit 10,10
-
-
- 多次运行,时间保持在0.0004-0.0005之间
-
- Select * From yanxue8_visit Where vid >=(
-
- Select vid From yanxue8_visit Order By vid limit 10,1
-
- ) limit 10
-
-
- 多次运行,时间保持在0.0005-0.0006之间,主要是0.0006
- 结论:偏移offset较小的时候,直接使用limit较优。这个显然是子查询的原因。
-
-
- 2、offset大的时候。
-
- select * from yanxue8_visit limit 10000,10
-
-
- 多次运行,时间保持在0.0187左右
-
- Select * From yanxue8_visit Where vid >=(
-
- Select vid From yanxue8_visit Order By vid limit 10000,1
-
- ) limit 10
-
-
- 多次运行,时间保持在0.0061左右,只有前者的1/3。可以预计offset越大,后者越优。
-
- 以后要注意改正自己的limit语句,优化一下mysql了
原文地址:http://www.csna.cn/viewthread.php?tid=569&sid=FbE5VS
一、 邮件传输协议简介
1. 邮件传输概念
邮件服务是Internet上最常用的服务之一,它提供了与操作系统平台无关的通信服务,使用邮件服务,用户可通过电子邮件在网络之间交换数据信息。邮件传输包括将邮件从发送者客户端发往邮件服务器,以及接收者从邮件服务器将邮件取回到接收者客户端。
2. SMTP和POP3
在TCP/IP协议簇中,一般使用SMTP协议发送邮件,POP3协议接收邮件。
SMTP,全称Simple Message Transfer Protocol,中文名为简单邮件传输协议,工作在TCP/IP层次的应用层。SMTP采用Client/Server工作模式,默认使用TCP 25端口,提供可靠的邮件发送服务。
POP3,全称Post Office Protocol 3,中文名为第三版邮局协议,工作在TCP/IP层次的应用层。POP3采用Client/Server工作模式,默认使用TCP 110端口,提供可靠的邮件接收服务。
3. SMTP和POP3的工作原理
发送和接收邮件都需要以下两个组件:用户代理(UA,常用的是Foxmail或Outlook)和SMTP/POP3服务器。
SMTP工作原理:
1) 客户端使用TCP协议连接SMTP服务器的25端口;
2) 客户端发送HELO报文将自己的域地址告诉给SMTP服务器;
3) SMTP服务器接受连接请求,向客户端发送请求账号密码的报文;
4) 客户端向SMTP服务器传送账号和密码,如果验证成功,向客户端发送一个OK命令,表示可以开始报文传输;
5) 客户端使用MAIL命令将邮件发送者的名称发送给SMTP服务器;
6) SMTP服务器发送OK命令做出响应;
7) 客户端使用RCPT命令发送邮件接收者地址,如果SMTP服务器能识别这个地址,就向客户端发送OK命令,否则拒绝这个请求;
8) 收到SMTP服务器的OK命令后,客户端使用DATA命令发送邮件的数据。
9) 客户端发送QUIT命令终止连接。
POP3工作原理:
1) 客户端使用TCP协议连接邮件服务器的110端口;
2) 客户端使用USER命令将邮箱的账号传给POP3服务器;
3) 客户端使用PASS命令将邮箱的账号传给POP3服务器;
4) 完成用户认证后,客户端使用STAT命令请求服务器返回邮箱的统计资料;
5) 客户端使用LIST命令列出服务器里邮件数量;
6) 客户端使用RETR命令接收邮件,接收一封后便使用DELE命令将邮件服务器中的邮件置为删除状态;
7) 客户端发送QUIT命令,邮件服务器将将置为删除标志的邮件删除,连接结束。
(注:客户端UA可以设定将邮件在邮件服务器上保留备份,而不将其删除。)
二、 跟踪分析Email电子邮件通讯过程
1. 分析Email的具体流程
1) 发送邮件
我们使用科来网络分析系统5.0捕获并分析一个使用SMTP协议的发送邮件过程,客户端主机名为“wangym”,客户端用户代理使用Foxmail 5.0 beta2,邮件发送者test1@colasoft.com,邮件接收者test2@colasoft.com。
在客户端主机上打开科来网络分析系统5.0。为避免数据干扰,设定一个过滤器,只捕获本机的数据通讯。
打开客户端主机上的Foxmail 5.0 beta2,新建两个邮件账户,test1@colasoft.com和test2@colasoft.com,设置好账户的SMTP/POP3服务器地址、用户名、密码等信息并测试成功。
在科来网络分析系统5.0中开始数据捕获,在Foxmail中使用test1@colasoft.com向test2@colasoft.com发送一封邮件,邮件原始信息如图1所示。发送完成后即可在科来网络分析系统5.0对刚才的邮件发送操作进行分析(为避免数据包干扰,分析时可停止捕获。)。
注意:此文里提到的发送邮件均指使用TCP 25端口的标准SMTP通信,对于非25端口的邮件发送,用户可在“工程->高级分析模块->邮件分析模块->SMTP设置->SMTP端口”处进行更改,系统默认为25,当SMTP服务器有多个端口时,多个端口之间用分号分隔,如25;125。
科来网络分析系统5.0对上面发送邮件操作的报文跟踪,详细信息如下:
A. 第1、2、3个数据包是TCP连接的三次握手数据包,连接的双方是本机与域名ns1.colasoft.com对应的IP地址;
