|
#
放一些屏幕截图来看图说话吧
流程设计界面
左边下拉框放至了我所有允许定义流程的业务对象类型,可通过底部的"新增"\"修改"\"删除"等操作进行维护.点击已定义的流程可以查看对应的流程设置
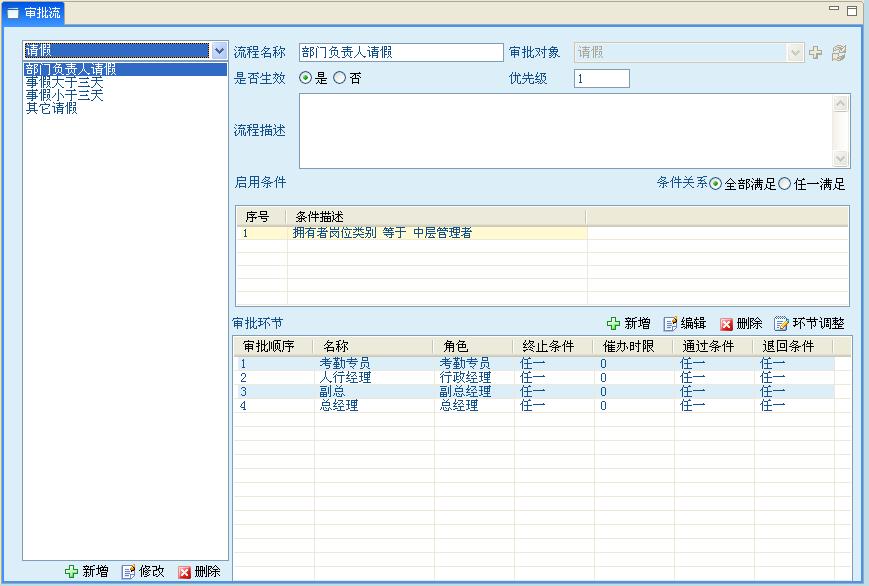
新增流程界面
新增时可为该流程设置相关启用条件,优先级别及审批步骤等
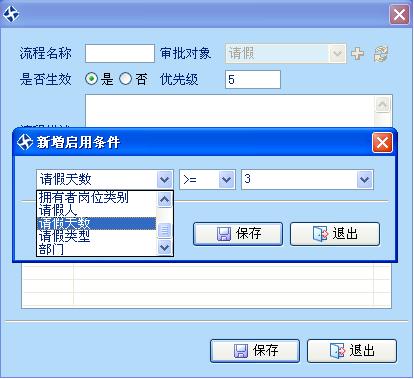
审批人的待办工作台,可以这里统一处理各类待办业务:
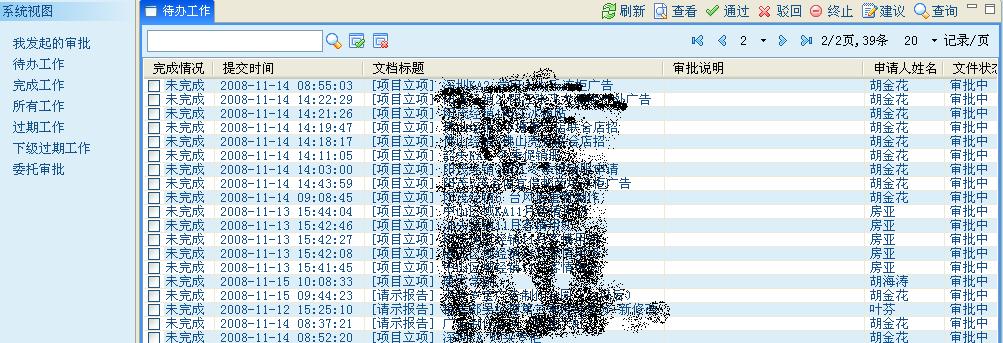
待办业务的查看界面:
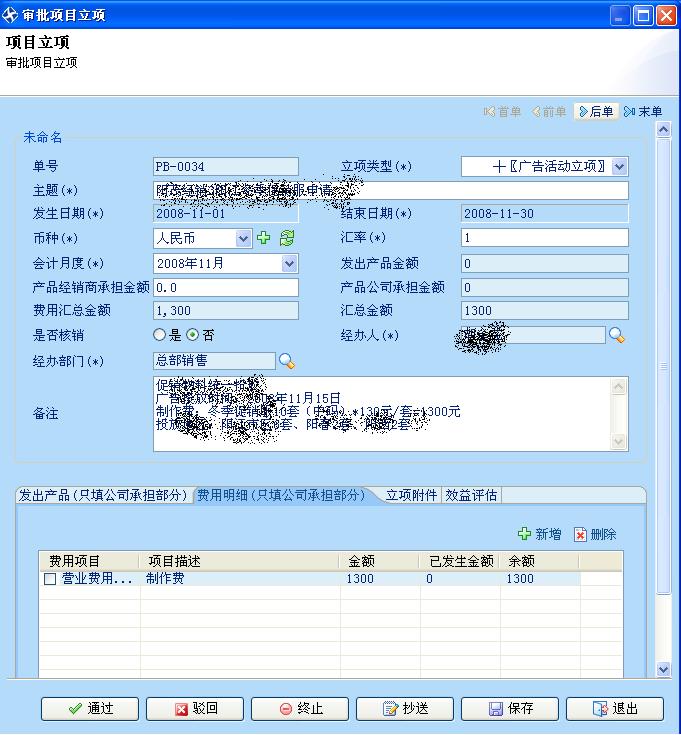
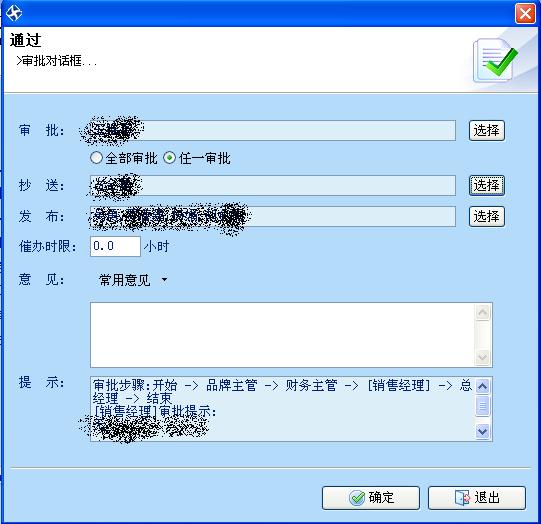
审批流转界面(以通过为例)
下面给出UML图供大家参考:
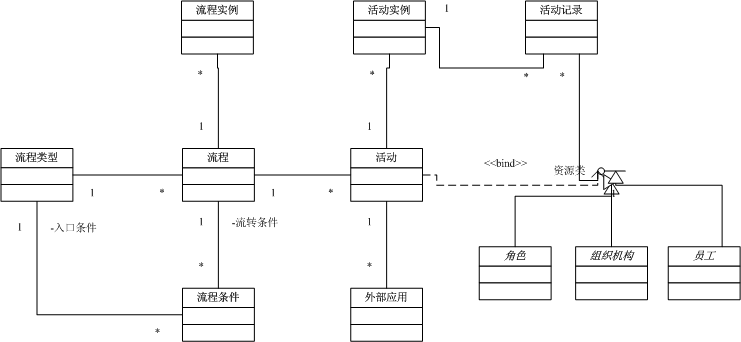
其中:
流程类型、流程、活动、流转条件、外部应用为设计时对象,用于描述流程规则
流程实例、活动实例、活动记录为运行时对象,用于记录实际发生的流程运行状况
