|
|
本文转自 http://trinea.iteye.com/blog/1196400
1、jps的作用 jps类似linux的ps命令,不同的是ps是用来显示进程,而jps只显示java进程,准确的说是当前用户已启动的部分java进程信息,信息包括进程号和简短的进程command。 2、某个java进程已经启动,用jps却显示不了该进程进程号 这个问题已经碰到过两次了,所以在这里总结下。 现象: 用ps -ef|grep java能看到启动的java进程,但是用jps查看却不存在该进程的id。待会儿解释过之后就能知道在该情况下,jconsole、jvisualvm可能无法监控该进程,其他java自带工具也可能无法使用 分析: java程序启动后,默认(请注意是默认)会在/tmp/hsperfdata_userName目录下以该进程的id为文件名新建文件,并在该文件中存储jvm运行的相关信息,其中的userName为当前的用户名,/tmp/hsperfdata_userName目录会存放该用户所有已经启动的java进程信息。对于windows机器/tmp用Windows存放临时文件目录代替。 而jps、jconsole、jvisualvm等工具的数据来源就是这个文件(/tmp/hsperfdata_userName/pid)。所以当该文件不存在或是无法读取时就会出现jps无法查看该进程号,jconsole无法监控等问题 原因: (1)、磁盘读写、目录权限问题 若该用户没有权限写/tmp目录或是磁盘已满,则无法创建/tmp/hsperfdata_userName/pid文件。或该文件已经生成,但用户没有读权限 (2)、临时文件丢失,被删除或是定期清理 对于linux机器,一般都会存在定时任务对临时文件夹进行清理,导致/tmp目录被清空。这也是我第一次碰到该现象的原因 这个导致的现象可能会是这样,用jconsole监控进程,发现在某一时段后进程仍然存在,但是却没有监控信息了。 (3)、java进程信息文件存储地址被设置,不在/tmp目录下 上面我们在介绍时说默认会在/tmp/hsperfdata_userName目录保存进程信息,但由于以上1、2所述原因,可能导致该文件无法生成或是丢失,所以java启动时提供了参数,可以对这个文件的位置进行设置,而jps、jconsole都只会从/tmp目录读取,而无法从设置后的目录读物信息, 这个问题只会在jdk 6u23和6u24上出现,在6u23和6u24上,进程信息会保存在-Djava.io.tmpdir下, 因此如果它被设置为非/tmp目录则会导致 jps,jconsole等无法读取的现象, 但在其他版本的jdk上,即使设置-Djava.io.tmpdir为非/tmp, 也会在/tmp/hsperfdata_userName下保存java进程信息.因此可以说这是6u23和6u24的bug,
以下是jdk对该bug的描述地址:
bug描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7021676
bug的修复描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7009828
bug修改代码:
http://hg.openjdk.java.net/jdk7/hotspot/hotspot/rev/34d64ad817f4
关于设置该文件位置的参数为-Djava.io.tmpdir
1. 根据上一章配好的集群,现为Myhost1配置backupNode和SecondaryNamenode, 由于机器有限,这里就不为Myhost2配置backupNode和SecondaryNamenode,但是方法相同. 2. 我们选定Myhost4为SecondaryNamenode, Myhost5为backupNode. 配置并启动SecondaryNamenode: 1. 配置:为Myhost1的 hdfs-site.xml 加入如下配置,指定SecondaryNamenode. <property>
<name>dfs.namenode.secondary.http-address</name>
<value> Myhost4:9001</value>
</property> 2. Myhost4的hdfs-site.xml 加入如下配置,指定nn的url和本地的checkpoint.dir. <property>
<name>dfs.federation.nameservice.id</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/yuling.sh/checkpoint-data</value>
</property> 3. 启动SecondaryNamenode. 在Myhost1上运行命令:sbin/star-dfs.sh或者在Myhost4上运行sbin/hadoop-daemo.sh start SecondaryNamenode 即可以启动SecondaryNamenode. 可以通过log或者网页Myhost4:50090查看其状态. 另外在checkpoint.dir下会有元数据信息. 配置并启动backupNode: 1. 配置Myhost5的hdfs-site.xml, 加入如下配置信息: <property>
<name>dfs.namenode.backup.address</name>
<value> Myhost5:9002</value>
</property>
<property>
<name>dfs.namenode.backup.http-address</name>
<value> Myhost5:9003</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/ backup-data</value>
</property> 2. 启动backupNode, 在Myhost5上运行bin/hdfs namenode –backup & 3. 在dfs.namenode.name.dir下查看元数据信息.
