进程的创建
进程本身是一个动态的实体,所以它本身在运行期间也通过创建进程系统调用,并且可以创建多个新进程,对于这句话我同样使用图解的方式来做个简单说明:
当一个进程创建一个新进程时,会存在两种可能的方式执行:
1. 父进程(继续执行)和子进程并行的执行;
2. 父进程等待部分或者全部子进程终止执行;
而新进程的地址空间也存在两种可能:
1. 子进程是父进程的一个COPY了;
2. 载入一个程序来运行;
到这里就有点感觉Erlang的进程思想端倪了(开始我咋看感觉有点象,但是越深入后就觉得确实就是到这个思想才形成了Erlang程序语言的意义本质,个人揣度啊,哈哈)既然有那么点思想的感觉,那我们就开始进入探讨阶段了。也正是下面即将要讲到的问题才印证一句话:技术的本质还存留在简单事物之上(个人总结,哈哈)。
进程间通信
进程间通信有两种本质的方式:
1. 共享缓冲区提供通信;
2. 消息传递;
大家有没有认真看到上面的四个字“消息传递”,对没错就是消息传递!那这里我就感觉是否就是这里和Erlang的语言所谈到的消息传递呢?尽管一个处于操作系统级别,而另一处于语言级别,但是初看给我的感觉是原理是否一致呢?呵呵,那就让我们来看看OS级别的进程间通信本质起了。
消息传递系统
消息系统的功能是允许进程与其他进程之间通讯不必借助共享数据,他们各自独立。而这里要说到一个概念,什么是IPC?
如果我们先不看它定义,而了解具体做法,看是一个什么效果。
到这里为止是不是感觉又和我们说的Erlang非常类似呢?真的没错。。。那就继续往下看看它到底如何而做了。有以下几种方法实现和Send/Receive操作的方法:
u 直接或者间接通信
u 对称或不对称通信
u 自动或手动缓冲
u 发送copy或者引用
u 定长消息或者变长消息
为了更好的说明上面各自的特征是如何引入和体现的,使用两个典型的进程p,q作为两个进程之间的通讯来加以演示。
直接通信:
这里就是两个非常赤裸的而且是非常利索的通信了:
u send(P,message) P发送一个消息给进程Q;
u receive(Q,message) 从进程Q中接收一个消息
特点:
1. 每对需要通信的进程之间自动建立一条链路,进程只需要知道彼此的进程标识符(Pid);
2. 一个连接就只连接到这两个进程;
因此这种机制在寻址上是对称的;发送者与接收者进程都必须要指明通信一方。不过这里要谈到它的一种特例:发送者需要知道接收者,但是接收者不需要知道发送者,其原语定义为:
Send(P,Message) 发送一个消息给P;
Receive(id,Message)从任意进程中接受一个消息;
由于通信是一种交互行为,所以一般情况来说我们有发送自然希望存在一个回复的交互动作,而像这种特例就无法知道它的这种情形,因此这种情况也是我们不希望所见的。
间接通信
间接通信中消息发送和接收则是通过邮箱(实际中更多的是端口方式,这里为了更好理解我们比作邮箱方式)进行的。若把邮箱看成一个对象,进程就可以把消息邮寄(放置)在其中,显而易见既然能够放入自然也就可以从邮箱中取出了。而每一个邮箱都有一个唯一的地址(标识符),进程可以通过不同的邮箱和其它进程通信了。两个进程只有共享一个邮箱才可以进程通信。因此基本构建和原语定义图示如下:
Send(A,M):发送消息(Message)给邮箱A;
Receive(A,M):从邮箱A接收到消息(M);
特点:
1. 只有在两个进程间有一个共享邮件箱下才能两者建立一个连接;
2. 一条链路可以连接两个或者更多的进程;
3. 每对通信进程之间可以同时存在多个不同的链路,而且每条链路对应一个邮箱;
那我们来看看直接通信和间接通信最大的区别是什么?没错,其实间接通信存在中间一个共享的邮箱,而正是这种方式才在以后的应用中得到广泛利用。这里就联想到Erlang语法的:Pid!M是否感觉很相似(注:M消息通知标示符为Pid的进程操作事件,而且具体在接受中也存在得到一个receive来获取消化了),在我看来它就是典型使用到了这个原理机制。这里来看一道例题:假如有两个进程P1,P2和P3都存在共享邮箱A,而且P2与P3正是从A中接收。那么谁 接收到P1发送来的消息呢?图示:
这里我们就需要具体讨论问题的实质了:
对照上面说讲到的间接通信特点,我们知道一条链路最多连接两个进程,同时最多允许任意选择进程来接收消息(现在这个例子中只存在P2,P3),所以他们两者只允许单独接收消息而不是同时接收消息。至于消息会发送给谁,这就需要系统本身来确定接收者了。因此,一个邮箱可能为一个进程或者操作系统所有,不难看出这个例子存在以下情况:
一旦拥有邮箱
A的
进程终止时,邮箱也就同时要消失,随后向该邮箱发送消息的进程就会被告知邮箱不存在。这里需要强调的是作为操作系统本身来说拥有一个邮箱是独立的不依赖于任何进程。所以操作系统有必要提供一种机制允许一个进程来专门做这个工作了,那是什么工作呢?具体有以下特征:
u 创建一个新邮箱;
u 通过这个邮箱发送和接收信息;
u 删除一个邮箱;
接下来就开始单独讨论所谓的这个“邮箱”的单独机制能够引发的一些线索了。
进程同步
通过消息传送来进程通信,这个是它本质所在。但是消息传送可能有阻塞或者无阻塞——同步和异步。所以这里就存在对于发送者和接收者的阻塞或无阻塞现象的讨论了,对于他们有一下特点:
1. 发送进程阻塞:发送进程被阻塞,直到接收进程接收消息;
2. 发送进程无阻塞:发送进程发送消息并且立刻恢复执行;
