转自
前言:google到一篇关于复合模式的文章,虽然是关于 .NET的,但是对于开发java同样有借鉴意义.
一、模式概述
描述Composite模式的最佳方式莫过于树形图。从抽象类或接口为根节点开始,然后生枝发芽,以形成树枝节点和叶结点。因此,
Composite模式通常用来描述部分与整体之间的关系,而通过根节点对该结构的抽象,使得客户端可以将单元素节点与复合元素节点作为相同的对象来看
待。
由于Composite模式模糊了单元素和复合元素的区别,就使得我们为这些元素提供相关的操作时,可以有一个统一的接口。例如,我们要编写一个字
处理软件,该软件能够处理文字,对文章进行排版、预览、打印等功能。那么,这个工具需要处理的对象,就应该包括单个的文字、以及由文字组成的段落,乃至整
篇文档。这些对象从软件处理的角度来看,对外的接口应该是一致的,例如改变文字的字体,改变文字的位置使其居中或者右对齐,也可以显示对象的内容,或者打
印。而从内部实现来看,我们对段落或者文档进行操作,实质上也是对文字进行操作。从结构来看,段落包含了文字,文档又包含了段落,是一个典型的树形结构。
而其根节点正是我们可以抽象出来暴露在外的统一接口,例如接口IElement:
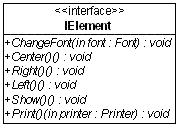
既然文字、段落、文档都具有这些操作,因此它们都可以实现IElement接口:
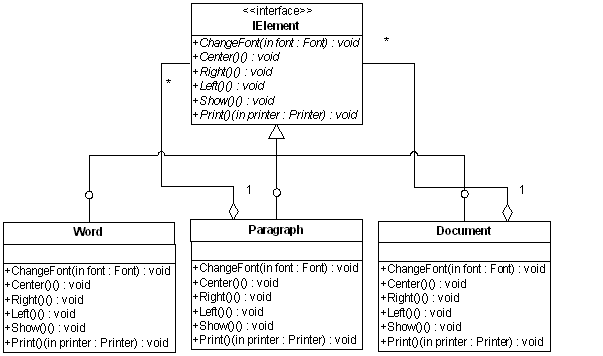
从上图可以看到,对象Word、Paragraph、Document均实现了IElement接口,但Paragraph和Document与
Word对象不同的是,这两者处除了实现了IElement接口,它们还与IElement接口对象之间具有聚合的关系,且是一对多。也就是说
Paragraph与Document对象内可以包含0个到多个IElement对象,这也是与前面对字处理软件分析获得的结果是一致的。
从整个结构来看,完全符合树形结构的各个要素,接口IElement是根节点,而Paragraph和Document类为枝节点,Word对象为
叶节点。既然作为枝节点,它就具有带叶节点的能力,从上图的聚合关系中我们体现出了这一点。也就是说,Paragraph和Document类除了具有排
版、打印方面的职责外,还能够添加、删除叶节点的操作。那么这些操作应该放在哪里呢?
管理对子节点的管理,Composite模式提供了两种方式:一个是透明方式,也就是说在根节点中声明所有用来管理子元素的方法,包括Add()、
Remove()等方法。这样一来,实现根节点接口的子节点同时也具备了管理子元素的能力。这种实现策略,最大的好处就是完全消除了叶节点和枝节点对象在
抽象层次的区别,它们具备完全一致的接口。而缺点则是不够安全。由于叶节点本身不具备管理子元素的能力,因此提供的Add()、Remove()方法在实
现层次是无意义的。但客户端调用时,却看不到这一点,从而导致在运行期间有出错的可能。
另一种策略则是安全方式。与透明方式刚好相反,它只在枝节点对象里声明管理子元素的方法,由于叶节点不具备这些方法,当客户端在操作叶节点时,就不会出现前一种方式的安全错误。然而,这种实现方式,却导致了叶节点和枝节点接口的不完全一致,这给客户端操作时带来了不便。
这两种方式各有优缺点,我们在实现时,应根据具体的情况,作出更加合理的抉择。在字处理软件一例中,我选择了安全方式来实现,因为对于客户端而言,
在调用IElement接口时,通常是将其视为可被排版、打印等操作的对象。至于为Paragraph和Document对象添加、删除子对象,往往是一
种初始化的行为,完全可以放到一个单独的模块中。根据单一职责原则(SRP),我们没有必要让IElement接口负累太重。所以,我们需要对上图作稍许
的修改,在Paragraph和Document对象中增加Add()和Remove()方法:
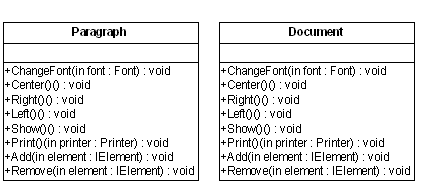
以下是IElement对象结构的实现代码:
public interface IElement
{
void ChangeFont(Font font);
void Show();
//其他方法略;
}
public class Word
{
public void ChangeFont(Font font)
{
this.font = font;
}
public void Show()
{
Console.WriteLine(this.ToString());
}
//其他方法略;
}
public class Paragraph
{
private ArrayList elements = new ArrayList();
public void Add(IElement element)
{
elements.Add(element);
}
public void Remove(IElement element)
{
elements.Remove(element);
}
public void ChangeFont(Font font)
{
foreach (IElement element in elements)
{
element.ChangeFont(font);
}
}
public void Show()
{
foreach (IElement element in elements)
{
element.Show(font);
}
}
//其他方法略;
}
//Document类略;
实际上,我们在为叶节点实现Add(),Remove()方法时,还需要考虑一些异常情况。例如在Paragraph类中,添加的子元素就不能是
