2008年12月26日
#
1. Remote
Method Invocation (RMI)
2. Hessian
3. Burlap
4. HTTP invoker
5. EJB
6. JAX-RPC
7. JMX
zz from http://marakana.com/forums/tomcat/general/106.html
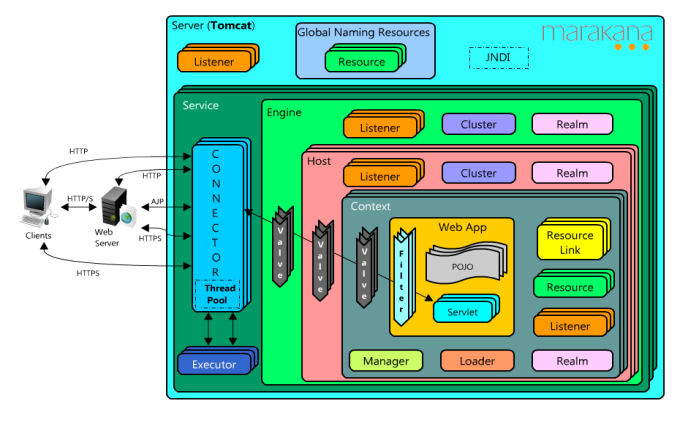
Valve and Filter:
"Valve" is Tomcat
specific notion, and they get applied at a higher level than anything in a specific webapp. Also, they work only in Tomcat.
"Filter" is a Servlet Specification notion and should work in any compliant servlet container. They get applied at a lower level than all of Tomcat's
Valves.
However, consider also the division between your application and the application
server. Think whether the feature you're planning is part of your application, or is it rather a generic feature of the application server, which could have uses in other applications as well. This would be the correct criteria to decide between Valve and Filter.
Order for filter: The order in which they are
defined matters. The container will execute the filters in the order
in which they are defined.
Use one single table "blank_fields" for both A and B. "blank_fields" has fields: 'ref_id', 'blank_field', 'type'. 'type' is used to identify which entity the record belongs to. Use 'type' + 'ref_id' to specify the collection of elements for one entity.
@Entity
@Table(name = "table_a")
public class A {
private Set<BlankField> blankFields = new HashSet<BlankField>();
@CollectionOfElements
@Fetch(FetchMode.SUBSELECT)
@Enumerated(EnumType.ORDINAL)
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "ref_id") })
@Cascade(value = org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
@Column(name = "blank_field", nullable = false)
@SQLInsert(sql = "INSERT INTO blank_fields(ref_id, blank_field, type) VALUES(?,?,0)")
@Where(clause = "type=0")
public Set<BlankField> getBlankFields() { // BlankField is an enum
return blankFields;
}
@SuppressWarnings("unused")
private void setBlankFields(Set<BlankField> blankFields) {
this.blankFields = blankFields;
}
} // End B
@Entity
@Table(name = "table_b")
public class B {
private Set<BlankField> blankFields = new HashSet<BlankField>();
@CollectionOfElements
@Fetch(FetchMode.SUBSELECT)
@Enumerated(EnumType.ORDINAL)
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "ref_id") })
@Cascade(value = org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
@Column(name = "blank_field", nullable = false)
@SQLInsert(sql = "INSERT INTO blank_fields(ref_id, blank_field, type) VALUES(?,?,1)") // used for insert
@Where(clause = "type=1") // used for query, if not @CollectionOfElements, such as @OneToMany, use @WhereJoinTable instead
public Set<BlankField> getBlankFields() {
return blankFields;
}
@SuppressWarnings("unused")
private void setBlankFields(Set<BlankField> blankFields) {
this.blankFields = blankFields;
}
}
当然还有其他的方式来实现上面的需求,上面采用的单表来记录不同实体的associations(这儿是CollectionOfElements,并且返回的是Set<Enum>,不是Set<Embeddable>),然后用'type'来区分不同的实体,这样做的好处是:数据库冗余少,易于扩展,对于新的实体,只需加一个type值,而不需更改数据库表结构。另外一种采用单表的方式是为每个实体增加新的字段,如"blank_fields": 'a_id', 'b_id', 'blank_field', a_id reference table_a (id), b_id reference table_b (id). 这样在映射的时候更简单,
对于A,映射为
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "a_id") })
对于B,映射为
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "b_id") })
这样作的缺点是:带来了数据库冗余,对于blank_fields来讲,任一条记录,a_id和b_id中只有一个不为null。当多个实体共用这个表时,用上面的方法更合理,如果共用实体不多时,这种方法更方便。
The case to use One Hibernate Session Multiple Transactions:
each transaction would NOT affect others.
i.e., open multiple transactions on the same session, even though one transaction rolls back, other transactions can be committed. If one action fails, others should fail too, then we should use one transaction for all actions.
Note:
A rollback with a single Session will lead to that Session being cleared (through "Session.clear()").
So do lazy collections still work if the session is cleared? =>Not of any objects that you loaded up until the rollback. Only for new objects loaded afterwards.
