Struts 2 中不想要要在在处理和HTTP相关的操作,自需要使用框架的接口即可。
在Strut 2 中不再会涉及到诸如 HttpServletRequest, HttpServletResponse, HttpSession等Http相关的Servlet接口类,取而代之的是Struts 2 的接口,例如RequestAware,SessionAware等。
Struts 2 的标签基于 CSS,标签可以提供自己需要的HTML支持。
Struts 2 的标签利用了CSS和模板,使用起来会非常方便,在Struts 1.x中我们需要使用Table来组织表单,但是在Struts 2中所有的标签自带了Table内容,可以方便的处理格式。例如<s:textfield> 标签自动添加了 <tr> <td> 等标签。
有状态的Checkbox,可以以一种统一的方式记录checkbox状态的变化。
在Struts 2中即使没有被选中的checkbox其内容仍然存在于Struts 2 框架中,不必像在Struts 1.x中那样需要做特殊的存在性判断。
灵活的取消按钮,在取消按钮点击的时候可以指向一个不同的action。
@TODO
可以在制定Form的action的同时,制定cancel按钮的action,当点击submit和cancel的时候出现完全按不同的功能。
第一等级的AJAX的支持,在普通struts 标签的基础上,使用AJAX增加了交互性和灵活性。
Struts 2 的标签内置了Ajax的支持。Struts 2 的标签使用了Dojotoolkit Ajax框架,不但能够使用Ajax特性,而且能够使用非常丰富和强大的浏览器小控件,例如日期选择控件
见到那集成Spring框架,非常简单的使用Spring框架提供的依赖注入功能。
可以方便的使用Spring管理Struts 2 的action的创建,通过使用Spring可以充分的利用Spring的依赖诸如功能,并且能够很好的集成其他的框架,例如Hibernate,iBatis等。
更多的返回形式,除了JSP还支持,JasperReports,JFreeChart, Action链,文件下载等。
除了支持JSP的表现形式,还支持JasperResports报表, JFreechart图标,Action链,文件下载等。
POJO表单,不再需要ActionForms,使用Javabean获得客户的收入或者将属性表示出来,
完全消除了ActionForm组建,可以使用任意合适的类型来接受页面传来的数据或者将数据表现出来。ActionFrom可以使用POJO的 JavaBean来替代,JavaBean中的属性可以使用String,也可以使用具体的类型,例如Date,Int等。
POJO Action,使用任意的类作为Action类,甚至可以使用接口。
任何类都可以作为Action类,只要接口满足一些简单的定义,不需要在使用Action类似的基类,你可以完全自由的发挥。
部署
插件结构,使用jar文件扩展框架功能,不需要在做手动的配置,内置了JavaServer Faces, JasperResports, JFreeChart, Tiles等插件。
扩展一个功能只需要添加一个插件,插件甚至可以热插拔,在你的应用不停止的情况下追加新的功能。
集成了分析功能,可以方便的找到程序性能的问题点。
可以不借助外力发现程序的热点,找到问题的所在,
准确的报告错误,可以非常准确的指出程序的问题点。
准确的报告运行时的错误,方便解决问题。
维护
Action容易测试,直接测试Struts 2的Action,不需要使用Mock Http对象来测试。
Action是普通的类,不需要特殊的环境,所以Struts 2 的Action 特别容易测试。
聪明的默认值,不需要配置不必要的配置,大部分的框架配置元素的都有非常合适的默认值,基本上你不需要在做任何配置。
Struts 2 有很多的配置项,但是每一个都有默认值,基本额上不需要更改默认的选项即可保证最佳
容易定制的控制器,可以定制每一个Action的处理过程。