3. 接收进程阻塞:接收进程被阻塞,知道一个消息为有效;
4. 接收进程无阻塞:接收进程获取一个有效或空消息;
以上的方式还可以组合形成。
既然有阻塞和无阻塞现象,那立刻可以联想到我们的邮箱扩展成一种管道方式呢?没错这里就需要讲解下面的定义形成。
缓冲
这里只想对于三个定义了解:
u 零长度:无缓冲消息系统;
u 限定长度:
自动缓冲
u 无限长度:
这里单独把限定长度和无限长度提取出来定义:
限定长度:消息队列中存在N个消息,发送者在发送未满的队列中无阻塞。一旦队列满则阻塞直到出现空闲空间。
无线长度:消息队列有无限个消息,也不会阻塞发送者。
下面我们就要通过这些概念扩展到程序开发中经常会遇到的实例。
(待续。。。。。。)
posted @
2008-12-14 12:42 叶澍成 阅读(1256) |
评论 (0) |
编辑 收藏在学习Erlang程序过程中,总觉得对于进程还是没有很好的把握。所以自己对于进程的再次提及让我不得不重温操作系统这门看似抽象的课程了。但是总觉得如果单一讲解进程或许略显抽象不够理解,自己就想把某些经验和知识片段有个很好的系统联系起来,我想这样可以让自己更好加强记忆理解。长话短说,我们进入主题,既然在Erlang的学习中始终围绕着进程一词来深入研究,我们就从进程这个话题谈起。
进程概念
1. 进程是运行中的程序。这里我们就可以稍微延伸下以便帮助我们记忆理解了:
在这里我们只要抓住“运动”词汇,就不然发现进程是个动态的实体,与之对应的是我们常说的程序,程序而是一个静态实体了。(bw:这里突然想到以前对于认识EJB2中也有一个对应的概念就是EntityBean与SessionBean,它们与之对应的就是一个典型的名词和动词概念了,哈哈啰嗦了,转回正题)。那我们会想是什么来体现我们说的进程为一个动态实体呢?立刻会联系产生接下来的一个特点了。
2. 进程不仅仅是程序代码,它包含了当前状态。而这种状态由两个方面来表示:
u 程序计数器(program counter)
u cpu中的寄存器(registers)
就是由于进程中有程序计数器—指明下一条要执行的指令而且拥有一组相关的资源。这里又要继续反问:到底是一个什么资源呢?那就要看下面会讲到的PCB的概念了。
3. 进程还包含进程栈(process stack)。
例如:方法参数(method parameters);返回地址与本地变量等
4. 两个进程可能会关联到同样的程序,刚才我们说到了所谓程序是一个静态实体。顾名思义就是两个进程允许使用同样的代码段,只是在参数不同而已。但是仍然认为这两个进程是独立执行的序列。例如:几个用户可能会同事运行主程序的不同拷贝一样。
进程状态
注:上面就是一个完整的进程状态图了。这里没有必要多说什么了,图表给了我们一个轮廓。
进程控制块(PCB)
这里就是我们要讲到的进程控制块了,对于操作系统都是需要通过PCB来表示进程的。有些资料上也称作为:任务控制块。对于PCB的整体描述我们还是以图表的方式来说明(这也是本人最喜欢也觉得最直观的一种理解方式了):
|
Pointer(指针)
|
Process state(进程状态)
|
|
Process number(进程序列号)
|
|
Program counter(程序计数器)
|
|
Register(寄存器)
|
|
Memory limits(主存中受限说明)
|
|
List of open files
|
|
。。。(这里其实还有很多,就不再一一列举了)
|
PCB描述图
既然是操作系统都需要通过进程控制块来调用进程过程,那我们在这里举例说明下如果有两个进程结合PCB是如何在CPU之中切换使用进程的。为了更加清晰了解它们的过程,还是老规矩使用一个图表来展示两个进程分别为P1,P2怎么运行的。
(这个图在自己的笔记本上已经用笔画出来了,可就是找不到一个好的工具,暂时放置在这,待续画图了)
进程调度
由于我们目前接触的其实多半都是以分时系统为主的,其目标也是为了在进程之间频繁转换cpu以便由于用户与运行的程序来交互。
1. 进程进入系统后,都被放在队列中了,我们称这个队列为:作业队列(也有些书上不是这么称呼的),所有的进程都在这个其中。
2. 处于就绪进程都被保留在一个列表中——就绪列表
3. 一旦进程获得了CPU并且执行,就可能发生一下某个事件存在:
u 进程可能发出一个I/O请求,然后被放置在I/O队列中;
u 进程也可能创建一个新的子进程并且等待它终止;
u 有时候发生一个中断,导致进程强行从CPU里移除并返回就绪队列;
调度程序
这里需要了解两个主要的概念:
1. 长程调度(操作系统调度程序):从一个池中选择进程并其载入内存中。
注:咋看不是很了解,可能这里需要了解虚拟存储过程对于这个概念就比较好理解。这里大致说明下。由于过去我们所使用的内存(主存储器)空间非常有限,在抢占的进程志愿中如果都想放入内存中显然是不够科学,而对于我们的后备动力辅助存储器——磁盘(这里我们说是硬盘,当然也有3.5英寸的小磁盘了,呵呵)来说,就可以充分考虑到使用它来做个过度动态的存储器。所以这样一来我们就不需要把一个进程中所有的信息都装载到内存中,而是在需要是再来考虑换入;而与之相反的就是不需要时就换出了(bw:这里的换入/换出如果比较频繁也就证明我们的内耗比较严重,一般称作这个叫:抖动现象。大家有时候感兴趣的可以观察我们主机的硬盘灯如果在频繁的闪动就表示资源在不断换入换出了,呵呵)。而这也就是虚拟存储的一个本质过程,当然中间需要通过逻辑转换表来过度,在这里我们就不再具体复述了。有兴趣的可以去看看相关OS方面的书籍。