Document对象和Paragraph对象。所以在添加IElement对象时,还需要做一些条件判断,以确定添加行为是否正确,如果错误,应抛出异
常。
采用Composite模式,我们将Word、Paragraph、Document抽象为IElement接口。虽然各自内部的实现并不相同,枝
节点和叶节点的实质也不一样,但对于调用者而言,是没有区别的。例如在类WordProcessor中,包含一个GetSelectedElement
()静态方法,它能够获得当前选择的对象:
public class WordProcessor
{
public static IElement GetSelectedElement(){……}
}
对于字处理软件的UI来说,如果要改变选中对象的字体,则可以在命令按钮cmdChangeFont的Click事件中写下如下代码:
public void cmdChangeFont_Click(object sender, EventArgs e)
{
WordProcessor.GetSelectedElement().ChangeFont(currentFont);
}
不管当前选中的对象是文字、段落还是整篇文档,对于UI而言,操作都是完全一致的,根本不需要去判断对象的类别。因此,如果在Business
Layer的类库设计时,采用Composite模式,将极大地简化UI表示层的开发工作。此外,应用该模式也较好的支持项目的可扩展性。例如,我们为
IElement接口增加了Sentence类,对于前面的例子而言,只需要修改GetSelectedElement()方法,而
cmdChangeFont命令按钮的Click事件以及Business
Layer类库原有的设计,都不需要做任何改变。这也符合OO的开放-封闭原则(OCP),即对于扩展是开放的(Open for
extension),对于更改则是封闭的(Closed for modification)。
二、.Net Framework中的Composite模式
在.Net中,最能体现Composite模式的莫过于Windows或Web的控件。在这些控件中,有的包含子控件,有的则不包含且不能包含子控
件,这正好符合叶节点和枝节点的含义。所有Web控件的基类为System.Web.UI.Contril类(如果是Windows控件,则基类为
System.Windows.Forms.Control类)。其子类包含有HtmlControl、HtmlContainerControl等。按
照Composite模式的结构,枝节点和叶节点属于根节点的不同分支,同时枝节点与根节点之间应具备一个聚合关系,可以通过Add()、Remove
()方法添加和移除其子节点。设定HtmlControl为叶节点,而HtmlContaiinerControl为枝节点,那么采用透明方式的设计方
法,在.Net中控件类的结构,就应该如下图所示:
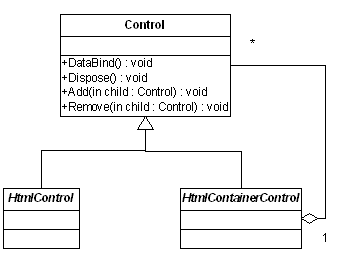
虽然根据透明方式的Composite模式,HtmlControl类与其父类Control之间也应具备一个聚合关系,但实质上该类并不具备管理
子控件的职责,因此我在类图中忽略了这个关系。此时,HtmlControl类中的Add()、Remove()方法,应该为空,或者抛出一个客户端能够
捕获的异常。
然而,从具体实现来考虑,由于HtmlControl类和HtmlContainerControl类在实现细节层次,区别仅在于前者不支持子控
件,但从控件本身的功能来看,很多行为是相同或者相近的。例如HtmlControl类的Render()方法,调用了方法RenderBeginTag
()方法:
protected override void Render(HtmlTextWriter writer)
{
this.RenderBeginTag(writer);
}
protected virtual void RenderBeginTag(HtmlTextWriter writer)
{
writer.WriteBeginTag(this.TagName);
this.RenderAttributes(writer);
writer.Write(’>');
}
而HtmlContainerControl类也具有Render()方法,在这个方法中也调用了RenderBeginTag()方法,且RenderBeginTag方法的实现和前者完全一致:
protected override void Render(HtmlTextWriter writer)
{
this.RenderBeginTag(writer);
this.RenderChildren(writer);
this.RenderEndTag(writer);
}
按照上面的结构,由于HtmlControl和HtmlContainerControl之间并无继承关系,这就要求两个类中,都要重复实现
RenderBeginTag()方法,从而导致产生重复代码。根据OO的特点,解决的办法,就是让HtmlContainerControl继承自
HtmlControl类(因为HtmlContainerControl的接口比HtmlControl宽,所以只能令
HtmlContainerControl作为子类),并让RenderBeginTag()方法成为HtmlControl类的protected方
法,子类HtmlContainerControl可以直接调用这个方法。然而与之矛盾的是,HtmlContainerControl却是一个可以包含
子控件的枝节点,而HtmlControl则是不能包含子控件的叶节点,那么这样的继承关系还成立吗?
