2014年2月14日
#
转载:
Spark环境搭建-WIndows版本 这段时间在看Scala语言方面的资料,接触到了Spark,于是昨天下午在公司,把Spark的环境搭建起来了。安装的时候陪到了一个问题,在网上没有找到解决方案,于是自己查了一下原因。现在做一下笔记。
1. spark的下载文件可以在官方找到,地址:http://spark.incubator.apache.org/downloads.html ,这次装的是截至目前为止,最新的版本:0.9
2. 下载完以后,直接解压到指定的路径,例如,d:/programs
3. 安装scala,并制定Scala_Home路径,scala安装请查看官网
4. 按照Spark官方的安装指南,在解压的目录下,运行
sbt/sbt package
命令就可以。
但是这是针对linux和OS X系统的,在windows下运行这条命令,会报错:
not a valid command
这个问题是因为,spark知道的sbt脚本无法在windows下运行,只要在网上下载一个windows版本的sbt,然后将里面的文件拷贝到Spark目录下的sbt (http://www.scala-sbt.org/),然后在运行命令,安装就会成功。
试试spark-shell
1 scala> val textFile = sc.textFile("README.md")
2 14/02/14 16:38:12 INFO MemoryStore: ensureFreeSpace(35480) called with curMem=177376, maxMem=308713881
3 14/02/14 16:38:12 INFO MemoryStore: Block broadcast_5 stored as values to memory (estimated size 34.6 KB, free 294.2 MB)
4
5 textFile: org.apache.spark.rdd.RDD[String] = MappedRDD[16] at textFile at <console>:12
6
7 scala> textFile.count
8 14/02/14 16:38:14 INFO FileInputFormat: Total input paths to process : 1
9 14/02/14 16:38:14 INFO SparkContext: Starting job: count at <console>:15
10 14/02/14 16:38:14 INFO DAGScheduler: Got job 7 (count at <console>:15) with 1 output partitions (allowLocal=false)
11 14/02/14 16:38:14 INFO DAGScheduler: Final stage: Stage 7 (count at <console>:15)
12 14/02/14 16:38:14 INFO DAGScheduler: Parents of final stage: List()
13 14/02/14 16:38:14 INFO DAGScheduler: Missing parents: List()
14 14/02/14 16:38:14 INFO DAGScheduler: Submitting Stage 7 (MappedRDD[16] at textFile at <console>:12), which has no missin
15 g parents
16 14/02/14 16:38:14 INFO DAGScheduler: Submitting 1 missing tasks from Stage 7 (MappedRDD[16] at textFile at <console>:12)
17
18 14/02/14 16:38:14 INFO TaskSchedulerImpl: Adding task set 7.0 with 1 tasks
19 14/02/14 16:38:14 INFO TaskSetManager: Starting task 7.0:0 as TID 5 on executor localhost: localhost (PROCESS_LOCAL)
20 14/02/14 16:38:14 INFO TaskSetManager: Serialized task 7.0:0 as 1560 bytes in 1 ms
21 14/02/14 16:38:14 INFO Executor: Running task ID 5
22 14/02/14 16:38:14 INFO BlockManager: Found block broadcast_5 locally
23 14/02/14 16:38:14 INFO HadoopRDD: Input split: file:/D:/program/spark-0.9.0-incubating/README.md:0+4491
24 14/02/14 16:38:14 INFO Executor: Serialized size of result for 5 is 563
25 14/02/14 16:38:14 INFO Executor: Sending result for 5 directly to driver
26 14/02/14 16:38:14 INFO Executor: Finished task ID 5
27 14/02/14 16:38:14 INFO TaskSetManager: Finished TID 5 in 6 ms on localhost (progress: 0/1)
28 14/02/14 16:38:14 INFO DAGScheduler: Completed ResultTask(7, 0)
29 14/02/14 16:38:14 INFO TaskSchedulerImpl: Remove TaskSet 7.0 from pool
30 14/02/14 16:38:14 INFO DAGScheduler: Stage 7 (count at <console>:15) finished in 0.009 s
31 14/02/14 16:38:14 INFO SparkContext: Job finished: count at <console>:15, took 0.012329265 s
32 res10: Long = 119
33
34 scala> textFile.first
35 14/02/14 16:38:24 INFO SparkContext: Starting job: first at <console>:15
36 14/02/14 16:38:24 INFO DAGScheduler: Got job 8 (first at <console>:15) with 1 output partitions (allowLocal=true)
37 14/02/14 16:38:24 INFO DAGScheduler: Final stage: Stage 8 (first at <console>:15)
38 14/02/14 16:38:24 INFO DAGScheduler: Parents of final stage: List()
39 14/02/14 16:38:24 INFO DAGScheduler: Missing parents: List()
40 14/02/14 16:38:24 INFO DAGScheduler: Computing the requested partition locally
41 14/02/14 16:38:24 INFO HadoopRDD: Input split: file:/D:/program/spark-0.9.0-incubating/README.md:0+4491
42 14/02/14 16:38:24 INFO SparkContext: Job finished: first at <console>:15, took 0.002671379 s
43 res11: String = # Apache Spark
44
45 scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
46 linesWithSpark: org.apache.spark.rdd.RDD[String] = FilteredRDD[17] at filter at <console>:14
47
48 scala> textFile.filter(line=> line.contains("spark")).count
49 14/02/14 16:38:37 INFO SparkContext: Starting job: count at <console>:15
50 14/02/14 16:38:37 INFO DAGScheduler: Got job 9 (count at <console>:15) with 1 output partitions (allowLocal=false)
51 14/02/14 16:38:37 INFO DAGScheduler: Final stage: Stage 9 (count at <console>:15)
52 14/02/14 16:38:37 INFO DAGScheduler: Parents of final stage: List()
53 14/02/14 16:38:37 INFO DAGScheduler: Missing parents: List()
54 14/02/14 16:38:37 INFO DAGScheduler: Submitting Stage 9 (FilteredRDD[18] at filter at <console>:15), which has no missin
55 g parents
56 14/02/14 16:38:37 INFO DAGScheduler: Submitting 1 missing tasks from Stage 9 (FilteredRDD[18] at filter at <console>:15)
57
58 14/02/14 16:38:37 INFO TaskSchedulerImpl: Adding task set 9.0 with 1 tasks
59 14/02/14 16:38:37 INFO TaskSetManager: Starting task 9.0:0 as TID 6 on executor localhost: localhost (PROCESS_LOCAL)
60 14/02/14 16:38:37 INFO TaskSetManager: Serialized task 9.0:0 as 1642 bytes in 0 ms
61 14/02/14 16:38:37 INFO Executor: Running task ID 6
62 14/02/14 16:38:37 INFO BlockManager: Found block broadcast_5 locally
63 14/02/14 16:38:37 INFO HadoopRDD: Input split: file:/D:/program/spark-0.9.0-incubating/README.md:0+4491
64 14/02/14 16:38:37 INFO Executor: Serialized size of result for 6 is 563
