2012年12月25日
最近准备将redis升级到最新版2.6,就简单从官网上寻找了一下最近的改动点.
2.2-2.4的改进
* 编码sorted sets, 小的soted sets将会使用非常小的内存
* 编码数据类型(ziplists,zipmaps,intsets)的本地持久化,更多的数据sets的保存和加载速度提高了一个数量级.
* 命令(SADD,HDEL,SREM,ZREM,ZADD,L/RPUSH)支持可变参数输入
* 为了避免减少内存碎片,支持jemalloc(linux系统默认开启)
* 保存时降低内存使用率
* 更多的信息field (peak memory, fork time, )
* OBJECT 命令 支持对象自检
* CLIENT 命令支持clients自检
* 非阻塞的从->主连接
* 更好的redis-cli连接处理,新的redis-cli特征
* 更好的redis-benchmark,现在能benchmark用户提供的命令.
* 色彩化Make命令.
* VM废弃,仍然支持,但是给出警告不要使用它.
* LRANGE优化,可以在查询一个长list的最后一部分时显著提高性能,。
* redis-cli 现在实现了一个延迟模式来监控redis的延迟
* Hash type settings 从INFO中移除 (一样的信息可以通过配置GET来获取)
* 在无法bind的时候 在错误信息中包含端口号
* AOF fsync 当fsync策略是'everysec'的时候,运行在后台.
* AOF performances improved moving in background a possibly slow close(2) call.
* AOF protocol synthesis speedup.
* 新的maxmemory测试.
* redis-check-dump: RDB version 2 now supported.
* 为一个uinx socket mask增加一个配置说明.
* CONFIG SET/GET 设置 loglevel.
* 在/utils 中增加redis 全系统(Debian/Ubuntu)安装脚本.
* redis-cli 现在支持单引号风格的字符串
* 通过CONFIG SET 命令关闭密码认证.
* redis.conf 部分更好地 better documented.
* 客户端默认超时timeout是0,即永不超时.
* 调整I/O缓存长度为了提高大负载的性能.
* Fixed crash on SPARC due to improper alighment due to bad assumptions about data types size.
* CLIENT LIST 输出加强,代码重构.
* CLIENT LIST 输出修改,包括客户端最后执行的命令.
* 协议错误现在记录log loglevel>=verbose.
* 两个新的INFO field关联到AOF,对于调查redis问题非常有用.
* 在redis的测试中实现--quiet选项
* 在INFO 中包含每个连接的slave的ip/端口/状态.
* 在INFO output信息中展示GCC版本.
* redis-cli增加 --pipe 模式, see http://redis.io/topics/mass-insert
* 更好地改进失效key收集算法,当大量keys在同时失效的时候, 使得server响应性能更快.
* INFO 命令展示slaves(包括端口号) 建议使用2.4.16以上的版本作slave
This makes Redis 2.4.16 compatible with Redis Sentinel. This fix required the introduction of a new internal command called REPLCONF, see commit b998ebe for more information.
* INFO 命令现在包含run_id字段保证Redis Sentinel的兼容性
* 支持参数'slave priority' 通过INFO发布,主要用于Redis Sentinel.
2.4-2.6的改进
* SORT现在会拒绝无法转换为数字的数字模型元素进行排序
* EXPIREs现在支持微秒失效. (but this is very unlikely to
break code that was not conceived exploting the previous resolution error
in some way.)
* INFO输出现在一点不同,包含空line和'#'开通的注释.所有主流的客户端现在已经支持新的INFO格式.
* Slaves 现在默认是只读模式(但是可以通过修改配置文件red is.conf的'slave-read-only'项 为'no' 来取消只读 ,或者使用CONFIG SET来取消).
下面的INFO field为了一致性调整了名字:
changes_since_last_save -> rdb_changes_since_last_save
bgsave_in_progress -> rdb_bgsave_in_progress
last_save_time -> rdb_last_save_time
last_bgsave_status -> rdb_last_bgsave_status
bgrewriteaof_in_progress -> aof_rewrite_in_progress
bgrewriteaof_scheduled -> aof_rewrite_scheduled
下面的redis.conf配置文件和 CONFIG GET / SET 参数做了调整:
* hash-max-zipmap-entries, 替换为 hash-max-ziplist-entries
* hash-max-zipmap-value, 替换为 hash-max-ziplist-value
* glueoutputbuf option 现在已经完全废弃 (was deprecated)
* Server 端支持Lua脚本, see http://redis.io/commands/eval
* Virtual Memory 完全去掉(was deprecated in 2.4)
* 关于客户端最大数量限制的硬编码去掉.
* AOF 低级的语义更明智,尤其是使用在slaves中的时候.
* 微秒级的expires,也增加了一些新的命令(PEXPIRE,PTTL,…) .
* 为了小集合(lists,ziplists和hashes里只包含小integer的时候)提供更好的内存使用率. * slaves只读.
* 新增位操作: BITCOUNT 和 BITOP 命令.
* 客户端最大输出缓存的软件限制和硬件限制.可以根据不同的客户端类型(normal,pubsub,slave)来指定不同的限制.
*更多地增量过期(减少阻塞)的过期key收集算法 ,当非常多的key在同一时间失效的时候,意味着redis可以提高响应的数据.
* AOF is now able to rewrite aggregate data types using variadic commands,
often producing an AOF that is faster to save, load, and is smaller in size.
* Every redis.conf directive is now accepted as a command line option for the
redis-server binary, with the same name and number of arguments.
* 为了减少碰撞攻击,hash表的种子采用随机产生
* 写大量object到red is的性能提高
* 集成内存测试.见命令:redis-server --test-memory.
* INCRBYFLOAT 和 HINCRBYFLOAT命令
* 新的命令 DUMP, RESTORE, MIGRATE(从 Redis Cluster 移植到 2.6).
* CRC64 校验 in RDB files.
* 更好的监控输出log(现在命令在执行前记录log)
* "Software Watchdog" feature to debug latency issues.
* 启动时增加Redis的ASCII码的艺术logo标记.
* 内存冲突的崩溃报告 或者失败断言 使得调试定位bug的困难程度得到一定地降低 .
* redis-benchmark 增强: 运行选择的测试,CSV输出,更快,更好的help
* redis-cli 增强: --eval lua脚本的开发
* SHUTDOWN 现在支持两个可选参数 'SAVE' 和 'NOSAVE' .
* INFO 输出分解为几个部分,这个命令可以指定输出某个部分.
* 增加新的统计,一个命令被调用了多少次,被执行了多少时间(INFO commandstats) .
* More predictable SORT behavior in edge cases.
* Build模块代码改进.
* 现在当slave-serve-stale-data 设置为yes并且master挂掉的时候, 代替报告一个通常的错误的red is回复 -MASTERDOWN
Now when slave-serve-stale-data is set to yes and the master is down, instead of reporting a generic error Redis replies with -MASTERDOWN.
2012年12月12日
metamorphosis 是通过jmx原理实现的监控,重载配置等服务.所以需要对metaq监控就有两个条件必须满足:
1 使用metamorphosis-server-wrapper
2 metaq的java启动参数中必须开启jmx的相关参数(-Dcom.sun.management.jmxremote )
才能使用metaServer.sh命令监控
stats命令
不加任何参数,展示metaq的整个程序的相关参数.
./metaServer.sh stats
结果
STATS
pid 16585
broker_id 1002
port 8123
uptime 691558
version 1.4.3
slave false
curr_connections 3
threads 134
cmd_put 1142
cmd_get 437188
cmd_offset 0
tx_begin 0
tx_xa_begin 0
tx_commit 0
tx_rollback 0
get_miss 437123
put_failed 0
total_messages 3192
topics 14
config_checksum 3605506033
END
-item参数 brokers
./metaServer.sh stats -item brokers
结果
STATS
brokers
resultCode 1
partitions 0
message_count 0
bytes 0
topic_realtime_put Invalid keyTwo:brokers
topic_realtime_get Invalid keyTwo:brokers
topic_realtime_offset null
topic_realtime_get_miss Invalid keyTwo:brokers
topic_realtime_put_failed null
topic_realtime_message_size Invalid keyTwo:brokers
END
topics
./metaServer.sh stats -item
执行结果
STATS
category partitions 1 message_count 28 accept_publish true accept_subscribe true
metatest2 partitions 1 message_count 1000 accept_publish true accept_subscribe true
test partitions 1 message_count 31 accept_publish true accept_subscribe true
metatest partitions 1 message_count 1058 accept_publish true accept_subscribe true
user_fav partitions 1 message_count 3 accept_publish true accept_subscribe true
product partitions 1 message_count 3 accept_publish true accept_subscribe true
listen_queue partitions 1 message_count 15 accept_publish true accept_subscribe true
listen_queue_confirm partitions 1 message_count 1048 accept_publish true accept_subscribe true
user_remind partitions 1 message_count 7 accept_publish true accept_subscribe true
cart *Empty*
listen_queue_success *Empty*
order *Empty*
user_changePass *Empty*
user_reg *Empty*
END
topic名称(比如:test)
./metaServer.sh stats -item test
执行结果
STATS
test
resultCode 0
partitions 1
message_count 31
bytes 3855
topic_realtime_put Count=0,Value=0,Value/Count=invalid,Count/Duration=0,Duration=1251
topic_realtime_get Count=0,Value=0,Value/Count=invalid,Count/Duration=0,Duration=1251
topic_realtime_offset null
topic_realtime_get_miss Count=0,Value=0,Value/Count=invalid,Count/Duration=0,Duration=1251
topic_realtime_put_failed null
topic_realtime_message_size Count=0,Value=0,Value/Count=invalid,Count/Duration=0,Duration=1251
END
2012年11月29日
message为主要关键字,类似于java中的class。
定义简单message类型
SearchRequest.proto定义了每个查询请求的消息格式,每个请求都会有查询关键词query,查询结果的页数,每页的结果数量这三个属性。于是
message SearchRequest{
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page =3;
repeated int32 samples = 4 [packed=true];
}
message定义了三个field,每个field由名字和类型来组成。
在这个例子中,SearchRequest的field都是基本类型,两个integer(page_number和result_per_page)和一个Stirng(query),也可以指定复杂的类型属性,包括枚举和其它类型。
每个field都是唯一数字的标记,这是用来标记这个field在message二进制格式中的位置的,一旦使用就不能再修改顺序了。
注:标记从1-15只有一个字节编码,包括自增长属性(更多的见Protocol Buffer Encoding)
标记从16-2047占用两个字节。因此尽量频繁使用1-15,记住为未来的扩展留下一些位置。
最小的tag你可以定义为1,最大2的29次方-1 536870922.你同样不能使用19000-19999(这个位置已经被GPB自己实现),
message SearchRequest{
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page =3;
repeated int32 samples = 4 [packed=true];
}
由于历史原因,repeated字段如果是基本数字类型的话,不能有效地编码。现在代码可以使用特殊选项[packed=true]来得到更有效率的编码。
注: 由于required是永远的,应该非常慎重地给message某个字段设置为required。如果未来你希望停止写入或者输出某个required字段,那就会成为问题;因为旧的reader将以为没有这个字段无法初始化message,会丢掉这部分信息。一些来自google的工程师们指出使用required弊大于利,尽量使用optional和repeated。
这个观点并不是通用的。
多个message类型能被定义在一个简单的.proto文件中,通常是创建具有关联关系的message时候这么作。
message SearchRequest{
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page =3;
repeated int32 samples = 4 [packed=true];
}
使用c/C++ style
message SearchRequest{
required string query = 1; //
optional int32 page_number = 2; // which page number do we want?
optional int32 result_per_page =3; // Number of results to return per page?
repeated int32 samples = 4 [packed=true];
}
protocol buffer编译一个proto文件,生成对应语言的代码。
大概包括各个字段的get和set方法,序列化message到输出流的方法,从输入流转成message的方法。
C++,为每个proto生成一个.h和.cc文件
Java,为每个proto生成一个.java文件
Python,有点不同,生成一个module
当含有optional字段的message从流转换成对象的时候,如果没有包含optional字段的数据,那么对象的optional字段会设置成默认值。
默认值可以作为message的描述出现。举个例子:
optional int32 result_per_page = 3 [default = 10];
如
pasting
果没有指定默认值的话,string 默认为空串,bool 默认为false,数字类型默认0,枚举类型,默认为类型定义中的第一个值,
如果字段的属性值是固定的几个值,可以使用枚举
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3 [default = 10];
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
optional Corpus corpus = 4 [default = WEB];
}
可以使用message类型做字段的属性,看例子:
message SearchResponse {
repeated Result result = 1;
}
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
上面的例子SearchResponse 与Result在一个.proto文件中。其实也可以使用另一个.proto文件来定义字段类型。
你可以通过import来定义。
import "myproject/other_protos.proto";
protocol编译器查找引入文件是通过编译器的命令参数 -I/--proto_path
如果没有指定,就在protoc执行目录下寻找。
The protocol compiler searches for imported files in a set of directories specified on the protocol compiler command line using the -I/--proto_path flag.
If no flag was given, it looks in the directory in which the compiler was invoked.
In general you should set the --proto_path flag to the root of your project and use fully qualified names for all imports.
你可以定义和使用内部message类。
message SearchResponse {
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
repeated Result result = 1;
}
如果要引用内部类,则通过parent.type方式来调用
message SomeOtherMessage {
optional SearchResponse.Result result = 1;
}
还可以很深、很深的内部类
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
required int64 ival = 1;
optional bool booly = 2;
}
}
message MiddleBB { // Level 1
message Inner { // Level 2
required int32 ival = 1;
optional bool booly = 2;
}
}
}
message SearchResponse {
repeated group Result = 1 {
required string url = 2;
optional string title = 3;
repeated string snippets = 4;
}
}
Extentions
extensions 声明一个消息中的一定范围的field的顺序数字用于进行扩展。其它人可以在自己的.proto文件中重新定义这些消息field,而不需要去修改原始的.proto文件
message Foo {
// 
extensions 100 to 199;
}
这些说明100-199的field是保留的。其它用户可以用这些field在他们自己的.proto文件中添加新的fields给Foo。举例:
extend Foo {
optional int32 bar = 126;
}
说明 Foo有一个optional的int32类型的名称为bar的field
当Foo的message编码后,数据格式就跟用户在Foo中定义一个新的field完全一样。但是你在程序中访问extension field的方式与访问正常的属性略微有点不同。生成的extensions的访问代码是不同的。举例:c++中如何set属性bar的值:
Foo foo;
foo.SetExtension(bar,15);
同样,Foo 定义了模板访问器 HasExtendsion(),ClearExtension(),GetExtension(),MutableExtension(),AddExtension().
所有 访问
注: extensions能使用任何field类型,包括自定义消息类型。
能声明extensions在另一个message中
message Baz {
extend Foo {
optional int32 bar = 126
;
}
}
在这个例子中, the C++ 代码访问访问这个属性:
Foo foo;
foo.SetExtension(Baz::bar, 15);
换句话说,这么做唯一影响是bar定义在了Baz的范围之内。
注意:容易混淆的地方 声明一个消息内部的继承类并不意味着外部类和extended类有任何关系。特别 以上的例子并不意味着Baz是任何Foo的子类。这些只是意味着符号bar是声明在Baz的范围之内的,它看起来更像是个静态成员。
一个通用的模式是在extensions的field范围内来定义extensions,举例说明,这里有一个Foo的extension作为Baz的一部分的属性类型是Baz
message Baz {
extend Foo {
optional Baz foo_ext = 127
;
}
}
没有必要非得在message内部定义一个extension的类型。你也可以这么做:
message Baz {
}
// This can even be in a different file.
extend Foo {
optional Baz foo_baz_ext = 127
;
}
事实上,上面的这个语法更加有效地避免混淆。正如上文所述,内部的那种语法语法对于不是熟悉extensions的人来说,经常会错认为子类。
非常重要的一点是双方不能使用同样数字添加一样的message类型,这样extension会被解释为错误类型。
可能需要有一个关于field的数字顺序的约定来保证你的project不会发生这样的重复的问题。
如果你的field数字比较大的话,可以使用max来指定你的textension范围上升到最大的范围
message Foo {
extensions 1000 to max;
}
max is 229 - 1, or 536,870,911.
19000-19999是protocol buffers的使用的字段,所以这个范围内的数字需要区别开来。
Packages
可以给一个.protol文件增加一个optional的package描述,来保证message尽量不会出现名字相同的重名。
package foo.bar
;
message Open {
}
也可以在指定field类型的时候使用
message Foo {
required foo.bar.Open open = 1
;
}
package会根据选择的语言来生成不同的代码:
C++ 生成的classes是用C++的namespace来区分的。举例:Open would be in the namespace foo::bar。
Java package用于Java的package,除非你单独的指定一个option java_package 在.proto文件中。
Python package是被忽略的,因为Python的modules是通过它们的文件位置来组织的。
在protocol buffer中package名称的方案看起来像C++,首先,最里面的范围被搜索,然后搜索次一级的范围,
每个package被认为在他的父package内。一个. (.foo.bar.Baz)意味着从最外层开始.
options
在一个proto文件中,还可以存在一些options。Options不能改变一个声明的整体的意义,但是可以影响一定的上下文。
可用的options的完整list定义在 Google/protobuf/descriptor.proto
一些options是第一级的,意味着它们应该被写在顶级范围,而不是在任何message,enum,sercie的定义中。
一些options是message级别的,意味着它们应该被写入message的描述中,
一些options是field-level级别的,意味着它们应该被写入field的描述中,
options也可以被写入enum类型中,enum的值,service类型 和service方法;
列举了常用的options:
java_package(file option)
定义生成的java class的package。如果在proto文件中没有明确的java_package选项,那么默认会使用package关键字指定的package名。
但是proto package通常不会好于Java packages,因为proto packages通常不会以domain名称开始。
如果不生成java代码,此选项没有任何影响。
option java_package = "com.example.foo";
java_outer_classname:(file option)
指定想要生成的class名称,如果此参数没有指定的话,那么默认使用.proto文件名来做为类名,并且采用驼峰表示(比如:foo_bar.proto 为 FooBar.java)
如果不生成java代码,此选项没有影响。
option java_outer_classname = "Ponycopter";
optimize_for (file option)
可以设置为speed、code_size或者lite_runtime.
SPEED:默认。protocol编译器会生成classes代码,提供了message类的序列化、转换和其它通用操作。这个代码是被高度优化过的。
CODE_SIZE: protocol编译器会生成最小的classes,并且依赖共享、基于反射的代码实现序列化、转换和其它通用操作。生成的classes代码小于speed,但是操作会慢一点。classes会实现跟SPEED模式一样的公共API。这个模式通常用在一个应用程序包含了大量的proto文件,但是并不需要所有的代码都执行得很快
LITE_RUNTIME: protocol编译器会生成仅仅依赖 lite 运行库(libprotobuf-lite代替libprotobuf)。lite运行时比全量库小很多,省略了某种特性(如: descriptors and reflection)这个选项对于运行在像移动手机这种有约束平台上的应用更有效。 编译器仍然会对所有方法生成非常快的代码实现,就像SPEED模式一样。protocol编译器会用各种语言来实现MessageList接口,但是这个接口仅仅提供了其它模式实现的Message接口的一部分方法子集。
例子
option optimize_for = CODE_SIZE;
cc_generic_services, java_generic_services, py_generic_services (file options)
无论如何,protoc编译器会生成基于C++,Java,Python的抽象service代码,这些默认都是true。截至到2.3.0版本,RPC实现提供了代码生成插件去生成代码,不再使用抽象类。
// This file relies on plugins to generate service code.
option cc_generic_services = false;
option java_generic_services = false;
option py_generic_services = false;
message_set_wire_format (message option)
如果设置为true,消息使用不同的二进制格式来兼容谷歌内部使用的称为MessageSet的旧格式。用户在google以外使用,将不再需要使用这个option。
消息必须按照以下声明
message Foo {
option message_set_wire_format = true;
extensions 4 to max;
}
packed (field option)
如果设置为true, 一个repeated的基本integer类型的field,会使用一种更加紧凑的压缩编码。请注意,在2.3.0版之前,protocol生成的解析逻辑收到未预期的压缩的数据将会忽略掉。因此,改变一个已经存在的field,一定会破坏其线性兼容性。在2.3.0以后,这种改变就是安全的,解析逻辑可以识别压缩和不压缩的格式,但是,一定要小心那些使用原先旧版本的protocol的程序。
repeated int32 samples = 4 [packed=true];
deprecated (field option):
如果设置为true,表示这个field被废弃,应该使用新代码。大多数语言中,这个没有任何影响。在java中,会生成@Deprecated的注释。未来,其它语言代码在field的访问方法上也会生成相应的注释。
optional int32 old_field = 6 [deprecated=true];
protocol buffer还允许你自定义options。这是个高级特性,大多数人并不需要。options其实都定义在 google/protobuf/descriptor.proto文件中。
自定义的options是简单的,继承这些messages
import "google/protobuf/descriptor.proto";
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
message MyMessage {
option (my_option) = "Hello world!";
}
这里我们定义了一个message级别的消息选项,当使用这个options的时候,选项的名称必须用括号括起来,以表明它是一个extension。
我们在C++中读取my_option的值就像下面这样:
string value = MyMessage::descriptor()->options().GetExtension(my_option);
这里,MyMessage::descriptor()->options()返回的MessageOptions protocol类型 message。
读取自定义就如同读取继承属性一样。
在Java中
String value = MyProtoFile.MyMessage.getDescriptor().getOptions().getExtension(MyProtoFile.myOption);
自定义options可以对任何message的组成元素进行定义
import "google/protobuf/descriptor.proto";
extend google.protobuf.FileOptions {
optional string my_file_option = 50000;
}
extend google.protobuf.MessageOptions {
optional int32 my_message_option = 50001;
}
extend google.protobuf.FieldOptions {
optional float my_field_option = 50002;
}
extend google.protobuf.EnumOptions {
optional bool my_enum_option = 50003;
}
extend google.protobuf.EnumValueOptions {
optional uint32 my_enum_value_option = 50004;
}
extend google.protobuf.ServiceOptions {
optional MyEnum my_service_option = 50005;
}
extend google.protobuf.MethodOptions {
optional MyMessage my_method_option = 50006;
}
option (my_file_option) = "Hello world!";
message MyMessage {
option (my_message_option) = 1234;
optional int32 foo = 1 [(my_field_option) = 4.5];
optional string bar = 2;
}
enum MyEnum {
option (my_enum_option) = true;
FOO = 1 [(my_enum_value_option) = 321];
BAR = 2;
}
message RequestType {}
message ResponseType {}
service MyService {
option (my_service_option) = FOO;
rpc MyMethod(RequestType) returns(ResponseType) {
// Note: my_method_option has type MyMessage. We can set each field
// within it using a separate "option" line.
option (my_method_option).foo = 567;
option (my_method_option).bar = "Some string";
}
}
如果想使用在package里面的自定义的option,必须要option前使用包名,如下
// foo.proto
import "google/protobuf/descriptor.proto";
package foo;
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
// bar.proto
import "foo.proto";
package bar;
message MyMessage {
option (foo.my_option) = "Hello world!";
}
最后一件事:既然自定义的options是extensions,他们必须指定field number就像其它field或者extension一样。如果你要在公共应用中使用自定义的options,那么一定要确认你的field numbers是全局唯一的
你能通过多选项带有一个extension 把它们放入一个子message中
message FooOptions {
optional int32 opt1 = 1;
optional string opt2 = 2;
}
extend google.protobuf.FieldOptions {
optional FooOptions foo_options = 1234;
}
// usage:
message Bar {
optional int32 a = 1 [(foo_options.opt1) = 123, (foo_options.opt2) = "baz"];
// alternative aggregate syntax (uses TextFormat):
optional int32 b = 2 [(foo_options) = { opt1: 123 opt2: "baz" }];
}
生成class代码
为了生成java、python、C++代码,你需要运行protoc编译器 protoc 编译.proto文件。
编译器运行命令:
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.proto
import_path 查找proto文件的目录,如果省略的话,就是当前目录。存在多个引入目录的话,可以使用--proto_path参数来多次指定,
-I=IMPORT_PATH就是--proto_path的缩写
输出目录
--cpp_out 生成C++代码在DST_DIR目录
--java_out 生成Java代码在DST_DIR目录
--python_out 生成Python代码在DST_DIR目录
有个额外的好处,如果DST是.zip或者.jar结尾,那么编译器将会按照给定名字输入到一个zip压缩格式的文件中。
输出到.jar会有一个jar指定的manifest文件。注意 如果输出文件已经存在,它将会被覆盖;编译器的智能不足以自动添加文件到一个存在的压缩文件中。
你必须提供一个或者多个.proto文件用作输入。虽然文件命名关联到当前路径,每个文件必须在import_path路径中一边编译器能规定它的规范名称
更新message如果一个message 不再满足所有需要,需要对字段进行调整.(举例:对message增加一个额外的字段,但是仍然有支持旧格式message的代码在运行)
要注意以下几点:
1、不要修改已经存在字段的数字顺序标示
2、可以增加optional或者repeated的新字段。这么做以后,所有通过旧格式message序列化的数据都可以通过新代码来生成对应的对象,正如他们不会丢失任何required元素。
你应该为这些元素添加合理的默认值,以便新代码可以与旧代码生成的消息交互。 新代码创建的消息中旧代码不存在的字段,在解析的时候,旧代码会忽略掉新增的字段。
无论如何,未知的field不会被丢弃,如果message晚点序列化,为。
注意 未知field对于Python来说当前不可用。
3、非required字段都可以转为extension ,反之亦然,只要type和number保持不变。
4、int32, uint32, int64, uint64, and bool 是全兼容的。这意味着你能改变一个field从这些类型中的一个改变为另一个,而不用考虑会打破向前、向后兼容性。
如果一个数字是通过网络传输而来的相应类型转换,你将会遇到type在C++中遇到的问题(e.g. if a 64-bit number is read as an int32, it will be truncated to 32 bits)
5、sint32 and sint64 彼此兼容,但是不能兼容其它integer类型.
6、string and bytes 在UTF-8编码下是兼容的.
7、如果bytes包含一个message的编码,内嵌message与bytes兼容.
8、fixed32 兼容 sfixed32, fixed64 兼容 sfixed64.
9、optional 兼容 repeated. 用一个repeat字段的编码结果作为输入,认为这个字段是可选择的客户端会这样处理,如果是原始类型的话,获得最后的输入作为相应的option值;如果是message 类型,合并所有输入元素.
10、更改默认值通常是OK的.要记得默认值并不会通过网络发送,如果一个程序接受一个特定字段没有设置值的消息,应用将会使用自己的版本协议定义的默认值,不会看见发送者的默认值.
2012年11月24日
Meta的client实现分析
由于meta不像activeMQ等产品,它们的broker端承载了非常多的功能,而像meta这样追求性能为目的的消息中间件,则是把broker端的功能弱化,同时加强了client端的某些功能,如当前client的消息offset的存储、从broker中pull消息等。
下面我们从消息pull这样一个client端最重要的功能作为分析的主线来了解meta中client的实现。
下面是client端执行pull消息的处理流程示意图:

1.通过ZKLoadRebalanceListener的rebalance方法,根据该client所订阅topic的分区数量来初始化对应数量的FetchRequest实例,并把它们放到FetchRequestQueue中(先进先出)。
2.消息抓取管理器初始化fetchRunners线程池,并启动所有线程对FetchRequestQueue进行读请求的操作。
3.当FetchRequestQueue中有请求时,则执行FetchRequestRunner线程中的processRequest方法,进行后续的操作。
4.通过SimpleMessageConsumer(消息消费者基类)的fetch方法从broker端获取某topic的某分区的消息数据byte组。
5.对broker端返回的消息数据byte组进行操作,解析出一条条消息,并对这些消息进行消费,具体代码实现在FetchRequestRunner类的notifyListener方法,它是消息消费的核心方法,后面我们会重点介绍。
6.FetchRequestRunner处理完一次从broker获取消息并消费的过程后,会把FetchRequest实例重新放回FetchRequestQueue中,重复进行下一轮操作。
上面是client端pull消息的主过程,由于meta的client涉及的功能也较多,为了更进一步了解client端的实现细节,我们从下面几个方面做更进一步的分析
pull模型的轮训时间
很多用户在一看到消息的获取是通过client端主动pull的方式,就感觉和activeMQ等其他消息中间件所采用的broker主动推送消息到client的方式相比较,实时性有所降低。但通过对meta源码的分析,发现它的实时性还是可以保证的,具体实现方法分析如下:
轮训时间的控制在FetchRequestQueue类的take方法中的如下几行代码:
final long delay = first.getDelay(TimeUnit.NANOSECONDS); if (delay > 0) { final long tl = this.available.awaitNanos(delay); }
delay值的设置是按照下面规则进行的:

- 初始化为0,所以第一次该请求会立即和broker端通讯,以获得消息组。
- 大部分情况下pull的轮训间隔为0,所以它的实时性还是可以保证的。
Meta使用zookeeper的细节
meta对zookeeper非常依赖,而且重要的信息同步都是通过它完成的,官方文档对这一块的说明也不多,所以,我们对meta的分析就从这开始,当我们清晰meta中zookeeper的使用细节后,meta的内部实现原理也就基本清晰了。
meta里使用zookeeper最典型的就是类ZKLoadRebalanceListener的 rebalance()方法,该方法使用到了很多zookeeper的znode,下面我们对这个方面做一个详细介绍:
rebalance方法是用来计算某消息消费者具体应该消费哪个meta服务器节点上的哪些分区中的消息(也就是“消费者的负载平衡”)。该方面在下面两种情况下被触发:
- 监视同一个消费者分组的consumer列表是否有变化;
- 监视订阅的topic下的broker节点是否有新增或删除;
当上面两种情况发生时,zookeeper的机制会自动触发到rebalance方法,它的具体算法如下:
1.从zookeeper的'/meta/consumers/某消费者组/ids/某消费者id'节点上获取该消费者的所有订阅了的主题;
2.从zookeeper的'/meta/brokers/ids'节点上获取所有的broker列表;
3.从zookeeper的'/meta/consumers/某消费者组/ids/'、'/meta/consumers/某消费者组/ids/某消费者id'这两个节点中获得每个topic下有哪些消费者;
4.从zookeeper的'/meta/brokers/topics/某topic'节点获得对应topic在broker(包括:master和slaves)里有哪些partition;
5.从上面获得的所有这些信息,调用类ZKLoadRebalanceListener中getRelevantTopicMap方法,判断最新的partition列表或consumer列表和当前在用的是否有变化,如果没有变化则再补充做一个动作(因为虽然partition和consumer都没有新增或删除,但可能cluster的结构发生变化了):对集群做一个比较,看是否有机器down或新增;如果没有变化则继续进行后续rebalance操作;
6.如果经过上面的操作确认相关partition列表或consumer列表有变化,则根据'负载均衡策略'获取某个consumer对应的partition列表,然后根据之前老的和最新的partition列表做相关操作,如新分区在zookeeper上的挂载、释放等操作;
上面是client端一个比较重要的功能,也是zookeeper在meta里一个用的较多的地方。
Meta的HA
HA是任何进入生产环境的软件都需要考虑的一个重要因素,meta提供两种HA的方式:同步和异步(推荐使用异步方式)。
官方提供的文档里已经很清晰说明了HA的场景,这里我们再补充一些官方文档中未详细说明的部分:
- meta采用冷备方式来实现HA,任何主、备的切换都得重启相关broker。
- 任何时候只有master可以执行写操作;实现代码在BrokerConnectionListener类的syncedUpdateBrokersInfo方法,该方法从zookeeper上同步最新的master列表供producer使用。
- client可以连接cluster上的任何一台机器包括master和slave,作为它的消息来源,类似数据库的读写分离。
- 如果master因为某种原因当机,则必须手动停止某台slave并对它进行相关配置操作,并启动它使它成为新的master。当那台坏了的master修复后,它将作为一台新的slave加入集群。
- 在master上不停机的情况下新增一个topic,这个新增的topic不能自动的同步到slave上,必须通过某种方式把master上的server.ini同步到所有slave上,然后通过人工重启或通过jmx重启slave。
同步HA的切换过程:
生产环境中有一台master和一个同步slave,slave是不注册到zookeeper上的,当master当机,则所有连接到该broker的生产者和消费者都停止正常工作。然后人工停止slave,并新增samsa_master.properties配置文件,修改其中recoverOffset属性为true。并且修改server.ini中的brokerId为故障master的id,这些修改做完后,重启slave。这样它就成为新的master对外提供服务了。
Meta的transaction实现
对事务的支持是meta的一个重要特点,目前它支持XA和本地事务,下面我们详细对XA事务进行分析,由于本地事务相对简单,可以参考XA的实现。
分布式事务(XA)
分布式事务介绍
分布式事务在分布式应用中是非常重要的,目前分布式事务的实现标准是XA,而在java体系中就是JTA标准。下面是XA的一个示意图:

这里我们重点说一下两阶段提交协议(2PC),它是XA的核心思想,具体示意图如下:

具体更多关于XA的细节请参考XA的接口规范。
meta的实现
meta里事务的实现主要是如下几个类:
- TransactionalCommandProcessor:事务命令处理器。它主要作用是接收client端发过来的各种请求,如beginTransaction、prepare、commit、rollback、新增消息等。
- JournalTransactionStore:基于文件方式的事务存储引擎。
- JournalStore:具体存储事务的文件存储类。
它们3者之间的关系是:TransactionalCommandProcessor接收client端的各种事务请求,然后调用JournalTransactionStore进行事务存储,JournalTransactionStore根据不同的client请求调用JournalStore具体保存事务信息到磁盘文件。
下面通过一个示意图来进一步进行说明:

client通过调用beginTransaction来新开始一个事务(在meta里就是一个Tx实例),并把它放在JournalTransactionStore类的inflightTransactions队列里,然后client就可以在这个Tx中新增消息,但这些新增的消息是放在JournalStore文件里,并且完整的保存在内存中(由于meta目前没有专门的内存管理机制,当事务数量特别大的时候,这个地方有可能会出现内存溢出)。当client进行2PC中的prepare时,事务从inflightTransactions队列移到preparedTransactions队列,并保存相关信息到JournalStore。当执行commit时,该Tx的所有消息才真正放到MessageStore里供消息消费者读取。当client端发起rollback请求后,Tx被从preparedTransactions队列中删除,并保存相关信息到JournalStore。
下面我们对meta事务实现的几个重要方面做一个详细介绍:
beginTransaction
当client端的TransactionContext(XAResource的实现)调用start方法,broker接收到请求后,启动一个新事务。
新增消息
处理序列图如下:

当事务begin后,client端向broker发送多条消息存储的请求,broker收到请求后会调用JournalTransactionStore的addMessage方法。该方法把请求存储在事务日志文件中(JournalStore),同时新建或找到对应的Tx实例,把这些消息存储请求保存在内存中。这里注意一点,在事务没有提交之前,这些消息存储是不会被放到对应topic消息存储文件中去的。
prepare的处理过程
处理序列图如下:

prepare的处理过程相对简单些,它只是把Tx实例从JournalTransactionStore类的inflightTransactions中移除到preparedTransactions中,同时在事务日志文件存储相关信息。
commit的处理过程
处理序列图如下:

commit过程相当复杂点。broker收到client端的commit请求,调用JournalTransactionStore的commit方法,从preparedTransactions里找到对应的Tx,把该Tx里的所有请求命令(PutCommand),按照topic和分区分别保存到真正的topic消息存储文件中去,当全部保存完时,就会通过回调类AppendCallback的appendComplete方法记录commit日志到事务日志文件。
recover的处理过程
处理序列图如下:

recover操作发生在系统重启的时候,主要是为了还原系统上一次停止时候的事务场景,如还原处在prepare阶段的事务,rollback所有本地事务和没有prepare的XA事务。recover的处理细节包括两部分:
- 在JournalTransactionStore的构造函数中进行JournalStore的recover操作
JournalStore的recover主要是完成从事务日志文件中按照最近的checkpoint从日志中读取所有的日志记录,并按照记录的类型APPEND_MSG和TX_OP分别进行还原操作:
APPEND_MSG类型
这种类型的日志记录就调用JournalTransactionStore的addMessage方法,但是不会往日志文件中重复记录该消息了。
TX_OP类型
这种类型的处理相当复杂点。它根据日志记录的类型又细分为下面几种
XA_PREPARE:根据TransactionId把对应的Tx实例从JournalTransactionStore类的inflightTransactions中移到preparedTransactions中。
XA_COMMIT和LOCAL_COMMIT:根据TransactionId从JournalTransactionStore类的inflightTransactions或preparedTransactions中找到对应的Tx实例。把该Tx内的所有消息请求对比相应topic消息存储文件中消息,如果topic消息存储文件中不存在这些消息则新增,如果存在则通过crc32校验码进行比对。
LOCAL_ROLLBACK和XA_ROLLBACK:根据TransactionId把对应的Tx实例从JournalTransactionStore类的inflightTransactions或preparedTransactions中删除。
在TransactionalCommandProcessor的init方法中调用JournalTransactionStore类的recover操作
经过上面的recover操作后,它已经把meta重启前的事务现场在JournalTransactionStore和JournalStore中进行了还原。接下来就是TransactionalCommandProcessor类的事务现场还原,这个过程是把JournalTransactionStore类的preparedTransactions中的所有Tx在TransactionalCommandProcessor中进行还原,该过程相对简单,可参考源码实现。
经过上面这些recover步骤后,meta作为XAResource就可以继续加入XA事务了。
2012年11月23日
Meta相比于kafka的一个重要特性就是消息高可用方案的实现,我们称之为HA方案。消息在发送到broker之后立即写入磁盘才返回客户端告诉消息生产者消息发送成功,通过unflushThreshold和unflushInterval两个参数的控制,可以保证单机消息数据的安全性,只要机器的磁盘没有永久损坏,消息总可以在重启后恢复并正常投递给消费者们。但是,如果遇到了磁盘永久损坏或者数据文件永久损坏的情况,那么该broker上的消息数据将可能永久丢失。为了防止这种情况的发生,一个可行的方案就是将消息数据复制到多台机器,类似mysql的主从复制功能。
同步复制和异步复制
meta提供类似mysql主从复制的异步复制和同步功能,分别对应不同的可靠级别。理论上说同步复制能带来更高的可靠级别,异步复制因为延迟的存在,可能会丢失极少量的消息数据,相应地,同步复制会带来性能的损失,因为要同步写入两台甚至更多的broker机器上才算写入成功。
在实际实践中,**我更推荐采用异步复制的架构**,因为异步复制的架构相对简单,并且易于维护和恢复,对性能也没有影响。而同步复制对运维要求相对很高,机制复杂容易出错,故障恢复也比较麻烦。**异步复制加上磁盘做磁盘阵列**,足以应对非常苛刻的数据可靠性要求。
异步复制配置
假设你已经根据如何开始这份文档配置了一台broker服务器,并且配置了一个topic为test,现在你希望test能复制到另一台slave broker上来保证消息数据的高可用。你可以这样做:
1.首先,你需要部署一个新的broker,具体仍然参照如何开始这份文档,配置server.ini从master broker拷贝一份。
2.其次,配置slave文件。编辑conf/async_slave.properties:
#slave编号,大于等于0表示作为slave启动,同一个master下的slave编号应该设不同值.
slaveId=0
#作为slave启动时向master订阅消息的group,如果没配置则默认为meta-slave-group
#不同的slaveId请使用不同的group
slaveGroup=meta-slave-group
#slave数据同步的最大延时,单位毫秒
slaveMaxDelayInMills=500
#是否自动从master同步server.ini, 1.4.2新增选项
#第一次仍然需要自己拷贝server.ini,后续可以通过设置此选项为true来自动同步
autoSyncMasterConfig=true
配置参数的含义请自己看注释。可见,一个master可以复制到多个slave。
3.执行下列命令启动slave:
bin/metaServer.sh start slave
4.第一次复制因为需要跟master完全同步需要耗费一定时间,你可以在数据文件的目录观察复制情况。
5.**请注意,异步复制的slave将参与消费者的消费活动,消息消费者可以从slave中获取消息并消费,消费者会随机从master和slaves中挑选一台作为消费broker。**
6.**请注意,从1.4.2开始,可以通过autoSyncMasterConfig选项配置是否自动同步master的server.ini到异步复制的slave上,当master的server.ini文件变更并通过bin/metaServer.sh reload之后,slave将监控到这一变更并自动同步。**
异步复制的局限
- 异步复制有延迟,虽然可以通过设定
slaveMaxDelayInMills来控制延迟。
异步复制的故障处理
- Master永久故障: 将slave作为master启动,去除启动参数中的slave即可,也就是
metaServer.sh restart
- Slave永久故障: 启动新的broker并配置作为master新的slave启动。
同步复制配置
Meta假定producer、broker和consumer都是分布式的集群系统。
Producer可以是一个集群,多台机器上的producer可以往同一个topic发送消息。
Meta的服务器broker一般也是一个集群,多台broker组成一个集群提供一些topic服务,生产者按照一定的路由规则往集群里某台broker发送消息,消费者按照一定的路由规则拉取某台broker上的消息。
Consumer也可以组织成一个集群来消费同一个topic,发往这个topic的消息按照一定的路由规则发送到consumer集群里的某一台机器。Consumer集群每个consumer必须拥有相同的分组名称。
Broker集群配置
Broker集群配置非常容易,假设你已经按照如何开始和服务器配置管理配置好并启用了你第一台broker,某一天你发现这个单台broker无法支撑更大的消息量,那么你可能就需要引入更多的broker作为集群来提供服务,你要做的事情很简单:
- 拷贝broker1的配置文件
conf/server.ini到新的broker,假设为broker2。 - 修改broker2的server.ini,只要修改brokerId为另一个不同于broker1的值即可
- 启动broker2,这样一来broker2将和broker1组成一个服务器集群
- 在这个过程中你不需要重启任何现有的服务,包括生产者、消费者和broker1,他们都将自动感知到新的broker2
可见,配置一个集群唯一要做的就是使用同一份配置文件并定义不同的brokerId即可。
负载均衡
负载均衡和failover分不开,我们将分别讨论下生产者和消费者的负载均衡策略。我们先假定broker是一个集群,这样每个topic必定有多个分区。
生产者的负载均衡和failover
每个broker都可以配置一个topic可以有多少个分区,但是在生产者看来,一个topic在所有broker上的的所有分区组成一个分区列表来使用。
在创建producer的时候,客户端会从zookeeper上获取publish的topic对应的broker和分区列表,生产者在发送消息的时候必须选择一台broker上的一个分区来发送消息,默认的策略是一个轮询的路由规则,一张图来表示
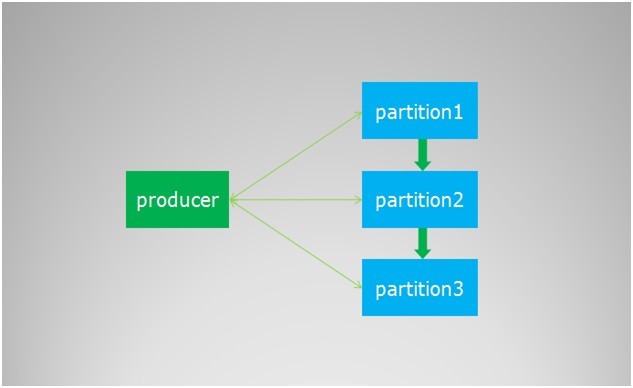
生产者在通过zk获取分区列表之后,会按照brokerId和partition的顺序排列组织成一个有序的分区列表,发送的时候按照从头到尾循环往复的方式选择一个分区来发送消息。考虑到我们的broker服务器软硬件配置基本一致,默认的轮询策略已然足够。
如果你想实现自己的负载均衡策略,可以实现上文提到过的PartitionSelector接口,并在创建producer的时候传入即可。
在broker因为重启或者故障等因素无法服务的时候,producer通过zookeeper会感知到这个变化,将失效的分区从列表中移除做到fail over。因为从故障到感知变化有一个延迟,可能在那一瞬间会有部分的消息发送失败。
消费者的负载均衡
消费者的负载均衡会相对复杂一些。我们这里讨论的是单个分组内的消费者集群的负载均衡,不同分组的负载均衡互不干扰,没有讨论的必要。 消费者的负载均衡跟topic的分区数目紧密相关,要考察几个场景。 首先是,单个分组内的消费者数目如果比总的分区数目多的话,则多出来的消费者不参与消费,如图
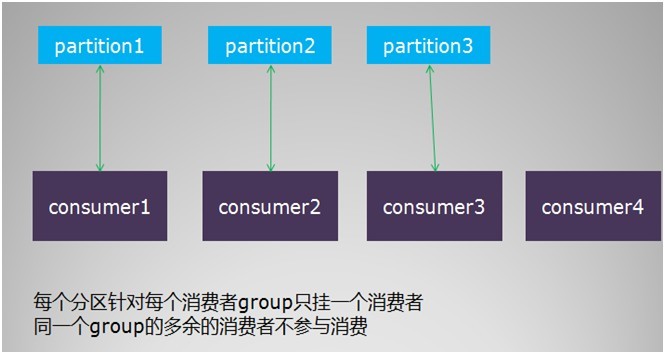
其次,如果分组内的消费者数目比分区数目小,则有部分消费者要额外承担消息的消费任务,具体见示例图如下

