High Availability for the HDFS Namenode
Sanjay Radia, Suresh Srinivas
Yahoo! Inc
(本文为namdnoe HA的设计文档翻译)
1. 问题阐述
有许多方法可以改善HDFS Namednoe(NN)的可用性,包括减少启动时间,更新配置而不需要重启集群,减少升级时间与提供一个手动或自动的NN故障切换等。本文主要关注于NN的故障切换以解决NN的单点故障问题。
有许多方法用以解决NN的失败,其中包括使用共享存储,使用虚拟IP与智能客户端。 可以使用Zookeeper用于领导者选举,或者其他架构类似Linux HA。 这些不同的解决方法可以共享一些框架部件, 本文的目的是定义这些框架部件并提供一些具体设计,用以建立一个机器故障切换的解决方案,以此提供HDFS Namenode的高可用性并隔离HDFS的服务。
2. 术语
1) Active NN - 为客户端提供读写操作的服务的活动NN
2) Standby NN - 这个NN等待并当Active NN死去的时候成为active
i. BackupNode 在hadoop-0.21中可用于实现Standby的共享存储文件系统的名字空间。
3) 为了不导致混淆,我们不会使用Primary 或者 Secondary来代表Active和Standby,因为Secondary在老版本中是checkpoing 节点。
4) Hot,Warm, Cold 的故障切换,Standby NN 存储正在运行的Active的子状态 。
i. Cold Standby:Standby NN没有状态。
ii. Warm Standby:Standby 有部分状态:
1. 它已加载fsImage和editLog但是没有收到块报告;
2. 它已加载fsImage和roolled logs与所有块报告。
5) Hot Standby: Standby已经有Active的所有状态,并立刻启动。
3. 上层应用
1) 计划停机: 一个hadoop集群经常需要停止以升级软件或配置,一个4000节点的hadoop集群需要大约两个小时的时间重启。
2) 非计划停机或服务无响应: Namenode服务经常由于硬件,系统,NN进程失败或NN 进程程序几分钟无响应而出现故障, 然而这些有可能出乎意料的影响一些重要的上层应用。
以上两种情况下,一个warm或hot 故障切换可以减少停机时间, 事实上计划升级是影响HDFS服务不可用的最大因素, 因为HDFS Namenode 失败是很少的。(根据Yahoo 和Facebook的经验)。
4. 不考虑的情况
1) Active-Active NNs -我们的初始设计是一个NN成为Active而另外一个standby(warm 或hot), 可选方案是可以考虑允许Standby提供读操作。 我们认为Active-Active 需要额外的工作, 也许需要重新设计。
2) 一个名字空间多于两个NN
3) 大面积的失败,这通常叫做BCP。
5. 支持的失败情况
1) 只要单HW失败(disks,NICs,links等),两个时不进行处理,但这种情况下保证数据不会损坏。
2) 软件失败:例如NN进程失败,或者NN 进程死锁。注意系统无法恢复当standby在刚变成Active的时候出现软件失败。
3) NN GC是一个棘手的问题,如果一个NN进入GC并且不回复,它不能被认为死。
6. 需求
1) 只有一个NN处于Active
i. 只有Active能处理客户端的请求并答复。
ii. 只有Active能改变持久化状态;
iii. 可选: Standby处理读请求。
2) 第一步支持手动故障切换-一些组织希望使用故障切换仅仅在软件升级的时候,这是导致hadoop集群不可用的最大原因。、
3) 无法自动回滚,如果旧的Active重启或变成健康状态的时候。
4) 数据比可用性更重要
i. 手动或者自动故障切换不应该导致数据损坏
5) 尽量不用特殊硬件
