经常可以从开发人员口中听到“面向对象”这个词:
场景1、
A:我今天开始用面向对象的方法设计程序了!
B:你怎么做的?
A:我把保存文件、加载文件封装成了一个类,以后只要调用这个类就可以实现文件操作了。
场景2、
A:我开始学习Java了,面向对象的语言,你不要再学VB了,好土呀!
B:VB怎么了?
A:VB是面向过程的,已经过时了,Java中都是类,很时髦!
B:VB中也有类呀!
A:(无语)
场景3、
A:面向对象思想就是好呀,我真的离不开Java了!
B:你又用什么高超技术了?
A:我今天从一个操纵数据库的类继承了一个子类,然后重写了它的保存到数据库的方法,然后把数据通过Socket发送到了远程客户端了,而调用者根本不知道,哈哈!
场景4、
A:我推荐你用的Java不错吧?
B:真是不错,面向对象就是好,JDK里边也有好多好多的类可以用,不用像在VB里边那样要去查API文档了。
A:但是我听说现在又出了个面向方面编程,咱们看来又落伍了呀,看来做编程真的不是长久之计。
写几个类就是面向对象了吗?继承父类就是为了重用父类的代码吗?覆盖父类的方法就可以瞒天过海了吗?VB中也有类,它是面向对象吗?
1.1
类与对象
“类”和“对象”是面向对象编程中最基本的概念,从语言的角度来讲,“类”是用户自定义的具有一定行为的数据类型,“对象”则是“类”这种数据类型的变量。通俗的讲,“类”是具有相同或相似行为的事物的抽象,“对象”是“类”的实例,是是一组具有相关性的代码和数据的组合体,是有一定责任的实体。
类本身还可以进一步抽象为类型,类型是一种更高层次上的抽象,它只用来描述接口,比如抽象类和接口就是一种类型。当一个类型的接口包含另外一个类型的接口时,我们就可以说它是此类型的子类型。类型是用来标识特定接口的,如果一个对象接受某个接口定义的所有行为,那么我们就可以说该对象具有该类型。一个对象同时拥有多种类型。
面向对象编程的特性
面向对象编程有三个特性:封装,继承,多态。这三个特性从低级到高级描述了面向对象的特征。一种语言只有同时具备这三种特性才能被称为面向对象的语言。VB中也有类,它的类也支持封装和简单的继承,但是它不支持所有的继承语义和多态,因此VB只能被称为基于对象的语言。
封装是所有抽象数据类型(ADT)的特性,很多刚刚接触面向对象的人认为封装就是就是面向对象。将程序按照一定的逻辑分成多个互相协作的部分,并将对外界有用的稳定的部分暴露出来,而将会发生的改变隐藏起来,外界只能通过暴露的部分向这个对象发送操作请求从而享受对象提供的服务,而不必管对象内部是如何运行的,这就是封装。理解封装是理解面向对象的第一个步骤,40%的程序员对面向对象的理解仅停留在封装这个层次。
继承也称为派生,继承关系中,被继承的称为基类,从基类继承而得的被称为派生类或者子类。继承是保持对象差异性的同时共享对象相似性的复用。能够被继承的类总是含有并只含有它所抽象的那一类事务的共同特点。继承提供了实现复用,只要从一个类继承,我们就拥有了这个类的所有行为。理解继承是理解面向对象的第二个步骤,50%的程序员对面向对象的理解仅停留在继承这个层次。语义上的“继承”表示“是一种(is-a)”的关系。很多人体会到了继承在代码重用方面的优点,而忽视了继承的语义特征。于是很多滥用继承的情况就发生了,关于这一点我们将会在后边介绍。
多态是“允许用户将父对象设置成为一个或更多的它的子对象相等的技术,赋值后,基类对象就可以根据当前赋值给它的派生类对象的特性以不同的方式运作”(Charlie Calvert)。多态扩大了对象的适应性,改变了对象单一继承的关系。多态是行为的抽象,它使得同名方法可以有不同的响应方式,我们可以通过名字调用某一方法而无需知道哪种实现将被执行,甚至无需知道执行这个实现的对象类型。多态是面向对象编程的核心概念,只有理解了多态,才能明白什么是真正的面向对象,才能真正发挥面向对象的最大能力。不过可惜的是,只有极少数程序员能真正理解多态。
对象之间的关系
对象之间有两种最基本的关系:继承关系,组合关系。
继承关系
继承关系可以分为两种:一种是类对接口的继承,被称为接口继承;另一种是类对类的继承,被称为实现继承。继承关系是一种“泛化/特化”关系,基类代表一般,而派生类代表特殊。
组合关系。
组合是由已有的对象组合而成新对象的行为,组合只是重复运用既有程序的功能,而非重用其形式。组合与继承的不同点在于它表示了整体和部分的关系。比如电脑是由CPU、内存、显示器、硬盘等组成的,这些部件使得电脑有了计算、存储、显示图形的能力,但是不能说电脑是由CPU继承而来的。
1.2
对象之间有两种最基本的关系:继承关系,组合关系。通过这两种关系的不断迭代组合最终组成了可用的程序。但是需要注意的就是要合理使用这两种关系。