下一篇博客将讲述如何搭建hadoop 0.23 的mapreduce
使用hadoop-0.23 搭建hdfs, namenode + datanode 1. HDFS-1052引入了多namenode, HDFS架构变化较大, 可以参考hortonworks的文章: http://hortonworks.com/an-introduction-to-hdfs-federation/. 我将在接下来的博客里把此文章翻译一下(另外还有: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/). 所有namenode共享datanode, 各个namenode相互独立, 互不影响, 每个namenode都有一个backupNode和SecondaryNamenode,提供主备切换功能和备份元数据的功能. 下文的配置信息主要参考HDFS-2471. 2. 环境: a) 五台机器 ,linux系统, b) 互相添加ssh-key,后应该可以不用密码互连 c) 编译好的0.23版本的包: hadoop-0.23.0-SNAPSHOT.tar.gz d) 每台机器需要安装java1.6或以上版本.并把JAVA_HOME加到$PATH中. e) 最好加上pssh和pscp工具. 这里把五台机器命名为: Myhost1 Myhost2 Myhost3 Myhost4 Myhost5 假设我们需要搭建如下集群: Myhost1和Myhost2开启 namenode, 另外三台机器启动datanode服务. 3. 首先把分配到五台机器上,然后解压.(推荐使用pscp, pssh命令) 4. 然后在五台机器上安装java,并把JAVA_HOME加到$PATH中 5. 进入解压后的hadoop目录, 编辑 etc/hadoop/hdfs-site.xml a) Myhost1的配置如下(其中hadoop存放在/home/yuling.sh/目录下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> b) Myhost2的配置如下(其中hadoop存放在/home/yuling.sh/目录下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> c) 这里把Myhost1集群起名ns1, Myhost1集群起名ns2, 三台slava的etc/hadoop/hdfs-site.xml配置如下: <property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost2:50070</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/yuling.sh/datanode</value>
</property>
d) 解释:namenode需要指定两个参数, 用于存放元数据和文件系统的URL. Datanode需指定要连接的namenode 的rpc-address和http-address. 以及数据存放位置dfs.datanode.data.dir. 6. 然后编辑两台namenode的hadoop目录下 etc/hadoop/slaves文件. 加入三台slave机器名: Myhost3 Myhost4 Myhost5 7. 现在需要格式化namenode, 由于namenode共享datanode, 因此它们的clusterid需要有相同的名字.这里我们把名字设为 yuling .命令如下: bin/hdfs namenode –format –clusterid yuling 两台机器格式话之后会在/home/yuling.sh/cluster-data下生成元数据目录. 8. 启动Myhost1和Myhost2上的namenode和slave上datanode服务. 命令如下: sbin/start-hdfs.sh 分别在Myhost1和Myhost2下运行. 9. 启动之后打开浏览器, 分别查看两namenode启动后状态. URL为: Myhost1:50070和Myhost2:50070 10. 这期间可能会遇到许多问题, 但是可以根据抛出的异常自己解决, 我这里就不多说了. 下一篇博客将讲述如何启动backupNode和SecondaryNamenode
编译(环境linux, 需要联网) 1. 首先下载hadoop 0.23版本 svn checkout http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.23.0-rc0/ 2. 进入release-0.23.0-rc0目录下能看到INSTALL.TXT文件, 这里有编译hadoop 0.23的教程. 编译前的准备:. a) * Unix System b) * JDK 1.6 c) * Maven 3.0 d) * Forrest 0.8 (if generating docs) e) * Findbugs 1.3.9 (if running findbugs) f) * ProtocolBuffer 2.4.1+ (for MapReduce) g) * Autotools (if compiling native code) h) * Internet connection for first build (to fetch all Maven and Hadoop dependencies) 可以根据需要安装全部或部分的工具,然后把它们加入到$PATH中. 这里介绍一下ProtocolBuffer的安装方法:下载2.4.1版本后解压,进入目录,运行如下命令即可. $ ./configure --prefile=/usr/local $ make $ sudo make install 3. 经过第二步准备之后,由于从hadoop0.23开始使用Maven编译,因此必需联网,命令如下: mvn package [-Pdist][-Pdocs][-Psrc][-Pnative][-Dtar] 建议先运行命令: mvn package -Pdist -DskipTests –Dtar (前提Maven 3.0和ProtocolBuffer2.4.1以上), 此命令成功之后会在release-0.23.0-rc0/下生成 hadoop-dist/target/hadoop-0.23.0-SNAPSHOT.tar.gz. 可以使用这个包搭建集群. 使用-Pdocs选项可以生成文档,当然前提是安装了Forrest 0.8和Findbugs 1.3.9. 可以参考如下命令手动指定:FORREST_HOME和FINDBUGS_HOME. mvn package -Pdocs -DskipTests -Dtar -Dmaven.test.skip -Denv.FORREST_HOME=/usr/local/apache-forrest-0.9 -Denv.FINDBUGS_HOME=/usr/local/findbugs-1.3.9 生成的文档在各自的target/site目录下.