6) HA安装和失败管理应该简单,并得防止数据损坏即使在操作失误的情况下。
7) 短时间的NN垃圾收集不应该被认为失败与触发自动故障切换。
7. 具体用例
1) 单点NN配置,没有故障切换
2) Active和Standby手动切换
i. Standby可以是cold/warm/hot
3) Active和Standby 自动切换
i. 两个NN启动,一个自动成为Active另外一个成为Standby
ii. Active 和Standby 运行着
iii. Active失败,或者不健康,Standby接替
iv. Active和Standby运行, Active 手动停机
v. Active和Standby运行,Standby失败,Active继续
vi. Active运行,Standby停机维修,Active死并无法启动,Standby启动并成为Active
vii. 两个NN启动,只有一个起来,它成为Active
viii. Active和Standby运行,Active状态未知,Standby接替。
8. 设计方案
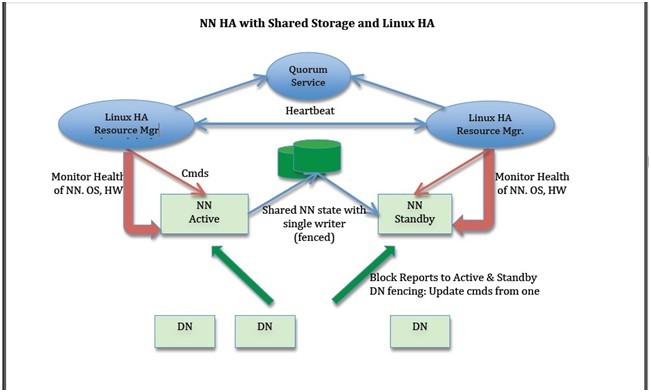
下面我们描述一些设计方案。在许多地方都有一些选择,例如:是否存储NN的实时状态,如何进行领导者选举(使用zookeeper 或者Linux HA或者其它方法),或者如何实现隔离技术。然而其余的部分很简单。下面两个图表描述使用zookeeper 和Linux HA做共享存储的整体方针;设计可以扩展到BackupNode。
NN HA with Shared Storage and Zookeeper
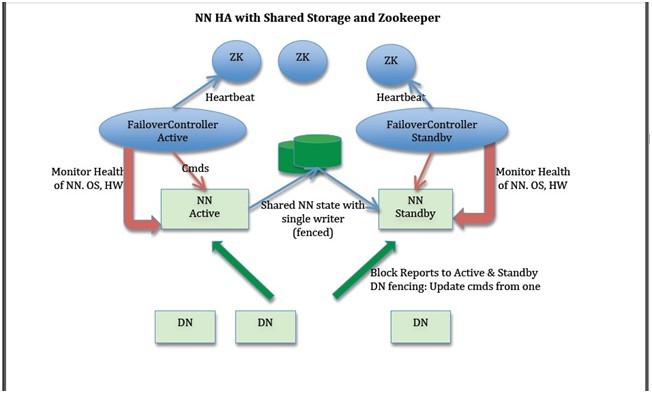
NN HA with Shared Storage and Linux HA
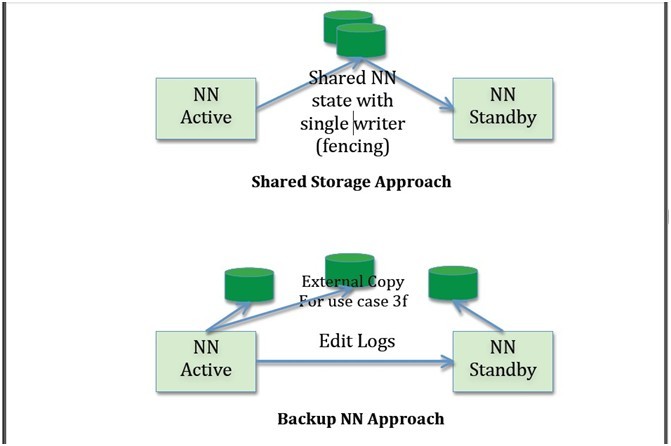
1) NN元数据的共享存储与无共享存储
Active与Standby既可以共享存储(例如NFS)或者Active把edits形成流发给Standby(就像0.21里BackupNode的实现)。其中一些考虑如下:
i. 共享存储成为单点故障,因此需要其高可用。Bookkeeper 是一个比较好的解决方法但是在prime time还未准备好,可以考虑成为长远的方法。使用bookkeeper ,NN不需要在本地磁盘保持状态,导致NN结束时‘无状态’。某些组织由于其他原因在其集群中已经存在HA NFS。
ii. BackupNode更便宜,因为它不需要使用共享服务器。然而其不支持用例的第三条。
iii. BackupNode不需要隔离技术,只要不必解决用例的第三条时。共享存储需要隔离。然而,如果我们使用Stonith来解决隔离问题,那么就能解决所有隔离需求。
iv. BackupNode不具有对称性,因此不能接替除非有Active的完整状态。
v. 当BackupNode停机时,还是依赖于remote存储以存储Active的额外状态,这就转回到了共享存储。
2) 并行块报告给Active和Atandby
我们的设计中需要并行发送块报告给Active和Standby以保证warm或hot故障切换。块报告可以直接由datanode发送,也可以通过中间层把块报告发给Active和Standby。
3) 客户端在故障切换时重定向
当Active失败时,客户端需要重新连接到新的Active,这叫做客户端故障切换。有多种方法可以实现。
i. 更改DNS的绑定:这不是一个好方法,因为操作系统以及许多库把DNS缓存着,因此不会立刻做相应的改变。
ii. 智能客户端:基于服务器的重定向,重试或者重新查找Active。
1. 注意基于服务器的重定向需要注意脑裂,无论服务器是否重定向。这种情况下一个更好的隔离方法是需要共享存储,因此只有一端可以写editlog。
2. 是否可以在HTTP或JMX下工作。
3. 故障切换时间将更长,因为在找到新NN的地址前客户端总是需要与第一个NN(有可能已经死了)交互。