2. 近程调度(CPU调度程序):从这些进程中选择就绪进程并为其某个分配CPU
注:说白了这里就是我们的cpu直接通过缓冲通道来调用就绪的程序进入运行。
上下文转换
前面我们也谈到了进程是在CPU中来回切换运行的,既然是一种来回切换运行那势必需要让CPU知道我们切换到下一个状态执行的地址或者说切入点在哪了。这个就是为什么需要一个程序计数器的功效了。那我们把这种来回切换状态,同时需要保存当前运行进程状态信息给记录下来以便下一次能够定位到的方式称作是——上下文转换。
就上面的这样一次转换表述在一定程度上需要耗的硬件资源非常大(这里又要我强调下,更多的信息需要你还了解一些计算机组成体系结构了。希望有时间自己也总结一篇关于一个简单程序在体系中运行过程)。因此上下文转换在很大程度上就取决于硬件的支持了。
接下来要讲到的应该是最核心的也是对以后我们无论是写程序好还是学习一门新语言好,都需要很好理解的部分了。在这里也尽可能表述清楚。
(待续......)
posted @
2008-12-14 00:25 叶澍成 阅读(1463) |
评论 (0) |
编辑 收藏云计算应该所具备的特质如下:
1. 高负载
2. 正常运转
3. 容错性
4. 分布式
5. 容易伸缩
Erlang(读音:['ə:læŋ]厄兰,中文意思为:占线小时(话务负载单位))正是由于它属于开放的电信业务平台,也就不难理解它的意义了。几乎完全具备以上特质,而且它也是典型的函数式语言。和我们OOP的思想有着截然不同的概念。在以下的学习过程中主要还是以《Erlang程序设计》这本书作为一个学习的依据。
原子
定义:在Erlang中原子用来表示不同的非数字常量值。这里说白了其实就是一种常量的定义。Erlang中原子是全局有效的,不需要像以前c/c++那样通过宏来定义或者包含文件。在定义原子的时候只需要注意以下一些特点就可以:
1. 一般情况原子是以一串以小写字母开头,后面有数字、字母、下划线、邮件符号(@);
2. 使用单引号引用起来的字符也属于原子,例如’Monday’;
3. 一个原子的值就是原子本身;
元组(tuple)
定义:首先它是Erlang中具有特质的一个定义,如果说把它和我们java中的一个JavaBean来类比可能稍显类似,书上引用的是c语言数据结构来解说元组的结构,尽管非强浅显能看懂。但是作为一个java程序员我觉得采用自己熟悉的语言结构来对比,学习效果更佳吧(对于记忆有很大帮助)。
比如我们一般对于JavaBean的定义是如下结构:
public class Person {
private String name;
private int height;
private int footSize;
private String eyeColor;
// get/set...
}
那在我们引用定义的时候就可以直接:
Person person1=new Person();
person1.setName("yeshucheng");
person1.setHeight(111);
person1.setFootSize(40);
person1.setEyeColor("black");
......
与之相对应的是我们使用Erlang来定义了,对于Erlang的定义就截然和c/c++或者java有着明显不同,相对于更加精炼明了:(这里我直接使用书上说的所谓二元组)
Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
没错,就是这么直截了当的来定义,甚至赋值(严格说Erlang不能这么说,但是为了好记忆可以这么理解)
对于以上的定义这里要说明注意的地方:
1. 定义元组,元组中字段没有名字,通常可以使用一个原子作为元组的第一元素来标明(请注意这里花括号内第一原子都是解释逗号后面一个说明),这个元组所能代表的含义就是上面列出的程序定义了。
2. 创建元组,在声明元组的同时其实已经创建了元组,这个也是Erlang的一大特点之一了。如果不再使用,也随之销毁。Erlang使用的垃圾搜集器去收回没有使用的内存。
如:F={firstName,wan}
L={lastName,andy}
P={person,F,L}//这里就应对我们第一条说明的一样第一个名称表示就是后面所有逗号的整体列举,如果在Erlang环境中对于上面写完后,直接敲回车(语句结束后存在”.”这里稍微注意下)就会得到以下结果,正好印证我们所说明这这个问题了
==》{persong,{firstName,wan},{lastName,andy}}.
如果在创建过程中存在一个未定义的变量,则程序编译就会产生错误。
3. 提取元组的字段值,刚才我们在程序中有定义一个Person的元组而且也设置值了,现在如果我们想得到或者说提取我们的值,那需要如何而做呢?首先我们采用基本的元组方式来试着看看如下:
1> Point={point,10,45}.
2> {point,X,Y}=Point.
3> X.
10
4> Y.
45
注明:这里又再次强调下point逗号后面的都是为他而说明的。
1>Person={person,{name,yeshucheng},{height,111},{footsize,40},{eyecolor,black}}.