经过以上步骤,我们已经编译好了hadoop-0.23,现在可以使用hadoop-0.23.0-SNAPSHOT.tar.gz来搭建集群了. 下一篇博客将讲述如何使用hadoop-0.23 搭建hdfs集群
本周末学习zookeeper,原理和安装配置 本文参考: http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ http://zookeeper.apache.org/ Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储,但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。 Zookeeper安装和配置比较简单,可以参考官网. 数据模型 Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图 1 所示:
图 1 Zookeeper 数据结构

Zookeeper 这种数据结构有如下这些特点: - 每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1
- znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录
- znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
- znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
- znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
- znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍
ZooKeeper 典型的应用场景 Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生 变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式,关于 Zookeeper 的详细架构等内部细节可以阅读 Zookeeper 的源码 下面详细介绍这些典型的应用场景,也就是 Zookeeper 到底能帮我们解决那些问题?下面将给出答案。 统一命名服务(Name Service) 分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形 的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 JNDI(Java Naming and Directory Interface,Java命名和目录接口,是一组在Java应用中访问命名和目录服务的API),没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。 Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。 配置管理(Configuration Management) 配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。 像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
图 2. 配置管理结构图
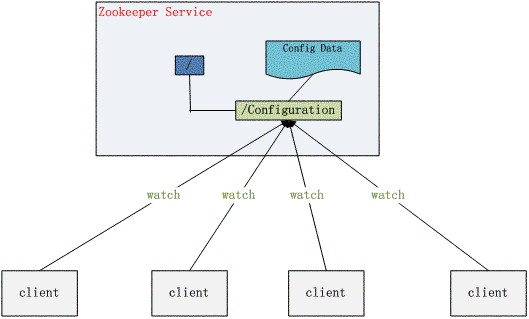 集群管理(Group Membership) Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服 务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。 Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。 它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。 Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
图 3. 集群管理结构图
 这部分的示例代码如下,完整的代码请看源代码:
清单 3. Leader Election 关键代码
void findLeader() throws InterruptedException { byte[] leader = null; try { leader = zk.getData(root + "/leader", true, null); } catch (Exception e) { logger.error(e); } if (leader != null) { following(); } else { String newLeader = null; try { byte[] localhost = InetAddress.getLocalHost().getAddress(); newLeader = zk.create(root + "/leader", localhost, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); } catch (Exception e) { logger.error(e); } if (newLeader != null) { leading(); } else { mutex.wait(); } } } | 共享锁(Locks) 共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
图 4. Zookeeper 实现 Locks 的流程图
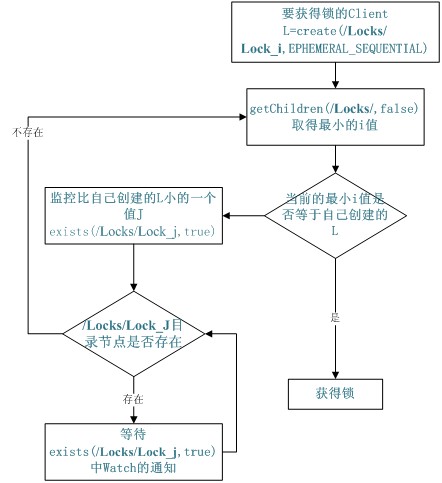 同步锁的实现代码如下,完整的代码请看源代码:
清单 4. 同步锁的关键代码
void getLock() throws KeeperException, InterruptedException{ List<String> list = zk.getChildren(root, false); String[] nodes = list.toArray(new String[list.size()]); Arrays.sort(nodes); if(myZnode.equals(root+"/"+nodes[0])){ doAction(); } else{ waitForLock(nodes[0]); } } void waitForLock(String lower) throws InterruptedException, KeeperException { Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ mutex.wait(); } else{ getLock(); } } | 队列管理 Zookeeper 可以处理两种类型的队列: - 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下: 创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。 用下面的流程图更容易理解:
图 5. 同步队列流程图
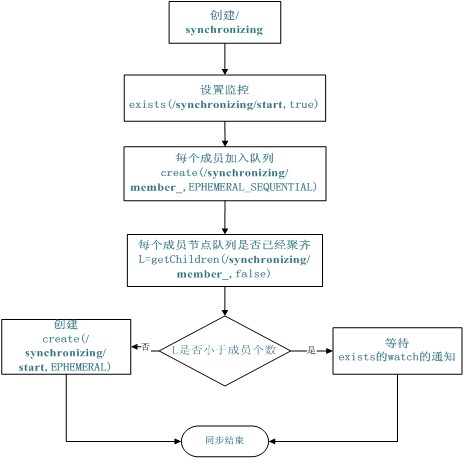 同步队列的关键代码如下,完整的代码请看附件:
清单 5. 同步队列
void addQueue() throws KeeperException, InterruptedException{ zk.exists(root + "/start",true); zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) { List<String> list = zk.getChildren(root, false); if (list.size() < size) { mutex.wait(); } else { zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } } } | 当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下: public void process(WatchedEvent event) { if(event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated){ System.out.println("得到通知"); super.process(event); doAction(); } } | FIFO 队列用 Zookeeper 实现思路如下: 实现的思路也非常简单,就是在特定的目录下创建 SEQUENTIAL 类型的子目录 /queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过 getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证 FIFO。 下面是生产者和消费者这种队列形式的示例代码,完整的代码请看附件:
清单 6. 生产者代码
boolean produce(int i) throws KeeperException, InterruptedException{ ByteBuffer b = ByteBuffer.allocate(4); byte[] value; b.putInt(i); value = b.array(); zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL); return true; } |
清单 7. 消费者代码
int consume() throws KeeperException, InterruptedException{ int retvalue = -1; Stat stat = null; while (true) { synchronized (mutex) { List<String> list = zk.getChildren(root, true); if (list.size() == 0) { mutex.wait(); } else { Integer min = new Integer(list.get(0).substring(7)); for(String s : list){ Integer tempValue = new Integer(s.substring(7)); if(tempValue < min) min = tempValue; } byte[] b = zk.getData(root + "/element" + min,false, stat); zk.delete(root + "/element" + min, 0); ByteBuffer buffer = ByteBuffer.wrap(b); retvalue = buffer.getInt(); return retvalue; } } } } | 总结 Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。 本文介绍的 Zookeeper 的基本知识,以及介绍了几个典型的应用场景。这些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管 理模型,而不仅仅局限于上面提到的几个常用应用场景。
使用 Linux 系统总是免不了要接触包管理工具。比如,Debian/Ubuntu 的 apt、openSUSE 的 zypp、Fedora 的 yum、Mandriva 的 urpmi、Slackware 的 slackpkg、Archlinux 的 pacman、Gentoo 的 emerge、Foresight 的 conary、Pardus 的 pisi,等等。DistroWatch 针对上述包管理器的主要用法进行了总结,对各位 Linux 用户来说具有很好的参考作用。这个总结还是有一点不足,有空给大家整理一个更全面的版本。 | 任务 | apt
Debian, Ubuntu | zypp
openSUSE | yum
Fedora, CentOS | | 安装包 | apt-get install <pkg> | zypper install <pkg> | yum install <pkg> | | 移除包 | apt-get remove <pkg> | zypper remove <pkg> | yum erase <pkg> | | 更新包列表 | apt-get update | zypper refresh | yum check-update | | 更新系统 | apt-get upgrade | zypper update | yum update | | 列出源 | cat /etc/apt/sources.list | zypper repos | yum repolist | | 添加源 | (edit /etc/apt/sources.list) | zypper addrepo <path> <name> | (add <repo> to /etc/yum.repos.d/) | | 移除源 | (edit /etc/apt/sources.list) | zypper removerepo <name> | (remove <repo> from /etc/yum.repos.d/) | | 搜索包 | apt-cache search <pkg> | zypper search <pkg> | yum search <pkg> | | 列出已安装的包 | dpkg -l | rpm -qa | rpm -qa | | 任务 | urpmi
