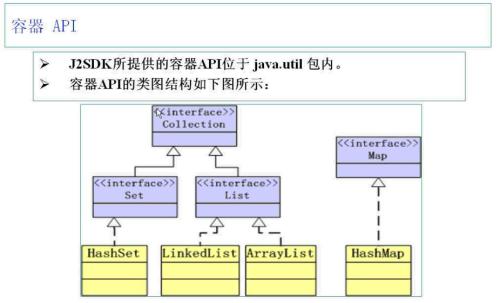
ArrayList 读快 改 慢 (底层数组实现)
LinkedList 改快 读 慢 (链表 实现)
Hash 两者之间
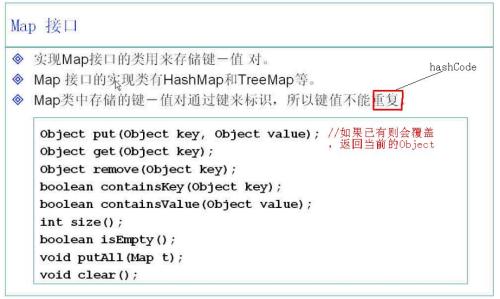
重复是指equals相同就是重复
当对象当作索引的时候(键、值):重写equals方法,必须重写hashCode方法,保证equals了,要保证hashCode也相同
Set: 没有顺序,不可以重复
List: 有顺序,可以重复
Map:一个叫键,一个值 两个两个往里面放的

Collection方法 举例子一:
package com.Collection;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionTest {
public static void main(String []args){
Collection c = new ArrayList();
c.add("hello");
c.add(new Integer(12));
c.add("lsb");
System.out.println(c.size());
System.out.println(c);
}
}
显示结果:
3
[hello, 12, lsb]
分析:打印 c 的时候调用c.toString()方法,显示的是c中的所有的内容并用[]扩住

Collection方法 举例二: Iterator
package com.Collection;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class CollectionTest {
public static void main(String []args){
Collection c = new HashSet();
c.add("hello");
c.add("abc");
c.add("lsb");
Iterator iter = c.iterator();
while(iter.hasNext()){
String str = (String)iter.next();
System.out.println(str);
}
}
}
显示结果:
hello
lsb
abc
Collection方法 举例二: Set方法
package com.Collection;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class CollectionTest {
public static void main(String []args){
Collection c1 = new HashSet();
c1.add("a");
c1.add("b");
c1.add("c");
Collection c2 = new HashSet();
c2.add("a");
c2.add("b");
c2.add("d");
Collection cn = new HashSet(c1);
cn.retainAll(c2); //取两个集合的交集
Collection cm = new HashSet(c1);
cm.addAll(c2);
System.out.println(cn);
System.out.println(cm);//取两个集合的并集
}
}
显示结果:
[a, b]
[d, a, c, b]


当对象要比较大小的时候,那要看该对象是否实现了Comparable接口,该接口中只有一个
方法public int compareTo(Object obj);(如果为jdk1.5以上那么参数为T 泛型),这样才可以比较大小与排序

MAP
下面的程序被设计用来打印它的类文件的名称。如果你不熟悉类字面常量,那么我告诉你Me.class.getName()将返回Me类完整的名称,即“com.javapuzzlers.Me”。那么,这个程序会打印出什么呢?
package com.javapuzzlers;
public class Me {
public static void main(String[] args){
System.out.println(
Me.class.getName().
replaceAll(".","/") + ".class");
}
}
该程序看起来会获得它的类名(“com.javapuzzlers.Me”),然后用“/”替换掉所有出现的字符串“.”,并在末尾追加字符串“.class”。你可能会认为该程序将打印com/javapuzzlers/Me.class,该程序正式从这个类文件中被加载的。如果你运行这个程序,就会发现它实际上打印的是///////////////////.class。到底怎么回事?难道我们是斜杠的受害者吗?