2>{_,{_,Who},{_,_},{_,_},{_,_}}=Person.
3>Who.
yeshucheng
说明下,如果上面想得到的是值,那么位置响应对号入座然后Who换成What就成(我开始也犯错误,编译立马出错,后来想想用过一个What试试,果然正确,呵呵)。
列表
定义:列表第一个元素称为列表的头(head),后部分称为列表尾(tail),一般[H|T]来标示列表了。
注:列表的头可以是任何东西,但是列表的尾通常还是一个列表。
至于具体的细节问题还是需要找找相关文档看下为好,它的概念牵涉到后面的非常多的定义了。
posted @
2008-12-09 10:20 叶澍成 阅读(1046) |
评论 (0) |
编辑 收藏边缘技术人员,这里是个人的一个定义阐述而已,所有的售前售后咨询师、维护人员、培训讲师等都包含在这个头衔中。咋看感觉自己对这个头衔有失偏颇的定论,其实不然我对这个行业的人员还是挺敬佩的。为什么这么说呢?因为他们当中多数是在和我们的客户一线打交道,客户的喜怒哀乐,喜形于色都能第一时间映入他们的脑海,他们需要学会最大的程度“承受”,即使受到某种轻视或者诋毁的状态都需要忍受,同时还要很快的去更好处理当时的尴尬场景。某种程度来说他们类似一些公司业务跑单人员,但是他们有更多的技术背景同时这里面也有很多的牛人。这类人员所具备的素养更加强调人性的一面,也正是由于接触不同社会个阶层人员的广泛,相对于那些整天坐在办公室电脑前敲代码的程序员来说是截然不同的天地。程序员的思维缜密这个都是毋庸置疑的,但是也正是这种思维方式让他们容易陷入规则死板的世界,甚至有些人员会钻牛角尖(你可别不承认哦?或许就是你自己了,哈哈)而对于这里的边缘技术人员来说如果遇到同样的一件事情很有可能他处理的方式会有很大不同,他的某种圆滑处理问题的方式或许就是你需要学习的。而作为公司的老板们也是最多和这类人员交涉的,因为他们了解公司的整体的宗旨方案,也了解客户的需求,他们的老练思维往往会让老板更加乐于倾听。这也不难想象为什么这类人员有时候拿钱或许比你做孺子牛的自己来说更多的缘故了,更加受到器重让你有嫉妒之嫌。你可曾想过如果老板让你去做,自己又能否胜任呢?呵呵。
说到这里可能大家会觉得我讲的似乎在说一名老练的销售业务人员吗?没错,如果你想做一个高端的边缘技术人员(说到这自己都感觉有点不大确切了,呵呵)上面谈到的那种圆滑是你必修课程,但是有这些个人认为还远远不够!为什么这么说呢?在我看来,过去一些年确实很多做销售的人员比做纯技术的人员赚钱多这个也是不争的事实。在未来如果你想在这个职位闯荡,需要的素养再也不是靠过去的“牛皮嘴”了更多的是需要一个务实的干练大气者。你需要知道在什么场合说话到位的分寸;你需要知道如何行云流水般的写一份好材料;你需要有细心的观察和不失吝啬的豪迈口才;更甚你还不能缺少酒桌文化。。。。。。所有的这些或许你不具备,每个人都不是天生赋予有这些能力,但是你只要还年轻懂得如何去“学”就是你最大的资本。当然这些前提都是需要你性格已经具备它的潜质所在,不然劝你另择道路或许也是你的一片天地呢?
写到这回过头看看,仿佛这个并不是自己的所谓“总结”了,连我自己都觉得自己都在天马行空,哈哈。因为我们听过太多的领导的年终评述,八股文的段落着实让自己不想再陈词滥调一番“在这辞旧迎新的新春,借着党的春风我们回顾过去,展望未来在接下来的09年。。。”
既然09年马上要到来,我也简述下吧,俗是俗了点但是形式上还是要走一下的,呵呵。对于个人发展来说,09年自己还是想有个新的环境。人老在一个地方呆容易把自己给“停滞”成为惯性的“懒惰”。尽管自己有很多想法,但是有想法确实是不够的,需要着实的执行一番。在09年开始有空就写blog了,做看官N年之久。把自己的一些心得体会写出来。若干年之后自己回头看看或许是一种美妙的回忆呢?呵呵。在09年继续巩固自己的技术基石,同时也开始学习一门新语言:Erlang。在它的迈进同时还是不忘JAVA给我带来无穷乐资。最后就是希望上天多给我一些机会,我时刻准备着,哈哈。相信自己一定行!