65 14/02/14 16:38:37 INFO Executor: Sending result for 6 directly to driver
66 14/02/14 16:38:37 INFO Executor: Finished task ID 6
67 14/02/14 16:38:37 INFO TaskSetManager: Finished TID 6 in 10 ms on localhost (progress: 0/1)
68 14/02/14 16:38:37 INFO DAGScheduler: Completed ResultTask(9, 0)
69 14/02/14 16:38:37 INFO TaskSchedulerImpl: Remove TaskSet 9.0 from pool
70 14/02/14 16:38:37 INFO DAGScheduler: Stage 9 (count at <console>:15) finished in 0.010 s
71 14/02/14 16:38:37 INFO SparkContext: Job finished: count at <console>:15, took 0.020335125 s
72 res12: Long = 7
另外Spark官网提供了入门的四段视频,但是国内被墙了,无法观看youtube,我把这四段视频放到了土豆网,大家可以看看。
Spark Screencast 1 – 搭建Spark环境Spark Screencast 2 – Spark文档总览Spark Screencast 3 – 转换和缓存Spark Screencast 4 – Scala独立任务
2013年5月23日
#
$ uptime
11:12:26 up 3:44, 4 users, load average: 0.38, 0.31, 0.19
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程树。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
上面的输出,load average后面分别是1分钟、5分钟、15分钟的负载情况。数据是每隔5秒钟检查一次活跃的进程数,然后根据这个数值算出来的。如果这个数除以CPU 的数目,结果高于5的时候就表明系统在超负荷运转了。
Linux系统Load average负载详细解释 我们知道判断一个系统的负载可以使用top,uptime等命令去查看,它分别记录了一分钟、五分钟、以及十五分钟的系统平均负载
例如我的某台服务器:
$ uptime
09:50:21 up 200 days, 15:07, 1 user, load average: 0.27, 0.33, 0.37
大部分的人都认为这个数字越小越好,其实有很多关联的提示信息,今天看到这个好文,应该可以给大家说清楚很多问题,转一下:
你可能对于 Linux 的负载均值(load averages)已有了充分的了解。负载均值在 uptime 或者 top 命令中可以看到,它们可能会显示成这个样子:
load average: 0.09, 0.05, 0.01
很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五 分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越 大,这也可能是服务器出现某种问题的信号。
而事实不完全如此,是什么因素构成了负载均值的大小,以及如何区分它们目前的状况是 “好”还是“糟糕”?什么时候应该注意哪些不正常的数值?
回答这些问题之前,首先需要了解下这些数值背后的些知识。我们先用最简单的例子说明, 一台只配备一块单核处理器的服务器。
行车过桥
一只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥 费 — 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。
因此,需要些特定的代号表示目前的车流情况,例如:
0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,总而言之很通畅,过往的车辆可以丝毫不用等待的通过。
1.00 表示刚好是在这座桥的承受范围内。 这种情况不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。
超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕? 例如 2.00 的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00 的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。
上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。
和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。
“所以你说的理想负荷为 1.00 ?”
嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有经验的系统管理员都会将这条线划在 0.70:
“需要进行调查法则”: 如果长期你的系统负载在 0.70 上下,那么你需要在事情变得更糟糕之前,花些时间了解其原因。
“现在就要修复法则”:1.00 。 如果你的服务器系统负载长期徘徊于 1.00,那么就应该马上解决这个问题。否则,你将半夜接到你上司的电话,这可不是件令人愉快的事情。
“凌晨三点半锻炼身体法则”:5.00。 如果你的服务器负载超过了 5.00 这个数字,那么你将失去你的睡眠,还得在会议中说明这情况发生的原因,总之千万不要让它发生。
2013年5月22日
#
Refer to: http://my.oschina.net/redhouse/blog/60739
CyclicBarrier (周期障碍)类可以帮助同步,它允许一组线程等待整个线程组到达公共屏障点。CyclicBarrier 是使用整型变量构造的,其确定组中的线程数。当一个线程到达屏障时(通过调用 CyclicBarrier.await()),它会被阻塞,直到所有线程都到达屏障,然后在该点允许所有线程继续执行。与CountDownLatch不同的是,CyclicBarrier 所有公共线程都到达后,可以继续执行下一个目标点,而CountDownLatch第一次到达指定点后,也就是记数器减制零,就无法再次执行下一目标工作。下面主要演义CyclicBarrier 的用法:
package com.test;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCyclicBarrier {
private static int[] timeWalk = { 5, 8, 15, 15, 10 }; // 徒步需要的时间
private static int[] timeSelf = { 1, 3, 4, 4, 5 }; // 自驾游
private static int[] timeBus = { 2, 4, 6, 6, 7 }; // 旅游大巴
static String now() {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
return sdf.format(new Date()) + ": ";
}
static class Tour implements Runnable {
private int[] times;
private CyclicBarrier barrier;
private String tourName;
public Tour(CyclicBarrier barrier, String tourName, int[] times) {
this.times = times;
this.tourName = tourName;
this.barrier = barrier;
}
public void run() {
try {
Thread.sleep(times[0] * 1000);
System.out.println(now() + tourName + " 合肥");
barrier.await();
Thread.sleep(times[1] * 1000);
System.out.println(now() + tourName + " 南京");
barrier.await();
Thread.sleep(times[4] * 1000);
System.out.println(now() + tourName + " 上海");
barrier.await();
System.out.println(tourName + "飞机 合肥");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(3);
ExecutorService exec = Executors.newFixedThreadPool(3);
exec.submit(new Tour(barrier, "徒步", timeWalk));
exec.submit(new Tour(barrier, "自驾", timeSelf));
exec.submit(new Tour(barrier, "大巴", timeBus));
exec.shutdown();
}
}
最后执行结果如下:
16:24:35: 自驾 合肥
16:24:36: 大巴 合肥
16:24:39: 徒步 合肥
16:24:42: 自驾 南京
16:24:43: 大巴 南京
16:24:47: 徒步 南京
16:24:52: 自驾 上海
16:24:54: 大巴 上海
16:24:57: 徒步 上海
徒步飞机 合肥
自驾飞机 合肥
大巴飞机 合肥
2013年5月21日
#
先描述一下问题: 有一个管理Job的UI,选中一些Job可以Run,每次只能启动一个。还有一个UI通过Timer定时发Ajax请求服务端,查询并显示Job的运行状况(进度)。 奇怪的问题出现了: 1)在FireFox和IE8运行正常(貌似正常,稍后再解释)。其他浏览器未测试。 2)IE6,7及更早版本,Timer无法检测到多于1个的Job运行。 先检查了一遍代码,Timer的控制没有问题。不行就使用Fiddler吧。刚好是IE的问题。 观察HTTP发现一个现象,运行Job的HTTP似乎没有成功,因为Body是-1,之后是每隔一秒的Timer发起的HTTP。如果再启动一个Job,发现Timer停止了!! 等待第一个Job运行成功之后,Timer又恢复了(重新发送Ajax请求)!! 似乎是运行Job的请求阻塞了(实际上该请求长时间没有返回,因为运行Job需要几分钟甚至更多时间)。 为啥不使用DWR3.0的Push技术?后来跟同事讨论明白,这不过是把Timer从客户端转移到了服务端。 记起来了,俺好像读DWR源代码的时候(当时对如何实现推非常感兴趣),见过一段代码分析Browser的类型和连接数,有的情况还抛出了异常。 明白了,肯定是IE6有连接数限制问题,后来得知,默认情况下,它不支持同时超过2个连接。哈哈。这就对了。 RunJob占用了一个(几分钟不等), Timer占用了一个(很短暂)。 刚好2个。 Java代码

- public class BrowserDetect
- {
- /**
- * How many connections can this browser open simultaneously?