问题在于String.replaceAll接受了一个正则表达式作为它的第一个参数,而并非接受了一个字符序列字面常量。(正则表达式已经被添加到了Java平台的1.4版本中。)正则表达式“.”可以匹配任何单个的字符,因此,类名中的每一个字符都被替换成了一个斜杠,进而产生了我们看到的输出。
要想只匹配句点符号,在正则表达式中的句点必须在其前面添加一个反斜杠(")进行转义。因为反斜杠字符在字面含义的字符串中具有特殊的含义——它标识转义字符序列的开始——因此反斜杠自身必须用另一个反斜杠来转义,这样就可以产生一个转义字符序列,它可以在字面含义的字符串中生成一个反斜杠。把这些合在一起,就可以使下面的程序打印出我们所期望的com/javapuzzlers/Me.class:
package com.javapuzzlers;
public class Me {
public static void main(String[] args){
System.out.println(
Me.class.getName().replaceAll(""".","/") + ".class");
}
}
为了解决这类问题,5.0版本提供了新的静态方法java.util.regex.Pattern.quote。它接受一个字符串作为参数,并可以添加必需的转义字符,它将返回一个正则表达式字符串,该字符串将精确匹配输入的字符串。下面是使用该方法之后的程序:
package com.javapuzzlers;
import java.util.regex.Pattern;
public class Me {
public static void main(String[] args){
System.out.println(Me.class.getName().
replaceAll(Pattern.quote("."),"/") + ".class");
}
}
该程序的另一个问题是:其正确的行为是与平台相关的。并不是所有的文件系统都使用斜杠符号来分隔层次结构的文件名组成部分的。要想获取一个你正在运行的平台上的有效文件名,你应该使用正确的平台相关的分隔符号来代替斜杠符号。这正是下一个谜题所要做的。
TB_OA_DUANXIN 表中的 OADX_ID 字段为自动增长
首先创个sequence :
create sequence SEQ_TB_OA_DUANXIN
minvalue 1
maxvalue 9999999999
start with 1
increment by 1
cache 20;
再创建个触发器:
create or replace trigger TR_TB_OA_DUANXIN_ID_INC
before insert on TB_OA_DUANXIN
for each row
declare
-- local variables here
tmp NUMBER;
begin
select SEQ_TB_OA_DUANXIN.nextval into tmp from dual;
:new.OADX_ID := to_char(tmp);
end TR_TB_OA_DUANXIN_ID_INC;
需要设置server character set , database character set, client character set,如果有一个不大一样,就有可能导致乱码
。
server character set,client character set可以在mysql config文件中设置,比如设置为utf8:
vi /etc/my.cnf
# server
[mysqld]
default_character_set=utf8
# client
[mysql]
default_character_set=utf8
然后重启mysqld。设置database 字符集,可以在mysql中进行。对于新建database:
create database database_name default character set utf8;
对于已存在database:
alter database database_name default character set utf8;
改进jdbc client的字符集, 在设置连接字串时设定:如
jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8
有时候完全备份, 当还原的时候说不时数据库文件不让还原, 解决办法:
可以直接复制数据库文件, xxx.mdf 和 xxx.ldf
用 sp_attach_db 存储过程 就能搞定.
示例
下面的示例将 pubs 中的两个文件附加到当前服务器。
EXEC sp_attach_db @dbname = N'pubs',
@filename1 = N'c:\Program Files\Microsoft SQL Server\MSSQL\Data\pubs.mdf',
@filename2 = N'c:\Program Files\Microsoft SQL Server\MSSQL\Data\pubs_log.ldf'
N表示Unicode的含义,就象类型中有varchar和nvarchar一样,一个Unicode字符占两个字节.使用N'的情况主要是在双字节系统环境中强制系统对每个字符用Unicode标准来解释,否则如果你的数据库.mdf文件是中文名而又不加N'的话,数据库加载后名称可能就变成乱码,因为系统按单字节处理字符造成!
............................................................
