摘要: serverStatus.pdf原文:https://docs.mongodb.com/v3.0/reference/command/serverStatus/定义serverStatusserverStatus命令用于返回数据库进程状态的概述文档. 大部分监控程序都会定期运行此命令来收集实例相关的统计信息:{ serverStatus: 1 } 其值(即上面的1)不影响命令的操作。2.4版本中修...
阅读全文
posted @
2017-06-26 21:08 胡小军 阅读(2609) |
评论 (0) |
编辑 收藏SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:

下面,将利用MySQL的客户端程序,分别测试几种隔离级别。测试数据库为test,表为tx;表结构:
两个命令行客户端分别为A,B;不断改变A的隔离级别,在B端修改数据。
(一)、将A的隔离级别设置为read uncommitted(未提交读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,事务B更新了一条记录,但是没有提交,此时事务A可以查询出未提交记录。造成脏读现象。未提交读是最低的隔离级别。
(二)、将客户端A的事务隔离级别设置为read committed(已提交读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

经过上面的实验可以得出结论,已提交读隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的数据不一致,因为在两次查询之间事务B更新了一条数据。已提交读只允许读取已提交的记录,但不要求可重复读。
(三)、将A的隔离级别设置为repeatable read(可重复读)
在B未更新数据之前:
客户端A:
B更新数据:
客户端B:

客户端A:

B插入数据:
客户端B:

客户端A:

由以上的实验可以得出结论,可重复读隔离级别只允许读取已提交记录,而且在一个事务两次读取一个记录期间,其他事务部的更新该记录。但该事务不要求与其他事务可串行化。例如,当一个事务可以找到由一个已提交事务更新的记录,但是可能产生幻读问题(注意是可能,因为数据库对隔离级别的实现有所差别)。像以上的实验,就没有出现数据幻读的问题。
(四)、将A的隔离级别设置为 可串行化 (Serializable)
A端打开事务,B端插入一条记录
事务A端:

事务B端:

