2012年3月27日
#============================================================Logger CommonLog
log4j.logger.CommonLog=DEBUG, Console, LogRollingFile
# Console output...
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
# RollingFileAppender output...
log4j.appender.LogRollingFile=org.apache.log4j.RollingFileAppender
log4j.appender.LogRollingFile.File=${user.dir}/yccb/log/yccb.log
log4j.appender.LogRollingFile.Append=true
log4j.appender.LogRollingFile.MaxFileSize=46MB
log4j.appender.LogRollingFile.MaxBackupIndex=50
log4j.appender.LogRollingFile.layout=org.apache.log4j.PatternLayout
log4j.appender.LogRollingFile.layout.ConversionPattern=[%-5p] %d{yyyy-MM-dd HH\:mm\:ss,SSS} method\:%l%n%m%n
#============================================================Logger SkmLog
log4j.logger.SkmLog=DEBUG, DailyRollingFile
# DailyRollingFile output...
log4j.appender.DailyRollingFile=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DailyRollingFile.DatePattern=yyyy-MM-dd'.log'
log4j.appender.DailyRollingFile.File=${user.dir}/yccb/log/skm/skm.log
log4j.appender.DailyRollingFile.layout=org.apache.log4j.PatternLayout
log4j.appender.DailyRollingFile.layout.ConversionPattern=[%-5p] %d{yyyy-MM-dd HH\:mm\:ss,SSS} method\:%l%n%m%n
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
sdf.setLenient(false);
boolean b = true;
try {
sdf.parse("2002-15-11");
} catch (ParseException e) {
e.printStackTrace();
b = false;
}
System.out.println(b);
http://blog.csdn.net/wuxianglong/article/details/6285978
1,公钥和私钥成对出现
2,公开的密钥叫公钥,只有自己知道的叫私钥
3,用公钥加密的数据只有对应的私钥可以 解密
4,用私钥加密的数据只有对应的公钥可以解密
5,如果可以用公钥解密,则必然是对应的私钥加的密
6,如果可以用私钥解密,则 必然是对应的公钥加的密
明白了?
假设一下,我找了两个数字,一个是1,一个是2。我喜欢2这个数字,就保留起来,不告诉你们,然 后我告诉大家,1是我的公钥。
我有一个文件,不能让别人看,我就用1加密了。别人找到了这个文件,但是他不知道2就是解密的私钥啊,所以 他解不开,只有我可以用数字2,就是我的私钥,来解密。这样我就可以保护数据了。
我的好朋友x用我的公钥1加密了字符a,加密后成了b, 放在网上。别人偷到了这个文件,但是别人解不开,因为别人不知道2就是我的私钥,只有我才能解密,解密后就得到a。这样,我们就可以传送加密的数据了。
现在我们知道用公钥加密,然后用私钥来解密,就可以解决安全传输的问题了。如果我用私钥加密一段数据(当然只有我可以用私钥加密,因为只有我知道 2是我的私钥),结果所有的人都看到我的内容了,因为他们都知道我的公钥是1,那么这种加密有什么用处呢?
但是我的好朋友x说有人冒充我 给他发信。怎么办呢?我把我要发的信,内容是c,用我的私钥2,加密,加密后的内容是d,发给x,再告诉他解密看是不是c。他用我的公钥1解密,发现果然 是c。这个时候,他会想到,能够用我的公钥解密的数据,必然是用我的私钥加的密。只有我知道我得私钥,因此他就可以确认确实是我发的东西。这样我们就能确 认发送方身份了。这个过程叫做数字签名。当然具体的过程要稍微复杂一些。用私钥来加密数据,用途就是数字签名。
好,我们复习一下:
1, 公钥私钥成对出现
2,私钥只有我知道
3,大家可以用我的公钥给我发加密的信了
4,大家用我的公钥解密信的内容,看看能不能解开, 能解开,说明是经过我的私钥加密了,就可以确认确实是我发的了。
总结一下结论:
1,用公钥加密数据,用私钥来解密数据
2, 用私钥加密数据(数字签名),用公钥来验证数字签名。
在实际的使用中,公钥不会单独出现,总是以数字证书的方式出现,这样是为了公钥的安 全性和有效性。
二,SSL
我和我得好朋友x,要进行安全的通信。这种通信可以是QQ聊天,很频繁的。用我的公钥加密数据就不行 了,因为:
1,我的好朋友x没有公私钥对,我怎么给他发加密的消息啊? (注:实际情况中,可以双方都有公私钥对)
2,用公私钥加密运算 很费时间,很慢,影响QQ效果。