如果确认是SQL SERVER无法启动,请按照下面步骤操作:
1.重装SQL SERVER(注意要保留原来数据库的数据库文件,日志文件可不要)
2.在SQL Analysis中用sp_attach_db将数据库加到服务器
sp_attach_db用法:
sp_attach_db
将数据库附加到服务器。
语法
sp_attach_db [ @dbname = ] 'dbname'
, [ @filename1 = ] 'filename_n' [ ,...16 ]
参数
[@dbname =] 'dbname'
要附加到服务器的数据库的名称。该名称必须是唯一的。dbname 的数据类型为 sysname,默认值为 NULL。
[@filename1 =] 'filename_n'
数据库文件的物理名称,包括路径。filename_n 的数据类型为 nvarchar(260),默认值为 NULL。最多可以指定 16 个文件名。参数名称以 @filename1 开始,递增到 @filename16。文件名列表至少必须包括主文件,主文件包含指向数据库中其它文件的系统表。该列表还必须包括数据库分离后所有被移动的文件。
返回代码值
0(成功)或 1(失败)
结果集
无
注释
只应对以前使用显式 sp_detach_db 操作从数据库服务器分离的数据库执行 sp_attach_db。如果必须指定多于 16 个文件,请使用带有 FOR ATTACH 子句的 CREATE DATABASE。
如果将数据库附加到的服务器不是该数据库从中分离的服务器,并且启用了分离的数据库以进行复制,则应该运行 sp_removedbreplication 从数据库删除复制。
权限
只有 sysadmin 和 dbcreator 固定服务器角色的成员才能执行本过程。
刚开始使用SQL Server 2000,就给了我一个下马威。不过最终还是解决了。具体情况和解决方法:
安装SQL Server 2000的操作系统是Windows 2000 Profession Edition,安装简体中文标准版。会提示该版本的操作系统不能安装服务器组件,只能安装SQL Server 2000个人版。于是退出,选择安装个人版。却出现了新的错误: “以前的某个程序安装已在安装计算机上创建挂起的文件操作。运行安装程序之前必须重新启动计算机。 ” 接着按照提示重启计算机,再安装,仍然出现同样的提示。再网上查找相关资料,得知是安装程序在先前的安装过程中在系统注册表留下某些信息,导致不能安装。于是经过多次试,发现删除掉如下键值信息即可安装:在运行窗口输入regedit,打开注册表编辑器,在HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\Session Manager中找到PendingFileRenameOperations, 删除该键值,关闭注册表编辑器。重新安装SQL Server 2000,哈哈,久违的安装界面终于浮出水面了。
这个键值是安装程序暂挂项目,只要找到对应的应用程序清除掉就行了。
原因分析:
ws2_32.dll是Windows Sockets应用程序接口,用于支持Internet和网络应用程序。程序运行时会自动调用ws2_32.dll文件,ws2_32.dll是个动态链接库文件,位于系统文件夹中,Windows在查找动态链接库文件时,会先在应用程序当前目录搜索,如果没有找到然后才会搜索Windows所在目录,如果还是没有会搜索system32和system目录。一些病毒利用此原理在杀软目录中建立了ws2_32.dll文件或文件夹,在杀软看来这是一个它需要的文件而调用,这个所谓的“文件”又不具备真正地ws2_32.dll文件所具有的功能,所以杀软就无法运行了.提示:应用程序正常初始化(0xc00000ba)失败
解决办法:
到杀毒软件的安装目录找到以"ws2_32.dll"命名的文件或文件夹,删除即可。注意:如果看不到"ws2_32.dll"文件夹,原因是该文件夹加了系统隐藏属性,即使找到"ws2_32.dll"文件夹也无法删除,原因是里面有一个名为1.的文件夹,该文件夹windows环境不能识别,因此出现系统找不到路径的提示。为此,本博发布用于清除"ws2_32.dll"文件夹的专用工具,使用方法是下载解压后将anti_ws.exe复制到杀毒软件的安装目录,然后运行anti_ws.exe即可。>>点击进入下载
友情提示:
一般只删除这个文件是解决不了问题的,因为病毒程序会监视系统,当发现该文件没了会自动恢复。目前已知的情况是中了病毒Win32.Troj.Romdrivers.ka ,请下载使用该病毒专杀工具:
http://hi.baidu.com/peaset/blog/item/82226e891f44fab20e244462.html
Spring 对AOP的支持(采用Annotation的方式)
1. spring依赖库
*SPRING_HOME/dist/spring.jar
*SPRING_HOME/lib/Jakarta-commons/commons-logging.jar
*SPRING_HOME/lib/log4j/log4j-1.2.14.jar
*SPRING_HOME/lib/aspectj/*.jar
2. 采用Aspect定义切面
3. 在Aspect定义Pointcut和Advice
4. 启用AspectJ对Annotation的支持并且将Aspect类和目标对象配置到Ioc容器中

注意:在这种方法定义中,切入点的方法是不被执行的,它存在的目的仅仅是为了重用切入点 即Advice中通过方法名引用这个切入点
AOP:
Cross cutting concern
Aspect
Advice
Pointcut
Joinpoint
Weave
Target Object
Proxy
Introduction
Spring 对AOP的支持(采用配置文件的方式)
1.spring依赖库
*SPRING_HOME/dist/spring.jar
*SPRING_HOME/lib/Jakarta-commons/commons-logging.jar
*SPRING_HOME/lib/log4j/log4j-1.2.14.jar
*SPRING_HOME/lib/aspectj/*.jar
2.配置如下:
<aop:config>
<aop:aspect id="security" ref="securityHandler">
<aop:pointcut id="allAddMethod" expression="execution(* com.lsb.spring.UserManagerImpl.add*(..))"/>
<aop:before method="checkSecurity" pointcut-ref="allAddMethod" />
</aop:aspect>
</aop:config>
Spring 对AOP的支持(JoinPoint参数介绍)
Aspect默认情况不用实现接口,但对于目标对象(UserManagerImpl.java),在默认情况下必须实现接口, 如果没有实现接口必须引入CGLIB库
我们可以通过Advice中添加一个JoinPoint参数,这个值会由spring自动传入,从JoinPoint中可以取得参数值、方法名等等
Spring 对AOP的支持
1. 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
2. 如果目标对象实现了接口,可以强制使用CGLIB实现AOP
3. 如果目标对象没有实现了接口,必须采用CGLIB库,spring会在JDK动态代理和CGLIB之间转换
4.