可以使用Intercepter来过滤每一个Action,在Action执行前后追加自定义的操作。
集成了Debugging,可以使用内容之的debugging工具找到问题。
灵活的标签库,可以通过修改FreeMarker模板来定制标签的输出,不需要在操作像天书异样的JSP Taglib API,模板语言支持,Freemarker和Velocity
可以自定义模板库,或者修改已有模板的内容来定制页面的显示。
Struts 2 中使用的模式
Command
Chain of responsibility
Struts2 处理流程概要
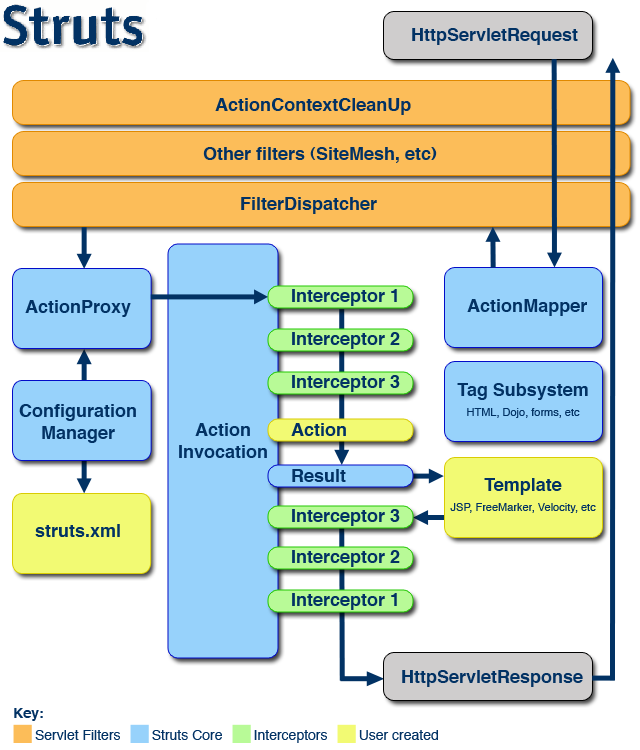
上图来源于Struts2官方站点,是Struts 2 的整体结构。
一个请求在Struts2框架中的处理大概分为以下几个步骤
1 客户端初始化一个指向Servlet容器(例如Tomcat)的请求
2 这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin)
3 接着FilterDispatcher被调用,FilterDispatcher询问ActionMapper来决定这个请是否需要调用某个Action
4 如果ActionMapper决定需要调用某个Action,FilterDispatcher把请求的处理交给ActionProxy
5 ActionProxy通过Configuration Manager询问框架的配置文件,找到需要调用的Action类
6 ActionProxy创建一个ActionInvocation的实例。
7 ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到相关拦截器(Intercepter)的调用。
8 一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可 能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2 框架中继承的标签。在这个过程中需要涉及到ActionMapper
在上述过程中所有的对象(Action,Results,Interceptors,等)都是通过ObjectFactory来创建的。
MyEclipse 快捷键
(1)Ctrl+M切换窗口的大小
(2)Ctrl+Q跳到最后一次的编辑处
(3)F2当鼠标放在一个标记处出现Tooltip时候按F2则把鼠标移开时Tooltip还会显示即Show Tooltip Description。
F3跳到声明或定义的地方。
F5单步调试进入函数内部。
F6单步调试不进入函数内部,如果装了金山词霸2006则要把“取词开关”的快捷键改成其他的。
F7由函数内部返回到调用处。
F8一直执行到下一个断点。
(4)Ctrl+Pg~对于XML文件是切换代码和图示窗口
(5)Ctrl+Alt+I看Java文件中变量的相关信息
(6)Ctrl+PgUp对于代码窗口是打开“Show List”下拉框,在此下拉框里显示有最近曾打开的文件
(7)Ctrl+/ 在代码窗口中是这种//~注释。
Ctrl+Shift+/ 在代码窗口中是这种/*~*/注释,在JSP文件窗口中是<!--~-->。
(8)Alt+Shift+O(或点击工具栏中的Toggle Mark Occurrences按钮) 当点击某个标记时可使本页面中其他地方的此标记黄色凸显,并且窗口的右边框会出现白色的方块,点击此方块会跳到此标记处。
(9)右击窗口的左边框即加断点的地方选Show Line Numbers可以加行号。
(10)Ctrl+I格式化激活的元素Format Active Elements。
Ctrl+Shift+F格式化文件Format Document。
(11)Ctrl+S保存当前文件。
Ctrl+Shift+S保存所有未保存的文件。
(12)Ctrl+Shift+M(先把光标放在需导入包的类名上) 作用是加Import语句。
Ctrl+Shift+O作用是缺少的Import语句被加入,多余的Import语句被删除。