好了,好朋友x,找了一个数字3,用我的公钥1,加密后发给我,说,我们以后就用这个数字来加密信息吧。 我解开后,得到了数字3。这样,只有我们两个人知道这个秘密的数字3,别的人都不知道,因为他们既不知x挑了一个什么数字,加密后的内容他们也无法解开, 我们把这个秘密的数字叫做会话密钥。
然后,我们选择一种对称密钥算法,比如DES,(对称算法是说,加密过程和解密过程是对称的,用一个 密钥加密,可以用同一个密钥解密。使用公私钥的算法是非对称加密算法),来加密我们之间的通信内容。别人因为不知道3是我们的会话密钥,因而无法解密。
好,复习一下:
1,SSL实现安全的通信
2,通信双方使用一方或者双方的公钥来传递和约定会话密钥 (这个过程叫做握手)
3, 双方使用会话密钥,来加密双方的通信内容
上面说的是原理。大家可能觉得比较复杂了,实际使用中,比这还要复杂。不过庆幸的是,好心的先行 者们在操作系统或者相关的软件中实现了这层(Layer),并且起了一个难听的名字叫做SSL,(Secure Socket Layer)。
超文本传输安全协议(缩写:HTTPS,英语:Hypertext Transfer Protocol Secure)是超文本传输协议和SSL/TLS的组合,用以提供加密通讯及对网络服务器身份的鉴定。HTTPS连接经常被用于万维网上的交易支付和企业信息系统中敏感信息的传输。HTTPS不应与在RFC 2660中定义的安全超文本传输协议(S-HTTP)相混。
主要思想
HTTPS的主要思想是在不安全的网络上创建一安全信道,并可在使用适当的加密包和服务器证书可被验证且可被信任时,对窃听和中间人攻击提供合理的保护。
HTTPS的信任继承基于预先安装在浏览器中的证书颁发机构(如VeriSign、Microsoft等)(意即“我信任证书颁发机构告诉我应该信任的”)。因此,一个到某网站的HTTPS连接可被信任,当且仅当:
- 用户相信他们的浏览器正确实现了HTTPS且安装了正确的证书颁发机构;
- 用户相信证书颁发机构仅信任合法的网站;
- 被访问的网站提供了一个有效的证书,意即,它是由一个被信任的证书颁发机构签发的(大部分浏览器会对无效的证书发出警告);
- 该证书正确地验证了被访问的网站(如,访问
https://example时收到了给“Example Inc.”而不是其它组织的证书); - 或者互联网上相关的节点是值得信任的,或者用户相信本协议的加密层(TLS或SSL)不能被窃听者破坏。
技术细节
- pasting
与HTTP的差异[编辑]
与HTTP的URL由“http://”起始且默认使用端口80不同,HTTPS的URL由“https://”起始且默认使用端口443。
HTTP是不安全的,且攻击者通过监听和中间人攻击等手段,可以获取网站帐户和敏感信息等。HTTPS被设计为可防止前述攻击,并(在没有使用旧版本的SSL时)被认为是安全的。
网络层[编辑]
HTTP工作在应用层(OSI模型的最高层),但安全协议工作在一个较低的子层:在HTTP报文传输前对其加密,并在到达时对其解密。严格地讲,HTTPS并不是一个单独的协议,而是对工作在一加密连接(TLS或SSL)上的常规HTTP协议的称呼。
HTTPS报文中的任何东西都被加密,包括所有报头和荷载。除了可能的CCA(参见限制小节)之外,一个攻击者所能知道的只有在两者之间有一连接这一事实。
服务器设置[编辑]
要使一网络服务器准备好接受HTTPS连接,管理员必须创建一数字证书,并交由证书颁发机构签名以使浏览器接受。证书颁发机构会验证数字证书持有人和其声明的为同一人。浏览器通常都预装了证书颁发机构的证书,所以他们可以验证该签名。
获得证书[编辑]
由证书颁发机构签发的证书有免费的[3][4],也有每年收费13美元[5]到1500美元[6]不等的。
一个组织也可能有自己的证书颁发机构,尤其是当设置浏览器来访问他们自己的网站时(如,运行在公司或学校局域网内的网站)。他们可以容易地将自己的证书加入浏览器中。
此外,还存在一个人到人的证书颁发机构,CAcert。
作为访问控制[编辑]
HTTPS也可被用作客户端认证手段来将一些信息限制给合法的用户。要做到这样,管理员通常会给每个用户创建证书(通常包含了用户的名字和电子邮件地址)。这个证书会被放置在浏览器中,并在每次连接到服务器时由服务器检查。
当私钥失密时[编辑]
TLS有两种策略:简单策略和交互策略。交互策略更为安全,但需要用户在他们的浏览器中安装个人的证书来进行认证。
不管使用了哪种策略,协议所能提供的保护总强烈地依赖于浏览器的实现和服务器软件所支持的加密算法。
HTTPS并不能防止站点被网络蜘蛛抓取。在某些情形中,被加密资源的URL可仅通过截获请求和响应的大小推得,[11]这就可使攻击者同时知道明文(公开的静态内容)和密文(被加密过的明文),从而使选择密文攻击成为可能。
因为SSL在HTTP之下工作,对上层协议一无所知,所以SSL服务器只能为一个IP地址/端口组合提供一个证书。[12]这就意味着在大部分情况下,使用HTTPS的同时支持基于名字的虚拟主机是不很现实的。一种叫域名指示(SNI)的方案通过在加密连接创建前向服务器发送主机名解决了这一问题。Firefox 2、Opera8和运行在Windows Vista的Internet Explorer 7都加入了对SNI的支持。[13][14][15]
因为HTTPS连接所用的公钥以明文传输,因此中国大陆的防火长城可以对特定网站按照匹配的黑名单证书,通过伪装成对方向连接两端的计算机发送RST包干扰两台计算机间正常的TCP通讯,以打断与特定IP地址之间的443端口握手,或者直接使握手的数据包丢弃,导致握手失败,从而导致TLS连接失败。[16]这也是一种互联网信息审查和屏蔽的技术手段。
如果Mac OS X中的家长控制被启用,那么HTTPS站点必须显式地在“总是允许”列表中列出。[17]
值传递(pass by value):stack(栈,常量、基本数据类型(八种)、对象引用、指令(对象的方法)),简单类型。
引用传递(pss by reference):stack(栈)和heap(堆,对象实例(object instance))。
stream在引用传递的过程中,不要随意关闭,一关都关!