因为此时事务A的隔离级别设置为serializable,开始事务后,并没有提交,所以事务B只能等待。
事务A提交事务:
事务A端

事务B端

serializable完全锁定字段,若一个事务来查询同一份数据就必须等待,直到前一个事务完成并解除锁定为止 。是完整的隔离级别,会锁定对应的数据表格,因而会有效率的问题。
转自:http://xm-king.iteye.com/blog/770721
posted @
2016-09-24 00:06 胡小军 阅读(285) |
评论 (0) |
编辑 收藏一、rsync的概述
rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync。rsync是Linux系统下的文件同步和数据传输工具,它采用“rsync”算法,可以将一个客户机和远程文件服务器之间的文件同步,也可以 在本地系统中将数据从一个分区备份到另一个分区上。如果rsync在备份过程中出现了数据传输中断,恢复后可以继续传输不一致的部分。rsync可以执行 完整备份或增量备份。它的主要特点有:
1.可以镜像保存整个目录树和文件系统;
2.可以很容易做到保持原来文件的权限、时间、软硬链接;无须特殊权限即可安装;
3.可以增量同步数据,文件传输效率高,因而同步时间短;
4.可以使用rcp、ssh等方式来传输文件,当然也可以通过直接的socket连接;
5.支持匿名传输,以方便进行网站镜象等;
6.加密传输数据,保证了数据的安全性;
二、镜像目录与内容
rsync -av duying /tmp/test
查看/tmp/test目录,我们可以看到此命令是把duying这个文件夹目录连同内容全部考到当前目录下了
rsync -av duying/ /tmp/test 注意:比上一条命令多了符号“/”
再次查看/tmp/test目录,我们发现没有duying这个目录,只是看到了目录中的内容
三、增量备份本地文件
rsync -avzrtopgL --progress /src /dst
-v是“--verbose”,即详细模式输出; -z表示“--compress”,即传输时对数据进行压缩处理;
-r表示“--recursive”,即对子目录以递归的模式处理;-t是“--time”,即保持文件时间信息;
-o表示“owner”,用来保持文件属主信息;-p是“perms”,用来保持文件权限;
-g是“group”,用来保持文件的属组信息;
--progress用于显示数据镜像同步的过程;
四、镜像同步备份文件
rsync -avzrtopg --progress --delete /src /dst
--delete选项指定以rsync服务器端为基础进行数据镜像同步,也就是要保持rsync服务器端目录与客户端目录的完全一致;
--exclude选项用于排除不需要传输的文件类型;
五、设置定时备份策略
crontab -e
30 3 * * * rsync -avzrtopg --progress --delete --exclude "*access*"
--exclude "*debug*" /src /dst
如果文件比较大,可使用nohup将进程放到后台执行。
nohup rsync -avzrtopgL --progress /data/opt /data2/ >/var/log/$(date +%Y%m%d).mail.log &
六、rsync的优点与不足
与传统的cp、tar备份方式对比,rsync具有安全性高、备份迅速、支持增量备份等优点,通过rsync可以解决对实时性要求不高的数据备份需求,例如,定期地备份文件服务器数据到远端服务器,对本地磁盘定期进行数据镜像等。
但是随着系统规模的不断扩大,rsync的缺点逐渐被暴露了出来。首先,rsync做数据同步时,需要扫描所有文件后进行对比,然后进行差量传输。如果文 件很大,扫面文件是非常耗时的,而且发生变化的文件往往是很少一部分,因此rsync是非常低效的方式。其次,rsync不能实时监测、同步数据,虽然它 可以通过Linux守护进程的方式触发同步,但是两次触发动作一定会有时间差,可能导致服务器端和客户端数据出现不一致。
转自:http://blog.sina.com.cn/s/blog_6954b9a901011esn.html
posted @
2016-09-23 22:01 胡小军 阅读(305) |
评论 (0) |
编辑 收藏 Linux下如何查看版本信息, 包括位数、版本信息以及CPU内核信息、CPU具体型号等等,整个CPU信息一目了然。
1、# uname -a (Linux查看版本当前操作系统内核信息)
Linux localhost.localdomain 2.4.20-8 #1 Thu Mar 13 17:54:28 EST 2003 i686 athlon i386 GNU/Linux
2、# cat /proc/version (Linux查看当前操作系统版本信息)
Linux version 2.4.20-8 (bhcompile@porky.devel.redhat.com)
(gcc version 3.2.2 20030222 (Red Hat Linux 3.2.2-5)) #1 Thu Mar 13 17:54:28 EST 2003
3、# cat /etc/issue 或cat /etc/redhat-release(Linux查看版本当前操作系统发行版信息)
Red Hat Linux release 9 (Shrike)
4、# cat /proc/cpuinfo (Linux查看cpu相关信息,包括型号、主频、内核信息等)
