版权信息: 可以任意转载, 转载时请务必以超链接形式标明文章原文出处, 即下面的声明.
原文出处:http://blog.chenlb.com/2009/06/java-classloader-architecture.html
jvm classLoader architecture:
- Bootstrap ClassLoader/启动类加载器
主要负责jdk_home/lib目录下的核心 api 或 -Xbootclasspath 选项指定的jar包装入工作。 - Extension ClassLoader/扩展类加载器
主要负责jdk_home/lib/ext目录下的jar包或 -Djava.ext.dirs 指定目录下的jar包装入工作。 - System ClassLoader/系统类加载器
主要负责java -classpath/-Djava.class.path所指的目录下的类与jar包装入工作。 - User Custom ClassLoader/用户自定义类加载器(java.lang.ClassLoader的子类)
在程序运行期间, 通过java.lang.ClassLoader的子类动态加载class文件, 体现java动态实时类装入特性。
类加载器的特性:
- 每个ClassLoader都维护了一份自己的名称空间, 同一个名称空间里不能出现两个同名的类。
- 为了实现java安全沙箱模型顶层的类加载器安全机制, java默认采用了 " 双亲委派的加载链 " 结构。

classloader-architecture

classloader-class-diagram
类图中, BootstrapClassLoader是一个单独的java类, 其实在这里, 不应该叫他是一个java类。因为,它已经完全不用java实现了。它是在jvm启动时, 就被构造起来的, 负责java平台核心库。
自定义类加载器加载一个类的步骤

classloader-load-class
ClassLoader 类加载逻辑分析, 以下逻辑是除 BootstrapClassLoader 外的类加载器加载流程:
- // 检查类是否已被装载过
- Class c = findLoadedClass(name);
- if (c == null ) {
- // 指定类未被装载过
- try {
- if (parent != null ) {
- // 如果父类加载器不为空, 则委派给父类加载
- c = parent.loadClass(name, false );
- } else {
- // 如果父类加载器为空, 则委派给启动类加载加载
- c = findBootstrapClass0(name);
- }
- } catch (ClassNotFoundException e) {
- // 启动类加载器或父类加载器抛出异常后, 当前类加载器将其
- // 捕获, 并通过findClass方法, 由自身加载
- c = findClass(name);
- }
- }
线程上下文类加载器
java默认的线程上下文类加载器是 系统类加载器(AppClassLoader)。
- // Now create the class loader to use to launch the application
- try {
- loader = AppClassLoader.getAppClassLoader(extcl);
- } catch (IOException e) {
- throw new InternalError(
- "Could not create application class loader" );
- }
-
- // Also set the context class loader for the primordial thread.
- Thread.currentThread().setContextClassLoader(loader);
以上代码摘自sun.misc.Launch的无参构造函数Launch()。
使用线程上下文类加载器, 可以在执行线程中, 抛弃双亲委派加载链模式, 使用线程上下文里的类加载器加载类.
典型的例子有, 通过线程上下文来加载第三方库jndi实现, 而不依赖于双亲委派.
大部分java app服务器(jboss, tomcat..)也是采用contextClassLoader来处理web服务。
还有一些采用 hotswap 特性的框架, 也使用了线程上下文类加载器, 比如 seasar (full stack framework in japenese).
线程上下文从根本解决了一般应用不能违背双亲委派模式的问题.
使java类加载体系显得更灵活.
随着多核时代的来临, 相信多线程开发将会越来越多地进入程序员的实际编码过程中. 因此,
在编写基础设施时, 通过使用线程上下文来加载类, 应该是一个很好的选择。
当然, 好东西都有利弊. 使用线程上下文加载类, 也要注意, 保证多根需要通信的线程间的类加载器应该是同一个,
防止因为不同的类加载器, 导致类型转换异常(ClassCastException)。
为什么要使用这种双亲委托模式呢?
- 因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。
- 考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时被加载,所以用户自定义类是无法加载一个自定义的ClassLoader。
java动态载入class的两种方式:
- implicit隐式,即利用实例化才载入的特性来动态载入class
- explicit显式方式,又分两种方式:
- java.lang.Class的forName()方法
- java.lang.ClassLoader的loadClass()方法
用Class.forName加载类
Class.forName使用的是被调用者的类加载器来加载类的。
这种特性, 证明了java类加载器中的名称空间是唯一的, 不会相互干扰。
即在一般情况下, 保证同一个类中所关联的其他类都是由当前类的类加载器所加载的。
- public static Class forName(String className)
- throws ClassNotFoundException {
- return forName0(className, true , ClassLoader.getCallerClassLoader());
- }
-
- /** Called after security checks have been made. */
- private static native Class forName0(String name, boolean initialize,
- ClassLoader loader)
- throws ClassNotFoundException;
上面中 ClassLoader.getCallerClassLoader 就是得到调用当前forName方法的类的类加载器
static块在什么时候执行?