综上所述,单个分组内的消费者集群的负载均衡策略如下
- 每个分区针对同一个group只挂载一个消费者
- 如果同一个group的消费者数目大于分区数目,则多出来的消费者将不参与消费
- 如果同一个group的消费者数目小于分区数目,则有部分消费者需要额外承担消费任务
Meta的客户端会自动帮处理消费者的负载均衡,它会将消费者列表和分区列表分别排序,然后按照上述规则做合理的挂载。
从上述内容来看,合理地设置分区数目至关重要。如果分区数目太小,则有部分消费者可能闲置,如果分区数目太大,则对服务器的性能有影响。
在某个消费者故障或者重启等情况下,其他消费者会感知到这一变化(通过 zookeeper watch消费者列表),然后重新进行负载均衡,保证所有的分区都有消费者进行消费。
示例配置
示例文件存放位置: metaq文件目录/conf/sample.server.ini服务端配置
Meta服务端配置主要在服务器conf目录下的server.ini文件,整体配置分为三部分:系统参数、zookeeper参数以及topic配置。系统参数在system section,zookeeper参数配置在zookeeper section,而topic的配置是在topic=xxxx section。具体说明如下:
系统参数部分
系统参数配置都放在[system]下面:
- brokerId: 服务器集群中唯一的id,必须为整型0-1024之间。对服务器集群的定义是使用同一个zookeeper并且在zookeeper上的root path相同,具体参见zookeeper配置。
hostName: 服务器hostname,默认取本机IP地址,如果你是多网卡机器,可能需要明确指定。服务器会将此hostname加上端口写入到zookeeper提供给客户端发现。
serverPort:服务器端口,默认8123。PS. 选择8123是因为这蕴含着作者儿子的生日。
numPartitions:系统默认情况下每个topic的分区数目,默认为1,可被topic配置覆盖。单个服务器的总分区数目不建议超过1000,太多将导致频繁的磁盘寻道严重影响IO性能。
dataPath: 服务器数据文件路径,默认在~home/meta下,每个topic可以覆盖此配置,对于多块磁盘的机器,可设置不同topic到不同磁盘来提升IO效率。
dataLogPath:数据日志文件路径,主要存放事务日志,默认跟dataPath一致,最好单独设置到不同的磁盘或者目录上。如果为空,使用指定的dataPath
getProcessThreadCount: 处理get请求的并发线程数,默认为CPUS*10。
putProcessThreadCount: 处理put请求的并发线程数,默认为CPUS*10。
maxSegmentSize: 单个数据文件的大小,默认为1G。默认无需修改此选项。
maxTransferSize: 传输给消费者的最大数据大小,默认为1M,请根据你的最大消息大小酌情设置,如果太小,每次无法传输一个完整的消息给消费者,导致消费者消费停滞。可设置成一个大数来取消限制。
1.4.3引入的新参数:
acceptPublish: 是否接收消息,默认为true;如果为false,则不会注册发送信息到zookeeper上,客户端当然无法发送消息到该broker。本参数可以被后续的topic配置覆盖。
acceptSubscribe: 与acceptPublish类似,默认也为true;如果为false,则不会注册消费信息到zookeeper上,消费者无法发现该broker,当然无法从该broker消费消息。本参数可以被后续的topic配置覆盖。
数据可靠性参数
Meta保证消息可靠性是建立在磁盘可靠性的基础上,发送的每一条消息都保证是在“写入磁盘”的情况下才返回给客户端应答。这里有两个关键参数可以控制:
- unflushThreshold: 每隔多少条消息做一次磁盘sync,强制将更改的数据刷入磁盘。默认为1000。也就是说在掉电情况下,最多允许丢失1000条消息。可设置为0,强制每次写入都sync。在设置为0的情况下,服务器会自动启用group commit技术,将多个消息合并成一次sync来提升IO性能。经过测试,group commit情况下消息发送者的TPS没有受到太大影响,但是服务端的负载会上升很多。
- unflushInterval: 间隔多少毫秒定期做一次磁盘sync,默认是10秒。也就是说在服务器掉电情况下,最多丢失10秒内发送过来的消息。不可设置为小于或者等于0。
请注意,上述两个参数都可以被topic单独配置说覆盖,也就是说每个topic可以配置不同的数据可靠级别。
数据删除策略配置
默认情况下,meta是会保存不断添加的消息,然后定期对“过期”的数据进行删除或者归档处理,这都是通过下列参数控制的:
deleteWhen: 何时执行删除策略的cron表达式,默认是 0 0 6,18 * * ? ,也就是每天的早晚6点执行处理策略。- deletePolicy: 数据删除策略,默认超过7天即删除,这里的168是小时,10s表示10秒,10m表示10分钟,10h表示10小时,不明确指定单位默认为小时。
delete是指删除,超过指定时间的数据文件将被彻底从磁盘删除。也可以选择archive策略,即不对过期的数据文件做删除而是归档,当使用archive策略的时候可以选择是否压缩数据文件,如167,archive,true即选择将更改时间超过7天的数据文件归档并压缩为zip文件,如果不选择压缩,则重命名为扩展名为arc的文件。
上述两个参数都可以被topic单独配置所覆盖,也就是每个topic可以指定自己独特的删除策略。通常来说,对于不重要的topic可以将更早地将他们删除来节省磁盘空间。
事务相关配置
- maxCheckpoints: 最大保存事务checkpoint数目,默认为3,服务器在启动的时候会从最近一次checkpoint回访事务日志文件,恢复重启前的事务状态。不建议修改此参数。
- checkpointInterval:事务checkpoint时间间隔,单位毫秒,默认1小时。间隔时间太长,会导致启动的时候replay事务日志占用了太多时间,太短则可能影响到性能。
- maxTxTimeoutTimerCapacity:最大事务超时timer的数量。服务端会为每个事务启动一个定时器监控事务是否超时,定时器的数目上限通过本参数限制。限制了本参数,也变相地控制了最大可运行的事务数。默认为30000个。
- maxTxTimeoutInSeconds:最大事务超时时间,单位为秒,默认为60秒。客户端设置的事务超时时间不能超过此设定,超过将被强制限制为此设定。
- flushTxLogAtCommit:服务端对事务日志的sync策略,0表示让操作系统决定,1表示每次commit都刷盘,2表示每隔1秒刷盘一次。此参数严重影响事务性能,可根据你需要的性能和可靠性之间权衡做出一个合理的选择。通常建议设置为2,表示每隔1秒刷盘一次,也就是最多丢失一秒内的运行时事务。这样的可靠级别对大多数服务是足够的。最安全的当然是设置为1,但是将严重影响事务性能。而0的安全级别最低。安全级别上
1>=2>0,而性能则是0 >= 2 > 1。
zookeeper配置
meta服务端会将自身id,topic信息和socket地址发送到zookeeper上,让客户端可以发现并连接服务器。Zookeeper相关的配置放在[zookeeper]模块下面:
- zk.zkEnable: 是否启用zookeeper,也就是是否将信息注册到zookeeper上。默认为true。对于同步复制的slave来说,本参数会被强制设置为false。
- zk.zkConnect: zookeeper服务器列表,例如
localhost:1281这样的字符串。默认也是localhost:2181。请设置你的zk集群地址列表。 - zk.zkSessionTimeoutMs: zookeeper的session timeout,默认为30秒。单位毫秒。
- zk.zkConnectionTimeoutMs: zookeeper的连接超时时间,默认同样为30秒,单位毫秒。
- zk.zkSyncTimeMs: 预期的zk集群间数据同步延迟,默认为5秒,这个参数对服务器无意义。
Topic配置
服务器将提供哪些topic服务都是通过topic配置来实现的,topic配置都是在[topic=xxx]的模块下面,其中xxx就是topic名称,一个示范配置如下:
[topic=meta-test]
stat=true
numPartitions=1
这里配置了一个名为meta-test的topic,并针对该topic启用实时统计,并将topic的在本服务器的分区数目设置为1。可见,topic配置可覆盖服务器的部分配置,包括:
- stat:是否启用实时统计,启用则会在服务端对该topic的请求做实时统计,可以通过stats topic-name协议观察到该topic运行状况,可选。
- numPartitions: 该topic在本服务器的分区总数,覆盖系统配置,可选。
- unflushInterval:每隔多少条消息做一次磁盘sync,覆盖系统配置,可选。
- unflushThreshold:每隔多少秒做一次磁盘sync,覆盖系统配置,可选。
- deletePolicy:topic的删除策略,覆盖系统配置,可选。
- deleteWhen:删除策略的执行时间,覆盖系统配置,可选。
- dataPath:设置数据文件路径,覆盖系统配置,可选。
1.4.3新增参数:
- acceptPublish: 是否接收该topic的消息,覆盖系统配置,可选。
- acceptSubscribe: 是否接受消费者的订阅,覆盖系统配置,可选。
新增Topic热部署
在新增或者删除topic并保存server.ini之后,可以通过下列命令热加载新的配置文件并生效: bin/metaServer.sh reload
Java客户端例子
使用maven,引用metaq的java client非常简单:
<dependency>
<groupId>com.taobao.metamorphosis</groupId>
<artifactId>metamorphosis-client-extension</artifactId>
<version>1.4.3</version>
</dependency>
也可以引用 client-extend
<dependency>
<groupId>com.taobao.metamorphosis</groupId>
<artifactId>metamorphosis-client-extension</artifactId>
<version>1.4.3</version>
</dependency>
直接用git 将metamorphosis-example clone 下载页面:https://github.com/killme2008/metamorphosis-example 。
请注意,1.4.3及以上版本的java客户端只能连接1.4.3及以上版本的MetaQ服务器,而1.4.3之前的老客户端则没有限制。主要是因为1.4.3引入了发布和订阅topic的分离,1.4.3的新客户端只能查找到新版本的broker
消息会话工厂类
在使用消息生产者和消费者之前,需要用到消息会话工厂类——MessageSessionFactory,由这个工厂帮你创建生产者或者消费者。除了这些,MessageSessionFactory还默默无闻地在后面帮你做很多事情,包括:
1.服务的查找和发现,通过diamond和zookeeper帮你查找日常的meta服务器地址列表,diamond可以忽略。
2.连接的创建和销毁,自动创建和销毁到meta服务器的连接,并做连接复用,也就是到同一台meta的服务器在一个工厂内只维持一个连接。
3.消费者的消息存储和恢复。
4.协调和管理各种资源,包括创建的生产者和消费者的。
因此,我们首先需要创建一个会话工厂类,MessageSessionFactory仅是一个接口,它的实现类常用的是MetaMessageSessionFactory:
MessageSessionFactory sessionFactory = new MetaMessageSessionFactory(new MetaClientConfig());
请注意,
MessageSessionFactory应当尽量复用,也就是作为应用中的单例来使用,简单的做法是交给spring之类的容器帮你托管。
消息生产者
package com.taobao.metamorphosis.example;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import com.taobao.metamorphosis.Message;
import com.taobao.metamorphosis.client.MessageSessionFactory;
import com.taobao.metamorphosis.client.MetaClientConfig;
import com.taobao.metamorphosis.client.MetaMessageSessionFactory;
import com.taobao.metamorphosis.client.producer.MessageProducer;
import com.taobao.metamorphosis.client.producer.SendResult;
import com.taobao.metamorphosis.utils.ZkUtils.ZKConfig;
public class Producer {
public static void main(String[] args) throws Exception {
final MetaClientConfig metaClientConfig = new MetaClientConfig();
final ZKConfig zkConfig = new ZKConfig();
//设置zookeeper地址
zkConfig.zkConnect = "127.0.0.1:2181";
metaClientConfig.setZkConfig(zkConfig);
// New session factory,强烈建议使用单例
MessageSessionFactory sessionFactory = new MetaMessageSessionFactory(metaClientConfig);
// create producer,强烈建议使用单例
MessageProducer producer = sessionFactory.createProducer();
// publish topic
final String topic = "matatest";
producer.publish(topic);
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String line = null;
while ((line = reader.readLine()) != null) {
// send message
SendResult sendResult = producer.sendMessage(new Message(topic, line.getBytes()));
// check result
if (!sendResult.isSuccess()) {
System.err.println("Send message failed,error message:" + sendResult.getErrorMessage());
}
else {
System.out.println("Send message successfully,sent to " + sendResult.getPartition());
}
}
}
}
消息生产者的接口是MessageProducer,你可以通过它来发送消息。创建生产者很简单,通过MessageSessionFactory的createProducer方法即可以创建一个生产者。在Meta里,每个消息对象都是Message类的实例,Message表示一个消息对象,它包含这么几个属性:
- id: Long型的消息id,消息的唯一id,系统自动产生,用户无法设置,在发送成功后由服务器返回,发送失败则为0。
- topic: 消息的主题,订阅者订阅该主题即可接收发送到该主题下的消息,生产者通过指定发布的topic查找到需要连接的服务器地址,必须。
- data: 消息的有效载荷,二进制数据,也就是消息内容,meta永远不会修改消息内容。消息内容通常限制在1M以内,作者的建议是最好不要发送超过上百K的消息,必须。数据是否压缩也完全取决于使用方。
- attribute: 消息属性,一个字符串,可选。生产者可通过设置消息属性来让消费者简单过滤。
在sendMessage之前必须调用 MessageProducer的publish(topic)方法
producer.publish(topic);
这一步在发送消息前是必要的,必须先发布将要发送消息的topic(另外,metaq的broker必须要先通过配置文件设置好topic,启动broker后,客户端才可能发布消息成功,不然就会报出异常),这是为了让会话工厂帮你去查找接收这些topic的meta服务器地址并初始化连接。这个步骤针对每个topic只需要做一次,多次调用无影响。
总结下这个例子,从标准输入读入你输入的数据,并将数据封装成一个Message对象,发送到[localhost:8123]服务的 topic为metatestbroker 上。
请注意,MessageProducer是线程安全的,完全可重复使用,因此最好在应用中作为单例来使用,一次创建,到处使用,配置为spring里的singleton bean。MessageProducer创建的代价昂贵,每次都需要通过zk查找服务器并创建tcp长连接。
消息消费者
发送消息后,消费者可以接收消息了,下面的代码创建异步消费者并订阅test这个主题,等待消息送达并打印消息内容
package com.taobao.metamorphosis.example;
import java.util.concurrent.Executor;
import com.taobao.metamorphosis.Message;
import com.taobao.metamorphosis.client.MessageSessionFactory;
import com.taobao.metamorphosis.client.MetaClientConfig;
import com.taobao.metamorphosis.client.MetaMessageSessionFactory;
import com.taobao.metamorphosis.client.consumer.ConsumerConfig;
import com.taobao.metamorphosis.client.consumer.MessageConsumer;
import com.taobao.metamorphosis.client.consumer.MessageListener;
import com.taobao.metamorphosis.utils.ZkUtils.ZKConfig;
public class AsyncConsumer {
public static void main(String[] args) throws Exception {
final MetaClientConfig metaClientConfig = new MetaClientConfig();
final ZKConfig zkConfig = new ZKConfig();
//设置zookeeper地址
zkConfig.zkConnect = "127.0.0.1:2181";
metaClientConfig.setZkConfig(zkConfig);
// New session factory,强烈建议使用单例
MessageSessionFactory sessionFactory = new MetaMessageSessionFactory(metaClientConfig);
// subscribed topic
final String topic = "metatest";
// consumer group
final String group = "meta-example";
// create consumer,强烈建议使用单例
MessageConsumer consumer = sessionFactory.createConsumer(new ConsumerConfig(group));
// subscribe topic
consumer.subscribe(topic, 1024 * 1024, new MessageListener() {
public void recieveMessages(Message message) {
System.out.println("Receive message " + new String(message.getData()));
}
public Executor getExecutor() {
// Thread pool to process messages,maybe null.
return null;
}
});
// complete subscribe
consumer.completeSubscribe();
}
}
通过createConsumer方法来创建MessageConsumer,请注意传入一个ConsumerConfig参数,这是消费者的配置对象。每个消息者都必须有一个ConsumerConfig配置对象,这里只设置了group属性,这是消费者的分组名称。Meta的Producer、Consumer和Broker都可以为集群。消费者可以组成一个集群共同消费同一个topic,发往这个topic的消息将按照一定的负载均衡规则发送给集群里的一台机器。同一个消费者集群必须拥有同一个分组名称,也就是同一个group。我们这里将分组名称设置为meta-example。
订阅消息通过subscribe方法,这个方法接受三个参数
- topic,订阅的主题
- maxSize,因为meta是一个消费者主动拉取的模型,这个参数规定每次拉取的最大数据量,单位为字节,这里设置为1M,默认最大为1M。
- MessageListener,消息监听器,负责消息消息。
MessageListener的接口方法如下:
public interface MessageListener {
/**
* 接收到消息列表,只有message不为空并且不为null的情况下会触发此方法
*
* @param message
*/
public void recieveMessages(Message message);
/**
* 处理消息的线程池
*
* @return
*/
public Executor getExecutor();
}
消息的消费过程可以是一个并发处理的过程,getExecutor返回你想设置的线程池,每次消费都会在这个线程池里进行。recieveMessage方法用于实际的消息消费处理,message参数即为消费者收到的消息,它必不为null。
这里简单地打印收到的消息内容就完成消费。如果在消费过程中抛出任何异常,该条消息将会在一定间隔后重新尝试提交给MessageListener消费。在多次消费失败的情况下,该消息将会存储到消费者应用的本次磁盘,并在后台自动恢复重试消费。
在调用subscribe之后,我们还调用了completeSubscribe方法来完成订阅过程。请注意,subscribe仅是将订阅信息保存在本地,并没有实际跟meta服务器交互,要使得订阅关系生效必须调用一次completeSubscribe,completeSubscribe仅能被调用一次,多次调用将抛出异常。 为什么需要completeSubscribe方法呢,原因有二:
- 首先,subscribe方法可以被调用多次,也就是一个消费者可以消费多种topic
- 其次,如果每次调用subscribe都跟zk和meta服务器交互一次,代价太高
因此completeSubscribe一次性将所有订阅的topic生效,并处理跟zk和meta服务器交互的所有过程。
同样,MessageConsumer也是线程安全的,创建的代价不低,因此也应该尽量复用。
2012年11月22日
1、首先下载最新版本https://github.com/killme2008/Metamorphosis/downloads
2、下载后解压缩
tar -zxvf metamorphosis-server-wrapper-x.x.x.x.tar.gz
3、解压缩后,文件结构如下:
启动脚本放在bin目录,主要的脚本是metaServer.sh,而配置文件主要是conf目录下server.ini,lib存放所有的依赖jar包。
taobao
--metamorphosis-server-wrapper
--bin
env.bat
env.sh
log4j.properties
metaServer.bat
metaServer.sh
tools_log4j.properties
--conf
async_slave.properties
gregor_slave.properties
jettyBroker.properties
notifyadaper
notifySlave.properties
sample.server.ini
samsa_master.properties
server.ini
timetunnel.properties
--lib
4、zookeeper依赖
metamorphosis 必须要依赖zookeeper,也就是说要想启动meta,不能没有zookeeper,使用zookeeper发布和订阅服务,并默认使用zookeeper存储消费者offset 。虽然conf/server.ini 中有这样的说明
;zk配置
[zookeeper]
;是否注册到zk,默认为true
;zk.zkEnable=true
但是笔者尝试将zkEnable属性设置为false,metamorphosis可以启动。但是在client端程序也没找到相应地不依赖于zookeeper的meta的调用方式(可能需要自己实现客户端)。于是乎,还是要下载zookeeper, 如何配置和启动zookeeper,详见地址
假设你在本机安装并启动了一个zookeeper,端口在默认的2181,请修改conf/server.ini文件,保证zookeeper地址正确
;zk的服务器列表
zk.zkConnect=localhost:2181
;zk心跳超时,单位毫秒,默认30秒
zk.zkSessionTimeoutMs=30000
;zk连接超时时间,单位毫秒,默认30秒
zk.zkConnectionTimeoutMs=30000
;zk数据同步时间,单位毫秒,默认5秒
zk.zkSyncTimeMs=5000
其它重要参数,详情见服务器配置
http://www.blogjava.net/livery/articles/391800.htmlbrokerId 服务器唯一标志,必须要有,不能重复
dataPath 指定数据文件路径,默认user.home/meta
dataLogPath 日志文件路径,默认跟dataPath一样
numPartitions 默认topic的分区数目
hostName 服务器hostname,可以为空,默认将取本机IP
serverPort 服务器端口 默认8123
其它具体参数信息请看conf/sample_server.ini示范文件。
5、启动、重启、关闭、检查运行状态
确保你的机器上安装了JDK并正确设置JAVA_HOME和PATH变量。
修改JAVA_HOME,JMX等变量,请修改 bin/env.sh 。
启动服务: bin/metaServer.sh start
重启服务:
bin/metaServer.sh restart
关闭服务:
bin/metaServer.sh stop
查询服务状态
bin/metaServer.sh stats
查询结果
也可以telnet到默认的8123端口执行stats命令查看。 STATS
pid 16637
broker_id 1001
port 8123
uptime 11604
version 1.4.3
slave false
curr_connections 1
threads 125
cmd_put 2050
cmd_get 946
cmd_offset 0
tx_begin 0
tx_xa_begin 0
tx_commit 0
tx_rollback 0
get_miss 944
put_failed 0
total_messages 2050
topics 3
config_checksum 2176933603
END
2012年11月19日
准备替换掉现实服务中使用的activemq,又开始调研消息队列。初步选中metaQ和ZeroMQ,因为这两款听人介绍得很多,耳朵都快出茧子了。
简单研究后,发现这两个消息队列的不同之处太多,不太适合用来对比。ZeroMQ和metaQ都是支持多语言客户端,性能都很好;相对于activemq这种企业级使用的消息队列,提高了消息的处理性能 ,尽量弱化broker 的功能,而ZeroMQ比较极致,甚至去掉了单独broker,采用类库依赖,客户端实现逻辑。
metaQ 的基础逻辑是消息生产者负责创建消息并发送到metaQ 服务器,meta服务器会将消息持久化到磁盘,消息消费者从metaQ服务器拉取消息并提交给应用消费 。与activemq相比弱化了broker的功能,将消息的消费保存、出错、重试等机制都尽可能放在了客户端上;使broker的处理逻辑尽量简单,来提高数据传输和处理的速度。metaQ还支持XA事务;当然XA事务还不是很成熟,另外事务还是对性能有一点影响的。
ZeroMQ并不像是一个传统意义上的消息队列服务器,事实上,它也根本不是一个服务器,它更像是一个底层的网络通讯库,在Socket API之上做了一层封装,将网络通讯、进程通讯和线程通讯抽象为统一的API接口。。所以它的性能也很好,相比metaQ来说,需要自己来实现大量的容错机制的代码。
硬件配置
metaq服务器(activemq也在其中)
型号 DELL 510
CPU Intel(R)Xeon(R) CPU E5606 @ 2.13GHz *4
Mem 12G
网卡 100M
客户端服务器
型号 DELL 710
CPU Intel(R)Xeon(R) CPU E5606 @ 2.13GHz *8
Mem 8G
网卡 100M
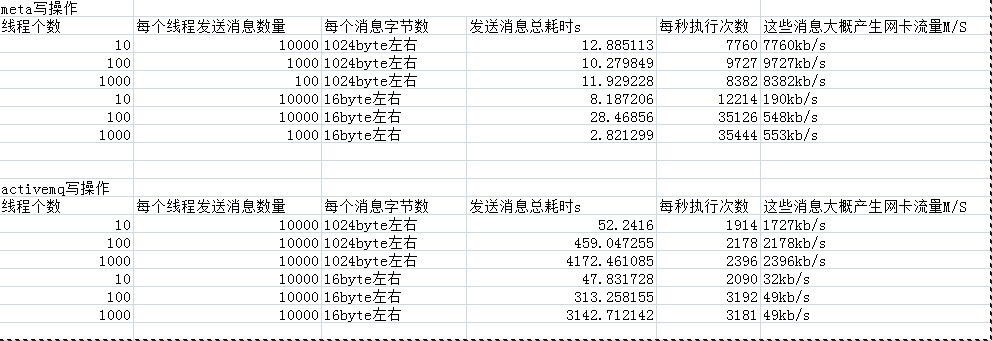
例子和相关源码稍后再补充
MessageSessionFactory接口
常用实现类 MetaMessageSessionFactory
MessageProducer接口
常用实现类SimpleMessageProducer
PartitionSelector接口
分区选择器,用于从分区列表中选中将要发送消息的分区。
主要实现类,轮询分区选择器 RoundRobinPartitionSelector
客户端可自定义分区选择器,并在创建生产者的时候注入
SendResult类
发送结果消息类
MessageConsumer接口
主要实现类SimpleMessageConsumer
MessageListener接口
消息监听器,处理消费消息
OffsetStorage接口
offset存储器
默认提供下列三种存储器
1、ZkOffsetStorage 存储在zookeeper
2、MysqlOffsetStorage 存储在mysql数据库
3、LocalOffsetStorage 存储在本地文件,适合消费者分组只有一个消费者的情况,无需共享offset信息。
用户可以自定义实现自己存储器。
客户端最佳实践
复用MessageSessionFactory,最好作为全局单例来使用。
生产者最佳实践
- 尽量复用MessageProducer,最好也是使用单例。可以单个MessageProducer发送多个topic,或者多个MessageProducer每个发送一种topic,尽量减少重复创建producer。
- 消息data的序列化方式锦衣不要使用特定语言的序列化方式(如java序列化),可以考虑 自定义协议、json、protocolbuffer、hessian等序列化协议,以便跨语言消费。
- 实现发送顺序所需要的PartitionSelector,推荐使用业务id。如:交易订单id来取模,分区列表选择固定分区发送。
- 单条消息大小最好限制在100k以下。
- 如无顺序等特殊需求,不要实现自己的PartitionSelector,默认的轮询策略足够。
消费者最佳实践- 尽量复用MessageConsumer,最好也是使用单例。可以单个MessageConsumer订阅多种topic,或者多个MessageConsumer每个订阅一种topic,尽量减少重复创建consumer。
- 单次拉取的数据不宜过大。如果对消息实时性要求较高的应用,应将单次拉取的数据缩小,但至少要大于单条消息的大小。如果对吞吐量要求较高,可以将该值设置大一些。
- 假设消费过程非常轻量级(如:只是打印log),可以不设置MessageListener线程池,减少资源耗费。
- 假设消息发送量巨大,消费能力不高,可适当提高拉取消息线程数 fetchRunnerCount和MessageListener的线程池大小。
- 尽量在消息的消费过程中,扑捉所有异常,减少消息在本地的堆积和恢复,前提是不要遗漏消息。如确实无法处理,请主动抛出异常,以便重试。
2012年11月12日
最近开始调研metamorphosis,官方文档很是详尽。于是边学习边做笔记。
基本概念
消息生产者
也称为Message Producer,一般简称为producer,负责产生消息并发送消息到meta服务器。
消息消费者
也称为Message Consumer,一般简称为consumer,负责消息的消费,meta采用pull模型,由消费者主动从meta服务器拉取数据并解析成消息并消费。
Topic
消息的主题,由用户定义并在服务端配置。producer发送消息到某个topic下,consumer从某个topic下消费消息。
分区(partition)
同一个topic下面还分为多个分区,如meta-test这个topic我们可以分为10个分区,分别有两台服务器提供,那么可能每台服务器提供5个分区,假设服务器分别为0和1,则所有分区为0-0、0-1、0-2、0-3、0-4、1-0、1-1、1-2、1-3、1-4。分区跟消费者的负载均衡机制相关。
Message
消息,负载用户数据并在生产者、服务端和消费者之间传输。
Broker
就是meta的服务端或者说服务器,在消息中间件中也通常称为broker。
消费者分组(Group)
消费者可以是多个消费者共同消费一个topic下的消息,每个消费者消费部分消息。这些消费者就组成一个分组,拥有同一个分组名称,通常也称为消费者集群
Offset
消息在broker上的每个分区都是组织成一个文件列表,消费者拉取数据需要知道数据在文件中的偏移量,这个偏移量就是所谓offset。Offset是绝对偏移量,服务器会将offset转化为具体文件的相对偏移量。
可靠性
Metamorphosis的可靠性保证贯穿客户端和服务器。
生产者的可靠性保证
消息生产者发送消息后返回SendResult,如果isSuccess返回为true,则表示消息已经确认发送到服务器并被服务器接收存储。整个发送过程是一个同步的过程。保证消息送达服务器并返回结果。
服务器的可靠性保证
消息生产者发送的消息,meta服务器收到后在做必要的校验和检查之后的第一件事就是写入磁盘,写入成功之后返回应答给生产者。因此,可以确认每条发送结果为成功的消息服务器都是写入磁盘的。
写入磁盘,不意味着数据落到磁盘设备上,毕竟我们还隔着一层os,os对写有缓冲。Meta有两个特性来保证数据落到磁盘上
- 每1000条(可配置),即强制调用一次force来写入磁盘设备。
- 每隔10秒(可配置),强制调用一次force来写入磁盘设备。
因此,Meta通过配置可保证在异常情况下(如磁盘掉电)10秒内最多丢失1000条消息。当然通过参数调整你甚至可以在掉电情况下不丢失任何消息。
服务器通常组织为一个集群,一条从生产者过来的消息可能按照路由规则存储到集群中的某台机器。Meta已经实现高可用的HA方案,类似mysql的同步和异步复制,将一台meta服务器的数据完整复制到另一台slave服务器,并且slave服务器还提供消费功能(同步复制不提供消费)。
消费者的可靠性保证
消息的消费者是一条接着一条地消费消息,只有在成功消费一条消息后才会接着消费下一条。如果在消费某条消息失败(如异常),则会尝试重试消费这条消息(默认最大5次),超过最大次数后仍然无法消费,则将消息存储在消费者的本地磁盘,由后台线程继续做重试。而主线程继续往后走,消费后续的消息。因此,只有在MessageListener确认成功消费一条消息后,meta的消费者才会继续消费另一条消息。由此来保证消息的可靠消费。
消费者的另一个可靠性的关键点是offset的存储,也就是拉取数据的偏移量。我们目前提供了以下几种存储方案
- zookeeper,默认存储在zoopkeeper上,zookeeper通过集群来保证数据的安全性。
- mysql,可以连接到您使用的mysql数据库,只要建立一张特定的表来存储。完全由数据库来保证数据的可靠性。
- file,文件存储,将offset信息存储在消费者的本地文件中,适合消费者分组只有一个消费者的情况,无需共享offset信息。
Offset会定期保存,并且在每次重新负载均衡前都会强制保存一次。
顺序
很多人关心的消息顺序,希望消费者消费消息的顺序跟消息的发送顺序是一致的。比如,我发送消息的顺序是A、B、C,那么消费者消费的顺序也应该是A、B、C。乱序对某些应用可能是无法接受的。
Metamorphosis对消息顺序性的保证是有限制的,默认情况下,消息的顺序以谁先达到服务器并写入磁盘,则谁就在先的原则处理。并且,发往同一个分区的消息保证按照写入磁盘的顺序让消费者消费,这是因为消费者针对每个分区都是按照从前到后递增offset的顺序拉取消息。
Meta可以保证,在单线程内使用该producer发送的消息按照发送的顺序达到服务器并存储,并按照相同顺序被消费者消费,前提是这些消息发往同一台服务器的同一个分区。为了实现这一点,你还需要实现自己的PartitionSelector用于固定选择分区
public interface PartitionSelector {
public Partition getPartition(String topic, List<Partition> partitions, Message message) throws MetaClientException;
}
选择分区可以按照一定的业务逻辑来选择,如根据业务id来取模。或者如果是传输文件,可以固定选择第n个分区使用。当然,如果传输文件,通常我们会建议你只配置一个分区,那也就无需选择了。
消息的顺序发送可以使用这个OrderedMessageProducer,自定义管理分区信息,并提供故障情况下的本地存储功能。
消息重复
消息的重复包含两个方面,生产者重复发送消息以及消费者重复消费消息。
针对生产者来说,有可能发生这种情况,生产者发送消息,等待服务器应答,这个时候发生网络故障,服务器实际已经将消息写入成功,但是由于网络故障没有返回应答。那么生产者会认为发送失败,则再次发送同一条消息,如果发送成功,则服务器实际存储两条相同的消息。这种由故障引起的重复,meta是无法避免的,因为meta不判断消息的data是否一致,因为它并不理解data的语义,而仅仅是作为载荷来传输。
针对消费者来说也有这个问题,消费者成功消费一条消息,但是此时断电,没有及时将前进后的offset存储起来,则下次启动的时候或者其他同个分组的消费者owner到这个分区的时候,会重复消费该条消息。这种情况meta也无法完全避免。
Meta对消息重复的保证只能说在正常情况下保证不重复,异常情况无法保证,这些限制是由远程调用的语义引起的,要做到完全不重复的代价很高,meta暂时不会考虑。
2012年10月23日
苹果基本授权原理:
为了防止盗版,苹果在所有的iPhone软件中也加入了DRM内容数字版权加密保护技术。类似于iTunes媒体文件,每一个IPA软件都带有DRM。安装程序时,若发现电脑未授权,即私钥不存在,安装程序就会自动终止。若发现授权账号和购买账号不一致,即公钥与私钥不相匹配,安装程序也会自动终止。如果通过某种方法将软件直接塞进设备,运行程序的结果将会是自动退出,ios6开始弹出账号,请求输入账号和密码。这就是数字签名验证。
因此,路人甲购买的软件除了有他账号的人可以使用之外,其他任何人都使用不了(因此想要分享自己购买的软件,分享之前一定要把IPA破解掉)。这样一来,苹果就最大程度上减少了盗版的可能性。
破解软件说明:
破解软件实际上就是去除了DRM保护的软件。破解软件的过程就是去除软件DRM数字签名的过程。
这就是为什么未越狱机器不能安装破解软件的原因。没有公钥,安装程序就会自动停止,并且出现“应用程序"XXX"未安装在iPhone"XXX"上,因为发生未知错误(0xE8008001)”的提示。所以安装破解软件的必要条件就是设备要越狱。设备越狱之后,系统最高权限被打开,系统文件就可以被修改了。安装破解软件,就需要把数字签名验证这一机制给去掉。这就是为什么在安装破解IPA之前,2.X时代要替换MobileInstallation文件,3.X ,4.X ,5.X系统要安装AppSync的原因,原理就是骗过iTunes的数字签名验证,允许没有合法签名的程序在设备上运行。
苹果软件通用的破解过程如下:
1.通过输入信息在var/mobile/Applications下定位待破解软件所在位置
2.复制软件目录下所有的文件到一个临时目录
3.通过toolchain中的otool分析程序主文件,找出cryptsize和cryptid
4.运行待破解程序,通过gdb调试程序监测程序内存
5.因为程序已经运行,所以此时是解密状态。dump当前未加密的内存
6.将dunp结果输出到一个bin文件,退出gdb调试程序
7.将主程序文件的cryptid字串改为0,改加密状态为未加密
8.将dump出来的bin文件中的未加密内存的内容覆盖到原主程序文件的相应位置
9.对主程序签名
10.删除一些垃圾文件
11.打包IPA
苹果itunes授权过程:
1.首先申请了一个appstore帐号,itunes会在C盘生成SCinfo (xp下的C:\Documents and Settings\All Users\Application Data\Apple Computer\iTunes\SC Info就是)
2.每在appstore下一个程序,itunes会自动更新sc里的授权信息授权信息里包括系统序列号、C盘ID、网卡MAC等,当然还有你帐户下购买所有的软件列表
3.当利用itunes同步软件时,itunes会同时把该帐号下的授权导入ipad,所以大神们分享授权也是这个原理,只要同步一个帐号下的授权就可以了,当然有新授权除外
4.itunes只认scinfo下的授权文件,所以用不同用户的scinfo可以得到不同人的授权信息并同步给ipad或iphone
多账号授权注意要点:
1.如果有多用户授权文件,如大V、大S、大A等三个人授权文件时(大A跟大V的授权帐号非常多,大概有20多个)先修改硬盘序列号为各授权文件的硬盘序列号(打开各自己授权人的.ini文件可以看到硬盘序列号,在最下边),然后再COPY授权文件到授权软件目录,导入相应的授权文件,如大V下有13个授权帐号(下过的清楚123个文件夹每个4个授权人软件)这时需要itunes同步13个授权(即内置的13个应用软件)到ipad,每次同步不超过5个应用,同步后,从itunes内删除应用,然后从ipad删除刚安装授权的几个应用,得到13个授权。这时ipad内除了本有的应用外,应该是空的。
2.打开第二个授权人文件,按步骤1的方法导入第二个授权人软件(注意授权人发布授权时一般都有注明有多少个授权帐号,都需要相应的授权帐号软件依次同步导入删除),然后删除ipad内的刚安装授权的应用(如果只有单一授权帐号时不需要删除原有软件)。
3.打开大S授权后重复以上步骤。最终可得到所有坛子上比较热门的所有授权人的帐号授权。
以上每次从itunes同步后,下次同步前,需将ipad内为得到授权而同步内的应用全部删除,或者说把除了系统自带的应用外的所有应用删除。
Control+SHIFT 快速放大dock的图标会暂时放大,而如果你开启了dock放大
Command+Option+W 将所有窗口关闭
Command+W 将当前窗口关闭(可以关闭Safari标签栏,很实用)
Command+Option+M 将所有窗口最小化
Command+Q 关闭当前应用程序(相当于Dock鼠标右键推出.很实用)
Command+M 将目前使用的窗口最小化
Command+H 隐藏当前窗口或者软件
Command+tab 为切换当前工作任务
Control+Command+S 切换控制条的显示和隐藏
Command+i 常规信息(显示及设置图标属性)
Command+delete 移到废纸篓(删除)
Optionion+鼠标 拖图像或文件夹可以将图像或文件夹拷贝到其它文件夹中,而不是移动
Command+Shift+backspace 清空废纸篓(再加上option一起按能跳过确认对话框)
Command+N 键可以建立新文件夹 “return”或“enter”或“O”键可以打开所选项目
Command+Option+esc 键可以强行退出死机程序
Command+Shift+3 截图(当前屏幕)
Command+Shift+4 截图(自由选取范围)
Option+F12 关机窗口(能选择关机、重起、睡眠)
Command+1 以图标方式显示
Command+2 以分栏方式显示
Command+3 以列表方式显示
Command+4 以Cover Flow方式显示
return或enter 键可以编辑所选图像或文件夹的名称
Control+Option+Command+8 屏幕颜色反转(晚上看书使用)
2010年4月21日
Linux 常用的查看系统信息的命令:
查看CPU信息:cat /proc/cpuinfo
查看硬盘信息: df -lh
查看内存信息: free -m
|
在LINUX环境开发驱动程序,首先要探测到新硬件,接下来就是开发驱动程序。
常用命令整理如下:
用硬件检测程序kuduz探测新硬件:service kudzu start ( or restart)
查看CPU信息:cat /proc/cpuinfo
查看板卡信息:cat /proc/pci
查看PCI信息:lspci (相比cat /proc/pci更直观)
例子: lspci |grep Ethernet 查看网卡型号
查看内存信息:cat /proc/meminfo
查看USB设备:cat /proc/bus/usb/devices
查看键盘和鼠标:cat /proc/bus/input/devices
查看系统硬盘信息和使用情况:fdisk & disk - l & df
查看各设备的中断请求(IRQ):cat /proc/interrupts
查看系统体系结构:uname -a |
dmidecode查看硬件信息,包括bios、cpu、内存等信息
|
Dmidecode
dmidecode以一种可读的方式dump出机器的DMI(Desktop Management Interface)信息。这些信息包括了硬件以及BIOS,既可以得到当前的配置,也可以得到系统支持的最大配置,比如说支持的最大内存数等。
DMI有人也叫SMBIOS(System Management BIOS),这两个标准都由DMTF(Desktop Management Task Force)开发。
dmidecode的输出格式一般如下:
----------------------------------------
Handle 0x0002
DMI type 2, 8 bytes
Base Board Information
Manufacturer:Intel
Product Name: C440GX+
Version: 727281-0001
Serial Number: INCY92700942
----------------------------------------
其中的前三行都称为记录头(recoce Header), 其中包括了:
1、recode id(handle): DMI表中的记录标识符,这是唯一的,比如上例中的Handle 0x0002。
2、dmi type id: 记录的类型,譬如说:BIOS,Memory,上例是type 2,即"Base Board Information"
3、recode size: DMI表中对应记录的大小,上例为8 bytes.(不包括文本信息,所有实际输出的内容比这个size要更大。)
记录头之后就是记录的值:
4、decoded values: 记录值可以是多行的,比如上例显示了主板的制造商(manufacturer)、model、version以及serial Number。
dmidecode的使用方法
1. 最简单的的显示全部dmi信息:
# dmidecode
这样将输出所有的dmi信息,你可能会被一大堆的信息吓坏,通常可以使用下面的方法。
2.更精简的信息显示:
# dmidecode -q
-q(--quite) 只显示必要的信息,这个很管用哦。
3.显示指定类型的信息:
通常我只想查看某类型,比如CPU,内存或者磁盘的信息而不是全部的。这可以使用-t(--type TYPE)来指定信息类型:
# dmidecode -t bios
# dmidecode -t bios, processor (这种方式好像不可以用,必须用下面的数字的方式)
# dmidecode -t 0,4 (显示bios和processor)
dmidecode到底支持哪些type?
这些可以在man dmidecode里面看到:
文本参数支持:
bios, system, baseboard, chassis, processor, memory, cache, connector, slot
数字参数支持很多:(见附录)
4.通过关键字查看信息:
比如只想查看序列号,可以使用:
# dmidecode -s system-serial-number
-s (--string keyword)支持的keyword包括:
-------------------------------------------------------------------------------------
bios-vendor,bios-version, bios-release-date,
system-manufacturer, system-product-name, system-version, system-serial-number,
baseboard-manu-facturer,baseboard-product-name, baseboard-version, baseboard-serial-number, baseboard-asset-tag,
chassis-manufacturer, chas-sis-version, chassis-serial-number, chassis-asset-tag,
processor-manufacturer, processor-version.
-------------------------------------------------------------------------------------
5.示例
5.1 查看当前内存和支持的最大内存
Linux下,可以使用free或者查看meminfo来获得当前的物理内存:
# free
total used free shared buffers cached
Mem: 8182532 8010792 171740 0 148472 4737896
-/+ buffers/cache: 3124424 5058108
Swap: 4192956 3304 4189652
# grep MemTotal /proc/meminfo
MemTotal: 8182532 kB
这里显示了当前服务器的物理内存是8GB。
服务器到底能扩展到多大的内存?
#dmidecode -t 16
# dmidecode 2.7
SMBIOS 2.4 present.
Handle 0x0013, DMI type 16, 15 bytes.
Physical Memory Array
Location: System Board Or Motherboard
Use: System Memory
Error Correction Type: Multi-bit ECC
Maximum Capacity: 64 GB (可扩展到64GB)
Error Information Handle: Not Provided
Number Of Devices: 4
但是,事实不一定如此,因此插槽可能已经插满了。也就是我们还必须查清这里的8G到底是4*2GB, 2*4GB还是其他?
如果是4*2GB,那么尽管可以扩展到64GB,但是插槽已经插满,无法扩展了:
#dmidecode -t 17
# dmidecode 2.7
SMBIOS 2.4 present.
Handle 0x0015, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽1有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM00
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM82
Part Number: MT9HTF6472FY-53EA2
Handle 0x0017, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽2有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM10
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM83
Part Number: MT9HTF6472FY-53EA2
Handle 0x0019, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽3有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM20
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM84
Part Number: MT9HTF6472FY-53EA2
Handle 0x001B, DMI type 17, 27 bytes.
Memory Device
Array Handle: 0x0013
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB 【插槽4有1条2GB内存】
Form Factor: DIMM
Set: None
Locator: DIMM30
Bank Locator: BANK
Type: Other
Type Detail: Other
Speed: 667 MHz (1.5 ns)
Manufacturer:
Serial Number: BZACSKZ001
Asset Tag: RAM85
Part Number: MT9HTF6472FY-53EA2
根据上面输出可以发现,如果要扩展,只有将上面的内存条换成16GB的,才能达到4*16GB=64GB的最大支持内存。
附录:
dmidecode支持的数字参数:
Type Information
----------------------------------------
0 BIOS
1 System
2 Base Board
3 Chassis
4 Processor
5 Memory Controller
6 Memory Module
7 Cache
8 Port Connector
9 System Slots
10 On Board Devices
11 OEM Strings
12 System Configuration Options
13 BIOS Language
14 Group Associations
15 System Event Log
16 Physical Memory Array
17 Memory Device
18 32-bit Memory Error
19 Memory Array Mapped Address
20 Memory Device Mapped Address
21 Built-in Pointing Device
22 Portable Battery
23 System Reset
24 Hardware Security
25 System Power Controls
26 Voltage Probe
27 Cooling Device
28 Temperature Probe
29 Electrical Current Probe
30 Out-of-band Remote Access
31 Boot Integrity Services
32 System Boot
33 64-bit Memory Error
