2008年3月5日
#
1. Remote
Method Invocation (RMI)
2. Hessian
3. Burlap
4. HTTP invoker
5. EJB
6. JAX-RPC
7. JMX
zz from http://marakana.com/forums/tomcat/general/106.html
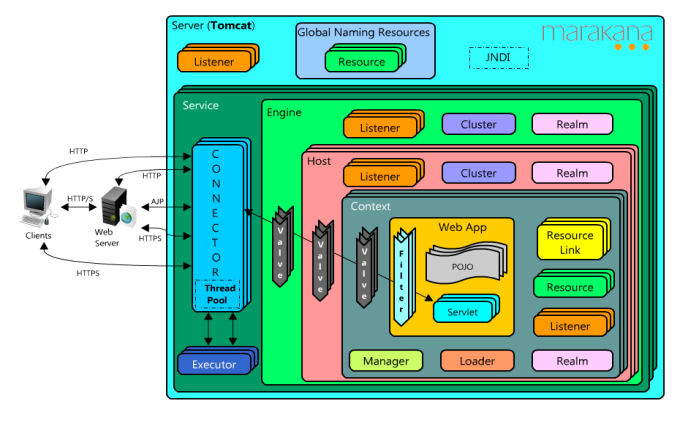
Valve and Filter:
"Valve" is Tomcat
specific notion, and they get applied at a higher level than anything in a specific webapp. Also, they work only in Tomcat.
"Filter" is a Servlet Specification notion and should work in any compliant servlet container. They get applied at a lower level than all of Tomcat's
Valves.
However, consider also the division between your application and the application
server. Think whether the feature you're planning is part of your application, or is it rather a generic feature of the application server, which could have uses in other applications as well. This would be the correct criteria to decide between Valve and Filter.
Order for filter: The order in which they are
defined matters. The container will execute the filters in the order
in which they are defined.
Use one single table "blank_fields" for both A and B. "blank_fields" has fields: 'ref_id', 'blank_field', 'type'. 'type' is used to identify which entity the record belongs to. Use 'type' + 'ref_id' to specify the collection of elements for one entity.
@Entity
@Table(name = "table_a")
public class A {
private Set<BlankField> blankFields = new HashSet<BlankField>();
@CollectionOfElements
@Fetch(FetchMode.SUBSELECT)
@Enumerated(EnumType.ORDINAL)
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "ref_id") })
@Cascade(value = org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
@Column(name = "blank_field", nullable = false)
@SQLInsert(sql = "INSERT INTO blank_fields(ref_id, blank_field, type) VALUES(?,?,0)")
@Where(clause = "type=0")
public Set<BlankField> getBlankFields() { // BlankField is an enum
return blankFields;
}
@SuppressWarnings("unused")
private void setBlankFields(Set<BlankField> blankFields) {
this.blankFields = blankFields;
}
} // End B
@Entity
@Table(name = "table_b")
public class B {
private Set<BlankField> blankFields = new HashSet<BlankField>();
@CollectionOfElements
@Fetch(FetchMode.SUBSELECT)
@Enumerated(EnumType.ORDINAL)
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "ref_id") })
@Cascade(value = org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
@Column(name = "blank_field", nullable = false)
@SQLInsert(sql = "INSERT INTO blank_fields(ref_id, blank_field, type) VALUES(?,?,1)") // used for insert
@Where(clause = "type=1") // used for query, if not @CollectionOfElements, such as @OneToMany, use @WhereJoinTable instead
public Set<BlankField> getBlankFields() {
return blankFields;
}
@SuppressWarnings("unused")
private void setBlankFields(Set<BlankField> blankFields) {
this.blankFields = blankFields;
}
}
当然还有其他的方式来实现上面的需求,上面采用的单表来记录不同实体的associations(这儿是CollectionOfElements,并且返回的是Set<Enum>,不是Set<Embeddable>),然后用'type'来区分不同的实体,这样做的好处是:数据库冗余少,易于扩展,对于新的实体,只需加一个type值,而不需更改数据库表结构。另外一种采用单表的方式是为每个实体增加新的字段,如"blank_fields": 'a_id', 'b_id', 'blank_field', a_id reference table_a (id), b_id reference table_b (id). 这样在映射的时候更简单,
对于A,映射为
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "a_id") })
对于B,映射为
@JoinTable(name = "blank_fields", joinColumns = { @JoinColumn(name = "b_id") })
这样作的缺点是:带来了数据库冗余,对于blank_fields来讲,任一条记录,a_id和b_id中只有一个不为null。当多个实体共用这个表时,用上面的方法更合理,如果共用实体不多时,这种方法更方便。
The case to use One Hibernate Session Multiple Transactions:
each transaction would NOT affect others.
i.e., open multiple transactions on the same session, even though one transaction rolls back, other transactions can be committed. If one action fails, others should fail too, then we should use one transaction for all actions.
Note:
A rollback with a single Session will lead to that Session being cleared (through "Session.clear()").
So do lazy collections still work if the session is cleared? =>Not of any objects that you loaded up until the rollback. Only for new objects loaded afterwards.
We should load necessary objects to session for each transactional action to avoid LazyInitializationException, even if those objects are loaded before other forward transactional actions, since forward action may be rolled back and clear the session.
BTW, Hibernate Session.merge() is different with Session.update() by:
Item item2 = session.merge(item);
item2 == item; // false, item - DETACHED, item2 - PERSIST
session.update(item); // no return value, make item PERSIST
发生这种异常的case:
@Transactional
public void foo() {
try{
bar();
} catch (RuntimeException re) {
// caught but not throw further

}
}
@Transactional
public void bar() {
}
如果foo在调用bar的时候,bar抛出RuntimeException,Spring在bar return时将Transactional标记为Rollback only, 而foo捕获了bar的RuntimeException,所以Spring将会commit foo的事务,但是foo和bar使用的是同一事务,因此在commit foo事务时,将会抛出UnexpectedRollbackException。注意:如果foo和bar在同一class中,不会出现这种情况,因为:
Since this mechanism is based on proxies, only 'external' method calls coming in through the proxy will be intercepted. This means that 'self-invocation', i.e. a method within the target object calling some other method of the target object, won't lead to an actual transaction at runtime even if the invoked method is marked with @Transactional!
可以通过配置log4j来debug Spring事务获取情况:
To delve more into it I would turn up your log4j logging to debug and also look at what ExerciseModuleController is doing at line 91, e.g.: add a logger for org.springframework.transaction
这周被Quartz折腾了一番。
我们知道,Quartz采用JobDataMap实现向Job实例传送配置属性,正如Quartz官方文档说的那样:
How can I provide properties/configuration for a Job instance? The key is the JobDataMap, which is part of the JobDetail object.