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 1
model name : AMD A4-3300M APU with Radeon(tm) HD Graphics
stepping : 0
cpu MHz : 1896.236
cache size : 1024 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 6
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr
sse sse2 syscall mmxext lm 3dnowext 3dnow
bogomips : 3774.87
5、# getconf LONG_BIT (Linux查看版本说明当前CPU运行在32bit模式下, 但不代表CPU不支持64bit)
32
6、# lsb_release -a
以上文章转载自:http://www.cnblogs.com/lanxuezaipiao/archive/2012/10/22/2732857.html
posted @
2016-09-23 21:58 胡小军 阅读(310) |
评论 (0) |
编辑 收藏
摘要: 原文:http://shiro.apache.org/reference.htmlApache Shiro介绍Apache Shiro是什么?Apache Shiro 是一个可干净处理认证,授权,企业会话管理以及加密的强大且灵活的开源安全框架.Apache Shiro的首要目标是易于使用和理解. 安全可以是非常复杂的,有时甚至是痛苦的,但它不是. 框架应该隐藏复杂的地方,暴露干净而方便的API,以...
阅读全文
posted @
2016-08-18 17:32 胡小军 阅读(2572) |
评论 (0) |
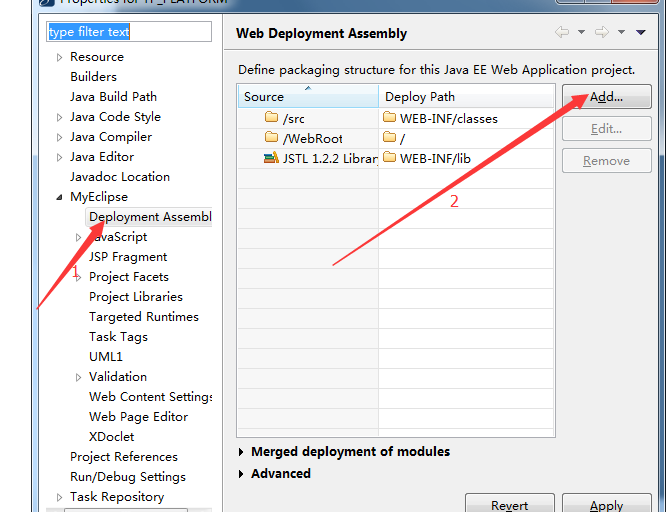
编辑 收藏- 在项目上右键进入Properties,选择Deployment Assembly,再点击Add...,如下图所示:
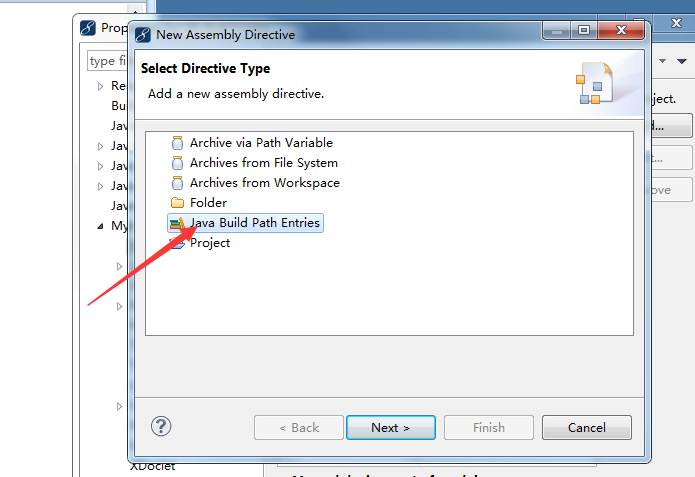
2.然后在弹出的窗口中,选择Java Build Path Entries,点击Next,如下图所示:
3.选择你要你引入的UserLibrary,点击Finish即可
注意:如果在Java Web Project引入了其它Java Project,默认引用的Java Project的编译后字节码是不会部署到WEB-INF/class下的,此时需要使用上面的Project进行导出.
posted @
2016-08-17 12:53 胡小军 阅读(2413) |
评论 (0) |
编辑 收藏介绍
除了帮助页面,所有URIs只会服务application/json类型的资源,并且需要HTTP基础认证(使用标准RabbitMQ用户数据库). 默认用户是guest/guest.
大多数URIs需要虚拟主机名称作为其路径的一部分, 因为名称是虚拟主机的唯一标识符对象. 默认虚拟主机称为"/", 它需要编码为"%2f".
PUT一个资源会对其进行创建. 你上传的JSON对象必须有某个键keys (下面文档有描述),其它的键会被忽略. 缺失键会引发错误.
在AMQP中,由于绑定没有名称或IDs,因此我们基于其所有属性人工合成了一个.
由于一般情况下很难预测这个名字, 你可以通过POST一个工厂URI来创建绑定.查看下面的例子.
注意事项
这些注意事项适用于当前管理AP的开发版本。在未来,他们将是固定的。
arguments 字段会被忽略.你不创建一个队列,交换器或使用参数进行绑定. 带有参数的队列,交换器或绑定也不会显示这些参数.- 权限偶尔才需要强制执行.如果一个用户能用HTTP API进行认证,那么它们可以做任何事情.
- 从GET请求中返回的对象中包含许多与监控相关的信息. 它们是无证实的,并且将来可能要发生变化.
示例
下面有几个快速例子,它们使用了Unix命令行工具curl:
- 获取虚拟主机列表:
$ curl -i -u guest:guest http://localhost:55672/api/vhosts
HTTP/1.1 200 OK
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Tue, 31 Aug 2010 15:46:59 GMT
Content-Type: application/json
Content-Length: 5
["/"]
- 创建一个新虚拟主机:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XPUT http://localhost:55672/api/vhosts/foo
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 16:56:00 GMT
Content-Type: application/json
Content-Length: 0
注意: 你必须将mime类型指定为application/json.
Note: 在上传的JSON对象中,对象名称是不需要的,因为它已经包含在了URI中. 由于一个虚拟主机除了名称外没有其它属性,这意味着你完全不需要指定一个body.