double:双精度浮点数,64位(bits)8字节,它可以表示十进制的15或16位有效数字。
float:单精度浮点数,32位(bits)4字节。
浮点:浮动小数点。
当部分网页上面的JAVA插件无法运行,系统提示是由于您的安全设置,所以该运行程序被阻止了,此问题是由于您的JAVA安全设置的级别引起的。
JAVA安全设置修改方式:windows控制面板 -> 程序 -> Java -> 安全。
通常做法是定义一个Servlet,并在web.xml中配置Servlet的启动顺序<load-on-startup>的值在DispatcherServlet之后。但这样做的缺点是在Servlet中无法使用Spring的依赖注入功能,只能使用WebApplicationContext的getBean()方法获取bean。
找到的解决办法如下:
1、自定义一个用于代理启动Servlet的类DelegatingServletProxy:
package com.test.common.util;
import java.io.IOException;
import javax.servlet.GenericServlet;
import javax.servlet.Servlet;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.support.WebApplicationContextUtils;
public class DelegatingServletProxy extends GenericServlet {
private String targetBean;
private Servlet proxy;
@Override
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException {
proxy.service(arg0, arg1);
}
@Override
public void init() throws ServletException {
this.targetBean = getServletName();
getServletBean();
proxy.init(getServletConfig());
}
private void getServletBean() {
WebApplicationContext wac = WebApplicationContextUtils.getRequiredWebApplicationContext(getServletContext());
this.proxy = (Servlet)wac.getBean(targetBean);
}
}
2、编写启动Servlet:
package com.test.common.util;
import java.io.IOException;
import java.util.List;
import javax.annotation.Resource;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import cn.edu.swu.oa.agency.model.Department;
import cn.edu.swu.oa.agency.model.Group;
import cn.edu.swu.oa.agency.service.DepService;
import cn.edu.swu.oa.agency.service.GroService;
import cn.edu.swu.oa.common.model.SysCode;
import cn.edu.swu.oa.safe.model.User;
import cn.edu.swu.oa.safe.service.UserService;
/**
*
*
* 类型解释:Spring启动完成后执行初始化操作
* 类型表述:预读某些实体的Key-Value,放入map,方便以后使用
* @author
* @version
*
*/
@Component("initialServlet")
public class InitialServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Resource
private UserService userService;
@Resource
private DepService depService;
@Resource
private GroService groService;
/**
* @see HttpServlet#HttpServlet()
*/
public InitialServlet() {
super();
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
}
@Override
public void init(ServletConfig config) throws ServletException {
//初始化eserMap
List<User> users = userService.getUsers();
for(int i = 0; i < users.size(); i++) {
User user = users.get(i);
Integer userId = user.getUserId();
String userName = user.getUserName();
SysCode.userMap.put(userId, userName);
}
//初始化depMap
List<Department> deps = depService.getAllDeps();
for(int i = 0; i < deps.size(); i++) {
Department dep = deps.get(i);
Integer depId = dep.getDepId();
String depName = dep.getDepName();
SysCode.depMap.put(depId, depName);
}
//初始化groMap
List<Group> gros = groService.getAllGroups();
for(int i = 0; i < gros.size(); i++) {
Group gro = gros.get(i);
Integer groId = gro.getGroId();
String groName = gro.getGroName();
SysCode.groMap.put(groId, groName);
}
}
}
3、在web.xml文件中配置InitialServlet :
<servlet>
<description></description>
<display-name>InitialServlet</display-name>
<servlet-name>initialServlet</servlet-name>
<servlet-class>
com.test.common.util.DelegatingServletProxy
</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>initialServlet</servlet-name>
<url-pattern>/InitialServlet</url-pattern>
</servlet-mapping>
完成这些操作后,就可以在Spring容器启动后执行自定义的Servlet,并且在自定义Servlet中可以使用Spring Annotation的自动注入功能。 <script></script>
package com.athrunwang.test;
import java.util.Calendar;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
public class TestTimer {
static int count = 0;
public static void showTimer() {
TimerTask task = new TimerTask() {
@Override
public void run() {
++count;
System.out.println("时间=" + new Date() + " 执行了" + count + "次"); // 1次
}
};
// 设置执行时间
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH);
int day = calendar.get(Calendar.DAY_OF_MONTH);// 每天
// 定制每天的21:09:00执行,
calendar.set(year, month, day, 9, 54, 00);
Date date = calendar.getTime();
Timer timer = new Timer();
System.out.println(date);
int period = 2 * 1000;
// 每天的date时刻执行task,每隔2秒重复执行
timer.schedule(task, date, period);
// 每天的date时刻执行task, 仅执行一次
//timer.schedule(task, date);
}