The JobDataMap can be used to hold any number of (serializable) objects
which you wish to have made available to the job instance when it
executes.
JobDataMap map = context.getJobDetail().getJobDataMap();
我们通过map向Job实例传送多个objects,其中有一个是个bean,一个是基本类型。对于scheduled triggers,我们要求bean对于所有的序列都不变,包括其属性,而基本类型可以在Job运行过程中改变,并影响下一个序列。实际情况是,对于下个序列,bean的属性被上次的修改了,而基本类型却维持第一次put到Map里面的值。正好和我们要求的相反。
受bean的影响,以为map里面包含的都是更新的对象,即每个序列里面的JobDetail是同一个对象,但是基本类型的结果否认了这一点。回头重新翻阅了下Quartz的文档:
Now, some additional notes about a job's state data (aka JobDataMap): A
Job instance can be defined as "stateful" or "non-stateful".
Non-stateful jobs only have their JobDataMap stored at the time they
are added to the scheduler. This means that any changes made to the
contents of the job data map during execution of the job will be lost,
and will not seen by the job the next time it executes.
Job有两个子接口:StatefulJob and InterruptableJob,我们继承的是InterruptableJob,或许Quartz应该有个InterruptableStatefulJob。另外StatefulJob不支持并发执行,和我们的需求不匹配,我们有自己的同步控制,Job必须可以并发运行。
然后查看了Quartz的相关源码:
// RAMJobStore.storeJob
public void storeJob(SchedulingContext ctxt, JobDetail newJob,
boolean replaceExisting) throws ObjectAlreadyExistsException {
JobWrapper jw = new JobWrapper((JobDetail)newJob.clone()); // clone a new one
.
jobsByFQN.put(jw.key, jw);
}
也就是说,store里面放的是初始JobDetail的克隆,在序列运行完时,只有StatefulJob才会更新store里面的JobDetail:
// RAMJobStore.triggeredJobComplete
public void triggeredJobComplete(SchedulingContext ctxt, Trigger trigger,
JobDetail jobDetail, int triggerInstCode) {
JobWrapper jw = (JobWrapper) jobsByFQN.get(jobKey);
if (jw != null) {
JobDetail jd = jw.jobDetail;
if (jd.isStateful()) {
JobDataMap newData = jobDetail.getJobDataMap();
if (newData != null) {
newData = (JobDataMap)newData.clone();
newData.clearDirtyFlag();
}
jd.setJobDataMap(newData); // set to new one
}
}
然后,每次序列运行时所用的JobDetail,是存放在Store里面的克隆。
// RAMJobStore.retrieveJob
public JobDetail retrieveJob(SchedulingContext ctxt, String jobName,
String groupName) {
JobWrapper jw = (JobWrapper) jobsByFQN.get(JobWrapper.getJobNameKey(
jobName, groupName));
return (jw != null) ? (JobDetail)jw.jobDetail.clone() : null; // clone a new
}
问题很清楚了,存放在Store里面的JobDetail是初始对象的克隆,然后每个序列所用的JobDetail, 是Store里面的克隆,只有Stateful job,Store里面的JobDetail才更新。
最有Quartz里面使用的clone():
// Shallow copy the jobDataMap. Note that this means that if a user
// modifies a value object in this map from the cloned Trigger
// they will also be modifying this Trigger.
if (jobDataMap != null) {
copy.jobDataMap = (JobDataMap)jobDataMap.clone();
}
所以对于前面所讲的,修改bean的属性,会影响所有clone的对象,因此,我们可以将基本类型封装到一个bean里面,map里面存放的是bean,然后通过修改bean的属性,来达到影响下一个序列的目的。
From:
Web application design: the REST of the story
Key points:
- HTTP is a very general, scalable protocol. While most people only
think of HTTP as including the GET and POST methods used by typical
interactive browsers, HTTP actually defines several other methods that
can be used to manipulate resources in a properly designed application
(PUT and DELETE, for instance). The HTTP methods provide the verbs in a web interaction.
- Servers are completely stateless. Everything necessary to service a request is included by the client in the request.
- All application resources are described by unique URIs. Performing
a GET on a given URI returns a representation of that resource's state
(typically an HTML page, but possibly something else like XML). The
state of a resource is changed by performing a POST or PUT to the
resource URI. Thus, URIs name the nouns in a web interaction.
刚刚看CCTV实话实说,很有感触,义乌技术职业学院给人眼前一亮,尤其是他们副院长的一番言论。
技术职业学院非得要升本科,本科非要成清华,义乌职业技术学院副院长评价当前高校的现状,定位严重有问题,技术职业学院应该培养应用型人才,而清华就应该培养研究性人才,两种学校的定位不能一样,培养方式,评判标准都应该不同,而现在大多数高校的定位都一样,这是不对的。个人非常赞同这个观点,其实,这个观点也可以应用到我们这些刚开始工作的年轻人身上,消除浮躁,找准定位,然后沿着定位踏实做事,并且应该采取相应的评判标准,这个很重要。
1. RFC documents
2. SCEP operations
-
PKIOperation:
-
Certificate Enrollment - request: PKCSReq, response: PENDING, FAILURE, SUCCESS
-
Poll for Requester Initial Certificate - request: GetCertInitial, response: same as for PKCSReq
-
Certificate Access - request: GetCert, response: SUCCESS, FAILURE
-
CRL Access - request: GetCRL, response: raw DER encoded CRL
- Non-PKIOperation: clear HTTP Get
-
Get Certificate Authority Certificate - GetCACert, GetNextCACert, GetCACaps
-
Get Certificate Authority Certificate Chain - GetCACertChain
3. Request message formats for PKIOperation
- Common fields in all PKIOperation messages:
-
senderNonce
-
transactionID
- the SCEP message being transported(SCEP messages) -> encrypted using the public key of the recipient(Enveloped-data)
-> signed by one of certificates(Signed-data): the requester can generate a self-signed certificate, or the requester can use
a previously issued certificate, if the RA/CA supports the RENEWAL option.
- SCEP messages:
-
PKCSReq: PKCS#10
- GetCertInitial: messages for old versions of scep clients such as Sscep, AutoSscep, and Openscep, are different with draft-18
issuerAndSubject ::= SEQUENCE {
issuer Name,
subject Name
}
-
GetCert: an ASN.1 IssuerAndSerialNumber type, as specified in PKCS#7 Section 6.7
-
GetCRL: an ASN.1 IssuerAndSerialNumber type, as defined in PKCS#7 Section 6.7
--zz: http://forums13.itrc.hp.com/service/forums/questionanswer.do?admit=109447627+1230261484567+28353475&threadId=1213960
Question:
We are planning to calculate the percentage of physical memory utilised as below:
System Page Size: 4Kbytes
Memory: 5343128K (1562428K) real, 13632356K (3504760K) virtual, 66088K free Page# 1/604
Now the formula goes as below:
(free memory / actual active real memory) * 100
(66088/1562428) * 100 = 4.22 %
Please let us know if its the correct formula .