需要解决的问题是,如何将我们的应用与此工作流引擎进行结合?我的解决方法是:
1、流程类型约定业务对象类型(即此流程可以与哪种业务对象关联)
2、业务对象中的属性或其组合可以定义为流转条件(即实现业务对象信息影响工作流流转)
3、活动执行者可以选择业务系统的组织机构、角色、人员定义(我是通过接口方式进行约定,IOC注入)
4、活动可调用已定义的应用(可多个)
5、业务对象可以通过报批动作启动工作流实例,之后由工作流按照设计信息与业务信息进行自动流转或全程提供表单与审批按钮支持。
由于此工作流系统是出于简化的目的进行设计的,设计时与运行时信息我都使用数据库信息来表示,设计器也未提供拖拉界面来进行设计,而是采用顺序定义的方式来操作。在实际运作过程中,我觉得它可以满足一般规模不大(文职人员100人左右)的企业的OA应用。
本人原创文章,欢迎转载,转载请注明出处!
工作流引擎产品无论国内或国外都有不少成熟之作,开源的工作流产品也有诸如shark之类的精品。但工作流产品做为一个独立的中间件,无论是其本身或通过它进行流程设计及与你自己的系统整合,对很多使用过工作流产品的开发人员来说都是一件不容易的事。特别是在一些其实只是一些很简单的流程控制应用需要时,我们是否需要一个独立的工作流产品来运作呢?