public static void main(String[] args) {
showTimer();
}
}
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class ByteToInputStream {
public static final InputStream byte2Input(byte[] buf) {
return new ByteArrayInputStream(buf);
}
public static final byte[] input2byte(InputStream inStream)
throws IOException {
ByteArrayOutputStream swapStream = new ByteArrayOutputStream();
byte[] buff = new byte[100];
int rc = 0;
while ((rc = inStream.read(buff, 0, 100)) > 0) {
swapStream.write(buff, 0, rc);
}
byte[] in2b = swapStream.toByteArray();
return in2b;
}
}
package others.interesting;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import javazoom.jl.decoder.JavaLayerException;
import javazoom.jl.player.Player;
public class MP3Player {
private String fileName;
private Player player;
public MP3Player(String fileName) {
this.fileName = fileName;
}
public void play() {
try {
BufferedInputStream buffer = new BufferedInputStream(
new FileInputStream(fileName));
player = new Player(buffer);
player.play();
} catch (FileNotFoundException e) {
System.err.println("FileNotFoundException:");
e.printStackTrace();
} catch (JavaLayerException e) {
System.err.println("JavaLayerException:");
e.printStackTrace();
}
}
public static void main(String[] args) {
MP3Player mp3Player = new MP3Player(
"C:\\Users\\Athrunwang\\Desktop\\杀死那个石家庄人.mp3");
mp3Player.play();
}
}
package org.study.sort;
import java.util.Arrays;
/**
* 问题描述:
* 吸血鬼数字是指位数为偶数的数字,可以由一对数字相乘而得到,而这对数字各包含乘积的一半位数的数字,
* 其中从最初的数字中选取的数字可以任意排序。
* 例如:
* 1260 = 21 * 60 1827 = 21 * 87 2187 = 27 * 81
* 要求输出所有四位数的吸血鬼数字。
*
* @author heng.ai
*
* 注:参考了CSDN一朋友的写法
*/
public class VampireNumber {
public static void main(String[] args) {
for(int i = 1; i < 100; i++){
for(int j = i+1; j < 100; j++){
//只要求输出四位数
if(i * j >= 1000){
String a = i + "" + j;
String b = i * j + "";
if(equal(a, b)){
System.out.printf("%d * %d = %d", i, j, i*j);
System.out.println();
}
}
}
}
}
//判断两个字符串包含的数字是否一致
private static boolean equal(String a, String b) {
//先排序
char[] as = a.toCharArray();
char[] bs = b.toCharArray();
Arrays.sort(as); //排序
Arrays.sort(bs); //排序
if(Arrays.equals(as, bs)){
return true;
}
return false;
}
}
在看这篇文章前,我推荐你看一下Eclipse 快捷键手册,我的eclipse版本是4.2 Juno。
先提三点
- 不要使用System.out.println作为调试工具
- 启用所有组件的详细的日志记录级别
- 使用一个日志分析器来阅读日志
1、条件断点想象一下我们平时如何添加断点,通常的做法是双击行号的左边。在debug视图中,BreakPoint View将所有断点都列出来,但是我们可以添加一个boolean类型的条件来决定断点是否被跳过。如果条件为真,在断点处程序将停止,否则断点被跳过,程序继续执行。
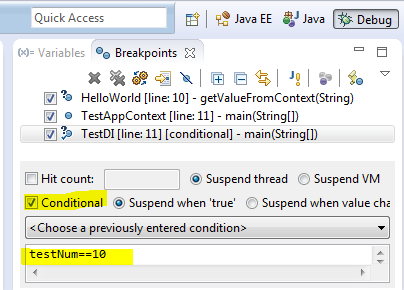
2、异常断点
在断点view中有一个看起来像J!的按钮,我们可以使用它添加一个基于异常的断点,例如我们希望当NullPointerException抛出的时候程序暂停,我们可以这样:
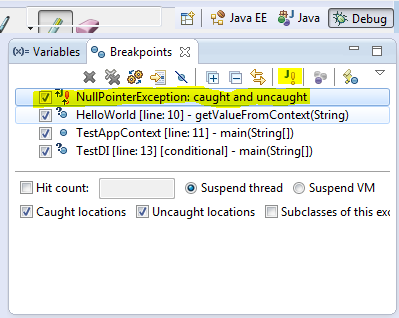
3、观察点
这个特性我非常喜欢,他允许当一个选定的属性被访问或者被更改的时候程序执行暂停,并进行debug。最简单的办法是在类中声明成员变量的语句行号左边双击,就可以加入一个观察点。
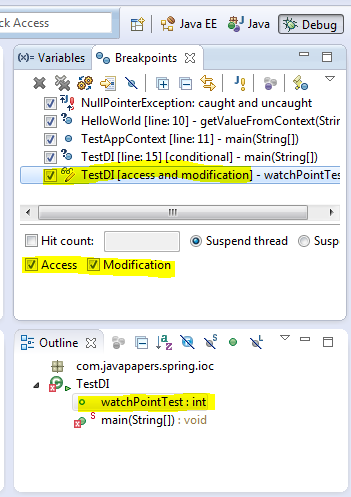
4、查看变量
在选中的变量上使用Ctrl+Shift+d 或者 Ctrl+Shift+i可以查看变量值,另外我们还可以在Expressions View中添加监视。
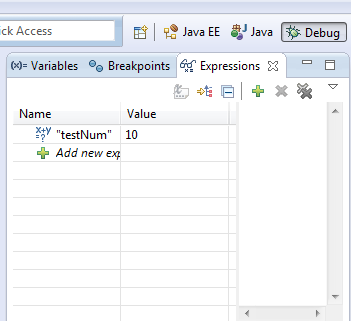
5、改变变量值
我们可以在Debug的时候改变其中变量的值。在Variables View中可以按下图所示操作。
6、在Main方法中停止
在Run/Debug设置中,我们可以按如下图所示的启用这个特性。程序将会在main方法的第一行停住
7、环境变量
我们可以很方便的在Edit Conriguration对话框中添加环境变量
8、Drop to frame
这个功能非常酷,是我第二个非常喜欢的功能,Drop to frame就是说,可以重新跳到当前方法的开始处重新执行,并且所有上下文变量的值也回到那个时候。不一定是当前方法,可以点击当前调用栈中的任何一个frame跳到那里(除了最开始的那个frame)。主要用途是所有变量状态快速恢复到方法开始时候的样子重新执行一遍,即可以一遍又一遍地在那个你关注的上下文中进行多次调试(结合改变变量值等其它功能),而不用重来一遍调试到哪里了。当然,原来执行过程中产生的副作用是不可逆的(比如你往数据库中插入了一条记录)。
9、Step 过滤
当我们在调试的时候摁F5将进入方法的内部,但这有个缺点有的时候可能会进入到一些库的内部(例如JDK),可能并不是我们想要的,我们可以在Preferences中添加一个过滤器,排除指定的包。
10、进入、跳过、返回
其实这个技巧是debug最基本的知识。
- F5-Step Into:移动到下一步,如果当前的行是一个方法调用,将进入这个方法的第一行。(可以通过第九条来排除)
- F6-Step Over:移动到下一行。如果当前行有方法调用,这个方法将被执行完毕返回,然后到下一行。
- F7-Step Return:继续执行当前方法,当当前方法执行完毕的时候,控制将转到当前方法被调用的行。
- F8-移动到下一个断点处。
public class Main {
public static void main(String[] args) {
String pathB = "/P/y/z/a/b/c/d/34/c.php";
String pathA = "/P/y/z/a/b/a/g/e.php";
System.out.println(pathARelativePathB(pathA,pathB,0));
}
public static String pathARelativePathB(String pathA , String pathB, int i){
if(pathA.contains(pathB)){
StringBuilder replaceSb = new StringBuilder();
if(i==1){
replaceSb.append(".");
}else{
while(i>1){
replaceSb.append("../");
--i;
}
}
return pathA.replace(pathB,replaceSb.substring(0, replaceSb.lastIndexOf("/")));
}else{
