MyFrame类用于实现数据的增删改查。
代码用JFrame进行了演示,其中的每一个按键都添加了事件监听。
这里假定mysql数据库的端口号是3306。
数据库是my_database。
表是user。
表中包含name和score两个元素。
使用前注意引入JDBC的jar包作为外部jar包。
import java.awt.Container;
import java.awt.FlowLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JTextField;
public class MyFrame extends JFrame {
private static final int Width = 420;
private static final int Height = 300;
private static JFrame frame = null;
//private static Container ctn = null;
private static FlowLayout flowLayout = null;
private static JLabel nameLabel = null;
private static JLabel scoreLabel = null;
private static JTextField nameText = null;
private static JTextField scoreText = null;
private static JButton addButton = null;
private static JButton deleteButton = null;
private static JButton modifyButton = null;
private static JButton searchButton = null;
private static JLabel resultLabel = null;
private static JTextField resultText = null;
private static JButton closeButton = null;
private static String driver = "com.mysql.jdbc.Driver";
private static String url = "jdbc:mysql://localhost:3306/my_database";
private static String userName = "root";
private static String password = "root";
private static Connection conn = null;
private static Statement stmt = null;
public MyFrame() {
frame = new JFrame("JFrame connect MySQL");
flowLayout = new FlowLayout(FlowLayout.LEFT);
flowLayout.setHgap(20);
flowLayout.setVgap(30);
frame.setLayout(flowLayout);
nameLabel = new JLabel("name");
scoreLabel = new JLabel("score");
nameText = new JTextField(10);
scoreText = new JTextField(10);
addButton = new JButton("ADD");
deleteButton = new JButton("DELETE");
modifyButton = new JButton("MODIFY");
searchButton = new JButton("SEARCH");
resultLabel = new JLabel("result");
resultText = new JTextField(30);
closeButton = new JButton("CLOSE");
frame.add(nameLabel);
frame.add(nameText);
frame.add(scoreLabel);
frame.add(scoreText);
frame.add(addButton);
frame.add(deleteButton);
frame.add(modifyButton);
frame.add(searchButton);
frame.add(resultLabel);
frame.add(resultText);
frame.add(closeButton);
addButton.addActionListener(new ButtonAction());
deleteButton.addActionListener(new ButtonAction());
modifyButton.addActionListener(new ButtonAction());
searchButton.addActionListener(new ButtonAction());
closeButton.addActionListener(new ButtonAction());
frame.setVisible(true);
frame.setSize(Width, Height);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
private class ButtonAction implements ActionListener {
public void actionPerformed(ActionEvent evt) {
Object s = evt.getSource();
String name = nameText.getText();
String score = scoreText.getText();
if(s == addButton) {
if(name.length()==0 || score.length()==0) {
System.out.println("Please enter the name and score!");
}
else {
String sqlInsert =
"INSERT INTO my_table (name,score) VALUES (\"" + name + "\"," + score + ");";
try {
stmt.executeUpdate(sqlInsert);
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("Add " + name + " Succeed!");
}
} else if(s == deleteButton) {
if(name.length() == 0) {
System.out.println("You must enter the name");
return;
} else if(score.length() == 0) {
String sqlDelete = "DELETE FROM my_table WHERE name=\"" + name + "\";";
try {
stmt.executeUpdate(sqlDelete);
} catch (SQLException e) {
e.printStackTrace();
}
} else {