(唧唧歪歪这么多写到这算都结束了!不知所云,哈哈)
PS:“有想法是不够的,执行力度还很差”---崔,我非常谢谢有你这个朋友,你的直率和指点让我知道太多的无知,也让我知道人的奋斗目标是什么;尽管有时候你喜欢给我吃“棒棒糖”,内心甜滋滋的,但正是你的这些语言从某些侧面刺激了我的思维,很是感谢你!真的。我希望我们09年我们都共勉。
08年总结评述(一)
08年总结评述(二)
08年总结评述(三)
posted @
2008-12-08 01:48 叶澍成 阅读(1630) |
评论 (1) |
编辑 收藏而至于架构师这里只是作为个人对这个头衔认定,或许以下对此评述有点片面或者主观看法。首先我承认我更多的是倾向于它,同时也是我努力的目标(呵呵,或许自己离这个还有很大一段差距),当然我也相信很多朋友都有这个向往,但正是它的淡定、从容务实让我内心的佩服。很多朋友都认为国内没有真正的所谓架构师一说,相对于国外的那些牛牛们简直就是小儿科。这点我首先承认确实目前中国整体大环境不是很好,所以在某些层面上社会的浮躁气息都会把很多有才华的程序员特别是那些有架构师的气质的朋友毫无顾忌的抹杀掉。但是如果你静心坐下来想想,如果你无法改变这个环境何不更加务实的换位思考从自身做起呢?多问问自己:我是否已经具备架构师的特质呢?如果能这么想,那很好说明自己在某些问题首先能够有淡定的决策感。
首先架构师在我看来需要有“存储”非常庞大的知识面能力,他可以涉猎非常多技术层次;视野也需要够广阔;对于新生技术敏锐的感知度;甚至在技术的角度来说他还是一个狂热者;在某个特定领域是一个行家(这里我并没有说是专家,因为在我看来专家是一个非常有压力的词汇。呵呵)。所以这个也就印证一些朋友说的:首先你要有知识的广博,一旦水到渠成后自然能够从纷乱繁杂的技术中脱颖而出,认知到自己更加对什么感兴趣,什么领域才是自己未来的方向。也就不存在很多朋友经常会问一些老鸟一样的疑问:我该学习什么呢?我该如何学?我适合什么呢?。。。所有的这些看似初哥的问题在架构师的他根本就不存在疑问,因为他自己非常清晰自己下面的路是如何而走。而更多的是务实贴近他去更快更准确的把握问题的所在。计算机的语言对他来说已经是一种超脱思维,他更注重事物的本质所在。语言对架构师来说就是一种工具,而他要选择的如何更加高效利用好工具。当然架构师也不是神,他也会有很多缺陷。例如在某些基础知识的欠缺,但是他知道如何回头去补充他的弱点,而且他也知道自己的欠缺是什么,他也需要别人去揭示他的不足。没有关系,只要他还是个普通人不是神,他也就有不断的长足进步可能。这些看上去觉得都挺虚幻,而且感觉自己比较难靠近甚至是觉得难以触及。但是我觉得如果你连试的勇气都没有,何来谈及这个词汇价值呢?呵呵,上面说的这些可能对于我们来说非常浅显的道理,但是都觉得这样的人离我们比较遥远(或许你也可能否认这个问题)。在这里我也就个人的角度来看到这个对于我来说都是“神”一样的职位。这里没有多谈该如何的步骤成为一个理想的架构师,因为每个人的情况境遇不尽相同。但是对于你自己心中的他,我觉得还是需要有定位的。其实对于要想达到这样一种也不是太远及,只要你从现在做起,相信我们都能。
(待续……)
08年总结评述(一)
08年总结评述(二)
08年总结评述(四)
posted @
2008-12-06 11:29 叶澍成 阅读(1914) |
评论 (1) |
编辑 收藏 对于这一年中自己更加清晰自己想要的是什么,也对技术的定位有着稍许自己的见解。特别是对于我们这些程序员来说,大家谈到最多的还是自己未来的归宿问题。每个人的性格不同对于事情的看法也就自然不一样,但是个人认为无论你如何去寻求别人帮助来看清自己属于哪种性格,更适合什么方向,这个还是有难度的。他人的意见更多的是参考,最后决定还是你自己。更多的认知度决定了一种水到渠成的站点。
程序员最终的归宿在我看来无非就是三大类:项目经理,架构师,边缘技术人员(这当中包括了:售前售后咨询师、维护人员、培训讲师)。当然这个概括或许是不准确的,这里只是谈到我自己一种认定方式而已。
先来谈谈项目经理,尽管在我接触的这些年同行中挂在嘴边最多的还是这个头衔,但是大家对于这个职业的定位还是不够清晰或许每个人心中的项目经理的层次不同。也印证了一句:一百个人看哈姆雷特就有一百个不一样的哈姆雷特,呵呵。但是在这个行业中大家不得不承认,每个人的水平和对于知识层次的不一样也造就了这种现象,而且这种现象也是正常的。这里列举几个典型对于项目经理描述的观点:
u 项目经理的职责就是需要把现实中的事件通过你的沟通传输与技术人员来沟通翻译,最终利用有效的资源来高效组合达到客户预期的目标。
u 项目经理的职责就是需要对行业定位够劲道,非常熟悉行业的业务流程。技术已经不在是你的讲究的资本,如何高效协调组员来完成任务才是本职工作,和客户沟通好也是最大的责任。
u 项目经理的职责就是需要对业务数据结构够清晰,业务流程够明白。
