1.马尔可夫
2.GBDT,随机森林
3.SVD,LDA等理论
4.上述理论的工具使用
5.网络可视化工具的调研
暂时就想到这些,到时候再补充~
posted @
2012-02-29 10:16 Seraphi 阅读(254) |
评论 (0) |
编辑 收藏Apriori算法乃是关联规则挖掘的经典算法,尽管是94年提出的算法,然而至今也有着旺盛的生命力。在互联网科学领域,也有着广泛的应用,因此还是值得大家都对此学习一下。
一、术语
1.支持度:support,所有实例中覆盖某一项集的实例数。
2.置信度:confidence。对于X→Y这个规则,如果数据库的包含X的实例数的c%也包含Y,则X→Y的置信度为c%。
3.频繁项集:也称large itemsets,指支持度大于minsup(最小支持度)的项集
二、思想
1.Apriori算法思想与其它关联规则挖掘算法在某些方面是相同的。即首先找出所有的频繁项集,然后从频繁项集中抽取出规则,再从规则中将置信度小于最小置信度的规则剃除掉。
2.若项集i为频繁项集,则其所有子集必为频繁项集。因此,Apriori算法思想在于从频繁的k-1项集中合并出k项集,然后剃除掉子集有不是频繁项集的k项集。
3.先从数据库中读出每条实例,对于设定阈值,选出频繁1项集,然后从频繁1项集中合并,并剃除掉包含非频繁1项集子集的2项集……
4.符号说明:
L
k:Set of large(frequent) k-itemsets
C
k:Set of candidate k-itemsets
apriori-gen()函数通过合并k-1的频繁项集,生成C
k
三、算法描述
1) Apriori基本算法
1
 L1={large 1-itemsets};
L1={large 1-itemsets};
2 for(k=2;Lk-1!=Φ;k++)
for(k=2;Lk-1!=Φ;k++)
3{
4 Ck=apriori-gen(Lk-1);
Ck=apriori-gen(Lk-1);
5 for(all transaction t∈D)
6
 {
{
7 Ct=subset(Ck,t);
8 for(all candidates c∈Ct)
9 c.count++;
10 }
}
11 Lk={c∈Ck|c.count>=minsup}
12 }
}
13Answer=∪k Lk; 2)apriori-gen()函数
这个函数将L
k-1(即所有k-1频繁项集的集合)作为参数,返回一个L
k的超集(即C
k)
算法如下:
1insert into Ck
2select p.item1, p.item2,  ,p.itemk-1,q.itemk-1
,p.itemk-1,q.itemk-1
3from Lk-1 p, Lk-1 q
4where p.item1=q.item1, p.item2=q.item2, , p.itemk-1<q.itemk-1 然后通过剪枝,剃除掉C
k中某些子集不为频繁k-1项集的项集,算法如下:
1for(all items c∈C
k)
3)从频繁项集中生成规则
1 for(all l
for(all l∈Answer)
2 {
{
3 A=set of nonempty-subset(l);
A=set of nonempty-subset(l);
4 for(all a∈A)
5 {
{
6 output a→(l-a);
7 }
}
8 }
} 四、举例(这里将minsup=1,mincof=0.5)
L3={{1 2 3}{1 2 4}{1 3 4}{1 3 5}{2 3 4}}
在合并步骤时,选取L3中,前两个项都相同,第三个项不同的项集合并,如{1 2 3}与{1 2 4}合并、{1 3 4}与{1 3 5}合并成{1 2 3 4}和{1 3 4 5}。因此,C4={{1 2 3 4}{1 3 4 5}},但是由于{1 3 4 5}中某子集{3 4 5}并未在L3中出现,因此,将{1 3 4 5}剃除掉,所以L4={{1 2 3 4}}。
然后以L4为例,选取出关联的规则:
L4中{1 2 3 4}项集中抽取出(这里只列出左边为3项的情况):
{1 2 3}→4
{1 2 4}→3
{1 3 4}→2
{2 3 4}→1
显然,因为只有一个4项集,因此,这四条规则的置信度都为100%。因此,全数为关联规则。
五、Apriori变体
有些Apriori变体为追求时间效率,不是从L
1→C
2→L
2→C
3→....的步骤产生,而是从L
1→C
2→C
3'..产生。
参考文献:
Agrawal, Rakesh, Srikant, Ramakrishnan. Fast algorithms for mining association rules in large databases. Very Large Data Bases, International Conference Proceedings, p 487, 1994 posted @
2012-02-27 13:08 Seraphi 阅读(792) |
评论 (0) |