- * @param request The request so we can get at the user-agent header
- * @return The number of connections that we think this browser can take
- */
- public static int getConnectionLimit(HttpServletRequest request)
- {
- if (atLeast(request, UserAgent.IE, 8))
- {
- return 6;
- }
- if (atLeast(request, UserAgent.Firefox, 3))
- {
- return 6;
- }
- else if (atLeast(request, UserAgent.AppleWebKit, 8))
- {
- return 4;
- }
- else if (atLeast(request, UserAgent.Opera, 9))
- {
- return 4;
- }
- else
- {
- return 2;
- }
- }
- //....
- }
2013年5月15日
#
DK1.5引入了新的类型——枚举。在 Java 中它虽然算个“小”功能,却给我的开发带来了“大”方便。
用法一:常量
在JDK1.5 之前,我们定义常量都是: public static fianl.... 。现在好了,有了枚举,可以把相关的常量分组到一个枚举类型里,而且枚举提供了比常量更多的方法。
Java代码

- public enum Color {
- RED, GREEN, BLANK, YELLOW
- }
用法二:switch
JDK1.6之前的switch语句只支持int,char,enum类型,使用枚举,能让我们的代码可读性更强。
Java代码
- enum Signal {
- GREEN, YELLOW, RED
- }
- public class TrafficLight {
- Signal color = Signal.RED;
- public void change() {
- switch (color) {
- case RED:
- color = Signal.GREEN;
- break;
- case YELLOW:
- color = Signal.RED;
- break;
- case GREEN:
- color = Signal.YELLOW;
- break;
- }
- }
- }
用法三:向枚举中添加新方法
如果打算自定义自己的方法,那么必须在enum实例序列的最后添加一个分号。而且 Java 要求必须先定义 enum实例。
Java代码
- public enum Color {
- RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
- // 成员变量
- private String name;
- private int index;
- // 构造方法
- private Color(String name, int index) {
- this.name = name;
- this.index = index;
- }
- // 普通方法
- public static String getName(int index) {
- for (Color c : Color.values()) {
- if (c.getIndex() == index) {
- return c.name;
- }
- }
- return null;
- }
- // get set 方法
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public int getIndex() {
- return index;
- }
- public void setIndex(int index) {
- this.index = index;
- }
- }
用法四:覆盖枚举的方法
下面给出一个toString()方法覆盖的例子。
Java代码
- public enum Color {
- RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
- // 成员变量
- private String name;
- private int index;
- // 构造方法
- private Color(String name, int index) {
- this.name = name;
- this.index = index;
- }
- //覆盖方法
- @Override
- public String toString() {
- return this.index+"_"+this.name;
- }
- }
用法五:实现接口
所有的枚举都继承自java.lang.Enum类。由于Java 不支持多继承,所以枚举对象不能再继承其他类。
Java代码
- public interface Behaviour {
- void print();
- String getInfo();
- }
- public enum Color implements Behaviour{
- RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
- // 成员变量
- private String name;
- private int index;
- // 构造方法
- private Color(String name, int index) {
- this.name = name;
- this.index = index;
- }
- //接口方法
- @Override
- public String getInfo() {
- return this.name;
- }
- //接口方法
- @Override
- public void print() {
- System.out.println(this.index+":"+this.name);
- }
- }
用法六:使用接口组织枚举
Java代码
- public interface Food {
- enum Coffee implements Food{
- BLACK_COFFEE,DECAF_COFFEE,LATTE,CAPPUCCINO
- }
- enum Dessert implements Food{
- FRUIT, CAKE, GELATO
- }
- }
用法七:关于枚举集合的使用
java.util.EnumSet和java.util.EnumMap是两个枚举集合。EnumSet保证集合中的元素不重复;EnumMap中的key是enum类型,而value则可以是任意类型。关于这个两个集合的使用就不在这里赘述,可以参考JDK文档。
关于枚举的实现细节和原理请参考:
2013年5月9日
#
在Linux或其他UNIX和类UNIX环境下,ps命令想必大家都不陌生,我相信也有不少同学写过 ps aux | grep java | grep -v grep | awk '{print $2}' 这样的管道命令来找出Java进程的pid。常言道,Java并非真的"跨平台",它自己就是平台。作为平台,当然也有些基本的工具,让我们可以用更简单、更统一,同时又是非侵入的方式来查询进程相关信息。今天我们就来认识一下其中的两个。
jps
顾名思义,它对应到UNIX的ps命令。用法如下:
jps [ options ] [ hostid ]
其中,options可以用 -q (安静) -m (输出传递给main方法的参数) -l (显示完整路径) -v (显示传递给JVM的命令行参数) -V (显示通过flag文件传递给JVM的参数) -J (和其他Java工具类似用于传递参数给命令本身要调用的java进程);hostid是主机id,默认localhost。
jstat
用于输出给定java进程的统计信息。用法如下:
jstat -options 可以列出当前JVM版本支持的选项,常见的有 -class (类加载器) -compiler (JIT) -gc (GC堆状态) -gccapacity (各区大小) -gccause (最近一次GC统计和原因) -gcnew (新区统计) -gcnewcapacity (新区大小) -gcold (老区统计) -gcoldcapacity (老区大小) -gcpermcapacity (永久区大小) -gcutil (GC统计汇总) -printcompilation (HotSpot编译统计)
假定你要监控的Java进程号是12345,那么
jstat -gcutil -t 12345 200 300 即可每200毫秒连续打印300次带有时间戳的GC统计信息。
简单解释一下: -gcutil是传入的option;必选,-t是打印时间戳,是以目标JVM启动时间为起点计算的,可选;12345是vmid/pid,和我们从jps拿到的是一样的,必选;200是监控时间间隔,可选,不提供就意味着单次输出;300是最大输出次数,可选,不提供且监控时间间隔有值的话,就是无限期打印下去。
jstat 1. jstat -gc pid
可以显示gc的信息,查看gc的次数,及时间。
其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。
2.jstat -gccapacity pid
可以显示,VM内存中三代(young,old,perm)对象的使用和占用大小,
如:PGCMN显示的是最小perm的内存使用量,PGCMX显示的是perm的内存最大使用量,
PGC是当前新生成的perm内存占用量,PC是但前perm内存占用量。
其他的可以根据这个类推, OC是old内纯的占用量。
3.jstat -gcutil pid
统计gc信息统计。
4.jstat -gcnew pid
年轻代对象的信息。
5.jstat -gcnewcapacity pid
年轻代对象的信息及其占用量。
6.jstat -gcold pid
old代对象的信息。
7.stat -gcoldcapacity pid
old代对象的信息及其占用量。
8.jstat -gcpermcapacity pid
perm对象的信息及其占用量。
9.jstat -class pid
显示加载class的数量,及所占空间等信息。
10.jstat -compiler pid
显示VM实时编译的数量等信息。
11.stat -printcompilation pid
当前VM执行的信息。
一些术语的中文解释:
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
EC:年轻代中Eden(伊甸园)的容量 (字节)
EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
OC:Old代的容量 (字节)
OU:Old代目前已使用空间 (字节)
PC:Perm(持久代)的容量 (字节)
PU:Perm(持久代)目前已使用空间 (字节)
YGC:从应用程序启动到采样时年轻代中gc次数
YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
FGC:从应用程序启动到采样时old代(全gc)gc次数
FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
NGCMN:年轻代(young)中初始化(最小)的大小 (字节)
NGCMX:年轻代(young)的最大容量 (字节)
NGC:年轻代(young)中当前的容量 (字节)
OGCMN:old代中初始化(最小)的大小 (字节)
OGCMX:old代的最大容量 (字节)
OGC:old代当前新生成的容量 (字节)
PGCMN:perm代中初始化(最小)的大小 (字节)
PGCMX:perm代的最大容量 (字节)
PGC:perm代当前新生成的容量 (字节)
S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
O:old代已使用的占当前容量百分比
P:perm代已使用的占当前容量百分比
S0CMX:年轻代中第一个survivor(幸存区)的最大容量 (字节)
S1CMX :年轻代中第二个survivor(幸存区)的最大容量 (字节)
ECMX:年轻代中Eden(伊甸园)的最大容量 (字节)
DSS:当前需要survivor(幸存区)的容量 (字节)(Eden区已满)
TT: 持有次数限制
MTT : 最大持有次数限制
虚拟机中的共划分为三个代:年轻代(Young Generation)、年老点(Old Generation)和持久代(Permanent Generation)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和年老代的划分是对垃圾收集影响比较大的。
年轻代:
所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个 Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个 Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
年老代:
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
持久代:
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate 等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
什么情况下触发垃圾回收:
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。
Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个对进行回收,所以比Scavenge GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC:
-server -Xmx3000m -Xms3000m -Xmn1200m -Xss256k -XX:SurvivorRatio=8 -XX:PermSize=96m -XX:MaxPermSize=96m -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:+CMSClassUnloadingEnabled -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/app_admin/logs/oom.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/home/app_admin/logs/gc.log-Xmx3000m:设置JVM最大可用内存为3000M。
-Xms3000m:设置JVM促使内存为3000M。可设置与-Xmx相同,避免每次gc后JVM重新分配内存。
-Xmn1200m:设置年轻代大小为1200m。整个堆大小=年轻代大小+年老代大小。增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss256k: 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1024k,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-XX:PermSize=96m -XX:MaxPermSize=96m:设置持久代大小为64m,根据应用自身class文件大小进行设置,运行时空余量在10%------20%左右。
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。
-XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。
-XX:-CMSParallelRemarkEnabled :If the -XX:+UseParNewGC option is in use the remark pauses may be decreased with the -XX:+CMSParallelRemarkEnabled option.