We should load necessary objects to session for each transactional action to avoid LazyInitializationException, even if those objects are loaded before other forward transactional actions, since forward action may be rolled back and clear the session.
BTW, Hibernate Session.merge() is different with Session.update() by:
Item item2 = session.merge(item);
item2 == item; // false, item - DETACHED, item2 - PERSIST
session.update(item); // no return value, make item PERSIST
发生这种异常的case:
@Transactional
public void foo() {
try{
bar();
} catch (RuntimeException re) {
// caught but not throw further

}
}
@Transactional
public void bar() {
}
如果foo在调用bar的时候,bar抛出RuntimeException,Spring在bar return时将Transactional标记为Rollback only, 而foo捕获了bar的RuntimeException,所以Spring将会commit foo的事务,但是foo和bar使用的是同一事务,因此在commit foo事务时,将会抛出UnexpectedRollbackException。注意:如果foo和bar在同一class中,不会出现这种情况,因为:
Since this mechanism is based on proxies, only 'external' method calls coming in through the proxy will be intercepted. This means that 'self-invocation', i.e. a method within the target object calling some other method of the target object, won't lead to an actual transaction at runtime even if the invoked method is marked with @Transactional!
可以通过配置log4j来debug Spring事务获取情况:
To delve more into it I would turn up your log4j logging to debug and also look at what ExerciseModuleController is doing at line 91, e.g.: add a logger for org.springframework.transaction
这周被Quartz折腾了一番。
我们知道,Quartz采用JobDataMap实现向Job实例传送配置属性,正如Quartz官方文档说的那样:
How can I provide properties/configuration for a Job instance? The key is the JobDataMap, which is part of the JobDetail object.
The JobDataMap can be used to hold any number of (serializable) objects
which you wish to have made available to the job instance when it
executes.
JobDataMap map = context.getJobDetail().getJobDataMap();
我们通过map向Job实例传送多个objects,其中有一个是个bean,一个是基本类型。对于scheduled triggers,我们要求bean对于所有的序列都不变,包括其属性,而基本类型可以在Job运行过程中改变,并影响下一个序列。实际情况是,对于下个序列,bean的属性被上次的修改了,而基本类型却维持第一次put到Map里面的值。正好和我们要求的相反。
受bean的影响,以为map里面包含的都是更新的对象,即每个序列里面的JobDetail是同一个对象,但是基本类型的结果否认了这一点。回头重新翻阅了下Quartz的文档:
Now, some additional notes about a job's state data (aka JobDataMap): A
Job instance can be defined as "stateful" or "non-stateful".
Non-stateful jobs only have their JobDataMap stored at the time they
are added to the scheduler. This means that any changes made to the
contents of the job data map during execution of the job will be lost,
and will not seen by the job the next time it executes.
Job有两个子接口:StatefulJob and InterruptableJob,我们继承的是InterruptableJob,或许Quartz应该有个InterruptableStatefulJob。另外StatefulJob不支持并发执行,和我们的需求不匹配,我们有自己的同步控制,Job必须可以并发运行。
然后查看了Quartz的相关源码:
// RAMJobStore.storeJob
public void storeJob(SchedulingContext ctxt, JobDetail newJob,
boolean replaceExisting) throws ObjectAlreadyExistsException {
JobWrapper jw = new JobWrapper((JobDetail)newJob.clone()); // clone a new one
.
jobsByFQN.put(jw.key, jw);
}
也就是说,store里面放的是初始JobDetail的克隆,在序列运行完时,只有StatefulJob才会更新store里面的JobDetail:
// RAMJobStore.triggeredJobComplete
public void triggeredJobComplete(SchedulingContext ctxt, Trigger trigger,
JobDetail jobDetail, int triggerInstCode) {
JobWrapper jw = (JobWrapper) jobsByFQN.get(jobKey);
if (jw != null) {
JobDetail jd = jw.jobDetail;
if (jd.isStateful()) {
JobDataMap newData = jobDetail.getJobDataMap();
if (newData != null) {
newData = (JobDataMap)newData.clone();
newData.clearDirtyFlag();
}
jd.setJobDataMap(newData); // set to new one
}
}
然后,每次序列运行时所用的JobDetail,是存放在Store里面的克隆。
// RAMJobStore.retrieveJob
public JobDetail retrieveJob(SchedulingContext ctxt, String jobName,
String groupName) {
JobWrapper jw = (JobWrapper) jobsByFQN.get(JobWrapper.getJobNameKey(
jobName, groupName));
return (jw != null) ? (JobDetail)jw.jobDetail.clone() : null; // clone a new
}
问题很清楚了,存放在Store里面的JobDetail是初始对象的克隆,然后每个序列所用的JobDetail, 是Store里面的克隆,只有Stateful job,Store里面的JobDetail才更新。
最有Quartz里面使用的clone():
// Shallow copy the jobDataMap. Note that this means that if a user
// modifies a value object in this map from the cloned Trigger
// they will also be modifying this Trigger.