上面只是列举比较常见的观点(期间做了些修饰,但是大体意思基本是一样的)其实它们的观点理论上来说本质是一样的,但是在个人看来扣住几个关键词:沟通、协调、行业业务、组织能力。能够把它们更加“和谐”的共处发挥到权衡的量度上还是需要一定功力和技巧的。这个职业是需要经验的累计,他的每次决策行径都是要靠前一次或者说以前的经验体会来推进的。在这之前强调更多的还是人性世界的主题,但是这里我发觉很多的程序员在这个职业的论道上缺少或者说尽可能的避免谈论:技术知识面的掌控。很多人会说:你一旦做技术到了4,5年再不在项目经理上,那你就废了。这种说法咋看都诧异,但是现实截然不同在我接触的人当中有太多人是这种意识。开始我也觉得他们这种认知度是对的,但是随着时间上的推移我慢慢发觉有这种思路的人多少带点惰性思维。为什么这么说?很多人都认为程序员在第三年,第五年都是一个坎或者说遇到所谓的瓶颈。而这些人把这些话一推出后,更多的是喜欢和有类似的人员通过近似的思维碰撞找到一个内心的平衡点,继而思维的“散发”也就慢慢蔓延开。他们就感觉:哦,原来我的想法还是对的原来不止我一个人有这样的观点。。。我不在这说有这种想法的人观点是否正确,但是接下来我要谈到的架构师多数的思维还是有不一样的境界。可以肯定的是如果人云亦云,那只能说明你的惰性在潜意识一直在做块遮羞布,“瓶颈”的效应能否让你可曾联想想到我们的CPU为什么要找突破口,如果你确实能够坦白这个现实。那说明真正的项目经理才是一种质的升华。(待续……)
08年总结评述(一)
08年总结评述(三)
08年总结评述(四)
posted @
2008-12-05 09:43 叶澍成 阅读(1845) |
评论 (6) |
编辑 收藏
昨天无意间被朋友问道:你今年的收获是什么?自己才意识到原来不平凡的08年就要过去了,大到国家小到周围朋友在这一年都有不同的变迁。这一年国家经历了前所未有的艰难之路,大雪灾、地震、北京奥运、金融海啸这些都让每个中国人或多或少的经历着不同的感受,最起码你是这当中的一个看似微小的组成原子也感同身受。看着朋友、同学个个都相继组建家庭,步入幸福的婚姻殿堂。每每参加一次为他们祝福的同时也是怜惜自己的尴尬处境,呵呵。这或许就是一个人随年龄的变化而不同的思维情绪了。这里就是一种我自认的缘分未到吧。
而这一年对于自己的表象变化不大,工作依然,情绪依旧。但是内心对于事物的认知度觉得有明显的不一样。对事情的看法更加的务实也更加的切合实际。人一生中可能会让自己永远无法忘记几个时间点,以前我真的不相信。但是自己着实的经历过才真切的能够感受到,08年3月4日,这天让我对事物的看法层面有着截然扭转。也是这天对我对今后的技术认知度有着全然不同看法。尽管当天我没有步入自己梦寐以求的技术殿堂,但是我确实很感谢当时的几位同仁(PS:这里让我记忆犹新的就是那位当时给我当头一棒的女同胞,经历过这么多交谈应该说什么样的对手都碰到过,但是能让我真正“汗”颜的就只有她了)给了我一种视野的开阔,也让我知道浮躁的背面就是坚实的基底,所以非常庆幸这天能给我一个来的稍显晚点的忠告。也正是这天让我真正梳理清晰我需要的是什么;我的方向是什么;我的不足是什么;我的目标是什么。这些所有的roadmap非常清晰在脑海里展现。那一刻让我更加鄙视自己的无知,也让自己知道:机会一定是留给一个时刻有准备的人。
至此那天之后我清楚的认识到我的不足也让我有向往的一种超越精神。自己的清晰定位让我阅读大量的技术书籍。一旦没有特别的应酬都只会闷在家中读书,把以前大学“存储”高阁的书本全部捡拾温习(PS:记得在一个QQ群中聊天时候当时有位朋友说,你这么做成本代价会很高,当时说实在的真没有悟到这个话的内涵,或许自己愚钝的缘故。但是我相信晚意识比没有意识要强)。在这种阅读的过程中,真正让我了解了互联网的水有多“深”,需要了解它需要非常夯实的基底。当然在阅读书籍时,我更多的是带着问题去寻找答案,所以也就自然感觉越到后面越觉得自己的认知度很渺小。因为一个知识点会牵动到其它问题的入口,自己便马上停下来找寻涉及到这个问题的入口寻找答案。。。。。。慢慢就知道自己了解的还是在一个圆内,自己不知道的圆都在这之外,自己也在不断的把所知道的这个圆慢慢的画大。
(待续……)
08年总结评述(二)
08年总结评述(三)
08年总结评述(四)
posted @
2008-12-03 10:02 叶澍成 阅读(1040) |
评论 (2) |
编辑 收藏了解HashMap原理对于日后的缓存机制多少有些认识。在网络中也有很多方面的帖子,但是很多都是轻描淡写,很少有把握的比较准确的信息,在这里试着不妨说解一二。
对于HashMap主要以键值(key-value)的方式来体现,笼统的说就是采用key值的哈希算法来,外加取余最终获取索引,而这个索引可以认定是一种地址,既而把相应的value存储在地址指向内容中。这样说或许比较概念化,也可能复述不够清楚,来看列式更加清晰:
int hash=key.hashCode();//------------------------1
int index=hash%table.lenth;//table表示当前对象的长度-----------------------2