(13)Ctrl+Space提示键入内容即Content Assist,此时要将输入法中Chinese(Simplified)IME-Ime/Nonlme Toggle的快捷键(用于切换英文和其他文字)改成其他的。
Ctrl+Shift+Space提示信息即Context Information。
(14)双击窗口的左边框可以加断点。
(15)Ctrl+D删除当前行。
---待续
[以下为转载]
Eclipse快捷键大全
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)
Ctrl+D: 删除当前行
Ctrl+Alt+↓ 复制当前行到下一行(复制增加)
Ctrl+Alt+↑ 复制当前行到上一行(复制增加)
Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)
Alt+↑ 当前行和上面一行交互位置(同上)
Alt+← 前一个编辑的页面
Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)
Alt+Enter 显示当前选择资源(工程,or 文件 or文件)的属性
Shift+Enter 在当前行的下一行插入空行(这时鼠标可以在当前行的任一位置,不一定是最后)
Shift+Ctrl+Enter 在当前行插入空行(原理同上条)
Ctrl+Q 定位到最后编辑的地方
Ctrl+L 定位在某行 (对于程序超过100的人就有福音了)
Ctrl+M 最大化当前的Edit或View (再按则反之)
Ctrl+/ 注释当前行,再按则取消注释
Ctrl+O 快速显示 OutLine
Ctrl+T 快速显示当前类的继承结构
Ctrl+W 关闭当前Editer
Ctrl+K 参照选中的Word快速定位到下一个
Ctrl+E 快速显示当前Editer的下拉列表(如果当前页面没有显示的用黑体表示)
Ctrl+/(小键盘) 折叠当前类中的所有代码
Ctrl+×(小键盘) 展开当前类中的所有代码
Ctrl+Space 代码助手完成一些代码的插入(但一般和输入法有冲突,可以修改输入法的热键,也可以暂用Alt+/来代替)
Ctrl+Shift+E 显示管理当前打开的所有的View的管理器(可以选择关闭,激活等操作)
Ctrl+J 正向增量查找(按下Ctrl+J后,你所输入的每个字母编辑器都提供快速匹配定位到某个单词,如果没有,则在stutes line中显示没有找到了,查一个单词时,特别实用,这个功能Idea两年前就有了)
Ctrl+Shift+J 反向增量查找(和上条相同,只不过是从后往前查)
Ctrl+Shift+F4 关闭所有打开的Editer
Ctrl+Shift+X 把当前选中的文本全部变味小写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+Shift+F 格式化当前代码
Ctrl+Shift+P 定位到对于的匹配符(譬如{}) (从前面定位后面时,光标要在匹配符里面,后面到前面,则反之)
下面的快捷键是重构里面常用的,本人就自己喜欢且常用的整理一下(注:一般重构的快捷键都是Alt+Shift开头的了)
Alt+Shift+R 重命名 (是我自己最爱用的一个了,尤其是变量和类的Rename,比手工方法能节省很多劳动力)
Alt+Shift+M 抽取方法 (这是重构里面最常用的方法之一了,尤其是对一大堆泥团代码有用)
Alt+Shift+C 修改函数结构(比较实用,有N个函数调用了这个方法,修改一次搞定)
Alt+Shift+L 抽取本地变量( 可以直接把一些魔法数字和字符串抽取成一个变量,尤其是多处调用的时候)
Alt+Shift+F 把Class中的local变量变为field变量 (比较实用的功能)
Alt+Shift+I 合并变量(可能这样说有点不妥Inline)
Alt+Shift+V 移动函数和变量(不怎么常用)
Alt+Shift+Z 重构的后悔药(Undo)
1.250定律