- 当调用forName(String)载入class时执行,如果调用ClassLoader.loadClass并不会执行.forName(String,false,ClassLoader)时也不会执行.
- 如果载入Class时没有执行static块则在第一次实例化时执行.比如new ,Class.newInstance()操作
- static块仅执行一次
各个java类由哪些classLoader加载?
- java类可以通过实例.getClass.getClassLoader()得知
- 接口由AppClassLoader(System ClassLoader,可以由ClassLoader.getSystemClassLoader()获得实例)载入
- ClassLoader类由bootstrap loader载入
NoClassDefFoundError和ClassNotFoundException
- NoClassDefFoundError:当java源文件已编译成.class文件,但是ClassLoader在运行期间在其搜寻路径load某个类时,没有找到.class文件则报这个错
- ClassNotFoundException:试图通过一个String变量来创建一个Class类时不成功则抛出这个异常
一:quartz简介 OpenSymphony 的Quartz提供了一个比较完美的任务调度解决方案。 Quartz 是个开源的作业调度框架,定时调度器,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。
Quartz中有两个基本概念:作业和触发器。作业是能够调度的可执行任务,触发器提供了对作业的调度
二:quartz spring配置详解- 为什么不适用java.util.Timer结合java.util.TimerTask
1.主要的原因,适用不方便,特别是制定具体的年月日时分的时间,而quartz使用类似linux上的cron配置,很方便的配置每隔时间执行触发。
2.其次性能的原因,使用jdk自带的Timer不具备多线程,而quartz采用线程池,性能上比timer高出很多。
在spring里主要分为两种使用方式:第一种,也是目前使用最多的方式,spring提供的MethodInvokingJobDetailFactoryBean代理类,通过雷利类直接调用任务类的某个函数;第二种,程序里实现quartz接口,quartz通过该接口进行调度。
主要讲解通过spring提供的代理类MethodInvokingJobDetailFactoryBean 1.业务逻辑类:业务逻辑是独立的,本身就与quartz解耦的,并没有深入进去,这对业务来讲是很好的一个方式。
public class TestJobTask{ /**
*业务逻辑处理
*/ public void service(){
/**业务逻辑*/ 
..
}
}
2.增加一个线程池 <!-- 线程执行器配置,用于任务注册 --><bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
3.定义业务逻辑类
<!-- 业务对象 --><bean id="testJobTask" class="com.mike.scheduling.TestJobTask" />
4.增加quartz调用业务逻辑
<!-- 调度业务 --><bean id="jobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="testJobTask" />
<property name="targetMethod" value="service" />
</bean>
5.增加调用的触发器,触发的时间,有两种方式:
第一种触发时间,采用类似linux的cron,配置时间的表示发出丰富 <bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="cronExpression" value="10 0/1 * * * ?" />
</bean>
Cron表达式“10 */1 * * * ?”意为:从10秒开始,每1分钟执行一次 第二种,采用比较简话的方式,申明延迟时间和间隔时间
<bean id="taskTrigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="startDelay" value="10000" />
<property name="repeatInterval" value="60000" />
</bean>
延迟10秒启动,然后每隔1分钟执行一次 6.开始调用
<!-- 设置调度 --><bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger" />
</list>
</property>
<property name="taskExecutor" ref="executor" />
</bean>
7.结束:启动容器即可,已经将spring和quartz结合完毕。 Cron常用的表达式 "0 0 12 * * ?" 每天中午12点触发"0 15 10 ? * *" 每天上午10:15触发
"0 15 10 * * ?" 每天上午10:15触发
"0 15 10 * * ? *" 每天上午10:15触发
"0 15 10 * * ? 2005" 2005年的每天上午10:15触发
"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发
"0 0/5 14 * * ?" 在每天下午2点到下午2:55期间的每5分钟触发
"0 0/5 14,18 * * ?" 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发
