摘要: 转载请注明出处 http://www.blogjava.net/fireflyk/ 接上文,[OSGi] OSGi + Spring + Web Demo [1] 1. 同样方法创建helloworldweb Bundle,用Maven方式创建并转为PDE Tools。 2. &nb...
转载请注明出处 http://www.blogjava.net/fireflyk/archive/2011/09/25/359447.html
1. 分类
1.1 定义:通过学习得到一个目标函数f,把每个属性集x映射到一个预先定义的类标号y。
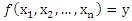
狭隘地说,有大量数据,预先知道所有的类型,但无法分类,通过将数据的多个属性维度来推测每条数据项属于哪个类型。(男,高,瘦,帅) -> 极品帅哥,(男,矮,胖,丑) -> 猥琐男。
严格来说,“分类”可以用于描述性建模和预测性建模。
1.2 应用场景
适合预测或描述二元或标称的,对于序数分类,分类技术不太有效,其他形式的联系会被忽略。(复习:标称的,=和≠,教师和工人;序数的,<和>,收入高和收入低)
例如,前几天看的一个科学研究,个人认为不适合用分类来做。科学家找来志愿者,按臀围大小分为两组做智商测试,发现臀围大的明显比臀围小的智商测试结果高。于是得出结论,臀围大的智商高。我认为,这就是最明显的一个错误,智商高低是序数分类,不能用分类方法来做。它隐藏了一些内在联系,例如智商高的相对来说爱学习、坐办公室、少运动导致肥胖、臀围大。而不是你把臀围搞大就一定能智商高!
1.3 实现方法
训练数据 -> 学习模型 -> 模型 -> 应用模型 -> 校验数据
简单说就是先训练,得出结论再校验。分类方法包括决策树分类法、基于规则的分类法、神经网络、支持向量机和朴素贝叶斯分类法。
模型准确率 = 正确预测数 / 总数
2. 决策树分类
2.1 定义
图2-1
如上图,通过提出一系列精心构思的问题,可以解决分类问题,每当一个问题得到答案,后续问题将随之解决。
根节点、内部节点都是非终结点,是属性测试条件。叶节点也是终结点,是分类结果。
2.2 建立决策树
Hunt算法,是许多决策树算法的基础,包括ID3,C4.5,CART。
训练数据集,(Tid, 有房者, 婚姻状况, 年收入, 拖欠贷款),具体数据见《数据挖掘导论》P94。
大量数据是不拖欠贷款的,所以选取类标号,“拖欠贷款=否”。然后选择测试条件“有房者”。接下来,再看生成数种,哪个叶子节点是无法确定到类标号的,无法确定的递归调用如上步骤,选取测试条件“婚姻状况”,然后是“年收入”。一棵决策树建立好了,为何按照这样的顺序?后边解释。
测试条件,可以是二元的(男,女),标称的(单身、已婚、离异),序数的(S号,M号,L号,XL号,分类结果不能是序数的,但是测试条件可以是序数的),连续的(工资是连续属性)。
2.3 选择最佳的划分度量
p(i|t)表示给定节点t中属于类i的记录所占的比例,有时候省略t,直接用pi表示。这里介绍不纯性(我称它为区分度,数字越小,区分度越大)度量的一种方法,c是类的个数,
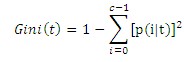
2.3.1 二元属性划分
划分A,结点N1,类C0,4个,类C1,3个;结点N2,类C0,2个,类C1,3个。
Gini(1) = 1-(4/7)2-(3/7)2 = 24/49
Gini(2) = 1-(2/5)2-(3/5)2 = 12/25
加权Gini = Gini(1) * 7/12 + Gini(2) * 5/12 = 0.486
划分B,同理得到Gini=0.371,由此说明划分B更好。
2.3.2 标称属性划分
与二元属性(一个属性,属性值多元)划分衡量方法相同,有三元或多元(一个属性,属性值多元)的情况,根据计算Gini来决定如何划分(可以划分为多路划分,不局限于两路划分)。
2.3.3 连续属性划分
把训练集中每一项都作为一个“<=测试条件”,列出每一个结点下的C0数量和C1数量,计算每一个点的Gini。而事实上,不用每一个点都计算。如《数据挖掘导论》P100中,60,70,75连续且类标号相同,120,125,220连续且类标号相同,所以划分点选取不能切断他们,所以这几个点不用计算Gini值。
2.4 决策树归纳特点
会有重复的数据碎片,即存在相同两棵子树,如图2-1。
目前为止,每个测试条件只包含一个属性,对于x1+x2<1,也是可以允许的,称为斜决策树。