对于做软件的人来说,唯一不变的就是变化。此为行业真理。而对于复杂业务系统的逻辑组件的定义不得不多考虑一下业务的可扩展性,来应对客户的变化。选择Rule Engine是一个不错的方案。
Drools 是用 Java 语言编写的开放源码规则引擎。Drools 允许使用声明方式表达业务逻辑。可以使用非 XML 的本地语言编写规则(这点很重要,本人之前曾用过自己公司的一套业务规则组件,无论是编写还是调试都很麻烦),从而便于学习和理解。并且,还可以将 Java 代码直接嵌入到规则文件中,使Drools 更加吸引人。简单的概括,就是简单使用,易于理解。而且它是免费的。
1.rule文件:
rule "rule name"
no-loop
when
customer : Customer( state == CustomerState.UNCENSORED )
then
customer.setState(CustomerState.AUDITING);
CustomerTask task=new CustomerTask();
Post law=userService.getPostByPostCode(Constants.PostCode.ROOT_LAW);
task.setAuditorPost(law);
task.setEntityState(CustomerState.AUDITING);
task.setEntityId(customer.getId());
task.setEntityCode(String.valueOf(customer.getId()));
task.setEntityType(Customer.class.getSimpleName());
task.setTitle(customer.getName()+" test");
taskService.assignmentTask(task);
logger.info("CustomerTask Submit auditorTitle:" + task.getAuditorTitle());
end
这里面有个状态的条件判断state == CustomerState.UNCENSORED ,then 关键字后面的便是符合条件的处理逻辑,只要是java程度都可以看懂,比xml类的rule文件好懂了许多。
接下来
语法说明:
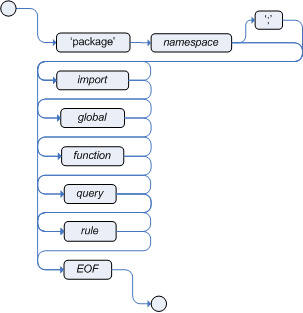
文件头部分:
package drools.java.demo;定义包名,等同于命名空间
import drools.java.demo.Machine;导入java类
global java.util.List myGlobalList
;此关键字让规则引擎知道,myGlobalList对象应该可以从规则中访问
.
function:类似于公用方法的抽象,如下定义后,各个同一文件下的rule都可以使用
function void setTestsDueTime(Machine machine, int numberOfDays) {
setDueTime(machine, Calendar.DATE, numberOfDays);
}
rule:定义了一个规则
rule "<name>"
<attribute>*
when
<conditional element>*
then
<action>*
end
<name> 即rule的名字标识
<attribute>:
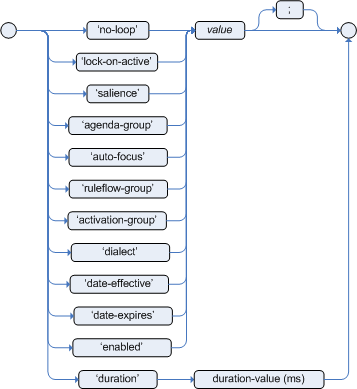
常用的属性:
no-loop :true 条件结果更改后,修改此条件且定义为no-loop:true的规则不会再重新执行。
lock-on-active:true 可以看作是no-loop的加强版,当条件结果更改后,不但修改此条件的规则不会重新执行,文件中的任何规则(其 active-lock 属性被设为 true)不会重新执行。
salience:100 使用它可以让规则执行引擎知道应该启动规则的结果语句的顺序。具有最高显著值的规则的结果语句首先执行;具有第二高显著值的规则的结果语句第二执行,依此类推。当您需要让规则按预定义顺序启动时,这一点非常重要。
其他属性的解释请见http://downloads.jboss.com/drools/docs/5.1.1.34858.FINAL/drools-expert/html_single/index.html#d0e2607
when:填写条件的地方,比如:
Cheese( type == "stilton", price < 10, age == "mature" )或
Cheese( type == "stilton" && price < 10, age == "mature" )
then:业务规则的地方,略。
2.用法
规则文件定义好后,就该是怎么使用它了

如上图,file rule定义好后,就该是如何使用它了。最重要的两个类RuleBase和WorkingMemory
下面是一个example:
public class RulesEngine {
private RuleBase rules;
private boolean debug = false;
public RulesEngine(String rulesFile) throws RulesEngineException {
super();
try {
// Read in the rules source file
Reader source = new InputStreamReader(RulesEngine.class
.getResourceAsStream("../../rules/" + rulesFile));
// Use package builder to build up a rule package
PackageBuilder builder = new PackageBuilder();
// This will parse and compile in one step
builder.addPackageFromDrl(source);
// Get the compiled package
Package pkg = builder.getPackage();
// Add the package to a rulebase (deploy the rule package).
rules = RuleBaseFactory.newRuleBase();
rules.addPackage(pkg);
} catch (Exception e) {
throw new RulesEngineException(
"Could not load/compile rules file: " + rulesFile, e);
}
}
public RulesEngine(String rulesFile, boolean debug)
throws RulesEngineException {
this(rulesFile);
this.debug = debug;
}
public void executeRules(WorkingEnvironmentCallback callback) {
WorkingMemory workingMemory = rules.newStatefulSession();
if (debug) {
workingMemory
.addEventListener(new DebugWorkingMemoryEventListener());
}
callback.initEnvironment(workingMemory);
workingMemory.fireAllRules();
}
}
RulesEngine构造方法演示了如何去读入一个rule文件,并构建了一个RuleBase对象(RuleBase 是一个包含了rule文件的所有规则的集合)
executeRules方法定义了如何使用规则文件中定义的那些内容,用RuleBase构建一个WorkingMemory对象,再执行fireAllRules()方法。
WorkingMemory 代表了与rulebase链接的session会话,也可以看作是工作内存空间。如果你要向内存中插入一个对象可以调用insert()方法,同理,更新一个对象使用update()方法。WorkingMemory还有一个setGlobal()方法,用来设置规则内可以引用的对象(相当于规则的全局变量)。
3.小技巧
可以一次把所有的rule文件都载入内存中存放,这样就不用每次执行都读取文件。
如果规则文件被修改,也可以用过一个方法来判断是否需要重新载入rule文件
比如:根据文件的最后修改时间,与内存中对应对象的时间做比较
public boolean hasChange(List<RuleFile> ruleFileList){
for(RuleFile ruleFile:ruleFileList){
if(!ruleFile.getLastModifyTime().equals(ruleFileMap.get(ruleFile.getFileName()).getLastModifyTime())){
return true;
}
}
return false;
}
注:具体的helloWorld 请见http://www.ibm.com/developerworks/cn/java/j-drools/#listing12,比我说得好多了。