派生类是基类的一个特殊种类,而不是基类的一个角色。语义上的“继承”表示“is-a”(是一种)的关系,派生类“is-a”基类,这是使用继承关系的最基本前提。如果类A是类B的基类,那么类B应该可以在任何A出现的地方取代A,这就是“Liskov代换法则(LSP)”。如果类B不能在类A出现的地方取代类A的话,就不要把类B设计为类A的派生类。
举例来说,“苹果”是“水果”的派生类,所以“水果是植物的果实”这句话中的“水果”可以用“苹果”来代替:“苹果是植物的果实”;而“苹果”不是“香蕉”的派生类,因为“香蕉是一种种子退化的了的植物果实”不能被“苹果”替换为“苹果是一种种子退化的了的植物果实”。
举这个例子好像有点多余,不过现实的开发中却经常发生“苹果”从“香蕉”继承的事情。
某企业中有一套信息系统,其中有一个“客户(Customer)”基础资料,里边记录了客户的名称、地址、email等信息。后来系统要进行升级,增加一个“供应商(Supplier)”基础资料,开发人员发现“供应商”中有“客户”中的所有属性,只是多了一个“银行帐号”属性,所以就把“供应商”设置成“客户”客户的子类。
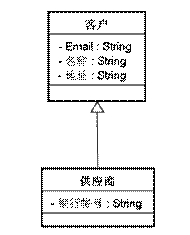
图 2.1
到了年终,老板要求给所有的客户通过Email发送新年祝福,由于“供应商”是一种(is-a)“客户”,所以系统就给“供应商”和“客户”都发送了新年祝福。第二天很多供应商都感动流涕的给老板打电话“谢谢老板呀,我们供应商每次都是求着贵公司买我们的东西,到了年终你们还忘不了我们,真是太感谢了!”。老板很茫然,找来开发人员,开发人员这才意识到问题,于是在发送Email的程序里做了判断“如果是供应商则不发送,否则发送”,一切ok了。到了年初,老板要求给所有很长时间没有购买他们产品的“客户”,打电话进行问候和意见征集。由于“供应商”是一种(is-a)“客户”,所以第二天电话里不断出现这样的回答:“你们搞错了吧,我们是你们的供应商呀!”。老板大发雷霆,开发人员这才意识到问题的严重性,所以在系统的所有涉及到客户的地方都加了判断“如果是供应商则……”,一共修改了60多处,当然由于疏忽遗漏了两处,所以后来又出了一次类似的事故。
我们可以看到错误使用继承的害处了。其实更好的解决方案应该是,从“客户”和“供应商”中抽取一个共同的基类“外部公司”出来:
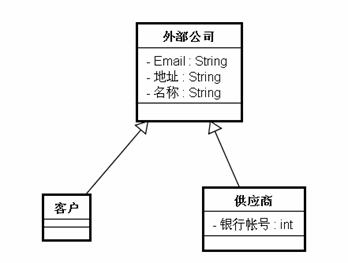
图 2.2
这样就将“客户”和“供应商”之间的继承关系去除了。
派生类不应大量覆盖基类的行为。派生类具有扩展基类的责任,而不是具有覆盖(override)基类的责任。如果派生类需要大量的覆盖或者替换掉基类的行为,那么就不应该在两个类之间建立继承关系。
让我们再来看一个案例:
一个开发人员要设计一个入库单、一张出库单和一张盘点单,并且这三张单都有登帐的功能,通过阅读客户需求,开发人员发现三张单的登帐逻辑都相同:遍历单据中的所有物品记录,然后逐笔登到台帐上去。所以他就设计出了如下的程序:
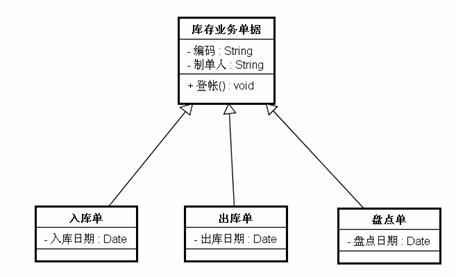
图 2.3
把登帐逻辑都写到了“库存业务单据”这个抽象类中,三张单据从这个类继承即可。过了三个月,用户提出了新的需求:盘点单在盘点过程中,如果发现某个货物的盘亏量大于50则停止登帐,并向操作人员报警。所以开发人员在盘点单中重写了“库存业务单据”的“登帐”方法,实现了客户要求的逻辑。又过了半个月,客户要求出库登帐的时候不仅要进行原先的登帐,还要以便登帐一边计算出库成本。所以开发人员在出库单中重写了“库存业务单据”的“登帐”方法,实现了客户要求的逻辑。到了现在“库存业务单据”的“登帐”方法的逻辑只是对“入库单”有用了,因为其他两张单据都“另立门户”了。
这时候就是该我们重新梳理系统设计的时候了,我们把“库存业务单据”的“登帐”方法设置成抽象方法,具体的实现代码由具体子类自己决定:
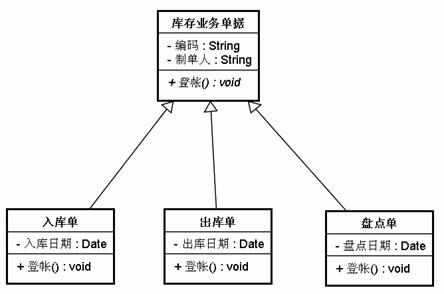
图 2.4
注意此处的“库存业务单据”中的“登帐”方法是斜体,在UML中表示此方法是一个抽象方法。这个不难理解,每张单据都肯定有登帐行为,但是每张单据的登帐行为都有差异,因此在抽象类中定义类的“登帐”方法为抽象方法以延迟到子类中去实现。
继承具有如下优点:实现新的类非常容易,因为基类的大部分功能都可以通过继承关系自动赋予派生类;修改或者扩展继承来的实现非常容易;只要修改父类,派生的类的行为就同时被修改了。
初学面向对象编程的人会认为继承真是一个好东西,是实现复用的最好手段。但是随着应用的深入就会发现继承有很多缺点:继承破坏封装性。基类的很多内部细节都是对派生类可见的,因此这种复用是“白箱复用”;如果基类的实现发生改变,那么派生类的实现也将随之改变。这样就导致了子类行为的不可预知性;从基类继承来的实现是无法在运行期动态改变的,因此降低了应用的灵活性。