return pathARelativePathB(pathA,pathB.substring(0,pathB.lastIndexOf("/")),++i);
}
}
}
if(window.external&&window.external.twGetRunPath&&window.external.twGetRunPath().toLowerCase().indexOf("360se")>-1){alert('本站不支持360浏览器访问,请更换其他浏览器!');}
摘要: 1、面向对象的特征有哪些方面 (1).抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面。抽象并不打算了解全部问题,而只是选择其中的一部分,暂时不用部分细 节。抽象包括两个方面,一是过程抽象,二是数据抽象。 (2).继承: 继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法。对象的一个... 阅读全文
Beanutils用了魔术般的反射技术,实现了很多夸张有用的功能,都是C/C++时代不敢想的。无论谁的项目,始终一天都会用得上它。我算是后知后觉了,第一回看到它的时候居然错过。
1.属性的动态getter,setter
在这框架满天飞的年代,不能事事都保证执行getter,setter函数了,有时候属性是要需要根据名字动态取得的,就像这样:
BeanUtils.getProperty(myBean,"code");
而BeanUtils更强的功能是直接访问内嵌对象的属性,只要使用点号分隔。
BeanUtils.getProperty(orderBean, "address.city");
相比之下其他类库的BeanUtils通常都很简单,不能访问内嵌的对象,所以经常要用Commons BeanUtils替换它们。
BeanUtils还支持List和Map类型的属性。如下面的语法即可取得顾客列表中第一个顾客的名字
BeanUtils.getProperty(orderBean, "customers[1].name");
其中BeanUtils会使用ConvertUtils类把字符串转为Bean属性的真正类型,方便从HttpServletRequest等对象中提取bean,或者把bean输出到页面。
而PropertyUtils就会原色的保留Bean原来的类型。
2.beanCompartor 动态排序
还是通过反射,动态设定Bean按照哪个属性来排序,而不再需要在bean的Compare接口进行复杂的条件判断。
List peoples = ...; // Person对象的列表Collections.sort(peoples, new BeanComparator("age"));如果要支持多个属性的复合排序,如"Order By lastName,firstName"
ArrayList sortFields = new ArrayList();sortFields.add(new BeanComparator("lastName"));sortFields.add(new BeanComparator("firstName"));ComparatorChain multiSort = new ComparatorChain(sortFields);
Collections.sort(rows,multiSort);
其中ComparatorChain属于jakata commons-collections包。
如果age属性不是普通类型,构造函数需要再传入一个comparator对象为age变量排序。
另外, BeanCompartor本身的ComparebleComparator, 遇到属性为null就会抛出异常, 也不能设定升序还是降序。
这个时候又要借助commons-collections包的ComparatorUtils.
Comparator mycmp = ComparableComparator.getInstance();
mycmp = ComparatorUtils.nullLowComparator(mycmp); //允许null
mycmp = ComparatorUtils.reversedComparator(mycmp); //逆序
Comparator cmp = new BeanComparator(sortColumn, mycmp);
3.Converter 把Request或ResultSet中的字符串绑定到对象的属性 经常要从request,resultSet等对象取出值来赋入bean中,下面的代码谁都写腻了,如果不用MVC框架的绑定功能的话。
String a = request.getParameter("a"); bean.setA(a); String b = ....不妨写一个Binder:
MyBean bean = ...; HashMap map = new HashMap(); Enumeration names = request.getParameterNames(); while (names.hasMoreElements()) { String name = (String) names.nextElement(); map.put(name, request.getParameterValues(name)); } BeanUtils.populate(bean, map); 其中BeanUtils的populate方法或者getProperty,setProperty方法其实都会调用convert进行转换。
但Converter只支持一些基本的类型,甚至连java.util.Date类型也不支持。而且它比较笨的一个地方是当遇到不认识的类型时,居然会抛出异常来。
对于Date类型,我参考它的sqldate类型实现了一个Converter,而且添加了一个设置日期格式的函数。
要把这个Converter注册,需要如下语句:
ConvertUtilsBean convertUtils = new ConvertUtilsBean();
DateConverter dateConverter = new DateConverter();
convertUtils.register(dateConverter,Date.class);
//因为要注册converter,所以不能再使用BeanUtils的静态方法了,必须创建BeanUtilsBean实例
BeanUtilsBean beanUtils = new BeanUtilsBean(convertUtils,new PropertyUtilsBean());
beanUtils.setProperty(bean, name, value);
4 其他功能4.1 PropertyUtils,当属性为Collection,Map时的动态读取:
Collection: 提供index
BeanUtils.getIndexedProperty(orderBean,"items",1);
或者
BeanUtils.getIndexedProperty(orderBean,"items[1]");
Map: 提供Key Value
BeanUtils.getMappedProperty(orderBean, "items","111");//key-value goods_no=111
或者
BeanUtils.getMappedProperty(orderBean, "items(111)")
4.2 PropertyUtils,获取属性的Class类型
public static Class getPropertyType(Object bean, String name)
4.3 ConstructorUtils,动态创建对象
public static Object invokeConstructor(Class klass, Object arg)
4.4 MethodUtils,动态调用方法
MethodUtils.invokeMethod(bean, methodName, parameter);
4.5 动态Bean 见用DynaBean减除不必要的VO和FormBean
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为"字节"。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为"计算机"。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。遇上00x10, 终端就换行,遇上0x07, 终端就向人们嘟嘟叫,例好遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0x20以下的字节状态称为"控制码"。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的"Ascii"编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集"。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 "GB2312"。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 "DBCS"(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍:
"一个汉字算两个英文字符!一个汉字算两个英文字符......"