B. 从第4个数据包开始,客户端开始通过TCP协议连接SMTP服务器,并与SMTP服务器进行命令的交互,及邮件的发送,具体的交互过程详见图3以及对图3的分析。
[attach]604[/attach]
科来网络分析系统5.0对上面发送邮件操作的TCP原始数据流重组信息。具体分析数据流重组信息,可以得到上面发送邮件操作的详细过程如下:
A. 客户端使用EHLO(或HELO)命令向SMTP服务器发送HELO报文,启动邮件传输过程,并同时将客户端地址发送SMTP服务器端,此处为wangym;
B. SMTP服务器接受了客户端的连接请求,并请求输入账号和密码进行认证;
C. 客户端向服务器端传送账号和密码;
D. SMTP服务器通过验证,客户端使用MAIL命令将邮件发送者的名称传送给SMTP服务器;
E. 客户端使用RCPT命令将邮件接收者的名称传送给SMTP服务器;
F. 客户端使用DATA命令传送邮件数据给SMTP服务器;
G. 数据传送完毕后,客户端发送QUIT命令关闭连接。
注意:
SMTP传输使用的是base64编码,图4中AUTH LOGIN下的“dGVzdDFAY29sYXNvZnQuY29t”是当前使用账号对应的base64编码;
图3所示的SMTP数据流中,客户端向SMTP服务器传送了两次发件人名称和收件人名称,可能的原因有两种:
a. 网络的延迟较大,客户端在规定时间内未收到SMTP服务器的响应,认为传送发件人名称和收件人名称的数据包丢失而进行的重传;
b. 客户端主机上的防病毒软件在邮件发送前对邮件进行的检测,如Norton Antivirus就会进行这种检测,禁用此检测功能即可避免此种情况的发生。
2) 接收邮件
我们再使用科来网络分析系统5.0捕获并分析一个使用POP3协议的接收邮件过程,客户端主机名为“wangym”,客户端用户代理使用Foxmail 5.0 beta2,邮件接收者test2@colasoft.com。
在客户端主机上打开科来网络分析系统5.0。与上面相同,设定一个过滤器,只捕获本机的数据通讯,选择高级分析模块,在邮件分析模块的常规设置中,将保存邮件选择为“是”,并选择好邮件的保存位置,如图1所示。
在科来网络分析系统5.0中开始数据捕获,同时在Foxmail中选中test2@colasoft.com,并收取邮件。接收完成后即可在科来网络分析系统5.0对刚才的邮件接收操作进行分析(为避免数据包干扰,分析时可停止捕获。)。
注意:此文里提到的接收邮件均指使用TCP 110端口的标准POP3通信,对于非110端口的邮件发送,用户可在“工程->高级分析模块->邮件分析模块->SMTP设置->POP3端口”处进行更改,系统默认为110,当SMTP服务器有多个端口时,多个端口之间用分号分隔,如110;1110。
科来网络分析系统5.0对上面接收邮件操作的报文跟踪。
A. 1、2、3数据包是TCP连接的三次握手数据包,连接的双方是本机与域名ns1.colasoft.com对应的IP地址;
B. 从第4个数据包开始,客户端开始通过TCP协议连接POP3服务器,并与POP3服务器进行命令的交互,及邮件的接收,具体的交互过程详见图4以及对图4的分析。
科来网络分析系统5.0对上面接收邮件操作的TCP原始数据流重组信息。具体分析其数据流重组信息,可以得到上面接收邮件操作的详细过程:
A. 客户端使用USER命令向POP3服务器传送用户账号test2@colasoft.com;
B. 客户端使用PASS命令向POP3服务器传送用户密码1234567890;
C. POP3服务器通过验证,向客户端发送一个OK报文;
D. 客户端使用STAT命令请求POP3服务器返回邮箱的统计资料信息,POP3服务器返回当前有一封邮件;
E. 客户端使用LIST命令列出POP3服务器里的邮件数量,当前为1封邮件;
F. 客户端使用RETR命令接收邮件,接收后使用DELE命令将邮件POP3服务器中的邮件置为删除状态;
G. 客户端发送QUIT命令,邮件服务器将将置为删除标志的邮件删除,连接结束。
注意:
POP3直接使用明文传输;
直接重组出了接收到的邮件内容,此信息不经过任何编码或加密处理,直接为明文方式,与图1所示的邮件原始信息一致。
3) SMTP/POP3命令码
通过SMTP/POP3协议进行邮件收发操作时,均通过不同的命令码进行不同的操作,现将其命令码总结如下:
SMTP命令如表1所示:
命令 作用
HELO 客户端发送此命令与SMTP服务器建立连接,将发送者邮件地址发送给SMTP服务器
MAIL 客户端将邮件发送者的名称传送给SMTP服务器
RCPT 客户端将邮件接收者的名称传送给SMTP服务器
DATA 客户端将邮件报文内容传送给SMTP服务器
SEND 用于向指定用户传送邮件
SAML/SOML 用于发送邮件
RSET 取消客户端与SMTP服务器间的当前事务,释放与当前事务相关的内存
EXPN 标识邮件接收者列表
QUIT 终止客户端与SMTP服务器间的连接
POP3命令如表2所示:
命令 作用
USER 客户端向POP3服务器传送账号
PASS 客户端向POP3服务器传送密码
STAT 客户端请求POP3服务器返回邮箱的统计信息
UIDL 客户端请求POP3服务器返回邮件的唯一标识符
LIST 客户端请求POP3服务器返回邮件数量和每封邮件的大小
RETR 客户端请求POP3服务器返回由参数标识的邮件的全部文本
DELE POP3服务器将由参数标识的邮件标记为删除
RSET POP3服务器重置所有标记为删除的邮件,用于撤消DELE命令
NOOP POP3服务器返回一个肯定的响应
QUIT 终止客户端POP3服务器间的连接
三、 总结
