#

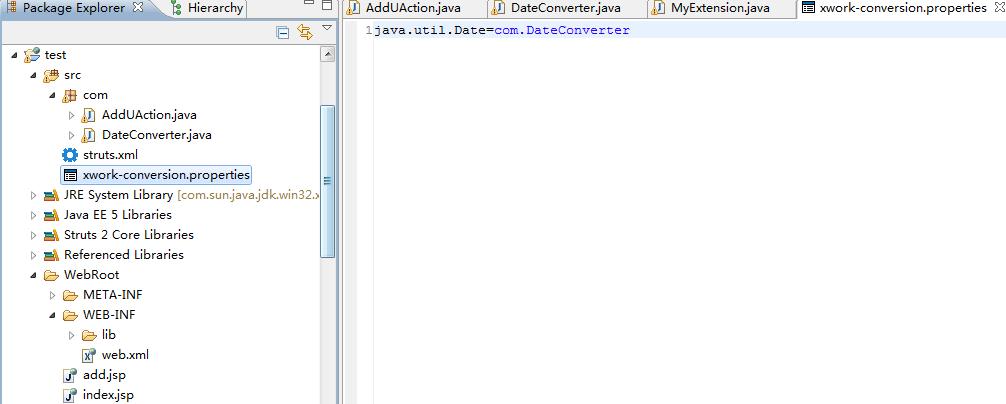
一、AddUAction
package com;
import java.util.Date;
public class AddUAction {
private Date birdate;
public Date getBirdate() {
return birdate;
}
public void setBirdate(Date birdate) {
this.birdate = birdate;
}
public String addU(){
System.out.println(birdate);
return "ok";
}
}
二、struts.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.1//EN" "
http://struts.apache.org/dtds/struts-2.1.dtd">
<struts>
<package name="te" namespace="/te" extends="struts-default">
<action name="teMan" class="com.AddUAction" method="addU">
<result name="ok">/index.jsp</result>
</action>
</package>
</struts>
三、DateConverter
package com;
import java.util.Date;
import java.text.SimpleDateFormat;
import java.util.Map;
import com.opensymphony.xwork2.conversion.impl.DefaultTypeConverter;
public class DateConverter extends DefaultTypeConverter {
@Override
public Object convertValue(Map<String, Object> context, Object value,
Class toType) {
SimpleDateFormat dateFormat=new SimpleDateFormat("yyyyMMdd");
try{
if(toType==Date.class){
String[] params=(String[]) value;
return dateFormat.parse(params[0]);
}else{
Date date=(Date) value;
return dateFormat.format(date);
}
}catch (Exception e) {
return null;
}
}
}
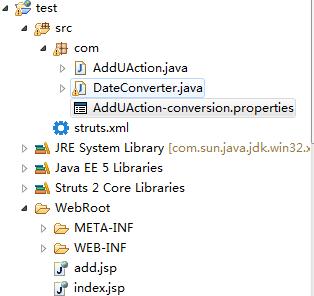
四、AddUAction-conversion.properties
birdate=com.DateConverter
五、包结构
六、在地址栏输入
http://localhost:8080/test/te/teMan!addU?birdate=20010205七、结果会在jsp页面显示出来
This is my JSP page.
Mon Feb 05 00:00:00 CST 2001
对数数组中的内容强排序
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class TestComparator {
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add(new Persion("lcl",28));
list.add(new Persion("fx",23));
list.add(new Persion("wqx",29));
Comparator comp = new Comparator(){
public int compare(Object o1,Object o2) {
Persion p1=(Persion)o1;
Persion p2=(Persion)o2;
if(p1.age<p2.age)
return 1;
else
return 0;
}
};
Collections.sort(list,comp);
for(int i=0;i<list.size();i++){
Persion p=(Persion) list.get(i);
System.out.println(p.age+"+"+p.name);
}
}
}
如果在Unity3D中或者Flex中访问tomcat会出现访问协议异常 做下面的配置即可解决
crossdomain.xml 位置 将这两个文件放在tomcat主目录下即 %TOMCAT_HOME%\webapps\ROOT 下可以避免不同项目相互访问资源导致的权限问题。
web访问位置http://your_host:port/crossdomain.xml,成功访问该文件即可。
1.crossdomain.xml
<?xml version="1.0"?>
<!DOCTYPE cross-domain-policy SYSTEM "./cross-domain-policy.dtd">
<cross-domain-policy> <site-control permitted-cross-domain-policies="all" />
<allow-access-from domain="*" />
<allow-http-request-headers-from domain="*" headers="*"/>
</cross-domain-policy>
2.cross-domain-policy.dtd
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- Adobe DTD for cross-domain policy files -->
<!-- Copyright (c) 2008-2009, Adobe Systems Inc. -->
<!ELEMENT cross-domain-policy (site-control?,allow-access-from*,allow-http-request-headers-from*,allow-access-from-identity*)>
<!ELEMENT site-control EMPTY>
<!ATTLIST site-control permitted-cross-domain-policies (all|by-content-type|by-ftp-filename|master-only|none) #REQUIRED>
<!ELEMENT allow-access-from EMPTY>
<!ATTLIST allow-access-from domain CDATA #REQUIRED>
<!ATTLIST allow-access-from to-ports CDATA #IMPLIED>
<!ATTLIST allow-access-from secure (true|false) "true">
<!ELEMENT allow-http-request-headers-from EMPTY>
<!ATTLIST allow-http-request-headers-from domain CDATA #REQUIRED>
<!ATTLIST allow-http-request-headers-from headers CDATA #REQUIRED>
<!ATTLIST allow-http-request-headers-from secure (true|false) "true">
<!ELEMENT allow-access-from-identity (signatory)>
<!ELEMENT signatory (certificate)>
<!ELEMENT certificate EMPTY>
<!ATTLIST certificate fingerprint CDATA #REQUIRED>