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片(-XX:CMSFullGCsBeforeCompaction=5:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生"碎片",使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理, 避免每次压缩性能消耗)
*-XX:+CMSClassUnloadingEnabled:*Perm Gen的使用到达一定的比率(默认为92% ) 出发cms回收
-XX:+DisableExplicitGC:屏蔽system.gc(), 这种显示调用垃圾回收
-XX:+HeapDumpOnOutOfMemoryError:内存溢出打印堆栈信息
-XX:HeapDumpPath=/home/app_admin/logs/oom.log:heapdump的日志文件路径
-XX:+PrintGCDetails:打印gc日志详情
-XX:+PrintGCDateStamps:打印gc时的具体时间
-Xloggc:/home/app_admin/logs/gc.log:gc打印日志文件的路径
JVM内存结构

• Method Area------方法区,被Class Loader所装载的class文件以及相关的方法信息、域信息、静态变量等都存放在这个区域内。该区域是所有Java线程所共享的。(设置方法区内存大小:-XX:PermSize -XX:MaxPermSize)
• Heap------堆区,这个区域就是用来存放java对象的,通常GC也是针对该区域。一个Java虚拟机实例只有一个堆,并直接由java虚拟机进行管理,在虚拟机启动时创建。该区域可以被所有Java线程所共享。(设置堆内存大小:-Xms -Xmx -Xmn)
• Stack------栈区,用来存放JVM的内存局部变量和操作数栈。通常虚拟机对它的操作比较简单(以帧为单位的压栈和出栈),速度也很快。每个线程都有自己的栈,且栈可以不连续。(设置栈内存大小:-Xss)
• Program Counter Register------每一个线程都有自己的一个PC寄存器,用于存放下一条被执行的指令的地址。每个线程的PC寄存器在线程启动时产生。
• Native Method Stack------保存本地方法进入区域的地址。(设置栈内存大小:-Xss)

GC日志格式说明:
[GC [<collector>: <starting occupancy1> -> <ending occupancy1>, <pause time1> secs] <starting occupancy3> -> <ending occupancy3>, <pause time3> secs]
<collector>GC收集器的名称
<starting occupancy1> 新生代在GC前占用的内存
<ending occupancy1> 新生代在GC后占用的内存
<pause time1> 新生代局部收集时jvm暂停处理的时间
<starting occupancy3> JVM Heap 在GC前占用的内存
<ending occupancy3> JVM Heap 在GC后占用的内存
<pause time3> GC过程中jvm暂停处理的总时间
YGC收集信息
2012-2-7T19:24:29.040+0800: 10429.503: [GC [PSYoungGen: 484520K->2577K(495936K)] 734774K->254308K(3129664K), 0.0118730 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
FGC收集信息
2012-2-7T19:38:37.391+0800: 10804.897: [Full GC (System) [PSYoungGen: 684K->0K(468416K)] [PSOldGen: 342164K->257451K(1060864K)] 342849K->257451K(1529280K) [PSPermGen: 123775K->122206K(237248K)], 1.1808050 secs] [Times: user=0.99 sys=0.18, real=1.18 secs]
JVM运行期分析工具
jps 虚拟机进程状况工具
jinfo java配置信息工具
jstat 虚拟机统计信息监视工具
jmap java内存映射工具
jhat 虚拟机堆转储快照分析工具
jstack java堆栈跟踪工具
Refer to: http://www.cnblogs.com/wangkangluo1/archive/2012/04/17/2453975.html
可以看作命令行浏览器
1、开启gzip请求
curl -I http://www.sina.com.cn/ -H Accept-Encoding:gzip,defalte
2、监控网页的响应时间
curl -o /dev/null -s -w "time_connect: %{time_connect}\ntime_starttransfer: %{time_starttransfer}\ntime_total: %{time_total}\n" "http://www.kklinux.com"
3. 监控站点可用性
curl -o /dev/null -s -w %{http_code} "http://www.kklinux.com"
4、以http1.0协议请求(默认为http1.1)
curl -0 ..............
1)读取网页
$ curl linuxidc.com">http://www.linuxidc.com
2)保存网页
$ curl http://www.linuxidc.com > page.html $ curl -o page.html http://www.linuxidc.com
3)使用的proxy服务器及其端口:-x
$ curl -x 123.45.67.89:1080 -o page.html http://www.linuxidc.com
4)使用cookie来记录session信息
$ curl -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
option: -D 是把http的response里面的cookie信息存到一个特别的文件中去,这样,当页面被存到page.html的同时,cookie信息也被存到了cookie0001.txt里面了
5)那么,下一次访问的时候,如何继续使用上次留下的cookie信息呢?
使用option来把上次的cookie信息追加到http request里面去:-b
$ curl -x 123.45.67.89:1080 -o page1.html -D cookie0002.txt -b cookie0001.txt http://www.linuxidc.com
6)浏览器信息~~~~
随意指定自己这次访问所宣称的自己的浏览器信息: -A
curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.yahoo.com
这样,服务器端接到访问的要求,会认为你是一个运行在Windows 2000上的IE6.0,嘿嘿嘿,其实也许你用的是苹果机呢!
而"Mozilla/4.73 [en] (X11; U; Linux 2.2; 15 i686"则可以告诉对方你是一台PC上跑着的Linux,用的是Netscape 4.73,呵呵呵
7)
另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的referer地址就是第一次访问成功后的页面地
址。这样,服务器端只要发现对下载页面某次访问的referer地址不 是首页的地址,就可以断定那是个盗连了~~~~~
讨厌讨厌~~~我就是要盗连~~~~~!!
幸好curl给我们提供了设定referer的option: -e
curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e "mail.yahoo.com" -o page.html -D cookie0001.txt http://www.yahoo.com
这样,就可以骗对方的服务器,你是从mail.yahoo.com点击某个链接过来的了,呵呵呵
8)curl 下载文件
刚才讲过了,下载页面到一个文件里,可以使用 -o ,下载文件也是一样。
比如, curl -o 1.jpg http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这里教大家一个新的option: -O
大写的O,这么用: curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这样,就可以按照服务器上的文件名,自动存在本地了!
再来一个更好用的。
如果screen1.JPG以外还有screen2.JPG、screen3.JPG、....、screen10.JPG需要下载,难不成还要让我们写一个script来完成这些操作?
不干!
在curl里面,这么写就可以了:
curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen[1-10].JPG
呵呵呵,厉害吧?!~~~
9)
再来,我们继续讲解下载!
curl -O http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
这样产生的下载,就是
~zzh/001.JPG
~zzh/002.JPG
...
~zzh/201.JPG
~nick/001.JPG
~nick/002.JPG
...
~nick/201.JPG
够方便的了吧?哈哈哈
咦?高兴得太早了。
由于zzh/nick下的文件名都是001,002...,201,下载下来的文件重名,后面的把前面的文件都给覆盖掉了~~~
没关系,我们还有更狠的!
curl -o #2_#1.jpg http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
--这是.....自定义文件名的下载?
--对头,呵呵!
