我们知道对RSS的访问,最常用的就是通过RSS Feed。也就是一个URL的链接,这个链接指向一个XML文件,在这个文件中描述了所有RSS解析器必须知道的信息
那么解析器如何读取这个XML文件并对其解析呢?特别是在当前RSS存在如此多的协议版本时。Informa的parsers包就提供了这样的功能,首先来看一下Informa能够支持的解析版本
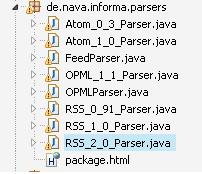
可以看到目前Informa能够支持的协议版本包括3类:
RSS 0.9.x / 2.0系
RSS 1.0系
Atom 0.3 / 1.0系
OPML 1.1
我们知道在RSS 0.9.x系协议中还包括了一些中间的版本,包括0.9.2, 0.9.3, 0.9.4等,但是目前Informa只支持0.9.1版本。根据Informa官网的文档,这里面最常用的就是FeedParser类,就先研究这个。在这个类的API说明有这样一段话:
Parser class which allows reading in of RSS news channels. The concrete rules how the XML elements map to our channel object model are delegated to version specific private classes.
从这段话就可以知道,FeedParser是一个facade类,这个类的工作就是根据读入的RSS Feed的协议系和版本“委托(delegate)”给已经硬编码的规则(concrete rules)指定的解析器,而且这些解析器是私有的。这意味着:用户不能直接调用一个诸如RSS_0_91_Parser类的实例来进行解析工作。
★FeedParser
FeedParser的一个重要工作就是加载XML解析引擎,目前比较常用的XML解析引擎有Jdom,Dom4J。Informa目前默认采用的是以Jdom为解析器。Informa允许你自行设置底层的解析器,但这个引擎必须实现SUN J2se API中的org.xml.sax.XMLReader借口。这个功能是通过方法setSaxDriverClassName来实现的。

 /** *//**
/** *//**
 * Sets the name of SAX2 Driver class to use for parsing. The class should
* Sets the name of SAX2 Driver class to use for parsing. The class should
* implement XMLReader interface and should exist in current class-loading
* paths. The method will check these conditions before accepting specified
* class name.
*
* @param className name of SAX2 Driver class.
*
* @throws ClassNotFoundException if class isn't found in the class path.
* @throws ClassCastException if class isn't implementing XMLReader interface.
 */
*/
 public static synchronized void setSaxDriverClassName(String className)
public static synchronized void setSaxDriverClassName(String className)
throws ClassNotFoundException  {
{
// Check if class is available
Class saxDriverClass = Class.forName(className);
// Check if class implements necessary XMLReader interface
Class[] extendsImplements = saxDriverClass.getInterfaces();
boolean found = false;

 for (int i = 0; !found && i < extendsImplements.length; i++) {
for (int i = 0; !found && i < extendsImplements.length; i++) {
Class parent = extendsImplements[i];
found = (parent == XMLReader.class);
 }
}
if (!found)
throw new ClassCastException("Specified class " + className
+ " does not implement XMLReader.");
saxDriverClassName = className;
}
这个方法的步骤如下:
A.接收外界传递而来的class name并加载这个类
B.通过反射得到这个类实现的所有接口
C.在循环中检查这个类是否实现了XMLReader接口
D.如果不符合条件则抛出异常
关于如何使用Java反射技术得到一个类的内部信息,请参考
Sun J2se API---反射
在加载解析器成功后,可以使用parse方法来解析不同的RSS Feed了。Informa提供了若干个重载方法
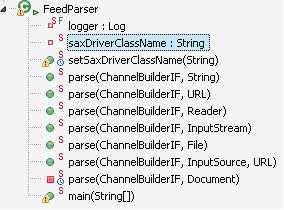 可以看到parse方法中,必须的参数有ChannelBuilder和数据源。前者是用来接收解析后的结果的,把自己作为参数注册到解析器,这样解析器在解析完后就会调用该builder来构建相应的channel object。而后者是数据源,在SUN SAX API中有一个抽象接口:InputSource,它代表了可以接受的各种XML数据源。根据规定,SAX必须支持以二进制流(stream),字符流(character),系统ID(URL)为数据源,Informa还提供了从字符串URL,文件来构建SAXBuilder的方法。
可以看到parse方法中,必须的参数有ChannelBuilder和数据源。前者是用来接收解析后的结果的,把自己作为参数注册到解析器,这样解析器在解析完后就会调用该builder来构建相应的channel object。而后者是数据源,在SUN SAX API中有一个抽象接口:InputSource,它代表了可以接受的各种XML数据源。根据规定,SAX必须支持以二进制流(stream),字符流(character),系统ID(URL)为数据源,Informa还提供了从字符串URL,文件来构建SAXBuilder的方法。
这些不同数据源的parse方法都会调用另外一个重载方法:parse(ChannelBuilderIF, InputSource, URL)。下面来看这个方法的代码
/** *//**
* Parse feed from input source with base location set and create channel.