34 Management Device
35 Management Device Component
36 Management Device Threshold Data
37 Memory Channel
38 IPMI Device
39 Power Supply
|
dmesg | more 查看硬件信息
对于“/proc”中文件可使用文件查看命令浏览其内容,文件中包含系统特定信息:
Cpuinfo 主机CPU信息
Dma 主机DMA通道信息
Filesystems 文件系统信息
Interrupts 主机中断信息
Ioprots 主机I/O端口号信息
Meninfo 主机内存信息
Version Linux内存版本信息
|
2010年3月23日
1 使用jms需要注意的问题
一下所述的问题,不仅是对ActiveMQ,对于其他的JMS也一样有效。
1.1 不要频繁的建立和关闭连接
JMS使用长连接方式,一个程序,只要和JMS服务器保持一个连接就可以了,不要频繁的建立和关闭连接。频繁的建立和关闭连接,对程序的性能影响还是很大的。这一点和jdbc还是不太一样的。
1.2 Connection的start()和stop()方法代价很高
JMS的Connection的start()和stop()方法代价很高,不能经常调用。我们试用的时候,写了个jms的connection
pool,每次将connection取出pool时调用start()方法,归还时调用stop()方法,然而后来用jprofiler发现,一般的
cpu时间都耗在了这两个方法上。
1.3 start()后才能收消息
Connection的start()方法调用后,才能收到jms消息。如果不调用这个方法,能发出消息,但是一直收不到消息。不知道其它的jms服务器也是这样。
1.4 显示关闭Session
如果忘记了最后关闭Connection或Session对象,都会导致内存泄漏。这个在我测试的时候也发现了。本来以为关闭了
Connection,由这个Connection生成的Session也会被自动关闭,结果并非如此,Session并没有关闭,导致内存泄漏。所以一
定要显示的关闭Connection和Session。
1.5 对Session做对象池
对Session做对象池,而不是Connection。Session也是昂贵的对象,每次使用都新建和关闭,代价也非常高。而且后来我们发现,
原来Connection是线程安全的,而Session不是,所以后来改成了对Session做对象池,而只保留一个Connection。
2 集群
ActiveMQ有强大而灵活的集群功能,但是使用起来还是会有很多陷阱。
2.1 broker cluster和 master-slave
ActiveMQ可以做broker的集群,也可以做master-slave方式的集群。前者能在多个broker之前fail-over和
load-balance,但是在某个节点出故障时,可能导致消息丢失;而后者能实时备份消息,和fail-over,但是不能load-
balance。broker
cluser的方式,在一个broker上发送的消息可以在其它的broker上收到。当一个broker失效时,客户端可以自动的转到别的broker
上运行,多个broker可以同时提供服务,但是消息只存储在一个broker上,如果那个broker失效了,那么客户端直到它重新启动后才能收到该
broker上的消息,假如很不幸,那个broker的存储介质坏了,那么消息就丢失掉了。
Master-slave方式中,只有master提供服务,slave只是实时的备份master的数据,所以消息不会丢失。当master失效
时,slave会自动升为master,客户端会自动转到slave上工作,所以能fail-over。由于只有master提供服务,所以不能将负载分
到多个broker上。
其实单个broker的性能已经是相当的惊人了,在我们公司的机器上能达到每秒收发4000个消息,没个消息4K字节这样的速度,足够公司目前的需要了,而公司并不希望丢失任何数据,所以我们选择使用master-slave模式。
2.2 多种master-slave模式
master-slave也有多种实现方式。它们的不同只是在共享数据和锁机制上。
2.2.1 Pure master-slave
Pure
master-slave,显示的在配置文件中指定一个broker做为另一个broker的slave。运行时,slave同过网络自动从master
出复制数据,同时在和master失去连接时自动升级为master。当master失效,slave成为master后,如果要让原先的master重
新投入运行,需要停掉运行中的slave(现在升级为master了),手动复制slave中的数据到master中。再重新启动master和
slave。这种方式最简单,效率也不错,但是只能有两台做集群,只能fail-over一次,而且需要停机回复master-slave结构。
2.2.2 JDBC master-slave
这种方式不需要特殊的配置,只要让所有的节点都把数据存储到同一个数据库中。先拿到数据库表的锁的节点成为master,一旦它失效了,其它的节点
获得锁,就可以成为master。因为数据通过数据库共享,放在一个地方,不需要停机恢复master-slave。这种方式,需要额外的数据库服务器,
如果数据库失效了,那么就全失效了,而且速度不是很快。我们在用mysql测试时,并没有成功,master失效后,其他的节点始终没有升级成
slave,可能是数据库配置的问题。
2.2.3 Share file master-slave
这种方式类似于前者,也不需要特别的配置,只是通过共享文件系统来共享数据,靠文件锁实现只有一台成为master。共享文件系统的方式有很多,我们测试了nfs v4 (v3有bug,不行), 最终在稳定性,效率等方面不是很满意,可能是通过网络太慢了。
测试过众多master-slave模式后发现,pure方式管理起来麻烦,jdbc方式成本高,效率低,share
file方式需要高性能的共享文件,都有缺点。鉴于单台activeMQ很可靠,而我们的基础平台组愿意用硬件备份,最终还是决定不用master-
slave了,也不用broker cluster,就用单台,通过硬件冗余保证数据不会丢失,并找另外一台刀片机做冷备,在主服务器失效时顶替。
2009年3月28日
JProfiler 是一个著名的用于 java 系统监控分析的软件,功能很强大,可以监控普通的 java application, applet, java web start, application server 等等。除了可以监控本地的程序,还可以对远程服务器上跑的应用进行监控。本文以 JBoss 为例,对 JProfiler 的安装、配置和使用做个简单介绍。
先说一下环境:
服务器:RedHat Linux 3.4.3-9.EL4(内核版本 2.6.9-5.ELsmp),JBoss 4.0.3,Sun JDK 1.5.0_08,JProfiler 4.3.2 for linux(安装包:jprofiler_linux_4_3_2.sh)
客户端:Windows XP,JProfiler 4.3.2 for windows(安装包:jprofiler_windows_4_3_2.exe)
客户端 JProfiler 安装:直接运行安装程序即可,没啥可说的。有一点就是安装过程中,norton 曾经报警,不理他,安完之后也没发现有什么问题
服务器端 JProfiler 安装:把 jprofiler_linux_4.3.2.sh 上传到到服务器,假设路径为 /opt/jprofiler4 (后文用 $JPROFILER_HOME指代)。用如下命令: # cd /opt/jprofiler4 # chmod +x *.sh # ./jprofiler_linux_4.3.2.sh -c
按照提示来安装,提示都很简单,不在多说。安装路径选择 $JPROFILER_HOME 。注意,这里的 -c 意思是用字符方式来安装,如果机器上没有 X 则加上该参数。
服务器端的配置:
1. 修改系统配置,在 LD_LIBRARY_PATH 里加入 JProfiler 的库文件所在路径 $JPROFILER_HOME/bin/linux-x86 ,如果是 64 位服务器,则选择 $JPROFILER_HOME/bin/linux-x64。
2. 修改 JBoss 的启动脚本,加入如下参数:
-agentlib:jprofilerti=port=8849 -Xbootclasspath/a:$JPROFILER_HOME/bin/agent.jar
例如: $JAVA_HOME/bin/java $JAVA_OPTS -agentlib:jprofilerti=port=8849 -Xbootclasspath/a:/opt/jprofiler-4.3.2/bin/agent.jar -Djava.endorsed.dirs="$JBOSS_ENDORSED_DIRS" -Djava.library.path=$JBOSS_HOME/server/default/lib -classpath "$JBOSS_CLASSPATH" org.jboss.Main -c default 1>$JBOSS_CONSOLE 2>&1 </dev/null &
8849 是默认的端口号
3. 重新 login linux ,启动 jboss 。查看一下 $JBOSS_HOME/server/default/log/server.log ,可以看到 JBoss 并未启动,原因是上边的配置选择的启动模式,只有当一个 JProfiler GUI(指 Windows XP 下安装的 jprofiler )的监听请求发过来时候,JProfiler才会真正的启动被监控的应用程序也就是 JBoss 。另外有一种启动模式与此不同,它可以直接启动被监控的应用程序而不必等待。这种配置稍微麻烦一点,以后在说。
客户端的配置和使用:
1. 运行 JProfiler 。第一次打开会有向导,忽略它。
2. 选择 Session->Integration Wizard->New Remote Integratation
3. 选择 On a remote computer;Platform of remote computer 选择 Linux x86/AMD 64;Next
4. 输入服务器 IP ;Next
5. 输入服务器上的 jprofiler 的安装路径,如 /opt/jprofiler4 ;next
6. 选择服务器的 JDK 环境,这里是:Sun,1.5.0,hotspot;next
7. 输入端口:这里是默认值 8849;next
8. 选择启动模式:这里选第一种 wait for a connection from the jprofiler GUI;next
9. 这里会列出需要在服务器端做的配置。上一步“服务器端的配置”我们已经做过了。如果在第 8 步选择了第二种启动方式 Don't wiat, start immediately ,这里也会列出相应的服务器端配置方法,可以参考。next
10. Finish
此时 session 会被启动。在 profiling settings 对话框里,不用做任何修改,ok 即可。此时 session 被启动。观察一下服务器,发现 JBoss 也启动了。这时就可以在客户端看到 jboss 的运行情况,比如内存的占用等等。
我用 jprofiler 主要是监控内存占用情况看是否有 member leak 。点左侧的 “VM Telemetry Views”可以看到 jboss 占用的内存情况。
ActiveMQ本身是开源项目,所以采用ActiveMQ的项目往往也是以其他开源软件共同构建,目前主流开源应用服务器有Boss,geronimo,JOnAs,而其中geronimo 默认的JMS Provider就是ActiveMQ,那我们就着重介绍ActiveMQ与JBoss,JOnAs的整合方案。
整合需要的环境.
jdk1.5
jboss-4.0.5.GA
activemq-ra-4.1.0-incubator.rar (在ActiveMQ 4.* lib\optional 目录里面有对应的ra的压缩包)
开始整合前请确保jboss能够正确的启动起来。
整合步骤
1. 步骤一: 解压activemq-rar-4.1.0-incubator.rar 到 jboss-4.0.5.GA\server\default\deploy\activemq-ra.rar (这个是目录名字) 下面是activemq-rar.rar目录下面的文件和子目录,请注意红色标记的地方(后面会逐一说明,整合的过程)
activeio-core-3.0.0-incubator.jar activemq-core-4.1.0-incubator.jar activemq-ra-4.1.0-incubator.jar backport-util-concurrent-2.1.jar commons-logging-1.0.3.jar derby-10.1.1.0.jar geronimo-j2ee-management_1.0_spec-1.0.jar spring-2.0.jar spring-1.2.6.jar xbean-spring-2.7.jar broker-config.xml META-INF
2.步骤二. 删除多余的spring-1.2.6.jar,由于4.1.0的ra里面包含了2个不同版本的spring会触发一个exception的产生,https://issues.apache.org/activemq/browse/AMQ-1124, 而且为了以后能够使用新的spring schema配置方式,我们这里会删除spring-1.2.6.jar,保留spring-2.0.jar。(最新的snapshot version的ra已经去掉了这个多余的spring-1.2.6.jar).
3.步骤三: 修改META-INF\ra.xml,让JBoss使用broker-config.xml 作为默认的配置文件配置borker. 修改下面的地方
<config-property-value>config-property-value> <!-- <config-property-value>xbean:broker-config.xml</config-property-value>-->
改为: <!-- <config-property-value></config-property-value> --> <config-property-value>xbean:broker-config.xmlconfig-property-value>
表示使用broker-config.xml来配置启动ActiveMQ.
4.步骤四: 修改borker-config.xml,默认的borker-config.xml会产生一个错误,无论是我使用的版本还是最后的snapshot版本,默认的borker-config.xml都会让xbean-spring 2.7(snapshot 使用的是2.8)抛出exception.解决的办法如下,将 <beans xmlns="http://activemq.org/config/1.0"> <broker useJmx="true" >
改为 <beans> <broker useJmx="true" xmlns="http://activemq.org/config/1.0">
即可
5.步骤五: 将xbean-spring-2.7.jar (或者是2.8) 复制到jboss-4.0.5.GA\server\default\lib下面
使用整合完毕的ActiveMQ作为ds绑定到JBoss的JNDI服务。
编写jboss-4.0.5.GA\server\default\depoly\activemq-ds.xml,xml 代码
<? xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE connection-factories PUBLIC "-//JBoss//DTD JBOSS JCA Config 1.5//EN" "http://www.jboss.org/j2ee/dtd/jboss-ds_1_5.dtd">
<connection-factories>
<tx-connection-factory>
<jndi-name>activemq/QueueConnectionFactory</jndi-name>
<xa-transaction />
<track-connection-by-tx />
<rar-name>activemq-ra.rar</rar-name>
<connection-definition>javax.jms.QueueConnectionFactory</connection-definition>
<serverurl>tcp://localhost:61616</serverurl>
<min-pool-size>1</min-pool-size>
<max-pool-size>200</max-pool-size>
<blocking-timeout-millis>30000</blocking-timeout-millis>
<idle-timeout-minutes>3</idle-timeout-minutes>
</tx-connection-factory>
<tx-connection-factory>
<jndi-name>activemq/TopicConnectionFactory</jndi-name>
<xa-transaction />
<track-connection-by-tx />
<rar-name>activemq-ra.rar</rar-name>
<connection-definition>javax.jms.TopicConnectionFactory</connection-definition>
<serverurl>tcp://localhost:61616</serverurl>
<min-pool-size>1</min-pool-size>
<max-pool-size>200</max-pool-size>
<blocking-timeout-millis>30000</blocking-timeout-millis>
<idle-timeout-minutes>3</idle-timeout-minutes>
</tx-connection-factory>
<mbean code="org.jboss.resource.deployment.AdminObject" name="activemq.queue:name=outboundQueue">
<attribute name="JNDIName">activemq/queue/outbound</attribute>
<depends optional-attribute-name="RARName">
jboss.jca:service=RARDeployment,name='activemq-ra.rar'
</depends>
<attribute name="Type">javax.jms.Queue</attribute>
<attribute name="Properties">PhysicalName=queue.outbound</attribute>
</mbean>
<mbean code="org.jboss.resource.deployment.AdminObject" name="activemq.topic:name=inboundTopic">
<attribute name="JNDIName">activemq/topic/inbound</attribute>
<depends optional-attribute-name="RARName">
jboss.jca:service=RARDeployment,name='activemq-ra.rar'
</depends>
<attribute name="Type">javax.jms.Topic</attribute>
<attribute name="Properties">PhysicalName=topic.inbound</attribute>
</mbean>
</connection-factories>
启动JBoss.如果看见以下信息就表示ActiveMQ已经成功启动,并且使用上面的ds配置文件成功地将topic/queue绑定到了JNDI服务上。
.....
[TransportConnector] Connector tcp://localhost:61616 Started
[NetworkConnector] Network Connector bridge Started
[BrokerService] ActiveMQ JMS Message Broker (localhost, ID:MyNoteBook-2165-1173250880171-1:0) started ......
[ConnectionFactoryBindingService] Bound ConnectionManager 'jboss.jca:service=ConnectionFactoryBinding,name=activemq/QueueConnectionFactory' to JNDI name 'java:activemq/QueueConnectionFactory'
[ConnectionFactoryBindingService] Bound ConnectionManager 'jboss.jca:service=ConnectionFactoryBinding,name=activemq/TopicConnectionFactory' to JNDI name 'java:activemq/TopicConnectionFactory'
[AdminObject] Bound admin object 'org.apache.activemq.command.ActiveMQQueue' at 'activemq/queue/outbound'
[AdminObject] Bound admin object 'org.apache.activemq.command.ActiveMQTopic' at 'activemq/topic/inbound ......
验证ActiveMQ+JBoss
这里你可以使用简单的jms client连接到broker-config.xml里面的协议连接器上面,默认的是tcp://localhost:61616
在后面我们会在此整合基础上开发Message Driver Bean和使用spring MDP 2种构架 来验证本次ActiveMQ+JBoss的整合。
$JBOSS-HOME/bin:
放置各种脚本文件以及相关文件,包括jboss 启动和停止的可执行脚本文件。
$JBOSS-HOME/client:
存储配置信息和可能被Java客户端应用程序或外部Web容器用到的jar文件,通常包括EJB客户端运行时所需要的jar
$JBOSS-HOME/docs:
保存在JBoss中引用到的XML文件和DTD文件(这里也提供了在JBoss中如何写配置文件的例子)、测试脚本。$JBOSS-HOME/docs/examples目录下有针对不通的数据库(如MySql、Oracle、SQL Server、Postgres等)配置数据源的JCA配置文件。 相关DTD定义文件位于$JBOSS-HOME/docs/dtd,在其下的文件中可以查阅某个XML配置文件中某个元素或属性的意义。
$JBOSS-HOME/lib:
这里存储运行JBoss微内核所需的jar文件。该目录下不要存储任何你自己的jar文件。
$JBOSS-HOME/server:
这里的每一个子目录对应着一个服务器配置。该配置由运行脚本文件时的参数"-c <配置名称>"来确定。在server目录下有三个配置例子,即all、default和minimal,每一个配置安装的服务都不一样。其中default下是缺省配置。
minimal:仅加载启动JBoss所需的最少服务,如日志服务、JNDI和URL部署扫描器(发现新的部署),不包含Web容器、EJB和JMS。
all:启动所有的服务,包括RMI/IIOP、集群服务和Web服务部署器(默认配置不会被加载)。
启动JBoss时,如果run.bat不带任何参数,则使用的配置是server/default目录下的配置。如果要以其它目录下的配置启动JBoss,可以使用如下参数:
run -c all
上述命令将以all目录下的配置信息启动JBoss。也可以在server目录下新建目录,按自己的需要写配置文件。
下面以default目录为例,介绍服务器配置的目录结构。
conf:该目录下有指定核心服务的jboss-service.xml文件,也可以放其它服务配置的文件。例如:jboss-log4j.xml 是log4j的配置文件
data:该目录是JBoss内置的数据库Hypersonic存储数据的地方,也是JBossMQ(the JBoss implementation of JMS)存储相关信息的地方。
deploy:这是部署J2EE应用程序(jar、war和ear文件)的位置,只需将相应文件拷贝到该目录下即可。该目录也用来热部署服务和JCA资源适配器。默认已经有一些服务部署到这个目录。
jmx-console,你启动JBoss后即可访问。JBoss会周期性的扫描deploy目录,当有任何组件改变,JBoss会重新部署该程序。
jboss-web.deployer就是jboss集成tomcat所在的位置。启动端口号可以通过修改该目录下的server.xml来进行配置。
数据源配置文件文件格式必须是*-ds.xml的样式。不同的数据库配置参数可参考$JBOSS-HOME/docs/examples/jca/下的示例文档。有关参数的细节在下面会有一定的描述。
lib:存放服务器配置所需的jar文件、公共的jar文件,比如,你可以将JDBC jar文件、log4j的jar文件等等放在该目录下。 如果这些jar已经在该lib下存在,那么web应用的WEB-INF/lib下不用再次放置。
log:存放日志信息。JBoss使用Jakarta log4j包存储日志,在程序中你也可以直接使用该信息。默认的log4j.xml配置是将日志输出到该文件夹下的server.log文件。 jboss-log4j.xml是默认配置文件
tmp:存储在部署过程中解压时产生的临时文件。
work:Tomcat编译JSP文件时的工作目录。如果JSP出错了,可以到该目录下去找对应的文件,定位问题。
目录data、log、tmp和work在JBoss安装后并不存在,当JBoss运行时自动建立。
启动JBOSS成功后
查看 http://localhost:8083 会出现一个没有错误的空白页,正常,应该是这样。
查看 http://localhost:1099 会出现一大堆乱字符,当然,里面包含了你的 IP 地址等等类似的信息。 1099 是 jnp 协议监听名字服务的缺省端口, RMI 的缺省端口也是一样的。在 JNDI 中,我们需要用到此端口。
2008年9月6日
AppFuse
是一个开源项目,主要目的是使用开源工具来帮助开发者快速有效的建立Web应用项目。使用AppFuse可以减少开发人员在建立新web应用时候花费大量
时间在项目结构的建立上。 最核心的是, AppFuse是一个项目的骨架,类似图使用IDE的向导方式来创建web项目。
AppFuse 2 的环境配置:
a. 安装JDK 5+ (确保JAVA_HOME 指向JDK目录, 而不是JRE目录).
b. 安装 MySQL 5.x.
c. 建立本地SMTP服务或者修改mail.properties (在src/main/resources) 的use为一个不同的主机名- it 缺省是 "localhost".
d. 安装Maven 2.0.9+.
因为AppFuse 2使用了Maven 2 的支持。一般的Maven2 会再你使用AppFuse的包的时候会下载这些包,但是如果你的网络不好的话。你也可以自己下载AppFuse2的依赖包,其下载地址为:https://appfuse.dev.java.net/servlets/ProjectDocumentList?folderID=9173&expandFolder=9173&folderID=9173,现在版本是AppFuse2.02.大小为80M多。
然后解压到某个文件夹下,然后修改Maven_Home下的/conf/settings.xml里的相应配置,设置本地资源库。
<!-- localRepository
The path to the local repository maven will use to store artifacts.
Default: ~/.m2/repository
<localRepository>/path/to/local/repo</localRepository>
-->
<localRepository>E:/appfusedeps/repository</localRepository>
需要注意的上面的配置里说默认的资源库路径为~/.m2/repository,这是指用户的home目录,但如果这样设置在windows下,会
产生一些问题,因为windows的用户目录在C:\Documents and
Settings下,而这个目录有空格,所以最好直接指定另外的没有空格的英文路径。
下面是创建不同种类项目的Archetype Command:
1.JSF Basic
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-basic-jsf
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
2.Spring MVC Basic
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-basic-spring
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
3. Struts 2 Basic
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-basic-struts
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
4. Tapestry Basic
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-basic-tapestry
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
5. JSF Modular
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-modular-jsf
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
6.Spring MVC Modular
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-modular-spring
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
7.Struts 2 Modular
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-modular-struts
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
8.Tapestry Modular
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-modular-tapestry
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
9.Core(backend only)
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-core
-DremoteRepositories=http://static.appfuse.org/releases-DarchetypeVersion=2.0
-DgroupId=com.mycompany.app -DartifactId=myproject
下面将举一个例子:
1. 在D盘创建一个目录D:\projects\
2. 启动cmd。进入目录D:\projects\.
3.执行如下建构命令创建基本的:
mvn archetype:create -DarchetypeGroupId=org.appfuse.archetypes
-DarchetypeArtifactId=appfuse-basic-struts
-DremoteReposities=http://static.appfuse.org/release
-Darchetypeversion=2.0.1 -DgroupId=com.zhangjr.framework
-DartifactId=myproject
4.执行结束后将会看到D:\projects\myproject目录结构,编辑D:\projects\myproject\pom.xml,修改mysql数据连接信息,主要是修改root的密码为你自己数据库用户密码
因为缺省为空<jdbc.password></jdbc.password>。
5.在cmd中进入目录D:\projects\myproject
6.执行mvn jetty:run-war
7.等执行结束后,在浏览器地址栏输入
http://localhost:8080/,你将会看到项目的界面,任意输入一个用户名和密码即可登入。
8.登入进去以后,不错吧。你的新项目不写一行代码就完成了吧。呵呵。
2008年8月6日
一、编写相关的VBS脚本
可以在PowerDesign里自定义一些命令与操作,具体的内容可以参考[powerdesigner安装目录下的]\VB Scripts目录下的脚本示例。
怎么运用这些脚本呢?
在Tools-》Execute Commands里可以进行操作,具体说明见帮助。
帮助的位置在
PowerDesigner General Features Guide
-> Working with Scripts
->Accessing objects using VBScript
->VBScript uses in PowerDesigner
二、PowerDesign的高级使用主要是DBMS的配置
1、修改建表脚本生成规则。如果每个表格都有相同的字段,可以如下修改:
Database -> Edit Current DBMS 展开 Script -> Object -> Table -> Create 见右下的Value值,可以直接修改如下:
/* tablename: %TNAME% */
create table [%QUALIFIER%]%TABLE% (
%TABLDEFN%
ts char(19) null default convert(char(19),getdate(),20),
dr smallint null default 0
)
[%OPTIONS%]
其中的 ts、dr 两列会在生成SQL脚本的时候自动的插入每个表格中,其中的%TNAME% 变量是给每个表格的SQL添加一个该表的Name值注释。
2、修改字段生成规则。要给每个字段都添加一个注释的话,同一窗口中展开 Script -> Object -> Column -> Add 的 Value修改为:
%20:COLUMN% [%COMPUTE%?AS (%COMPUTE%):%20:DATATYPE% [%IDENTITY%?%IDENTITY%:[%NULL%][%NOTNULL%]][ default %DEFAULT%]
[[constraint %CONSTNAME%] check (%CONSTRAINT%)]]/*%COLNNAME%*/
其中的%COLNNAME%就是列的Name值(可以是中文)
3、修改外键命名规则。选择Database—>Edit Current DBMS
选择Scripts-》Objects-》Reference-》ConstName
可以发现右侧的Value为:
FK_%.U8:CHILD%_%.U9:REFR%_%.U8:PARENT%
可见,该命名方法是:'FK_'+8位子表名+9位Reference名+8位父表名,你可以根据这中模式自定义为:
FK_%.U7:CHILD%_RELATIONS_%.U7:PARENT%,
可以使FK名称变为FK_TABLE_2_RELATIONS_TABLE_1
掌握这种方法后就可以按照自己的想法修改了
生成建库脚本SQL文件中的表头注释很讨厌,可以在 Databse -> Generate Database (Ctrl+G)窗口中,选择Options卡片,去掉Usage的Title钩选项即可。
4、添加外键
Model -> References新建一条外键后,双击进入外键属性,在“Joins”卡片中可以选择子表的外键字段
5、去掉生成的SQL脚本双引号的问题:ORACLE 8I2::Script\Sql\Format\CaseSensitivityUsingQuote改成No,默认是Yes所以会有双引号。
使用经验:
1、pd中复制一列是,实际上是一个链接。源列的变动同时体现在复制列上
2、数据库设计通常步骤:CDM缺定主要结构--》生成PDM--》在PDM上修改,必要时生成CDM
若由pdm生成cdm再生成pdm,在pdm中修改过的外键名将被改回到默认值
3、必要时可以通过修改模板(Database-Edit Current
DataBase)改变脚本的格式。
例如:
Script-Objects-Column-Add的Value中开头增加一行“--%COLNNAME%”以便在脚本中显示列的中英文对照
4、去掉讨厌的name、code映射:Tools-General Options-clear the Name to Code mirroring check
box
5、对于大小写不敏感的数据库(如Oracle),PowerDesign在创建脚本时自动给表名和字段名加上双引号,以“强字符串”形式来获 取区分大小写,这样给sql语句的编写制造很多麻烦。
去掉这个添足的功能:
Database
-〉Edit Current DBMS -〉Script -〉Sql -〉Format
-〉CaseSensitivityUsingQuote右边面板参数值 Value 选择No
6、由cdm生成pdm,可以控制是否将关系生成引用;由pdm生成脚本,可以控制是否将引用生成外键
7、对于oracle而言,为表设置选项(如tablespace GPSSYSTEM)可使其创建到正确的表空间;为主键设置选项(using index
tablespace GPSINDEX)使索引创建到正确的表空间中
8、使数据模型图上显示中文:Tools-Model Options-Naming Convertion,在右侧Display处选择Name
9、建立一个表后,为何检测出现Existence of index的警告
A table should contain
at least one column, one index, one key, and one reference.
可以不检查 Existence
of index 这项,也就没有这个警告错误了!
意思是说没有给表建立索引,而一个表一般至少要有一个索引,这是一个警告,不用管也没有关系!
10、创建一个表在修改字段的时候,一修改name的内容,code也跟着变化,如何让code不随着name变化
Name和Code
的右侧都有一个按钮“=”,如果需要不同步的话,把这个按钮弹起来就可以了。
Tools->General
Options->Dialog->Name to Code Mirroring (去掉)
11、由pdm生成建表脚本时,字段超过15字符就发生错误(oracle)
原因未知,解决办法是打开PDM后,会出现Database的菜单栏,进入Database - Edit Current DBMS
-script-objects-column-maxlen,把value值调大(原为30),比如改成60。出现表或者其它对象的长度也有这种错误的话都可以选择对应的objects照此种方法更改!
或者使用下面的这种方法:
生成建表脚本时会弹出Database generation提示框:把options - check
model的小勾给去掉,就是不进行检查(不推荐)!
或者可以修改C:\Program Files\Sybase\PowerDesigner
Trial 11\Resource Files\DBMS\oracl9i2.xdb文件
修改好后,再cdm转为pdm时,选择“Copy the
DBMS definition in model”把把这个资源文件拷贝到模型中。
12、由CDM生成PDM时,自动生成的外键的重命名
PDM Generation Options->Detail->FK index
names默认是%REFR%_FK,改为FK_%REFRCODE%,其中%REFRCODE%指的就是CDM中Relationship的code!另外自动生成的父字段的规则是PDM
Generation Options->Detail->FK column name
template中设置的,默认是%.3:PARENT%_%COLUMN%,可以改为Par%COLUMN%表示是父字段!
13、如何防止一对一的关系生成两个引用(外键)
要定义关系的支配方向,占支配地位的实体(有D标志)变为父表。
在cdm中双击一对一关系->Detail->Dominant
role选择支配关系
14、修改报表模板中一些术语的定义
即文件:C:\Program Files\Sybase\PowerDesigner Trial 11\Resource
Files\Report Languages\Chinese.xrl
Tools-Resources-Report
Languages-选择Chinese-单击Properties或双击目标
修改某些对象的名称:Object Attributes\Physical
Data Model\Column\
ForeignKey:外键
Mandatory:为空
Primary:主键
Table:表
用查找替换,把“表格”替换成“表”
修改显示的内容为别的:Values
Mapping\Lists\Standard,添加TRUE的转化列为是,FALSE的转化列为空
另外Report-Title
Page里可以设置标题信息
15、
PowerDesigner11中批量根据对象的name生成comment的脚本
'******************************************************************************
'*
File: name2comment.vbs
'* Purpose: Database generation cannot use object
names anymore
' in version 7 and above.
' It always
uses the object codes.
'
' In case the object codes are not
aligned with your
' object names in your model, this script will
copy
' the object Name onto the object comment for
' the Tables and Columns.
'
'* Title:
把对象name拷入comment属性中
'* Version: 1.0
'* Author:
'* 执行方法:PD11 -- Open
PDM -- Tools -- Execute Commands -- Run
Script
'******************************************************************************
Option Explicit
ValidationMode = True
InteractiveMode =
im_Batch
Dim mdl ' the current model
' get the current active model
Set mdl = ActiveModel
If
(mdl Is Nothing) Then
MsgBox "There is no current Model"
ElseIf Not
mdl.IsKindOf(PdPDM.cls_Model) Then
MsgBox "The current model is not an
Physical Data model."
Else
ProcessFolder mdl
End If
' This routine copy name into code for each table, each column
and each view
' of the current folder
Private sub
ProcessFolder(folder)
Dim Tab'running table
for each Tab in
folder.tables
if not tab.isShortcut then
tab.comment =
tab.name
Dim col ' running column
for each col in
tab.columns
col.comment= col.name
next
end
if
next
Dim view 'running view
for each view in
folder.Views
if not view.isShortcut then
view.comment =
view.name
end if
next
' go into the sub-packages
Dim f ' running folder
For Each f In folder.Packages
if not f.IsShortcut then
ProcessFolder f
end if
Next
end sub
16、PowerDesigner 生成SQL的Existence of refernce错误问题
现象:用PowerDesigner生成SQL语句时,提示Existence of
refernce错误。
原因:该表没有与其他表的关联(如外键等),而PowerDesigner需要存在一个refernce才能生成SQL.
解决方法:
在工具栏空白处右键打开Palette面板,选中Link/Extended Dependency
按钮,然后在提示出错的表上添加到自己的Dependency。
重新生成SQL,你将发现刚才提示的错误没有了,问题解决。
17、利用PowerDesigner批量生成测试数据
主要解决方法:
A:在PowerDesigner
建表
B:然后给每一个表的字段建立相应的摘要文件
步骤如下:
Model->Test Data
Profiles配置每一个字段摘要文件General:输入Name、Code、
选择Class(数字、字符、时间)类型
选择Generation
Source: Automatic、List、ODBC、File
Detail:配置字段相关信息
所有字段摘要文件配置完成后双击该表->选择字段->Detail->选择Test Data
Parameters 摘要文件如果字段值与其它字段有关系在: Computed Expression
中输入计算列--生成测试数据:
DataBase->Generation Test Data->
选择:Genration
类型(Sript、ODBC)
Selection(选择要生成的表)
Test Data Genration(Default
number of rows 生成记录行数)
2008年7月28日
啥子是Programmer manager
A:program manager的program不是程序啦。。。一般管一个business
domain的end to end solution. 在甲方的话,一般还会分成几个team,下面的service
manager管operation和client management,还有initiative manager管一堆project
manager来deliver project。
Q: 请教一下,从带10-20人到带更多的人,最需要注意的是什么?
A:
请教不敢,我就是完全失败的一个典型,呵呵,经验教训可以简单说说。
我自己的经验,其实技术团队的管理, 真正质变的大概是从超过25-30人起, 道理很简单。 一个人可以直接充分管理的人大概就是4-5个为佳, 25个以内,分组就可以,超过25/30个以后就必须分3层,管理成本就开始剧烈增加,啥问题都出来了。
二
层结构的时候,下面人有问题容易及时修补,对小组leader的协调能力要求不高,只要负责即可,这种情况下基本没有多少管理成本。但是到了三层结构以后
对第二层的人要求比较高,如果没有合适的第二层人员,就基本是个乱摊子。老大这时候主要的工作,其实就是应该在人数超过50之前,尽可能快的培养出适合第
二层次的负责人,而不是急着做大导致整天忙着救火。另外分层架构的一个必然问题就是容易产生帮派和分离势力,不注意这方面出现的内耗杀伤力极大。所以对下
属马仔头目的监控会耗费你比较多的精力,而且同时还要充分考虑到如何让这些小流氓敏感脆弱的心理感觉到尊重。
我自己感觉50个人
左右时是个大坎,如果可以突破就可以顺利向三层的黑社会组织结构发展,可以过度到100人以上,我们那时候的问题就是老板其实并没有意思到管理成本这个问
题,错误的以为可以通过规模追求效益。在基本能突破50个人这个坎的时候,老板被上年的产值弄混了头,盲目发起了一场新战役,又空降了一个一心想做大事的
牛人,两人一合作,就一起over了。我们当时的架构,老板热衷于搞大合并,把几个事业部合并了弄个大部门,把一些马仔头目拆分的乱七八糟的,说是充分利
用资源,打破部门间的壁垒(扁平化管理?),然后又乱七八糟塞了一大堆人进来,原来的三层结构彻底打破,结果变成无人负责制。
软件项
目的团队规模,个人还是觉得越小越好,可能的情况下尽可能走小而精的道路,在培养了团队成员的默契和一些共同的文化认同以后,再逐步拆分扩充,要比一开始
就上大摊子有效的多。
我们之前成功的一个项目,最初的预算是60人,我采取的做法现在看起来非常明智,首先只找了1,2个核心的程序员和少数的普通程序员,通过结对开发的方式
让他们彼此熟悉和磨合,在这个过程中完成基本的核心开发,在2个月以后再补充第二批程序员,把原来人分拆重新结对。通过这种方式逐步过度到20-30的团
队。
再往后考虑到个人能力和管理成本的问题,就拒绝再加入了,最后以项目规划的1半左右的资源就完成了开发工作。而且这期间培养了不少人,大部分人后来又补充
到其他项目,逐步建立了整个部门技术团队。这种逐步圈地的做法比较稳妥,也容易培养团队之间的信任文化,那时候整个工作气氛还是蛮好的,我们是公司最少加
班的团队,但是是公司开发效率最高的团队。而其他几个规模只有一半,一开始就砸进几十个人的项目,都是问题多多那种。
100个人以上的团
队,我只见过,没管过,,基本上我觉得战斗力要比50人甚至30人低,吵架pk聊天时间多过做事时间,别相信啥1+1>2
。最近听朋友说XXX为了保证销售额,把销售人员增加了1倍,销售人员任务降低一半,这种规模游戏也就是骗领导有用吧,地球人都知道,横竖能干活的就是那
么几个人。
对一个leader来说,我自己的感觉就是4,5个人的时候啥都可以不管,自己把活干大头就好了,要有nb的小弟就扔给她做。
10来个人的时候,就要注意大家吃喝玩乐心情愉快,因为到了这个规模,基本上靠个别牛人发飙已经不可能搞定工作了,需要你去努力拍下属的马匹投其所好,让
他们赏脸做事,而且一定要有风险控制机制,关键工作岗位一定要有backup。规模再往上走,自觉往后面站,基本上你工作的中心就是要培养一批打手让他们
自己折腾自己。
P:
非常喜欢5-10人的小团队,我上一个项目就是了,4个dev,两个是senior两个
junior,另外4个tester,关系好打理,每个人知道自己在团队里的职责和位置。虽然个体能力不突出,但团队战斗力强。跟我们同期的另外一个20
人的队,有3个牛得不得了的人,manager和leader之间谁都不服谁,最后项目交付了,但一大堆bug。
Q: 受教了,多谢分享!
一个问题就是:在2个月以后,团队开始扩充时,如果仍然采用结对的方式,而不是传统的分组(几个人一个小组,然后选拔组长),如何保证队伍具有非常一致的目标和想法,如何保证团结?
A:
软件工程里面有个著名的brook定理,大意就是向一个进度落后的项目加人,只会让这个项目更加落后,引申开来就是应该避免在项目的中后期大幅度加人。 这里面的主要的原因有几点。
1. 新人加入团队以后需要获取团队成员的信任和尊重,这需要比较多的沟通和交流成本,软件开发说到底是一种群体活动。
2. 新人要理解,认同团队的文化,也需要很大的成本
3. 新人需要对项目进行学习和了解,过程会拖累其他开发人员
4. 新人太多,有可能会彻底摧毁原来团队已经建立的平衡结构,比如团队文化, 团队间的角色定位。
5. 管理者会因此大幅度的增加管理成本,另外,管理者很可能并未做好管理这样团队的准备,有可能会因为不合适的行为和决定导致团队崩溃
6. 人员增加以后,彼此之间的交流沟通成本会大幅度增加,超出一般人的想象。
因此一般正确的做法是避免在项目中后期加人,虽然这么显然简单的道理大部分老板都不相信。
所以表面上看,逐步圈地的做法是违反brook定理的。但实际情况,恰恰因为结对工作在很大程度上克服了上述的问题,所以你要是理解了结对的收益,就可以明白为什么结对可以保证“队伍具有非常一致的目标和想法,保证团结”
1. 结对可以让新人之间加快了解过程,尽快的融入团队, 不使用结对的方式,一个新人可能需要1,2周才能和团队相处融洽, 使用结对的方式以后,1,2天就可以很熟悉。
2.
结对降低了新人的学习成本,在结对过程中,原团队的成员采取人盯人的方式尽快的将技能和团队文化传递给新人,而新人一开始就可以上手工作(即便是菜鸟,在
结对过程中也可以通过质疑和提问对老人提供帮助和监督,而出于维护个人的自尊,团队成员一般都会急于向新人推销,证明自己 ),更有成就感和归宿感。对团队也就更容易认同。
),更有成就感和归宿感。对团队也就更容易认同。
3. 结对是分而治之的,有助于避免新人因为陌生环境产生分离感,建立自己的帮派。 有助于强制性的向新人灌输团队的目标,保证团队的团结。习惯了结对的工作模式以后,程序员之间必须强制性的进行沟通和交流,也可以避免产生帮派和内耗。
4.
作为boss更关心的一点就是,通过结对这种方式,可以获得足够的backup,可以避免因为人员流动给项目带来毁灭性的风险。因此可以大幅度的降低管理
成本。我们项目中期流失了近三分之一的人,进度没有受到任何影响,所以前期boss极力反对做pp,后期大力支持。我们自己有过一个大致统计,正常情况下
离职一个人,要损失至少半年的人工。
通过结对这种方式,互相之间建立了沟通和信任机制,再划分如果有目的的小团队,就比较自然,另外在不同的小团队之间交换结对伙伴也可以做激励和监督作用。而一次性投入的建设新团队,碰到的问题会更多。
这
个项目其实失败的一个地方就是中期迫于人员流动而放弃了结对,最后导致帮派和内耗,纠正过来化了血本,否则还能做的更好。人员流失有一部分是因为个人当时
管理经验不足,对问题的解决欠妥,还有一个原因是原材料不合适,老板在团队组建之初盲目的招来了一些并不适合的人(后来碰到一个老板,居然跟我提招10留
1的理论,Orz),也为后来的内耗埋下了隐患。这也算是一个经验,团队成员的选择leader一定要过问,对于那些性格比较偏激,难以控制的人应该尽量
回避,绝不可以因为资源紧迫就充数。
按:pp的工作方式,对团队成员性格有一定要求。
Q:
任何团队的组织划分,一定不是用技术最好的人来做leader。对技术好的人要进行压制。不管有多出色,都要尽力扶持听话的人。
找技术好的人是对的,但是他技术好,你技术不好,就面临挑战了。何况技术好,不听话的,到哪里都是干活的命,没有人会重视他们的。
A:
你老外说话也不真见外,按你这样管, 几天大家就造反了。
软
件团队和一般的团队区别非常大, 对软件团队来说,最好的管理模式就是不管理,
让大家自己发挥,做好足够的引导工作就好。小团队leader身先士卒起个带头示范左右,大团队, leader要躲在后面做好后援当保姆。
技术好的人的做leader是非常自然的,不懂技术的人做负责人倒是比较容易引起问题,技术人员都比较骄傲,除非是个美女mm带头,那还可以忍忍。
不是说不懂技术的人做不好pm,但是没有技术背景的人天然就和技术人员有鸿沟,技术人员背后搞的小九九,花样那个多,所以没有技术背景,管理成本会比较
高。
有个老外专门写了本书论证为啥技术好的人就该做leader, 你可以找找看。
按:管理层对技术人员的不尊重和粗暴压制, 才是技术人员不听话的一个重要原因。
Q:
说起来, 管理无所谓,只要肯听话的,这个是永远的原则。
听话的,能力也强的--这当然最好的,但是一般听话的能力都比较一般。要是能力强,不听话,最好不要,这样的人, 很容易出问题。
A:
软件开发和普通的项目是有根本的差别的,软件本质还是个体的脑力劳动, 所以软件的生产力完全取决于个人的能力和工作态度。 2个程序员之间工作效率的差别可以轻易超过10倍, 所以你找找再多听话的人又有什么用?