如何强制使用CGLIB实现AOP?
*添加CGLIB库,SPRING_HOME/lib/cglib/*.jar
*在spring配置文件中加入<aop:aspectj-autoproxy proxy-target-class="true"/>
JDK动态代理和CGLIB字节码生成的区别?
*JDK动态代理只能对实现了接口的类生成代理,而不能针对类
*CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法,因为是继承,所以该类最好不要申明成final
本书所用软件、使用版本、下载地址列表:
(1)JDK:
本书使用版本:1.5.0
官方网站:http://java.sun.com/
下载页面:http://java.sun.com/javase/downloads/index_jdk5.jsp
下载文件:jdk-1_5_0_14-windows-i586-p.exe
(2)MySQL:
本书使用版本:5.1.22
官方网站:http://www.mysql.com/
下载页面:http://dev.mysql.com/downloads/mysql/5.1.html
下载地址:http://dev.mysql.com/get/Downloads/MySQL-5.1/mysql-noinstall-5.1.22-rc-win32.zip/from/pick#mirrors
下载文件:mysql-noinstall-5.1.22-rc-win32.zip
SQL-Front客户端:
本书使用版本:3.3
官方网站:http://www.sql-front.com/
下载页面:http://www.sql-front.com/download.html
下载地址:http://www.omnipotus.com/download/SQL-Front_Setup.exe
下载文件:SQL-Front_Setup.exe
(3)Tomcat:
本书使用版本:5.5.25
官方网站:http://tomcat.apache.org/
下载页面:http://tomcat.apache.org/download-55.cgi
下载地址:http://apache.mirror.phpchina.com/tomcat/tomcat-5/v5.5.25/bin/apache-tomcat-5.5.25.exe
下载文件:apache-tomcat-5.5.25.exe
(4)Eclipse:
本书使用版本:3.1.1
官方网站:http://www.eclipse.org/
下载页面:http://archive.eclipse.org/eclipse/downloads/index.php
下载地址:http://archive.eclipse.org/eclipse/downloads/drops/R-3.1.1-200509290840/download.php?dropFile=eclipse-SDK-3.1.1-win32.zip
下载文件:eclipse-SDK-3.1.1-win32.zip
Eclipse中文语言包:
下载页面:http://archive.eclipse.org/eclipse/downloads/drops/L-3.1.1_Language_Packs-200510051300/index.php
下载文件:NLpack1_FeatureOverlay-eclipse-SDK-3.1.1.zip,NLpack1-eclipse-SDK-3.1.1a-win32.zip
MyEclipse:
本书使用版本:4.0.2
官方网站:http://www.myeclipseide.com/
下载页面:http://www.myeclipseide.com/module-htmlpages-display-pid-4.html
下载地址:http://www.myeclipseide.com/Downloads-req-getit-lid-45.html
下载文件:EnterpriseWorkbenchInstaller_4.0.2GA_E3.1.exe
(5)CVS:
本书使用版本:2.5
官方网站:http://www.cvsnt.org/
下载页面:http://www.cvsnt.org/
下载地址:http://www.march-hare.com/downloads/(S(2dgeeg55tshsv245f4oitq55))/index.aspx
下载文件:cvsnt-2.5.03.2382.msi
(6)Struts:
本书使用版本:1.2.9
官方网站:http://struts.apache.org/
下载页面:http://struts.apache.org/1.2.9/index.html
下载地址:http://archive.apache.org/dist/struts/binaries/struts-1.2.9-bin.zip
下载文件:struts-1.2.9-bin.zip
(7)Struts2:
本书使用版本:2.0.9
官方网站:http://struts.apache.org/
下载页面:http://struts.apache.org/2.0.9/index.html
下载地址:http://archive.apache.org/dist/struts/binaries/struts-2.0.9-all.zip
下载文件:struts-2.0.9-all.zip
(8)Hibernate:
本书使用版本:3.0
官方网站:http://www.hibernate.org/
下载页面:http://sourceforge.net/project/showfiles.php?group_id=40712