也许你可以尝试自己做一个工作流组件?听起来好象有点儿难,但其实并不是一件很恐怖的工作。让我们先从通常会使用到工作流引擎的情景分析下我们需要什么?
情景:某公司需要对员工请假进行管理,员工请假需进行系统填写申请,如果请假天数<=1天,可以部门主管批准。如果请假天数>1天,需由部门主管->副总经理进行再行批复。批准后的请假自动记入考勤系统。
从这个简单的业务需求,我们进行分析它的需求:
1、工作流程的选择是由业务信息(请假单)相关联的,工作流独立存在是无意义的。
2、业务信息中的内容会决定流程的选择与流向。如:请假天数,或是主管的批复意见
3、工作流程的流转与组织结构、角色、员工相关。
4、工作流程通常会调用相关业务应用(记入考勤)来完成多应用系统之间的协作。
结合以上需求,我们定义出工作流系统所需功能与数据:
1、流程定义工具(负责生成工作流引擎能明白的流程控制信息),对应于XPDL
2、工作流控制变量定义(即用于控制流程流转的控制量,如请假天数与各级审批意见,可由系统根据流程实体信息自动注入至工作流引擎)
3、工作流相关数据,即与业务过程相关的数据,如:业务表单、组织结构、角色、员工等
4、工作流引擎,负责解释流程定义,创建过程实例并控制其执行,并可能提供相关的监控界面以保障工作流的正确运转。
5、外部应用,可由工作流引擎进行调用完成多个业务系统的流程衔接。这通常是工作流引擎的最大亮点。
未完待续>>
本人原创文章,欢迎转载,转载请注明出处!
* 如何在minilang中使用Java静态方法获得数据
使用beanshell脚本:
 <set field="notApplied" value="${bsh:org.ofbiz.accounting.invoice.InvoiceWorker.getInvoiceNotApplied(invoice)}" type="Double"/> <set field="notApplied" value="${bsh:org.ofbiz.accounting.invoice.InvoiceWorker.getInvoiceNotApplied(invoice)}" type="Double"/>
警告:你必须使用type=""来转换你的结果类型,否则的话,它将返回字符串类型.
* 如何在minilang中调用Java程序
你可以在minilang中插入一段beanshell代码,类似于 applications/ecommerce/script/org/ofbiz/ecommerce/customer/CustomerEvents.xml的示例:
<call-bsh><![CDATA[
String password = (String) userLoginContext.get("currentPassword");
String confirmPassword = (String) userLoginContext.get("currentPasswordVerify");
String passwordHint = (String) userLoginContext.get("passwordHint");
org.ofbiz.securityext.login.LoginServices.checkNewPassword(newUserLogin, null, password, confirmPassword, passwordHint, error_list, true, locale);
]]></call-bsh>
在beanshell脚本中可以访问在minilang中所有的变量
* 清除 与 刷新的比较
<clear-field field-name="foo"/> 设置它为null. 这可以是一个类的属性或是集合中的一个值
<refresh-value value-name="foo"/> 从数据库中重新获得foo的值. foo必须是一个GenericValue.
* 如何设置一个布尔值
我无法找到任何例子,但是我这样做是成功的:
<set field="orderAvailableCtx.countNewReturnItems" value="true" type="Boolean"/>
我想minilang使用type=""中的类型与value中的值的做为构造调用.猜想在某天我看到这些代码时能证明我是对的...
本文档译自ofbiz 4.0 cookbooks,本人翻译,欢迎转载,请注明出处.
我的产品是被要求运行在多种常见数据库平台下(mysql/sqlserver/oracle)下,在开发中需要严格遵循相关的规范以确保能够实现跨数据库类型的要求.(相关的要点在我的"你的系统真的因为使用hibernate就可以适应各种数据库吗? "一文中已提及).在初始开发时有一个问题是比较困扰我的团队的,我们开发的时候必定是基于某个特定的数据库开发的(比如mysql),但在测试阶段是需要在不同的数据库平台下进行兼容性测试,由于开发过程中数据库结构与种子数据变化非常快,全部编写sql方式非常浪费时间,如何能找到一种高效的数据库相互迁移的工具,是我们当时所急需的解决方案.
其实也没啥选择,比较常用的数据库迁移工具就是Sqlserver自带的DTS,这玩意在sql server数据库间进行数据导入/导出时倒确实比较好用,在不同数据库类型进行操作时,就会出多多问题,如:类型转换需手工指定/导出字段有双引号...