其实最终就是这两个式子决定了值得存储位置。但是以上两个表达式还有欠缺。为什么这么说?例如在key.hashCode()后可能存在是一个负整数,你会问:是啊,那这个时候怎么办呢?所以在这里就需要进一步加强改造式子2了,修改后的:
int index=(hash&Ox7FFFFFFF)%table.lenth;
到这里又迷惑了,为什么上面是这样的呢?对于先前我们谈到在hash有可能产生负数的情况,这里我们使用当前的hash做一个“与”操作,在这里需要和int最大的值相“与”。这样的话就可以保证数据的统一性,把有符号的数值给“与”掉。而一般这里我们把二进制的数值转换成16进制的就变成了:Ox7FFFFFFF。(注:与操作的方式为,不同为0,相同为1)。而对于hashCode()的方法一般有:
public int hashCode(){
int hash=0,offset,len=count;
char[] var=value;
for(int i=0;i<len;i++){
h=31*hash+var[offset++];
}
return hash;
}
说道这里大家可能会说,到这里算完事了吧。但是你可曾想到如果数据都采用上面的方式,最终得到的可能index会相同怎么办呢?如果你想到的话,那恭喜你!又增进一步了,这里就是要说到一个名词:冲突率。是的就是前面说道的一旦index有相同怎么办?数据又该如何存放呢,而且这个在数据量非常庞大的时候这个基率更大。这里按照算法需要明确的一点:每个键(key)被散列分布到任何一个数组索引的可能性相同,而且不取决于其它键分布的位置。这句话怎么理解呢?从概率论的角度,也就是说如果key的个数达到一个极限,每个key分布的机率都是均等的。更进一步就是:即便key1不等于key2也还是可能key1.hashCode()=key2.hashCode()。
对于早期的解决冲突的方法有折叠法(folding),例如我们在做系统的时候有时候会采用部门编号附加到某个单据标号后,这里比如产生一个9~11位的编码。通过对半折叠做。
现在的策略有:
1. 键式散列
2. 开放地址法
在了解这两个策略前,我们先定义清楚几个名词解释:
threshold[阀值],对象大小的边界值;
loadFactor[加载因子]=n/m ;其中n代表对象元素个数,m表示当前表的容积最大值
threshold=(int)table.length*loadFactor
清晰了这几个定义,我们再来看具体的解决方式
键式散列:
我们直接看一个实例,这样就更加清晰它的工作方式,从而避免文字定义。我们这里还是来举一个图书编号的例子,下面比如有这样一些编号:
78938-0000
45678-0001
72678-0002
24678-0001
16678-0001
98678-0003
85678-0002
45232-0004
步骤:
1. 把编号作为key,即:int hash=key.hashCode();
2. int index=hash%表大小;
3. 逐步按顺序插入对象中
现在问题出现了:对于编号通过散列算法后很可能产生相同的索引值,意味着存在冲突。

解释上面的操作:如果对于key.hashCode()产生了冲突(比如途中对于插入24678-0001对于通过哈希算法后可能产生的index或许也是501),既而把相应的前驱有相同的index的对象指向当前引用。这也就是大家认定的单链表方式。以此类推…
而这里存在冲突对象的元素放在Entry对象中,Entry具有以下一些属性:
int hash;
Object key;
Entry next;
对于Entry对象就可以直接追溯到链表数据结构体中查阅。
开放地址法:
1. 线性地址探测法:
如何理解这个概念呢,一句话:就是通过算法规则在对象地址N+1中查阅找到为NULL的索引内容。
处理方式:如果index索引与当前的index有冲突,即把当前的索引index+1。如果在index+1已经存在占位现象(index+1的内容不为NULL)试图接着index+2执行。。。直到找到索引为内容为NULL的为止。这种处理方式也叫:线性地址探测法(offset-of-1)
如果采用线性地址探测法会带来一个效率的不良影响。现在我们来分析这种方式会带来哪些不良因素。大家试想下如果一个非常庞大的数据存储在Map中,假如在某些记录集中有一些数据非常相似(他们产生的索引在内存的某个块中非常的密集),也就是说他们产生的索引地址是一个连续数值,而造成数据成块现象。另一个致命的问题就是在数据删除后,如果再次查询可能无法定到下一个连续数字,这个又是一个什么概念呢?例如以下图片就很好的说明开发地址散列如何把数据按照算法插入到对象中:
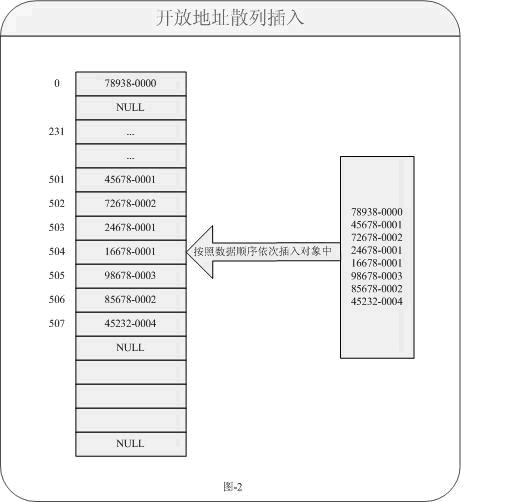
对于上图的注释步骤说明:
从数据“78938-0000”开始通过哈希算法按顺序依次插入到对象中,例如78938-0000通过换