继承关系有很多缺点,如果合理使用组合则可以有效的避免这些缺点,使用组合关系将系统对变化的适应力从静态提升到动态,而且由于组合将已有对象组合到了新对象中,因此新对象可以调用已有对象的功能。由于组合关系中各个各个对象的内部实现是隐藏的,我们只能通过接口调用,因此我们完全可以在运行期用实现了同样接口的另外一个对象来代替原对象,从而灵活实现运行期的行为控制。而且使用合成关系有助于保持每个类的职责的单一性,这样类的层次体系以及类的规模都不太可能增长为不可控制的庞然大物。因此我们优先使用组合而不是继承。
当然这并不是说继承是不好的,我们可用的类总是不够丰富,而使用继承复用来创建一些实用的类将会不组合来的更快,因此在系统中合理的搭配使用继承和组合将会使你的系统强大而又牢固。
1.3
接口的概念
接口是一种类型,它定义了能被其他类实现的方法,接口不能被实例化,也不能自己实现其中的方法,只能被支持该接口的其他类来提供实现。接口只是一个标识,标识了对象能做什么,至于怎么做则不在其控制之内,它更像一个契约。
任何一个类都可以实现一个接口,这样这个类的实例就可以在任何需要这个接口的地方起作用,这样系统的灵活性就大大增强了。
接口编程的实例
SQL语句在各个不同的数据库之间移植最大的麻烦就是各个数据库支持的语法不尽相同,比如取出表的前10行数据在不同数据库中就有不同的实现。
MSSQLServer:Select top 10 * from T_Table
MySQL:select * from T_Table limit 0,10
Oracle:select * from T_Table where ROWNUM <=10
我们先来看一下最朴素的做法是怎样的:
首先定义一个SQL语句翻译器类:
public class Test1SQLTranslator
{
private int dbType;
public Test1SQLTranslator(int dbType)
{
super();
this.dbType = dbType;
}
public String translateSelectTop(String tableName, int count)
{
switch (dbType) {
case 0:
return "select top " + count + " * from " + tableName;
case 1:
return "select * from " + tableName + " limit 0," + count;
case 2:
return "select * from " + tableName + " where ROWNUM<=" + count;
default:
return null;
}
}
}
然后如下调用
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
int dbType = 0;
Test1SQLTranslator translator = new Test1SQLTranslator(dbType);
String sql = translator.translateSelectTop(tableName,count);
System.out.println(sql);
}
如果要增加对新的数据库的支持,比如DB2,那么就必须修改Test1SQLTranslator类,增加一个对DB2的case语句,这种增加只能是在编辑源码的时候进行添加,无法在运行时动态添加。再来看一下如果用基于接口的编程方式是如何实现的。
首先,定义接口ISQLTranslator,这个接口定义了所有SQL翻译器的方法,目前只有一个翻译Select top的方法:
public interface ISQLTranslator
{
public String translateSelectTop(String tableName, int count);
}
接着我们为各个数据库写不同的翻译器类,这些翻译器类都实现了ISQLTranslator接口:
public class MSSQLServerTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select top " + count + " * from " + tableName;
}
}