String sqlDelete = "DELETE FROM my_table WHERE name=\"" + name
+ "\" and score<=" + score + ";";
try {
stmt.executeUpdate(sqlDelete);
} catch (SQLException e) {
e.printStackTrace();
}
}
System.out.println("Delete succeed!");
} else if(s == modifyButton) {
if(name.length() == 0 || score.length() == 0) {
System.out.println("Please enter the name and score you want to modify!");
} else {
String sqlModify = "UPDATE my_table SET name=\"" + name
+ "\" WHERE score=" + score + ";";
try {
stmt.executeUpdate(sqlModify);
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("Modify " + name + " succeed!");
}
} else if(s == searchButton) {
String sqlName = " name=\"" + name + "\"";
String sqlScore = " score=" + score;
String sqlSelect = "SELECT * FROM my_table";
if(name.length() == 0 && score.length() == 0) {
;
} else if(score.length() == 0) {
sqlSelect += " WHERE" + sqlName + ";";
} else if(name.length() == 0) {
sqlSelect += " WHERE" + sqlScore + ";";
} else {
sqlSelect += " WHERE" + sqlName + " and" + sqlScore + ";";
}
//System.out.println(sqlSelect);
try {
ResultSet res = stmt.executeQuery(sqlSelect);
while(res.next()) {
String ansName = res.getString(1);
String ansScore = res.getString(2);
System.out.println(ansName + " get score: " + ansScore);
}
} catch (SQLException e) {
e.printStackTrace();
}
} else if(s == closeButton) {
try {
stmt.close();
if(conn != null)
conn.close();
} catch (SQLException e) {
System.out.println("SQLException异常"+e.getMessage());
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
try {
Class.forName(driver);
System.out.println("数据库连接成功");
} catch (ClassNotFoundException e) {
System.out.println("ClassNotFoundException");
}
try {
conn = DriverManager.getConnection(url, userName, password);
System.out.println("connect database successful");
stmt = conn.createStatement();
new MyFrame();
} catch (SQLException e) {
System.out.println("SQLException异常"+e.getMessage());
e.printStackTrace();
}
}
}
posted @
2015-03-08 16:43 marchalex 阅读(693) |
评论 (0) |
编辑 收藏
alex alice 88
alex candice 100
jobs alice 100
john lucy 89
在这里,我们假设每个人的评分都为0到100的整数,最终的结果向下取整。那么MapReduce程序可以写成如下:
我们需要三样东西:一个map函数,一个reduce函数,和一些用来运行作业的代码。
map函数由Mapper接口实现来表示,后者声明了一个map()方法。
AverageMapper.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class AverageMapper extends MapReduceBase
implements Mapper<IntWritable, Text, Text, IntWritable> {
public void map(IntWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String s = value.toString();
String name = new String();
int point = 0;
int i;
for(i=0;i<s.length() && s.charAt(i)!='\t';i++);
for(i++;i<s.length() && s.charAt(i)!='\t';i++) {
name += s.charAt(i);
}
for(i++;i<s.length();i++) {
point = point * 10 + (s.charAt(i) - '0');
}
if(name.length() != 0 && point >=0 && point <= 100) {
output.collect(new Text(name), new IntWritable(point));
}
}
}
该Mapper接口是一个泛型类型,他有四个形参类型,分别指定map函数的输入键、输入值、输出键、输出值的类型。
以示例来说,输入键是一个整形偏移量(表示行号),输入值是一行文本,输出键是美女的姓名,输出值是美女的得分。
Hadoop自身提供一套可优化网络序列化传输的基本类型,而不直接使用Java内嵌的类型。这些类型均可在org.apache.hadoop.io包中找到。
这里我们使用IntWritable类型(相当于Java中的Integer类型)和Text类型(想到与Java中的String类型)。
map()方法还提供了OutputCollector示例用于输出内容的写入。
我们只在输入内容格式正确的时候才将其写入输出记录中。
reduce函数通过Reducer进行类似的定义。
AverageReducer.java
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class AverageReducer extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