- 在默认虚拟主机中创建一个新的交换器:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XPUT -d'{"type":"direct","auto_delete":false,"durable":true,"arguments":[]}' \ http://localhost:55672/api/exchanges/%2f/my-new-exchange
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 17:04:29 GMT
Content-Type: application/json
Content-Length: 0注意: 在PUT或DELETE的响应中, 除非失败了,否则我们绝不会返回一个body.
- 再删除它:
$ curl -i -u guest:guest -H "content-type:application/json" \ -XDELETE http://localhost:55672/api/exchanges/%2f/my-new-exchange
HTTP/1.1 204 No Content
Server: MochiWeb/1.1 WebMachine/1.7 (participate in the frantic)
Date: Fri, 27 Aug 2010 17:05:30 GMT
Content-Type: application/json
Content-Length: 0
参考
| GET | PUT | DELETE | POST | Path | Description |
|---|
| X |
|
|
| /api/overview | 描述整个系统的各种随机信息。 |
| X |
|
|
| /api/connections | 所有打开连接的列表. |
| X |
| X |
| /api/connections/name | 一个单独的连接. DELETE它会导致连接关闭. |
| X |
|
|
| /api/channels | 所有打开通道的列表. |
| X |
|
|
| /api/channels/channel | 单个通道的详情. |
| X |
|
|
| /api/exchanges | 所有交换器的列表. |
| X |
|
|
| /api/exchanges/vhost | 指定虚拟主机中所有交换器列表. |
| X | X | X |
| /api/exchanges/vhost/name | 一个单独的交换器.要PUT一个交换器,你需要一些像下面这样的body:{"type":"direct","auto_delete":false,"durable":true,"arguments":[]} |
| X |
|
|
| /api/exchanges/vhost/name/bindings | 指定交换器中的绑定列表. |
| X |
|
|
| /api/queues | 所有队列的列表. |
| X |
|
|
| /api/queues/vhost | 指定虚拟主机中所有队列列表. |
| X | X | X |
| /api/queues/vhost/name | 一个单独队列.要PUT一个队列, 你需要一些像下面这样的body:{"auto_delete":false,"durable":true,"arguments":[]} |
| X |
|
|
| /api/queues/vhost/queue/bindings | 指定队列中的所有绑定列表. |
| X |
|
|
| /api/bindings | 所有绑定列表. |
| X |
|
|
| /api/bindings/vhost | 指定虚拟主机上的所有绑定列表. |
| X |
|
| X | /api/bindings/vhost/queue/exchange | 队列和交换器之间的所有绑定列表. 记住,队列和交换器可以绑定多次!要创建一个新绑定, POST 这个URI.你需要一些像下面这样的body:{"routing_key":"my_routing_key","arguments":[]}响应会包含一个Location header,它会告诉你新绑定的URI. |
| X | X | X |
| /api/bindings/vhost/queue/exchange/props | 队列和交换器之间的单个绑定. URI的props部分是一个名称,用于由路由键和属性组成的绑定.你可以通过PUT这个URI来创建一个绑定,它比上面POST URI更方便. |
| X |
|
|
| /api/vhosts | 所有虚拟主机列表. |
| X | X | X |
| /api/vhosts/name | 单个虚拟主机.由于虚拟主机只有一个名称,因此在PUT时不需要body. |
| X |
|
|
| /api/users | 所有用户列表. |
| X | X | X |
| /api/users/name | 单个用户. 要PUT一个用户, 你需要一些像下面这样的body:{"password":"secret"} |
| X |
|
|
| /api/users/user/permissions | 指定用户的所有权限列表. |
| X |
|
|
| /api/permissions | 所有用户的所有权限列表. |
| X | X | X |
| /api/permissions/vhost/user | 一个虚拟主机中某个用户的个人权限. 要PUT一个权限,你需要一些像下面这样的body:{"scope":"client","configure":".*","write":".*","read":".*"} |