Mainly we are interested in RAM percentage utilised
Reply 1:
Red Hat/Centos v 5 take spare ram and use it for a buffer cache.
100%
memory allocation is pretty meaningless because allocation is almost
always near 100%. The 2.6.x kernel permits rapid re-allocation of
buffer to other purposes eliminating a performance penalty that you see
on an OS like HP-UX
I'm not thrilled with your formula because
it includes swap(virtual memory). If you start digging too deep into
virtual memory, your system start paging processes from memory to disk
and back again and slows down badly.
The formula is however essentially correct.
Reply 2:
Here, a quick example from the machine under my desk:
Mem: 3849216k total, 3648280k used, 200936k free, 210960k buffers
Swap: 4194296k total, 64k used, 4194232k free, 2986460k cached
If
the value of 'Swap used' is up (i.e. hundreds of megabytes), then
you've got an issue, but as you can see, it's only 64k here.
Your formula for how much memory is used is something along the lines of this:
(Used - (Buffers + Cached) / Total) * 100 = Used-by-programs%
(Free + Buffers + Cached / Total) * 100 = Free%
.. Roughly ..
昨天遇到个非常奇怪的bug:更新了一下后台的代码,结果每次点击页面都会导致servlet方法调用两次,从而页面报错(逻辑上不让调两次 ),我们的前台采用gwt,servlet engine采用tomcat,debug的时候,断点放在servlet所调用的method上,结果invoke两次,由此断定,前台代码的问题(有点武断哦

),然后负责前台的同事debugging前台的代码,噼里啪啦半天。。。,说是前台好像没有调两次(之所以用好像,是debugging时部分代码走两次,部分走一次),而我当时的想法是,后台怎么操作,也不至于让servlet调用两次吧,所以我个人就认定是前台逻辑导致重复rpc调用(gwt),但是这个bug在这两天才出现的,从svn的历史记录来看,前台代码在这两天基本没什么改变,同事只好从svn上一个version接一个version的check,最后确定出两个相邻的versions,前一个能用,后一个出bug,这时我隐约感觉到是后台的问题,但是还是想不明白,后台的逻辑怎么就能让前台重复调用,非常不解,没办法,在同事的建议下,在servlet的那个method上加上一条debug信息,做了两次试验,一次是完整的代码,一次是把method中调用后台的接口注释掉,结果从日志上看出,前一次试验debug信息打印了两次,后一次试验debug只打印了一次,此时,确定是后台逻辑影响了前台的调用(此时,觉得走弯路了,为什么不早点做这个试验,其实确定是前台还是后台的问题,只需要做这样一个简单的试验。。。)。接下来,我思考的就是到底是什么在作怪呢,对比svn上的两个版本,只有两处可能的改动,一处是将return改成throw exception, 一处是调用了Thread.currentThread.interrupt(),我一个感觉是后者,注掉这句后,一切OK,呵呵,庆幸没有先尝试前者,要不改动很大,。。。
刚刚看了gwt的源码,还没找到问题的根源,我的观点是,thread接收到interrupt信号时,会重复发送rpc调用,(呵呵,还没确定)。。。
最近心情不是很好,上周三,父亲的一次意外,给家里本来平静的生活带来了很大的波澜,我也第一次感受到来自于家庭的压力,由此带来的一系列问题,一直萦绕着我,责任,responsibility,是这几天我告诫自己最多的一个词,是啊,该到了承受家庭责任的时候了。
父亲的这次意外,揪住了全家人的心,我也更多的为两位老人思考了,这两天,老想起一句话:人只有经历的多了,才能成熟。我很喜欢类比,其实就跟我们做数学题一样,看的多了,做的多了,考试的时候才能迎刃而解,什么东西,或许只有自己亲身经历,才能体会其中的更多细节,才能激发更多的收获。
祝福父亲的身体早日康复,bless。。。
最近,时不时地回想自己这一路的教育经历,使得我越来越相信——命运!
总体来说,我自认为我这一路上走的太顺利,缺少更多的经历,缺少一些该有的挫折!
但是,顺利归顺利,在两次作抉择的时候,随机的选择决定现在的方向!一次当然是过独木桥——高考,另一次是硕士入学时选择导师!两次选择都很随意,甚至于无意,尤其是第二次。第一次的随意更多的是无知,而第二次的无意,却源于自己的不适应。随意带来了大学时代的混乱,无意却给自己带来了意外的收获,人生无常,命运有数。
高考时,分数超出了自己的预料,志愿填的有些草率,一方面,是因为自己的年轻和无知,另一方面是由于周围缺少必要的指点,填的很仓促,很随意,非常的“高效”。正值00年高校扩招猖獗之时,我所填报的学校就是由三个学校合并而成,并且是在高考的前两个月宣布合并的,其中有两个合并之前不是一本,但是合并之后,肯定都是一本了。我当时选报了自动化这个专业,当时填的时候就因为高中班主任说了一声:“现在自动化是一个很好的方向。”然而,此时命运开始现数,其中有两个学校都有自动化这个专业,一个之前就是一本(合并后,称之为‘校本部’,不知道这个是什么意思,或许我要去查查字典,好好揣测一下本部的含义。),另一个是三个学校中最差的一个,报道那天才知道有两个自动化,但是由于刚合校,还没来得及合并专业,当时就想,我该在哪个校区的自动化呢?最后随着师长的指引,我被校车拉到了分校区,也就是那个最差的了,一路上,还在思索两个自动化的分配算法,还是直到开学一个月以后,一次偶然的机会,才得知:两个自动化是根据当时各省分数的交替顺序分配,安徽省生源的第一名在本部,第二名在分校区,第三名本部,第四名分校区。。。。只能怪自己被动的排在了一个偶数的序位上,如果用一个函数来表示这个序位的话,其自变量的个数还是蛮多的,当年安徽省报考该校该专业的人生,你在这些人中的名次,另外还有,我还不太确定的因素,但是我能确定因素的存在。。。
后来,进一步得知,分校区的自动化之前没有,我们是第一届,当时在合校之前就已经确定要新增这个专业,合的时候,各个学校的招生计划都没变,只是将三个计划简单的数学累加,现在看来,合校是多么的可笑,一个学校从任意层次可以一下成为中国最好的学校,只要清华愿意合并它,而合并后再很长一段时间,那个学校除了学生的层次提高之外,没有任何的改变,教师还是那些教师,设施还是那些设施,思想还是那些思想,我不知道这可不可以称之为赤裸裸的抢劫,它无视了那些默默地而踏踏实实前进的高校,助长了一些不公正的风气,或许正应了中国当时浮躁的社会氛围。
就这样在这度过了自己的三年大学时光,就在最后一个大学暑假之前,学校经过三年的发展和磨合,决定将我们这个专业撤销,统一合并到本部去,我们被迫搬回了第一天报道的地方,其实两个自动化的方向是不一样的,或许我们要庆幸,我们学习了两个专业,在大学的四年中,但是或许,更多的人可能会埋怨两个方向影响了自己的学习,其实,我想,大多数的人根本不在于什么方向,什么专业了,一个大框架的混乱,注定了最终的结果,就像当前的中国足球。。。
我要说的是,其实我在大学中过得很愉快,我认识了一批很好的同学,我经历了到目前为止最好的一段时光,虽然期间有很多遗憾,比如没谈一次恋爱。。。我想这段时光势必会在我的记忆集合中占据非常重要的一块。这里,我只不过是要论述命运有数,这样的一个过程多少还是影响了我的人生轨迹。
下面要谈论我的第二次抉择,硕士时选择导师。大学毕业时,我选择了继续就读,一切都很顺利,到了04年9月,我来到了新的学校,在合肥,这儿离家很近,因为我是安徽人,经历了大学时回家的艰辛,再加上我又是个比较恋家的人。刚入校,就遇到了一个。。。。
明天继续。。。。
1.