long tot_point = 0, num = 0;
while(values.hasNext()) {
tot_point += values.next().get();
num ++;
}
int ave_point = (int)(tot_point/num);
output.collect(key, new IntWritable(ave_point));
}
}
第三部分代码负责运行MapReduce作业。
Average.java
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
public class Average {
public static void main(String[] args) throws IOException {
if(args.length != 2) {
System.err.println("Usage: Average <input path> <output path>");
System.exit(-1);
}
JobConf conf = new JobConf(Average.class);
conf.setJobName("Average");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(AverageMapper.class);
conf.setReducerClass(AverageReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
}
}
JobConf对象指定了作业执行规范。我们可以用它来控制整个作业的运行。
在Hadoop作业上运行着写作业时,我们需要将代码打包成一个JAR文件(Hadoop会在集群上分发这些文件)。
我们无需明确指定JAR文件的名称,而只需在JobConf的构造函数中传递一个类,Hadoop将通过该类查找JAR文件进而找到相关的JAR文件。
构造JobCOnf对象之后,需要指定输入和输出数据的路径。
调用FileInputFormat类的静态方法addInputPath()来定义输入数据的路径。
可以多次调用addInputOath()实现多路径的输入。
调用FileOutputFormat类的静态函数SetOutputPath()来指定输出路径。
该函数指定了reduce函数输出文件的写入目录。
在运行任务前该目录不应该存在,否则Hadoop会报错并拒绝运行该任务。
这种预防措施是为了防止数据丢失。
接着,通过SetMapperClass()和SetReducerClass()指定map和reduce类型。
输入类型通过InputFormat类来控制,我们的例子中没有设置,因为使用的是默认的TextInputFormat(文本输入格式)。
新增的Java MapReduce API
新的Hadoop在版本0.20.0包含有一个新的Java MapReduce API,又是也称为"上下文对象"(context object),旨在使API在今后更容易扩展。
新特性:
倾向于使用虚类,而不是接口;
新的API放在org.apache.hadoop.mapreduce包中(旧版本org.apache.hadoop.mapred包);
新的API充分使用上下文对象,使用户代码能与MapReduce通信。例如:MapContext基本具备了JobConf,OutputCollector和Reporter的功能;
新的API同时支持“推”(push)和“拉”(pull)的迭代。这两类API,均可以将键/值对记录推给mapper,但除此之外,新的API也允许把记录从map()方法中拉出、对reducer来说是一样的。拉式处理的好处是可以实现批量处理,而非逐条记录的处理。
新的API实现了配置的统一。所有作业的配置均通过Configuration来完成。(区别于旧API的JobConf)。
新API中作业控制由Job类实现,而非JobClient类,新API中删除了JobClient类。
输出文件的命名稍有不同。
用新上下文对象来重写Average应用
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NewAverage {
static class NewAverageMapper
extends Mapper<IntWritable, Text, Text, IntWritable> {
public void map(IntWritable key, Text value, Context context)
throws IOException, InterruptedException {
String s = value.toString();
String name = new String();
int point = 0;
int i;
for(i=0;i<s.length() && s.charAt(i)!='\t';i++);
for(i++;i<s.length() && s.charAt(i)!='\t';i++) {
name += s.charAt(i);
}
for(i++;i<s.length();i++) {
point = point * 10 + (s.charAt(i) - '0');
}
if(name.length() != 0 && point >=0 && point <= 100) {
context.write(new Text(name), new IntWritable(point));
}
}
}
static class NewAverageReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
long tot_point = 0, num = 0;
for(IntWritable value : values) {
tot_point += value.get();
num ++;
}
int ave_point = (int)(tot_point/num);
context.write(key, new IntWritable(ave_point));
}
}
public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.err.println("Usage: NewAverage <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(NewAverage.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(NewAverageMapper.class);
job.setReducerClass(NewAverageReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
posted @
2015-03-08 13:27 marchalex 阅读(1433) |
评论 (0) |
编辑 收藏
之前我写过获得tmall上qfour某单品页上第一张图片的
程序。
这次我又在qfour上面选了一个
猫娘志2015春秋新款女装显瘦小清新碎花长袖田园连衣裙女单品页用于获得下面的这张图。

这张图对应的url为:
http://gi4.md.alicdn.com/bao/uploaded/i4/TB1aRpnHpXXXXaNXVXXXXXXXXXX_!!0-item_pic.jpg
我写了一个ImageDownload类,其中的download方法用于下载url对应的图片并保存在特定的本地目录上。代码如下:
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
public class ImageDownload {
public static void download(String urlString, String filename) throws Exception {
URL url = new URL(urlString); // 构造URL
URLConnection con = url.openConnection(); // 打开链接
con.setConnectTimeout(5*1000); //设置请求超时为5s
InputStream is = con.getInputStream(); // 输入流
byte[] bs = new byte[1024]; // 1K的数据缓冲
int len; // 读取到的数据长度
int i = filename.length();
for(i--;i>=0 && filename.charAt(i) != '\\' && filename.charAt(i) != '/';i--);
String s_dir = filename.substring(0, i);
File dir = new File(s_dir); // 输出的文件流
if(!dir.exists()){
dir.mkdirs();
}
OutputStream os = new FileOutputStream(filename);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
}
public static void main(String[] args) throws Exception {
download("http://gi4.md.alicdn.com/bao/uploaded/i4/TB1aRpnHpXXXXaNXVXXXXXXXXXX_!!0-item_pic.jpg", "d:\\qfour\\sample.jpg");
}
}
posted @
2015-03-08 12:33 marchalex 阅读(1801) |
评论 (0) |
编辑 收藏
检测设备的运行状态,有的是使用ping的方式来检测的。所以需要使用java来实现ping功能。
为了使用java来实现ping的功能,有人推荐使用java的 Runtime.exec()方法来直接调用系统的Ping命令,也有人完成了纯Java实现Ping的程序,使用的是Java的NIO包(native io, 高效IO包)。但是设备检测只是想测试一个远程主机是否可用。所以,可以使用以下三种方式来实现:
1.Jdk1.5的InetAddresss方式
自从Java 1.5,java.net包中就实现了ICMP ping的功能。
见:Ping类的ping(String)函数。
使用时应注意,如果远程服务器设置了防火墙或相关的配制,可能会影响到结果。另外,由于发送ICMP请求需要程序对系统有一定的权限,当这个权限无法满足时, isReachable方法将试着连接远程主机的TCP端口 7(Echo)。
2.最简单的办法,直接调用CMD
见Ping类的ping02(String)函数。
3.Java调用控制台执行ping命令
具体的思路是这样的:
通过程序调用类似“ping 127.0.0.1 -n 10 -w 4”的命令,这命令会执行ping十次,如果通顺则会输出类似“来自127.0.0.1的回复: 字节=32 时间<1ms TTL=64”的文本(具体数字根据实际情况会有变化),其中中文是根据环境本地化的,有些机器上的中文部分是英文,但不论是中英文环境, 后面的“<1ms TTL=62”字样总是固定的,它表明一次ping的结果是能通的。如果这个字样出现的次数等于10次即测试的次数,则说明127.0.0.1是百分之百能连通的。
技术上:具体调用dos命令用Runtime.getRuntime().exec实现,查看字符串是否符合格式用正则表达式实现。
见Ping类的ping(String,int,int)函数。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Ping {
public static boolean ping(String ipAddress) throws Exception {
int timeOut = 3000 ; //超时应该在3钞以上
boolean status = InetAddress.getByName(ipAddress).isReachable(timeOut); // 当返回值是true时,说明host是可用的,false则不可。
return status;
}
public static void ping02(String ipAddress) throws Exception {
String line = null;
try {
Process pro = Runtime.getRuntime().exec("ping " + ipAddress);
BufferedReader buf = new BufferedReader(new InputStreamReader(
pro.getInputStream()));
while ((line = buf.readLine()) != null)
System.out.println(line);
} catch (Exception ex) {
System.out.println(ex.getMessage());
}
}
public static boolean ping(String ipAddress, int pingTimes, int timeOut) {
BufferedReader in = null;
Runtime r = Runtime.getRuntime(); // 将要执行的ping命令,此命令是windows格式的命令
String pingCommand = "ping " + ipAddress + " -n " + pingTimes + " -w " + timeOut;
try { // 执行命令并获取输出
System.out.println(pingCommand);
Process p = r.exec(pingCommand);
if (p == null) {
return false;
}
in = new BufferedReader(new InputStreamReader(p.getInputStream())); // 逐行检查输出,计算类似出现=23ms TTL=62字样的次数
int connectedCount = 0;
String line = null;
while ((line = in.readLine()) != null) {
connectedCount += getCheckResult(line);
} // 如果出现类似=23ms TTL=62这样的字样,出现的次数=测试次数则返回真
return connectedCount == pingTimes;
} catch (Exception ex) {
ex.printStackTrace(); // 出现异常则返回假
return false;
} finally {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//若line含有=18ms TTL=16字样,说明已经ping通,返回1,否則返回0.
