下面是来自 Taobao QA Team中的安全测试方面的文章,对初学者很有指导意义
安全测试学习笔记系列:
1. http://qa.taobao.com/?p=11352
2.http://qa.taobao.com/?p=11363
3.http://qa.taobao.com/?p=11472
4.http://qa.taobao.com/?p=11479
5.http://qa.taobao.com/?p=11484
------
WEB漏洞攻击之SQL注入:http://qa.taobao.com/?p=11403
摘要: onabort 当用户中断下载图像时触发。
onactivate 当对象设置为活动元素时触发。
onafterprint 对象所关联的文档打印或打印预览后立即在对象上触发。
onafterupdate 当成功更新数据源对象中的关联对象后在数据绑定对象上触发。
onbeforeactivate new 对象要被设置为当前元素前立即触发。
onbeforecopy 当选中区复制到系统剪贴板之前在源对象触发。
onbeforecut 当选中区从文档中删除之前在源对象触发。
onbeforedeactivate 在 activeElement 从当前对象变为父文档其它对象之前立即触发。
onbeforeeditfocus 在包含于可编辑元素内的对象进入用户界面激活状态前或可编辑容器变成控件选中区前触发。
onbeforepaste 在选中区从系统剪贴板粘贴到文档前在目标对象上触发。
阅读全文
数组类Array是Java中最基本的一个存储结构。它用于存储一组连续的对象或基本类型的数据。其中的元素的类型必须相同。
Array是最有效率的一 种:
1、效率高,但容量固定且无法动态改变。 Array还有一个缺点是,无法判断其中实际存有多少元素,length只是告诉我们Array的容量。
2、Java中有一个Arrays类,专门用来操作Array,提供搜索、排序、复制等静态方法。 equals():比较两个Array是否相等,Array拥有相同元素个数,且所有对应元素两两相等。 fill():将值填入Array中。 sort():用来对Array进行排序。 binarySearch():在排好序的Array中寻找元素。 System.arraycopy():Array的复制。
Java Collections Framework成员主要包括两种类型,即:Collection和Map类型。 在Java中提供了Collection和Map接口。其中List和Set继承了Collection接口;Vector、ArrayList、 LinkedList三个类实现List接口,HashSet、TreeSet实现Set接口,HashTable、HashMap、 TreeMap实现Map接口。由此可见,Java中用8种类型的基本数据结构来实现其Collections Framework;下面分别进行介绍。
Vector:基于Array的List,性能也就不可能超越Array,并且Vector是"sychronized"的,这个也是Vector和ArrayList的唯一的区别。
ArrayList:同Vector一样是一个基于Array的,但是不同的是ArrayList不是同步的。所以在性能上要比Vector优越一些,但 是当运行到多线程环境中时,可需要自己在管理线程的同步问题。从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快。
LinkedList:LinkedList不同于前面两种List,它不是基于Array的,所以不受Array性能的限制。它每一个节点(Node) 都包含两方面的内容:
1、节点本身的数据(data);
2、下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候 就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了所以它适合于进行频繁进行插入和删除操 作。这就是LinkedList的优势。Iterator只能对容器进行向前遍历,而 ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
List总结:
1、所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ];
2、所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ];
3、所有的List中可以有null元素,例如[ tom,null,1 ];
4、基于Array的List(Vector,ArrayList)适合查询,而LinkedList(链表)适合添加,删除操作。
HashSet:虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是 Set则是在HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的 对应存储项,这也是为什么在Set中不能像在List中一样有重复的项的根本原因,因为HashMap的key是不能有重复的。HashSet能快速定位 一个元素,但是放到HashSet中的对象需要实现hashCode()方法0。
TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和 Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要重复定义相同的排序算法,只要实现Comparator接口即可。TreeSet是SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
Set总结:
1、Set实现的基础是Map(HashMap);
2、Set中的元素是不能重复的,如果使用add(Object obj)方法添加已经存在的对象,则会覆盖前面的对象; Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别? Set里的元素是不能重复的,即不能包含两个元素e1、e2(e1.equals(e2))。那么用iterator()方法来区分重复与否。 equals()是判读两个Set是否相等。==方法决定引用值(句柄)是否指向同一对象。
HashMap、TreeMap、Hashtable:
1、HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它有一些扩展的方法,比如 firstKey(),lastKey()等。
2、Hashtable:不允许空(null)键(key)或值(value),Hashtable的方法是Synchronize的,在多个线程访问 Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
3、HashMap和Hashtable的区别:HashMap是Hashtable(线程案例的)的轻量级实现(非线程安全的实现),他们都完成了Map接口。主要区别在于HashMap允许空(null)键(key)或值(value),非同步,由于非线程安全,效率上可能高于Hashtable。
Map总结:
是一种把键对象和值对象进行关联的容器,Map有两种比较常用的实现: HashTable、HashMap和TreeMap。
摘要: 1005:创建表失败
1006:创建数据库失败
1007:数据库已存在,创建数据库失败
1008:数据库不存在,删除数据库失败
1009:不能删除数据库文件导致删除数据库失败
1010:不能删除数据目录导致删除数据库失败
1011:删除数据库文件失败
1012:不能读取系统表中的记录
1020:记录已被其他用户修改
1021:硬盘剩余空间不足,请加大硬盘可用空间...