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案。当时的中国人想让电脑显示汉字,就必须装上一个"汉字系统",专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么"倚天汉字系统"才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办?
真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了:一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称 "UNICODE"。
UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ascii里的那些"半角"字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于"半角"英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的strlen函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从 UNICODE 开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的"一个字符"!同时,也都是统一的"两个字节",请注意"字符"和"字节"两个术语的不同,"字节"是一个8位的物理存贮单元,而"字符"则是一个文化相关的符号。在UNICODE 中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
从前多种字符集存在时,那些做多语言软件的公司遇上过很大麻烦,他们为了在不同的国家销售同一套软件,就不得不在区域化软件时也加持那个双字节字符集咒语,不仅要处处小心不要搞错,还要把软件中的文字在不同的字符集中转来转去。UNICODE 对于他们来说是一个很好的一揽子解决方案,于是从 Windows NT 开始,MS 趁机把它们的操作系统改了一遍,把所有的核心代码都改成了用 UNICODE 方式工作的版本,从这时开始,WINDOWS 系统终于无需要加装各种本土语言系统,就可以显示全世界上所有文化的字符了。
但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。
如前所述,UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。如果还不够也没有关系,ISO已经准备了UCS-4方案,说简单了就是四个字节来表示一个字符,这样我们就可以组合出21亿个不同的字符出来(最高位有其他用途),这大概可以用到银河联邦成立那一天吧!
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到UTF时并不是直接的对应,而是要过一些算法和规则来转换。
受到过网络编程加持的计算机僧侣们都知道,在网络里传递信息时有一个很重要的问题,就是对于数据高低位的解读方式,一些计算机是采用低位先发送的方法,例如我们PC机采用的 INTEL 架构,而另一些是采用高位先发送的方式,在网络中交换数据时,为了核对双方对于高低位的认识是否是一致的,采用了一种很简便的方法,就是在文本流的开始时向对方发送一个标志符。如果之后的文本是高位在位,那就发送"FEFF",反之,则发送"FFFE"。不信你可以用二进制方式打开一个UTF-X格式的文件,看看开头两个字节是不是这两个字节?
讲到这里,我们再顺便说说一个很著名的奇怪现象:当你在 windows 的记事本里新建一个文件,输入"联通"两个字之后,保存,关闭,然后再次打开,你会发现这两个字已经消失了,代之的是几个乱码!呵呵,有人说这就是联通之所以拼不过移动的原因。
其实这是因为GB2312编码与UTF8编码产生了编码冲撞的原因。
从网上引来一段从UNICODE到UTF8的转换规则:
Unicode
UTF-8
0000 - 007F
0xxxxxxx
0080 - 07FF
110xxxxx 10xxxxxx
0800 - FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如"汉"字的Unicode编码是6C49。6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是其UTF8的编码。
而当你新建一个文本文件时,记事本的编码默认是ANSI, 如果你在ANSI的编码输入汉字,那么他实际就是GB系列的编码方式,在这种编码下,"联通"的内码是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了吗?第一二个字节、第三四个字节的起始部分的都是"110"和"10",正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节的10去掉,我们就得到了"00001 101010",再把各位对齐,补上前导的0,就得到了"0000 0000 0110 1010",不好意思,这是UNICODE的006A,也就是小写的字母"j",而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。这就是只有"联通"两个字的文件没有办法在记事本里正常显示的原因。
而如果你在"联通"之后多输入几个字,其他的字的编码不见得又恰好是110和10开始的字节,这样再次打开时,记事本就不会坚持这是一个utf8编码的文件,而会用ANSI的方式解读之,这时乱码又不出现了。
/**
*
*/
package sortAlgorithm;
import java.io.File;
import java.io.IOException;
import java.sql.Time;
import java.util.Random;
/**
* @author sky
* 该类给出各种排序算法
*
*/
public class sort{
private static Integer[] elem(int n){
int N=n;
Random random=new Random();
Integer elem[]=new Integer[N];
for (int i=0;i<N;i++){
elem[i]=random.nextInt(1000);
}
return elem;
}
public static void main (String Args[]) throws InterruptedException{
int n=30000;
Integer elem[]=elem(n);
long start,end;
class sort0 extends Thread{
Integer elem[];
int n;
sort0(Integer elem[],int n){
this.elem=elem;
this.n=n;
}
public void run(){
System.out.println("线程启动");
straightInsertSort(elem,n);
}
}
elem=elem(n);
start=System.currentTimeMillis();
sort0 s1=new sort0(elem,n);
elem=elem(n);
sort0 s2=new sort0(elem,n);
elem=elem(n);
sort0 s3=new sort0(elem,n);
elem=elem(n);
sort0 s4=new sort0(elem,n);
elem=elem(n);
sort0 s5=new sort0(elem,n);
s1.start();
s2.start();
s3.start();
s4.start();
s5.start();
s2.join();
s1.join();
s3.join();
s4.join();
s5.join();
System.out.println("多线程简单插入排序:");
end=System.currentTimeMillis();
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
straightInsertSort(elem,n);
end=System.currentTimeMillis();
System.out.println("简单插入排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
shellSort(elem,n);
end=System.currentTimeMillis();
System.out.println("希尔排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
bubbleSort(elem,n);
end=System.currentTimeMillis();
System.out.println("冒泡排序:");
System.out.println(end-start);
/*
elem=elem(n);
start=System.currentTimeMillis();
quickSort(elem,n);
end=System.currentTimeMillis();
System.out.println("快速排序:");
System.out.println(end-start);*/
elem=elem(n);
start=System.currentTimeMillis();
simpleSelectionSort(elem,n);