posted @
2016-08-13 21:50 胡小军 阅读(7424) |
评论 (0) |
编辑 收藏
摘要: 3.1.15 消息监听器容器配置有相当多的配置SimpleMessageListenerContainer 相关事务和服务质量的选项,它们之间可以互相交互.当使用命名空间来配置<rabbit:listener-container/>时,下表显示了容器属性名称和它们等价的属性名称(在括号中).未被命名空间暴露的属性,以`N/A`表示.Table 3.3. 消...
阅读全文
posted @
2016-08-13 16:24 胡小军 阅读(6662) |
评论 (0) |
编辑 收藏
摘要: 3.1.10 配置broker介绍AMQP 规范描述了协议是如何用于broker中队列,交换器以及绑定上的.这些操作是从0.8规范中移植的,更高的存在于org.springframework.amqp.core包中的AmqpAdmin 接口中. 那个接口的RabbitMQ 实现是RabbitAdmin,它位于org.springframework.amqp.rabbit.core 包.A...
阅读全文
posted @
2016-08-13 16:07 胡小军 阅读(5039) |
评论 (0) |
编辑 收藏
摘要: 3.1.9 Request/Reply 消息介绍AmqpTemplate 也提供了各种各样的sendAndReceive 方法,它们接受同样的参数选项(exchange, routingKey, and Message)来执行单向发送操作. 这些方法对于request/reply 场景也是有用的,因为它们在发送前处理了必要的"reply-to"属性配置,并能通过它在专...
阅读全文
posted @
2016-08-13 15:59 胡小军 阅读(6736) |
评论 (0) |
编辑 收藏
摘要: Consumer Tags从1.4.5版本开始,你可以提供一种策略来生成consumer tags.默认情况下,consumer tag是由broker来生成的.public interface ConsumerTagStrategy { String createConsumerTag(String queue); }该队列是可用的,所以它可以(可选)在tag中使用。参考Sectio...
阅读全文
posted @
2016-08-13 12:48 胡小军 阅读(13119) |
评论 (0) |
编辑 收藏
摘要: Queue Affinity 和 LocalizedQueueConnectionFactory当在集群中使用HA队列时,为了获取最佳性能,可以希望连接到主队列所在的物理broker. 虽然CachingConnectionFactory 可以配置为使用多个broker 地址; 这会失败的,client会尝试按顺序来连接. LocalizedQueueConnectionFac...
阅读全文
posted @
2016-08-13 12:38 胡小军 阅读(6390) |
评论 (0) |
编辑 收藏
摘要: 3. 参考这部分参考文档详细描述了组成Sring AMQP的各种组件. main chapter 涵盖了开发AMQP应用程序的核心类. 这部分也包含了有关示例程序的章节.3.1 使用 Spring AMQP在本章中,我们将探索接口和类,它们是使用Spring AMQP来开发应用程序的必要组件 .3.1.1 AMQP 抽象介绍Spring ...
阅读全文
posted @
2016-08-13 12:21 胡小军 阅读(6641) |
评论 (0) |
编辑 收藏
摘要: 原文:http://docs.spring.io/spring-amqp/docs/1.6.0.RELEASE/reference/html/1. 前言Spring AMQP项目将其核心Spring概念应用于基于AMQP消息解决方案的开发中.我们提供了一个发送和接收消息的高级抽象模板.同时,我们也提供了消息驱动POJO的支持.这些包有助于AMQP资源的管理,从而提升依赖注入和声明式配置的使用. 在...
阅读全文
posted @
2016-08-13 12:03 胡小军 阅读(5984) |
评论 (0) |
编辑 收藏
摘要: 1 概述1.1 本文档的目标此文档定义了一个网络协议-高级消息队列协议(AMQP), 它使一致的客户端程序可以与一致的消息中间件服务器进行通信.我们面对的是这个领域有经验的技术读者,同时还提供了足够的规范和指南.技术工程师可以根据这些文档,在任何硬件平台上使用各种编程语言来构建遵从该协议的解决方案。1.2 摘要1.2.1 为什么使用AMQP?AMQP在一致性客户端和消息中间件(也称为"broker...
阅读全文
posted @
2016-08-12 18:30 胡小军 阅读(10974) |
评论 (0) |
编辑 收藏
摘要: 原文:http://docs.spring.io/spring/docs/current/spring-framework-reference/htmlsingle/#beans-java7.12.1 基本概念: @Bean 和 @Configuration在Spring新的Java配置支持中,其核心构件是@Configuration注解类和@Bean注解方法.@Bean 注解用来表示方...
阅读全文
posted @
2016-08-05 17:04 胡小军 阅读(2350) |
评论 (0) |
编辑 收藏