"0 15 10 15 * ?" 每月15日上午10:15触发
"0 15 10 L * ?" 每月最后一日的上午10:15触发
"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
三:quartz原理
根据上面spring的配置,我们就比较清楚quartz的内部情况,下面我们主要详解配置涉及到的每个点 1.我们先从最后一个步骤看起,
SchedulerFactoryBean ,scheduler的工厂实现,里面可以生产出对应的多个jobDetail和trigger,每个jobDetail对应trigger代表一个任务
Quartz的SchedulerFactory是标准的工厂类,不太适合在Spring环境下使用。此外,为了保证Scheduler能够感知 Spring容器的生命周期,完成自动启动和关闭的操作,必须让Scheduler和Spring容器的生命周期相关联。以便在Spring容器启动后, Scheduler自动开始工作,而在Spring容器关闭前,自动关闭Scheduler。为此,Spring提供 SchedulerFactoryBean,这个FactoryBean大致拥有以下的功能: 1)以更具Bean风格的方式为Scheduler提供配置信息;
2)让Scheduler和Spring容器的生命周期建立关联,相生相息;
3)通过属性配置部分或全部代替Quartz自身的配置文件。
2.jobDetail,表示一个可执行的业务调用
3.trigger:调度的时间计划,什么时候,每隔多少时间可执行等时间计划
4.ThreadPoolTaskExecutor,线程池,用来并行执行每个对应的job,提高效率,这也是上面提到不推荐使用jdk自身timer的一个很重要的原因
之前有接触过hadoop,但都比较浅显,对立面的东东不是很清楚!
打算后面在hadoop上花时间把里面的内容,好好学学,这篇博客将在后面陆续更新hadoop学习笔记。
一:基本原理 主要是要实现网络之间的通讯,
网络通信需要做的就是将流从一台计算机传输到另外一台计算机,基于传输协议和网络IO来实现,其中传输协议比较出名的有http、 tcp、udp等等,http、tcp、udp都是在基于Socket概念上为某类应用场景而扩展出的传输协议,网络IO,主要有bio、nio、aio 三种方式,所有的分布式应用通讯都基于这个原理而实现。
二:实践
在分布式服务框架中,一个最基础的问题就是远程服务是怎么通讯的,在Java领域中有很多可实现远程通讯的技术:RMI、MINA、ESB、Burlap、Hessian、SOAP、EJB和JMS
既然引入出了这么多技术,那我们就顺道深入挖掘下去,了解每个技术框架背后的东西:
1.首先看RMI
RMI主要包含如下内容:
远程服务的接口定义
·远程服务接口的具体实现 ·桩(Stub)和框架(Skeleton)文件 ·一个运行远程服务的服务器 ·一个RMI命名服务,它允许客户端去发现这个远程服务 ·类文件的提供者(一个HTTP或者FTP服务器) ·一个需要这个远程服务的客户端程序 来看下基于RMI的一次完整的远程通信过程的原理:
1)客户端发起请求,请求转交至RMI客户端的stub类;
2)stub类将请求的接口、方法、参数等信息进行序列化;
3)基于tcp/ip将序列化后的流传输至服务器端;
4)服务器端接收到流后转发至相应的skelton类;
5)skelton类将请求的信息反序列化后调用实际的处理类;
6)处理类处理完毕后将结果返回给skelton类;
7)Skelton类将结果序列化,通过tcp/ip将流传送给客户端的stub;
8)stub在接收到流后反序列化,将反序列化后的Java Object返回给调用者。
RMI应用级协议内容:
基于Java串行化机制将请求的java object信息转化为流。
根据采用的协议启动相应的监听端口,当有流进入后基于Java串行化机制将流进行反序列化,并根据RMI协议获取到相应的处理对象信息,进行调用并处理,处理完毕后的结果同样基于java串行化机制进行返回。
tcp/ip。
原理讲了,开始实践:
创建RMI程序的6个步骤:
1、定义一个远程接口的接口,该接口中的每一个方法必须声明它将产生一个RemoteException异常。
2、定义一个实现该接口的类。
3、使用RMIC程序生成远程实现所需的残根和框架。
4、创建一个服务器,用于发布2中写好的类。
5. 创建一个客户程序进行RMI调用。
6、启动rmiRegistry并运行自己的远程服务器和客户程序
1)首先创建远程接口:
/**
* 远程接口
*
* @author mike
*
* @since 2012-3-14
*/
public interface Hello extends Remote {
/**
* 测试rmi
*
* @return hello
* @throws RemoteException
*/
public String hello()throws RemoteException;
}
2)创建接口实现
package com.gewara.rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
/**
* 远程接口实现
*
* @author mike
*
* @since 2012-3-14
*/
public class HelloImpl extends UnicastRemoteObject implements Hello {
/**
* seria id
*/
private static final long serialVersionUID = -7931720891757437009L;
protected HelloImpl() throws RemoteException {
super();
}
/**
* hello实现
*
* @return hello world
