Posted on 2012-10-10 11:32
云云 阅读(48924)
评论(5) 编辑 收藏

一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
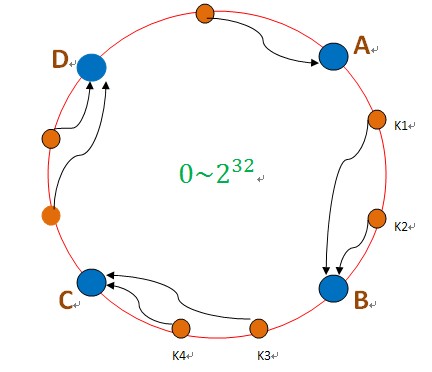
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
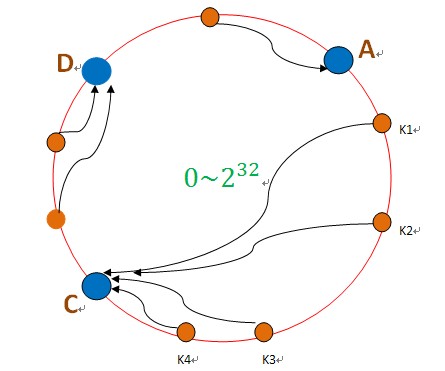
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
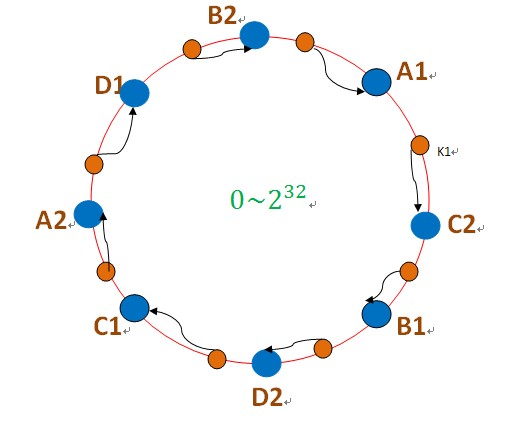
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
Java实现:
- public class Shard<S> {
-
- private TreeMap<Long, S> nodes;
- private List<S> shards;
- private final int NODE_NUM = 100;
-
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
-
- private void init() {
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) {
- final S shardInfo = shards.get(i);
-
- for (int n = 0; n < NODE_NUM; n++)
-
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
-
- }
- }
-
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key));
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey());
- }
-
-
-
-
-
-
-
- private Long hash(String key) {
-
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
-
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
-
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
-
- long h = seed ^ (buf.remaining() * m);
-
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
-
- k *= m;
- k ^= k >>> r;
- k *= m;
-
- h ^= k;
- h *= m;
- }
-
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
-
-
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
-
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
-
- buf.order(byteOrder);
- return h;
- }
-
- }