 2010年4月6日
2010年4月6日
Not like the previous solution here http://www.blogjava.net/chaocai/archive/2012/08/05/384844.html
The following solution not using the back tracing way is more concise and readable, but for the searching space becomes huger, the performance is much worser then the previous one.
(ns SICP.unit3)(defn conflictInCol? [s col]
(some #(= col %) s)
)
(defn conflictInDia? [s col]
(let [dia (count s)
n1 (fn [c] (Math/abs (- dia (.indexOf s c))))
n2 (fn [c] (Math/abs (- col c)))]
(some #(= (n1 %) (n2 %)) s)
)
)
(defn safe? [s col]
(not (or (conflictInCol? s col) (conflictInDia? s col)))
)
(defn next-level-queens [solutions-for-prev-level board-size current-level]
(let [solutions (atom [])]
(doseq [s solutions-for-prev-level]
(doseq [col (range 0 board-size)]
(if (safe? s col)
(reset! solutions (cons (conj s col) @solutions))
)
)
)
(if (< current-level (dec board-size))
(recur @solutions board-size (inc current-level))
(count @solutions)
)
)
)
(defn queens [board-size]
(next-level-queens (apply vector (map #(vector %) (range 0 board-size))) board-size 1)
)
Chao Cai (蔡超)
Sr. SDE
Amazon
The functions to support using XPath in Clojure.
Source Code
1 ;The code was implemented by caichao@amazon.com
2 ;You could use the code anyway, but should keep the comments
3 ;Created 2012.10
4 (ns clojure.ccsoft.xml
5 (:require [clojure.xml :as xml]))
6
7 (import '(java.io StringReader)
8 '(java.io ByteArrayInputStream))
9
10 (defn xml-structure [xml-txt]
11 [ (xml/parse (-> xml-txt
12 (.getBytes)
13 (ByteArrayInputStream.)
14 )
15 )]
16 )
17
18 (defn node [tag xmlStruct]
19
20 (first (filter #(= (:tag %) tag) (:content xmlStruct)))
21 )
22
23 (defn node [path xml-txt]
24 (loop [path path
25 xml-content (xml-structure xml-txt)
26 ]
27 (let [current-tag (first path) current-elem (first xml-content)]
28 (if (= (:tag current-elem ) current-tag)
29
30 (if (= (count path) 1)
31 current-elem
32 (recur (rest path) (:content current-elem ))
33 )
34 (if (> (count xml-content) 1)
35 (recur path (rest xml-content))
36 )
37 )
38 )
39 )
40 )
How to Use
(def cmd-example "<command>
<header>
<type>script</type>
<transaction_id>12345</transaction_id>
</header>
<body>
println 3+4;
</body>
</command>")
(node [:command :header :transaction_id] cmd-example)
The following program is about solving N-Queens problem (http://en.wikipedia.org/wiki/Eight_queens_puzzle) by Clojure. If you have the better solution in Clojure or Haskell, welcome to provide your solution.
(ns queens)
(defn conflictInRow? [queens newqueen]
(some #(= newqueen %) queens)
)
(defn conflictInDia? [queens newqueen]
(let [dia (count queens)
n1 (fn [queen] (Math/abs (- dia (.indexOf queens queen))))
n2 (fn [queen] (Math/abs (- newqueen queen)))]
(some #(= (n1 %) (n2 %)) queens)
)
)
(defn conflict? [queens newqueen]
(or (conflictInRow? queens newqueen) (conflictInDia? queens newqueen))
)
(def cnt (atom 0))
(defn put-queens [queens newqueen boardSize ]
(if (= (count queens) boardSize)
(do
(println queens)
(reset! cnt (inc @cnt))
)
(do
;(println queens)
(if (> newqueen boardSize)
(if (and (= (peek queens) boardSize) (= (count queens) 1))
(throw (Exception. (str "That's all " @cnt)))
(recur (pop queens) (inc (peek queens)) boardSize )
)
(if (conflict? queens newqueen)
(recur queens (inc newqueen) boardSize )
(do
(put-queens (conj queens newqueen) 1 boardSize )
(recur queens (inc newqueen) boardSize )
)
)
)
)
)
)
(defn queens [boardSize]
(put-queens [] 1 boardSize)
)
Chao Cai (蔡超)
Sr. Software Dev Engineer
Amazon.com
1 The annotation:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Inherited
public @interface NeedToRetry {
Class<?>[] recoverableExceptions();
int retryTime();
int intervalIncrementalFactor() default 0;
long retryInterval() default 0L;
}
2 The Aspect
@Aspect
public class InvokingRetryInterceptor {
private static Logger log = Logger.getLogger(InvokingRetryInterceptor.class);
private boolean isNeedToRetry(Throwable t,Class<?>[] recoverableExceptions){
String exceptionName= t.getClass().getName();
for (Class<?> exp:recoverableExceptions){
if (exp.isInstance(t)){
return true;
}
}
log.warn("The exception doesn't need recover!"+exceptionName);
return false;
}
private long getRetryInterval(int tryTimes,long interval,int incrementalFactor){
return interval+(tryTimes*incrementalFactor);
}
@Around(value="@annotation(amazon.internal.dropship.common.NeedToRetry)&&@annotation(retryParam)",argNames="retryParam")
public Object process(ProceedingJoinPoint pjp,NeedToRetry retryParam ) throws Throwable{
boolean isNeedTry=true;
int count=0;
Throwable fault;
Class<?>[] recoverableExceptions=retryParam.recoverableExceptions();
int retryTime=retryParam.retryTime();
long retryInterval=retryParam.retryInterval();
int incrementalFactor=retryParam.intervalIncrementalFactor();
do{
try{
return pjp.proceed();
}catch(Throwable t){
fault=t;
if (!isNeedToRetry(t,recoverableExceptions)){
break;
}
Thread.sleep(getRetryInterval(retryTime,retryInterval,incrementalFactor));
}
count++;
}while(count<(retryTime+1));
throw fault;
}
}
http://www.rkb.gov.cn/jsj/cms/s_contents/download/s_dt201103170102.html
ATDD (Acceptance Test Driven Development) is the extension of TDD, which helps us deliver exactly what the customer wants. Now ATDD has already been the hot spot in the software development world. There are several variations of ATDD including BDD, EDD and etc, also more and more frameworks have been created to help us develop with ATDD, for example FIT and JBehave.