以上简单介绍了SMTP和POP3协议,并使用科来网络分析分析系统5.0跟踪分析了一个基于SMTP/POP3协议的邮件收发操作。据此,用户在遇到不能正常收发邮件(使用SMTP/POP3协议)的问题时,即可结合上述的SMTP/POP3相关知识,使用网络检测分析软件(这儿是科来网络分析系统5.0)对邮件接收和邮件发送的报文进行跟踪分析,以完成对此类故障的快速排查。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/hyde82/archive/2007/06/13/1650581.aspx
1.网页内容获取
java.io.inputstream in;
java.net.url url = new java.net.url(www.xyz.com/content.html);
java.net.httpurlconnection connection = (java.net.httpurlconnection)
url.openconnection();
connection = (java.net.httpurlconnection) url.openconnection();
//模拟成ie
connection.setrequestproperty("user-agent","mozilla/4.0 (compatible; msie 6.0; windows 2000)");
connection.connect();
in = connection.getinputstream();
java.io.bufferedreader breader =
new bufferedreader(new inputstreamreader(in , "gbk"));
string str=breader.readline());
while(st != null){
system.out.println(str);
str=breader.readline());
}
2.cookie管理
1.直接的方式
取得cookie:
httpurlconnection huc= (httpurlconnection) url.openconnection();
inputstream is = huc.getinputstream();
// 取得sessionid.
string cookieval = hc.getheaderfield("set-cookie");
string sessionid;
if(cookieval != null)
{
sessionid = cookieval.substring(0, cookieval.indexof(";"));
}
发送设置cookie:
httpurlconnection huc= (httpurlconnection) url.openconnection();
if(sessionid != null)
{
huc.setrequestproperty("cookie", sessionid);
}
inputstream is = huc.getinputstream();
2.利用的jcookie包(http://jcookie.sourceforge.net/ )
获取cookie:
url url = new url("http://www.site.com/");
httpurlconnection huc = (httpurlconnection) url.openconnection();
huc.connect();
inputstream is = huc.getinputstream();
client client = new client();
cookiejar cj = client.getcookies(huc);
新的请求,利用上面获取的cookie:
url = new url("http://www.site.com/");
huc = (httpurlconnection) url.openconnection();
client.setcookies(huc, cj);
3.post方式的模拟
url url = new url("www.xyz.com");
httpurlconnection huc = (httpurlconnection) url.openconnection();
//设置允许output
huc.setdooutput(true);
//设置为post方式
huc.setrequestmethod("post");
huc.setrequestproperty("user-agent","mozilla/4.7 [en] (win98; i)");
stringbuffer sb = new stringbuffer();
sb.append("username="+usernme);
sb.append("&password="+password);
//post信息
outputstream os = huc.getoutputstream();
os.write(sb.tostring().getbytes("gbk"));
os.close();
bufferedreader br = new bufferedreader(new inputstreamreader(huc.getinputstream()))
huc.connect();
string line = br.readline();
while(line != null){
l
system.out.printli(line);
line = br.readline();
}
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/hyde82/archive/2007/06/06/1640817.aspx