能力的问题可以举个真实例子: 某500强企业开发的一个业务系统, 投入近20个人, 历时2年至今还不能上线。而同样的东西,在另外一个团队只是2个人一个月的工作量而已。第二个团队的平均人工是要低于第一个团队的。
态度的问题也可以举个真实例子: 某公司开发的一个应用系统,4个人组成的验收团队测试了5个月只找到40个的缺陷, 系统提交客户以后,客户方自己组织测试,3天内就发现了40个以上的重要缺陷。
任何一个公司,都必须有听话(执行者)和不听话的人(创造者和破坏者)的存在,否则这个公司就离死不远了。 管理要的不是简单的听话与否,管理者关心的应该是可控和有效性。
Q:
为了达到目标,有效性就是听话,完成任务达到目标可控性,也就是要听话。
A:
算了,让我去死吧。
按:管理人员和技术人员的沟通真是鸡同鸭讲,呵呵。
DTO的转换规律一般可以总结为如下的几个类型,实际变化则可以是各种类型的组合:
属
性内容的增减在DTO不同形态之间的转变时候经常会发生。比如上例中添加用户LoginInfo对象的VO转换到BO的时候,就需要丢弃“重复输入密码”
的属性。有些VO对象甚至根本不需要转换成BO。在BO转换成PO的时候同样也会有属性内容减少的情况出现,比如“部门”这类树状层次结构对象,因为运行
效率的因素,也许会需要BO中有“下级部门列表”,实际存储到数据库的时候,PO只需要一个“上级部门ID”就可以了。
属
性内容同样会有可能增加,但是在系统处理DTO转换的时候,属性增加可能就意味着需要进行额外的查询和填充,比如我们使用“用户名”和“密码”进行登录的
时候,最终系统需要通过数据库查询得到并且存储“用户ID”,以此来保证用户的唯一性。又比如提交的数据存在校验错误,我们可能需要重新刷新该页面,并且
增加新属性“ErrorMessage”,以便把它显示在界面上,提醒用户注意。
我们可以看上面最后一个“添加用户”的例子,一个LoginInfo的BO转化为PO的时候被拆分成了2个对象,一个存放基本的用户信息,一个存放对应的Role信息。通常对象拆分的时候,常常需要填充或者补足新对象的内容;而对象合并的时候,常常出现内容减少的情况。
出现对象属性类型的变化在VO到BO的转换中比较常见,比如把用户输入的生日转化为一个真正的DateTime类型。
属性名称在转换过程中会有变化,一般这种情况应该尽可能不要出现,但是在项目重构的时候出现的概率较大。
除了DTO不同形态之间的转换规律之外,不同形态内部还有不同的工作要做:
“
不要相信任何用户的输入”,这是设计程序跟用户进行交互操作时候永远需要遵守的一个原则。也就是所有的外部输入都需要进行正确性的校验。校验器是分为两个
层次,一个是属性层次的校验,比如“年龄”只能0到150之间有效。另外一个是对象层次的校验,或者说跨属性层次的校验,比如“年份输入闰年的时候,2月
可以有29日”等。
校验并不是一个单纯的问题,几乎所有的业务逻辑校验基本都需要一次完整的贯穿所有层次的调用。代价颇大。这个也是为什么我们在显示层做很多事先校验,而一旦进入业务逻辑层的时候,校验就经常会被“事后校验”代替了,人们会使用抛出异常的方法来代替“事前检查”。
中小型软件开发项目一般都具有任务急、工期短的特点,要在确保满足时间、质量、成本和效益的情况下交付给客户满
意软件产品,
必须保证团队与客户、团队成员之间能良好的沟通与协作。沟通与协作是团队开发活动的基础,它贯穿于软件开发的整个生命周期。是软件开发项目速度、成本、效
率的关键。
随着Web服务技术和面向服务的体系结构(SOA)的发展,要求软件开发必须从使用本地丰富的内部应用资源向联接外部广泛分布的服务资源过渡。
这一转变却正面临一些新的困难,新时期的软件开发必须回答如下三个问题:如何使包装为Web服务的软件资源协同工作、如何在技术演进的过程中保持平台的中立性、如何在当前动荡的Internet时代适应需求的变化?
通过与这三个问题相对照,不难发现:传统的软件开发方法难以重用和协同软件资源,难以保持平台的中立性,也难以满足变化的需求。因此,迫切需要一种能够克服这些困难的新方法,那就是——协作开发。
今天的大多软件工作能否获得成功,取决于团队的协作,而不是个人的突出表现,特别是在中小型软件企业当中,创建并维护一个高绩效的团队,以产生潜在的杰作是非常重要的一项工作。团队成员彼此都影响着整个团队的成功,他们必须要向着一个共同的目标而合作。
孤军作战已经成为历史
几年前,“软件开发是一项团队活动”是Rational提出的口号之一。可以说,直到今天,这个标语更为正确了,个体开发者在单独完成一个重要项目的时代已经成为过去了。
然而,简单地将一些人分配给某项目并不意味着你拥有了一个团队。要想创建一个有效的工作组,团队成员必须相互“检入”且配合。敏捷开发中提到,团队成员应当可以认识到彼此的优点和缺点,并相互配合以取得成功。
多年来,人们仅将软件局限在应用工具的狭小区域,这种片面的理解致使人们很难联想起大规模的软件工业。因而,软件开发往往与编写程序等同起来,而调研分析、建模、测试、部署和全局管理等工作却被忽略。
这种局面在一些中小型软件开发项目当中非常明显,特别是对任务认识的片面性也体现在对软件开发角色的划分上,程序编写者(开发人员)是主力军,代表了一切。如此以来,在开发工作中就呈现“独木难支”的局面。
可见,今天的软件开发已不单是一种技术或工具的应用,抑或一种灵感的迸发。资源的调配、协作的布局、流程的设置在软件开发中占据越来越重要的地位。技术、工具、人和管理方法以开发对象为核心,要达到水乳交融的境界。
在潜心经营软件开发工具多年后,IBM Rational力求通过整合将软件开发的要素粘合在一起,提供一种功能强大的平台,促进软件工艺的发展。
从角色入手管理团队
虽然充分的协作开发具有很多优势,但这在事实运行当中却存在很多问题,例如,对于一个管理者而言,一类挑战是在既有协作团队中增加新的成员。有
些小公司起步于一个核心团队。当公司发展壮大时,该核心团队需要吸收新的成员,这时,就有可能发生一些冲突。结果可能是,新成员会被驱逐出来或者核心团队
成员选择放弃并离开公司。
以下有几个方法,可以避免出现类似的情况。
首先,当新成员加入一个团队时,请确保他们的个性与本团队相匹配。
第二,不要聘请超级明星。尽管他们可能带来好的效果,但是你想要他们做的大部分工作可能对于有经验的人们而言已是重复工作,而且也不能够充分他们的才能。
第三,或许最重要的是,当团队中加入新成员时,为他们指派一些可以帮助他们掌握窍门并理解文化的良师。这将有助于他们更快地融入团队并产生一种归属感和成就感。
从项目当中的角色管理入手,也是提高协作开发效率的一项重要举措,IBM Rational所倡导的整合开发平台,是将与软件开发相关的所有人员凝聚在一起,通过一套整合的流程和全面的质量控制机制,形成一个功能强大的开发平台。
高品质软件是多道工序锤炼的结果,创造高品质软件的开发平台必须整合完成所有这些工序的角色,以使其倾力协作。角色的整合建立在清晰的角色定位
之上,从开发实践中IBM
Rational定义了项目经理、系统分析人员、架构设计师、开发人员、测试人员、部署人员六大角色,他们的工作环环相扣,形成一个缺一不可的团体,每一
个角色都能在开发平台上找到自己的位置,并能获取适合自己的工具。
沟通与协作不仅指开发团队的内部成员之间,,也包括开发团队与用户、客户之间的互动。在软件开发的全过程中,
沟通与协作是一切活动的基础,它将会扮演越来越重要的角色,而采用专业的平台与工具,不仅将会让团队的沟通写作更加有序、高效,更能够保证整个软件项目的
质量与客户满意度。
2008年7月17日
<SCRIPT language="javascript">
代码......
</SCRIPT>
添加到head头部中。
这种添加js在jsp中其作用,而在html中没有做用。要添加到元素后面js才其作用。
2008年6月5日
1.什么是软件概要设计?该阶段的基本任务是什么?
软件概要设计:在需求分析的基础上通过抽象和分解将系统分解成模块,确定系统功能是实现,即把
软件需求转换为软件包表示的过程。
基 本 任 务:
(1)设计软件系统结构(简称软件结构)
a.采用某种设计方法,将一个复杂的系统按功能划分成模块(划分)
b.确定模块的功能。 (功能)
c.确定模块之间的调用关系。 (调用)
d.确定模块之间的接口,即模块之间传递的信息。 (接口)
e.评价模块结构的质量。 (质量)
(2)数据结构及数据库设计
a.数据结构设计
b.数据库设计:(概念设计、逻辑设计、物理设计)
(3)编写概要设计文档(文档主要有:概要设计说明书、数据库设计说明书、用户手册、修订测试计划)
(4)评审
2.软件设计的基本原理包括哪些内容?
软件设计的基本原理:
(1)模块化(四个属性:接口、功能、逻辑、状态)
(2)抽象
(3)信息隐蔽
(4)模块独立性(两个定性的度量标准:耦合性与内聚性)
3.衡量模块独立性的两个标准是什么?它们各表示什么含义?
两个定性的度量标准:耦合与内聚性
耦合性:也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就
越强,模块的独立性则越差。
内聚性:也称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。模块内元
素联系越紧密,内聚性越高。
4.模块间的耦合性有哪几种?它们各表示什么含义?
耦合性有六种:无直接耦合、数据耦合、标记耦合、控制耦合、公共耦合、内容耦合
无直接耦合:两个模块之间没有直接的关系,它们分别从属于不同模块的控制与调用,它们之间不传递任何信息。 (无直接关系)
数据耦合:指两个模块之间有调用关系,传递的是简单的数据值,相当于高级语言中的值传递。 (数据值 )
标记耦合:指两个模块之间传递的是数据结构。 (数据结构 )
控制耦合:指控制模块调用另一个模块时,传递的是控制变量,被调用块通过该控制变量的值有选择地执行块内某一功能(控制变量 )
公共耦合:指通过一个公共数据环境相互作用的那些模块间的耦合。 (一个公式数据环境)
内容耦合:一个模块直接使用另一个模块的内部数据,或通过非正常入口而转入另一个模块内部 (内部数据 )
5.模块的内聚性有哪几种?各表示什么含义?
模块间的内聚性有6种:偶然内聚、逻辑内聚、时间内聚、通信内聚、顺序内聚、功能内聚。
偶然内聚:一个模块内的各处理元素之间没有任何联系。
逻辑内聚:模块内执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。
时间内聚:把需要同时执行的动作组合在一起。
通信内聚:指模块内所有处理元素都在同一个数据结构上操作,或者指各处理使用相同的输入数据或产生相同的输出数据。
顺序内聚:一个模块中各处理元素都密切相关于同一功能且必须顺序执行,前一功能元素的输出是下一功能元素的输入。
功能内聚:最强的内聚,指模块内所有元素共同完成一个功能,缺一不可。
6.什么是软件结构?简述软件结构设计优化准则。
软件结构:软件系统的模块层次结构,反映了整个系统的功能实现,即将来程序的控制体系。
软件结构设计优化准则:
a.划分模块时,尽量做到高内聚,低耦合,保持模块相对独立性,以此为原则优化初始的软件结构。
b.一个模块的作用范围应在其控制范围之内,且判定所在的模块应与受其影响的模块在层次上尽量靠近
c.软件的深度、宽度、扇入、扇出应适当。
D.模块的大小要适中。
E.模块的控制范围模块的接口要简单、清晰、含义明确,便于理解,易于实现、测试与维护。
7.什么是模块的影响范围?什么是模块的控制范围?它们之间应该建立什么关系?
模块的影响范围:受该模块内的一个判定影响的所有模块的集合。
模块的控制范围:模块本身及其所有下属模块(直接或间接从属于它的模块)的集合。
一个模块的影响范围应在其控制范围之内,且判定所在的模块应与受其影响的模块在层次上尽量靠近。
8.什么是"变换流"?什么是“事务流”?试将相应形式的数据流图转换成软件结构图。
变换流由输入、变换(或处理)、输出三部分组成。某个加工将它的输入流分离成许多发散
的数据流,形成许多加工路径,并根据输入选择其中一个路径来执行这种特征的DFD称为事物流。
9.试述“变换分析”,“事务分析”的设计步骤。
变换分析:
a.确定DFD中的变换中心。
b.设计软件结构的顶层和第一层-------变换结构。
c.设计中下层模块。(输入模块下属模块的设计,输出模块下属模块的设计,变换模块下属模块的设计,设计的优化)
事务分析:
a.确定DFD中的事务中心和加工路径。
b.设计软件结构的顶层和第一层------事务结构。(接收、发送给支)
c.事务结构中、下层模块的设计、优化工作同变换结构。
1、测试任何可能的错误。单元测试不是用来证明您是对的,而是为了证明您没有错。
2、单元测试代码和被测试代码使用一样的包,不同的目录。
--junit4.0使用注意说明;
3、测试方法必须按照规范书写
1. 测试方法必须使用注解 org.junit.Test 修饰。
2. 测试方法必须使用 public void 修饰,而且不能带有任何参数。
@Test public void wordFormat4DBegin(){
String target = "EmployeeInfo";
String result = WordDealUtil.wordFormat4DB(target);
assertEquals("employee_info", result);
}
4、同一测试类中的所有测试方法都可以共用它来初始化 Fixture 和注销 Fixture。和编写 JUnit 测试方法一样,公共 Fixture 的设置也很简单,您只需要:
1. 使用注解 org,junit.Before 修饰用于初始化 Fixture 的方法。
2. 使用注解 org.junit.After 修饰用于注销 Fixture 的方法。
3. 保证这两种方法都使用 public void 修饰,而且不能带有任何参数。
//初始化Fixture方法
@Before public void init(){……}
//注销Fixture方法
@After public void destroy(){……}
引入了类级别的 Fixture 设置方法,编写规范如下:
1. 使用注解 org,junit.BeforeClass 修饰用于初始化 Fixture 的方法。
2. 使用注解 org.junit.AfterClass 修饰用于注销 Fixture 的方法。
3. 保证这两种方法都使用 public static void 修饰,而且不能带有任何参数
//类级别Fixture初始化方法
@BeforeClass public static void dbInit(){……}
//类级别Fixture注销方法
@AfterClass public static void dbClose(){……}
类级别的 Fixture 仅会在测试类中所有测试方法执行之前执行初始化,并在全部测试方法测试完毕之后执行注销方法。
5、注解 org.junit.Test 中有两个非常有用的参数:expected 和 timeout。
1、参数 expected 代表测试方法期望抛出指定的异常,如果运行测试并没有抛出这个异常,则 JUnit 会认为这个测试没有通过。
@Test(expected=UnsupportedDBVersionException.class)
public void unsupportedDBCheck(){
……
}
2、参数timeout,指定被测试方法被允许运行的最长时间应该是多少,如果测试方法运行时间超过了指定的毫秒数,则JUnit认为测试失败。
@Test(timeout=1000)
public void selfXMLReader(){
……
}
6、org.junit.Ignore 用于暂时忽略某个测试方法,因为有时候由于测试环境受限,并不能保证每一个测试方法都能正确运行。
@ Ignore(“db is down”)
@Test(expected=UnsupportedDBVersionException.class)
public void unsupportedDBCheck(){
……
}
7、新概念出现了——测试运行器
JUnit 中所有的测试方法都是由它负责执行的。JUnit 为单元测试提供了默认的测试运行器,但 JUnit 并没有限制您必须使用默认的运行器。相反,您不仅可以定制自己的运行器(所有的运行器都继承自 org.junit.runner.Runner),而且还可以为每一个测试类指定使用某个具体的运行器。指定方法也很简单,使用注解 org.junit.runner.RunWith 在测试类上显式的声明要使用的运行器即可:
@RunWith(CustomTestRunner.class)
public class TestWordDealUtil {
……
}
8、
在实际项目中,随着项目进度的开展,单元测试类会越来越多,可是直到现在我们还只会一个一个的单独运行测试类,这在实际项目实践中肯定是不可行的。为了解决这个问题,JUnit 提供了一种批量运行测试类的方法,叫做测试套件。这样,每次需要验证系统功能正确性时,只执行一个或几个测试套件便可以了。测试套件的写法非常简单,您只需要遵循以下规则:
1. 创建一个空类作为测试套件的入口。
2. 使用注解 org.junit.runner.RunWith 和 org.junit.runners.Suite.SuiteClasses 修饰这个空类。
3. 将 org.junit.runners.Suite 作为参数传入注解 RunWith,以提示 JUnit 为此类使用套件运行器执行。
4. 将需要放入此测试套件的测试类组成数组作为注解 SuiteClasses 的参数。
5. 保证这个空类使用 public 修饰,而且存在公开的不带有任何参数的构造函数。
package com.ai92.cooljunit;
import org.junit.runner.RunWith;
import org.junit.runners.Suite;
……
/**
* 批量测试 工具包 中测试类
* @author Ai92
*/
@RunWith(Suite.class)
@Suite.SuiteClasses({TestWordDealUtil.class,xxx.class})
public class RunAllUtilTestsSuite {
}
上例代码中,我们将前文提到的测试类 TestWordDealUtil 放入了测试套件 RunAllUtilTestsSuite 中,在 Eclipse 中运行测试套件,可以看到测试类 TestWordDealUtil 被调用执行了。测试套件中不仅可以包含基本的测试类,而且可以包含其它的测试套件,这样可以很方便的分层管理不同模块的单元测试代码。但是,您一定要保证测试套件之间没有循环包含关系,否则无尽的循环就会出现在您的面前……
9、参数化测试
为了保证单元测试的严谨性,我们模拟了不同类型的字符串来测试方法的处理能力,为此我们编写大量的单元测试方法。可是这些测试方法都是大同小异:代码结构都是相同的,不同的仅仅是测试数据和期望值。有没有更好的方法将测试方法中相同的代码结构提取出来,提高代码的重用度,减少复制粘贴代码的烦恼?在以前的 JUnit 版本上,并没有好的解决方法,而现在您可以使用 JUnit 提供的参数化测试方式应对这个问题。
参数化测试的编写稍微有点麻烦(当然这是相对于 JUnit 中其它特性而言):
1. 为准备使用参数化测试的测试类指定特殊的运行器 org.junit.runners.Parameterized。
2. 为测试类声明几个变量,分别用于存放期望值和测试所用数据。
3. 为测试类声明一个使用注解 org.junit.runners.Parameterized.Parameters 修饰的,返回值为 java.util.Collection 的公共静态方法,并在此方法中初始化所有需要测试的参数对。
4. 为测试类声明一个带有参数的公共构造函数,并在其中为第二个环节中声明的几个变量赋值。
5. 编写测试方法,使用定义的变量作为参数进行测试。
我们按照这个标准,重新改造一番我们的单元测试代码:
@RunWith(Parameterized.class)
public class TestWordDealUtilWithParam {
private String expected;
private String target;
@Parameters
public static Collection words(){
return Arrays.asList(new Object[][]{
{"employee_info", "employeeInfo"}, //测试一般的处理情况
{null, null}, //测试 null 时的处理情况
{"", ""}, //测试空字符串时的处理情况
{"employee_info", "EmployeeInfo"}, //测试当首字母大写时的情况
{"employee_info_a", "employeeInfoA"}, //测试当尾字母为大写时的情况
{"employee_a_info", "employeeAInfo"} //测试多个相连字母大写时的情况
});
}
/**
* 参数化测试必须的构造函数
* @param expected 期望的测试结果,对应参数集中的第一个参数
* @param target 测试数据,对应参数集中的第二个参数
*/
public TestWordDealUtilWithParam(String expected , String target){
this.expected = expected;
this.target = target;
}
/**
* 测试将 Java 对象名称到数据库名称的转换
*/
@Test public void wordFormat4DB(){
assertEquals(expected, WordDealUtil.wordFormat4DB(target));
}
}
10、junit3兼容junit4可以在测试类中加入
public static junit.framework.Test suite() {
return new JUnit4TestAdapter(AssertionTest.class);
}
11、JUnit 4 为比较数组添加了两个 assert() 方法:
public static void assertEquals(Object[] expected, Object[] actual)
public static void assertEquals(String message, Object[] expected, Object[] actual)
这两个方法以最直接的方式比较数组:如果数组长度相同,且每个对应的元素相同,则两个数组相等,否则不相等。数组为空的情况也作了考虑。
12、需要补充的地方
JUnit 4 基本上是一个新框架,而不是旧框架的升级版本。JUnit 3 开发人员可能会找到一些原来没有的特性。
最明显的删节就是 GUI 测试运行程序。如果您想在测试通过时看到赏心悦目的绿色波浪线,或者在测试失败时看到令人焦虑的红色波浪线,那么您需要一个具有集成 JUnit支持的 IDE,比如 Eclipse。不管是 Swing 还是 AWT 测试运行程序都不会被升级或捆绑到 JUnit 4 中。
下一个惊喜是,失败(assert 方法检测到的预期的错误)与错误(异常指出的非预期的错误)之间不再有任何差别。尽管JUnit3测试运行程序仍然可以区别这些情况,而JUnit4运行程序将不再能够区分。
最后,JUnit 4没有 suite()方法,这些方法用于从多个测试类构建一个测试套件。相反,可变长参数列表用于允许将不确定数量的测试传递给测试运行程序。
2008年6月2日
1. 简单的Eclipse模板的创建
直接将需要作为模板的语句填写在模板的Pattern栏里,如前面的public final static String SEQUENCE_T_PRODUCT_HIST = "T_PRODUCT_HIST";这样的常量的定义。我们可以定义一个strConstant的模板,将该模板的Pattern写为:“public final static String ${cursor} ;”。其中${cursor}的意思是光标所在的位置。
这样,你如果在程序的适当位置输入:strConstant,然后点击Atl /,那么你将得到如下的结果:
public final static String (光标所在位置) ;
在实际的项目中,我们会遇到这样的情况:
if (LOG.isDebugEnabled()) {
LOG.debug(METHOD_NAME, "The user : " user.getName);
}
我们为了性能的考虑,经常希望在日志被关闭以后,不再执行LOG.debug方法里面的任何操作,如"The user : " user.getName这样的语句。所以我们在LOG.debug方法外面加上LOG.isDebugEnabled()这样的判断语句。加上了判断语句以后,代码的性能得到了提高,但每一个日志都加上:
if (LOG.isDebugEnabled()) {
}
却带来了代码重用上的困难。如今使用Eclipse模板正好解决了这个问题。
我们来创建一个enabledLOG的模板,它的Pattern为:
if (LOG.isDebugEnabled()) {
LOG.debug(METHOD_NAME, "${cursor}");
}
还有一个例子,我们在写自定义标签的时候,经常需要编码的是doEndTag方法,在这个方法里面,我们要先写日志:
final String METHOD_NAME = "doEndTag";
PLOG.info(METHOD_NAME, PerformanceLogger.Event.METHOD_ENTRY);
然后将我们的代码用try…catch包括起来,如下:
try {
……
} catch (Exception e) {
LOG.error(METHOD_NAME, "……", e);
}
省略号都是我们要写的代码。
最后,我们又需要纪录日志,然后返回,如下:
PLOG.info(METHOD_NAME, PerformanceLogger.Event.METHOD_EXIT);
return SKIP_BODY;
每一个自定义标签的格式都是如此,因此,我们可以创建一个doEndTag的模板,它的Pattern为:
public int doEndTag() throws JspException {
final String METHOD_NAME = "doEndTag";
PLOG.info(METHOD_NAME, PerformanceLogger.Event.METHOD_ENTRY);
try {
${cursor}
} catch (Exception e) {
LOG.error(METHOD_NAME, "", e);
}
PLOG.info(METHOD_NAME, PerformanceLogger.Event.METHOD_EXIT);
return SKIP_BODY;
}
在实际的编码过程中,我们会遇到很多这样的例子,使用Eclipse模板,将会把我们从烦躁而易于出错的拷贝粘贴中解放出来。
2. 带参数的Eclipse模板
Eclipse除了能让我们创建简单的、静态的Eclipse模板以外,还可以让我们创建动态的模板,这就是带参数的模板。请看下面的例子:
private static final String EMPLOYEE_SQL = "SELECT * FROM EMPLOYEE";
protected String getEMPLOYEE_SQL () {
return EMPLOYEE_SQL;
}
private static final String DEPART_SQL = "SELECT * FROM DEPARTMENT";
protected String getDEPART_SQL () {
return DEPART_SQL;
}
这是我在实际项目中遇到过的代码,这两个相似的代码,除了常量的值不同以外,还有常量名不同,get方法不同,但get方法都是“get 常量名”的组合。对于这样的模板,我们就需要引入带参数的Eclipse模板。具体方法如下:
我们创建一个名为sqlConstant的模板,它的Pattern如下:
private static final String ${name} = "";
protected String get${name}() {
return ${name};
}
其中的${name}就是我们的模板参数,当我们在程序的适当位置输入sqlConstant,然后点击Alt /的时候,出现如下的效果:
这种参数的好处是,我们有三个地方为name,当我们在一个地方修改name为EMPLOYEE_SQL的时候,其他的两个地方的name同时改为EMPLOYEE_SQL。
我们看,这样的带参数的模板是不是很好用。
我们再来看一个例子:
假设我们有这样的代码,
protected static IEmployeeBSV getEmployeeBSV()
{
IBusinessServiceManager bsvmgr = GenericContainer.getInstance().getBusinessServiceManager();
return (IEmployeeBSV) bsvmgr.getBusinessService(IEmployeeBSV.class);
}
protected static IDepartmentBSV getDepartmentBSV()
{
IBusinessServiceManager bsvmgr = GenericContainer.getInstance().getBusinessServiceManager();
return (IDepartmentBSV) bsvmgr.getBusinessService(IDepartment.class);
}
我们就可以创建一个名为bsv的模板,其Pattern如下:
protected static I${enclosing_method} get${enclosing_method}()
{
IBusinessServiceManager bsvmgr = GenericContainer.getInstance().getBusinessServiceManager();
return (I${enclosing_method}) bsvmgr.getBusinessService(I${enclosing_method}.class);
}
从上面的例子可以看出,给Eclipse模板带上参数以后,对Eclipse模板的使用就更加的灵活了。这样,我们就可以更加灵活的创建Eclipse模板,更加灵活的使用Eclipse模板了。
3. Eclipse模板的几个特殊参数
我们可以引用${enclosing_type}参数来代表使用模板的代码所在的类的类名。假如我们有如下的代码:
public class ICRMValidationFormTag
{
private final static Logger.Module MOD = new Logger.Module(ModuleId.MOD_TAG);
private final static Logger LOG = Logger.getLogger(ICRMValidationFormTag.class, MOD);
private final static PerformanceLogger PLOG = PerformanceLogger.getLogger(ICRMValidationFormTag.class);
……
}
public class Employee
{
private final static Logger.Module MOD = new Logger.Module(ModuleId.MOD_TAG);
private final static Logger LOG = Logger.getLogger(Employee.class, MOD);
private final static PerformanceLogger PLOG = PerformanceLogger.getLogger(Employee.class);
……
}
我们可以将每个类的前面三行作为一个模板,名为myLog模板,Pattern为:
private final static Logger.Module MOD = new Logger.Module(ModuleId.MOD_TAG);
private final static Logger LOG = Logger.getLogger(${enclosing_type}.class, MOD);
private final static PerformanceLogger PLOG = PerformanceLogger.getLogger
(${enclosing_type}.class);
这样,如果我们在ICRMValidationFormTag类里引用myLog模板,如下:
public class ICRMValidationFormTag
{
myLog
}
则模板中凡是${enclosing_type}的地方,都将被ICRMValidationFormTag代替。
如果我们在Employee类中引用该模板,如下:
public class Employee
{
myLog
}
则模板中凡是${enclosing_type}的地方,都将被Employee代替。
同理,我们可以使用${enclosing_method}参数来代替使用模板的代码所在方法的方法名,如,如果我们想用模板来代替每一个方法里形如final String METHOD_NAME = "getEmployee";的语句,我们可以使用这样的模板:
模板名为methodName,Pattern为:
final String METHOD_NAME = "${enclosing_method}";
这样,如果你在getEmployee方法里使用该模板,那么结果为:
final String METHOD_NAME = "getEmployee";
如果你在saveEmployee方法里使用该模板,那么结果为:
final String METHOD_NAME = "saveEmployee";
其他的几个常用的特殊参数有:enclosing_method_arguments—返回该参数所在方法的参数类型;encloging_package—返回该参数所在类的包名;enclosing_project—返回该参数所在的项目名;enclosing_type—返回该参数所在类的类名等等。
最后,我们以一个完整一点的例子作为本文的结束语。
在Spring的持久层,大家可能都写过这样的代码:
1. Get方法
public ObjOwnedRolePrivilegeModel getRolePrivilegeById(int id) throws Exception
{
final ObjOwnedRolePrivilegeModel oorp = new ObjOwnedRolePrivilegeModel();
try
{
JdbcTemplate template = new JdbcTemplate(dataSource);
String sql = "select ID,ROLE_ID,OBJ_PRIV_ID,DESCRIPTION from t_obj_priv_role where ID=" id;
log.info(this.getClass(), "getRolePrivilegeById", "SQL: " sql);
template.query(sql, new RowCallbackHandler()
{
public void processRow(ResultSet rs) throws SQLException
{
//ObjOwnedRolePrivilege oorp = new ObjOwnedRolePrivilege(rs.getInt(1),rs.getInt(2),rs.getInt(3),rs.getString(4));
oorp.setId(rs.getInt(1));
oorp.setRoleId(rs.getInt(2));
oorp.setObjPrivId(rs.getInt(3));
oorp.setDescription(rs.getString(4));
}
});
}
catch(Exception Ex)
{
log
.error(this.getClass(), "getRolePrivilegeByid", Ex,
Ex.getMessage());
throw new PersistenceException(Ex);
}
return oorp;
}
2. Save方法
public void addPrivilege(final ObjOwnedPrivilegeModel oop) throws Exception
{
StringBuffer sbSql = new StringBuffer();
try
{
JdbcTemplate template = new JdbcTemplate(dataSource);
sbSql
.append("insert into t_obj_privilege(ID,OBJ_ID,OBJ_TYPEID,PRIV_NAME,PRIV_VALUE,DESCRIPTION)");
sbSql.append(" values(?,?,?,?,?,?)");
log.info(this.getClass(), "addPrivilege", "SQL: "
sbSql.toString());
template.update(sbSql.toString(), new PreparedStatementSetter()
{
public void setValues(PreparedStatement ps) throws SQLException
{
ps.setInt(1, oop.getId());
ps.setInt(2, oop.getObjId());
ps.setInt(3, oop.getObjType());
ps.setString(4, oop.getName());
ps.setInt(5, oop.getValue());
ps.setString(6, oop.getDescription());
}
});
}
catch(Exception Ex)
{
//System.out.println(Ex.getMessage());
log.error(this.getClass(), "addPrivilege", Ex, Ex.getMessage());
throw new PersistenceException(Ex);
}
}
3. Delete方法
public void removeUserRole(int[] id) throws Exception
{
String ids = "-1";
for(int i = 0; i < id.length; i )
{
ids = ids "," id[i];
}
String sql = "delete from t_user_role where id in (" ids ")";
log.info(this.getClass(), "removeUserRole", "SQL: " sql);
try
{
JdbcTemplate template = new JdbcTemplate(dataSource);
template.execute(sql);
}
catch(Exception Ex)
{
log.error(this.getClass(), "removeUserRole", Ex, Ex.getMessage());
throw new PersistenceException(Ex);
}
}
这些是典型的对数据库的操作,包括查询、新增、修改和删除。每一种操作都是相似的,有很多的公用代码,但由于代码里既有try…catch语句,又有匿名内部类,所以不好在面向对象的技术上实现重用。但是使用Eclipse模板却是恰到好处。下面我以第一段代码作为例子,其余的代码大家可以自行实现。
我们设计一个名为get的模板,其Pattern为:
final ${return_type} retn ;
try
{
JdbcTemplate template = new JdbcTemplate(dataSource);
String sql = "";
log.info(this.getClass(), "${enclosing_type}", "SQL: " sql);
template.query(sql, new RowCallbackHandler()
{
public void processRow(ResultSet rs) throws SQLException
{
}
});
}
catch(Exception Ex)
{
log
.error(this.getClass(), "${enclosing_type}", Ex,
Ex.getMessage());
throw new PersistenceException(Ex);
}
return retn;
设置行距有一个专门的属性:line-height,这个应该称之为行高。因为我们要设定的是一行的高度,而不是行与行之间的距离。但是行距依然是可以通过我们设定的行高最终产生,所以方法不同,但是目标是一致的。一般我们的行高一定是要超过字体高度的,否则行与行之间就会重叠,当然我们不排除使用这种式做一些特别的效果,但是至少在阅读文本上我们需要行行清楚。行距不宜太大,太大了阅读效率不高,如果太小了又容易读错行。所以一般行高不应超过两个字的高度。
最常用的是1.6em~1.8em之间,
如果宽度很大,我们就需要加大行距不然我们很容易读错行,如果宽度小的时候行距过大则失去了阅读的效率。那么我们把刚才的段落的CSS做一下增加,标注一
下我们的行距:
p {margin:1em 0; line-height:1.6em; }
这样对于一个基本的段落设置就已经完成了,如果需要给这个段落加个首行缩进,还可以为这个段落设置一下字体,字大小,字样式,色彩等等:
p {margin:1em 0; text-indent:2em; font:normal normal 12px/1.6em "宋体"; color:#000; }
这里关于字体的属性也是个缩写形式,顺序是:“font : font-style || font-variant ||
font-weight || font-size || line-height || font-family
”,这里的color是文字的色彩,#后面的数值应该是6位,可以直接复制
Photoshop拾色板里的数值。缩写方式是,奇数位与偶数位的值相同时即可合并为3位的色值。比如:#4488cc,可以缩写
为#48c,如果需要首突出,那么不光需要把text-indent的值设为负值,还需要修改padding的数值,因为突出去的也就是超出了内容区,那么如果padding区没有空间那么这两个突出去的字就无法显示。那我们再给出一个首行突出两字的CSS
p {margin:1em 0; padding:0 0 0 2em; text-indent:-2em; font:normal normal 12px/1.6em "宋体"; color:#000; }
2008年5月29日
在敏捷开发过程中,我们还需要对系统架构进行设计吗?事实上,Martin Fowler在《Is Design
Dead?》一文中已经给出了答案,那就是我们同样不能忽略对系统架构的设计。与计划性的设计(Planned
Design)不同,我们需要演进式的设计(Evolutionary
Design)。在敏捷开发的生命周期中,我们通过每一次迭代来丰富与更新我们的设计方案,以使其最大限度地符合客户对系统的需求。这里所指的需求,包括
功能性需求和非功能性需求。
在Agile Journal四月刊中,IBM's Methods
Group的敏捷专家Scott W. Ambler详细地阐述了在敏捷语境中的架构设计方法,他提出了所谓“架构预测(Architectural
Envisioning)”的方法,以应对敏捷开发中逐步演进的架构设计过程。
Scott指出,敏捷模型驱动开发(Agile Model Driven
Development,AMDD)明确地包括了初始需求分析与架构建模,这个过程发生在敏捷项目开发的第0次迭代中。所谓第0次迭代,就相当于项目的热
身活动,是项目得以启动的基础。在此迭代期间,团队需要充分地理解项目的范围,甄别可行地技术策略。这个阶段所能够收集到的信息将有助于你对整个项目最初
的粗略估计,以制定合适的项目计划,从而获得启动项目的资金与足够的支持。
敏捷模型驱动开发的生命周期如下图所示:
根据图中所示,在每次迭代的初期,制定的迭代计划都应该包括建模的工作。在此期间,可以召开建模的头脑风暴会议,讨论系统的功能特征,并思考实现这些特征的高层设计策略。大多数敏捷团队都会通过测试驱动开发(TDD)确定需求与设计的细节。
通过对架构的预测,可以在项目早期进行一些高层次的架构建模,以助于团队与关键利益相关人商讨系统采取的技术策略。这一行为的关键目标是识别出架构策略,
而不是撰写如山一般堆积的文档,从而使得你能够快速完成架构建模。其中的窍门就是尽量保持简单。开发者不需要对大量的细节进行建模,而只需要足够即可。如
果你正在编写用例,意味着你只需要以标注形式列出用例的要点就足够好了。如果你正在对领域建模,可以直接在白板上绘图,或者使用CRC卡片。你的目的在于
对信息的共享与交流,而不是编写细致的文档。
如果采用架构预测的方式,你需要对哪些内容进行建模呢?Scott在文中指出有如下四部分内容需要建模:
1. 技术图表。例如UML部署图。这些图表有助于开发者预测主要的软件和硬件组件,包括你需要访问的旧系统和数据库,系统有可能会与它们进行交互。
2. 用户交互流程图。通过分析用户交互的主要页面/外观和报告,对系统的UI进行架构设计。如果在进行架构设计的时候不考虑用户交互界面,就可能存在潜在危机,那就是你构建的系统不是利益相关人所希望看到的。请记住,UI才是最终用户使用的系统。
3. 领域图。在最初的架构建模中,一个重要的组成部分是对领域的高层建模。模型可以非常微小,只需要捕获主要的业务实体,以及它们之间的关系。有的人可能认为领域模型应该属于需求建模的一部分,而不是架构建模。但正如上图所示,这两者在第0次迭代中是并发进行的。
4. 变更情形。就是在架构级需求中描述可能的技术或业务变更,而这些变更需要在未来能够提供支持。变更情形要求你考虑架构的扩展能力,但并不是过度构建你的系统。因为你只是要考虑由于变更所造成的影响,以确保你构建的系统还能够正常工作。
架构建模是贯穿于整个项目周期的,因此这些图表就是在项目结束时形成的整体文档的基础。由于你事先明确架构是演进的,因此就不必承担架构设计在项目早期必
须“正确无误”的压力,而只需要在当前形势下保证足够好就可以了。Scott建议使用白板和草稿纸等简便工具,勾勒出这些模型的初始版本。当然,如果团队
成员具有熟练的建模技巧,也可以使用专门的建模工具。这一建议足以体现架构设计的敏捷性,与长篇累牍的传统架构设计方式迥然不同。
对于这样一种架构设计方式,熟悉传统架构设计方式的架构师普遍不以为然。Scott对这一看法给与了强有力的反驳。他将架构设计场景分为三种类型。第一种
是架构师熟悉系统架构设计所必需的技能与经验。既然你已经熟悉了这些内容,当然就没有必要作出完整的设计了。你只需要在白板上体现你的架构设计,保证团队
的每个人都能够按照相同的体系架构进行实现就可以了。
第二种场景是架构师对相关技巧与经验完全不知。此时,仍然只需要作少量的初始建模即可。因为你缺乏足够的知识来完成细致而又全面的架构设计,反而会因为了解不够而导致错误,从而增加项目的风险,并且阻碍了项目的进度。
第三种场景则是架构师熟悉部分知识。这种情形也是团队开发中最常见的场景。在这种情况下,可以耗费几天时间作出一个初始的架构建模,以验证系统可能存在的
风险,并制定可能策略以减轻风险可能造成的后果。你可以实现一些可工作的代码来验证架构。建模在这种情况下是非常有意义的,因为它使得你可以定义一个一致
的技术愿景,为团队成员所分享,并对系统的主要问题进行思考。
当你的团队成员是分散在各地时,或者当团队非常庞大,下面分为多个小组时,这种初始的架构建模就能够带来无与伦比的价值。它有助于在团队成员之间建立一个
公共的愿景,更重要的是它能够识别出分离的组件/子系统,以及这些组件的初始接口。一旦识别出这些耦合度较低的组件或子系统,就能够合理地对团队进行分
组,并保证小组之间设计与实现的一致性。
Scott指出,所谓的“架构预测”能够提供如下价值:
1. 提高生产力
2. 降低技术风险
3. 减少开发时间
4. 增强沟通
5. 可伸缩的敏捷软件开发。
需要明确的是,这样的一种架构预测方式,正好符合敏捷开发迭代的需要。在项目开发早期,对系统整体进行一次高层次的概览,并对关键业务需求进行甄别与分
析,划分合理的系统模块,有助于在迭代开发中为团队成员建立一个统一的标准与目标。而在每次迭代过程中,团队就可以对本次迭代期间的功能进行深入的架构建
模,然后通过TDD充分理解需求,对模块的细节进行设计与实现。这是敏捷架构设计的核心操作原理,它与敏捷开发原则是一脉相承的。
2008年5月27日
1 Target
指定所定义的annotation可以用在哪些程序单元上
如果Target没有指定,则表示该annotation可以使用在任意程序单元上
代码
@Target({ElementType.ANNOTATION_TYPE,
ElementType.CONSTRUCTOR,
ElementType.FIELD,
ElementType.LOCAL_VARIABLE,
ElementType.METHOD,
ElementType.PACKAGE,
ElementType.PARAMETER,
ElementType.TYPE})
public @interface TODO {}
2 Retention
指出Java编译期如何对待annotation
annotation可以被编译期丢掉,或者保留在编译过的class文件中
在annotation被保留时,它也指定是否会在JVM加载class时读取该annotation
代码
@Retention(RetentionPolicy.SOURCE) // Annotation会被编译期丢弃
public @interface TODO1 {}
@Retention(RetentionPolicy.CLASS) // Annotation保留在class文件中,但会被JVM忽略
public @interface TODO2 {}
@Retention(RetentionPolicy.RUNTIME) // Annotation保留在class文件中且会被JVM读取
public @interface TODO3 {}
3 Documented
指出被定义的annotation被视为所熟悉的程序单元的公开API之一
被@Documented标注的annotation会在javadoc中显示,这在annotation对它标注的元素被客户端使用时有影响时起作用
d, Inherited
该meta-annotation应用于目标为class的annotation类型上,被此annotattion标注的class会自动继承父类的annotation
4 Annotation的反射
我们发现java.lang.Class有许多与Annotation的反射相关的方法,如getAnnotations、isAnnotationpresent
我们可以利用Annotation反射来做许多事情,比如自定义Annotation来做Model对象验证
代码
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.FIELD, ElementType.METHOD })
public @interface RejectEmpty {
/** hint title used in error message */
String value() default "";
}
@Retention(RetentionPolicy.RUNTIME)
@Target( { ElementType.FIELD, ElementType.METHOD })
public @interface AcceptInt {
int min() default Integer.MIN_VALUE;
int max() default Integer.MAX_VALUE;
String hint() default "";
}
使用@RejectEmpty和@AcceptInt标注我们的Model的field,然后利用反射来做Model验证
2007年11月13日
2005 年 8 月 18 日
在最近的Web应用开发中,Hibernate,Spring,Struts框架做为开源的轻量级框架,正被越来越多的开发者使
用,而如何将这些框架集成起来,应用到WebSphere
Portlet开发中去,将是本文讨论的内容。本文还描述了将这些框架应用到Portlet上的时候,遇到的一些细节问题。
引言
Hibernate是最近比较流行的一个用来处理O/R
Mapping的持久层框架。它的工作原理是通过文件把值对象和数据库表之间建立起一个映射关系,这样,我们只需要通过操作这些值对象和
Hibernate提供的一些基本类,就可以达到使用数据库的目的。使用Hibernate可以很好的将持久层和逻辑层进行隔离。请参阅参考资料一节获得
更多Hibernate框架的信息。
Spring框架是一个包含了MVC层,中间层和持久层管理的框架,其核心模块是bean管理,现在很多的应用都采用Spring的bean管理机制来管理其逻辑层。请参阅参考资料一节获得更多Spring框架的信息。
Struts框架是Apache Jakarta项目的一部分,它为构建Web应用程序提供了很流行的MVC框架。WebSphere
Portal V5提供了Struts
Portlet框架,这个框架针对Portlet应用,将Struts的类包和taglib在URL生成,URL解析等处,做了自己的改写,使
Portlet框架也可以支持Struts应用,将其作为Portlet来部署。
本文将通过构建一个使用Hibernate,Spring,Struts框架的Portlet应用,来描述如何在Portlet应用中使用这些框
架。对于那些并不熟悉使用这些框架进行开发的Web应用程序的读者来说,本文提供了足够的信息使您可以掌握一些基础知识。但本文并不是一篇介绍如何使用这
些框架的教程。
在本文中讨论的应用程序的开发或部署中用到了以下产品:
WebSphere Portal 5.0.2.2
WebSphere Studio Application Developer 5.1.2
请您注意!如果您的部署服务器Portal
Server的版本低于5.0.2.2,您在部署web.xml的时候,在过滤器设置上将会遇到问题导致不能部署,从而无法通过设置过滤器来解决应用程序
的中文问题。如果您的开发环境低于WebSphere Studio Application Developer
5.1.2,您可能不能得到本文中所述的Struts Portlet的全部支持。
示例应用程序
我们的示例应用程序将实现对一组持久数据的标准的创建、读取、更新、删除(Create/Read/Update/Delete,CRUD)操作。这个示例应用程序为一个新闻编辑程序,用户可以在列表中查看新闻,并新建,修改,删除新闻。
虽然这个示例应用程序是一个比较简单的应用,但为了更好的阐述Hibernate,Spring和Struts的作用范围,我们还是将这个应用程序进行分层的阐述:
应用程序的分层
和通常大多数的Web应用程序一样,本应用程序分为四层,这四层是:presentation(描述),business(业务),persistence(持久)和domain model(域模型)。
表示层(The Presentation Layer)
一般来讲,一个典型的Web应用的的末端应该是表示层。用来管理用户的请求,做出相应的响应,给出显示。在这里,我们使用了Struts Portlet框架来实现本应用程序的表示层。
域模型层(The Domain Model Layer )
域模块层由实际需求中的业务对象组成,即我们常说的BO(Business Object) 比如, Order , Pet等等。
开发者在这层 不用管那些DTOs,仅关注domain object即可。
例如,Hibernate允许你将数据库中的信息存放入对象(domain objects),这样你可以在连接断开的情况下把这些数据显示到UI层。
而那些对象也可以返回给持久层,从而在数据库里更新。
业务层(The Business Layer)
一个典型Web应用的中间部分是业务层或者服务层。这一层最容易受到忽视,从而导致大量的代码紧密的耦合在一起,从而使整个程序变的难以维护。在这
里,我们使用Spring框架来解决这个问题,Spring把程序中所涉及到包含业务逻辑和Dao?的Objects--例如transaction
management handler(事物管理控制)、Object Factories(对象工厂)、service
objects(服务组件)--都通过XML来配置联系起来,从而使业务层变得非常灵活和易于维护。
持久层(The Persistence Layer)
持久层是我们典型的Web应用的另一个末端。现在已经有很多很好的ORM开源框架来解决持久层的各种问题,尤其是Hibernate。
Hibernate为Java提供了OR持久化机制和查询服务, 它还给已经熟悉SQL和JDBC API
的Java开发者一个学习桥梁,他们学习起来很方便。 Hibernate的持久对象是基于POJO和Java collections。
前期准备工作
1. 打开WSAD,点击 文件-新建-其他,在弹出的对话框左边选择Portlet开发,右边选择Portlet项目。如图1:
图1