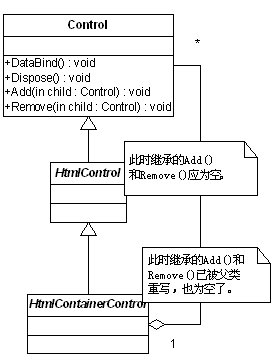
HtmlControl类对Add()方法和Remove()方法的重写后,这两个方法内容为空。由于HtmlContainerControl类
继承HtmlControl类,但我们又要求它的Add()和Remove()方法和Control类保持一致,而父类HtmlControl已经重写这
两个方法,此时是无法直接继承来自父类的方法的。以上是采用透明方式的设计。
如果采用安全方式,仍然有问题。虽然在HtmlControl类中不再有Add()和Remove()方法,但由于Control类和
HtmlContainerControl类都允许添加子控件,它们包含的Add()、Remove()方法,只能分别实现。这样的设计必然会导致重复代
码。这也是与我们的期望不符的。
那么在.Net中,Control类究竟是怎样实现的呢?下面,我将根据.Net实现Control控件的源代码,来分析Control控件的真实结构,以及其具体的实现细节。
三、深入分析.Net中的Composite模式
首先,我们来剖析Web控件的基类Control类的内部实现:
public class Control : IComponent, IDisposable, IParserAccessor, IDataBindingsAccessor
{
// Events;略
// Methods
public Control()
{
if (this is INamingContainer)
{
this.flags[0×80] = true;
}
}
public virtual bool HasControls()
{
if (this._controls != null)
{
return (this._controls.Count > 0);
}
return false;
}
public virtual void DataBind()
{
this.OnDataBinding(EventArgs.Empty);
if (this._controls != null)
{
string text1 = this._controls.SetCollectionReadOnly(”Parent_collections_readonly”);
int num1 = this._controls.Count;
for (int num2 = 0; num2 < num1; num2++)
{
this._controls[num2].DataBind();
}
this._controls.SetCollectionReadOnly(text1);
}
}
protected virtual void Render(HtmlTextWriter writer)
{
this.RenderChildren(writer);
}
protected virtual ControlCollection CreateControlCollection()
{
return new ControlCollection(this);
}
// Properties
public virtual ControlCollection Controls
{
get
{
if (this._controls == null)
{
this._controls = this.CreateControlCollection();
}
return this._controls;
}
}
// Fields
private ControlCollection _controls;
}
Control基类中的属性和方法很多,为清晰起见,我只保留了几个与模式有关的关键方法与属性。在上述的源代码中,我们需要注意几点:
1、Control类不是抽象类,而是具体类。这是因为在设计时,我们可能会创建Control类型的实例。根据这一点来看,这并不符合OOP的要
求。一般而言,作为抽象出来的基类,必须定义为接口或抽象类。不过在实际的设计中,也不应拘泥于这些条条框框,而应审时度势,根据实际的情况来抉择最佳的
设计方案。
2、公共属性Controls为ControlCollection类型,且该属性为virtual属性。也就是说,这个属性可以被它的子类
override。同时,该属性为只读属性,在其get访问器中,调用了方法CreateControlCollection();这个方法为
protected虚方法,默认的实现是返回一个ControlCollection实例。
3、方法HasControls(),功能为判断Control对象是否有子控件。它判断的依据是根据私有字段_controls(即公共属性
Controls)的Count值。但是需要注意的是,通过HasControls()方法的返回值,并不能决定对象本身属于叶节点,还是枝节点。因为即
使是枝节点其内部仍然可以不包含任何子对象。
4、
方法DataBind()的实现中,首先调用了自身的OnDataBinding()方法,然后又遍历了Controls中的所有控件,并调用其
DataBind()方法。该方法属于控件的共有行为,从这里可以看出不管是作为叶节点的控件,还是作为枝节点的控件,它们都实现统一的接口。对于客户端
调用而言,枝节点和叶节点是没有区别的。
5、 Control类的完整源代码中,并不存在Add()、Remove()等类似的方法,以提供添加和移除子控件的功能。事实上,继承Control类的所有子类均不存在Add()、Remove()等方法。
显然,在Control类的定义和实现中,值得我们重视的是公共属性Controls的类型ControlCollection。顾名思义,该类必
然是一个集合类型。是否有关子控件的操作,都是在ControlCollection类型中实现呢?我们来分析一下ControlCollection的
代码:
public class ControlCollection : ICollection, IEnumerable
{
// Methods
public ControlCollection(Control owner)
{
this._readOnlyErrorMsg = null;
if (owner == null)
{
throw new ArgumentNullException("owner");
}
this._owner = owner;
}
public virtual void Add(Control child)
{
if (child == null)
{
throw new ArgumentNullException("child");
}
if (this._readOnlyErrorMsg != null)
{
throw new HttpException(HttpRuntime.FormatResourceString(this._readOnlyErrorMsg));
}
if (this._controls == null)
{
this._controls = new Control[5];
}
else if (this._size >= this._controls.Length)
{
Control[] controlArray1 = new Control[this._controls.Length * 4];
Array.Copy(this._controls, controlArray1, this._controls.Length);
this._controls = controlArray1;
}
int num1 = this._size;
this._controls[num1] = child;
this._size++;
this._version++;
this._owner.AddedControl(child, num1);
}
public virtual void Remove(Control value)
{
int num1 = this.IndexOf(value);
if (num1 >= 0)
{
this.RemoveAt(num1);
}
}
// Indexer
public virtual Control this[int index]
{
get
{
if ((index < 0) || (index >= this._size))
{
throw new ArgumentOutOfRangeException(”index”);
}
return this._controls[index];
}
}
// Properties
public int Count
{
get
{
return this._size;
}
}
protected Control Owner
{
get
{
return this._owner;
}
}
protected Control Owner { get; }
// Fields
private Control[] _controls;
private const int _defaultCapacity = 5;
private const int _growthFactor = 4;
private Control _owner;
}
一目了然,正是ControlCollection的Add()、Remove()方法完成了对子控件的添加和删除。例如:
Control parent = new Control();
Control child = new Child();
//添加子控件child;
parent.Controls.Add(child);
//移除子控件child;
parent.Controls.Remove(child);
为什么要专门提供ControlCollection类型来管理控件的子控件呢?首先,作为类库使用者,自然希望各种类型的控件具有统一的接口,尤
其是自定义控件的时候,不希望自己重复定义管理子控件的操作;那么采用透明方式自然是最佳方案。然而,在使用控件的时候,安全也是需要重点考虑的,如果不
考虑子控件管理的合法性,一旦使用错误,会导致整个应用程序出现致命错误。从这样的角度考虑,似乎又应采用安全方式。这里就存在一个抉择。故而,.Net
在实现Control类库时,利用了职责分离的原则,将控件对象管理子控件的属性与行为和控件本身分离,并交由单独的ControlCollection
类负责。同时采用聚合而非继承的方式,以一个公共属性Controls,存在于Control类中。这种方式,集保留了透明方式和安全方式的优势,又摒弃
了这两种方式固有的缺陷,因此我名其为“复合方式”。
“复合方式”的设计,其对安全的保障,不仅仅是去除了Control类关于子控件管理的统一接口,同时还通过异常管理的方式,在ControlCollection类的子类中实现:
public class EmptyControlCollection : ControlCollection
{
// Methods
public EmptyControlCollection(Control owner) : base(owner)
{}
public override void Add(Control child)
{
this.ThrowNotSupportedException();
}
private void ThrowNotSupportedException()
{
throw new
HttpException(HttpRuntime.FormatResourceString(”Control_does_not_allow_children”,
base.Owner.GetType().ToString()));
}
}
EmptyControlCollection继承了ControlCollection类,并重写了Add()等添加子控件的方法,使其抛出一个