所以最后的选择就是自己做一个DTS好啦,思路如下:
1、选择源数据库连接与目标数据库连接
2、根据源数据库遍历所有数据库对象(表),做为基准
3、删除目标数据库所有表外键及索引、删除所有种字数据(根据约定)数据、字段均允许null
4、遍历源数据库中所有表,为目标数据库修改结构(如增删字段,字段改类型、大小)
5、将源数据库中种子数据表数据拷贝至目标数据库中
6、根据源数据库为目标数据库中的表创建外键及索引、设置是否允许为null
7、搞掂!
完工后总代码量不过两千行(因为需考虑不同数据库的SQL Dialet,否则应该更少)
用户界面基于Eclipse RCP技术开发,使用JFace Wizard向导(如果不是想用向导的话,你可以用SWT来做)对话框获得源数据库与目标数据库的连接内容,并在用户点击完成按钮后,在进度条中提示用户执行情况.用了这个玩意以后,测试同事的数据库兼容性测试就再也不用来烦我们开发组啦!真是爽呀!当然很多喜欢折腾的客户(比如突然在哪里听说oracle是大型数据库,非让你帮他弄过去)此类朝三暮四也就自然不在话下啦!
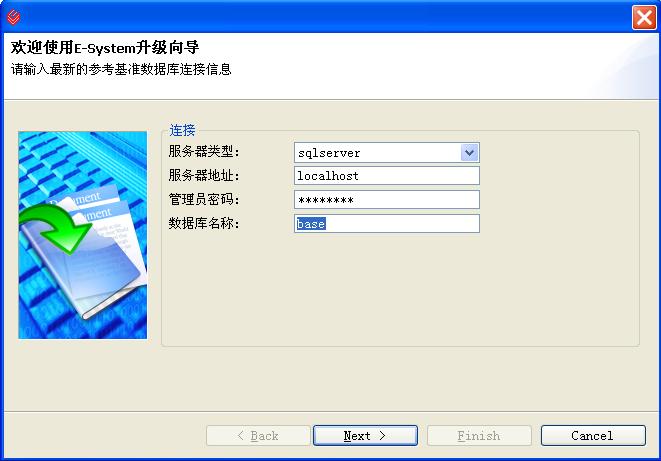
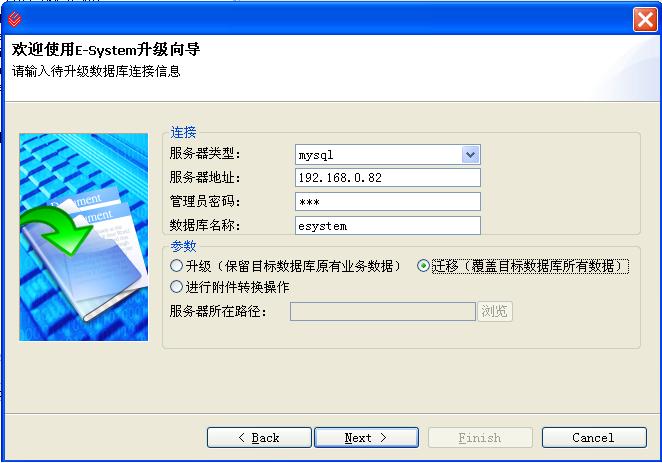
本人原创文章,欢迎转载,转载请注明出处!
* 如何为SELECT SUM(QUANTITY - CANCEL_QUANTITY) AS QUANTITY之类的语句设置别名
<alias entity-alias="OI" name="quantity" function="sum">
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0"/>
</complex-alias>
</alias>
SELECT SUM(COALESCE(OI.QUANTITY,'0') - COALESCE(0I.CANCEL_QUANTITY)) AS QUANTITY在结果集包含默认值是一个好的习惯,否则如果有一项为null,那么最终相减的结果就也为null了.
操作符可以为任何你当前使用数据库所支持的SQL操作符,比如算术运算符+, -, * 和/ 或者字符串连接符 ||.
你可以增加function=""标签来完成在complex-alias-field中的min, max, sum, avg, count, count-distinct, upper 及lower集合运算. 示例, 以上的定义可以用另一种方法表示为:
<alias entity-alias="OI" name="quantity">
<complex-alias operator="-">
<complex-alias-field entity-alias="OI" field="quantity" default-value="0" function="sum"/>
<complex-alias-field entity-alias="OI" field="cancelQuantity" default-value="0" function="sum"/>
</complex-alias>
</alias>
即为SELECT (SUM(COALESCE(OI.QUANTITY,'0')) - SUM(COALESCE(OI.CANCEL_QUANTITY,'0'))) AS QUANTITY查询结果集
* 我讨厌OFBiz的实体引擎,我要自己的JDBC连接!