end=System.currentTimeMillis();
System.out.println("简单选择排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
heapSort(elem,n);
end=System.currentTimeMillis();
System.out.println("堆排序:");
System.out.println(end-start);
elem=elem(n);
start=System.currentTimeMillis();
mergeSort(elem,n);
end=System.currentTimeMillis();
System.out.println("归并排序:");
System.out.println(end-start);
}
//显示排序结果
public static <T extends Comparable<? super T>> void show(T[] elem,int n){
for (int i=0;i<n;i++){
System.out.print(elem[i]);
System.out.print(' ');
}
System.out.println();
}
//交换元素
private static <T extends Comparable<? super T>> void swap(T[] elem,int i,int j){
T tmp=elem[i];
elem[i]=elem[j];
elem[j]=tmp;
}
//直接插入排序法,复杂度为O(n^2)
public static <T extends Comparable<? super T>> void straightInsertSort (T elem[],int n){
for (int i=1;i<n;i++){
T e=elem[i];
int j;
for (j=i-1;j>=0 && e.compareTo(elem[j])<0;j--){
elem[j+1]=elem[j];
}
elem[j+1]=e;
}
}
//shell插入排序算法,复杂度为O(n^1.5)
private static <T extends Comparable<? super T>> void shellInsertHelp(T elem[],int n,int incr){
for (int i=incr;i<n;i++){
T e=elem[i];
int j=i-incr;
for (;j>=0 && e.compareTo(elem[j])<0;j=j-incr){
elem[j+incr]=elem[j];
}
elem[j+incr]=e;
}
}
public static <T extends Comparable<? super T>> void shellSort(T elem[],int n ){
for (int incr=n/2;incr>0;incr=incr/2){
shellInsertHelp(elem,n,incr);
}
}
//冒泡排序算法,时间复杂度为O(n^2)
public static <T extends Comparable<? super T>> void bubbleSort(T elem[],int n){
for (int i=n-1;i>0;i--){
for (int j=0;j<i;j++){
if (elem[j].compareTo(elem[i])>0){
swap(elem,i,j);
}
}
}
}
//快速排序算法,时间复杂度为O(n*log(n))
private static <T extends Comparable<? super T>> int partition(T elem[],int low,int high){
while (low<high){
for (;elem[high].compareTo(elem[low])>=0 && low<high;high--);
swap(elem,high,low);
for (;elem[high].compareTo(elem[low])>=0 && low<high;low++);
swap(elem,high,low);
}
return low;
}
private static <T extends Comparable<? super T>> void quickSortHelp(T elem[],int low,int high){
if (low<high){
int pivot=partition(elem,low,high);
quickSortHelp(elem,low,pivot-1);
quickSortHelp(elem,pivot+1,high);
}
}
public static <T extends Comparable<? super T>> void quickSort(T elem[],int n){
quickSortHelp(elem,0,n-1);
}
//简单选择排序算法,时间复杂度为O(n^2)
public static <T extends Comparable<? super T>> void simpleSelectionSort(T elem[],int n){
for (int i=0;i<n-1;i++){
int lowIdx=i;
for (int j=i+1;j<n;j++){
if (elem[lowIdx].compareTo(elem[j])>0)
lowIdx=j;
}
swap(elem,lowIdx,i);
}
}
//堆排序,时间复杂度为O(n*log(n))
private static <T extends Comparable<? super T>> void heapAdjust(T elem[],int low,int high){
for (int i=low,lhs=2*i+1 ;lhs<=high;lhs=2*i+1){
if (lhs<high && elem[lhs].compareTo(elem[lhs+1])<0)lhs++;
if (elem[i].compareTo(elem[lhs])<0){
swap(elem,i,lhs);
i=lhs;
}else break;
}
}
public static <T extends Comparable<? super T>> void heapSort(T elem[],int n){
//初始化堆
for (int i=(n-2)/2;i>=0;i--){
heapAdjust(elem,i,n-1);
}
swap(elem,0,n-1);
//排序
for (int i=n-2;i>0;--i){
heapAdjust(elem,0,i);
swap(elem,0,i);
}
}
//归并排序算法,时间复杂度为O(n*log(n))
private static <T extends Comparable<? super T>> void simpleMerge(T elem[],T tmpElem[],int low ,int mid, int high){
int i=low,j=mid+1,k=low;
for (;i<=mid && j<=high;k++){
if (elem[i].compareTo(elem[j])<=0)
tmpElem[k]=elem[i++];
else
tmpElem[k]=elem[j++];
}
for (;i<=mid;i++){
tmpElem[k++]=elem[i];
}
for (;j<=high;j++){
tmpElem[k++]=elem[j];
}
for (;low<=high;low++){
elem[low]=tmpElem[low];
}
}
private static <T extends Comparable<? super T>> void mergeHelp(T elem[],T tmpElem[],int low ,int high){
if (low < high){
int mid=(low+high)/2;
mergeHelp(elem,tmpElem,low,mid);
mergeHelp(elem,tmpElem,mid+1,high);
simpleMerge(elem,tmpElem,low,mid,high);
}
}
public static <T extends Comparable<? super T>> void mergeSort(T elem[],int n){
T[] tmpElem=(T[])new Comparable[n];
mergeHelp(elem,tmpElem,0,n-1);
}
}
--创建用户
CREATE USER "APITEST" PROFILE "DEFAULT"
IDENTIFIED BY "apitest" DEFAULT TABLESPACE "LOUSHANG"
TEMPORARY TABLESPACE "TEMP"
ACCOUNT UNLOCK;
--为用户指定表空间
GRANT UNLIMITED TABLESPACE TO "APITEST";
--为用户授权
GRANT "CONNECT" TO "APITEST";
GRANT "DBA" TO "APITEST";
GRANT "RESOURCE" TO "APITEST";
--将锁定用户解锁
alter user <用户名> account unlock;
--修改用户密码
alter user <用户名> identified by <新密码>;