iii. 使用一个负载平衡器来发送客户端的请求到正确的NN,但这在大规模的环境中(例如:10万客户端)是很困难的。
iv. IP故障切换-这在生产环境下经常用到。
1. Namenode服务器使用虚拟IP地址,虚拟IP地址被Active使用。
2. 问题:在跨交换机的环境下是否工作,是否只能在VLAN中使用。
4) 客户端在NN启动时超时
NN在某些情况下花很长时间启动,加载image,应用edits恢复块位置信息。这有可能导致客户端超时并认为NN死了。因此,当Active启动的时候,应该在客户端的请求中返回“启动中”以表示客户端应该等待。这种模式是safemode的特殊例子。
5) 故障切换控制使用独立于NN进程的故障切换控制器(Watchdog)
我们的方法是使用独立于NN进程的故障切换控制器进程。这个故障切换控制器与Linux HA的资源管理器非常相似。在基于Linux HA的解决方法中,作为其一部分的RM可以直接使用。而zookeeper ,我们可以自己写一个,或者配置Linux HA的资源管理器使用zookeeper 。
故障切换控制器执行以下功能:
i. 监控健康的NN,OS和HW,以及其他资源例如网络连接。
ii. 使用heartbeat以此选举领导者。(heartbeat发送给zookeeper,使用zookeeper 选举领导者 )
iii. 在领导选举中Active被选中。Active故障切换控制器指示其监控的NN从Standby转换为Active。(注意每个NN启动的时候都是Standby,只有在接到故障切换控制器的指示后才成为active)
使用独立的故障切换控制器进程有以下的优点:
i. 把这个功能集成到NN会导致心跳机制患上GC的失败。
ii. 故障切换控制器应该是写成紧凑的代码,从失败的应用中独立出来以增加容错。
iii. 把选举机制做成插件形式。
6) 隔离(fencing)
在 故障切换的解决方案中,保证只有一个Active实例能更新共享状态是很重要的。即使有选举机制,旧的Active有可能被隔离,不可能立刻成为 Standby,有可能继续共享共享状态。Fencing是一种阻止旧Active继续写共享存储的方法。Fencing需要Active服务不重试,在 恢复对共享存储设备的控制时通过fenced设备返回IO错误;在这种情况下旧Active应该退出并附带错误信息(成为standby不是很好)。
下面的共享资源可以考虑:
i. 作为NN元数据的共享存储器:保证只有Active写更新到edits logs。
ii. Datanode:保证只有一NN进行删除操做以移动/管理在datanode上的副本。
iii. 客户端:客户端不严格的需要NN更新的共享状态,然而客户端发送更新命令到两个NN之一。需要保证只有Active NN给客户端回复。注意如果共享存储器fencing时,如果非active NN试图写将被fenced并且这种情况下不会返回成功给客户端。
2) 其他故障切换问题
i. 故障切换时恢复租约-具体TBD。
ii. 故障切换时Pipeline恢复
2. 具体设计
1) Fencing
我们已经描述了fencing和需要fenced的共享资源/状态,以及NN应该在由于fencing写失败的时候退出的需求。
2) Fencing 包含NN元数据的共享存储
在HDFS-1073中, fsImage和EditLogs已经脱离, 因此只有editlog需要fenced. 注意, 启动一个新的NN总会启动一个新的editlog. 一个需要防止的事情是防止旧的active 继续写旧的editlog并把这个结果告诉客户端.
i. 使用NFS, fencing的解决方案需要调查.
ii. 使用Bookeeper, 当前正在与bookkeeper团队讨论增加fencing解决方案.
iii. 使用共享磁盘(SCSI 或者 SAN), 共享磁盘提供一个已经解决的 fencing解决方案, 但不适合hadoop环境.