阅读全文
摘要: 序言
在担任公司高管的几年间,我面试过数以百计的各个层面的员工,其中最让我感到遗憾的一个现象就是很多人有着非常好的素质,甚至有的还是名校的毕业生,因为不懂得去规划自己的职业,在工作多年后,依然拿着微薄的薪水,为了一份好一点的工作而奔波。很多这样的人,他们只要稍微修正一下自己的职业方向,就能够在职业发展上走得更从容。
有一次一个大连理工大学的研究生,好像是学电子的...
阅读全文
国外:
BJ Rolison (I.M.Testy) http://blogs.msdn.com/imtesty
BJ是微软负责EE工作的Test Architecture,也是HWTSaM的作者。他的文章非常有条理,看起来也比较容易,其中的数据也非常丰富,是我喜欢的风格。
Alan Page http://blogs.msdn.com/alanpa/
Alan是微软负责EE工作的Director,是HWTSaM的主要作者,他的博客是了解微软测试非常好的一个窗口。最近几年,他不限于测试技术的推广,他更多的考虑是测试管理,以及测试氛围/文化的形成,以及对于测试的影响。我很同意他的一句话“95%的UI自动化测试都是浪费时间”详情。他的博客文章比较随意,有时也不知道他在唠叨些什么,但不时却有很多精彩的观点。
Google Test Blog http://googletesting.blogspot.com
这是Google官方的测试博客,信息量很少,除了每年一次的Google Automation Test Conference之外,文章较少。今年6月,James Whittaker离开微软,加入Google后,才到这里增加不少好文章。
James Bach的博客 http://www.satisfice.com/blog/
James是一个软件测试的资深人士,90年代曾在Apple和Boland公司���过测试管理工作,后来在其他一些公司负责测试流程和质量管理,2000年自己创办了satisfice测试咨询公司,提供软件质量保证相关的咨询和培训. 他和Cem Kaner撰写了很多Explorary Testing相关的文章和书籍,并且提出了Context-Driven-Testing,这些方法论很适合现在的Agile Testing的特点。
Adam Goucher的博客 http://adam.goucher.ca/
一个多产高质的测试写作专家,基本上每个月都有10多篇关于测试的文章,有时候一天写了多篇,真是非常佩服他的写作能力。他的思想很有深度,对软件测试各个方面都有全面的理解,他阅读了几乎所有新出的测试书籍,并且些了与其相关的评论。这些评论通常非常尖锐。比如说,HWTSaM的评论,他的评论就比较中肯。对James Whittalkes的 Exploratory Testing评论 却是嗤之以鼻。
软件测试杂文集:http://blogs.msdn.com/b/cheno/
文章转自:http://www.cesoo.com/
一、写在前面
刚开学,趁着有时间把设计模式重新整理一次。学好设计模式是走向架构的第一步,系统架构应该朝着可维护,可扩展,强壮性好的方向去发展。大学的最后一个学期了,时间不多了,3月初就要去腾讯实习了,还有毕设。加油 :)
二、常见的模式分类
|
创建模式
|
结构模式
|
行为模式
|
|
简单工厂模式
|
适配器模式
|
不变模式
|
|
工厂方法模式
|
缺省适配模式
|
策略模式
|
|
抽象工厂模式
|
合成模式
|
模版方法模式
|
|
单例模式
|
装饰模式
|
观察者模式
|
|
多例模式
|
代理模式
|
迭代子模式
|
|
建造模式
|
享元模式
|
责任链模式
|
|
原始模型模式
|
门面模式
|
命令模式
|
|
桥梁模式
|
备忘录模式
|
|
|
状态模式
|
|
|
访问者模式
|
|
|
解释器模式
|
|
|
调停者模式
|
三、主要模式的定义和描述
以下内容来自《head first 设计模式》一书
|
模式
|
定义
|
描述
|
|
装饰者
|
动态地将责任附加到对象上。若要扩展功能,装饰者提供了比继承更有弹性的替代方案
|
包装一个对象,以提供新的行为
|
|
状态
|
允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类
