作者:肖文伟
各位在看这篇文章之前请先到w3school来了解一下<img>标签中的usemap属性是什么:
http://www.w3school.com.cn/tags/tag_img_prop_ismap_usemap.asp
在有些概念之后,文章将要开始介绍<img>标签的usemap详细使用方法了.
usemap属性在w3school描述为: usemap 属性提供了一种“客户端”的图像映射机制.
事实上我个人觉得它就是在一个图像上描绘了多个“热点”.这样解释好像比较容易理解一点.
让我们先来看看在Dreamweaver中一个图像上被描绘上了两个热点的最终效果吧:

我们可以在上图很明显的看到,这个图片上有两个热点,分别在图像的左上角和右下角.只要点击不同区域时,就可以超链接到不同的地方.
现来看看页面中的代码吧,这个应该比较重要些,代码如下:
<body>
<img src="images/loginfoot.jpg" border="0" usemap="#Map1" name="foot" width="100" height="100"/>
<map name="Map1">
<area shape="rect" coords="50,50,100,100" style="cursor:hand" href="login.jsp" />
<area shape="rect" coords="0,0,50,50" style="cursor:hand" href="main.jsp"/>
</map>
</body>
让我来解释一下这段代码吧:
先解释这一段:<img src="images/loginfoot.jpg" border="0" usemap="#Map1" name="foot" width="100" height="100"/>
其实不用多说,这段就是在页面上插入一个图像.
图像为: images目录下的loginfoot.jpg.
边框为0,页面中名称为foot,宽100,高100:( border="0" name="foot" width="100" height="100")
重点是这个: usemap="#Map1",我想它应该描述为在此图像中使用图像映射,映射的具体描述为页面中的一个<map>,而它的名称为Map1.
接下来就要讲到<map>了, 这个<map>的名字为Map1,在<map></map>之间有两个<area/>,这两个<area/>分别代表了图片上的两个热点区域.
下面就<area/>标签的属性来作一些介绍:
shape="rect":热点的形状shape为矩形rect(rectangular);
style="cursor:hand":鼠标指针cursor的样式为手hand;
href="login.jsp":超连接到login.jsp页面;
coords="50,50,100,100":这用属性用来描述这个指点区域的具体位置.
我不知道描述位置的属性为什么要使用coords ,这很让人想不明白.如果你不明白coords里面几个值具体是什么意思,我按照个人理解,画了下面这张图.希望你看完之后能够明白:
(将coords="a,b,c,d"里面的几个值分别看作是a,b,c,d ).
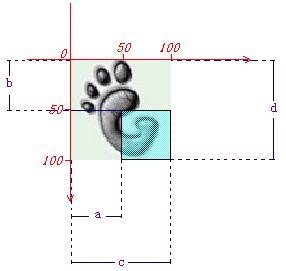
这副图像大小为100*100,中只有一个热点<area/>位于图像的右下角.中间用来描述位置的属性及其值为: coords="50,50,100,100",即:a=50,b=50,c=100,d=100.
看完之后不知道你明白了吗?
以上均为我个人的理解,我将他分享出来.如有错误,还请各位帮忙指正,谢谢!!