Apache Shiro 架构
ApacheShiro的设计目标是使程序的安全变得简单直观而易于实现,shiro的核心设计参照大多数用户对安全的思考模式--如何对某人(或某事)在与程序交互的环境中的进行安全控制。
程序设计通常都以用户为基础,换句话说,你经常以用户可以(或者应该)如何与软件交互为基础来设计用户接口或者服务API,例如,你可能说,“如果当前与我程序交互的用户已经登录了,我将展示一个按钮给他,他可以点击去查看自己的账户住处,如果他们没有登录,我将显示一个注册按钮。”
这个陈述例子指出我们开发程序很大程度上是为了满足用户的需求,即使“用户(User)”是另外一个软件系统而并非一个人,你仍然要写代码对当前与你软件交互的谁(或者什么)的动作进行回应。
shiro从它的设计中表现了这种理念,为了与软件开发者的直觉相配合,Apache Shiro在几乎所有程序中保留了直观和易用的特性。
概览
在概念层,shiro架构包含三个主要的理念:Subject,SecurityManager和Realm。下面的图展示了这些组件如何相互作用,我们将在下面依次对其进行描述。

subject:就像我们在上一章示例中提到的那样,subject本质上是当前运行用户特定的'view',而单词“user”经常暗指一个人,subject可以是一个人,但也可以是第三方服务、守护进程帐户、时钟守护任务或者其它--当前和软件交互的任何事件。
subject实例都和(也需要)一个SecurityManager绑定,当你和一个subject进行交互,这些交互动作被转换成SecurityManager下subject特定的交互动作。
SecurityManager:SecurityManager是Shiro架构的核心,配合内部安全组件共同组成安全伞。然而,一旦一个程序配置好了SecurityManager和它的内部对象,SecurityManager通常独自留下来,程序开发人员几乎花费的所有时间都集中在Subjet API上。
我们将在以后详细讨论SecurityManager,但当你和一个Subject互动时了解它是很重要的。任何Subject的安全操作中SecurityManager是幕后真正的举重者,这在上面的图表中可以反映出来。
Realms:Reamls是Shiro和你的程序安全数据之间的“桥”或者“连接”,它用来实际和安全相关的数据如用户执行身份认证(登录)的帐号和授权(访问控制)进行交互,shiro从一个或多个程序配置的Realm中查找这些东西。
Realm本质上是一个特定的安全DAO:它封装与数据源连接的细节,得到shiro所需的相关的数据。在配置shiro的时候,你必须指定至少一个Realm来实现认证(authentication)和/或授权(authorization)。SecurityManager可以配置多个复杂的Realm,但是至少有一个是需要的。
Shiro提供out-of-the-box Realms来连接安全数据源(或叫地址)如LDAP、JDBC、文件配置如INI和属性文件等,如果已有的Realm不能满足你的需求你也可以开发自己的Realm实现。
和其它内部组件一样,ShiroSecurityManager管理如何使用Realms获取Subject实例所代表的安全和身份信息。
详细架构
下面的图表展示了Shiro的核心架构思想,下面有简单的解释。
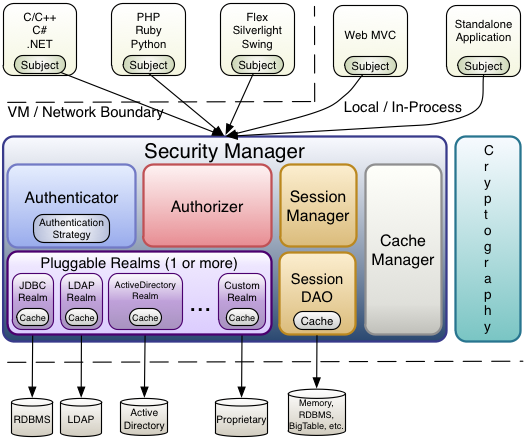
Subject (org.apache.shiro.subject.Subject)
正在与软件交互的一个特定的实体“view”(用户、第三方服务、时钟守护任务等)。
SecurityManager(org.apache.shiro.mgt.SecurityManager)
如同上面提到的,SecurityManager 是Shiro的核心,它基本上就是一把“伞”用来协调它管理的组件使之平稳地一起工作,它也管理着Shiro中每一个程序用户的视图,所以它知道每个用户如何执行安全操作。
Authenticator(org.apache.shiro.authc.Authenticator)
Authenticator是一个组件,负责执行和反馈用户的认证(登录),如果一个用户尝试登录,Authenticator就开始执行。Authenticator知道如何协调一个或多个保存有相关用户/帐号信息的Realm,从这些Realm中获取这些数据来验证用户的身份以确保用户确实是其表述的那个人。
Authentication Strategy(org.apache.shiro.authc.pam.AuthenticationStrategy)
如果配置了多个Realm,AuthenticationStrategy将会协调Realm确定在一个身份验证成功或失败的条件(例如,如果在一个方面验证成功了但其他失败了,这次尝试是成功的吗?是不是需要所有方面的验证都成功?还是只需要第一个?)