--删除用户
drop user apitest; ----仅仅是删除用户,
drop user apitest cascade ;----会删除此用户名下的所有表和视图。
---查看当前用户信息
select * from user_users;
---查询当前数据库实例中有哪些用户
select * from dba_users order by username;
---查看当前用户拥有的角色
select * from user_role_privs;
---查看当前用户所拥有的表
select * from user_tables;
---查看当前用户所拥有表的列
select * from USER_TAB_COLUMNS ;
---显示特权用户(一般包括sys、system)
select * from v$pwfile_users;
---查询当前用户所拥有的所有对象(表、视图、索引、存储函数和过程等)
select * from user_objects
----查看序列号
select * from user_sequences;
---查看当前用户所有的视图
select * from user_views;
--查看当前连接信息
select SID,SERIAL#,USERNAME,MACHINE,LOGON_TIME from v$session where username='APITEST';
--断开指定连接
alter system kill session '530,49177';
DAO层的代码分页代码:
public PageModel findByPageModel(String hql,PageModel pm) {
pm.setTotalCount(this.getHibernateTemplate().find(hql).size());
pm.setGoToHref(ServletActionContext.getRequest().getServletPath().replace("/",""));
int totalCount = pm.getTotalCount();
int pageSize = pm.getPageSize();
int totalPage = (totalCount+pageSize-1)/pageSize ;
int currentPage = pm.getCurrentPage() ;
pm.setTotalPage(totalPage);
int offset = (currentPage-1)*pageSize;
pm.setList(this.getSession().createQuery(hql).setFirstResult(offset).setMaxResults(pageSize).list());
return pm;
}
分页的JAVABEAN:
public class PageModel {
private int currentPage;
private int pageSize;
private int totalCount;
private int totalPage;
private List list ;
private String goToHref;
public int getCurrentPage() {
if(currentPage<=0) currentPage=1;
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getPageSize() {
if(pageSize<=0) pageSize=10;
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getTotalCount() {
return totalCount;
}
public void setTotalCount(int totalCount) {
this.totalCount = totalCount;
}
public int getTotalPage() {
return totalPage;
}
public void setTotalPage(int totalPage) {
this.totalPage = totalPage;
}
public List getList() {
return list;
}
public void setList(List list) {
this.list = list;
}
public String getGoToHref() {
return goToHref;
}
public void setGoToHref(String goToHref) {
this.goToHref = goToHref;
}
}
JSP页面:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<link rel="stylesheet" type="text/css" href="<%=basePath %>findByHql/pagingBar/css/pagingBar.css">
<input type="button" class="firstPage commonPage" alt="首页" title="首页"/>
<input type="button" class="beforePage commonPage" alt="上一页" title="上一页"/>
<input type="button" class="nextPage commonPage" alt="下一页" title="下一页"/>
<input type="button" class="lastPage commonPage" alt="尾页" title="尾页" />
<input type="hidden" id="currentPage" value="${requestScope.pm.currentPage }" />
<input type="hidden" id="totalPage" value="${requestScope.pm.totalPage }" />
<input type="hidden" id="goToHref" value="${requestScope.pm.goToHref }" />
<span class="cp">当前第${requestScope.pm.currentPage }页</span>
<span class="tc"> 相关资讯:${requestScope.pm.totalCount }条</span>
<span class="ps">每页${requestScope.pm.pageSize }条 </span>
<span class="tp">共${requestScope.pm.totalPage}页</span>
<script type="text/javascript" src="<%=basePath%>js/jquery.js"></script>
<script type="text/javascript">
(function($) {
var currentPage = parseInt($('#currentPage').val());
var totalPage = parseInt($('#totalPage').val());
var toHref = $('#goToHref').val();
$('.firstPage').bind('click', function() {
goToHref(1);
});
$('.nextPage').bind('click', function() {
if (currentPage >= totalPage)
goToHref(totalPage);
else
goToHref(currentPage + 1);
});
$('.beforePage').bind('click', function() {
if (currentPage <= 1)
goToHref(1);
else
goToHref(currentPage - 1);
});
$('.lastPage').bind('click', function() {
goToHref(totalPage);
});
function goToHref(cp) {
document.location.href = toHref+"?currentPage=" + cp;
}
})(jQuery)
</script>
CSS:下面有几张图片需要自己找...
/*点击栏*/
.commonPage{
width: 16px;
height: 16px;
border: none;
cursor: pointer;
}
.firstPage{
background: url("../images/page-first.png") no-repeat;
}
.nextPage{
background: url("../images/page-next.png") no-repeat;
}
.beforePage{
background: url("../images/page-prev.png") no-repeat;
}
.lastPage{
background: url("../images/page-last.png") no-repeat;
}
/*显示栏*/
.cp,.tc,.ps,.tp{
font-size: 14px;
}
在action中调用DAO层的方法,给currentPage和pageSize设置初始值,然后就返回一个list到你分页的页面迭代,以后就直接嵌套在分页页面中就行