编辑 收藏本文要解决的主要问题是社交网络中的标签推荐(本文主要为音乐、视频等多媒体对象推荐合适的标签)。较之以前的推荐策略——a.根据已有标签进行词语共现的推荐; b.根据文本特征(如标题、描述)来推荐; c.利用标签相关性度量来推荐。大部分仅仅至多使用了上述的两种策略,然而本文将3种特征全部结合,并提出一些启发式的度量和两种排序学习(L2R)的方法,使得标签推荐的效果(p@5)有了显著的提高。
问题陈述:作者将数据集分为三类:train, validation, test。对于训练集D,包含<L
d,F
d>。L
d指对象d的所有标签集;F
d指d的文本特征集(即L
d=L
1d∪L2d∪L
3d...L
nd,F
d=F
1d∪ F
2d∪ F
3d....F
nd)。对于验证集和测试集,由三部分组成<L
o,F
o,y
o>。L
o为已知标签,y
o为答案标签,实验中作者将一部分标签划分L
o,一部分为y
o,这样做可以方便系统自动评价推荐性能。
Metrics说明:(1)Tag Co-occurrence:基于共现方法的标签推荐主要是利用了关联规则(association rules),如X→y,X为前导标签集,y为根据X(经过统计)得到的标签。还要提到两个参数:support(
σ),意为X,y在训练集中共现的次数,confidence(
θ)=p(y与object o相关联|X与object o相关联)。由于从训练集中得到的规则很多,因此要设定σ 、θ 的最小阈值,只选取最为频繁发生、最可靠的共现信息。
Sum(c,o,l)=
ΣX⊆L0 θ(X→c), (X→c)
∈R, |X|≤l
(2)Discriminative Power: 指区分度,对于一个频繁出现的标签特征,区分度会很低。作者提出一个IFF度量(类似于IR中的IDF),定义如下:
IFF(c)=log[(|D|+1)/(fctag+1)]
其中f
ctag为训练集D中,以c作为标签者的对象数。
尽管这个度量可能偏重于一些并未在训练集中出现作为标签的词语,然而在排序函数中,它的权重会被合理安排。
另外,过于频繁的标签和过于稀少的标签都不会是合理的推荐,而那些频率中等的term则最受青睐。有一种Stability(Stab)度量倾向于频率适中的词语:
Stab(c,k
s)=k
s/[k
s+|k
s-log(f
ctag)|] , 其中k
s表示term的理想频率,要根据数据集来调整。
(3)Descriptive Power
指对于一个侯选c的描述能力,主要有如下4种度量
:①TF: TF(c,o)=
ΣFoi∈Fo tf(c,Foi)②TS: TS(c,o)=
ΣFoi∈Fo j, where j=1 (if c
∈Foi )
, otherwise j=0③wTS:wTS(c,o)=
ΣFoi∈Fo j, where j=AFS(F
i) (if c∈
Foi )
, otherwise j=0 ④wTF:wTS(c,o)=
ΣFoi∈Fo tf(c,Foi), where j=AFS(F
i) (if c∈
Foi )
, otherwise j=0 这里要引入两个概念:
FIS:Feature Instance spread. FIS(F
oi) 为F
oi中所有的term的平无数TS值。
AFS:Average Feature Spread:AFS(F
i)为训练集中所有对象的平均FIS(F
oi),即
AFS(F
i)=
Σoj∈D FIS(Foji)/|D|
(4)词项预测度
Heymann et al.[11]通过词项的熵来度量这个特征。
词项c在标签特征的熵值H
tags(c)=-
Σ(c→i)∈R θ(c→i)logθ(c→i) ,其中R为训练集中的规则集。
标签推荐策略:(1)几个先进的baseline:
① Sum
+:扩展了Sum度量,通过相应关联规则的前导和后继中的词项的Stablity为Confidence赋予权重。给定一个对象o的侯选标签c,Sum
+定义如下:
Sum
+(c,o,k
x,k
c,k
r)=
Σx∈L
0 θ(x→c)*Stab(x,kx)*Stab(c,kc)*Rank(c,o,kr)
其中:k
x,k
c,k
r为调节参数,Rank(c,o,k
r)=k
r/[k
r+p(c,o), p(c,o)为c在这个关联规则中confidence排名的位置,这个值可以使Confidence值更为平滑地衰减。Sum
+限制了前导中的标签数为1。
② LATRE(Lazy Associative Tag Recommendation):与Sum
+不同,LATRE可以在立即请求的方式快速生成更大的关联规则,这与其它策略不同(因为它们都是事先在训练集中计算好所有的规则),但也可能包含一些在测试集中并不是很有用的规则。 LATRE排序每个侯选c,通过相加所有包含c的规则的confidence值。
③ CTTR(Co-occurrence and Text based Tag Recommender):利用了从文本域特征中抽取出的词项和一个相关性度量,但所有考虑事先已经赋给对象o的标签。作者对比CTTR与作者的方法,评价了作者自创几个度量和应用事先预有标签的有效性,篇幅有限,不再对此详述。
(2) New Heuristics
8种,作者扩展了Sum
+和LATRE baseline加入了描述性度量(TS,TF,wTS,wTF),共合成了8种方案。
Sum
+DP(c,o,k
x,k
c,k
r,
α)=αSum
+(c,o,k
x,k
c,k