Authorizer(org.apache.shiro.authz.Authorizer)
Authorizer是负责程序中用户访问控制的组件,它是最终判断一个用户是否允许做某件事的途径,像Authenticator一样,Authorizer也知道如何通过协调多种后台数据源来访问角色和权限信息,Authorizer利用这些信息来准确判断一个用户是否可以执行给定的动作。
SessionManager(org.apache.shiro.session.mgt.SessionManager)
SessionManager知道如何创建并管理用户Session生命周期而在所有环境中为用户提供一个强有力的Session体验。这在安全框架领域是独一无二--Shiro具备管理在任何环境下管理用户Session的能力,即使没有Web/Servlet或者EJB容器。默认情况下,Shiro将使用现有的session(如Servlet Container),但如果环境中没有,比如在一个独立的程序或非web环境中,它将使用它自己建立的session提供相同的作用,sessionDAO用来使用任何数据源使session持久化。
SessionDAO(org.apache.shiro.session.mgt.eis.SessionDAO)
SessionDAO代表SessionManager执行Session持久(CRUD)动作,它允许任何存储的数据挂接到session管理基础上。
CacheManager(org.apache.shiro.cache.CacheManager)
CacheManager创建并管理其它shiro组件的catch实例生命周期,因为shiro要访问许多后端数据源来实现认证、授权和session管理,caching已经成为提升性能的一流的框架特征,任何一个现在开源的和/或企业级的caching产品都可以插入到shiro中实现一个快速而有效的用户体验。
Cryptography (org.apache.shiro.crypto.*)
Cryptography在安全框架中是一个自然的附加产物,shiro的crypto包包含了易用且易懂的加密方式,Hashes(亦即digests)和不同的编码实现。该包里所有的类都亦于理解和使用,曾经用过Java自身的加密支持的人都知道那是一个具有挑战性的工作,而shiro的加密API简化了java复杂的工作方式,将加密变得易用。
Realms (org.apache.shiro.realm.Realm)
如同上面提到的,Realm是shiro和你的应用程序安全数据之间的“桥”或“连接”,当实际要与安全相关的数据进行交互如用户执行身份认证(登录)和授权验证(访问控制)时,shiro从程序配置的一个或多个Realm中查找这些数据,你需要配置多少个Realm便可配置多少个Realm(通常一个数据源一个),shiro将会在认证和授权中协调它们。
SecurityManager
因为shiro API鼓励以Subject为中心的开发方式,大部分开发人员将很少会和SecurityManager直接交互(尽管框架开发人员也许发现它非常有用),尽管如此,知道SecurityManager如何工作,特别是当在一个程序中进行配置的时候,是非常重要的。
设计
如前所述,程序中SecurityManager执行操作并且管理所有程序用户的状态,在shiro基础的SecurityManager实现中,包含以下内容:
认证(Authentication)
授权(Authorization)
会话管理(Session Management)
缓存管理(Cache Management)
Realm协调(Realm coordination)
事件传导(Event propagation )
"RememberMe" 服务("Remember Me" Services)
建立Subject(Subject creation)
退出登录(Logout)
及其它。
但这些功能都在一个单独的组件中管理,并且,当所有功能集中在一个类中实现是灵活和可定制是非常困难的。
为了实现配置的简单、灵活、可插拔,shiro在设计时实现了高模块化--尽管模块化,SecurityManager(包括它的继承类)并没有做到,相反地,SecurityManager实现更像一个轻量级的‘容器(container)’,代表几乎所有嵌套/封装组件的行为,这种‘封装(wrapper)’设计在上面的架构图表中已有反映。
当组件执行逻辑的时候,SecurityManager知道如何以及何时去协调组件做出正确的动作。
SecurityManager和JavaBean兼容,这允许你(或者配置途径)通过标准的JavaBean访问/设置方法(get*/set*)很容易地定制插件,这意味着shiro模块可以根据用户行为转化成简易的配置。
简易的配置
因为适合JavaBean,任何支持Javabean配置的组件都有非常简单的途径配置SecurityManager,如Spring、Guice、JBoss,等等。
我们将在下一节讨论配置(Configuration )
为文档加把手
我们希望这篇文档可以帮助你使用Apache Shiro进行工作,社区一直在不断地完善和扩展文档,如果你希望帮助shiro项目,请在你认为需要的地方考虑更正、扩展或添加文档,你提供的任何点滴帮助都将扩充社区并且提升Shiro。
提供你的文档的最简单的途径是将它发送到用户论坛(http://shiro-user.582556.n2.nabble.com/)或邮件列表(http://shiro.apache.org/mailing-lists.html)
原文地址:http://shiro.apache.org/architecture.html