public class MySQLTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select * from " + tableName +" limit 0,"+count;
}
}
public class OracleSQLTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select * from " + tableName+" where ROWNUM<="+count;
}
}
如下调用:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new MSSQLServerTranslator();
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
运行以后,打印出了:
select top 10 from T_Table
可以看到,不同的数据库翻译实现由不同的类来承担,这样最大的好处就是可扩展性极强,比如也许某一天出现了了支持中文语法的数据库,我要为它做翻译器只需再增加一个类:
public class SinoServerTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "读取表"+tableName+"的前"+count+"行";
}
}
修改调用代码:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new SinoServerTranslator();
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
运行后控制台打印出:
读取表T_Table的前10行
这里的translator 可以随意实例化,只要实例化的类实现了ISQLTranslator 就可以了,这个类也可以通过配置文件读取,甚至是其他类传递过来的,这都无所谓,只要是实现了ISQLTranslator 接口它就能正常工作。
如果要给SQL语句加上验证功能,也就是翻译的时候首先验证一下翻译的结果是否能在数据库中执行,我们就可以采用偷天换日的方式来进行。
首先创建一个VerifyTranslator类:
public class VerifyTranslator implements ISQLTranslator
{
private ISQLTranslator translator;
private Connection connection;
public VerifyTranslator(ISQLTranslator translator, Connection connection)
{
super();
this.translator = translator;
this.connection = connection;
}
public String translateSelectTop(String tableName, int count)
{
String sql = translator.translateSelectTop(tableName, count);
PreparedStatement ps = null;
try
{
ps = connection.prepareStatement(sql);
ps.execute();
} catch (SQLException e)
{
DbUtils.close(ps);
return "wrong sql";
}
return sql;
}
}
这个类接受一个实现了ISQLTranslator 接口的变量和数据库连接做为构造参数,最重要的是这个类本身也实现了ISQLTranslator 接口,这样它就完全能“伪装”成SQL翻译器来行使翻译的责任了,不过它没有真正执行翻译,它把翻译的任务转发给了通过构造函数传递来的那个翻译器变量:
String sql = translator.translateSelectTop(tableName, count);
它自己的真正任务则是进行SQL语句的验证:
ps = connection.prepareStatement(sql);
再次修改调用代码:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new VerifyTranslator(
new SinoServerTranslator(), getConnection());
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
运行后控制台打印出:
wrong sql
下面这段代码看上去是不是很眼熟呢?