* @throws RemoteException
*/
public String hello() throws RemoteException {
return "hello world";
}
}
3)创建服务器端
package com.gewara.rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class Server {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* RMI Server
*/
public Server() {
try {
//创建远程对象
Hello hello=new HelloImpl();
//启动注册表
LocateRegistry.createRegistry(10009);
//将名称绑定到对象
Naming.bind(RMI_URL, hello);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param args
*/
public static void main(String[] args) {
new Server();
}
}
4)创建客服端
package com.gewara.rmi;
import java.rmi.Naming;
public class Client {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* @param args
*/
public static void main(String[] args) {
try {
String result=((Hello)Naming.lookup(RMI_URL)).hello();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5)先启动服务器端,然后再启动客户端
显示结果:hello world
由于涉及到的内容比较多,打算每一篇里讲一个远程通讯框架,继续详解RMI
三:详解RMI内部原理
1. RMI基本结构:包含两个独立的程序,服务器和客户端,服务器创建多个远程对象,让远程对象能够被引用,等待客户端调用这些远程对象的方法。客户端从服务器获取到一个或则多个远程对象的引用,然后调用远程对象方法,主要涉及到RMI接口、回调等技术。
2.RMI回调:服务器提供远程对象引用供客户端调用,客户端主动调用服务器,如果服务器主动打算调用客户端,这就叫回调。
3.命名远程对象:客户端通过一个命名或则一个查找服务找到远程服务,远程服务包含Java的命名和查找接口(Java Naming and Directory Interface)JNDI
RMI提供了一种服务:RMI注册rmiregistry,默认端口:1099,主机提供远程服务,接受服务,启动注册服务的命令:start rmiregistry
客户端使用一个静态类Naming到达RMI注册处,通过方法lookup()方法,客户来询问注册。
一:spring概要 简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
◆
控制反转——Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
◆
面向切面——Spring提供了
面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
◆
容器——Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置
原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
◆
框架——Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它们也为Spring中的各种模块提供了基础支持。
二:spring的整个生命周期 首先说一下spring的整个初始化过程,web应用中创建spring容器有两种方式: 第一种:在web.xml里直接配置spring容器,servletcontextlistener
第二种:通过load-on-startup servlet实现。
主要就说一下第一种方式:
spring提供了ServletContextListener的实现类ContextLoaderListener,该类作为listener使用,在创建时自动查找WEB-INF目录下的applicationContext.xml,该文件是默认查找的,如果只有一个就不需要配置初始化xml参数,如果需要配置,设置contextConfigLocation为application的xml文件即可。可以好好阅读一下ContextLoaderListener的源代码,就可以很清楚的知道spring的整个加载过程。
spring容器的初始化代码如下:
/** * Initialize the root web application context.
*/
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());//contextLoader初始化web应用容器
}
继续分析initWebApplicationContext做了什么事情:
/**
* Initialize Spring's web application context for the given servlet context,
* according to the "{@link #CONTEXT_CLASS_PARAM contextClass}" and
* "{@link #CONFIG_LOCATION_PARAM contextConfigLocation}" context-params.