Mandriva | slackpkg
Slackware | pacman
Arch | | 安装包 | urpmi <pkg> | slackpkg install <pkg> | pacman -S <pkg> | | 移除包 | urpme <pkg> | slackpkg remove <pkg> | pacman -R <pkg> | | 更新包列表 | urpmi.update -a | slackpkg update | pacman -Sy | | 更新系统 | urpmi --auto-select | slackpkg upgrade-all | pacman -Su | | 列出源 | urpmq --list-media | cat /etc/slackpkg/mirrors | cat /etc/pacman.conf | | 添加源 | urpmi.addmedia <name> <path> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 移除源 | urpmi.removemedia <media> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 搜索包 | urpmf <pkg> | -- | pacman -Qs <pkg> | | 列出已安装的包 | rpm -qa | ls /var/log/packages/ | pacman -Qii | | 任务 | conary
rPath, Foresight | pisi
Pardus | emerge
Gentoo | | 安装包 | conary update <pkg> | pisi install <pkg> | emerge <pkg> | | 移除包 | conary erase <pkg> | pisi remove <pkg> | emerge -C <pkg> | | 更新包列表 | | pisi update-repo | emerge --sync | layman -S [for added repositories] | | 更新系统 | conary updateall | pisi upgrade | emerge -NuDa world | | 列出源 | | pisi list-repo | layman -L | | 添加源 | | pisi add-repo <name> <path> | layman -a | | 移除源 | | pisi remove-repo <name> | layman -d | | 搜索包 | conary query <pkg> | pisi search <pkg> | emerge --search | | 列出已安装的包 | conary query | pisi list-installed | cat /var/lib/portage | more |
本文转自 http://linuxtoy.org/archives/linux-package-management-cheatsheet.html
-Xms256m
-Xmx512m
-Xmn128m
-XX:PermSize=96m
-XX:MaxPermSize=96m
-Xverify:none
-Xnoclassgc
-XX:UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=85 加入以上参数能使eclipse启动速度得到加快.至于各个参数的意义可以在网上查找到,这里不详细赘述.
Eclipse插件开发 1. 下载并安装jdk和eclipse
这里强调一下: 需要下载Eclipse for RCP and RAP Developers, 否则无法新建Plug-in Development 项目.
2. 新建项目
安装好之后打开eclipse, 点击 File->NewProject。选择Plug-in Project,点击Next。新建一个名为com.developer.showtime的项目,所有参数采用默认值. 3. 在com.developer.showtime项目的src下新建一个类: ShowTime,代码如下:
package com.developer.showtime;
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IStartup;
public class ShowTime implements IStartup {
public void earlyStartup() {
Display.getDefault().syncExec(new Runnable() {
public void run(){
long eclipseStartTime = Long.parseLong(System.getProperty("eclipse.startTime"));
long costTime = System.currentTimeMillis() - eclipseStartTime;
Shell shell = Display.getDefault().getActiveShell();
String message = "Eclipse start in " + costTime + "ms";
MessageDialog.openInformation(shell, "Information", message);
}
});
}
}
4. 修改plugin.xml文件如下: <?xml version="1.0" encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.startup">
<startup class="com.developer.showtime.ShowTime"/>
</extension>
</plugin> 5. 试运行 右键点击Run as -> Eclipse Application. 此时会运行一个eclipse, 启动之后就能显示启动所需时间. 6. 导出插件. 右键Export -> Deployable plug-ins and fragments. 在Directory中输入需要导出的路径, 点击finish后会在该目录下产生一个plugins的目录, 里面就是插件包: com.developer.showTime_1.0.0.201110161216.jar. 把这个包复制到eclipse目录下的plugin目录下. 然后再启动eclipse 便可以看到eclipse启动所花的时间.