r)+(1-α)DP(c,o)
LATRE
+DP(c,o,l,α)=αSum(c,o,l)+(1-α)DP(c,o)
(3)排序学习策略:
对一个Metric矩阵(对于侯选c)M
c∈Rm,m是考虑的metric数,即矩阵的维数。然后验证集V的对象v赋一个Y
c,若c为v的合理推荐,Y
c=1,否则Y
c=0。因为训练集用来抽取关联规则和计算metrics,验证集用来学习solutions,因此只对验证集赋Y
c。学习模型,即排序函数f(M
c)将被用于测试集:
① RankSVM:作者使用SVM-rank tool学习一个函数f(M
c)=f(W,M
c),其中W=<w
1,w
2,....,w
m>是一个对metrics赋权值的向量。其中,RankSVM有两个参数,kernel function和cost j。
② 遗传算法:
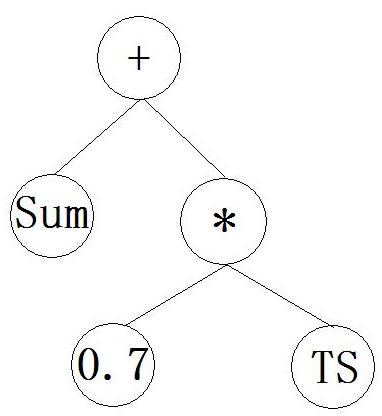
这里将个体(即标签排序函数)看成一个树表示,叶子结点为变量或常数。树内结点为基本运算符(+,-,*,/,ln)。若域超出运算范围,结果默认为0。例如,一个树表示函数:Sum+0.7*TS,如下图:
个体的健壮度(Fitness)表示相应排序函数的推荐质量,本文以P@k为衡量标准给定f(M
c),y
o是o的相关标签,R
of是通过f(M
c)排序后的o的推荐结果,R
k,of的R
of中前k个结果,推荐质量定义如下:
P@k(R
of,y
o,f)=|R
k,of∩yo|/min(k,|y
o|)
实验评价:(1)数据收集:LastFM, Youtube, YahooVideo。 然后去停用词,词干化处理(Poster Stemmer)
(2)评价方法:
a.将object预先的一些标签一部分作为已经,一部分作为答案,方便评价,某些生成的答案,并不能在答案集中,但并不意味不相关,因此可作为lower bound。
b.在实际实验中,作者将验证集和测试集的对象标签平均分为L
o,y
o,使用title和description作为文本特征F
o。
c.在评价指标上,主要使用P@5,并用了Recall和MAP值
d.以两种方案来对各种推荐方法评价:
① 把每个数据集分为3份,对应小规模,中规模,大规模,以便针对每种情况,调整参数,评价不同规模下各方法的效果
② 利用整个数据集,统一的评价
这两种方案,①更加有针对性,②则代价较低
对于第一个方案,作者随机从每个子集(大、中、小规模)中选取50000个样本,对于第二种方案,作者使用第一个方案选取出的3个样本集组合的样本。这两种方案都把每个样本集分为5份来做5折交叉验证。3/5做训练,1/5做验证,1/5做测试。之所以在验证集上做L2R是为了避免过拟合。
(3)参数设定
① Sum
+DP中,k
r=k
x=k
c=5,
α=[0.7,1.0]
② LATRE
+DP和L2R中,l=3, k
s=5。在确定
σmin和θmin时,将值设定为与σ
min和θ
min=0相比,结果下降小于3%的值
③ RankSVM中,选定线性核,cost j=100
④ 归一化特征向量结果不明显,因此本文并没有采取特征向量归一化。
(4)实验结果:
a. LastFM上提升较小,原因有二:① 有LastFM上标签、标题、描述内容重叠少,使TS,wTS集中在小值上,使得难以区别good,bad;② LastFM上对象标签较少,使TS,wTS难以发挥较好作用。
b. LATRE在大部分情况,好于Sum
+,而CTTR在一些情况好于LATRE。尤其是在Youtube。
c. 对比每个方案和数据集,作者的heuristics都有较大提升,因此引入描述性度量(descriptive power)会显著提高推荐效果,尤其是标签数较少的情况(因为共现效果差)
d. 比较Sum+, LATRE, CTTR。作者的8种启发式护展都有不小的提升(LastFM最小),证实了利用预先已知标签和描述度量的作用。
e. 新启发思想中,LATRE+wTS在大多数情况最好。在DP确定下,LATRE通常好于Sum+;DP变时,wTS最好,其实是wTF,TS。
f. L2R中,两种方法都有提升,但提升幅度有限,观察发现,GP和SVMRank主要利用的还是LATRE+wTS的metrics,GP中最常用的是Sum(c,o,3),然后是wTS,再是IFF,其它少于这些函数的25%。RankSVM中,最高权重主要还是集中于Sum,wTS。
g.尽管L2R效果提升不明显,但框架灵活,易于扩展(加入新度量和tag recommender问题,如个性化)
h.对于SVMRank和GP的比较,效果好坏主要取决于数据集。
论文:Fabiano Belem, Eder Martins, Tatiana Pontes, Jussara Almeida, Marcos Goncalves. Associative Tag Recommendation Exploiting Multiple Textual Features.
Proceedings of the 34th international ACM SIGIR conference on Research and development in Information, Jul. 2011. 论文链接:SIGIR2011_Associative_Tag_Recommendation_Exploiting_Multiple_Textual_Features.pdf