#1是变量,指的是{zzh,nick}这部分,第一次取值zzh,第二次取值nick
#2代表的变量,则是第二段可变部分---[001-201],取值从001逐一加到201
这样,自定义出来下载下来的文件名,就变成了这样:
原来: ~zzh/001.JPG ---> 下载后: 001-zzh.JPG
原来: ~nick/001.JPG ---> 下载后: 001-nick.JPG
这样一来,就不怕文件重名啦,呵呵
9)
继续讲下载
我们平时在windows平台上,flashget这样的工具可以帮我们分块并行下载,还可以断线续传。
curl在这些方面也不输给谁,嘿嘿
比如我们下载screen1.JPG中,突然掉线了,我们就可以这样开始续传
curl -c -O http://cgi2.tky.3wb.ne.jp/~zzh/screen1.JPG
当然,你不要拿个flashget下载了一半的文件来糊弄我~~~~别的下载软件的半截文件可不一定能用哦~~~
分块下载,我们使用这个option就可以了: -r
举例说明
比如我们有一个http://cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3 要下载(赵老师的电话朗诵 :D )
我们就可以用这样的命令:
curl -r 0-10240 -o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3 &\
curl -r 10241-20480 -o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3 &\
curl -r 20481-40960 -o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3 &\
curl -r 40961- -o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
这样就可以分块下载啦。
不过你需要自己把这些破碎的文件合并起来
如果你用UNIX或苹果,用 cat zhao.part* > zhao.mp3就可以
如果用的是Windows,用copy /b 来解决吧,呵呵
上面讲的都是http协议的下载,其实ftp也一样可以用。
用法嘛,
curl -u name:passwd ftp://ip:port/path/file
或者大家熟悉的
curl ftp://name:passwd@ip:port/path/file
10)上传的option是 -T
比如我们向ftp传一个文件: curl -T localfile -u name:passwd ftp://upload_site:port/path/
当然,向http服务器上传文件也可以
比如 curl -T localfile http://cgi2.tky.3web.ne.jp/~zzh/abc.cgi
注意,这时候,使用的协议是HTTP的PUT method
刚才说到PUT,嘿嘿,自然让老服想起来了其他几种methos还没讲呢!
GET和POST都不能忘哦。
http提交一个表单,比较常用的是POST模式和GET模式
GET模式什么option都不用,只需要把变量写在url里面就可以了
比如:
curl http://www.yahoo.com/login.cgi?user=nickwolfe&password=12345
而POST模式的option则是 -d
比如,curl -d "user=nickwolfe&password=12345" http://www.yahoo.com/login.cgi
就相当于向这个站点发出一次登陆申请~~~~~
到底该用GET模式还是POST模式,要看对面服务器的程序设定。
一点需要注意的是,POST模式下的文件上的文件上传,比如
<form method="POST" enctype="multipar/form-data" action="http://cgi2.tky.3web.ne.jp/~zzh/up_file.cgi">
<input type=file name=upload>
<input type=submit name=nick value="go">
</form>
这样一个HTTP表单,我们要用curl进行模拟,就该是这样的语法:
curl -F upload=@localfile -F nick=go http://cgi2.tky.3web.ne.jp/~zzh/up_file.cgi
罗罗嗦嗦讲了这么多,其实curl还有很多很多技巧和用法
比如 https的时候使用本地证书,就可以这样
curl -E localcert.pem https://remote_server
再比如,你还可以用curl通过dict协议去查字典~~~~~
curl dict://dict.org/d:computer
今天为了检查所有刺猬主机上所有域名是否有备案.在使用wget不爽的情况下,找到了curl这个命令行流量器命令.发现其对post的调用还是蛮好的.特别有利于对提交信息及变
更参数进行较验.对于我想将几十万域名到miibeian.gov.cn进行验证是否有备案信息非常有用.发现这篇文章很不错,特为转贴.
我的目标:
curl -d "cxfs=1&ym=xieyy.cn" http://www.miibeian.gov.cn/baxx_cx_servlet
在出来的信息中进行过滤,提取备案号信息,并设置一个标识位.将域名,备案号及标识位入库
用curl命令,post提交带空格的数据
今天偶然遇到一个情况,我想用curl登入一个网页,无意间发现要post的数据里带空格。比如用户名为"abcdef",密码为"abc def",其中有一个空格,按照我以前的方式提交:
curl -D cookie -d "username=abcdef&password=abc def" http://login.xxx.com/提示登入失败。
于是查看curl手册man curl。找到:
d/--data (HTTP) Sends the speci?ed data in a POST request to the HTTP server, in a way that can emulate as if a user has ?lled in a HTML form and pressed the
submit button. Note that the data is sent exactly as speci?ed with no extra processing (with all newlines cut off). The data is expected to be "url-encoded".
This will cause curl to pass the data to the server using the content-type application/x-www-form-urlencoded. Compare to -F/--form. If this option is used
more than once on the same command line, the data pieces speci?ed will be merged together with a separating &-letter. Thus, using ’-d name=daniel -d
skill=lousy’ would generate a post chunk that looks like ’name=daniel&skill=lousy’.
于是改用:
curl -D cookie -d "username=abcdef" -d "password=abc efg" http://login.xxx.com/这样就能成功登入了。
(责任编辑:飘飞的夜)
Curl是Linux下一个很强大的http命令行工具,其功能十分强大。
1) 二话不说,先从这里开始吧!
$ curl http://www.linuxidc.com
回车之后,www.linuxidc.com 的html就稀里哗啦地显示在屏幕上了 ~
2) 嗯,要想把读过来页面存下来,是不是要这样呢?
$ curl http://www.linuxidc.com > page.html
当然可以,但不用这么麻烦的!
用curl的内置option就好,存下http的结果,用这个option: -o
$ curl -o page.html http://www.linuxidc.com
这样,你就可以看到屏幕上出现一个下载页面进度指示。等进展到100%,自然就 OK咯
3) 什么什么?!访问不到?肯定是你的proxy没有设定了。
使用curl的时候,用这个option可以指定http访问所使用的proxy服务器及其端口: -x
$ curl -x 123.45.67.89:1080 -o page.html http://www.linuxidc.com
4) 访问有些网站的时候比较讨厌,他使用cookie来记录session信息。
像IE/NN这样的浏览器,当然可以轻易处理cookie信息,但我们的curl呢?.....
我们来学习这个option: -D <— 这个是把http的response里面的cookie信息存到一个特别的文件中去
$ curl -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,当页面被存到page.html的同时,cookie信息也被存到了cookie0001.txt里面了
5)那么,下一次访问的时候,如何继续使用上次留下的cookie信息呢?要知道,很多网站都是靠监视你的cookie信息,来判断你是不是不按规矩访问他们的网站的。
这次我们使用这个option来把上次的cookie信息追加到http request里面去: -b
$ curl -x 123.45.67.89:1080 -o page1.html -D cookie0002.txt -b cookie0001.txt http://www.linuxidc.com
这样,我们就可以几乎模拟所有的IE操作,去访问网页了!