if (jobDataMap != null) {
copy.jobDataMap = (JobDataMap)jobDataMap.clone();
}
所以对于前面所讲的,修改bean的属性,会影响所有clone的对象,因此,我们可以将基本类型封装到一个bean里面,map里面存放的是bean,然后通过修改bean的属性,来达到影响下一个序列的目的。
From:
Web application design: the REST of the story
Key points:
- HTTP is a very general, scalable protocol. While most people only
think of HTTP as including the GET and POST methods used by typical
interactive browsers, HTTP actually defines several other methods that
can be used to manipulate resources in a properly designed application
(PUT and DELETE, for instance). The HTTP methods provide the verbs in a web interaction.
- Servers are completely stateless. Everything necessary to service a request is included by the client in the request.
- All application resources are described by unique URIs. Performing
a GET on a given URI returns a representation of that resource's state
(typically an HTML page, but possibly something else like XML). The
state of a resource is changed by performing a POST or PUT to the
resource URI. Thus, URIs name the nouns in a web interaction.
刚刚看CCTV实话实说,很有感触,义乌技术职业学院给人眼前一亮,尤其是他们副院长的一番言论。
技术职业学院非得要升本科,本科非要成清华,义乌职业技术学院副院长评价当前高校的现状,定位严重有问题,技术职业学院应该培养应用型人才,而清华就应该培养研究性人才,两种学校的定位不能一样,培养方式,评判标准都应该不同,而现在大多数高校的定位都一样,这是不对的。个人非常赞同这个观点,其实,这个观点也可以应用到我们这些刚开始工作的年轻人身上,消除浮躁,找准定位,然后沿着定位踏实做事,并且应该采取相应的评判标准,这个很重要。
1. RFC documents
2. SCEP operations
-
PKIOperation:
-
Certificate Enrollment - request: PKCSReq, response: PENDING, FAILURE, SUCCESS
-
Poll for Requester Initial Certificate - request: GetCertInitial, response: same as for PKCSReq
-
Certificate Access - request: GetCert, response: SUCCESS, FAILURE
-
CRL Access - request: GetCRL, response: raw DER encoded CRL
- Non-PKIOperation: clear HTTP Get
-
Get Certificate Authority Certificate - GetCACert, GetNextCACert, GetCACaps
-
Get Certificate Authority Certificate Chain - GetCACertChain
3. Request message formats for PKIOperation
- Common fields in all PKIOperation messages:
-
senderNonce
-
transactionID
- the SCEP message being transported(SCEP messages) -> encrypted using the public key of the recipient(Enveloped-data)
-> signed by one of certificates(Signed-data): the requester can generate a self-signed certificate, or the requester can use
a previously issued certificate, if the RA/CA supports the RENEWAL option.
- SCEP messages:
-
PKCSReq: PKCS#10
- GetCertInitial: messages for old versions of scep clients such as Sscep, AutoSscep, and Openscep, are different with draft-18
issuerAndSubject ::= SEQUENCE {
issuer Name,
subject Name
}
-
GetCert: an ASN.1 IssuerAndSerialNumber type, as specified in PKCS#7 Section 6.7
-
GetCRL: an ASN.1 IssuerAndSerialNumber type, as defined in PKCS#7 Section 6.7
--zz: http://forums13.itrc.hp.com/service/forums/questionanswer.do?admit=109447627+1230261484567+28353475&threadId=1213960
Question:
We are planning to calculate the percentage of physical memory utilised as below:
System Page Size: 4Kbytes
Memory: 5343128K (1562428K) real, 13632356K (3504760K) virtual, 66088K free Page# 1/604
Now the formula goes as below:
(free memory / actual active real memory) * 100
(66088/1562428) * 100 = 4.22 %
Please let us know if its the correct formula .
Mainly we are interested in RAM percentage utilised
Reply 1:
Red Hat/Centos v 5 take spare ram and use it for a buffer cache.
100%
memory allocation is pretty meaningless because allocation is almost
always near 100%. The 2.6.x kernel permits rapid re-allocation of
buffer to other purposes eliminating a performance penalty that you see
on an OS like HP-UX
I'm not thrilled with your formula because
it includes swap(virtual memory). If you start digging too deep into
virtual memory, your system start paging processes from memory to disk
and back again and slows down badly.
The formula is however essentially correct.
Reply 2:
Here, a quick example from the machine under my desk:
Mem: 3849216k total, 3648280k used, 200936k free, 210960k buffers
Swap: 4194296k total, 64k used, 4194232k free, 2986460k cached
If
the value of 'Swap used' is up (i.e. hundreds of megabytes), then
you've got an issue, but as you can see, it's only 64k here.
Your formula for how much memory is used is something along the lines of this:
(Used - (Buffers + Cached) / Total) * 100 = Used-by-programs%
(Free + Buffers + Cached / Total) * 100 = Free%
.. Roughly ..