下载地址:http://downloads.sourceforge.net/hibernate/hibernate-3.0.zip?modtime=1112314767&big_mirror=1
下载文件:hibernate-3.0.zip
MiddleGen-Hibernate:
本书使用版本:2.1
官方网站:http://boss.bekk.no/boss/middlegen/
下载页面:http://sourceforge.net/project/showfiles.php?group_id=36044
下载地址:http://downloads.sourceforge.net/middlegen/middlegen-2.1.zip?modtime=1096973436&big_mirror=0
下载文件:middlegen-2.1.zip
(9)Spring:
本书使用版本:2.0.6
官方网站:http://www.springframework.org/
下载页面:http://www.springframework.org/download
下载地址:http://downloads.sourceforge.net/springframework/spring-framework-2.0.6.zip
下载文件:spring-framework-2.0.6.zip
(10)Ant:
本书使用版本:1.7.0
官方网站:http://ant.apache.org/
下载页面:http://ant.apache.org/bindownload.cgi
下载地址:http://apache.mirror.phpchina.com/ant/binaries/apache-ant-1.7.0-bin.zip
下载文件:apache-ant-1.7.0-bin.zip
说明:考虑到版权问题,我们只提供了这些软件的下载链接地址。这些下载地址在本书写作时都已经经过了验证确认,有些链接也许需要您注册登录后才能够下载。如果下载的链接地址不存在,则表明该网站已经移除了该链接,请您在指定的官方网站上找到下载的页面来下载对应版本的文件。
本书配套光盘包含以下目录:
1.blank目录
在该目录下包含了本书架构过程中,部署每一种技术所需要的jar、tld、xml等各种技术配置的原始文件,以"_blank"命名结尾。包括:
(1)jdbc_blank:连接MySQL的JDBC驱动程序,及数据库连接测试jsp代码;
(2)struts_blank:构建Struts环境的jar、tld、xml文件;
(3)struts2_blank:构建Struts2环境的jar、tld、xml文件;
(4)log4j_blank:构建Log4j环境的jar、properties文件;
(5)sitemesh_blank:构建Sitemesh环境的jar、tld、xml及装饰文件样例;
(6)dbcp_blank:构建DBCP环境的jar文件,及struts-config.xml连接样例;
(7)hibernate_blank:构建Hibernate环境的jar文件,及配置文件hibernate.cfg.xml、管理类文件HibernateSessionFactory.java;
(8)junit_blank:构建Junit环境的jar文件;
(9)spring_blank:构建Spring环境的jar、tld、xml文件;
在本书的案例构建过程中,将会明确说明从以上的原始目录进行环境的搭建。
2.source目录
该目录下包含了本书开发的所有架构原型程序包、系统及数据库。该目录下包含了三部分源代码:
首先是四个入门样例源代码:
(1)StrutsTest.zip:Struts快速入门样例
(2)HibernateTest.zip:Hibernate快速入门样例
(3)SpringTest.zip:Spring快速入门样例
(4)Struts2Test.zip:Struts2快速入门样例
下面为十个软件架构原型源程序包,命名中的技术是相应架构的构建技术:
(1)demo(JSP).zip
(2)demo(JSP+JavaBean).zip
(3)demo(JSP+JavaBean+Servlet).zip
(4)demo(Struts).zip
(5)demo(Struts+Hibernate).zip
(6)demo(Spring).zip
(7)demo(Sprint+Hibernate).zip
(8)demo(Struts+Spring).zip
(9)demo(Struts+Spring+Hibernate).zip
(10)demo(Struts2+Spring+Hibernate).zip
下面为开发的系统源代码:
(1)demo_ssh_address.zip:基于Struts+Spring+Hibernate的个人通讯录系统
(2)demo_ssh_oa.zip:基于Struts+Spring+Hibernate的办公自动化系统
(3)demo_ssh2_oa.zip:基于Struts2+Spring+Hibernate的办公自动化系统
另外,database.zip为上面的系统所使用的MySQL数据库文件及其建表SQL。
提示:source目录中共提供了4个入门样例、10个架构原型包、3个OA程序包,并包含数据库的脚本database.zip。读者在按照1.4节配置好MTEC的开发环境后,可以使用下面的方法运行这17个程序:首先将要运行的程序包解压缩到Eclipse的工作目录(如D:\eclipse\workspace),单击Eclipse左侧的项目工作区空白处,单击鼠标右键,在弹出的右键菜单中选择"导入",然后在弹出的导入窗口中选择"从现有项目到工作空间中",并选择刚才解压缩后的程序目录,单击"确定"即可导入到Eclipse中。