posted @
2012-02-24 13:05 Seraphi 阅读(712) |
评论 (0) |
编辑 收藏大致内容:
本文在political affilication(民主党,共和党), ethnicity identification(African Americans)和affinity for a particular business(星巴克)三个任务上,对user进行二元分类
相关参考资源:
Bing Social
Klout
Twitter's "Who to Follow"
Google's "Follow Finder"
用户的profile可被用来自动匹配相似用户,也可以通过profile显式表达去推荐
GBDT(Gradient Boosted Decision Tree)
avatar 头像
本文思想及实现:
对用户分类,用到两类信息:
(1)user-centric information(言语表达,tweet内容,行为,喜好)
(2)social graph information
整个系统架构由两部分组成:(1)ML(machine learning) component,用来通过user-centric information对用户分类;(2)a graph-based updating component,包含了social graph信息,通过该用户的社会网络分布对分类信息做出更新
ML部分:使用GBDT Framework作为分类算法,GBDT可解决过拟合问题,且有smaller resulting models and faster decoing time的特点[7]。
(1)profile:选取基本profile信息:a.用户名长度;b.用户名中字母数字个数;c.用户名中不同的大小写形式;d.头像使用;e.粉丝数;f.关注者;g.粉丝/关注比例;h.创建帐户日期;i.bio;j.location。其中bio使用正则表达式进行匹配抽取信息
(2)Tweeting bahavior:判断information source/seeker:a.tweet数;b.retweet数/比例;c.reply数/比例;d.平均hashtag数;e.URLs per tweets;f.fraction of tweets touneated;g.tweets时间间隔,标准差;h.一天的平均tweet数和标准差
(3)Linguistic Content Feature:使用LDA,从BOW中抽取
a.proto-word(typical lexical expression in a specific class):本文通过概率模型抽取pro-word
b.proto-hashtag:与proto-word类似
c.Generic LDA:假设a user can be represented as a multinomial distribution over topics
d.Domain-specific LDA:GLDA得到粗粒度topic,DLDA细粒度
e.sentiment words:对于某term建立窗口,对其周围n个词语进行考查,判断用户倾向。
(4)社会网络特征:
a.Friend Accounts
b.Users whom to the target user replyed and retweeted
基于图的标签更新:
这个步骤基于社会关系网络用来对机器学习所给出错误标注做以纠正。在这个实验中,作者仅仅选取了friend accouts一项,因为它最能表示target user的兴趣和倾向。实验在target user的所有friends都运行了ML算法,将其所有朋友帐号都赋予了一个标签,然后用朋友帐号的标签来对target user的标签做出评判及更正。
final_score(ui)=α*ML+(1-α)*label updating
实验分析:
作者分别将α设为0,1和0.5进行实验。最后实验表明,ML本身就可以取得较高的结果,而标签更新算法本身则效果不佳。对于political affinity,标签更新作用较大,对整体结果有着较好(比起其它两个task)但仍然是很微小的提升。Starbuck标签更新算法也有用,则非常小。而对于Ethnicity来说,标签更新算法还不如没有,反而起到了负作用。作者分析原因,在于social connection对于政治有着较大的帮助,而对于种族和商品这种个性化的东西,作用不是很大。
在实验中,作者使用了两个base line:
B2:在ML阶段只使用了profile和tweeting bahavior两项特征(这两项特征容易取得)
B1在不同实验中,有着不同含义:
a.政治倾向上:B1把在bio field中提到的对民主/共和党的倾向作为分类依据,进行分类
b.种族上:B1根据用户的头像来对其进行种族分类。
c.星巴克:B1把所有在bio field提到星巴克的用户分类为星巴克粉丝。
结果表明:B2总体性能不如本文所提到的系统,说明lingistic特征和社会网络特征对于结果有着巨大的积极影响。而B1有着极高的准确率,但召回率太低,也没有太大的实用价值。