3) Fencing Datanodes
两个解决方案:
1. 在heartbeat的答复中, NN返回自己状态: active或standby
如果DN发现状态更改, 则向ZK询问谁是active.
如果active由A改为B,然后改为A, DN应该然后能检测到.
一个更好的解决方案, 故障切换控制器告诉DN, 但是过多的DN难以等待其确认, 因此需要在协议中解决.
2.
每个NN都有一个序列号, 这个序列号在nn状态更改时传递给DN.
DN在运行时保持这个序列号, DN只听从最后一个从standby转换到active的NN.
如果一个此前active的NN重新回来(类似GC), DN将拒绝它, 因为其序列号已经过时, 另外一个新NN已经使用新的序列号代替了它.
4) Fencing 客户端
一个客户端发送更新命令到两个NN中的一个, 只有active NN回答给客户端. 这需要更深入的调查. 注意如果共享存储已经fenncing了, 那么非active NN试图写不会返回成功给客户端.
5) 使用stonith作为fencing的解决方案.
如果没有其他好的解决方案时, Stonith (Shoot the other node in the head) 经常被用于fencing解决方案, Stonith往往通过电源操作关闭其它节点.
6) 领导者选举和故障切换控制器进程
我们已经概括了把控制进程分离出来的好处, 它还有其它优势. 故障切换控制器进程在Linux HA中叫做资源管理器, zookeeper没有类似的看门狗进程, 因此建议使用LinuxHA的RM接口:
因为LinuxHA使用Linux HA 资源管理器作为故障切换控制进程.
为ookeeper写一个故障切换控制器作为测试是否健康, 直接使用Linux HA资源管理器和zookeeper, 这能有效的使用zookeeper 作为领导者选举器.
7) 故障切换控制器进程操作
i. 心跳, 用于保证active存活, 失去heartbeat时触发领导者选举.
如果是zookeeper , 故障切换控制器定期发送心跳给ZK.
LinuxHA, 其资源管理器管理发送Standby心跳的故障切换控制器.
ii. 使用故障切换控制器监控是否健康.
处理NN的状态(ps命令)
NN简单的需求(例如GC)
OS检测
Nic检测
交换机检测
iii. 故障切换控制器需要处理一系列命令, 无论是NN从Standby‐to‐Active 还是 Active‐to‐Standby. 这些操作需要配置, 例如Linux HA允许每个其管理的资源配置一系列的命令.
iv. Standby‐to‐Active过程中, 需要以下过程:
Fenced共享存储和DN(如果没有其它资源, 可以使用Stonish)
更新共享客户端地址和/或虚拟IP
告诉NN转换为active
v. Active‐to‐Standby转换中, 需要以下过程
更新客户端地址或放弃虚拟IP
告诉NN变成standby或退出, 如果NN无回应, 则kill之.
8) NN启动和Active与standby状态更改
在启动NN是进入Standby, 只在接到故障切换控制器的命令后才能转为active.
9) Standby的NN
i. 不向客户端提供服务
ii. 读取image并处理edits
iii. 接收BR并处理, 但不回复”删除”或”复制”命令给DN
10) NN变为Active
当NN变为active时: 结束处理最新的edits; 告诉客户端它在启动模式.
问题: 如果NN仅仅是从Active转换为Standby或重启.
11) 客户端重定向
我们已经概括以上两种可行的方法. TBD
12) 智能客户端
TBD描述了智能客户端的方法, 当客户端连接NN失败时通过其它服务(如zookeeper ) 寻找active. 需要讨论其利弊.
13) IP故障切换方法
生成领域标准方法, 如何工作: TBD
好处: 适合各种协议, HDFS, HTTP, JMX等
挑战: 虚拟IP跨网段.
14) 共享存储方法
Standby从共享存储器读取edits, 只有过时的写到当前未滚动的edits, 详情:TBD
Fencing已经在上文叙述
15) 非共享存储方法:使用Backup NN
描述BackupNN的工作以及这种方法: TBD
3. 附录
1) 自动故障回滚
描述问题以及其产生条件
2) 健忘症
失去已经和客户端此前的交流过的信息.
3) GC
如何区别NN不回复的时候是否是GC? 需要调查