|
封装了基本状态的行为,并使用委托在行为之间切换
|
|
迭代器
|
提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露其内部的表示
|
在对象的集合之中游走,而不暴露集合的实现
|
|
外观(门面)
|
提供一个统一的接口,用来访问子系统中的一群接口。外观定义了一个高层接口,让子系统更多容易使用
|
简化一群类的接口
|
|
策略
|
定义算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户
|
封装可以互换的行为,并使用委托来决定使用那一种
|
|
代理
|
为另一个对象提供一个替身或点位符以访问这个对象
|
包装对象,以控制对此对象的访问
|
|
工厂方法
|
定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法让类把实例化推迟到子类
|
由子类决定要创建是具体类是哪一个
|
|
抽象工厂
|
提供一个接口,用于创建相关或依赖对象的家族,而不需要明确指定具体类
|
允许客户创建对象的家族,而无需指定他们的具体类
|
|
适配器
|
将一个类的接口,转换成客户期望另一个接口。适配器让原来不兼容的类可以合作无间
|
封装对象,并提供不同的接口
|
|
观察者
|
在对象之间定义一对多的依赖,这样一来,当一个对象改变时,依赖它的对象都会收到通知并自动更新
|
让对象能够在状态改变时被通知
|
|
模板方法
|
在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下,重新定义算法中的某些步骤
|
由子类决定如何实现一个算法中的步骤
|
|
组合
|
允许你将对象组成树结构来表现“整体/部分”的层次结构。组合能让客户以一致的方式处理个别对象和对象组合
|
客户用一致的方式处理对象集合和单个对象
|
|
单件(单体)
|
确保一个类只有一个实例,并提供全局访问点
|
确保只有一个对象被创建
|
|
命令
|
将请求封装成对象,这可以让你使用不同的请求、队列,或者日志请求来参数化其它对象。命令模式也可以支持撤销操作
|
封装请求为对象
|
四、参考资料
IBM社区设计模式方面资料: http://www.ibm.com/developerworks/cn/java/design/
常见OO原则:http://www.blogjava.net/jicheng687/archive/2011/02/13/344174.html
--END--
一、在单元测试领域里,JUnit可以说是王者,它不但精致,而且使用方便。最后有些时间,把JUnit源码读读,顺便复习下设计模式 :)
二、参考文章
在深入看代码之前,先看下面的文章,对JUnit有一个基本的了解后,看代码会更有目的性。
JUnit官方网站:http://www.junit.org/
分析 JUnit 框架源代码: http://www.ibm.com/developerworks/cn/java/j-lo-junit-src/
JUnit A cook's tour: http://junit.sourceforge.net/doc/cookstour/cookstour.htm
三、核心架构
我分析的源码的版本是JUnit 3.8.2,这个版本相对简略,把核心思想表现出来了,没有4.X版本那么多附加的功能
JUnit是一个模式密集型的框架,主要用组合模式、模样方法、观察者模式、参数收集方法、命令模式、装饰者模式和适配器模式。其中核心是 前三种
核心类之间的关系
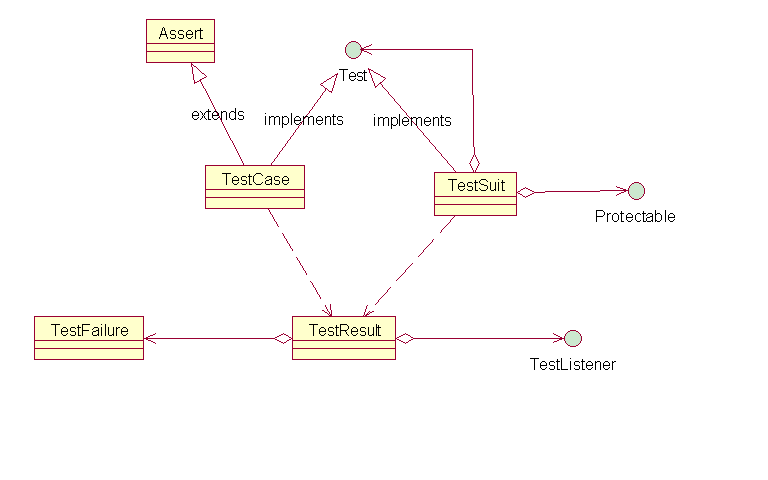
Test、TestCase和TestSuit构成了测试框架的基础,它们用composite模式组合在一起,使得客户端可以将对象的集合以及个别的对象(TestCase)一视同仁.TestRusult用来保存测试结果,和TestListner组成observer模式,支持文本界面、图形界面和 Eclipse 集成组件三种监听器
和JUnit A cook's tour中提到的模式图很相似

类与类之间的关系在此就不作解释了,可以看看参考文章。有兴趣的朋友,欢迎一起讨论 :)