private static int getCheckResult(String line) { // System.out.println("控制台输出的结果为:"+line);
Pattern pattern = Pattern.compile("(\\d+ms)(\\s+)(TTL=\\d+)", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(line);
while (matcher.find()) {
return 1;
}
return 0;
}
public static void main(String[] args) throws Exception {
String ipAddress = "127.0.0.1";
System.out.println(ping(ipAddress));
ping02(ipAddress);
System.out.println(ping(ipAddress, 5, 5000));
}
}
小结:
第一种方法:Jdk1.5的InetAddresss,代码简单。
第二种方法:使用java调用cmd命令,这种方式最简单,可以把ping的过程显示在本地。
第三种方法:也是使用java调用控制台的ping命令,这个比较可靠,还通用,使用起来方便:传入个ip,设置ping的次数和超时,就可以根据返回值来判断是否ping通。
posted @
2015-03-08 09:48 marchalex 阅读(22225) |
评论 (3) |
编辑 收藏
在之前简要介绍过
深度优先搜索和
广度优先搜索这两个算法。
同时我们之前也讲过Java中
队列的使用。
在
基于百度的推荐程序的基础上,我们可以开展大规模搜索了,也就是说:
今天,我写的东西是 DFS/BFS 和 推荐 的 结合。
我将会把网页信息的挖取加上搜索从而达到得到更多信息的效果。
举个例子,比如我在百度搜索“一句话木马”,百度会推荐给我一些信息,如“广外女生木马”,然后我再继续搜“广外女生木马”,会得到一个“网络神偷”的推荐词;这个推荐词是不包含在搜“一句话木马”的推荐词里面的,但是也是我感兴趣的,所以我通过广度优先搜索或者深度优先搜索来进行这种大规模的网络上的搜索。
RelateDigger类用于实现该功能。
其中的bfs方法体现了广度优先搜索的功能;dfs方法体现了深度优先搜索的功能。
使用digInBFS方法进行大规模的bfs网页挖取推荐信息功能。
使用digInDFS方法进行大规模的dfs网页挖取推荐信息功能。
我用max_count限制广度优先搜索搜索到的关键词的最大数量,用max_depth限制搜索的深度。大家可以根据自己的需求更改这两个常量。
用HashMap来记录得到的关键词。
代码如下:
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue;
public class RelateDigger {
public static HashMap <String,Integer> map;
private static final int max_count = 100;
private static int count;
private static final int max_depth = 3;
private static void init() {
count = 0;
map = new HashMap<String, Integer>();
}
private static void dfs(String u, int depth) throws Exception {
System.out.println("digging in " + u);
String[] res = FindRelate.getRelate(u);
int n = res.length;
for(int i=0;i<n;i++) {
String v = res[i];
if(map.containsKey(v)) continue;
map.put(v, new Integer(1));
if(depth >= max_depth) return;
dfs(v, depth+1);
}
return;
}
public static void digInDFS(String word) throws Exception {
init();
map.put(word, new Integer(1));
dfs(word, 0);
Iterator<String> iter = map.keySet().iterator();
while(iter.hasNext()) {
String key = iter.next();
System.out.print(key);
if(iter.hasNext()) System.out.print(",");
}
}
private static void bfs(String u) throws Exception {
Queue<String> queue = new LinkedList<String>();
queue.offer(u);
while((u=queue.poll())!=null){
System.out.println("digging in " + u);
String[] res = FindRelate.getRelate(u);
int n = res.length;
for(int i=0;i<n;i++) {