ISQLTranslator translator = new VerifyTranslator(new SinoServerTranslator(), getConnection());
这段代码和我们经常写的流操作非常类似:
InputStream is = new DataInputStream(new FileInputStream(new File(“c:/boot.ini”)));
这就是设计模式中经常提到的“装饰者模式”。
针对接口编程
从上面的例子我们可以看出,当代码写到:
String sql = translator.translateSelectTop(tableName, count);
的时候,代码编写者根本不关心translator这个变量到底是哪个类的实例,它只知道它调用了接口约定支持的translateSelectTop方法。
当一个对象需要与其他对象协作完成一项任务时,它就需要知道那个对象,这样才能调用那个对象的方法来获得服务,这种对象对另一个协作对象的依赖就叫做关联。如果一个关联不是针对具体类,而是针对接口的时候,任何实现这个接口的类都可以满足要求,因为调用者仅仅关心被依赖的对象是不是实现了特定接口。
当发送的请求和具体的请求响应者之间的关系在运行的时候才能确定的时候,我们就称之为动态绑定。动态绑定允许在运行期用具有相同接口的对象进行替换,从而实现多态。多态使得对象间彼此独立,所有的交互操作都通过接口进行,并可以在运行时改变它们之间的依赖关系。
针对接口编程,而不是针对实现编程是面向对象开发中的一个非常重要的原则,也是设计模式的精髓!
针对接口编程有数不清的例子,比如在Hibernate中,集合属性必须声明为Set、Map、List等接口类型,而不能声明为HashSet、HashMap、ArrayList等具体的类型,这是因为Hibernate在为了实现LazyLoad,自己开发了能实现LazyLoad功能的实现了Set、Map、List等接口的类,因为我们的属性的类型只声明为这些属性为这些接口的类型,因此Hibernate才敢放心大胆的返回这些特定的实现类。
现实的开发过程中有如下一些违反针对接口编程原则的陋习:
陋习1
ArrayList list = new ArrayList();
for(int i=0;i<10;i++)
{
list.add(……);
}
这里使用的是ArrayList的add方法,而add方法是定义在List接口中的,因此没有必要声明list变量为ArrayList类型,修改如下:
List list = new ArrayList();
for(int i=0;i<10;i++)
{
list.add(……);
}
陋习2
public void fooBar(HashMap map)
{
Object obj = map.get(“something”);
……
}
在这个方法中只是调用Map接口的get方法来取数据,所以就不能要求调用者一定要传递一个HashMap类型的变量进来。修改如下:
public void fooBar(Map map)
{
Object obj = map.get(“something”);
……
}
这样修改以后用户为了防止传递给fooBar方法的Map被修改,用户就可以这样调用了:
Map unModMap = Collections.unmodifiableMap(map);
obj.fooBar(unModMap);
Collections.unmodifiableMap是JDK提供的一个工具类,可以返回一个对map的包装,返回的map是不可修改的,这也是装饰者模式的典型应用。
试想如果我们把接口声明为public void fooBar(HashMap map)用户还能这么调用吗?
1.4 抽象类
抽象类的主要作用就是为它的派生类定义公共接口,抽象类把它的部分操作的实现延迟到派生类中来,派生类也能覆盖抽象基类的方法,这样可以很容易的定义新类。抽象类提供了一个继承的出发点,我们经常定义一个顶层的抽象类,然后将某些位置的实现定义为抽象的,也就是我们仅仅定义了实现的接口,而没有定义实现的细节。
一个抽象类应该尽可能多的拥有共同的代码,但是不能把只有特定子类才需要的方法移动到抽象类中。Eclipse的某些实现方式在这一点上就做的不是很好,Eclipse的一些界面类中提供了诸如CreateEmailField之类的方法来创建界面对象,这些方法并不是所有子类都用得到的,应该把它们抽取到一个工具类中更好。同样的错误在我们的案例的JCownewDialog中也是存在的,这个类中就提供了CreateOKBtn、CreateCanceBtn两个方法用来创建确定、取消按钮。
在设计模式中,最能体现抽象类优点的就是模版方法模式。模版方法模式定义了一个算法的骨架,而具体的实现步骤则由具体的子类类来实现。JDK中的InputStream类是模版方法的典型代表,它对skip等方法给出了实现,而将read等方法定义为抽象方法等待子类去实现。后边案例中的PISAbstractAction等类也是模版方法的一个应用。
在实际开发中接口和抽象类从两个方向对系统的复用做出了贡献,接口定义了系统的服务契约,而抽象类则为这些服务定义了公共的实现,子类完全可以从这些抽象类继承,这样就不用自己实现自己所不关心的方法,如果抽象类提供的服务实现不满足自己的要求,那么就可以自己从头实现接口的服务契约。