多行注释:
ctrl+v 进入列模式,向下或向上移动光标,把需要注释的行的开头标记起来,然后按大写的I,再插入注释符,比如#,再按esc,就会全部注释了.
zz: java.sys-con.com
Java servlet technology provides developers with functionality,
scalability, and portability that can't be found in other server-side
languages. One feature of the Java servlet specification that's
commonly used, and sometimes misused, is the HttpSession interface.
This simple interface allows you to maintain a session or state for Web
site visitors.
In my previous article ("Introduction to Session Management," [JDJ,
Vol. 7, issue 9]), I introduced you to session management and the
HttpSession interface. In that article, we walked through using the
HttpSession API to create, use, and destroy session objects for Web
site visitors. The next step is to better understand how to manage the
sessions and those objects in a session. This article will help you
achieve this by helping you understand the following concepts:
- Code-based session management through listeners
- Proper design of the session and the objects it contains
- Controlling what is in the session and why it's there
- Session persistence
- Memory management
The Java APIs discussed in this article are from Sun's Java Servlet 2.3 specification.
Listeners
A listener is an object that's
called when a specified event occurs. There are four listener
interfaces that allow you to monitor changes to sessions and the
objects that are in those sessions:
- HttpSessionListener
- HttpSessionBindingListener
- HttpSessionAttributeListener
- HttpSessionActivationListener
Figure 1 provides a method summary for each of the listener
interfaces. The implementing class that you write will override these
methods to provide the functionality you need.
HttpSessionListener
The HttpSessionListener
interface is used to monitor when sessions are created and destroyed on
the application server. Its best practical use would be to track
session use statistics for a server.
The use of HttpSessionListener requires a configuration entry
in the deployment descriptor, or web.xml file, of the application
server. This entry points the server to a class that will be called
when a session is created or destroyed. The entry required is simple.
All you need is a listener and listener-class element in the following
format. The listener-class element must be a fully qualified class
name.
<listener>
<listener-class>package.Class</listener-class>
</listener>
As you can see in Figure 1, the class that implements this
listener can override two methods: sessionCreated() and
sessionDestroyed(). These methods will be notified when the server
creates or destroys a session.
These methods take an HttpSessionEvent object as a parameter.
HttpSessionEvent is simply a class that represents notifications of
changes to the Web application's sessions. HttpSessionEvent has one
method, getSession(), that returns the HttpSession object that's been
modified.
HttpSessionBindingListener
The
HttpSessionBindingListener interface is implemented when an object
needs to be notified if it's being bound to a session or unbound from a
session.
This interface has two methods, valueBound() and
valueUnbound(), that are notified when the status of the object has
changed (see Figure 1).
These methods have an HttpSessionBindingEvent parameter that
can be used to retrieve the session that the object was bound to and
the name it was given in the session. In Figure 2, you can see the
methods of this object that are used to get the name that's assigned to
the object, the session it's bound to, and the actual object.
HttpSessionAttributeListener
The
HttpSessionAttributeListener interface is used to monitor changes to
attributes in any session on the server. This can be useful when you
know the name assigned to a specific object that gets put into the
session and you want to track how often it's being used.
As with HttpSessionListener, HttpSessionAttributeListener also
requires an entry in the deployment descriptor for the server. This
entry tells the server which class to call when an attribute in a
session has changed.
The HttpSessionAttributeListener interface has three methods -
attributeAdded(), attributeRemoved(), and attributeReplaced(). These
methods, shown in Figure 1, are called by the server when attributes of
a session are changed.
HttpSessionActivationListener
The final listener,
HttpSessionActivationListener, is implemented when an object needs to
know if the session that it's bound to is being activated or passivated
(moved). You would come across this scenario if your session is being
shared across JVMs or your server is persisting the session in a
database or file system.
This interface, displayed in Figure 1, has two methods that
are overridden by the implementing class: sessionDidActivate() and
sessionWillPassivate(). These methods are called when the status of the
session in a JVM is changed.
Session Persistence
Today's J2EE-compliant
servers allow for fault-tolerance and failover to provide support in
the event that a server suddenly becomes unavailable because of
hardware, software, or network failure. This support is usually
provided by allowing two or more application servers, often called a
cluster, to run together and provide backup support for each other. If
one server fails, the others pick up the requests and continue on as if
nothing happened. This allows your Web site visitors to keep going
without interruption.
A proxy server is usually used in front of the application
servers. This server is responsible for directing each HTTP request to
the appropriate server. The proxy server can be set up to ensure that
the server receiving the first request from a user will continue to
receive all subsequent requests from that user. This means that a
session created for the user on the application server will continue to
be available for that user. If the server suddenly fails, there has to
be a system in place to allow the session to continue on without it.
Session persistence allows the session contents to be saved
outside the application server so that other servers can access it.
Figure 3 shows the relationship between the persisted session data and
the application servers that access it. In this figure, you see a
client accessing a Web site's HTTP server. The HTTP server is
forwarding requests for application resources to one of the application
servers through the use of a proxy server. The application servers are
persisting the session data in an external form.
There are four types of session persistence:
- Memory persistence (one server or a cluster of two or more)
- File system persistence
- Database persistence
- Cookie persistence
Every application server will handle session persistence
differently and all servers may not support all types of persistence.
Objects that are placed in the session must be serializable for
persistence to work.