* @param servletContext current servlet context
* @return the new WebApplicationContext
* @see #CONTEXT_CLASS_PARAM
* @see #CONFIG_LOCATION_PARAM
*/
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
//首先创建一个spring的父容器,类似根节点root容器,而且只能是一个,如果已经创建,抛出对应的异常
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);//创建通过web.xml配置的父容器
具体里面的代码是怎么实现的,就不在这里进行详解了
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
this.context = createWebApplicationContext(servletContext, parent);//主要的创建过程都在改方法内,可以自己去看源代码
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
//把spring初始好的容器加载到servletcontext内,相当于servletcontext包含webapplicationcontext
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}
看到这里基本已经清楚了整个spring容器的加载过程,如果还想了解更加深入,请查看我红色标注的方法体。
其次再说一下spring的IOC和AOP使用的场景,由于原理大家都很清楚了,那就说一下它们使用到的地方:
IOC使用的场景:
管理bean的依赖关系,目前主流的电子商务网站基本都采用spring管理业务层代码的依赖关系,包括:淘宝,支付宝,阿里巴巴,百度等公司。
一:struts2概要 以WebWork优秀设计思想为核心,吸收了struts1的部分优点。
二:struts2详解 主要就是详解struts2与struts1之间的区别,以及为什么要采用webwork重新设计新框架,以及吸收了struts1的哪部分优点。
首先将区别:- 最大的区别是与servlet成功解耦,不在依赖容器来初始化HttpServletRequest和HttpServletResponse
struts1里依赖的核心控制器为ActionServlet而struts2依赖ServletDispatcher,一个是servlet一个是filter,正是采用了filter才不至于和servlet耦合,所有的数据 都是通过拦截器来实现,如下图显示:

- web层表现层的丰富,struts2已经可以使用jsp、velocity、freemarker
- 线程模式方面:struts1的action是单例模式而且必须是线程安全或同步的,是struts2的action对每一个请求都产生一个新的实例,因此没有线程安全问 题。
- 封装请求参数:是struts1采用ActionForm封装请求参数,都必须继承ActionForm基类,而struts2通过bean的属性封装,大大降低了耦合。
- 类型转换:struts1封装的ActionForm都是String类型,采用Commons- Beanutils进行类型转换,每个类一个转换器;struts2采用OGNL进行类型转 换,支持基本数据类型和封装类型的自动转换。
- 数据校验:struts1在ActionForm中重写validate方法;struts2直接重写validate方法,直接在action里面重写即可,不需要继承任何基类,实际的调用顺序是,validate()-->execute(),会在执行execute之前调用validate,也支持xwork校验框架来校验。
其次,讲一下为什么要采用webwork来重新设计struts2
首先的从核心控制器谈起,struts2的FilterDispatcher,这里我们知道是一个filter而不是一个servlet,讲到这里很多人还不是很清楚web.xml里它们之间的联系,先简短讲一下它们的加载顺序,context-param(应用范围的初始化参数)-->listener(监听应用端的任何修改通知)-->filter(过滤)-->servlet。
filter在执行servlet之间就以及调用了,所以才有可能解脱完全依赖servlet的局面,那我们来看看这个filter做了什么事情:
/** * Process an action or handle a request a static resource.
* <p/>
* The filter tries to match the request to an action mapping.
* If mapping is found, the action processes is delegated to the dispatcher's serviceAction method.
* If action processing fails, doFilter will try to create an error page via the dispatcher.
* <p/>
* Otherwise, if the request is for a static resource,
* the resource is copied directly to the response, with the appropriate caching headers set.
* <p/>
* If the request does not match an action mapping, or a static resource page,
* then it passes through.
*
* @see javax.servlet.Filter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)
*/
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) res;
ServletContext servletContext = getServletContext();
String timerKey = "FilterDispatcher_doFilter: ";
try {
// FIXME: this should be refactored better to not duplicate work with the action invocation
ValueStack stack = dispatcher.getContainer().getInstance(ValueStackFactory.class).createValueStack();
ActionContext ctx = new ActionContext(stack.getContext());
ActionContext.setContext(ctx);
UtilTimerStack.push(timerKey);
request = prepareDispatcherAndWrapRequest(request, response);
ActionMapping mapping;
try {
mapping = actionMapper.getMapping(request, dispatcher.getConfigurationManager());
} catch (Exception ex) {
log.error("error getting ActionMapping", ex);
dispatcher.sendError(request, response, servletContext, HttpServletResponse.SC_INTERNAL_SERVER_ERROR, ex);
return;
}
if (mapping == null) {
// there is no action in this request, should we look for a static resource?