好的,以下是你获得JDBC连接的方法:
import org.ofbiz.entity.jdbc.ConnectionFactory;
String helperName = delegator.getGroupHelperName("org.ofbiz"); // gets the helper (localderby, localmysql, localpostgres, etc.) for your entity group org.ofbiz
Connection conn = ConnectionFactory.getConnection(helperName);
Statement statement = conn.createStatement();
statement.execute("SELECT * FROM PARTY");
ResultSet results = statement.getResultSet();
//  通过普通JDBC 的结果集来操作 通过普通JDBC 的结果集来操作
//Alternatively, you can use the SQLProcessor like this:
SQLProcessor sqlproc = new SQLProcessor(helperName);
sqlproc.prepareStatement("SELECT * FROM PARTY");
ResultSet rs1 = sqlproc.executeQuery();
ResultSet rs2 = sqlproc.executeQuery("SELECT * FROM PRODUCT");
你可以查看framework/webtools/webapp/webtools/WEB-INF/actions/entity/EntitySQLProcessor.bsh了解它的使用
在以下网址你可以获得相关JavaDoc的内容:
http://www.opentaps.org/javadocs/version-1.0/framework/api/org/ofbiz/entity/jdbc/SQLProcessor.html
http://www.opentaps.org/javadocs/version-1.0/framework/api/org/ofbiz/entity/jdbc/ConnectionFactory.html
*** 请先考虑以下内容: 你放弃数据库的无关性意味着你在某些方法将无法与框架或其它程序集成.你确定你要这么做吗?
获得更好的做法,请访问 http://www.opentaps.org/docs/index.php/Using_the_Query_Tool
* 关于时间比较方法的一些警告
在你用 GREATER_THAN比较一个 Timestamp类型数据时, 你有可能获得相同的时间数据:
delegator.findByAnd("XXX", UtilMisc.toList(new EntityExpr("fromDate", EntityOperator.GREATER_THAN, "2007-12-31 23:59:59.998")));
有可能包含fromDate=2007-12-31 23:59:59.998的数据. (此种情况发生于PostgreSQL 8.1并且GenericDAO 类生成的SQL代码是'FROM_DATE > ' so 所以我也不明白发生这个问题的原因.) 所以确保安全的方法是, 增加1秒到需要比较的时间中然后使用 GREATER_THAN_EQUAL_TO方法
delegator.findByAnd("XXX", UtilMisc.toList(new EntityExpr("fromDate", EntityOperator.GREATER_THAN_EQUAL_TO, "2008-01-01 00:00:00.998")));
* 警告: 在空集合中使用EntityOperator.IN
请小心如果使用EntityOperator.IN去判断一个非空集合在一个空集合中的包含项,你有可能获得一个语法错误: 在Derby或者其它一些不为人知的数据库中可能会出错.
所以建议你能在使用EntityOperator.IN之间,通常执行UtilValidate.isNotEmpty方法来判断一下结果集是否为空
* 警告: delegator.getNextSubSeqId 不能确保唯一性
很多实体有很多合成的主键.示例OrderItem's 主键是orderId + orderItemSeqId. InventoryItemDetail's 主键是inventoryItemId +inventoryItemSeqId. 通常, delegator.getNextSubSeqId 通常是获得一个序列值,但是在多线程的访问下有可能无法确保生成的值的唯一性. 此段内容在 http://issues.apache.org/jira/browse/OFBIZ-1636 中有相关文档记录.
当前, 如果有可能多个线程尝试同时写入实体组合键时,可以使用delegator.getNextSeqId来替代getNextSubSeqId. (此问题不会发生于OrderItem, 因为它只使用单线程写入, 但有可能发生于 InventoryItemDetail, 它使用多线程来创建库存记录项.)
完>>
本文档译自ofbiz 4.0 cookbooks,本人翻译,欢迎转载,请注明出处.
* 我可以在entitymodel.xml文件中定义自己的view-entities吗?
不能, 你可以动态定义它们.你可以查看org.ofbiz.party.party.PartyServices中的findParty方法学习它的使用
* 如果为有效期间创建条件?
我们提供了一组非常有用的方法EntityUtil.getFilterByDateExpr ,它能返回一个EntityConditionList根据有效期间来筛选一个结果集.