Memory Persistence
In most cases, a single
standalone server will store sessions in memory. This allows for fast
retrieval and update of the information. It also means that the session
information will be lost when the server is shut down. This is usually
the default configuration on most application servers. Memory
persistence can be used when two or more servers need to share the
session information. The application servers can be configured to share
any changes made to the session so that the information is available on
multiple servers. This redundancy of the session information helps the
cluster preserve the session during a failure.
File System Persistence
File system persistence
can be used to serialize any objects that are in the session. The
object contents are placed in a file on the server. The location of the
files created is configurable; however, the files must be accessible by
all the servers in the cluster. The speed at which the file system is
accessed can be a factor in the performance of your Web site. A slow
disk drive, for example, would result in a delay as data is read from
or written to the file.
Database Persistence
Database persistence can be
used to provide a central data store for the session contents. Each
application server in the cluster must be able to access the database.
When sessions are modified, the changes are immediately persisted in
the database. A data source is usually set up for JDBC persistence and
the connections are pooled. This provides a quicker response. There's
also the issue of database failover, which would be addressed at the
database level of the system.
Cookie Persistence
The fourth type of session
persistence, cookie persistence, is so ineffective and insecure that it
doesn't deserve consideration when designing a fail-safe system. Cookie
persistence, as the name implies, persists session data by storing the
session information in browser cookie(s). There's a limitation on data
handling because cookies store only text, not objects, and the amount
of data that can be transmitted in a cookie is limited. There's also
the fact that cookies transmit data back and forth between the client
and the server. This prevents you (at least it should) from saving
sensitive information, like a social security number. This type of
persistence should be used in only the smallest of Web sites, and only
if there's a good reason not to store the session in memory.
The most common type of persistence is database persistence.
It provides an efficient way of saving session data and it's usually
fairly easy to set up on the application server. Memory persistence in
a cluster is also easy to use, if your application server supports it.
The only drawback is that sessions can sometimes hold large amounts of
data. Storing the session in memory reduces the amount of memory
available to the other processes on the server. File system persistence
can be slow at times and the file system may not always be accessible
to multiple servers.
Watching the Session Size
As you and your
fellow employees work on a Web application, you may notice that more
and more objects are being thrown into the session, often "for
convenience" or "just temporarily." The session becomes a quick
catch-all for any information you need to get from your servlets to
your JSPs. The HttpSession interface makes sessions easy to use, which
can lead to the session being overused. This is a concern because the
session takes up space. In most cases that would be memory space. In
other cases, it could be database or file system space. In all cases,
it means more work for the server and more work for the programmers to
manage what is there.
Although the session is convenient because it's accessible
from every servlet or JSP, it's not always the best place to put
information. Most of the data that's retrieved for display in a Web
application will only be used on one page. Instead of putting the
information into the session scope, use the request scope and then
forward the request from the servlet to the JSP. This causes the
objects to be destroyed after the request has ended, which is after the
data is displayed by the JSP. If you put the objects into the session,
you would either have to remove them in your code or leave them there.
Leaving objects in the session is not a good idea because you're using
up valuable resources for no reason. This becomes even more of an issue
when your Web site has hundreds or thousands of visitors, all of whom
have a session that's loaded with objects.
Some objects should be stored in the session. Objects that may
be needed over and over again as a user moves through a Web site are
those that should be put into the session. Anything that needs to exist
longer than one request can be stored in the session, as long as these
objects are removed as soon as they're no longer needed.
Considerations for Managing Sessions
When working with sessions, there are a few things to consider before designing or redesigning a Web application:
- Are sessions needed in the application?
- How long should the session be inactive before timing out?
- Are all the objects in the session serializable?
- Are the objects being bound to the session too large?
- Do the objects that are in the session really need to be there?
A Need for Sessions
If you have unique
users on a Web site and need to know who they are or need to get
specific information to them, such as search results, then you should
be using sessions. If you follow the guidelines set here, there's no
reason not to use the HttpSession interface that Java provides. It's
easy to use, flexible, secure, and it helps you to build a better Web
site.
There's another architecture that deals with maintaining state for
a client. Instead of relying on the HttpSession interface, state for
clients can be maintained within Enterprise JavaBeans (EJBs). The EJB
architecture takes the business logic for an application and places it
in components or beans. A session bean is a type of EJB that exists for
a given client/server session and provides database access or other
business logic, such as calculations. Session beans can be stateless or
they can maintain the state for a client, very much like an HttpSession
object.
There is still some debate over where the state for a Web site
visitor should be maintained. The best design for the application at
this time is to continue using the HttpSession object for maintaining
the state of the presentation layer of the Web application and to use
stateful EJBs to maintain the state of the business logic and data
layer. There are many other factors that should be considered with
EJBs, one being the better performance of stateless beans over those
that maintain state. These issues, which are outside the scope of this
article, should be considered carefully when architecting an
application.
Session Timeout
By default, on most servers
the session is set to expire after 30 minutes of inactivity. The amount
of time can be configured in the deployment descriptor of the Web
application. The HttpSession API also provides a
setMaxInactiveInterval() method that you can use to specify the timeout
period for a session. The getMaxInactiveInterval() method will return
this timeout value. The value given is in seconds.
The length of time will vary depending on what your visitors
are doing on your site. If they're logging in to check their account
balance, a shorter session timeout period can be used because it
doesn't take long for a person to read a couple of numbers. If, on the
other hand, the user is logging in to read large amounts of data, you
need to be sure that you provide enough time for the user to do what he
or she wants without being logged out. If the user is constantly
navigating through your site, the session will last indefinitely.
Implement Serializable
It's important to
make sure that all objects placed in the session can be serialized.
This may not be an issue if you know that your Web application will not
run in a cluster, but it should still be done anyway. What happens if
your Web site grows too big for one server and you suddenly have to
move to two? If you implement Serializable in your code now, you won't
have to go back and do it later.
Keep It Simple
You should design objects
that are going to be placed into a session so that they're not too big
and don't contain unnecessary information. A JavaBean that contains a
customer's name, address, phone number, e-mail address, credit card
numbers, and order history should not be placed into the session if
you're only going to use the object to get the customer's name.
Session Contents
When you're working on a
Web site, it's important to know which objects are in the session and
why they're needed. The size of the session should be kept as small as
possible. If you're building a new Web site, work out ahead of time
what goes in the session, why it's there, and where it gets removed. If
you're redesigning an existing site, this may be a little tougher,
especially when you have hundreds of servlets and JSPs to deal with. In
this case, try implementing an HttpSessionAttributeListener to get an
idea of what is going into the session. With this information, you may
be able to better manage your sessions.
Conclusion
Hopefully this article helped
you to better understand the design issues involved in using the
HttpSession interface. Java provides a more robust session
implementation than other languages. It's because of this power and
flexibility that you must take the time to properly lay out the use of
the session. A well-designed session will help make a Web application
better for the programmers and the users.