String v = res[i];
if(map.containsKey(v)) continue;
map.put(v, new Integer(1));
count ++;
queue.offer(v);
if(count >= max_count) return;
}
}
}
public static void digInBFS(String word) throws Exception {
init();
map.put(word, new Integer(1));
count ++;
bfs(word);
Iterator<String> iter = map.keySet().iterator();
while(iter.hasNext()) {
String key = iter.next();
System.out.print(key);
if(iter.hasNext()) System.out.print(",");
}
}
public static void main(String[] args) throws Exception {
digInDFS("一句话木马");
digInBFS("珠穆朗玛峰");
}
}
其中digInDFS得到的结果为:null,中国十大最难懂方言,必应词典,盗号木马,震荡波病毒,充值软件,盗号,网络神偷,塔佐蠕虫,中越黑客大战,黑客教程,蛀船虫,中国黑客联盟,小球病毒,宏病毒,中华吸血鬼,特洛伊木马,qq木马,鬼影病毒,后门木马,动漫日语,中国红客联盟,CIH病毒,李俊,有道词典,黑光病毒,伯乐木马,百度杀毒,手机透视器,黑客教父,qq盗号木马,机器狗病毒,米特尼克,qq枪手,冰河木马,c病毒,火焰病毒,g病毒,免费黑客网,百度翻译,华夏黑客联盟,广外女生木马,oldboot,cih病毒,特洛伊:木马屠城,玻璃蛇,网游大盗,学术翻译,灰鸽子木马,三角木马,熊猫烧香,女巫的椅子,江民炸弹,黑客工具,网上学英语,米米病毒,金山词霸,灰鸽子远程控制软件,莫里斯蠕虫,百度卫士,僵尸世界大战2,远程控制软件,悬玉环,食骨蠕虫,千斤顶,超级工厂病毒,灰鸽子,灵格斯,磁碟机病毒,骑木马驴,机器狗,震荡波,幸运破解器,黑客基地,维罗妮卡病毒,nabau,一句话木马,蠕虫病毒,冲击波病毒,黑客技术教程,大小姐木马,木马病毒,大麻病毒,不死木马,2001中美黑客大战,下村勉,trojan.generic,金猪报喜,qq尾巴,欢乐时光病毒,geohot,asp木马,手机骷髅病毒,中国鹰派,世界十大黑客,海词词典,黑客,王江民,潘多拉,杀毒软件,citrus,qq大盗,计算机病毒,g幼体,罗塞塔石碑,黑客技术,卡巴斯基免费版,丧尸,万能登陆器,高危型人乳头瘤病毒,铁莲花
digInBFS得到的结果为:德令哈外星人遗址,百慕大三角,麦田怪圈,中国三大海峡,太阳墓,中国四大无人区,海底金字塔,中国最美十大名山,中国梯,巴黎性博物馆,中国死海,玫瑰湖,天门山,大蓝洞,贡嘎山,51区,西藏,普罗旺斯,中华十大名山,山西十大景区,克尔黑洞,暗物质,美国大峡谷空中走廊,魔鬼城,安纳布尔纳峰,羌塘,哭岛,全球被遗弃的31个景点,外星人,白洞,史瓦西黑洞,罗布泊,中国五大淡水湖,恐怖谷理论,道教四大名山,性博物馆,托木尔峰,中国四大名塔,幽灵岛,乞力马扎罗山,霍金,四大道教名山,喜马拉雅山脉,怪坡,黑洞,可可西里,无底洞,毛里求斯,藏王,中国四大古镇,藏北无人区,巧克力山,玉珠峰,撒哈拉之眼,大西国,爱因斯坦,奥林匹斯山,黄泉大道,天门山玻璃栈道,球状闪电,帕巴拉神庙,中华侏罗纪公园,凤凰山ufo事件,神农架,卡瓦格博,中国十大古城,珠峰大本营,亚特兰蒂斯,昆仑山死亡谷,查亚峰,魔鬼塔,巨人之路,贵州时光隧道,潘洛斯阶梯,处女峰,怒江72拐,希勒湖,乔戈里峰,倒悬空寺,鱼人岛,慕士塔格峰,日本龙三角,地心人,列宁峰,全球十大惊悚地点,不可能图形,死亡谷,巴比伦通天塔,珠穆朗玛峰,马尔代夫太阳岛,天下第一桥,蓝洞,9.8新疆ufo事件,沈阳怪坡,雁荡山,中国四大古城,四姑娘山,三山五岳,墨脱水电站,黑林错觉
posted @
2015-03-07 22:20 marchalex 阅读(254) |
评论 (0) |
编辑 收藏
第一种:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
第二种:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
其中,第一种方法效率较高。
posted @
2015-03-07 21:46 marchalex 阅读(174) |
评论 (0) |
编辑 收藏
不同于深度优先搜索,广度优先搜索(breadth-first search,简称BFS,又称宽度优先搜索)采取的工具是队列。
我们回顾一下
深度优先搜索,可以发现:
深度优先搜索是通过递归实现的,其实就相当于在内存中开了一个
栈来实现。
而广度优先搜索通过
队列来实现,其解决问题的大体思路如下:
首先,将代表初始状态的节点放入队列queue中;
然后,循环进行以下操作:
从队列里面推出一个元素u,将通过u能够联系到的且可以优化的节点v推入队列中
即:
深度优先搜索用栈(stack)来实现,整个过程可以想象成一个倒立的树形:
1、把根节点压入栈中。
2、每次从栈中弹出一个元素,搜索所有在它下一级的元素,把这些元素压入栈中。并把这个元素记为它下一级元素的前驱。
3、找到所要找的元素时结束程序。
4、如果遍历整个树还没有找到,结束程序。