* 如何在大数据结果集下工作
如果你检出一个大的数据结果集,你应当使用EntityListIterator通过迭代方式读取数据,而非List.
示例,如果你使用:
List products = delegator.findAll("Product");
你可能获得一个"java.lang.OutOfMemoryError". 这是由于你通过findAll, findByAnd, findByCondition等方法来获得一个大的内存数据结果集导致内存溢出. 在这种情况下, 应该使用EntityListIterator迭代方式来读取你的数据. 这个示例应改写成:
productsELI = delegator.findListIteratorByCondition("Product", new EntityExpr("productId", EntityOperator.NOT_EQUAL, null), UtilMisc.toList("productId"), null);
注意获得EntityListIterator的方法只用通过条件, 所以你需要将你的条件重写为EntityExpr (在此次情况下,productId是主键字段不可能为空的, 所以将返回所有Proudct实例,)或 EntityConditionList.
此方法参数中包含检出的字段(这里为productId)以及排序字段(这里不需要,所以赋了null)
你可以传递一个null作为EntityCondition参数来获得所有结果.然后这不一定在所有数据库下都能正常工作! 在maxdb及其它不常用的数据库下时你要小心使用这些高级功能.
* 如何使用EntityListIterator
当我们通过EntityListIterator迭代访问数据时, 通常是这样:
  while ((nextProduct = productsELI.next()) != null) { while ((nextProduct = productsELI.next()) != null) {
 . .
// operations on nextProduct
 } }
在EntityListIterator 中使用 .hasNext()方法是一种不经济的做法.
在你完成你的操作后,要记得关闭此迭代
productsELI.close();
* 如何查询无重结果集
当前只能通过list iterator方法并指定EntityFindOptions参数,示例如下:
listIt = delegator.findListIteratorByCondition(entityName, findConditions,
null, // EntityConditions参数
fieldsToSelectList,
fieldsToOrderByList,
//关键部分. 第一个true表示"specifyTypeAndConcur"
// 第二个true指完是一个滤重查询. 显然在实体引擎中只能通过这个方法来进行滤重查询
new EntityFindOptions(true, EntityFindOptions.TYPE_SCROLL_INSENSITIVE, EntityFindOptions.CONCUR_READ_ONLY, true));
在minilang, 它会更简单:
<entity-condition entity-name="${entityName}" list-name="${resultList}" distinct="true">
<select field="${fieldName}"/>
.
* 如何进行一个大小写不敏感的查询(即不分大小写)
你需要查询条件表达式两边均转为大写,示例:
andExprs.add(new EntityExpr("lastName", true, EntityOperator.LIKE, "%"+lastName+"%", true));
(来源org.ofbiz.party.party.PartyServices)
* 如何将EntityListIterator转换成List
使用EntityListIterator.getCompleteList() 及getPartialList 方法
* 如何自动获得下一个ID值
在minilang 中使用 <sequence-id-to-env ...> 或在Java中通过delegator.getNextSeqId(...) 获得 . id序列存放于SequenceValueItem中.
* 关于ID值的一些警告
不要在种子/演示数据中使用10000做为数据的ID,当系统尝试自动创建数据时,它们都将尝试10000,这将导致一个键值冲突错误.
* 如何从一个明细项中获得序列ID
有些实体,比如拥有itemSeqId 的InvoiceItem(发票明细项) and OrderItem(订单明细项).此项通常在你处一次为item生成GenericValue 时自动生成ID,之后向delegator要求生成项目的seq Id:
GenericValue orderItem = delegator.makeValue("OrderItem", orderItemValues);
delegator.setNextSubSeqId(orderItem, "orderItemSeqId", ORDER_ITEM_PADDING, 1);
未完待续>>
本文档译自ofbiz 4.0 cookbooks,本人翻译,欢迎转载,请注明出处.
* 保持实体名称少于25个字符
这个限制主要是为了Oracle只支持30字符以内的数据库对象名称,再加上OFBiz会自动在单词之间加上"_",所以就得出了这么个限制.