拉德认为:每一位顾客身后,大体有250名亲朋好友。如果您赢得了一位顾客的好感,就意味着赢得了250个人的好感;反之,如果你得罪了一名顾客,也就意味着得罪了250 名顾客。 在你的网站访客中,一个访客可能可以带来一群访客,任何网站都有起步和发展的过程,这个过程中此定律尤其重要。
2.达维多定律
达维多认为,一个企业要想在市场上总是占据主导地位,那么就要做到第一个开发出新产品,又第一个淘汰自己的老产品。 国内网站跟风太严重,比如前段时间的格子网,乞讨网,博客网,一个成功了,大家一拥而上。但实际效果是,第一个出名的往往最成功,所以在网站的定位上,要动自己的脑筋,不是去捡人家剩下的客户。同理,买人家出售的数据来建站效果是很糟糕的。
3.木桶定律
水桶定律是指,一只水桶能装多少水,完全取决于它最短的那块木板。这就是说任何一个组织都可能面临的一个共同问题,即构成组织的各个部分往往决定了整个组织的水平。 注意审视自己的网站,是速度最糟糕?美工最糟糕?宣传最糟糕?你首先要做的,不是改进你最强的,而应该是你最薄弱的。
4.马太效应
《新约》中有这样一个故事,一个国王远行前,交给三个仆人每人一锭银子,吩咐他们:“你们去做生意,等我回来时,再来见我。”国王回来时,第一个仆人说: “主人,你交给我们的一锭银子,我已赚了10锭。”于是国王奖励他10座城邑。第二个仆人报告说:“主人,你给我的一锭银子,我已赚了5锭。”于是国王例奖励了他5座城邑。第三个仆人报告说:“主人,你给我的一锭银子,我一直包在手巾里存着,我怕丢失,一直没有拿出来。”于是国王命令将第三个仆人的一锭银子也赏给第一个仆人,并且说:“凡是少的,就连他所有的也要夺过来。凡是多的,还要给他,叫他多多益善。”这就是马太效应。 在同类网站中,马太效应是很明显的。一个出名的社区,比一个新建的社区,更容易吸引到新客户。启示是,如果你无法把网站做大,那么你要做专。作专之后再做大就更容易。
5.手表定理
手表定理是指一个人有一只表时,可以知道现在是几点钟,而当他同时拥有两只表时却无法确定。
一个网站,你只需要关注你特定的用户群需求。不要在意不相干人的看法。
6.不值得定律
不值得定律:不值得做的事情,就不值得做好 不要过度seo,如果你不是想只做垃圾站。不要把时间浪费在美化再美化页面,优化再优化程序,在你网站能盈利后,这些事情可以交给技术人员完成。
7.彼得原理
劳伦斯.彼得认为:在各种组织中,由于习惯于对在某个等级上称职的人员进行晋升提拔,因而雇员总是趋向于晋升到其不称职的地位。
不要轻易改变自己网站的定位。如博客网想变门户,盛大想做娱乐,大家拭目以待吧。
8.零和游戏原理
当你看到两位对弈者时,你就可以说他们正在玩“零和游戏”。因为在大多数情况下, 总会有一个赢,一个输,如果我们把获胜计算为得1分,而输棋为-1分,那么,这两人得分之和就是:1+(-1)=0 不要把目光一直盯在你的竞争网站上,不要花太多时间抢它的访客。我们把这些时间用来寻找互补的合作网站,挖掘新访客。
9.华盛顿合作规律
华盛顿合作规律说的是: 一个人敷衍了事,两个人互相推诿, 三个人则永无成事之日。
如果你看准一个方向,你自己干,缺人手就招。不要轻易找同伴一起搞网站,否则你会发现,日子似乎越过越快了,事情越做越慢了。
10.邦尼人力定律
一个人一分钟可以挖一个洞,六十个人一秒种却挖不了一个洞。合作是一个问题,如何合作也是一个问题。你需要有计划。
11.牛蛙效应
把一只牛蛙放在开水锅里,牛蛙会很快跳出来;但当你把它放在冷水里,它不会跳出来,然后慢慢加热,起初牛蛙出于懒惰,不会有什么动作,当水温高到它无法忍受的时候,想出来,但已经没有了力气。 如果你是soho,注意关注你的财务。不要等到没钱了再想怎么挣,你会发现那时候挣钱更难。
12.蘑菇管理
蘑菇管理是许多组织对待初出茅庐者的一种管理方法,初学者被置于阴暗的角落(不受重视的部门,或打杂跑腿的工作),浇上一头大粪(无端的批评、指责、代人受过),任其自生自灭(得不到必要的指导和提携)。
做网站毕竟要遭遇这样的阶段,搜索引擎不理你,友情链接找不到,访客不上门。这是磨练。
13.奥卡姆剃刀定律
如无必要,勿增实体。
把网站做得简单,再简单,简单到非常实用,而不是花俏。google的首页为什么比雅虎好?