*
* @param cBuilder specific channel builder to use.
* @param inpSource input source of data.
* @param baseLocation base location of feed.
*
* @return parsed channel.
*
* @throws IOException if IO errors occur.
* @throws ParseException if parsing is not possible.
*/
public static ChannelIF parse(ChannelBuilderIF cBuilder,
InputSource inpSource, URL baseLocation) throws IOException,
ParseException {
// document reading without validation
SAXBuilder saxBuilder = new SAXBuilder(saxDriverClassName);
// turn off DTD loading
saxBuilder.setEntityResolver(new NoOpEntityResolver());
try {
Document doc = saxBuilder.build(inpSource);
ChannelIF channel = parse(cBuilder, doc);
channel.setLocation(baseLocation);
return channel;
} catch (JDOMException e) {
throw new ParseException("Problem parsing "
+ inpSource.getSystemId() + ": " + e);
}
}
这个方法首先使用前面指定的解析器引擎来创建SAXBuilder实例,然后关闭DTD加载(节省时间),接下来读入数据源的数据,构建出一个XML Document对象。最后把channelBuilder和这个XML Document对象一起作为参数传递给另一个私有的parse方法。当解析成功后返回的channel,其中已经包含了该RSS Feed的所有信息。
那么这个私有的parse方法的作用是什么呢?其实这个方法只是简单的“检查-委托”作用
if (rootElement.startsWith("rss")) {
String rssVersion = root.getAttribute("version").getValue();
if (rssVersion.indexOf("0.91") >= 0) {
logger.info("Channel uses RSS root element (Version 0.91).");
return RSS_0_91_Parser.getInstance().parse(cBuilder, root);
} else if (rssVersion.indexOf("0.92") >= 0) {
logger.info("Channel uses RSS root element (Version 0.92).");
// logger.warn("RSS 0.92 not fully supported yet, fall back to 0.91.");
// TODO: support RSS 0.92 when aware of all subtle differences.
return RSS_0_91_Parser.getInstance().parse(cBuilder, root);
} else if (rootElement.indexOf("0.93") >= 0) {
logger.info("Channel uses RSS root element (Version 0.93).");
logger
.warn("RSS 0.93 not fully supported yet, fall back to 0.91.");
// TODO: support RSS 0.93 when aware of all subtle differences.
} else if (rootElement.indexOf("0.94") >= 0) {
logger.info("Channel uses RSS root element (Version 0.94).");
logger
.warn("RSS 0.94 not fully supported yet, will use RSS 2.0");
// TODO: support RSS 0.94 when aware of all subtle differences.
return RSS_2_0_Parser.getInstance().parse(cBuilder, root);
} else if (rssVersion.indexOf("2.0") >= 0 || rssVersion.equals("2")) {
logger.info("Channel uses RSS root element (Version 2.0).");
return RSS_2_0_Parser.getInstance().parse(cBuilder, root);
} else {
throw new UnsupportedFormatException(
"Unsupported RSS version [" + rssVersion + "].");
}
}
A.检查是否RSS 0.9.x / 2.0系协议,委托给相应的解析器
B.检查是否RSS 1.0协议,委托给对应的解析器
C.检查是否Atom 0.3 / 1.0系协议,委托给相应的解析器
D.如果都不符合则抛出异常
关于这个方法还有一个地方需要加以注意的就是它必须是同步的。因为SAX规范规定:
在解析器解析一个XML文档的过程中,不允许任何其他外部程序访问XML文档的内容,直到这个文档解析完毕。所以这个私有的parse方法的声明中加了关键字synchronized,就是为了防止多个线程在解析器还没有解析完文档后就开始访问。
-------------------------------------------------------------
生活就像打牌,不是要抓一手好牌,而是要尽力打好一手烂牌。
posted on 2009-12-29 15:56
Paul Lin 阅读(1528)
评论(0) 编辑 收藏 所属分类:
J2SE