2. 点下一步,在项目名中输入Sample,类型选择Struts
Portlet,如果没有需要配置的高级选项,点击完成。这样,就创建了一个设置为使用 WebSphere Portal Server 所包括的
Struts Portlet Framework 的 Portlet。如图2:
图2

3.
建立目录结构。在刚建的Sample项目上点右键,选择属性-JAVA构建路径-源,选中Sample/JavaSource,选中'除去',将这个目录
从构建路径中清除。点击'添加文件夹',在JavaSource下创建目录:dao,service,web,并将这三个目录添加到构建路径中。在下面的
步骤中,我们将在dao目录下放置和持久层相关的代码,在service目录下放置业务层相关的代码,在web目录下放置struts相关的
action,form代码。在Sample目录下建立Test目录,Test目录下建立dao,service目录。我们将在Test/dao下放置
dao层的JUnit测试代码,在Test/service下放置service层的JUnit测试代码。如图3:
图3

4. 配置环境变量将附件中lib目录下的文件,全部拷贝到Sample项目的对象lib目录下,并在构建路径中完成类路径设置。
5.
配置数据库。在附件中,你可以找到两个文件,分别名为build.xml和build.properties,将其拷贝到Sample应用的根目录下。修
改build.properties文件中关于数据库的设置,包括数据库用户名,数据库密码,数据库名,数据库驱动类名,连接数据库的URL,以及
Hibernate需要使用的数据库Dialect类名。将其设置为你的测试环境数据库一致即可。默认的数据库设置为MySql。
创建域模型层
这层是编码的着手点,我们的编码就从这层开始。 本应用中的Domain Object比较简单,只使用了一个对象:com.ibm.sample.bo.InfoObject.java。
代码清单 :
package com.ibm.sample.bo;
public class InfoObject {
private Long infoId;
private String title;
private String content;
}
|
infoId记录了这个InfoObject对象的唯一标识,title记录了新闻标题,content记录了新闻内容。
创建持久层
1. 持久化BO。 Hibernate是通过POJO工作的,
因此我们先给InfoObject对象的fileds
加上getter,setter方法。Hibernate通过XML文件来映射(OR)对象,在这里,我们使用XDoclet工具来生成
hibernate的XML映射文件。为了使用Xdoclet这个工具,我们需要在BO对象的代码里面添加一些描述语句。修改后的BO对象代码如下:
代码清单2:
package com.ibm.sample.bo;
/**
* @author rayguo mail:guorui@cn.ibm.com
*
* @hibernate.class table="InfoObject"
*
*/
public class InfoObject {
private Long infoId;
private String title;
private String content;
/**
* Returns the Content.
* @return String
*
* @hibernate.property
* @hibernate.column name="Content" not-null="false"
* length="3000"
*/
public String getContent() {
return content;
}
/**
* Returns the id.
* @return Long
*
* @hibernate.id column="infoId"
* generator-class="native"
*/
public Long getInfoId() {
return infoId;
}
/**
* Returns the Title.
* @return String
*
* @hibernate.property
* @hibernate.column name="title" not-null="true"
* length="200"
*/
public String getTitle() {
return title;
}
public void setContent(String string) {
content = string;
}
public void setInfoId(Long long1) {
infoId = long1;
}
public void setTitle(String string) {
title = string;
}
}
|
在类名前的注释@hibernate.class table="InfoObject",表明了这个类将被映射到数据库表InfoObject,在get方法前的注释,表明了每个属性在数据库表中的对应字段。
2.运行Ant的XDoclet任务,生成InfoObject.hbm.xml文件。在WSAD中右键点击build.xml文
件,并选择"运行Ant",运行其中的hibernatedoclet任务,将会在classes目录下生成所需要的
InfoObject.hbm.xml文件。在这个文件中,还定义了用来生成数据库表结构的任务,将在下面做详细说明。
3.创建DAO接口。为了程序的扩展性,我们首先需要创建一个提供数据访问服务的接口层,定义出对外的访问接口,在本示例中,为IInfoObjectDAO,代码如下:
代码清单3:
package com.ibm.sample.dao;
public interface IInfoObjectDAO {
public abstract InfoObject saveInfoObject(InfoObject info);
public abstract InfoObject getInfoObjectById(Long infoId);
public abstract List getAllInfoObjects();
public abstract void removeInfoObject(Long infoId);
}
|
这个接口定义了对InfoObject的RUCD各项操作。
4. 创建DAO层的实现。本示例的DAO层实现,我们采用了Hibernate,按通常的实现,我们需要先得到Hibernate
的session对象,然后调用session对象的save,delete,update等方法来实现对数据对象的CRUD操作,但由于Spring框
架已经提供了对Hibernate框架的良好支持,使我们不再需要再头痛于Hibernate的session管理,事务管理等方面,这些Spring框
架已经进行了很好的封装,我们只需要将我们的Hibernate实现类继承HibernateDaoSupport类,然后通过调用
HibernateTemplate类上的方法,就可以实现我们需要的数据对象访问的操作。代码如下:
代码清单4:
package com.ibm.sample.dao.hibernate;
public class InfoObjectDAOHibernate extends
HibernateDaoSupport implements IInfoObjectDAO {
public InfoObjectDAOHibernate(){
super();
}
public InfoObject saveInfoObject(InfoObject info) {
getHibernateTemplate().saveOrUpdate(info);
return info;
}
public InfoObject getInfoObjectById(Long infoId){
InfoObject info =
(InfoObject) getHibernateTemplate().load(InfoObject.class, infoId);
return info;
}
public void removeInfoObject(Long infoId) {
InfoObject info = getInfoObjectById(infoId);
getHibernateTemplate().delete(info);
}
public List getAllInfoObjects() {
return getHibernateTemplate().loadAll(InfoObject.class);
}
}
|
5.通过配置,将Spring框架与Hibernate框架结合使用。
如果你以前使用过Hibernate,你现在该感到有些迷惑:使用Hibernate框架的时候,需要提供的hibernate.cfg.xml配置文件
应该放在哪里呢?为了使Spring框架能够真正的感知到Hibernate对象,为其添加事务管理,SessionFactory管理等功能,我们需要
添加一个Spring的配置文件,而且,Spring提供了一个便捷的方式-----在Spring内部配置中并入了Hibernate的
hibernate.cfg.xml配置文件。首先在Sample项目的JavaSource/dao目录下,建立文件
applicationContext-hibernate.xml,在文件中添加如下内容:
代码清单5:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<!-- ==================== Start of PERSISTENCE DEFINITIONS ================== -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"
destroy-method="close">
<property name="driverClassName">
<value>com.mysql.jdbc.Driver</value>
</property>
<property name="url">
<value>jdbc:mysql://localhost:3306/infos</value>
</property>
<property name="username">
<value>root</value>
</property>
<property name="password">
<value></value>
</property>
</bean>
<!-- Choose the dialect that matches your "dataSource" definition -->
<bean id="mySessionFactory"
class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
<property name="dataSource">
<ref local="dataSource" />
</property>
<property name="mappingResources">
<list>
<value>com/ibm/sample/bo/InfoObject.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<props>
<prop
key="hibernate.dialect">net.sf.hibernate.dialect.MySQLDialect</prop>
</props>
</property>
</bean>
<!-- DAO object: Hibernate implementation -->
<bean id="infoObjectDAO"
class="com.ibm.b2e.app.itsubsystem.dao.hibernate.InfoObjectDAOHibernate">
<property name="sessionFactory"><ref
local="mySessionFactory"/></property>
</bean>
</beans>
|
Spring的核心功能就是Bean管理,在这个配置文件中,我们配置了3个Java对象,id分别为:dataSource,
mySessionFactory和infoObjectDAO。mySessionFactory的dataSource属性引用了
dataSource对象,infoObjectDAO的sessionFactory属性又引用了mySessionFactory对象。在
Spring框架启动的时候,会自动的根据这个配置文件,生成相应的对象,并将生成的对象注入到对应的属性中去,这就是所谓的"依赖注入"
(dependency injection)。通过这样的方式,可以将我们从 单例模式(singleton
objects)和工厂模式(factories)中解放出来,降低代码的维护成本。在这里,mySessionFactory中配置的属性,对应于
Hibernate的hibernate.cfg.xml配置文件。
dataSource中的属性设置是针对MySql数据库的,你需要将其改成与你的测试环境数据库一致。
好了,至此,我们完成了示例应用的DAO层创建工作,是不是感到有些心神不宁?是的,虽然我们用的不是测试驱动开发(Test Driver Development),可现在也该写点测试用例来测试一下我们刚刚新建的DAO层了。
建立JUnit单元测试来测试DAO层
1. 测试前的数据准备工作。
如果你使用的是MySql数据库,运行ant任务setup-db,此任务将创建一个名为infos的数据库,并在数据库中建立数据表
infoobject。如果你使用的不是MySql数据库,你需要手工建立测试数据库,然后运行ant任务db-prepare,将会在数据库中自动建立
表infoobject。
2. 编写单元测试基类
代码清单6:
package com.ibm.sample.dao;
public class BaseDAOTestCase extends TestCase{
protected final static XmlBeanFactory factory ;
static {
Resource rs1 = new ClassPathResource("applicationContext-hibernate.xml");
factory = new XmlBeanFactory(rs1);
}
}
|
这个基类非常简单,完成的功能就是通过读入Spring的配置文件,构建一个Spring的bean管理工厂,通过将这段代码包含在静态段中,可以确保Spring的Bean工厂对所有的测试只装载了一次。
3. 编写DAO的单元测试
本示例中用到的对InfoObjectDAO进行测试的类为InfoObjectDAOTest,具体代码可以查看附件中的
InfoObjectDAOTest.java类代码。测试覆盖了InfoObject的各个方法,你可以简单的将其拷贝到自己的项目中并运行,如果数据
库都配置正确的话,你将看到绿色的状态条,OK,测试通过,我们的DAO层已经可以顺利运行了,下面我们进入业务层代码的编写。
创建业务层
现在,我们需要来构建我们的BSO(business service
objects)了,用来执行程序的逻辑,调用持久层,得到UI层的requests,处理transactions,并且控制exceptions。
在这里,我们将使用Spring框架,很快,你就会感受到使用Spring框架来管理业务层,将给你的应用程序带来极大的灵活性,和更松散的耦合度。
1. 建立业务服务对象接口
首先我们需要做的,还是要定义出我们在业务层提供的接口。在Spring框架中,任何注册到Spring框架中的bean,如果实现了某个接口,那
么在得到这个bean的时候,只能将其下溯造型成其接口进行操作,而不能直接下溯造型成具体的类型进行操作。原因在于Spring的AOP实现机制,
Spring中的Bean管理实际上是基于动态AOP机制实现,为了实现动态AOP,Spring在默认情况下会使用Java Dynamic
Proxy,但是,Dynamic Proxy要求其代理的对象必须实现一个接口,该接口定义了准备进行代理的方法。而对于没有实现任何接口的Java
Class,需要采用其他方式,Spring通过CGLib实现这一功能。当类实现了一个接口之后,Spring将通过Java Dynamic
Proxy机制实现代理功能,此时返回的Bean,是通过java.lang.reflect.Proxy.newProxyInstance方法创建的
其接口的一个代理实现,这个实例实现了其接口,但与类已经没有继承关系,因此无法通过下溯造型进行强制转型,如果进行转换,则会抛出异常。这也就强制要求
编程人员要面向接口编程,使程序员能够从接口的角度考虑程序设计,从而降低了程序的耦合度。
代码清单7:
package com.ibm.sample.service;
public interface IInfoObjectService {
public abstract InfoObject saveInfoObject(InfoObject infoObject) throws InfoObjectException;
public abstract InfoObject findInfoObjectById(Long id) throws InfoObjectException;
public abstract List findAllInfoObjects() throws InfoObjectException;
public abstract void removeInfoObject(Long deleteId) throws InfoObjectException;
public abstract void setInfoObjectDAO(IInfoObjectDAO infoObjectDAO);
}
|
通过接口可以看到,在业务层对底层的Exception进行了捕捉,并进行了统一的封装,再用定义好的业务服务级别的Exception抛出。注意
到这段代码里有一个 setInfoObjectDAO(),它就是一个DAO Object设置方法,将DAO的实现注射到Service对象中。
但这里并没有一个getInfoObjectDao的方法,这不必要,因为并不会在外部访问这个DAO。Service层将调用这个DAO
Object和持久层通信。我们将用Spring把DAO Object 和 business service
object搭配起来的。因为我们是面向接口编程的,所以并不需要将实现类紧密的耦合在一起。
2.
实现业务服务对象接口,并通过Spring将其和DAO对象关联起来因为本例比较简单,所以接口的实现也很简单,并没有什么复杂的操作,通过调用
InfoObjectDAO对象上的方法,就可以实现服务对象接口,具体的代码见附件中的com.ibm.sample.service.impl.
InfoObjectServiceImpl.java文件。我们主要需要关注的是如何通过Spring将业务对象与DAO对象关联起来,并实现事务。在
Spring的配置文件中添加如下代码:
代码清单8:
<!-- Transaction manager for a single Hibernate SessionFactory (alternative to JTA) -->
<bean id="myTransactionManager"
class="org.springframework.orm.hibernate.HibernateTransactionManager">
<property name="sessionFactory"><ref local="mySessionFactory"/>
</property>
</bean>
<!-- ***** InfoObject SERVICE *****-->
<bean id="infoObjectService"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager"><ref
local="myTransactionManager"/></property>
<property name="target"><ref local="infoObjectTarget"/></property>
<property name="transactionAttributes">
<props>
<prop key="find*">PROPAGATION_REQUIRED,readOnly,-InfoObjectException
</prop>
<prop key="save*">PROPAGATION_REQUIRED,-InfoObjectException</prop>
</props>
</property>
</bean>
<!-- InfoObjectTarget primary business object implementation -->
<bean id="infoObjectTarget" class="com.ibm.sample.service.impl. InfoObjectServiceImpl">
<property name="infoObjectDAO"><ref local="infoObjectDAO"/></property>
</bean>
|
在这里, myTransactionManager引用了mySessionFactory bean。
本例使用一个TransactionProxyFactoryBean,它定义了一个属性transactionManager。
这个对象很有用,它能很方便的处理你申明的事物还有Service Object。你可以通过transactionAttributes
属性来定义怎样处理。TransactionProxyFactoryBean 还有个属性target. 这将会注入我们的 Business
service object(infoObjectTarget)引用, infoObjectTarget定义了
业务服务层,并且它还有个属性,将会注入我们的DAO对象(InfoObjectDAO)引用,通过这个配置,我们就将DAO对象和Service
Object对象关联了起来,并在Business
Service这一层提供了事务管理,在InfoObjectService中所有以find开头的方法,则以只读的事务处理机制进行处理。(设为只读型
事务,可以使持久层尝试对数据操作进行优化,如对于只读事务Hibernate将不执行flush操作,而某些数据库连接池和JDBC
驱动也对只读型操作进行了特别优化。);而使用save开头的方法,将会纳入事务管理范围。如果此方法中抛出异常,则Spring将当前事务回滚,如果方
法正常结束,则提交事务。
在这里,我们的DAO层是使用Hibernate实现的,如果我们将DAO层的实现技术改为JDBC,JDO,DAO等,只需要实现
IInfoObjectDAO接口,并在Spring配置文件里,将infoObjectDAO
bean的实现类名替换为新实现的类名即可,如此就可以将改动控制在最小的范围之内,不会因为DAO层的变化而引起程序结构大规模的改变,显得非常的灵
活,具有良好的可维护性。
建立表示层(The Presentation Layer)
我们已经建立了应用程序的DAO层和Service层,现在我们需要做的就是将Service的接口暴露给表示层,使表示层能够调用到
Service层的接口,并将处理结果展现给用户。在这一层,我们在本示例中将使用Struts Portlet框架编写Portlet进行展现。
设计页面流程
我们先设计一下实现本示例功能的页面操作流程:
用户访问本示例Portlet后,首先看到的是新闻列表,点击新闻链接,可以查看新闻内容,点击新建按钮,进入新建新闻页面,可以新建新闻,选择新闻后,点击编辑新闻按钮,进入编辑新闻页面,可以编辑新闻,选择新闻后,点击删除按钮,可以删除新闻。
由此,我们可以设计出Struts框架下应用需要的元素:
FormBean 表单bean
InfoObjectForm 我们在com.ibm.sample.web.forms包下建立InfoObjectForm类,用来记录一条新闻信息的Formbean对象
Action 操作
我们在 com.ibm.sample.web.actions 包中创建三个 Struts 操作。
GetInfoObjectAction
SaveInfoObjectAction
ListInfoObjectsAction
JSP
ListInfoObjects.jsp :展示新闻列表页面
ViewInfoObject.jsp : 查看新闻页面
EditInfoObject.jsp : 编辑新闻页面
整个应用的Web图如下:
图4