* 关联的工作方式
它们定义于entitymodel.xml文件中的<entity>段,示例如下:
<relation type="one" fk-name="PROD_CTGRY_PARENT" title="PrimaryParent" rel-entity-name="ProductCategory">
<key-map field-name="primaryParentCategoryId" rel-field-name="productCategoryId"/>
</relation>
<relation type="many" title="PrimaryChild" rel-entity-name="ProductCategory">
<key-map field-name="productCategoryId" rel-field-name="primaryParentCategoryId"/>
</relation>
type这个属性标签定义关联类型: "one"表示一对一,"many"表示从此实体引出的一对多关系
fk-name的属性值是数据库外键名.为自己的外键命名是一个好的习惯,虽然如果你不设置此属性,OFiz也会自己建外建.
rel-entity-name的属性值指向关联的实体名称
title用来区分两个实体之间的多重关系
<key-map>节点定义关联中使用到的字段.field-name指向本实体内的引用字段,rel-field-name定义关联的实体字段,你可以通过多个字段组合关联
当你访问一个关联,你可以使用title+entityName作为参数调用.getRelated("")或.getRelatedOne("")方法.在关联为"many"时使用.getRelated("")是恰当的,因为它返回一个List,同样在关联为"one"时通过.getRelatedOne("")方法获得一个值.
* view-entities相关内容
view-entities的功能非常强大,它允许你可以创建一个join-like查询,即使你的数据库不支持join.
关于你数据库的join语法存放在entityengine.xml的datasource节点下的join-style属性中.
当你通过<view-link...>节点将两上实体连接起来时,记住:
1. 实体名称顺序是重要的
2. 默认的连接方式是inner join(即同样的值存在于两个实体类中),外连接需要使用rel-optional="true"
如果多个实体中拥有相同的字段名称,比如statusId,结果集中的statusId使用第一个实体中的该列,其它实体中的同名列将被丢弃.如果你想要同时获得这些列,你需要通过在其之前加入<alias-all>节点,一个方式是使用<alias ..>节点来为不同实体的同名字段起别名,示例:
<alias entity="EntityOne" name="entityOneStatusId" field="statusId"/>
<alias entity="EntityTwo" name="entityTwoStatusId" field="statusId"/>
另一种方法是在<alias-all>节点中使用<exclude field="">,如下:
<alias-all entity-alias="EN">
<exclude field="fieldNameToExclude1"/>
<exclude field="fieldNameToExclude2"/>
</alias-all>
这样也可以排除掉很多不打算使用到的信息,特别是在一个非常大的表中查询时.
如果你打算执行类似于以下的查询语句时:
SELECT count(visitId) FROM GROUP BY trackingCodeId WHERE fromDate > '2005-01-01'
需要包含字段visitId以及function="count" 标签,trackingCodeId需加上group-by="true"标签,fromDate需要加上group-by="false"标签
在你进行查询时,有一件非常重要的事情需要注意,比如说delegator.findByCondition方法,你必须指定检出的字段列表,并且你不能指定fromDate字段,否则你将得到一个错误.这就是为webtools不能够使用view-entities来查看的原因.
你可以查看applications/marketing/entitydef/entitymodel.xml的底部内容学习,及通过applications/marketing/webapp/marketing/WEB-INF/actions/reports学习beanshell脚本的调用.
未完待续>>
本文档译自ofbiz 4.0 cookbooks,本人翻译,欢迎转载,请注明出处.
项目总结不知道大家是否都会真正去做,隔段时间会不会再去阅读与体会当时的心情呢?找出一篇旧时的项目总结,细细读来,看得仿佛还能感觉到当时的心酸。这个项目是我刚进入一家公司不久的情况下,我的职位是PM,当时公司有一个迟迟不能终验的项目,拖了三年,据说在我之前项目经理已经换了四任,所有项目成员也都不在公司里了。所以公司里资深些的PM都不愿意接这个项目,我想大家做过项目都明白,项目奖早就分完了,而且公司只剩尾款未收,根本就不愿意真正投入人力去完成这个项目,只是对客户有个交待罢了。于是,这么个烂摊子就落在我这个当时的新人身上了。
从总结中摘抄一些部分放在这里,希望可以安慰时有低落心情的我及有相似遭遇的朋友们:
一堆无人愿去看的源代码、无一原项目组成员的参与、充斥报怨的客户、乱七八糟的文档、无序的需求...这一切使得每个人不禁望而生畏。说实话,当时我心里也是非常不愿意接手这个项目的,心想:这个项目我对其一无所知、因为当时项目开发已进行了多年,需求与最初已发生极大变化、重新搜集需求又得不到客户的理解与支持、项目组普遍弥漫着一种失败论的气氛。
没有人愿意接,公司领导指派我去完成这件事。那我就抱着尽力试一试的想法参与进来。从此进入了漫长的需求摸索(资料不全、负责此项目客户的变化)、完整的功能的再次开发(我项目组无人精通Delphi,也无人愿意去看无文档无人员支持的原有的代码),还要在此过程去平息客户的怒火及吸收理解客户业务的内涵。在这漫长的过程,没有太多的肯定或成为焦点的可能。很有些苦闷的时候,我也想要去放弃——承认自己的无能、不愿再面对这种混乱的局面... 在这个过程中,幸有项目组人员、公司领导的理解与支持及自己不愿认输的因素才能坚持到今天。
从这个过程我也学到了对客户业务的理解。我想今日的我再不会象初接手这个项目面对客户时,那样不敢说出自己的建议和业务理解了。
时至今日,总结过去所发生的,有一些经验和想法愿意与大家分享:
(1)在你最苦恼的时候,请勿轻言放弃,你的成功不是为了得到鲜花与掌声。做完你要做的事,是你自己的成功;离成功最近的地方也是最易放弃的地方。
(2)选择一至两个可以倾诉的对象,他们的支持(可能只是倾听你的牢骚)会是你最大的动力。
(3)团队的力量:选择一个假想敌或是共同的目标(不能让这些打算看你们笑话的人的阴谋得逞),会成为你这个团队战斗力的最大源泉
(4)表面看起来蛮不讲理的客户是你最好的老师:只因为他得不到他想要的东西,才会看起来这样蛮不讲理。
过去的经验,也许快乐,也许心酸。但回首时,只要你有真正的努力,你一定有属于自己的收获!