String resourcePath = RequestUtils.getServletPath(request);
if ("".equals(resourcePath) && null != request.getPathInfo()) {
resourcePath = request.getPathInfo();
}
if (staticResourceLoader.canHandle(resourcePath)) {
staticResourceLoader.findStaticResource(resourcePath, request, response);
} else {
// this is a normal request, let it pass through
chain.doFilter(request, response);
}
// The framework did its job here
return;
}
dispatcher.serviceAction(request, response, servletContext, mapping);//过滤用户请求,拦截器执行,把对应的action请求转到业务action执行 }
finally {
try {
ActionContextCleanUp.cleanUp(req);
} finally {
UtilTimerStack.pop(timerKey);
}
}
}
对应的action参数由拦截器获取。
解耦servlet是struts2采用webwork思路的最重要的一个原因,也迎合了整个技术的一个发展方向,解耦一直贯穿于整个框架。
JVM specification对JVM内存的描述
首先我们来了解JVM specification中的JVM整体架构。如下图:
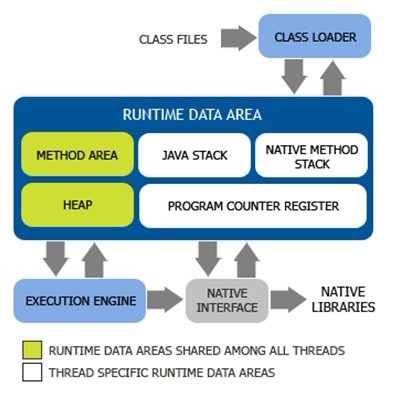
主要包括两个子系统和两个组件: Class loader(类装载器) 子系统,Execution engine(执行引擎) 子系统;Runtime data area (运行时数据区域)组件, Native interface(本地接口)组件。
Class loader子系统的作用 :根据给定的全限定名类名(如 java.lang.Object)来装载class文件的内容到 Runtime data area中的method area(方法区域)。Javsa程序员可以extends java.lang.ClassLoader类来写自己的Class loader。
Execution engine子系统的作用 :执行classes中的指令。任何JVM specification实现(JDK)的核心是Execution engine, 换句话说:Sun 的JDK 和IBM的JDK好坏主要取决于他们各自实现的Execution engine的好坏。每个运行中的线程都有一个Execution engine的实例。
Native interface组件 :与native libraries交互,是其它编程语言交互的接口。
Runtime data area 组件:这个组件就是JVM中的内存

Runtime data area 主要包括五个部分:Heap (堆), Method Area(方法区域), Java Stack(java的栈), Program Counter(程序计数器), Native method stack(本地方法栈)。Heap 和Method Area是被所有线程的共享使用的;而Java stack, Program counter 和Native method stack是以线程为粒度的,每个线程独自拥有。
Heap
Java程序在运行时创建的所有类实或数组都放在同一个堆中。而一个Java虚拟实例中只存在一个堆空间,因此所有线程都将共享这个堆。每一个java程序独占一个JVM实例,因而每个java程序都有它自己的堆空间,它们不会彼此干扰。但是同一java程序的多个线程都共享着同一个堆空间,就得考虑多线程访问对象(堆数据)的同步问题。 (这里可能出现的异常java.lang.OutOfMemoryError: Java heap space)
JVM堆一般又可以分为以下三部分:
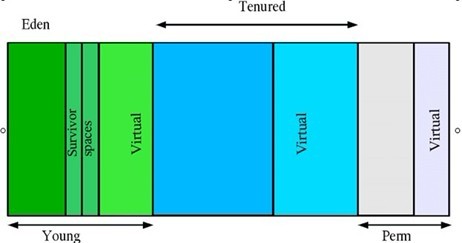
Ø Perm
Perm代主要保存class,method,filed对象,这部门的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的class没有被卸载掉,这样就造成了大量的class对象保存在了perm中,这种情况下,一般重新启动应用服务器可以解决问题。
Ø Tenured
Tenured区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在Young复制转移一定的次数以后,对象就会被转移到Tenured区,一般如果系统中用了application级别的缓存,缓存中的对象往往会被转移到这一区间。
Ø Young
Young区被划分为三部分,Eden区和两个大小严格相同的Survivor区,其中Survivor区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制对象用,在Young区间变满的时候,minor GC就会将存活的对象移到空闲的Survivor区间中,根据JVM的策略,在经过几次垃圾收集后,任然存活于Survivor的对象将被移动到Tenured区间。