实现表现层对Service层的访问
1. 配置web.xml文件
为了实现表现层对Service层的调用,我们首先需要更改web.xml文件,在里面添加如下代码:
代码清单9:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/classes/applicationContext-hibernate.xml</param-value>
</context-param>
<servlet id="servlet_12345">
<servlet-name>SpringContextServlet</servlet-name>
<servlet-class>org.springframework.web.context.ContextLoaderServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>SpringContextServlet</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
|
通过这样的配置,示例应用程序在启动的时候,会首先初始化Spring框架自带的ContextLoaderServlet,这个Servlet的
作用就是读取由contextConfigLocation指定的Spring配置文件的位置,初始化Spring框架的Context对象,并将这个对
象保存在ServletContext中,留待Action调用。
同时,为了解决中文输入问题,我们在web.xml中加入过滤器,过滤器的具体代码请见附件。
代码清单10:
<filter>
<filter-name>SetCharacterEncodingFilter</filter-name>
<display-name>SetCharacterEncodingFilter</display-name>
<filter-class>com.ibm.sample.web.filter.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GB2312</param-value>
</init-param>
<init-param>
<param-name>ignore</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>SetCharacterEncodingFilter</filter-name>
<url-pattern>/SetCharacterEncodingFilter</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>SetCharacterEncodingFilter</filter-name>
<servlet-name>action</servlet-name>
</filter-mapping>
|
2.定义BaseAction
代码清单11:
public class BaseAction extends StrutsAction{
protected transient final Log log = LogFactory.getLog(getClass());
private static WebApplicationContext wac = null;
public Object getBean(String name) {
return wac.getBean(name);
}
public void setServlet(ActionServlet actionServlet) {
super.setServlet(actionServlet);
ServletContext servletContext = actionServlet.getServletContext();
wac =
WebApplicationContextUtils.getRequiredWebApplicationContext(servletContext);
}
}
|
可以看到,在BaseAction中,维持了一个WebApplicationContext对象,通过调用这个对象的getBean方法,传入配置文件中的bean id,我们就可以定位到这个bean,也就是我们前面定义的业务层的各种服务。
在这里,我们的Action继承自StrutsAction,这个类继承自Struts框架中的Action类,其作用在Portlet
Struts框架中与Action类在Struts框架中的作用类似。我们需要通过重载其public ActionForward
execute(ActionMapping mapping,ActionForm form,PortletRequest
request)throws
Exception方法来实现我们自己的Action类。与Struts框架中的Action类相比,可以发现这个方法的参数中取消了Response对
象,使我们无法简单的引用到,这个设计是由于IBM的WebSphere Portal Server的Portlet框架设计引起的,Portlet
处理分两阶段实现,操作阶段和呈现阶段。操作处理在呈现显示视图之前执行。在操作阶段,只有请求对象才会被传递给
portlet,而响应对象则不会传递,一些在操作阶段提供的信息(即请求参数)在呈现阶段不再可用。另外,因为在 portlet
没有新的事件发生时,刷新 portlet 页面时会调用呈现方法(如
doView()),因此所有呈现该页面所需的信息必须在每次调用该方法时可用,这就意味着,所有需要呈现的信息,都需要保存在
PortletSession对象中,而不能保存在PortletRequest对象中,如果保存在Request对象中,在刷新页面的时候,会因为没有
可用的变量而导致页面出错。
Action类的具体实现,请参见附件中的代码文件。
整个项目文件结构图:

结束语
本示例介绍了如何在 Portlet 开发中引入 Hibernate,Spring 和 Struts Portlet 框架,在下面的下载部分提供了本例的完整实现。附件是本示例的war包,其中已经包含了示例的源代码,可以直接将其导入WSAD中查看。
Portlets
“Portlets
是一种Web组件-就像servlets-是专为将合成页面里的内容聚集在一起而设计的。通常请求一个portal页面会引发多个portlets被调
用。每个portlet都会生成标记段,并与别的portlets生成的标记段组合在一起嵌入到portal页面的标记内。”(摘自Portlet规范,
JSR 168)
本文探讨了以下内容:
1. Portal页面的元素
2. Portal是什么?
3. Portlets是什么?
4. 开发“Hello World” Portlet
5. 在Pluto上部署HelloWorld Portlet
6. 如何创建Portal页面
7. 结束语
8. 资源
Portlet规范将portlet定义为一种“基于Java技术的web组件,由处理请求和生成动态内容的portlet容器管理”。这段话听起来是不是有些费解?本文将说明portlets是什么以及能用它们做什么。
图1显示了在访问一个portal服务器时浏览器中页面的样子。

图1 典型的portal服务器的页面(点击查看原图)
如果仔细查看浏览器里的页面,就会看到页面是由不同的“窗口”组成的。一个窗口用于刷新天气,另一个用于新闻,还有一个用于刷新股价,等等。这里的每一
个窗口都代表了一个portlets。如果看得再仔细些,还会发现每个窗口都有一个标题条和一些按钮,包括最小化和最大化按钮。
在系
统里,这些窗口是相互独立开发、各不同的应用。新闻portlet的开发者创建应用并打包成war格式的文件,随后portal服务器的管理员在服务器上
部署该war文件并创建页面,接下来每个用户会选择在他的页面里有哪些应用。例如,如果用户对股价不感兴趣而对体育感兴趣,他可以用“体育”窗口替换“股
价”窗口。
Portlet技术需要学习许多新概念,本文不可能全都涵盖,因此本文分为两部分。在第一部分里我们详细说明portals和portlets,并开发一个简单的“Hello World”portlet;在第二部分我们将探讨一些高级主题。
我们将用Apache的Pluto服务器(Portlet API 1.0规范的参考实现)来测试我们的示例portlets,我们还会花些时间探讨如何安装和使用Pluto服务器。
Portal页面的元素
图2显示了Portal页面的各种元素。

图2 portal页面的元素
每个portlet页面由一个或多个portlet窗口组成,每个portlet窗口又分为两部分:一个是外观,它决定了portlet窗口的标题条、控制和边界的样式;另一个是portlet段,它由portlet应用填充。
Portal服务器决定了portal页面的整体观感,像标识、标题条颜色、控制图标等。通过修改几个JSP和css模板文件就可以改变portal的整个观感。我们将在“如何创建portal页面”部分对此做深入讨论。
Portal是什么?
在了解portlet之前有必要先了解portal。在Portlet规范里是这样讲的:“portal是一种web应用,通常用来提供个性化、单次登
录、聚集各个信息源的内容,并作为信息系统表现层的宿主。聚集是指将来自各个信息源的内容集成到一个web页面里的活动”。
Portal的功能可以分为三个主要方面:
1. Portlet
容器:Portlet容器与servlet容器非常类似,所有的portlet都部署在portlet容器里,portlet容器控制portlet的生
命周期并为其提供必要的资源和环境信息。Portlet容器负责初始化和销毁portlets,向portlets传送用户请求并合成响应。
2. 内容聚集:Portlet规范中规定portal的主要工作之一是聚集由各种portlet应用生成的内容,我们将在“如何创建Portal页面”部分对此做进一步讨论。
3. 公共服务:portlet服务器的一个强项是它所提供的一套公共服务。这些服务并不是portlet规范所要求的,但portal的商业实现版本提供了丰富的公共服务以有别于它们的竞争者。在大部分实现中都有望找到的几个公共服务有:
o 单次登录:只需登录portal服务器一次就可以访问所有其它的应用,这意味着你无需再分别登录每一个应用。例如一旦我登录了我的intranet网站,我就能访问mail应用、IM消息应用和其它的intranet应用,不必再分别登录这些应用。
Portal服务器会为你分配一个通行证库。你只需要在mail应用里设定一次用户名和密码,这些信息将以加密的方式存储在通行证库中。在你已登录到
intranet网站并要访问mail应用的时候,portal服务器会从通行证库中读取你的通行证替你登录到mail服务器上。你对其它应用的访问也将
照此处理。
o个性化:个性化服务的基本实现使用户能从两方面个性化她的页面:第一,用户可以根据她的自身喜好决定标题条的颜
色和控制图标。第二,用户可以决定在她的页面上有哪些portlets。例如,如果我是个体育迷,我可能会用一个能提供我钟爱球队最新信息的
portlet来取代股票和新闻portlets。
一些在个性化服务方面领先的商业实现版本允许你建立为用户显示什么样的应用所
依据的标准(如收入和兴趣)。在这种情况下,可以设定一些像“对任何收入为X的用户显示馈赠商品的portlet”和“对任何收入为X的用户显示打折商品
的portlet”这样的商业规则。
此外还有一些公共服务,比如机器翻译,是由portal服务器将portlet生成的内容翻译为用户要求的语言。大部分的商业portal服务器都支持手持设备访问并具有针对不同的浏览终端生成不同内容的能力。
Portlets是什么?
与servlets类似,portlets是部署在容器内用来生成动态内容的web组件。从技术角度讲portlet是一个实现了javax.portlet.Portlet接口的类,它被打包成war文件格式部署到portlet容器里。
Portlets在以下方面与servlets相似:
1. portlets由特定的容器管理。
2. portlets生成动态内容。
3. portlet的生命周期由容器管理。
4. portlets通过请求/响应模式与web客户端交互。
Portlets在以下方面与servlets相异:
1. portlets只能生成标记段,而不是整个文档。
2. portlets没有可供直接访问的URL地址。不过你还是能够让别人通过URL访问到portlet,你可以把包含该portlet的页面的URL发给他。
3. portlets
不能随意地生成内容,这是因为portlet生成的内容最终要成为portal页面的一部分。如果portal服务器要求的是html/text类型,那
么所有的portlets都应生成html/text类型的内容。再比方说,如果portal服务器要求的是WML类型,那么所有的portlets都应
生成WML类型的内容。
portlets还提供了一些附加的功能:
1. 设置参数的持久化存储:portlets提供了一个PortletPreferences对象用来保存用户的设置参数。这些参数被存入一个持久化数据库,这样服务器重启后数据依然有效。开发者不必关心这些数据存储的具体实现机制。
2.
请求处理:portlets提供了更为细粒度的请求处理。对于用户在portlet上动作时向该portlet发出的请求(一种称为活跃期的状态),或者
因用户在其它portlet上动作而引发的刷新页面请求,Portal服务器提供了两种不同的回调方法来处理。
3. Portlet
模式:portlets用模式的概念来表示用户在做什么。在使用mail应用的时候,你可能会用它来读信、写信或检查信件――这些都是mail应用的预定
功能,Portlets通常以VIEW模式提供这些功能。但还有一些活动,像指定刷新时间或(重新)设置用户名和密码,这些活动允许用户定制应用的行为,
因此它们用的是EDIT模式。Mail应用的帮助功能用的是HELP模式。
如果仔细想想其实这里面并没有什么新东西,它们反而大部分都是普通的业务需求。Portlet规范的作用在于它提供了一个抽象层,这才是它对所有与之相关的人-最终用户、开发者和管理员-的价值所在。
作为一个开发者,我会将所有与VIEW模式有关的业务逻辑放入doView()方法,将与应用配置有关的业务逻辑放入doEdit()方法,将与帮助有关的逻辑放入doHelp()方法
这就简化了管理员对portlet应用的访问控制管理,因为他只需改变portlet的访问权限就能决定用户能做什么。例如,如果mail应用的一个用户能够在EDIT模式下设定用户名和密码,那么就可以断定他具有EDIT模式访问权限。
不妨考虑这样一种情形:我是一个intranet网站的管理员,我的公司买了一个能显示新闻信息的第三方portlet应用,该应用允许用户指定跟踪新
闻更新的URL地址,我想借助它为用户显示公司的内部新闻。另一个需求是我不想让用户通过该应用来跟踪任何其它的新闻信息来源。作为管理员,我可以为所有
的用户指定一个用于内部新闻更新的URL地址,同时通过改变portlet应用的部署描述符来取消其它人修改该地址的权限。
由于所有的portlet应用都具有相似的UI界面,因此采用portlets可使网站对最终用户更具吸引力。如果她想阅读任何一个应用的帮助信息,她可以点击帮助按钮;她也知道点击编辑按钮能让她进入应用的配置屏。标准化的用户界面使你的portlet应用更引人。
4.
窗口状态:窗口状态决定了portal页面上留给portlet生成内容的空间。如果点击最大化按钮,portlet将占据整个屏幕,成为用户唯一可用的
portlet;而在最小化状态,portlet只显示为标题条。作为开发者应当根据可用空间的大小来定做内容。
5. 用
户信息:通常portlets向发出请求的用户提供个性化的内容,为了能更加行之有效,portlets需要访问用户的属性信息,如姓名、email、电
话等。Portlet
API为此提供了用户属性的概念,开发者能够用标准的方式访问这些属性,并由管理员负责在这些属性与真实的用户信息数据库(通常是LDAP服务器)之间建
立映射关系。
我们将在本文的第二部分深入讨论这些特点-请求处理、用户信息和portlet模式。
开发"Hello World" Portlet
现在我们就来开发一个简单的HelloWorld portlet。
1. 创建一个名为HelloWorld的web项目,它与通常的servlet项目类似,有一个/WEB-INF/web.xml文件作为项目的部署描述符。
2. 在build path里加入portlet-api-1.0.jar文件,该jar文件是Pluto发行包的一部分。
3. 在Source文件夹中按如下内容创建HelloWorld.java文件:
public class HelloWorld extends GenericPortlet{
protected void doView(RenderRequest request,
RenderResponse response) throws
PortletException, IOException {
response.setContentType("text/html");
response.getWriter().println("Hello Portlet");
}
}
每个portlet都要实现Portlet接口,该接口为portlet定义了生命周期方法。由于不想覆盖所有这些方法,我们只对
GenericPortlet类进行扩展,它是一个实现了Portlet接口的适配器类。GenericPortlet类提供了所有生命周期方法的默认实
现,所以我们只需实现我们所需要的方法。
我们在 HelloWorld portlet里要做的只是显示“Hello
Portlet”,所以我们将覆盖GenericPortlet类的doView()方法,该方法以PortletRequest 和
PortletResponse作为参数。在doView()方法中首先调用response.setContentType()以通知portlet容
器该portlet将要生成何种类型的内容-如果不这样做就会导致IllegalStateException异常。一旦设置了内容的类型,就可以从
response对象中获得PrintWriter并开始写入。
4. 每个portlet应用在/WEB-INF文件夹中都有一个portlet.xml文件,它是portlet应用的部署描述符。按以下内容创建portlet.xml文件:
<portlet>
<description>HelloWorldDescription
</description>
<portlet-name>HelloWorld
</portlet-name>
<display-name>Hello World
</display-name>
<portlet-class>com.test.HelloWorld
</portlet-class>
<expiration-cache>-1
</expiration-cache>
<supports>
<mime-type>text/html</mime-type>
<portlet-mode>VIEW
</portlet-mode>
</supports>
<supported-locale>en
</supported-locale>
<portlet-info>
<title>Hello World</title>
<short-title>Hello World
</short-title>
<keywords>Hello,pluto</keywords>
</portlet-info>
</portlet>
<portlet-name>元素声明了portlet的名字,<portlet-class>元素指定了portlet的全
限定类名,<expiration-cache>元素以秒为单位指定了内容超期的时间。这里面有一点需要注意:你在portlet上的某些动
作可能会导致内容刷新,这与缓存时间无关。
<supports>元素指定对于给定的<mime-type>有哪些模
式可供支持。在示例中我们假定HelloWorld只能生成text/html类型的内容,且只有view模式可支持该内容类型。如果要增加对其它内容类
型的支持,需要添加新的<support>元素并指定支持该MIME类型的模式有哪些。通常portlet对于text/html类型有
VIEW、EDIT和HELP模式可供支持,而对于WML MIME类型则只有VIEW模式。
还可以用<supported-
locale>元素来指定portlet支持哪些本地化。<title>元素用来指定portlet的标题。如果要对标题做国际化处
理,可以用元素<resource-bundle>指定资源(比例properties文件)的文件名。在这种情况下,容器将根据用户所在的
地区从适当的properties文件中选择标题。
5. 每个portlet应用都是一个web应用,因此除了portlet.xml文件之外还需要有web.xml文件。
<web-app>
<display-name>Hello World Portlet
</display-name>
<welcome-file-list
<welcome-file>index.jsp
</welcome-file>
</welcome-file-list>
</web-app>
6. 接下来将这些文件进行编译并打包为war文件。你可以自己完成这些工作,或者下载带有build.xml 的示例代码(参见“资源”部分)来创建war文件。
在Pluto上部署HelloWorld Portlet
Pluto尚处于开发阶段的早期,因此还没有一套易于使用的管理工具。为了能使用Pluto服务器,需要将编译和源代码两个版本都下载。需要注意的是以
下说明是针对Windows平台的,Unix用户通过修改斜杠符号和执行sh shell脚本(不是bat批命令文件)会得到类似的结果。
1. 创建一个文件夹,比如C:"PlutoInstallation。
2. 从Pluto的网站下载pluto-1.0.1-rc1.zip和pluto-src-1.0.1-rc1.zip。
3. 将pluto-1.0.1-rc1.zip解压到C:"PlutoInstallation.文件夹,它应被解压到C:"PlutoInstallation"pluto-1.0.1-rc1文件夹下。
4. 执行C:"PlutoInstallation"pluto-1.0.1-rc1"bin"startup.bat启动Pluto,现在可以通过地址http://localhost:8080/pluto/portal访问Pluto服务器。
5. 将pluto-src-1.0.1-rc1.zip解压到C:"PlutoInstallation"PlutoSrc文件夹。
6.
进入C:"PlutoInstallation"PlutoSrc文件夹,执行maven
distribute:all.,编译并下载运行常规管理任务所必需的相关资源文件。现在可以将HelloWorldPortlet.war作为
portlet进行安装了。
7. 首先将HelloWorldPortlet.war文件拷贝到C:"PlutoInstallation"portlets目录,如果没这个目录就创建它。
8. 将C:"PlutoInstallation"plutosrc"build.properties.sample更名为build.properties。
9. 编辑build.properties,将maven.tomcat.home指向Pluto编译版的安装位置,在本例中应改为maven.tomcat.home=C:/PlutoInstallation/pluto-1.0.1-rc1。
10.
为了安装portlet,进入C:"plutoInstallation"plutosrc"deploy文件夹,执行maven deploy
-Ddeploy=c:"PlutoInstallation"portlets"HelloWorldPortlet.war,应能看到“build
successful”信息。
11. 在C:"PlutoInstallation"pluto-1.0.1-rc1"webapps文件夹下,应该有一个HelloWorldPortlet文件夹。
12. 现在进入C:"PlutoInstallation"pluto-1.0.1-rc1"webapps"HelloWorld"WEB-INF" folder文件夹,打开portlet的web.xml文件,你会发现里面自动多了几行,如下所示:
<servlet>
<servlet-name>HelloWorld</servlet-name>
<display-name>HelloWorld Wrapper</display-name>
<description>Automated generated
Portlet Wrapper</description>
<servlet-class>org.apache.pluto.core.PortletServlet
</servlet-class>
<init-param>
<param-name>portlet-class</param-name>
<param-value>com.test.HelloWorld
</param-value>
</init-param>
<init-param>
<param-name>portlet-guid</param-name>
<param-value>HelloPluto.HelloWorld
</param-value>
</init-param>
</servlet>
13.
接下来我们将该portlet加到页面里。进入C:"PlutoInstallation"pluto-1.0.1-rc1"webapps"pluto
"WEB-INF"data文件夹,可以看到有两个XML文件:pageregistry.xml和
portletentityregistry.xml。
14. portletentityregistry.xml包含了portlet的定义,在该文件中加入以下几行:
<application id="5">
<definition-id>HelloWorld</definition-id>
<portlet id="1">
<definition-id>HelloWorld.HelloWorld</definition-id>
</portlet>
</application>
应用的<definition-id>应为web应用所在文件夹的名字,portlet的<definition-id>应与web.xml中生成的portlet-guid相一致。
15. pageregistry.xml定义了页面中包含了哪些portlets,对该文件做如下改动:
<fragment name="p2" type="portlet">
<property name="portlet" value="5.1"/>
</fragment>
16. 执行shutdown命令和startup命令重启Pluto服务器,返回到地址http://localhost:8080/pluto/portal并点击“Test Link”-此时页面中将出现我们的
HelloWorld portlet。
图3的右侧显示了HelloWorld portlet看上去的样子。