广度优先搜索使用队列(queue)来实现,整个过程也可以看做一个倒立的树形:
1、把根节点放到队列的末尾。
2、每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。并把这个元素记为它下一级元素的前驱。
3、找到所要找的元素时结束程序。
4、如果遍历整个树还没有找到,结束程序。
广度优先搜索可以用来解决很多问题,比如,求最短路的SPFA算法就是用了宽度优先搜索的思想。
posted @
2015-03-07 21:14 marchalex 阅读(277) |
评论 (0) |
编辑 收藏
深度优先搜索(depth-first search,简称dfs)就是递归地进行一系列操作,直到找到想要的结果或者搜到头了(无路可走)。
我对深度优先搜索的总结就是:
(1)不见南墙不回头
(2)找到以后往回走
深度优先搜索其实和我们大多数人小时候走迷宫时选择的策略非常类似。

深度优先搜索有一个很简单的例子:求n!。
int f(int n) {
if(n == 0 || n == 1) return 1;
return f(n-1) * n;
}
我们以现在ACM竞赛中一道简单的竞赛题 --
素数环 为例,来讲解深度优先搜索。
点此进入题目描述
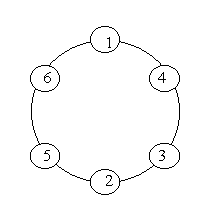
这道题目的意思是,找到所有的素数环输出。
我们可以写下对应的伪代码:
function dfs(深度) {
if(深度 == 1) {
第1个点确定为1;
第1个点标记访问过了;
dfs(深度+1);
撤销第1个点的标记;
}
else {
for(i = 1 to n) {
if(i加上第(深度-1)个点的值是素数 and i没有被访问过) {
第(深度)个点确定为i;
第i个点标记访问过了;
dfs(深度+1);
撤销第i个点的标记;
}
}
}
if(深度 > n) {
if(第(深度-1)个点的值+1是素数) {
输出这串素数环;
}
return;
}
return;
}
简单了解了深度优先搜索,并且差不多看懂了这个伪代码,我们就可以用代码实现一下了。下面是完整的Java代码:
import java.util.Scanner;
public class Main {
public static boolean isprime(int n) {
if(n ==2 || n == 3 || n == 5 || n == 7 || n == 11 || n == 13 || n == 17 || n == 19 ||
n == 23 || n == 29 || n == 31 || n == 37 || n == 41)
return true;
return false;
}
private static boolean[] vis = new boolean[22];
private static int[] ans = new int[22];
private static Scanner in;
public static void dfs(int dep,int n) {
for(int i=1;i<=n;i++) {
if(vis[i] == false && isprime(ans[dep-1] + i)) {
vis[i] = true;
ans[dep] = i;
if(dep == n && isprime(1+i)) {
System.out.print(ans[1]);
for(int i1=2;i1<=n;i1++) System.out.print(" " + ans[i1]);
System.out.println("");
vis[i] = false;
return;
} else if(dep == n) {
vis[i] = false;
return;
}
dfs(dep+1, n);
vis[i] = false;
}
}
return;
}
public static void main(String[] args) {
in = new Scanner(System.in);
int cnt = 0;
while(in.hasNext()) {
int n = in.nextInt();
for(int i=1;i<=n;i++) vis[i] = false;
cnt ++;
System.out.println("Case " + cnt + ":");
vis[1] = true;
ans[1] = 1;
dfs(2, n);
System.out.println("");
}
}
}
递归地一种很好玩的现象:德罗斯特效应

posted @
2015-03-07 20:47 marchalex 阅读(212) |
评论 (0) |
编辑 收藏上百度搜东西的时候,右边总有一些推荐的东西很吸引我们的注意,因为那是百度的推荐系统给我推荐的我们感兴趣的东西。
那这些推荐的内容也在源代码里面出现了。
所以采用类似分析网页源代码的方法我们能够把里面的东西全都挖下来。
比如说我在百度搜索了“一句话木马”,百度就会跳到一个固定的链接:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%9C%A8%E9%A9%AC&rsv_pq=fcb3de5b00004128&rsv_t=6f62cGPSB5k0xYiyhhPSjjDXemE9KEBVk0diG3YR6PnVzpq1vmoq%2FDdFD8E&rsv_enter=1&rsv_n=2&rsv_sug3=1
好长是不?