工具:
Opinion Finder[25]
论文:
Marco Pennacchiotti, Ana-Maria Popescu:Democrats, Republicans and Starbucks Afficionados: User Classification in Twitter.
Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, Aug. 2011
论文链接:
KDD2011_Democrats_republicans_and_starbucks_afficionados_user_classification_in_twitter.pdf
posted @
2012-02-18 13:23 Seraphi 阅读(714) |
评论 (0) |
编辑 收藏大致内容:
这篇论文的任务是对twitter上的短文本进行分类,分到预先定义的5个类别中:news,event,opinions,deal,PM(private message)。该论文摒弃传统的BOW特征模型而别出心裁地选取了8个特征(8F):
1个是名词性特性:用户。这个特征是8F特征中最为主要的特征,因为它反映了信息源的主要类别特征。如,企业的用户和个人用户通常有着不同的用户行为,这个特征可以限定该用户tweet的分类范围。
另外7个是binary feature(存在特征):
俚语与词语缩写的使用:俚语和词语缩写通常不会是一个新闻
time-event短语:Event类别的重要特征
评论性词语:Opinion类重要特征
词语的强调(大写或字母重要,如veeery):同上
currency和percentage标志:如¥$%,这些都是Deal类别的重要特征
@usrname:这是PM的重要特征,当然也有可能是Event类中的一个特征(participants)。
实验表明8F比BOW在精度上均为大幅提高。
使用工具:
weka
论文:
Bharath Sriram, Dave Fuhry, Engin Demir, Hakan Ferhatosmanoglu, Murat Demirbas:Short Text Classification in Twitter to Improve Information Filtering.
Proceeding of the 33rd international ACM SIGIR conference on Research and development in information retrieval, Jul. 2010论文链接:
SIGIR2010_Short_Text_Classification_in_Twitter_to_Improve_Information_Filtering.pdf
posted @
2012-02-18 12:32 Seraphi 阅读(1311) |
评论 (0) |
编辑 收藏术语:
content-based, neighborhood-based, collaborative filtering, substitutes(相等价的商品,如可口可乐与百事可乐), complements(附加的、补充的商品,如ipod和ipod faceplate), listing fee上市费, flippers(who buy a low price and resell at a higher price)
大致内容:
这篇论文的作者是e-bay的高级技术人员,主要从scale, product dimension, buy dimension, seller dimension, buyer seller handshake这几个方面和5Ws(what, where, when, why, who)和1H(how)来说明E-Bay推荐的关键问题和难点。
同样的商品,可能有多种情况(有无盒,有无标签,有多新/旧)。而对于买家,也分为casual shopper, impulsive shopper, value-driven shopper, collector filppers
what:对于用户不同的浏览情况,给予不同的推荐。例如:用户U1和U2都浏览了某个item-i1。用户U1反复浏览多次i1,并将其加入购物车。用户U2则看了一眼就再也没有访问i1的页面。对于这两位用户,推荐系统所做出的推荐不能是相同的。
where:在用户浏览的不同网页/阶段(search,bid,check-out,post-transaction)所做的推荐不同。
when:用户在购买商品后,经过不同的时间,给予不同的推荐(例如:对于一个刚买相机一天的用户,推荐系统应该推荐其附件(包),对于一个买了相机30多天的用户来说,推荐系统更应为其推荐一些关于相机保养的商品)
why:推荐系统给出推荐原因,如60%的用户买了这个商品也买了那件
who:不同的用户类型给予不同的推荐。对于老手,推荐并非有太大功效,而对于新用户,则作用最大。
how:推荐时会有大规模,超稀疏的user-item矩阵,用SVD进行降维分解。另一种方案是聚类,可用K-means和层次聚类的方法。
论文:
Neel Sundaresan:Recommender Systems at the Long Tail
.