References
Hall, M. (2002). More Servlets and JavaServer Pages. Prentice Hall PTR.
Java Servlet Technology:
http://java.sun.com/products/servlet
Enterprise JavaBeans Technology:
http://java.sun.com/products/ejb
Java BluePrints (J2EE):
http://java.sun.com/blueprints/guidelines/
designing_enterprise_applications
另外,还有一些收集的材料
关于HttpSession的误解实在是太多了,本来是一个很简单的问题,怎会搞的如此的复杂呢?下面说说我的理解吧:
1、HTTP协议本身是“连接-请求-应答-关闭连接”模式的,是一种无状态协议(HTTP只是一个传输协议);
2、Cookie规范是为了给HTTP增加状态跟踪用的(如果要精确把握,建议仔细阅读一下相关的RFC),但不是唯一的手段;
3、所谓Session,指的是客户端和服务端之间的一段交互过程的状态信息(数据);这个状态如何界定,生命期有多长,这是应用本身的事情;
4、由于B/S计算模型中计算是在服务器端完成的,客户端只有简单的显示逻辑,所以,Session数据对客户端应该是透明的不可理解的并且应该受控于服务端;Session数据要么保存到服务端(HttpSession),要么在客户端和服务端之间传递(Cookie或url rewritting或Hidden input);
5、由于HTTP本身的无状态性,服务端无法知道客户端相继发来的请求是来自一个客户的,所以,当使用服务端HttpSession存储会话数据的时候客户端的每个请求都应该包含一个session的标识(sid, jsessionid 等等)来告诉服务端;
6、会话数据保存在服务端(如HttpSession)的好处是减少了HTTP请求的长度,提高了网络传输效率;客户端session信息存储则相反;
7、客户端Session存储只有一个办法:cookie(url rewritting和hidden input因为无法做到持久化,不算,只能作为交换session id的方式,即a method of session tracking),而服务端做法大致也是一个道理:容器有个session管理器(如tomcat的 org.apache.catalina.session包里面的类),提供session的生命周期和持久化管理并提供访问session数据的 api;
8、使用服务端还是客户端session存储要看应用的实际情况的。一般来说不要求用户注册登录的公共服务系统(如google)采用 cookie做客户端session存储(如google的用户偏好设置),而有用户管理的系统则使用服务端存储。原因很显然:无需用户登录的系统唯一能够标识用户的就是用户的电脑,换一台机器就不知道谁是谁了,服务端session存储根本不管用;而有用户管理的系统则可以通过用户id来管理用户个人数据,从而提供任意复杂的个性化服务;
9、客户端和服务端的session存储在性能、安全性、跨站能力、编程方便性等方面都有一定的区别,而且优劣并非绝对(譬如TheServerSide号称不使用HttpSession,所以性能好,这很显然:一个具有上亿的访问用户的系统,要在服务端数据库中检索出用户的偏好信息显然是低效的,Session管理器不管用什么数据结构和算法都要耗费大量内存和CPU时间;而用cookie,则根本不用检索和维护session数据,服务器可以做成无状态的,当然高效);
reply1:
不过我们也不能在session里面放入过多的东西
一般来说不能超过4K
太多了
对系统资源是一个很严重的浪费
reply2:
4K已是很大的一个数字了。
我一般喜欢写一个类。封装用户登陆后的一些信息。
然后把这个类放在session中,取得直接用类的方法取相关信息,
最近接到两个很小的tickets,两个都是为了项目开发时的方便:一是将logs写入到数据库中,以方便日志的查询;一是在build时,在war包加入svn revision info。
1) logging to database
经过调查,决定采用log4j的org.apache.log4j.jdbc.JDBCAppender,于是采用:
# logging to db
log4j.logger.com.example=DEBUG, DATABASE
log4j.additivity.com.example=false
log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.DATABASE.url=jdbc:postgresql://localhost:5432/test
log4j.appender.DATABASE.driver=org.postgresql.Driver
log4j.appender.DATABASE.user=pguser
log4j.appender.DATABASE.password=post
log4j.appender.DATABASE.sql=INSERT INTO debug_log(created, logger, priority, message) VALUES (to_timestamp('%d{ISO8601}','YYYY-MM-DD HH:MI:SS.MS'),'%c.%M:%L','%p','%m')
log4j.appender.DB.layout=org.apache.log4j.PatternLayout
log4j.appender.DATABASE.layout.ConversionPattern=%d{ISO8601} %p %c.%M:%L %m
很直观,用起来还很方便,但是不久就出现了问题,tomcat抛出了exception。只好把之前fixed ticket reopen,提交新的comments:Unfortunately, org.apache.log4j.jdbc.JDBCAppender that ships with the Log4j distribution is not able to process logging messages that have characters like ' (single quote) and , (comma) in it. When logging messages contains characters like single quote or comma, the program will throw an exception.
重新google了,找到了一个plusjdbc,Looking further, I found an alternative JDBCAppender package (org.apache.log4j.jdbcplus.JDBCAppender) from http://www.dankomannhaupt.de/projects/index.html. It can solve this problem. 长叹了一下。
最后采用:
log4j.appender.DATABASE=org.apache.log4j.jdbcplus.JDBCAppender
log4j.appender.DATABASE.url=jdbc:postgresql://localhost:5432/test
log4j.appender.DATABASE.dbclass=org.postgresql.Driver
log4j.appender.DATABASE.username=pguser
log4j.appender.DATABASE.password=post
log4j.appender.DATABASE.sql=INSERT INTO debug_log(created, logger, priority, message) VALUES (to_timestamp('@LAYOUT:1@', 'YYYY-MM-DD HH:MI:SS.MS'),'@LAYOUT:3@','@LAYOUT:2@','@LAYOUT:4@')
log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
log4j.appender.DATABASE.layout.ConversionPattern=%d{ISO8601}#%p#%c.%M:%L#%m
log4j.appender.DATABASE.layoutPartsDelimiter=#
log4j.appender.DATABASE.buffer=1
log4j.appender.DATABASE.commit=true
log4j.appender.DATABASE.quoteReplace=true
问题解决,但是中间有点小波折,在我的项目中,log4j.jar(>1.2.9)重复了,在$CATALINA_HOME/lib下有一份,在web工程下的WEB-INF/lib下也有一份,而plus-jdbc.jar放置在$CATALINA_HOME/lib下,结果启动Tomcat,出现
log4j:ERROR A "org.apache.log4j.jdbcplus.JDBCAppender" object is not assignable to a "org.apache.log4j.Appender" variable.
log4j:ERROR The class "org.apache.log4j.Appender" was loaded by
log4j:ERROR [WebappClassLoader^M
delegate: false^M
repositories:^M
----------> Parent Classloader:^M
org.apache.catalina.loader.StandardClassLoader@1ccb029^M
] whereas object of type
log4j:ERROR "org.apache.log4j.jdbcplus.JDBCAppender" was loaded by [org.apache.catalina.loader.StandardClassLoader@1ccb029].
log4j:ERROR Could not instantiate appender named "DATABASE".