异常。注意,它并没有重写父类的Remove()方法,这是因为ControlCollection类在实现Remove()方法时,对集合内的数据进行
了非空判断。而在EmptyControlCollection类中,是不可能添加子控件的,直接调用父类的Remove()方法,是不会出现错误的。
既然管理子控件的职责由ControlCollection类型负责,且Control类中的公共属性Controls即为
ControlCollection类型。所以,对于控件而言,如果是树形结构中的叶节点,它不能包含子控件,它的Controls属性就应为
EmptyControlCollection类型,假如用户调用了Controls的Add()方法,就会抛出异常。如果控件是树形结构中的枝节点,它
支持子控件,那么Controls属性就是ControlCollection类型。究竟是枝节点还是叶节点,决定权在于公共属性Controls:
public virtual ControlCollection Controls
{
get
{
if (this._controls == null)
{
this._controls = this.CreateControlCollection();
}
return this._controls;
}
}
在属性的get访问器中,调用了protected方法CreateControlCollection(),它创建并返回了一个ControlCollection实例:
protected virtual ControlCollection CreateControlCollection()
{
return new ControlCollection(this);
}
很明显,在Control基类实现Controls属性时,采用了Template Method模式,它推迟了ControlCollection的创建,将决定权交给了CreateControlCollection()方法。
如果我们需要定义一个控件,要求它不能管理子控件,就重写CreateControlCollection()方法,返回EmptyControlCollection对象:
protected override ControlCollection CreateControlCollection()
{
return new EmptyControlCollection(this);
}
现在再回过头来看HtmlControl和HtmlContainerControl类。根据前面的分析,我们要求
HtmlContainerControl继承HtmlControl类,同时,HtmlContainerControl应为枝节点,能够管理子控件;
HtmlControl则为叶节点,不支持子控件。通过引入ControlCollection类和其子类
EmptyControlCollection,以及Template Method模式后,这些类之间的关系与结构如下所示:
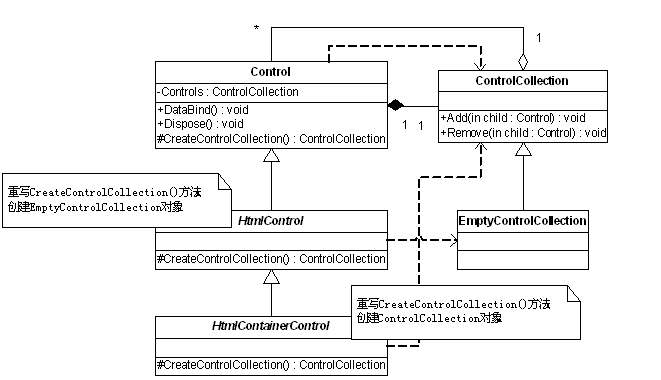
HtmlContainerControl继承了HtmlControl类,这两个类都重写了自己父类的protected方法
CreateControlCollection()。HtmlControl类,该方法返回EmptyControlCollection对象,使其成
为了不包含子控件的叶节点;HtmlContainerControl类中,该方法则返回ControlCollection对象,从而被赋予了管理子控
件的能力,成为了枝节点:
public abstract class HtmlControl : Control, IAttributeAccessor
{
// Methods
protected override ControlCollection CreateControlCollection()
{
return new EmptyControlCollection(this);
}
}
public abstract class HtmlContainerControl : HtmlControl
{
// Methods
protected override ControlCollection CreateControlCollection()
{
return new ControlCollection(this);
}
}
HtmlControl和HtmlContainerControl类均为抽象类。要定义它们的子类,如果不重写其父类的
CreateControlCollection()方法,那么它们的Controls属性,就与父类完全一致。例如HtmlImage控件继承自
HtmlControl类,该控件不能添加子控件;而HtmlForm控件则继承自HtmlContainerControl类,显然,HtmlForm
控件是支持添加子控件的操作的。
.Net的控件设计采用Composite模式的“复合方式”,较好地将控件的透明性与安全性结合起来,它的特点是:
1、在统一接口中消除了Add()、Remove()等子控件的管理方法,而由ControlCollection类实现,同时通过EmptyControlCollection类保障了控件进一步的安全;
2、控件能否管理子控件,不由继承的层次决定;而是通过重写CreateControlCollection()方法,由Controls属性的真正类型来决定。
如此一来,要定义自己的控件就更加容易。我们可以任意地扩展自己的控件类。不管继承自Control,还是HtmlControl或
HtmlContainerControl,都可以轻松地定义出具有枝节点或叶节点属性的新控件。如果有新的需求要求改变管理子控件的方式,我们还可以定
义继承自ControlCollection的类,并在控件类的方法CreateControlCollection()中创建并返回它的实例。