本周学习了mapreduce-64,对map端的spill有了较为深入的了解. 附件描述了修改前后sort的原理.mapreduce-64前spill原理较为简单,打上mapreduce-64后主要流程也不难,需要了解各个参数的意义.
下文翻译自yahoo博客:http://developer.yahoo.com/blogs/hadoop/posts/2011/02/mapreduce-nextgen/
Hadoop的下一代mapreduce 概述 在大数据商业领域中,运行个数少但较大的集群比运行多个小集群更划算,大集群还可以处理更大的数据集并支持更多的作业和用户. Apache Hadoop 的MapReduce框架已经达到4000台机器的扩展极限,我们正在发展下一代MapReduce,使其成为一个通用资源管理,单作业,用户自定义组件,管理着应用程序执行的框架. 由于停机成本更大,高可用必需从一开始就得建立,就如安全性和多用户组,用以支持更多用户使用更大的集群,新的构架在许多地方进行了创新,增加了敏捷性和机器利用率. 背景 当前Apache Hadoop 的MapReduce的接口会显示其年龄. 由于集群大小和工作负载的变化趋势, MapReduce的JobTracker需要彻底的改革以解决其可扩展性,内存消耗,线程模型,可靠性和性能上的不足. 过去五年,我们做了一些小的修复,然而最近,修改框架的的成本越来越高. 结构的缺陷和纠正措施都很好理解,甚至早在2007年,当我们记录下修复建议: https://issues.apache.org/jira/browse/MAPREDUCE-278. 从运营的角度看,目前的Hadoop MapReduce框架面临系统级别的升级,以解决例如bug修复,性能改善和功能的需求. 更糟糕的是,它迫使每个用户也需要同时升级,不顾其利益;这使用户使用新版本的周期变长. 需求 我们考虑改善Hadoop MapReduce框架的方法,重要的是记住最迫切的需求,下一代Hadoop MapReduce框架最迫切的需求是: - 可靠性
- 可用性
- 可扩展性 - 10000台机器,200000核,或者更多
- 向后兼容性 - 确保用户的MapReduce应用程序在下一代框架下不需要改变
- 进展 – 客户端可以控制hadoop软件堆栈的升级.
- 可预测的延迟 – 用户很关注的一点.
- 集群利用率
第二层次需求: - 使MapReduce支持备用编程范式
- 支持短时间的服务
鉴于以上需求,显然我们需要重新考虑使用hadoop成为数据处理的基础设施. 事实上,当前MapReduce结构无法满足我们的需求,因此需要新的创新,这在hadoop社区这已成为共识,查看2008年一月的一个提议,在jira: https://issues.apache.org/jira/browse/MAPREDUCE-279. 下一代MapReduce 重构的基本思想是把jobtracker的两大功能分开,使资源管理和作业分配/监控成为两个部件.新的资源管理器管理提供给应用(一个或多个)的计算资源,应用管理中心管理应用程序的调度和协调,应用程序既是一个经典MapReduce作业也是这类作业的DAG. 资源管理器和每台机器的NodeManager服务,管理该机上的用户进程,形成计算结构. 每个应用程序的ApplicationMaster是一个具体库的架构,负责从资源管理器请求资源,并和NodeManager协同执行和监控任务. 资源管理器支持应用程序的分组,这些组保证使用一定比例集群资源. 它是纯粹的调度,也就是,它运行时并不监控和追踪应用的状态. 此外,它不保证重新启动失败的任务,无论是应用程序或硬件导致的失败. 资源管理器执行调度功能是基于应用的资源需求,每个应用需要多种资源需求,代表对对容器所需的资源,资源需求包括内存,cpu,硬盘,网络等,注意这与当前使用slot模型的MapReduce有很大的不同,slot模型导致集群利用率不高,资源管理器有一个调度策略插件,负责分把集群资源分给各个组,应用等.有基础的调度插件,例如:当前的CapacityScheduler 和FairScheduler. NodeManager是每台机器的框架代理,负责提交应用程序的容器,监控他们的资源利用率(cpu,内存,硬盘,网络),并且报告给调度器. 每个应用程序的ApplicationMaster负责与调度器请求适当的资源容器,提交作业,追踪其状态,监控进度和处理失败任务. 结构 改进当前实现面对面的Hadoop MapReduce 可扩展性 在集群中把资源管理从集群管理器的整个生命周期和他们的部件中分离出来后形成的架构:扩展性更好并且更优雅, Hadoop MapReduce的JobTracker花费很大一部分时间和精力管理应用程序的生命周期,这是导致软件灾难的原因.把它移到应用指定的实体是一个重大的胜利. 可扩展性在当前硬件趋势下更加重要,当前hadoop的MapReduce已经发展到4000台机器,然而4000台机器在2009年(例:8core,16G RAM,4TB硬盘)只有2011年400台机器的一半(16core,48G RAM, 24TB硬盘). 并且,运营成本的因素有助于迫使和巩固我们使用更大的集群:6000台机器或者更多. 可用性 - 资源管理器 – 使用 Apache ZooKeeper 用于故障转移. 当资源管理器发生故障,另外一个可以迅速恢复,这是由于集群状态保存在ZooKeeper中. 资源管理器失败后,重启所有组和正在运行的应用程序.