其实我们可以将这个url缩短一下,变成:
http://www.baidu.com/s?wd=%E4%B8%80%E5%8F%A5%E8%AF%9D%E6%9C%A8%E9%A9%AC
等同于
http://www.baidu.com/s?wd=一句话木马
网页的右侧出现了三个栏:“相关病毒”,“相关人物”和“其他人还搜”,直觉告诉我第一个是联系比较紧密的。
所以我的目的就是变成找出第一个栏(不光是这里)的所有推荐内容。
分析网页会发现每个栏目最前面都会有一个标志性的字符串:"<span title="
而每个栏目里面的每个内容前面也会有一个标志性的字符串:"rsv_re_ename"
据此我写了一个分析的FinderRelate类,其中的getRelate(String word)用于获得关键词word对应的推荐的内容。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.StringTokenizer;
public class FindRelate {
public static String[] getRelate(String word) throws Exception {
String urlString = "http://www.baidu.com/s?wd=" + word;
String ans = "";
String s_span = "<span title=";
int len_span = s_span.length();
String s_rsv = "rsv_re_ename";
int len_rsv = s_rsv.length();
URL url = new URL(urlString);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
BufferedReader reader = new BufferedReader(new InputStreamReader(urlConnection.getInputStream(), "utf-8"));
String line;
boolean ok = false;
while ((line = reader.readLine()) != null){
int len = line.length();
for(int i=0;i+len_span<=len;i++) {
if(line.substring(i, i+len_span).equals(s_span)) {
if(ok == false) ok = true;
else {
StringTokenizer st = new StringTokenizer(ans);
int n = st.countTokens();
String[] res = new String[n];
for(int j=0;j<n;j++) {
res[j] = st.nextToken();
}
return res;
}
}
}
if(ok == false) continue;
for(int i=0;i+len_rsv<=len;i++) {
if(line.substring(i, i+len_rsv).equals(s_rsv)) {
for(int j=i+len_rsv+3;j<len && line.charAt(j)!='\'';j++) {
ans += line.charAt(j);
}
ans += " ";
}
}
}
String[] null_res = new String[1];
null_res[0] = null;
return null_res;
}
public static void main(String[] args) throws Exception {
String[] res = getRelate("一句话木马");
int len = res.length;
for(int i=0;i<len;i++)
System.out.println(res[i]);
}
}
其输出结果如下:
广外女生木马
qq尾巴
熊猫烧香
欢乐时光病毒
灰鸽子
大小姐木马
盗号
机器狗
盗号木马
冰河木马
冲击波病毒
莫里斯蠕虫
asp木马
cih病毒
火焰病毒
posted @
2015-03-07 00:07 marchalex 阅读(1625) |
评论 (0) |
编辑 收藏
之前写了一个
FileHelper类用于实现文件的读取和写入。
这次在原来的基础上写了一个WebpageMaker类,其createPage方法用于将特定文件中的内容生成在特定的网页中。
其中如果要插入代码可以将代码加入
中。
import java.util.StringTokenizer;
public class WebpageMaker {
public static String initBegin() {
String s = "<!doctype html><html><head><title></title></head><body>\r\n";
return s;
}
public static String initEnd() {
String s = "\r\n</body></html>\r\n";
return s;
}
public static void createPage(String inputfilename, String outputfilename) throws Exception {
String content = FileHelper.readFile(inputfilename);
StringTokenizer st = new StringTokenizer(content, "\r\n");
String ans = "";
ans += initBegin();
boolean isCoding = false;
while(st.hasMoreElements()) {
String s = st.nextToken();
int len = s.length();
for(int i=0;i<len;i++) {
if(i+6 <= len && s.substring(i,i+6).equals("<alex>")) {
isCoding = true;
ans += "<pre style=\"background-color:aliceblue\">";
i += 5;
continue;
}
if(i+7 <= len && s.substring(i,i+7).equals("</alex>")) {
isCoding = false;
ans += "</pre>";
i += 6;
continue;
}
char c = s.charAt(i);
if(c == '\"') ans += """;
else if(c == '&') ans += "&";
else if(c == '<') ans += "<";
else if(c == '>') ans += ">";
else if(c == ' ') ans += " ";
else if(c == '\t') ans += " ";
else ans += c;
}
if(false == isCoding)
ans += "<br />\r\n";
else
ans += "\r\n";
}
ans += initEnd();
FileHelper.writeFile(ans, outputfilename);
}
public static void main(String[] args) throws Exception {
createPage("D://test.txt", "D://test.html");
}
}
样例:
输入文件:test.txt
hello world!
大家好:)
#include
int main() {
printf("hello world!\n");
return 0;
}
输出文件:test.html
<!doctype html><html><head><title></title></head><body>
hello world!<br />
大家好:)<br />
<pre style="background-color:aliceblue">#include <stdio.h>
int main() {
printf("hello world!\n");
return 0;
}</pre><br />
</body></html>
效果如下:
hello world!
大家好:)
#include <stdio.h>
int main() {
printf("hello world!\n");
return 0;
}
posted @
2015-03-06 16:36 marchalex 阅读(386) |
评论 (2) |
编辑 收藏