在整理自己的文档库时发现了这篇五年前在另家公司工作时向公司老大提议"软件技术支持组"的一个建议书,后来因为由于缺乏相关的推动力(当时自己还只是一个PM并缺乏相应的授权与支持),最终并没有达到设想的效果,现在发出来聊以纪念一下年青时的想法吧:
1 前言
在近期推动组件库项目实施的过程中,经常感觉到没有执行能力能够推动公司技术革新之困境。现征询xxxx咨询公司及其它朋友意见之后。现向您建议成立公司软件技术支持组(PIT)并授予相应职责的权力以负责公司的技术(工具、方法和过程)的挑选和识别,并将经过挑选和验证的技术有序地引入公司的软件开发过程。
2 实施后的蓝图
1、公司由于技术的先进性获得市场竞争地位的极大提高。
2、售前人员可使用PIT根据公司用户市场情况、技术积累、成本因素、资源情况所制定出的商业解决方案向客户销售,对销售可起到良好的技术支持作用。
3、将过程财富(组件、工具、方法、经验)及规范标准在公司各软件项目中实施,可极大降低研发部门(成本中心)所耗费的巨额开发成本,获得最大的投入产出比。
4、可对风险进行预先评价,做好风险预防。
5、项目经理或销售人员可在需求调研阶段即可获得公司已有财富的情况和资源分配情况,对用户的引导可有的放矢,从而带来诸多额外的收获。
6、可有效的鼓舞公司研发人员的士气,加强公司战斗力和凝聚力。
3 PIT的职责
1、 PIT对SEPG和高层管理者负责,有专门的定期汇报渠道。经批准后的行动计划和规范制度对公司研发部员工具有强制性。
2、 向公司高层汇报公司技术积累情况,长期技术策略以及提高公司市场竞争地位的发展路线。并负责安排和提供相应的实施计划(包括技术更新可能涉及的范围、更新的时机、可选的方案、评估情况、初期培训及指导、成本耗费情况)。经同行评审和高层批准后负责安排实施。
3、 负责收集市场、客户、项目的数据并根据公司技术积累、成本因素、资源情况、用户市场情况制定出销售所适用的解决方案。
4、 负责的技术范围包括:软件重用、CASE技术、架构设计、组件库规划及安排实施、语言规范及对应的形式方法。支持的范围包括语言、数据库、工具。并负责向外界寻求组织内部无法解决的技术问题。
5、 与各软件项目组一同确定软件开发计划,向项目组提供可用技术、已有技术积累应用及相应标准开发方法、开发工具、语言、过程的选择。并将在项目中应用的情况记录入过程财富库。
6、 负责提供公司的技术(工具、方法、语言、架构等)参考数据,包括:风险评价、公司资源情况、生产率、成本、进度、缺陷率、已知问题列表及公司已有技术积累情况。
7、 负责提供工具、方法、过程、新技术的培训及指导。
8、 负责收集本组工作结果,并成文归档。估计其在组织中的效益与影响、风险。决定是否在公司大规模推广、否决或重新试验。
这只是一个建议书,只是想从实施后的效果与日常的工作职责让老大明白这件事的意义,具体的计划与KPA文档就不一并附上了 。
|