原来是两个JDBCAppender实例不在同一个classlaoder里面,将WEB-INF/lib下的log4j.jar删除掉,重启就没问题了,按理,将$CATALINA_HOME/lib下的plus-jdbc.jar移到WEB-INF/lib下,应该也没问题,没有测试。
2)Add build revision info in war file and read it on tomcat startup
这个经历比较惨痛,两个问题,如何获取revision? And how to read it when tomcat startup? 第二个问题倒是没什么,采用javax.servlet.ServletContextListener就可以实现,很简单,走弯路的是第一个问题,google后发现有两种常见的实现:
As I have learned, there are totally two solutions to get svn revision info.
First, retrieve the svn revision from local file($BASE_HOME/.svn/entries). Just parsing the xml file, get the revision property and write it to a properties file.(就是该死的xml,远在乌克兰的同事,该文件却不是xml的,也只怪自己调研不充分,还得折腾了半天,后来发现,最新版的svn为了performance的考虑,采用meta data来实现entries)
Second, retrieve the svn revision from the remote repository. The solution always use a svn client to perform a demand with remote server to retrieve the revision info. Installing a snv client and using SvnAnt? are most commonly used at present. SvnAnt? is an ant task that provides an interface to Subversion revision control system and encapsulates the svn client. It uses javahl - a native (JNI) java interface for the subversion api if it can find the corresponding library. javahl is platform-dependent.
Because of needing interaction with the server(服务器在国外,更新很慢), now I employ the first solution. But I found a flaw of this method when i was going off duty. Generally, we may update our project with svn before committing. This may make a mismatch with svn revision between remote server and local file. Svn revision in local file is usually updated when we update our project. But when we take a commit after update, the svn revision in the remote server will change to a new one.
So, the case is that if we update, commit, and then build, we may get a mismatch with the newest svn revision, and build the error revision into our ROOT.war. If we update , then build ,without commit, we can get right revision info.
下面是第一版实现:
<!-- retrieve the svn revision from the remote repository
<path id="svnant.lib" >
<fileset dir="${lib.dir}">
<include name="svnant.jar"/>
<include name="svnClientAdapter.jar"/>
<include name="svnjavahl.jar"/>
</fileset>
</path>
<taskdef name="svn" classpathref="svnant.lib" classname="org.tigris.subversion.svnant.SvnTask" />
<target name="get-svn-revision">
<svn username="*******" password="******" javahl="true">
<status urlProperty="https://example.com" path="." revisionProperty="svn.revision" />
</svn>
<echo>svn revision: ${svn.revision}</echo>
</target>
-->
<!-- retrieve the svn revision from local file(.svn/entries). The file may contain several 'wc-entries.entry.revision' elements.
The property will get several values seperated by ',' when using xmlproperty task. Then the svn revison expected will be the
max one of these property values.
-->
<property name="svn.revision.file" value=".svn/entries" />
<!-- This property is used to run xmlproperty task successfully with a low version of svn client (under 1.3.1). Don't sure whether it really makes sense -->
<property name="build.id" value="foo" />
<target name="get-svn-revision">
<xmlproperty file="${svn.revision.file}" collapseAttributes="true"/>
<echo>svn revision: ${wc-entries.entry.revision}</echo>
</target>
<!--
If the file doesn't contain any 'wc-entries.entry.revision' element, the content of the property file will be: revision = ${wc-entries.entry.revision};
If contain a 'wc-entries.entry.revision' element, mark this value as $revision_value, then the content will be: revision = $revision_value;
If contain several 'wc-entries.entry.revision' elements, mark these values as $value1, $value2, ..., respectively, then the content will be: revision = $value1,$value2,..., seperated by a ',';
-->
<property name="svn.revision.propertyfile" value="${build.dir}/revision.properties" />
<target name="write-svn-revision-to-file" depends="get-svn-revision">
<delete file="${svn.revision.propertyfile}"/>
<propertyfile file="${svn.revision.propertyfile}" comment="record svn revision">
<entry key="revision" value="${wc-entries.entry.revision}"/>
</propertyfile>
</target>
结果write-svn-revision-to-file这个在我这倒是可以获取本地的svn revision,但是远方的同事可急了,build老失败,只好把这部分build注释了,还好,到周末了,可以在家好好研究一下,很快找了一个新的工具:
It's my fault. In my version of svn, the entries file is xml formatted. So i parse it using ant task - 'xmlproperty'. Now i have fix this problem by using 'svnkit' tools, a pure java svn toolkit. Now there are two ways to retrieve svn revision. One is from remote repository server. For this one, before building, you should set your own username and password for the remote repository server('remote.repository.username' and 'remote.repository.password' properties in build.xml,respectively). Another one is retrieving revision from local working copy. If using this one, you should set 'local.repository' property in build.xml to your own directory.