Method area
在Java虚拟机中,被装载的class的信息存储在Method area的内存中。当虚拟机装载某个类型时,它使用类装载器定位相应的
class文件,然后读入这个class文件内容并把它传输到虚拟机中。紧接着虚拟机提取其中的类型信息,并将这些信息存储到方法区。该类型中的类(静态)变量同样也存储在方法区中。与Heap 一样,method area是多线程共享的,因此要考虑多线程访问的同步问题。比如,假设同时两个线程都企图访问一个名为Lava的类,而这个类还没有内装载入虚拟机,那么,这时应该只有一个线程去装载它,而另一个线程则只能等待。 (这里可能出现的异常java.lang.OutOfMemoryError: PermGen full)
Java stack
Java stack以帧为单位保存线程的运行状态。虚拟机只会直接对Java stack执行两种操作:以帧为单位的压栈或出栈。每当线程调用一个方法的时候,就对当前状态作为一个帧保存到
java stack中(压栈);当一个方法调用返回时,从java stack弹出一个帧(出栈)。栈的大小是有一定的限制,这个可能出现StackOverFlow问题。 下面的程序可以说明这个问题。
public class TestStackOverFlow {
public static void main(String[] args) {
Recursive r = new Recursive();
r.doit(10000);
// Exception in thread "main" java.lang.StackOverflowError
}
}
class Recursive {
public int doit(int t) { if (t <= 1) { return 1;
}
return t + doit(t - 1);
}
}
Program counter
每个运行中的Java程序,每一个线程都有它自己的PC寄存器,也是该线程启动时创建的。PC寄存器的内容总是指向下一条将被执行指令的饿“地址”,这里的“地址”可以是一个本地指针,也可以是在方法区中相对应于该方法起始指令的偏移量。
Native method stack
对于一个运行中的Java程序而言,它还能会用到一些跟本地方法相关的数据区。当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。本地方法可以通过本地方法接口来访问虚拟机的运行时数据区,不止与此,它还可以做任何它想做的事情。比如,可以调用寄存器,或在操作系统中分配内存等。总之,本地方法具有和JVM相同的能力和权限。 (这里出现JVM无法控制的内存溢出问题native heap OutOfMemory )
JVM提供了相应的参数来对内存大小进行配置。
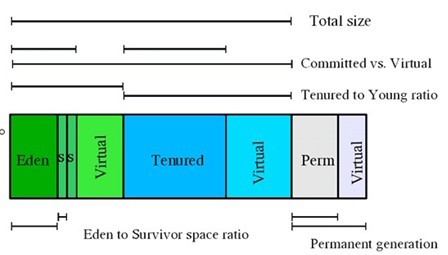
正如上面描述,JVM中堆被分为了3个大的区间,同时JVM也提供了一些选项对Young,Tenured的大小进行控制。
Ø Total Heap
-Xms :指定了JVM初始启动以后初始化内存
-Xmx:指定JVM堆得最大内存,在JVM启动以后,会分配-Xmx参数指定大小的内存给JVM,但是不一定全部使用,JVM会根据-Xms参数来调节真正用于JVM的内存
-Xmx -Xms之差就是三个Virtual空间的大小
Ø Young Generation
-XX:NewRatio=8意味着tenured 和 young的比值8:1,这样eden+2*survivor=1/9
堆内存
-XX:SurvivorRatio=32意味着eden和一个survivor的比值是32:1,这样一个Survivor就占Young区的1/34.
-Xmn 参数设置了年轻代的大小
Ø Perm Generation
-XX:PermSize=16M -XX:MaxPermSize=64M
Thread Stack
-XX:Xss=128K
1. 多线程概念:
线程是指进程中的一个执行流程,一个进程中可以运行多个线程。比如java.exe进程中可以运行很多线程。线程总是属于某个进程,进程中的多个线程共享进程的内存。
- 多线程的实现方式和启动
- 多线程是依靠什么方式解决资源竞争
- 多线程的各种状态以及优先级
- 多线程的暂停方式
2. 多线程详解 1)多线程的实现方式和启动:- 继承Thread和是实现Runnable接口,重写run方法
- 启动只有一种方式:通过start方法,虚拟机会调用run方法
2) 多线程依靠什么解决资源竞争- 锁机制:分为对象锁和类锁,在多个线程调用的情况,每个对象锁都是唯一的,只有获取了锁才能调用synchronized方法
- synchronize同步:分为同步方法和同步方法块
- 什么时候获取锁:每次调用到synchronize方法,这个时候去获取锁资源,如果线程获取到锁则别的线程只有等到同步方法介绍后,释放锁后,别的线程 才能继续使用
3)线程的几种状态- 主要分为:新状态(还没有调用start方法),可执行状态(调用start方法),阻塞状态,死亡状态
默认优先级为normal(5),优先级数值在1-10之间
4) 多线程的暂停方式- sleep:睡眠单位为毫秒
- wait,waitAll,notify,notifyAll,wait等待,只有通过wait或者waitAll唤醒
- yield:cpu暂时停用
- join