图3 portlet的屏幕截图
如何创建Portal页面
图4显示了portal容器如何将分离的portlets组装为页面。

图4 创建Portal页面
大部分的portal服务器基本上都是部署于应用服务器上的web应用,通过servlet来处理访问portal服务器的请求。查看一下Pluto的
安装目录就会发现Pluto不过是一个部署于Tomcat服务器上的一个普通web应用,再看看C:"PlutoInstallation"pluto-
1.0.1-rc1"webapps"pluto"WEB-INF"web.xml会发现所有发往Pluto服务器的请求都被映射到
org.apache.pluto.portalImpl.Servlet上。
在本文开始部分“Portal页面的元素”中,我们提到portal页面由两部分组成。一部分是由页面中的portlets生成的内容,另一部分是由portal服务器生成的内容。
在Pluto里,只要用户发出请求,就会由servlet进行控制,根据用户所请求的页面来确定需要显示的portlets的列表。一旦生成了列表,servlet就将控制转给这些portlets线程并收集由它们生成的内容。
对于由portal服务器生成的内容(像portal网站的观感及每个portlet的外观和控制之类)则取决于C:"
PlutoInstallation"pluto-1.0.1-rc1"webapps"pluto"WEB-INF"aggregation文件夹下的
JSP文件。RootFragment.jsp是主JSP文件,它决定了整体的观感和对齐方式;它还包含了Heads以定义在生成的页面中的<
HEAD>标签里的内容。TabNavigation.jsp用来选择在banner中该显示什么(默认情况下在banner显示列表中也包扩了
pluto.png图片)。TabNavigation.jsp用来确定portal网站的导航方案。这意味着只需改动该文件夹下少量的几个JSP文件,
就能改变整个portal网站的观感。
Pluto根据pageregistry.xml中的设置确定页面中有多少行,并用
RowFragment.jsp去填充。ColumnFragment.jsp用来填充每个栏目。PortletFragmentHeader.jsp用
来填充每个portlet的页头,像标题条及最大化和最小化控制。footer.jsp用来填充JSP的页脚。如果去看一下portal页面的HTML代
码就会发现每个portlet窗口无非都是嵌入<TD>标签的内容块。
结束语
任何一种新技术要想获得成功都应具备以下条件:首先,它能提升现有技术;其次,它能解决现有技术遇到的普遍问题;再次,它能提供多于一个的抽象层(有人说,每抽象出一层,问题就解决一半)。
由于portlet与现有的应用服务器架构兼容,这对Portlet
API来说是一次发展servlet技术的好机会。你可以从portlet里调用EJB,或者用它启动和参与由应用服务器控制的全局性事务。换句话说,在
以商业逻辑为核心的领域里,portlet完全可以做得和servlet一样好。
Portlets提供了一个抽象层,现在你不必再担
心客户端使用了什么样的HTTP方法,也不必自己编写程序去捕获像点击按钮这样的客户端事件。最后但绝不是最次要的一点是,portlets以提供像单次
登录、个性化等服务的方式解决了servlets不能解决的大部分问题。
Portlet 是基于 java 的 web 组件,由 portlet 容器管理,并由容器处理请求,生产动态内容。 Portals 使用
portlets 作为可插拔用户接口组件,提供信息系统的表示层。作为利用 servlets 进行 web 应用编程的下一步, portlets
实现了 web 应用的模块化和用户中心化。 portlet 规范,即 jsr ( java specification request )
168 ,是为了实现 portal 和 portlet 的互操作。它定义了 portlet 和 portlet 容器之间的和约,让
portlet 实现个性化、表示和安全的 api 集。规范还定义了怎样在 portlets 应用中打包 portlets 。本系列的
第一部分描述了 portlet 规范,并解释了其中的根本概念。第二部分中,笔者解释了规范的参考实现和一些 portlet 实例。
随着企业级 portal 的大量涌现,不同提供商创建了不同的 portal 组件 api ,即 portlet 。不同的不兼容给应用服务商,
portal 用户和 portal server 提供商都造成了问题。为了消除这些问题, jsr168 ,即 portlet
规范提出,从而提供 portlet 和 portal 间的互操作性。 jsr168 定义, portlet 是基于 java 的 web
组件, portlet 容器处理 request 并生成动态内容,管理 portlet 。 portal 使用 portletportlet
作为可插入用户接口组件,提供信息系统的表示曾。
jsr168 的目标是:
定义 portlet 的运行时环境,即 portlet 容器
定义 portlet 和 portlet 容器之间的 api 集
提供 portlet 存储易失数据和持久数据的机制
提供 portlet 包含 servlet 和 jsp 的机制
定义方便部署的 portlet 打包方法
提供 jsr168 规范下的 portal 的二进制 portlet 便携性
通过 WSRP ( web service for remote portlet )协议运行符合 jsr168 规范的远程 portlet
IT 界已经广泛的接受了 jsr168 规范。所有的 portal 领域主要公司都是 jsr168 专家组的成员:
Apache,AGT,BEA,Boeing,Borland,Broadvision,Citrix,EDS, Fujitsu, Hitachi,
IBM, Novell, Oracle, SAP, SAS Institute, Sun Microsystems, Sybase,
TIBCO, and Vignette 。官方支持列表甚至更长。
当前, jsr168 正在进行公众审视,最终版本将在 2003 年九月发布。
本文中,首先定义了 portal 和 portlet ,然后解释了 jsr168 的概念,包括 api 的基本对象。接下来,深入到 jsr
的高级功能,比如用户信息,本地化和缓存。然后讲到了扩展,从而使 portal 提供者扩展当前 portlet 规范的函数功能。本文包含了
portlet 应用的打包和部署。
基本定义
这部分中,讲讲述 portlet 规范中的基础定义,包括 portal 基本构架, portlet 容器和 portal 页面。
portal
portal 是一个基于 web 的应用,它能提供个性化,单点登陆,不同源的内容聚合,和信息系统的表示曾集中。聚合是整合不同 web
页面源数据的过程。为了提供用户定制的内容, portal 可能包含复杂的个性化特征。为不同用户创建内容的 portal 页,可能包含不同的
portlet 集。
图 1 表示了 portal 的基本架构。 portal web 应用处理客户请求,找回用户当前页中的 portlet ,然后调用
portlet 容器,从新获取各个 portlet 的内容。 portlet 容器提供 portlet 的运行时环境,并通过 portlet
api 调用 portlet 。 portal 通过 portlet invoker api 调用 portlet 容器。 portlet
容器通过 portlet provider spi ( service provide interface )获取 portal 信息。
图 2 表示了基本的 portal 页面组件。 portal 页面本身代表一个完整的标记文档,并且聚集了一些 portlet 窗口。除
portlet 外,页面可能还包含导航区合标志区( navigation area and banners )。一个 portlet
窗口包含一个标题栏,装饰,和 portlet 产生的内容。装饰可以包括改变 portlet 窗口状态和模式的按钮(后文将解释这些概念)。
portlet
正如上文所说, portlet 是基于 java 的 web 组件,处理 request 并产生动态内容。 portlet
产生的内容称为片段,即一段遵守中心规则的标记(比如 html, xhtml,wml( 无线标记语言 )
)。如图三所示,多个片段可以聚合成一个完整的文档。多个 portlet 聚合在以期,组成 portal 页。 portlet 容器控制
portlet 的生命周期。
web 客户通过 portal 实现的 request/response 范例与 portlet 交互。通常, portlet 中的动作会被
portal 接受,从而用户与 portlet 中的内容交互(比如点击 portlet 中的链接,提交 form ),提交到 portlet
的目标。
对不同的用户,根据其配置,同一个 portlet 会产生不同的内容。
portlet 容器
portlet 容器提供它们需求的运行时环境并运行 portlet 。它包含 portles 并控制它们的生命周期。容器提供 portlet
参数的持久存储机制,它接受来之 portal 的 request ,并在其持有的 portlet 上执行 request 。容器不负责
portlet 产生内容的聚合, portal 自己处理内容聚合。
portal 和 portlet 容器可以作为应用套件构建在一起,也可以做为组件各自单独发布。
2007年7月6日
InnoDB概述
InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读。这些特色增加了多用户部署和性能。没有在InnoDB中扩大锁定的需要,因为在InnoDB中行级锁定适合非常小的空间。InnoDB也支持FOREIGN KEY强制。在SQL查询中,你可以自由地将InnoDB类型的表与其它MySQL的表的类型混合起来,甚至在同一个查询中也可以混合。
InnoDB是为处理巨大数据量时的最大性能设计。它的CPU效率可能是任何其它基于磁盘的关系数据库引擎所不能匹敌的。
InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB 表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
InnoDB默认地被包含在MySQL二进制分发中。Windows Essentials installer使InnoDB成为Windows上MySQL的默认表。
InnoDB被用来在众多需要高性能的大型数据库站点上产生。著名的Internet新闻站点Slashdot.org运行在InnoDB上。Mytrix, Inc.在InnoDB上存储超过1TB的数据,还有一些其它站点在InnoDB上处理平均每秒800次插入/更新的负荷。
InnoDB配置
InnoDB存储引擎是默认地被允许的。如果你不想用InnoDB表,你可以添加skip-innodb选项到MySQL选项文件。
被InnoDB存储引擎管理的两个重要的基于磁盘的资源是InnoDB表空间数据文件和它的日志文件。
如果你指定无InnoDB配置选项,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件。
注释:InnoDB给MySQL提供具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎。如果拟运行的操作系统和硬件不能如广告说的那样运行,InnoDB就不能实现如上能力。许多操作系统或磁盘子系统可能为改善性能而延迟或记录写操作。在一些操作系统上,就是系统调用(fsync()) 也要等着,直到所有未写入已被刷新文件的数据在被刷新到稳定内存之前可以确实返回了。因为这个,操作系统崩溃或掉电可能损坏当前提交的数据,或者在最坏的 情况,因为写操作已被记录了,甚至破坏了数据库。如果数据完整性对你很重要,你应该在用任何程序于生产中之前做一些“pull-the-plug”测试。Mac OS X 10.3 及以后版本,InnoDB使用一个特别的fcntl()文件刷新方法。在Linux下,建议禁止回写缓存。
在ATAPI硬盘上,一个类似hdparm -W0 /dev/hda命令可能起作用。小心某些驱动器或者磁盘控制器可能不能禁止回写缓存。
注释:要获得好的性能,你应该如下面例子所讨论那样,明确提供InnoDB参数。自然地,你应该编辑设置来适合你的硬件和要求。
要建立InnoDB表空间文件,在my.cnf选项文件里的[mysqld]节里使用innodb_data_file_path选项。在Windows上,你可以替代地使用my.ini文件。innodb_data_file_path的值应该为一个或多个数据文件规格的列表。如果你命名一个以上的数据文件,用 分号(‘;’)分隔它们:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
例如:把明确创建的具有相同特征的表空间作为默认设置的设置操作如下:
[mysqld]
innodb_data_file_path=ibdata1:10M:autoextend
这个设置配置一个可扩展大小的尺寸为10MB的单独文件,名为ibdata1。没有给出文件的位置,所以默认的是在MySQL的数据目录内。
尺寸大小用M或者G后缀来指定说明单位是MB或者GB。
一个表空间,它在数据目录里包含一个名为ibdata1的固定尺寸50MB的数据文件和一个名为ibdata2大小为50MB的自动扩展文件,其可以像这样被配置:
[mysqld]
innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
一个指定数据文件的完全后缀包括文件名,它的尺寸和数个可选属性:
file_name:file_size[:autoextend[:max:max_file_size]]
autoextend属性和后面跟着的属性只可被用来对innodb_data_file_path行里最后一个数据文件。
如果你对最后的数据文件指定autoextend选项。如果数据文件耗尽了表空间中的自由空间,InnoDB就扩展数据文件。扩展的幅度是每次8MB。
InnoDB并不感知最大文件尺寸,所以要小心文件系统,在那上面最大的文件尺寸是2GB。要为一个自动扩展数据文件指定最大尺寸,请使用max属性。下列配置允许ibdata1涨到极限的500MB:
[mysqld]
innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB默认地在MySQL数据目录创建表空间文件。要明确指定一个位置,请使用innodb_data_home_dir选项。比如,要使用两个名为ibdata1和ibdata2的文件,但是要把他们创建到/ibdata,像如下一样配置InnoDB:
[mysqld]
innodb_data_home_dir = /ibdata
innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
注释:InnoDB不创建目录,所以在启动服务器之前请确认/ibdata目录的确存在。这对你配置的任何日志文件目录来说也是真实的。使用Unix或DOS的mkdir命令来创建任何必需的目录。
通过把innodb_data_home_dir的值原原本本地部署到数据文件名,并在需要的地方添加斜杠或反斜杠,InnoDB为每个数据文件形成目录路径。如果innodb_data_home_dir选项根本没有在my.cnf中提到,默认值是“dot”目录 ./,这意思是MySQL数据目录。
处理InnoDB初始化问题
如果InnoDB在一个文件操作中打印一个操作系统错误,通常问题是如下中的一个:
· 你没有创建一个InnoDB数据文件目录或InnoDB日志目录。
· mysqld没有访问这些目录的权限以创建文件。
· mysqld不能恰当地读取my.cnf或my.ini选项文件,因此不能看到你指定的选项。
· 磁盘已满,或者超出磁盘配额。
· 你已经创建一个子目录,它的名字与你指定的数据文件相同。
· 在innodb_data_home_dir或innodb_data_file_path有一个语法错误。
当InnoDB试着初始化它的表空间或日志文件之时,如果出错了,你应该删除InnoDB创建的所有文件。这意味着是所有ibdata文件和所有ib_logfiles文件。万一你创建了一些InnoDB表,为这些表也从MySQL数据库目录删除相应的.frm文件(如果你使用多重表空间的话,也删除任何.ibd文件)。然后你可以试着再次创建InnoDB数据库。最好是从命令提示符启动MySQL服务器,以便你可以查看发生了什么。
AUTO_INCREMENT列在InnoDB里如何工作
如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。自动增长计数器仅被存储在主内存中,而不是存在磁盘上。
InnoDB使用下列算法来为包含一个名为ai_col的AUTO_INCREMENT列的表T初始化自动增长计数器:服务器启动之后,当一个用户对表T做插入之时,InnoDB执行等价如下语句的动作:
SELECT MAX(ai_col) FROM T FOR UPDATE;
语句取回的值逐次加一,并被赋给列和自动增长计数器。如果表是空的,值1被赋予该列。如果自动增长计数器没有被初始化,而且用户调用为表T显示输出的SHOW TABLE STATUS语句,则计数器被初始化(但不是增加计数)并被存储以供随后的插入使用。注意,在这个初始化中,我们对表做一个正常的独占读锁定,这个锁持续到事务的结束。
InnoDB对为新创建表的初始化自动增长计数器允许同样的过程。
注意,如果用户在INSERT中为AUTO_INCREMENT列指定NULL或者0,InnoDB处理行,就仿佛值还没有被指定,且为它生成一个新值。
自动增长计数器被初始化之后,如果用户插入一个明确指定该列值的行,而且该值大于当前计数器值,则计数器被设置为指定列值。如果没有明确指定一个值,InnoDB给计数器增加一,并且赋新值给该列。
当访问自动增长计数器之时,InnoDB使用专用的表级的AUTO-INC锁定,该锁持续到当前SQL语句的结束而不是到业务的结束。引入了专用锁释放策略,来为对一个含AUTO_INCREMENT列的表的插入改善部署。两个事务不能同时对同一表有AUTO-INC锁定。
注意,如果你回滚从计数器获得数的事务,你可能会在赋给AUTO_INCREMENT列的值的序列中发现间隙。
如果用户给列赋一个赋值,或者,如果值大过可被以指定整数格式存储的最大整数,自动增长机制的行为不被定义。
在CREATE TABLE和ALTER TABLE语句中,InnoDB支持AUTO_INCREMENT = n 表选项来设置计数器初始值或变更当前计数器值。因在本节早先讨论的原因,这个选项的影响在服务器重启后就无效了。
外键约束
InnoDB也支持外键约束。InnoDB中对外键约束定义的语法看起来如下:
[CONSTRAINT symbol] FOREIGN KEY [id] (index_col_name, ...)
REFERENCES tbl_name (index_col_name, ...)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
外键定义服从下列情况:
· 所有tables必须是InnoDB型,它们不能是临时表。
· 在引用表中,必须有一个索引,外键列以同样的顺序被列在其中作为第一列。这样一个索引如果不存在,它必须在引用表里被自动创建。
· 在引用表中,必须有一个索引,被引用的列以同样的顺序被列在其中作为第一列。
· 不支持对外键列的索引前缀。这样的后果之一是BLOB和TEXT列不被包括在一个外键中,这是因为对这些列的索引必须总是包含一个前缀长度。
· 如果CONSTRAINTsymbol被给出,它在数据库里必须是唯一的。如果它没有被给出,InnoDB自动创建这个名字。
InnoDB拒绝任何试着在子表创建一个外键值而不匹配在父表中的候选键值的INSERT或UPDATE操作。一个父表有一些匹配的行的子表,InnoDB对任何试图更新或删除该父表中候选键值的UPDATE或DELETE操作有所动作,这个动作取决于用FOREIGN KEY子句的ON UPDATE和ON DETETE子句指定的referential action。当用户试图从一个父表删除或更新一行之时,且在子表中有一个或多个匹配的行,InnoDB根据要采取的动作有五个选择:
· CASCADE: 从父表删除或更新且自动删除或更新子表中匹配的行。ON DELETE CASCADE和ON UPDATE CASCADE都可用。在两个表之间,你不应定义若干在父表或子表中的同一列采取动作的ON UPDATE CASCADE子句。
· SET NULL: 从父表删除或更新行,并设置子表中的外键列为NULL。如果外键列没有指定NOT NULL限定词,这就是唯一合法的。ON DELETE SET NULL和ON UPDATE SET NULL子句被支持。
· NO ACTION: 在ANSI SQL-92标准中,NO ACTION意味这不采取动作,就是如果有一个相关的外键值在被参考的表里,删除或更新主要键值的企图不被允许进行(Gruber, 掌握SQL, 2000:181)。 InnoDB拒绝对父表的删除或更新操作。
· RESTRICT: 拒绝对父表的删除或更新操作。NO ACTION和RESTRICT都一样,删除ON DELETE或ON UPDATE子句。(一些数据库系统有延期检查,并且NO ACTION是一个延期检查。在MySQL中,外键约束是被立即检查的,所以NO ACTION和RESTRICT是同样的)。
· SET DEFAULT: 这个动作被解析程序识别,但InnoDB拒绝包含ON DELETE SET DEFAULT或ON UPDATE SET DEFAULT子句的表定义。
当父表中的候选键被更新的时候,InnoDB支持同样选择。选择CASCADE,在子表中的外键列被设置为父表中候选键的新值。以同样的方式,如果在子表更新的列参考在另一个表中的外键,更新级联。
注意,InnoDB支持外键在一个表内引用,在这些情况下,子表实际上意味这在表内附属的记录。
InnoDB需要对外键和被引用键的索引以便外键检查可以快速进行且不需要一个表扫描。对外键的索引被自动创建。这是相对于一些老版本,在老版本中索引必须明确创建,否则外键约束的创建会失败。
在InnoDB内,外键里和被引用列里相应的列必须有类似的内部数据类型,以便它们不需类型转换就可被比较。整数类型的大小和符号必须相同。字符串类型的长度不需要相同。如果你指定一个SET NULL动作,请确认你没有在子表中宣告该列为为NOT NULL。
如果MySQL从CREATE TABLE语句报告一个错误号1005,并且错误信息字符串指向errno 150,这意思是因为一个外键约束被不正确形成,表创建失败。类似地,如果ALTER TABLE失败,且它指向errno 150, 那意味着对已变更的表,外键定义会被不正确的形成。你可以使用SHOW INNODB STATUS来显示一个对服务器上最近的InnoDB外键错误的详细解释。
注释:InnoDB不对那些外键或包含NULL列的被引用键值检查外键约束。
对SQL标准的背离:如果在父表内有数个行,其中有相同的被引用键值,然后InnoDB在外键检查中采取动作,就仿佛其它有相同键值的父行不存在一样。例如,如果你已定义一个RESTRICT类型的约束,并且有一个带数个父行的子行,InnoDB不允许任何对这些父行的删除。
居于对应外键约束的索引内的记录,InnoDB通过深度优先选法施行级联操作。
对SQL标准的背离: 如果ON UPDATE CASCADE或ON UPDATE SET NULL递归更新相同的表,之前在级联过程中该表一被更新过,它就象RESTRICT一样动作。这意味着你不能使用自引用ON UPDATE CASCADE或者ON UPDATE SET NULL操作。这将阻止级联更新导致的无限循环。另一方面,一个自引用的ON DELETE SET NULL是有可能的,就像一个自引用ON DELETE CASCADE一样。级联操作不可以被嵌套超过15层深。
对SQL标准的背离: 类似一般的MySQL,在一个插入,删除或更新许多行的SQL语句内,InnoDB逐行检查UNIQUE和FOREIGN KEY约束。按照SQL的标准,默认的行为应被延迟检查,即约束仅在整个SQL语句被处理之后才被检查。直到InnoDB实现延迟的约束检查之前,一些事情是不可能的,比如删除一个通过外键参考到自身的记录。
注释:当前,触发器不被级联外键的动作激活。
一个通过单列外键联系起父表和子表的简单例子如下:
CREATE TABLE parent(id INT NOT NULL,
PRIMARY KEY (id)
) TYPE=INNODB;
CREATE TABLE child(id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) TYPE=INNODB;
如下是一个更复杂的例子,其中一个product_order表对其它两个表有外键。一个外键引用一个product表中的双列索引。另一个引用在customer表中的单行索引:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) TYPE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) TYPE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) TYPE=INNODB;
InnoDB允许你用ALTER TABLE往一个表中添加一个新的外键约束:
ALTER TABLE yourtablename
ADD [CONSTRAINT symbol] FOREIGN KEY [id] (index_col_name, ...)
REFERENCES tbl_name (index_col_name, ...)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION}]
记住先创建需要的索引。你也可以用ALTER TABLE往一个表添加一个自引用外键约束。
InnoDB也支持使用ALTER TABLE来移除外键:
ALTER TABLE yourtablename DROP FOREIGN KEY fk_symbol;
当年创建一个外键之时,如果FOREIGN KEY子句包括一个CONSTRAINT名字,你可以引用那个名字来移除外键。另外,当外键被创建之时,fk_symbol值被InnoDB内部保证。当你想要移除一个外键之时,要找出标记,请使用SHOW CREATE TABLE语句。例子如下:
mysql> SHOW CREATE TABLE ibtest11c\G
*************************** 1. row ***************************
Table: ibtest11c
Create Table: CREATE TABLE `ibtest11c` (
`A` int(11) NOT NULL auto_increment,
`D` int(11) NOT NULL default '0',
`B` varchar(200) NOT NULL default '',
`C` varchar(175) default NULL,
PRIMARY KEY (`A`,`D`,`B`),
KEY `B` (`B`,`C`),
KEY `C` (`C`),
CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`)
REFERENCES `ibtest11a` (`A`, `D`)
ON DELETE CASCADE ON UPDATE CASCADE,
CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`)
REFERENCES `ibtest11a` (`B`, `C`)
ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=INNODB CHARSET=latin1
1 row in set (0.01 sec)
mysql> ALTER TABLE ibtest11c DROP FOREIGN KEY 0_38775;
InnoDB解析程序允许你在FOREIGN KEY ... REFERENCES ...子句中用`(backticks)把表和列名名字围起来。InnoDB解析程序也考虑到lower_case_table_names系统变量的设置。
InnoDB返回一个表的外键定义作为SHOW CREATE TABLE语句输出的一部分:
SHOW CREATE TABLE tbl_name;
从这个版本起,mysqldump也将表的正确定义生成到转储文件中,且并不忘记外键。
你可以如下对一个表显示外键约束:
SHOW TABLE STATUS FROM db_name LIKE 'tbl_name';
外键约束被列在输出的Comment列。
当执行外键检查之时,InnoDB对它照看着的子或父记录设置共享的行级锁。InnoDB立即检查外键约束,检查不对事务提交延迟。
要使得对有外键关系的表重新载入转储文件变得更容易,mysqldump自动在转储输出中包括一个语句设置FOREIGN_KEY_CHECKS为0。这避免在转储被重新装载之时,与不得不被以特别顺序重新装载的表相关的问题。也可以手动设置这个变量:
mysql> SET FOREIGN_KEY_CHECKS = 0;
mysql> SOURCE dump_file_name;
mysql> SET FOREIGN_KEY_CHECKS = 1;
如果转储文件包含对外键是不正确顺序的表,这就以任何顺序导入该表。这样也加快导入操作。设置FOREIGN_KEY_CHECKS为0,对于在LOAD DATA和ALTER TABLE操作中忽略外键限制也是非常有用的。
InnoDB不允许你删除一个被FOREIGN KEY表约束引用的表,除非你做设置SET FOREIGN_KEY_CHECKS=0。当你移除一个表的时候,在它的创建语句里定义的约束也被移除。
如果你重新创建一个被移除的表,它必须有一个遵从于也引用它的外键约束的定义。它必须有正确的列名和类型,并且如前所述,它必须对被引用的键有索引。如果这些不被满足,MySQL返回错误号1005 并在错误信息字符串中指向errno 150。
MyISAM是默认存储引擎。它基于更老的ISAM代码,但有很多有用的扩展。(注意MySQL 5.1不支持ISAM)。
每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
要明确表示你想要用一个MyISAM表格,请用ENGINE表选项指出来:
CREATE TABLE t (i INT) ENGINE = MYISAM;
注释:老版本的MySQL使用TYPE而不是ENGINE(例如,TYPE = MYISAM)。MySQL 5.1为向下兼容而支持这个语法,但TYPE现在被轻视,而ENGINE是首先的用法。
一般地,ENGINE选项是不必要的;除非默认已经被改变了,MyISAM是默认存储引擎。
如下是MyISAM存储引擎的一些特征:
· 所有数据值先存储低字节。这使得数据机和操作系统分离。二进制轻便性的唯一要求是机器使用补码(如最近20年的机器有的一样)和IEEE浮点格式(在主流机器中也完全是主导的)。唯一不支持二进制兼容性的机器是嵌入式系统。这些系统有时使用特殊的处理器。
先存储数据低字节并不严重地影响速度;数据行中的字节一般是未联合的,从一个方向读未联合的字节并不比从反向读更占用更多的资源。服务器上的获取列值的代码与其它代码相比并不显得时间紧。
· 大文件(达63位文件长度)在支持大文件的文件系统和操作系统上被支持。
· 当把删除和更新及插入混合的时候,动态尺寸的行更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块来自动完成。
· 每个MyISAM表最大索引数是64。 这可以通过重新编译来改变。每个索引最大的列数是16个。
· 最大的键长度是1000字节。这也可以通过编译来改变。对于键长度超过250字节的情况,一个超过1024字节的的键块被用上。
· BLOB和TEXT列可以被索引。
· NULL值被允许在索引的列中。这个占每个键的0-1个字节。
· 所有数字键值以高字节为先被存储以允许一个更高地索引压缩。
· 当记录以排好序的顺序插入(就像你使用一个AUTO_INCREMENT列之时),索引树被劈开以便高节点仅包含一个键。这改善了索引树的空间利用率。
· 每表一个AUTO_INCREMEN列的内部处理。MyISAM为INSERT和UPDATE操作自动更新这一列。这使得AUTO_INCREMENT列更快(至少10%)。在序列顶的值被删除之后就不能再利用。(当AUTO_INCREMENT列被定义为多列索引的最后一列,可以出现重使用从序列顶部删除的值的情况)。AUTO_INCREMENT值可用ALTER TABLE或myisamch来重置。
· 如果数据文件中间的表没有自由块了,在其它线程从表读的同时,你可以INSERT新行到表中。(这被认识为并发操作)。自由块的出现是作为删除行的结果,或者是用比当前内容多的数据对动态长度行更新的结果。当所有自由块被用完(填满),未来的插入又变成并发。
· 你可以把数据文件和索引文件放在不同目录,用DATA DIRECTORY和INDEX DIRECTORY选项CREATE TABLE以获得更高的速度。
· 每个字符列可以又不同的字符集。
· 在MyISAM索引文件里又一个标志,它表明表是否被正确关闭。如果用--myisam-recover选项启动mysqld,MyISAM表在打开得时候被自动检查,如果被表被不恰当地关闭,就修复表。
· 如果你用--update-state选项运行myisamchk,它标注表为已检查。myisamchk --fast只检查那些没有这个标志的表。
· myisamchk --analyze为部分键存储统计信息,也为整个键存储统计信息。
· myisampack可以打包BLOB和VARCHAR列。
MyISAM也支持下列特征:
· 支持true VARCHAR类型;VARCHAR列以存储在2个字节中的长度来开始。
· 有VARCHAR的表可以有固定或动态记录长度。
· VARCHAR和CHAR列可以多达64KB。
· 一个被搞乱的已计算索引对可对UNIQUE来使用。这允许你在表内任何列的合并上有UNIQUE。(尽管如此,你不能在一个UNIQUE已计算索引上搜索)。
MyISAM表的存储格式
静态格式是MyISAM表的默认存储格式。当表不包含变量长度列(VARCHAR, BLOB, 或TEXT)时,使用这个格式。每一行用固定字节数存储。
MyISAM的三种存储格式中,静态格式就最简单也是最安全的(至少对于崩溃而言)。静态格式也是最快的on-disk格式。快速来自于数据文件中的行在磁盘上被找到的容易方式:当按照索引中的行号查找一个行时,用行长度乘以行号。同样,当扫描一个表的时候,很容易用每个磁盘读操作读一定数量的记录。
当MySQL服务器正往一个固定格式MyISAM文件写的时候,如果计算机崩溃了,安全是显然的。在这种情况下,myisamchk可以容易地决定每行从哪里开始到哪里结束,所以它通常可以收回所有记录,除了写了一部分的记录。注意,基于数据行,MyISAM表索引可以一直被重新构建。
静态格式表的一般特征:
· CHAR列对列宽度是空间填补的。
· 非常快。
· 容易缓存。
· 崩溃后容易重建,因为记录位于固定位置。
· 重新组织是不必要的,除非你删除巨量的记录并且希望为操作系统腾出磁盘空间。为此,可使用OPTIMIZE TABLE或者myisamchk -r。
· 通常比动态格式表需要更多的磁盘空间。
动态表特征
如果一个MyISAM表包含任何可变长度列(VARCHAR, BLOB或TEXTDynamic),或者如果一个表被用ROW_FORMAT=DYNAMIC选项来创建,动态存储格式被使用。
这个格式更为复杂一点,因为每行有一个表明行有多长的头。当一个记录因为更新的结果被变得更长,该记录也可以在超过一个位置处结束。
你可以使用OPTIMIZE TABLE或myisamchk来对一个表整理碎片。如果在一个表中有你频繁访问或改变的固定长度列,表中也有一些可变长度列,仅为避免碎片而把这些可变长度列移到其它表可能是一个好主意。
动态格式表的一般特征:
· 除了长度少于4的列外,所有的字符串列是动态的。
· 在每个记录前面是一个位图,该位图表明哪一列包含空字符串(对于字符串列)或者0(对于数字列)。注意,这并不包括包含NULL值的列。如果一个字符列在拖曳空间移除后长度为零,或者一个数字列为零值,这都在位图中标注了且列不被保存到磁盘。 非空字符串被存为一个长度字节加字符串的内容。
· 通常比固定长度表需要更少的磁盘空间。
· 每个记录仅使用必需大小的空间。尽管如此,如果一个记录变大,它就按需要被分开成多片,造成记录碎片的后果。比如,你用扩展行长度的信息更新一行,该行就变得有碎片。在这种情况下,你可以时不时运行OPTIMIZE TABLE或myisamchk -r来改善性能。可使用myisamchk -ei来获取表的统计数据。
· 动态格式表在崩溃后要比静态格式表更难重建,因为一个记录可能被分为多个碎片且链接(碎片)可能被丢失。
已压缩表特征
已压缩存储格式是由myisampack工具创建的只读格式。
所有MySQL分发版里都默认包括myisampack。已压缩表可以用myisamchk来解压缩。
已压缩表有下列特征:
· 已压缩表占据非常小的磁盘空间。这最小化了磁盘用量,当使用缓慢的磁盘(如CD-ROM)之时,这是很有用的。
· 每个记录是被单独压缩的,所以只有非常小的访问开支。依据表中最大的记录,一个记录的头在每个表中占据1到3个字节。每个列被不同地压缩。通常每个列有一个不同的Huffman树。一些压缩类型如下:
o 后缀空间压缩。
- 前缀空间压缩。
- 零值的数用一个位来存储。
- 如果在一个整型列中的值有一个小的范围,列被用最小可能的类型来存储。比如,一个BIGINT列(8字节),如果所有它的值在-128到127范围内,它可以被存储为TINYINT列(1字节)
- 如果一个列仅有一小组可能的值,列的类型被转化成ENUM。
- 一个列可以使用先前压缩类型的任意合并。
· 可以处理固定长度或动态长度记录。
InnoDB和MyISAM是在使用MySQL最常用的两个表类型,各有优缺点,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持已经外部键等高级数据库功能。
MyIASM是IASM表的新版本,有如下扩展:
二进制层次的可移植性。
NULL列索引。
对变长行比ISAM表有更少的碎片。
支持大文件。
更好的索引压缩。
更好的键吗统计分布。
更好和更快的auto_increment处理。
以下是一些细节和具体实现的差别:
1.InnoDB不支持FULLTEXT类型的索引。
2.InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的。
3.对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
4.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
5.LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”
任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。
1 InnoDB Tables 概述
InnoDB 给 MySQL 提供了具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。InnoDB 提供了行锁(locking on row level),提供与 oracle 类型一致的不加锁读取(non-locking read in Selects)。这些特性均提高了多用户并发操作的性能表现。在InnoDB表中不需要扩大锁定(lock escalation),因为 InnoDB 的列锁定(row level locks)适宜非常小的空间。InnoDB 是 MySQL 上第一个提供外键约束(FOREIGN KEY constraints)的表引擎。
InnoDB 的设计目标是处理大容量数据库系统,它的 CPU 利用率是其它基于磁盘的关系数据库引擎所不能比的。
在技术上,InnoDB 是一套放在 MySQL 后台的完整数据库系统,InnoDB 在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。 InnoDB 把数据和索引存放在表空间里,可能包含多个文件,这与其它的不一样,举例来说,在 MyISAM 中,表被存放在单独的文件中。InnoDB 表的大小只受限于操作系统的文件大小,一般为 2 GB。
在http://www.innodb.com/上可以找到 InnoDB 最新的信息。InnoDB 手册的最新版本总是被放置在那里,并且在那里可以得到 InnoDB 的商业许可(order commercial licenses)以及支持。
InnoDB 现在(2001年十月)在一些大的需高性能的数据库站点上被使用。著名的 Internet 新闻站点 Slashdot.org 就是使用的 InnoDB。 Mytrix, Inc. 在 InnoDB 表上存储了超过 1 TB 的数据,而且另外的一个站点在 InnoDB 表上处理着平均每秒 800 次的插入/更新的负载。
在 MySQL 的源代码中,从 3.23.34a 开始包含 InnoDB 表引擎,并在 MySQL -Max 的二进制版本中激活。
为了使用 InnoDB 表引擎,必须在‘my.cnf’或‘my.ini’文件中详细指定 InnoDB 的启动配置。最小的修改方法就是在 [mysqld] 区中加入下面一行:
innodb_data_file_path=ibdata:30M
但是为了得到最好的性能推荐详细指定配置选项,查看 2 InnoDB Startup Options。
InnoDB 以 GNU GPL 版本 2 的许可发布(1991年六月)。
1.1 MySQL/InnoDB 发布版本间的差别
MySQL-Max-3.23: 这是一个稳定版本,被推荐为产品使用。
MySQL-4.0: 这是一个开发版本,与 MySQL 3.23 相比它包含了一些新特性,比如多表删除(multi-table delete)、查询结果缓冲(cached query results)和 SSL 通信。4.0 版与 3.23 版中的 InnoDB 表引擎是一致的。4.0.1 的稳定性可被归类为 beta。
MySQL-