6)稍微等等 ~我好像忘记什么了 ~
对了!是浏览器信息
有些讨厌的网站总要我们使用某些特定的浏览器去访问他们,有时候更过分的是,还要使用某些特定的版本 NND,哪里有时间为了它去找这些怪异的浏览器呢!?
好在curl给我们提供了一个有用的option,可以让我们随意指定自己这次访问所宣称的自己的浏览器信息: -A
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,服务器端接到访问的要求,会认为你是一个运行在Windows 2000上的 IE6.0,嘿嘿嘿,其实也许你用的是苹果机呢!
而"Mozilla/4.73 [en] (X11; U; Linux 2.2; 15 i686"则可以告诉对方你是一台 PC上跑着的Linux,用的是Netscape 4.73,呵呵呵
7)另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的 referer地址就是第一次访问成功后的页面地址。这样,服务器端只要发现对下载页面某次访问的referer地址不是首页的地址,就可以断定那是个盗 连了 ~
讨厌讨厌 ~我就是要盗连 ~!!
幸好curl给我们提供了设定referer的option: -e
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e "mail.linuxidc.com" -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,就可以骗对方的服务器,你是从mail.linuxidc.com点击某个链接过来的了,呵呵呵
8)写着写着发现漏掉什么重要的东西了!——- 利用curl 下载文件
刚才讲过了,下载页面到一个文件里,可以使用 -o ,下载文件也是一样。比如,
$ curl -o 1.jpg http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这里教大家一个新的option: -O 大写的O,这么用:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这样,就可以按照服务器上的文件名,自动存在本地了!
再来一个更好用的。
如果screen1.JPG以外还有screen2.JPG、screen3.JPG、....、screen10.JPG需要下载,难不成还要让我们写一个script来完成这些操作?
不干!
在curl里面,这么写就可以了:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen[1-10].JPG
呵呵呵,厉害吧?! ~
9)再来,我们继续讲解下载!
$ curl -O http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
这样产生的下载,就是
~zzh/001.JPG
~zzh/002.JPG
...
~zzh/201.JPG
~nick/001.JPG
~nick/002.JPG
...
~nick/201.JPG
够方便的了吧?哈哈哈
咦?高兴得太早了。
由于zzh/nick下的文件名都是001,002...,201,下载下来的文件重名,后面的把前面的文件都给覆盖掉了 ~
没关系,我们还有更狠的!
$ curl -o #2_#1.jpg http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
—这是.....自定义文件名的下载? —对头,呵呵!
这样,自定义出来下载下来的文件名,就变成了这样:原来: ~zzh/001.JPG —-> 下载后: 001-zzh.JPG 原来: ~nick/001.JPG —-> 下载后: 001-nick.JPG
这样一来,就不怕文件重名啦,呵呵
完
2013年5月5日
#
最近在开发java web application的时候,因为很多原因,无法对自己开发的项目在本地进行调试,常常需要进行远程调试,之前一直通过打logger的方式进行,每次都要重新部署,相当的痛苦,今天下午研究了以下,如果进行远程调试。
开发的web application是部署在tomcat上面的,那么问题就转化为如何调试tomcat。其实调试tomcat,本质上就是调试JVM。JVM的强大,从J2SE1.4.2开始,就实现了JPDA (Java Platform Debug Architecture)。
tomcat默认情况下,是没有启用jpda的,如果要启用,需要传入参数
-Xdebug -Xrunjdwp:transport=dt_socket, address=8000,server=y,suspend=y
那么问题是这些参数如何在tomcat启动的使用传入呢?这是时候,需要了解tomcat的启动脚本,在TOMCAT_HOME/bin
目录下,有三个脚本catalina.sh, startup.sh, 和 shutdown.sh。如果查看startup.sh和shutdown.sh,都是通过catalina.sh来启动的。脚本如下:
EXECUTABLE=catalina.sh
exec "$PRGDIR"/"$EXECUTABLE" start "$@"
于是,我们可以查看下catalina.sh的脚本是如何实现的。
# JPDA_TRANSPORT (Optional) JPDA transport used when the "jpda start"
# command is executed. The default is "dt_socket".
#
# JPDA_ADDRESS (Optional) Java runtime options used when the "jpda start"
# command is executed. The default is 8000.
#
# JPDA_SUSPEND (Optional) Java runtime options used when the "jpda start"
# command is executed. Specifies whether JVM should suspend
# execution immediately after startup. Default is "n".
#
# JPDA_OPTS (Optional) Java runtime options used when the "jpda start"
# command is executed. If used, JPDA_TRANSPORT, JPDA_ADDRESS,
# and JPDA_SUSPEND are ignored. Thus, all required jpda
# options MUST be specified. The default is:
#
# -agentlib:jdwp=transport=$JPDA_TRANSPORT,
# address=$JPDA_ADDRESS,server=y,suspend=$JPDA_SUSPEND
if [ "$1" = "jpda" ] ; then
if [ -z "$JPDA_TRANSPORT" ]; then
JPDA_TRANSPORT="dt_socket"
fi
if [ -z "$JPDA_ADDRESS" ]; then
JPDA_ADDRESS="8000"
fi
if [ -z "$JPDA_SUSPEND" ]; then
JPDA_SUSPEND="n"
fi
if [ -z "$JPDA_OPTS" ]; then
JPDA_OPTS="-agentlib:jdwp=transport=$JPDA_TRANSPORT,address=$JPDA_ADDRESS,server=y,suspend=$JPDA_SUSPEND"
fi
CATALINA_OPTS="$CATALINA_OPTS $JPDA_OPTS"
shift
fi
通过这个代码,我们可以看出,其实要启动jpda, 最主要的是要对JPDA_SUSPEND的值进行设置,由N改为Y。
借鉴start.sh的启动,在linux下,我们可以自己创建一个jpda.sh的脚本,用来启动开启debug模式的tomcat,具体脚本如下,黑体为修改部分。
os400=false
darwin=false
case "`uname`" in
CYGWIN*) cygwin=true;;
OS400*) os400=true;;
Darwin*) darwin=true;;
esac