算得到索引为0,当前所指内容为NULL所以直接插入;45678-0001同样通过换算得到索引为地址501所指内容,当前内容为NULL所以也可以插入;72678-0002得到索引502所指内容,当前内容为NULL也可以插入;请注意当24678-0001得到索引也为501,当前地址所指内容为45678-0001。即表示当前数据存在冲突,则直接对地址501+1=502所指向内容为72678-0002不为NULL也不允许插入,再次对索引502+1=503所指内容为NULL允许插入。。。依次类推只要对于索引存在冲突现象,则逐次下移位知道索引地址所指为NULL;如果索引不冲突则还是按照算法放入内容。对于这样的对象是一种插入方式,接下来就是我们的删除(remove)方法了。按照常理对于删除,方式基本区别不大。但是现在问题又出现了,如果删除的某个数据是一个存在冲突索引的内容,带来后续的问题又会接踵而来。那是什么问题呢?我们还是同样来看看图示的描述,对于图-2中如果删除(remove)数据24678-0001的方法如下图所示:
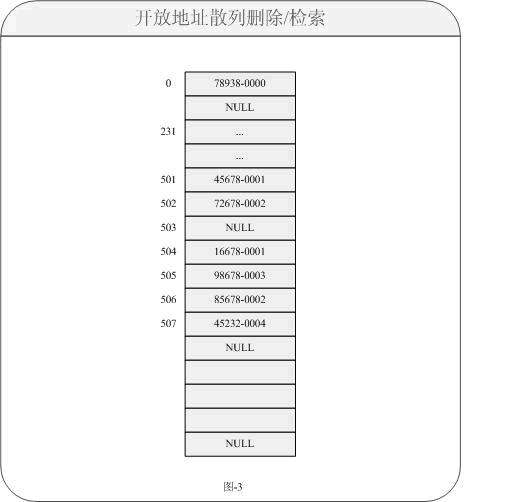
对于我们会想当然的觉得只要把指向数据置为NULL就可以,这样的做法对于删除来说当然是没有问题的。如果再次定位检索数据16678-0001不会成功,因为这个时候以前的链路已经堵上了,但是需要检索的数据事实上又存在。那我们如何来解决这个问题呢?对于JDK中的Entry类中的方法存在一个:boolean markedForRemoval;它就是一个典型的删除标志位,对于对象中如果需要删除时,我们只是对于它做一个“软删除”即置一个标志位为true就可以。而插入时,默认状态为false就可以。这样的话就变成以下图所示:
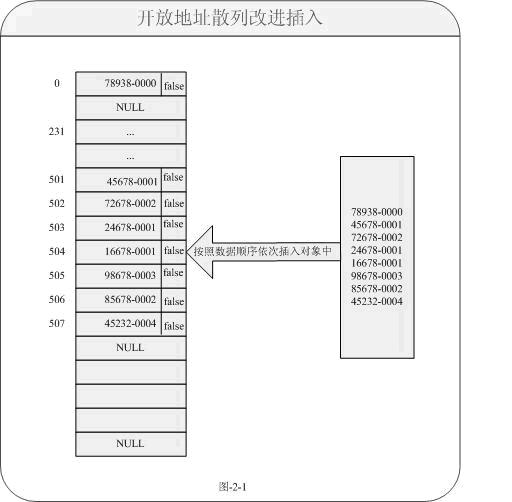
通过以上方式更好的解决冲突地址删除数据无法检索其他链路数据问题了。
2. 双散列(余商法)
在了解开放地址散列的时候我们一直在说解决方法,但是大家都知道一个数据结构的完善更多的是需要高效的算法。这当中我们却没有涉及到。接下来我们就来看看在开放地址散列中它存在的一些不足以及如何改善这样的方法,既而达到无论是在方法的解决上还是在算法的复杂度上更加达到高效的方案。
在图2-1中类似这样一些数据插入进对象,存在冲突采用不断移位加一的方式,直到找到不为NULL内容的索引地址。也正是由于这样一种可能加大了时间上的变慢。大家是否注意到像图这样一些数据目前呈现出一种连续索引的插入,而且是一种成块是的数据。如果数据量非常的庞大,或许这种可能性更大。尽管它解决了冲突,但是对于数据检索的时间度来说,我们是不敢想象的。所有分布到同一个索引index上的key保持相同的路径:index,index+1,index+2…依此类推。更加糟糕的是索引键值的检索需要从索引开始查找。正是这样的原因,对于线性探索法我们需要更进一步的改进。而刚才所描述这种成块出现的数据也就定义成:簇。而这样一种现象称之为:主簇现象。
(主簇:就是冲突处理允许簇加速增长时出现的现象)而开放式地址冲突也是允许主簇现象产生的。那我们如何来避免这种主簇现象呢?这个方式就是我们要来说明的:双散列解决冲突法了。主要的方式为:
u int hash=key.hasCode();
u int index=(hash&Ox7FFFFFFF)%table.length;
u 按照以上方式得到索引存在冲突,则开始对当前索引移位,而移位方式为:
offset=(hash&Ox7FFFFFFF)/table.length;
u 如果第一次移位还存在同样的冲突,则继续:当前冲突索引位置(索引号+余数)%表.length
u 如果存在的余数恰好是表的倍数,则作偏移位置为一下移,依此类推
这样双散列冲突处理就避免了主簇现象。至于HashSet的原理基本和它是一致的,这里不再复述。在这里其实还是主要说了一些简单的解决方式,而且都是在一些具体参数满足条件下的说明,像一旦数据超过初始值该需要rehash,加载因子一旦大于1.0是何种情况等等。还有很多问题都可以值得我们更加进一步讨论的,比如:在java.util.HashMap中的加载因子为什么会是0.75,而它默认的初始大小为什么又是16等等这些问题都还值得说明。要说明这些问题可能又需要更加详尽的说明清楚。
posted @
2008-09-15 21:53 叶澍成 阅读(3816) |
评论 (6) |
编辑 收藏前几天和电信下属分公司的部门负责人聊天有感,这个无意就让我自问一些问题:
1.需求分析人员的职责应该是什么
2.架构师的职责是什么
3.需求分析人员是否能等同于架构师
4.如果不是,那他们是一种粘合关系
5.如果是,是一个什么承接关系
而从这个部门负责人聊天感觉他的思路就是:先要有需求分析,才能有架构设计;没有好的需求分析,再好的架构设计都等于垃圾
不过从他的理解程度,显然他对架构和框架混为一谈。
posted @
2008-08-23 18:32 叶澍成 阅读(292) |
评论 (1) |
编辑 收藏