利用svnkit,从服务器上获取revision大概是:
repository = SVNRepositoryFactory.create(SVNURL.parseURIDecoded(urlStr));
ISVNAuthenticationManager authManager = SVNWCUtil.createDefaultAuthenticationManager(username, password);
repository.setAuthenticationManager(authManager);
headRevision = repository.getLatestRevision();
从本地working copy获取revision:
SVNClientManager clientManager = SVNClientManager.newInstance();
SVNWCClient wcClient = clientManager.getWCClient();
SVNInfo info = wcClient.doInfo(new File(fileUrl), SVNRevision.WORKING);
headRevision = info.getRevision().getNumber();
利用ant task将获取的revision写入到一个配置文件中(如revision.properties),在tomcat启动的时候加载进来,就可以了。
zz: http://rosonsandy.blogdriver.com/rosonsandy/871539.html
1 - Tomcat的类载入器的结构
Tomcat Server在启动的时候将构造一个ClassLoader树,以保证模块的类库是私有的
Tomcat Server的ClassLoader结构如下:
+-----------------------------+
| Bootstrap |
| | |
| System |
| | |
| Common |
| / \ |
| Catalina Shared |
| / \ |
| WebApp1 WebApp2 |
+-----------------------------+
其中:
- Bootstrap - 载入JVM自带的类和$JAVA_HOME/jre/lib/ext/*.jar
- System - 载入$CLASSPATH/*.class
- Common - 载入$CATALINA_HOME/common/...,它们对TOMCAT和所有的WEB APP都可见
- Catalina - 载入$CATALINA_HOME/server/...,它们仅对TOMCAT可见,对所有的WEB APP都不可见
- Shared - 载入$CATALINA_HOME/shared/...,它们仅对所有WEB APP可见,对TOMCAT不可见(也不必见)
- WebApp - 载入ContextBase?/WEB-INF/...,它们仅对该WEB APP可见
2 - ClassLoader的工作原理
每个运行中的线程都有一个成员contextClassLoader,用来在运行时动态地载入其它类
系统默认的contextClassLoader是systemClassLoader,所以一般而言java程序在执行时可以使用JVM自带的类、$JAVA_HOME/jre/lib/ext/中的类和$CLASSPATH/中的类
可以使用Thread.currentThread().setContextClassLoader(...);更改当前线程的contextClassLoader,来改变其载入类的行为
ClassLoader被组织成树形,一般的工作原理是:
1) 线程需要用到某个类,于是contextClassLoader被请求来载入该类
2) contextClassLoader请求它的父ClassLoader来完成该载入请求
3) 如果父ClassLoader无法载入类,则contextClassLoader试图自己来载入
注意:WebApp?ClassLoader的工作原理和上述有少许不同:
它先试图自己载入类(在ContextBase?/WEB-INF/...中载入类),如果无法载入,再请求父ClassLoader完成
由此可得:
- 对于WEB APP线程,它的contextClassLoader是WebApp?ClassLoader
- 对于Tomcat Server线程,它的contextClassLoader是CatalinaClassLoader
3 类的查找
ClassLoader类中loadClass方法为缺省实现,用下面的顺序查找类:
1、调用findLoadedClass方法来检查是否已经被加载。如果没有则继续下面的步骤。
2、如果当前类装载器有一个指定的委托父装载器,则用委托父装载器的loadClass方法加载类,也就是委托给父装载器加载相应的类。
3、如果这个类装载器的委托层级体系没有一个类装载器加载该类,则使用类装载器定位类的特定实现机制,调用findClass方法来查找类。
4 - 部分原代码分析
4.1 - org/apache/catalina/startup/Bootstrap.java
Bootstrap中定义了三个classloader:commonLoader,catalinaLoader,sharedLoader.三者关系如下:
//注意三个自己定置的ClassLoader的层次关系:
// systemClassLoader (root)
// +--- commonLoader
// +--- catalinaLoader
// +--- sharedLoader
Tomcat Server线程的起点
构造ClassLoader树,通过Thread.currentThread().setContextClassLoader(catalinaLoader)设置当前的classloader为catalinaLoader。
载入若干类,然后转入org.apache.catalina.startup.Catalina类中
4.2 org.apache.catalina.loader.StandardClassLoader.java
通过看loadClass这个方法来看tomcat是如何加载类的,顺序如下:
(0) Check our previously loaded class cache查找已经装载的class
clazz = findLoadedClass(name);
(1) If a system class, use system class loader通过系统classloader来装载class
ClassLoader loader = system;
clazz = loader.loadClass(name);
(2) Delegate to our parent if requested如果有代理则使用父类classloader
ClassLoader loader = parent;
if (loader == null)
loader = system;
clazz = loader.loadClass(name);
(3) Search local repositories 查找本地类池,比如$CATALINA_HOME/server
clazz = findClass(name);
(4) Delegate to parent unconditionally 默认使用代理装载器
[查看代码]
4.3 - org/apache/catalina/startup/ClassLoaderFactory.java
根据设置创建并返回StandardClassLoader的实例
[查看代码]
4.4 - org/apache/catalina/loader/StandardClassLoader.java
类载入器
4.5 - org/apache/catalina/startup/SecurityClassLoad.java
该类仅包含一个静态方法,用来为catalinaLoader载入一些类
[查看代码]
Appendix - 参考
[1] http://jakarta.apache.org/tomcat/中的Tomcat 4.1.x文档Class Loader HOW-TO
在一个JVM中可能存在多个ClassLoader,每个ClassLoader拥有自己的NameSpace。一个ClassLoader只能拥有一个class对象类型的实例,但是不同的ClassLoader可能拥有相同的class对象实例,这时可能产生致命的问题。如ClassLoaderA,装载了类A的类型实例A1,而ClassLoaderB,也装载了类A的对象实例A2。逻辑上讲A1=A2,但是由于A1和A2来自于不同的ClassLoader,它们实际上是完全不同的,如果A中定义了一个静态变量c,则c在不同的ClassLoader中的值是不同的。
[2] 深入Java2平台安全
zz: http://mail-archives.apache.org/mod_mbox/tomcat-users/200212.mbox/raw/%3c20021204192034.P86616-100000@icarus.apache.org%3e
try {
Properties props = new Properties();
InputStream in = getClass().getResourceAsStream("/conf/db.properties");
props.load(in);
......
propertie1 = props.getProperty("propertie1");
The examples already given will find properties files for you just fine whether the file is in a directory structure or inside an archive. How do you think Java loads classes? It works out of archives, no? here are some various was to access a properties file ( or any resource, for that matter) in whether the app is deployed as a directory or as a .war file (even inside a .jar file in WEB-INF/lib)....
1. This will load a file in WEB-INF/classes/conf or any jar file in the classpath with a package of "conf"...
getClass().getResourceAsStream("/conf/db.properties");
2. This will load a file relative to the current class. For instance, if the class is "org.mypackage.MyClass", then the file would be loaded at "org.mypackage.conf.dbproperties". Note that this is because we didn't prepend "/" to the path. When that is done, the file is loaded from the root of the current classloader where this loads it relative to the current class...
getClass().getResourceAsStream("conf/db.properties");
3. This will find db.properties anywhere in the current classloader as long as it exists in a "conf" package...
getClass().getClassLoader().getResourceAsStream("conf/db.properties");
4. This will find the file in a "conf" directory inside the webapp (starting from the root). This starts looking in the same directory as contains WEB-INF. When I say "directory", I don't mean "filesystem". This could be in a .war file as well as in an actual directory on the filesystem...
getServletContext().getResourceAsStream("/conf/db.properties");
5. Of course you would probably not want just anyone seeing your db.properties file, so you'd probably want to put in inside WEB-INF of your webapp, so....
getServletContext().getResourceAsStream("/WEB-INF/conf/db.properties");
6. If your db.properties exists in another classloader which your app has access to, you can reach it by using:
Thread.currentThread().getContextClassLoader().getResourceAsStream("conf/db.properties");
that will act similar to getClass().getClassLoader(), but it can see across all available classloaders where the latter can only see within the classloader that loaded the current class.
1、sudo vim ~/.exrc
添加如下内容:
if &t_Co > 1
syntax enable
endif
2、如果不行,再sudo apt-get install vim
/usr/share/fonts/truetype/ 下面 的某文件夹,例如yahei
cd /usr/share/fonts/truetype/yahei
sudo mkfontscale && sudo mkfontdir && sudo fc-cache -fv