hibernate 二级缓存:(缓存的是实体对象,二级缓存是放变化不是很大的数据)


二级缓存也称进程级的缓存或SessionFactory级的缓存,而二级缓存可以被所有的session(hibernate中的)共享二级缓存的生命周期和SessionFactory的生命周期一致,SessionFactory可以管理二级缓存
二级缓存的配置和使用:
1.将echcache.xml文件拷贝到src下, 二级缓存hibernate默认是开启的,手动开启
2.开启二级缓存,修改hibernate.cfg.xml文件,
<property name=”hibernate.cache.user_second_level_cache”>true</property>
3.指定缓存产品提供商
<property name=”hibernate.cache.provider_calss”>org.hibernate.cache.EhCacheProvider</property>
4.指定那些实体类使用二级缓存(两种方法,推荐使用第二种)
第一种:在*.hbm.xml中,在<id>之前加入
<cache usage=”read-only” />, 使用二级缓存
第二种:在hibernate.cfg.xml配置文件中,在<mapping resource=”com/Studnet.hbm.xml” />后面加上:
<class-cache class=” com.Studnet” usage=”read-only” />
二级缓存是缓存实体对象的
了解一级缓存和二级缓存的交互
测试二级缓存:
一.开启两个session中发出两次load查询(get与load一样,同样不会查询数据库),
Student sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
sessioin.close();
………..
sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
开启两个session中发出两次load查询,第一次load的时候不会去查询数据库,因为他是LAZY的,当使用的时候才去查询数据库, 第二次load的时候也不会,当使用的时候查询数据库,开启了二级缓存,也不会查询数据库。
二.开启两个session,分别调用load,再使用sessionFactory清楚二级缓存
Student sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
sessioin.close();
………..
SessionFactory factory = HibernateUtil.getSessionFactory();
//factory.evict(Student.class); //清除所有Student对象
Factory.evict(Student.class,1); //清除指定id=1 的对象
sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
开启两个session中发出两次load查询,第一次load的时候不会去查询数据库,因为他是LAZY的,当使用的时候才去查询数据库, 第二次load的时候也不会,当使用的时候查询数据库,它要查询数据库,因为二级缓存中被清除了
三.一级缓存和二级缓存的交互
session.setCacheMode(CacheMode.GET); //设置成 只是从二级缓存里读,不向二级缓存里写数据
Student sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
sessioin.close();
………..
SessionFactory factory = HibernateUtil.getSessionFactory();
//factory.evict(Student.class); //清除所有Student对象
Factory.evict(Student.class,1); //清除指定id=1 的对象
sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
开启两个session中发出两次load查询,第一次load的时候不会去查询数据库,因为他是LAZY的,当使用的时候才去查询数据库, 第二次load的时候也不会,当使用的时候查询数据库,它要查询数据库,因为 设置了CacheMode为GET,(load设置成不能往二级缓冲中写数据), 所以二级缓冲中没有数据
session.setCacheMode(CacheMode.PUT); //设置成只是向二级缓存里写数据,不读数据
Student sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
sessioin.close();
………..
SessionFactory factory = HibernateUtil.getSessionFactory();
//factory.evict(Student.class); //清除所有Student对象
Factory.evict(Student.class,1); //清除指定id=1 的对象
sutdent = (Student)session.load(Student.class,1);
System.out.println(student.getName());
开启两个session中发出两次load查询,第一次load的时候不会去查询数据库,因为他是LAZY的,当使用的时候才去查询数据库, 第二次load的时候也不会,当使用的时候查询数据库,它要查询数据库,因为设置了CacheMode为POST,(load设置成只是向二级缓存里写数据,不读数据)