14.巴莱多定律(Paredo 也叫二八定律)
你所完成的工作里80%的成果,来自于你20%的付出;而80%的付出,只换来20%的成果。
随时衡量你所做的工作,哪些是最有效果的。
1.马蝇效应
林肯少年时和他的兄弟在肯塔基老家的一个农场里犁玉米地,林肯吆马,他兄弟扶犁,而那匹马很懒,慢慢腾腾,走走停停。可是有一段时间马走得飞快。林肯感到奇怪,到了地头,他发现有一只很大的马蝇叮在马身上,他就把马蝇打落了。看到马蝇被打落了,他兄弟就抱怨说:”哎呀,你为什么要打掉它,正是那家伙使马跑起来的嘛!” 在你心满意足的时候,去寻找你的马蝇。没有firefox,不会有ie7,firefox就是微软的马蝇之一。马蝇不可怕,怕的是会一口吃掉你的东西,像ie当初对网景干的那样。
2.最高气温效应
每天最热总是下午2 时左右,我们总认为这个时候太阳最厉害,其实这时的太阳早已偏西,不再是供给最大热量的时候了。此时气温之所以最高,不过是源于此前的热量积累。
你今天的网站流量,是你一个星期或更长时间前所做的事带来的。
3.超限效应(溢出效应)
刺激过多、过强和作用时间过久而引起心理极不耐烦或反抗的心理现象,称之为“超限效应”。 别到别人论坛里发太多广告。别在自己网站上放太多广告。别在自己的论坛里太多地太明显地诱导话题。
4.懒蚂蚁效应
生物学家研究发现,成群的蚂蚁中,大部分蚂蚁很勤劳,寻找、搬运食物争先恐后,少数蚂蚁却东张西望不干活。当食物来源断绝或蚁窝被破坏时,那些勤快的蚂蚁一筹莫展。“懒蚂蚁”则“挺身而出”,带领众伙伴向它早已侦察到的新的食物源转移。 不要把注意力仅仅放在一个网站上,即使这个网站现在为你带来一切。你要给自己一些时间寻找新的可行的方向,以备万一。
5.长尾理论
ChrisAnderson认为,只要存储和流通的渠道足够大,需求不旺或销量不佳的产品共同占据的市场份额就可以和那些数量不多的热卖品所占据的市场份额相匹敌甚至更大。 对于搜索引擎,未必你需要一个热门词排在第一位,如果有一千个冷门词排在第一位,效果不但一样,还会更稳定更长远。
6.破窗理论
栋建筑上的一块玻璃,又没有及时修好,别人就可能受到某些暗示性的纵容,去打碎更多的玻璃。 管理论坛时,如果你发现第一个垃圾贴,赶紧删掉他吧。想想:落伍现在为什么那么多××贴?现在控制比最初控制难多了。
7.“羊群效应”,又称复制原则(Copy Strategy)
一个羊群(集体)是一个很散乱的组织,平时大家在一起盲目地左冲右撞。如果一头羊发现了一片肥沃的绿草地,并在那里吃到了新鲜的青草,后来的羊群就会一哄而上,争抢那里的青草,全然不顾旁边虎视眈眈的狼,或者看不到其它地方还有更好的青草。
不要轻易跟风,保持自己思考的能力。
8.墨菲定律
如果坏事情有可能发生,不管这种可能性多么小,它总会发生,并引起最大可能的损失。
除非垃圾站,否则不要作弊,对搜索引擎不要,对广告也不要。
9.光环效应
人们对人的某种品质或特点有清晰的知觉,印象比较深刻、突出, 这种强烈的知觉, 就像月晕形式的光环一样,向周围弥漫、扩散,掩盖了对这个人的其他品质或特点的认识。
不要轻易崇拜一个人或者公司、一个概念、一种做法。
10.蝴蝶效应
一只亚马逊河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,两周后,可能在美国德克萨斯州引起一场龙卷风。
不管你做什么,网站或者其他,你都应该关注新闻。机遇或者灾难可能就在那。
11.阿尔巴德定理
一个企业经营成功与否,全靠对顾客的要求了解到什么程度。 我赞同别人的点评:看到了别人的需要,你就成功了一半;满足了别人的需求,你就成功了全部。尤其是做网站。
12.史密斯原则
如果你不能战胜他们,你就加入到他们之中去。
不要试图做孤胆英雄。如果潮流挡不住,至少,你要去思考为什么。