Proceedings of the fifth ACM conference on Recommender systems, Oct. 2011论文链接:
Recsys2011_Recommender_System_at_the_Long_Tail.pdf
posted @
2012-02-18 11:49 Seraphi 阅读(579) |
评论 (0) |
编辑 收藏术语:
followee/friend 用户关注的对象(即新浪微博中的“关注”)
follower 关注用户的对象(即微博中的“粉丝”)
collaborative filtering 协同过滤
大致内容:
本文作者及其团队对twitter用户推荐做了深入研究,并制作了一个在线的twitter用户推荐的应用。并以profile推荐和search推荐两种方式呈现给用户。
profile推荐即用户不需要自己输入查询,该应用将根据用户的profile自动生成查询,来查找相关用户。
search推荐即用户自行输入查询,来寻找自己感兴趣的用户。
本文列举了9种生成用户profile的策略:
S1:由用户U本身的tweets
S2:由用户U的followees的tweets产生
S3:由用户U的followers的tweets产生
S4:由S1,S2,S3的并集产生
S5:由用户U的followee ID产生
S6:由用户U的follower ID产生
S7:由S5,S6并集产生
S8:结合S1-S7,得分函数依赖于S1和S6
S9:结果S1-S7,得分函数基于推荐列表中用户位置。
※以上方法中,S1-S4为content based,S5-S7是collaborative filtering。
然后用lucene对这9种策略分别建立索引,进行实验。其中,基于内容的策略中,采用tf-idf权值。
评价指标:
1、①Precision:即推荐列表与已有followee重复的百分比,S5-S7(Collaborative filtering)好于S1-S4(content based),S3高于S2,Precision随Recommendation List Size增大而降低
②Position:相关用户的位置因素亦很重要,在此,基于内容方法略好于协同过滤。
2、以上两个指标均为脱机(offline)评价指标,实际上即便是followee中没有存在的那些出现在Recommendation List中的用户,也并非不相关,有很多为potential followees。因此,本文还做了一个live-user trial,选取了34位参与者参加实验,结果30个推荐列表中,平均采取6.9人,且位置主要集中在推荐列表的top10。另外,search中(31名参与)结果并不如profile,平均4.9人采纳。作者分析了这个原因,在于search中用户所提供信息远小于profile中的信息,因此效果不如profile推荐。
论文:
John Hannon, Mike Bennett, Barry Smyth:Recommending Twitter Users to Follow Using Content and Collaborative Filtering Approaches.
Proceedings of the fourth ACM conference on Recommender systems, Sep. 2010论文链接:
2010_RECSYS_RecommendingTwitterUsers.pdf
posted @
2012-02-18 11:28 Seraphi 阅读(689) |
评论 (0) |
编辑 收藏大致内容:
对twitter构成及使用进行了简要的说明,并通过实验证明,在某一领域中,根据粉丝数推荐的列表最受欢迎。另外,比起无领域知识和twitter经验的用户,具有领域知识和熟练使用twitter的用户会倾向于相关领域list数量。
实验方法:
用twitter API爬取twitter,对用户分析(粉丝数、list数、相关list数),做在线survey来分析结果。
论文:
Wit Krutkam, Kanda Runapongsa Saikeaw, Arnut Chaosakul: Twitter Accounts Recommendation Based on Followers and Lists
论文链接:
jictee2010_Twitter_Accounts_Recommendation_based_on_followers_and_lists.pdf
posted @
2012-02-18 11:04 Seraphi 阅读(152) |
评论 (0) |
编辑 收藏