The followings will introduce how to use the JBehave in your real project effectively.
Figure 1 Test Code Structure
Each test implementation could be divided into four layers, this structure could help us improve the codes reusability and maintainability, So, it will make us implement the tests quickly and easily.
Specification/Scenario layer:
This layer describes system’s behaviors and functionalities by the scenarios. For using JBehave, we can use the natural language describe the scenarios and just need to follow the JBehave ‘Given-When-Then’ rule.
Parser layer:
We don’t need to implement this layer , this layer has been implemented by JBehave. What exactly JBehave do is to relate the steps of the scenario to the methods of the test codes.
Step Logic Layer:
The layer implements test logics associating with every step of the scenarios. Every step are implemented by a Java method.
Action/Utils layer
This the very important layer to improve the reusability of our codes. This layer provides the utility methods to help you implement step logics. These utility methods usually involved the system state checking, mock requests sending and so on.
For example, we can provide the methods to check the data in database/file or check the state of the middleware, also so frameworks are very useful to implement the logic simulating the client browser’s requests.
Chao Cai
Working for Amazon.com
chaocai2001@yahoo.com.cn
How to design the testable software? You may always find some best practices about designing for scalable, extensible or maintainable. To be testable, the best way should be TDD. Followings are some tips from my real practices on TDD.
1 TDD is design process; it let you design for testing, naturally
Write the test firstly, it does not only help you find the bugs; but the most important point is to let you design for test naturally.
Also you should keep in mind, tests not only help you find bugs, but also protect your codes; when some changes impact on your existing codes, the tests will be broken.
2 Keep the implementation simple
Keep your implementation simple, just let the test pass. The complex implementation may introduce the logics or codes not covered by the tests, even leads some codes not testable.
3 TDD in each scope.
You may get to know the concept ATDD (acceptance test driven development). TDD could be used in every phase of the development and by the different granularity.
To ATDD, you could consider on using some existing framework such as FIT, these frameworks will be bridge between business logic and implementation logic.
Recently, the concept BDD (behavior driven development) is introduced to the ATDD process, so the BDD frameworks such as JBehave is also the good choice.
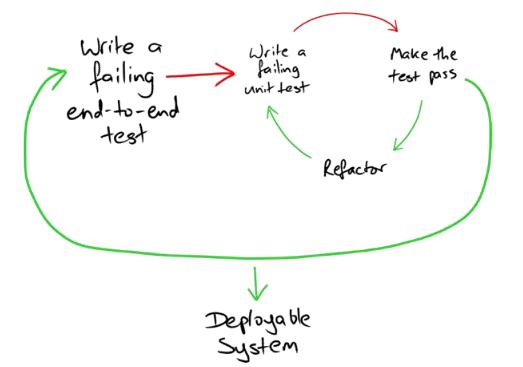
Different TDD process could be nested and should be nested don’t let your step too large.
4 keep each step small enough
Always keep each step small to avoid introducing the untestable codes or logics and pass each test quickly.
6 Always refactor
This step is always overlooked in TDD process; however it is the very important step. Also, never forget refactor should involve all your tests.
Why can't write test firstly?
1.not think how to meature the codes
2. The current step maybe too large, should separate into small ones
3. The codes with ugly dependencies
http://blog.csdn.net/chaocai2004/archive/2011/01/09/6125479.aspx
Chao Cai (蔡超)
Sr. SDE
Amazon.com
相信大家对于算法的时间复杂度O都不会陌生,不过你知道一个算法的时间复杂度是如何计算出来的吗?
以前在学习算法和数据结构的时候,对于每种算法的复杂度都是死记的并没有真正的去研究他们是如何计算出来,最近突然对算法产生了兴趣,迫使自己研究了一下算法复杂度的计算方法。
概念
大O表示法表示时间复杂性,注意它是某一个算法的时间复杂性。大O表示只是说有上界,由定义如果f(n)=O(n),那显然成立f(n)=O(n^2),它给你一个上界,但并不是上确界,但人们在表示的时候一般都习惯表示前者。
另外除了这个官方概念,个人认为大O表示的是问题规模n和算法中语句执行次数的关系。
以二分查找为例,我们求解它的时间复杂度
1 设规模为n个元素时,要执行T(n)次
T(n)=T(n/2)+1
T(n)=[T(n/4)+1]+1
…
T(n)=T(n/2^m)+m
当n=2^m
T(n)=T(1)+log2n
T(1)=1
所以其算法复杂度为O(log2n)
摘要:
由于脚本语言通常提供了更为简洁的语法及Java所不具有的一些新的语言特性(如:闭包,元编程等),所以在一些情况下可以创造出比Java程序更具有可读性的代码。另外,众多基于JVM的脚本语言也为与Java程序整合带来了便利。
Client: 语义模型实例的调用者
SemanticConcept: 语义模型定义,可以通过脚本语言或Java实现
ModelBuilder: 语...
阅读全文