# resolve links - $0 may be a softlink
PRG="$0"
while [ -h "$PRG" ] ; do
ls=`ls -ld "$PRG"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '/.*' > /dev/null; then
PRG="$link"
else
PRG=`dirname "$PRG"`/"$link"
fi
done
PRGDIR=`dirname "$PRG"`
EXECUTABLE=catalina.sh
# Check that target executable exists
if $os400; then
# -x will Only work on the os400 if the files are:
# 1. owned by the user
# 2. owned by the PRIMARY group of the user
# this will not work if the user belongs in secondary groups
eval
else
if [ ! -x "$PRGDIR"/"$EXECUTABLE" ]; then
echo "Cannot find $PRGDIR/$EXECUTABLE"
echo "The file is absent or does not have execute permission"
echo "This file is needed to run this program"
exit 1
fi
fi
export JPDA_SUSPEND=y
exec "$PRGDIR"/"$EXECUTABLE" jpda start "$@"
在Eclipse中远程调试Tomcat
首先将Tomcat 5.5.26的源代码分为container connectors jasper servletapi build五个项目,导入到Eclipse中。启动相关的代码主要在container中,就以它为当前项目,打开”Debug Configurations“对话框。
然后创建一个”Remote Java Application“,Connection Type选择”Standard (Socket Attach)“,Host填写localhost(Tomcat所在的主机地址),Port填写8000。最后点击”Apply“保存。

首先确保已经执行了jpda.bat,Tomcat正在等待调试器连接;然后执行上述的Debug Configuration,Eclipse就可以连上Tomcat。
Tomcat的启动是从Bootstrap的main方法开始,我在第一行代码处设置了断点,Tomcat的启动就停在了这一行:
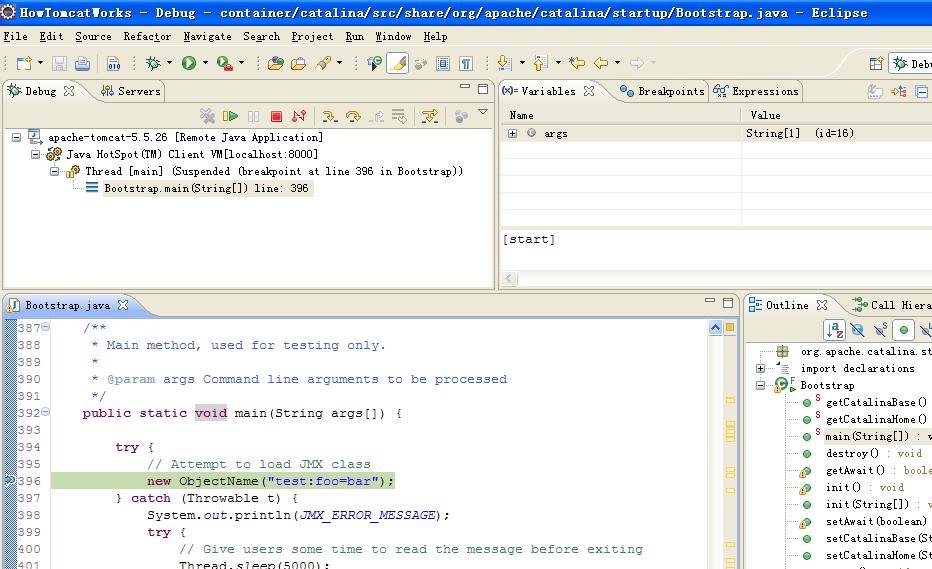
接着,让Tomcat继续执行,我们可以看到,控制台输出了启动信息。

用了Spring MVC有一个多月了,之前虽然有接触过一些,但是一直没有在实际工作中使用。今天和同事聊起,谈到Spring MVC中的Controller是单例实现的,于是就写了一段代码验证一些。
1. 如果是单例的,那么在Controller类中的实例变量应该是共享的,如果不共享,则说明不是单例。
直接代码:
@Controller
public class DemoAction {
private int i = 0;
@RequestMapping(value = "/singleton")
@ResponseBody
public String singleton(HttpServletRequest request, HttpServletResponse response) throws InterruptedException {
int addInt = Integer.parseInt(request.getParameter("int"));
i = i + addInt;
return String.valueOf(i);
}
}
分别三次请求: localhost:8080/projectname/singleton?int=5
得到的返回结果如下。
第一次: i=5
第二次: i=10
第三次: i=15
重结果可以得知,i的状态是共享的,因此Controller是单例的。
-------------------------------------------------------------------------------------------------------------------------
2. 如果是单例,那么多个线程请求同一个Controller类中的同一个方法,线程是否会堵塞?
验证代码如下:
@RequestMapping(value = "/switcher")
@ResponseBody
public String switcher(HttpServletRequest request, HttpServletResponse response)
throws InterruptedException {
String switcher = request.getParameter("switcher");
if (switcher.equals("on")) {
Thread.currentThread().sleep(10000);
return "switch on";
} else {
return switcher;
}
}
验证方法:
分别发送两个请求,
第一个请求:localhost:8080/projectname/singleton?switcher=on
第二个请求:localhost:8080/projectname/singleton?switcher=everything
验证结果:
第一个请求发出去以后,本地服务器等待10s,然后返回结果“switch on”,
在本地服务器等待的者10s当中,第二期的请求,直接返回结果“everything”。说明之间的线程是不互相影响的。
-------------------------------------------------------------------------------------------------------------------------
3.既然Controller是单例的,那么Service是单例的吗?验证方法和Controller的单例是一样的。
验证代码:
Controller:
@Controller
public class DemoAction {
@Resource
private DemoService demoService;
@RequestMapping(value = "/service")
@ResponseBody
public String service(HttpServletRequest request, HttpServletResponse response)
throws InterruptedException {
int result = demoService.addService(5);
return String.valueOf(result);
}
}
Service:
@Service
public class DemoService {
private int i = 0;
public int addService(int num){
i = i + num;
return i;
}
}
分别三次请求: localhost:8080/projectname/service
得到的返回结果如下。
第一次: i=5
第二次: i=10
第三次: i=15
重结果可以得知,i的状态是共享的,因此Service默认是单例的。
-------------------------------------------------------------------------------------------------------------------------
相同的验证方法,可以得出@Repository的DAO也是默认单例。
2013年5月4日
#
摘要: Spring MVC PK Struts2
我们用struts2时采用的传统的配置文件的方式,并没有使用传说中的0配置。spring3 mvc可以认为已经100%零配置了(除了配置spring mvc-servlet.xml外)。
Spring MVC和Struts2的区别:
1. 机制:spring mvc的入口是servlet,而struts2是filter(...
阅读全文