- 应用中心 - 下一代MapReduce支持应用特殊点的检查功能 ,依靠其把自身状态存储在hdfs上的功能,MapReduce 应用中心可以从失败中恢复,
兼容性 下一代MapReduce使用线兼容协议以允许不同版本的服务端和客户端相互通信,在将来的releases版本,这将使集群滚动升级,一个重要的可操作性便成功了. 创新和敏捷性 提出的构架一个主要优点是MapReduce将更有效,成为user-land library. 计算框架(资源管理器和节点管理器)完全通用并在MapReduce看来是透明的. 这使最终客户在同一个集群使用可用不同版本的MapReduce, 这是微不足道的支持,因为MapReduce的应用中心和运行时的多版本可用于不同的应用. 这为应用提供显著的灵活性,因为整个集群没必要升级,如修复bug,改进和新功能的应用. 它也允许终端用户根据他们自己的安排升级其应用到MapReduce版本,这大大提高了集群的可操作性. 允许用户自定义的Map-Reduce版本的创新不会影响软件的稳定性. 这是微不足道的,就像hadoop在线原型进入用户MapReduce版本而不影响其他用户.( It will be trivial to incorporate features such as the Hadoop Online Prototype into the user’s version of MapReduce without affecting other users.) 集群利用率 下一代MapReduce资源管理器使用通用概念,用于调度和分配给单独的个体. 集群中的每个机器资源是概念性的,例如内存,cpu,I/O带宽等. 每个机器都是可替代的,分配给应用程序就像基于应用指定需求资源的容器.每个容器包括一些处理器,并和其他容器逻辑隔离,提供强有利的多租户支持. 它删除了当前hadoop MapReduce中map和reduce slots概念. Slot会影响集群的利用率,因为在任何时候,无论map和reduce都是稀缺的. 支持MapReduce编程范式 下一代MapReduce提供一个完全通用的计算框架以支持MapReduce和其他的范例. 架构允许终端用户实现应用指定的框架,通过实现用户的ApplicationMaster,可以向资源管理器请求资源并利用他们,因为他们通过隔离并保证资源的情况下看起来是适合的. 因此,在同一个hadoop集群下支持多种编程范式,例如MapReduce, MPI, Master-Worker和迭代模型,并允许为每个应用使用适当的框架.这对自定义框架顺序执行一定数目的MapReduc应用程序(例: K-Means, Page-Rank)很重要. 结论 Apache Hadoop和特定的Hadoop MapReduce,是一个用于处理大数据集的成功开源项目. 我们建议Hadoop的 MapReduce重构以提供高可用性,增加集群利用率,提供编程范例的支持以加快发展. 我们认为,在已存在的选项中如Torque, Condor, Mesos 等,没有一个用于设计解决MapReduce集群规模的问题, 某些功能很新且不成熟, 另外一些没有解决关键问题,如调度在上十万个task,规模的性能,安全和多用户等. 我们将与Apache Hadoop社区合作,为实现这以提升Apache Hadoop以适应下一代大数据空间.
0.23的调度方法: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/
|