<!ATTLIST certificate fingerprint-algorithm CDATA #REQUIRED>
<!-- End of file. -->
本文讲述Hibernate的generator属性的意义。Generator属性有7种class,本文简略描述了这7种class的意义和用法。
- <class name="onlyfun.caterpillar.User"
- table="USER">
- <id name="id" type="string" unsaved-value="null">
- <column name="USER_ID"/>
- <generator class="uuid.hex"/>
- </id>
- </class>
Hibernate的Generator属性有7种class,本文简略描述了这7种class的意义和用法。
1、identity:用于MySql数据库。特点:递增
- <id name="id" column="id">
- < generator class="identity"/>
- </id>
注:对于MySql数据库使用递增序列时需要在建表时对主键指定为auto_increment属性。
2、sequence:用于Oracle数据库
- <id name="id" column="id">
- <generator class="sequence">
- <param name="sequence">序列名</param>
- </generator>
- </id>
3、native:跨数据库时使用,由底层方言产生。
Default.sequence为hibernate_sequence
- <id name="id" column="id">
- <generator class="native"/>
- </id>
注:使用native时Hibernate默认会去查找Oracle中的hibernate_sequence序列。
如果Oracle中没有该序列,连Oracle数据库时会报错。
4、hilo:通过高低位合成id,先建表hi_value,再建列next_value。必须要有初始值。
- <id name="id" column="id">
- <generator class="hilo">
- <param name="table">high_val</param>
- <param name="column">nextval</param>
- <param name="max_lo">5</param>
- </generator>
- </id>
5、sequencehilo:同过高低位合成id,建一个sequence序列,不用建表。
- <id name="id" column="id">
- <generator class="hilo">
- <param name="sequence">high_val_seq</param>
- <param name="max_lo">5</param>
- </generator>
- </id>
6、assigned:用户自定义id;
- <id name="id" column="id">
- <generator class="assigned"/>
- </id>
7、foreign:用于一对一关系共享主健时,两id值一样。
本文讲解Hibernate中hbm的generator子元素的一些内置生成器的快捷名字。Generator子元素是一个非常简单的接口;某些应用程序可以选择提供他们自己特定的实现。
在*.hbm.xml必须声明的< generator>子元素是一个Java类的名字,用来为该持久化类的实例生成唯一的标识。
- <generator class="sequence"/>
这是一个非常简单的接口;某些应用程序可以选择提供他们自己特定的实现。当然,Hibernate提供了很多内置的实现。下面是Generator子元素的一些内置生成器的快捷名字:
increment(递增)
用于为long, short或者int类型生成唯一标识。只有在没有其他进程往同一张表中插入数据时才能使用。 在集群下不要使用。
identity
对DB2,MySQL, MS SQL Server, Sybase和HypersonicSQL的内置标识字段提供支持。返回的标识符是long, short 或者int类型的。
sequence (序列)
在DB2,PostgreSQL, Oracle, SAP DB, McKoi中使用序列(sequence),而在Interbase中使用生成器(generator)。返回的标识符是long, short或者 int类型的。
hilo (高低位)
使用一个高/低位算法来高效的生成long, short或者 int类型的标识符。给定一个表和字段(默认分别是是hibernate_unique_key 和next_hi)作为高位值得来源。高/低位算法生成的标识符只在一个特定的数据库中是唯一的。在使用JTA获得的连接或者用户自行提供的连接中,不要使用这种生成器。
seqhilo(使用序列的高低位)
使用一个高/低位算法来高效的生成long, short或者 int类型的标识符,给定一个数据库序列(sequence)的名字。
uuid.hex
用一个128-bit的UUID算法生成字符串类型的标识符。在一个网络中唯一(使用了IP地址)。UUID被编码为一个32位16进制数字的字符串。
uuid.string
使用同样的UUID算法。UUID被编码为一个16个字符长的任意ASCII字符组成的字符串。不能使用在PostgreSQL数据库中
native(本地)
根据底层数据库的能力选择identity, sequence 或者hilo中的一个。
assigned(程序设置)
让应用程序在save()之前为对象分配一个标示符。
foreign(外部引用)
使用另外一个相关联的对象的标识符。和< one-to-one>联合一起使用。
Generator子元素的用法:
- <class name="onlyfun.caterpillar.User" table="USER">
- <id name="id" type="string" unsaved-value="null">
- <column name="USER_ID"/>
- <generator class="uuid.hex"/>
- </id>
- </class>
index当前这次迭代从 0 开始的迭代索引
count当前这次迭代从 1 开始的迭代计数
first用来表明当前这轮迭代是否为第一次迭代的标志
last用来表明当前这轮迭代是否为最后一次迭代的标志
begin属性值
end属性值
step属性值
例:
表格偶数行与奇数行颜色交替效果
引标签库
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<%@ taglib prefix="fn" uri="http://java.sun.com/jsp/jstl/functions" %>
<c:forEach items="${queryPromotionList}" var="vPromotion" varStatus="vstatus">
<c:choose>
<c:when test="${vstatus.index%2==0}">
<tr bgcolor="#FFFFFF" height="40">
</c:when>
<c:otherwise>
<tr bgcolor="#F3F3F5" height="40">
</c:otherwise>
</c:choose>
<table class=table_body_bg cellspacing=1 cellpadding=1
width="100%" align=center border=0>
<c:forEach items="${list}" var="a" varStatus="vs">
<c:if test="${vs.count%5==1}">
<tr align="left" height="20">
</c:if>
<td class=table_body_td width="20%"><a href="/aam/degree/advisorAnswer.do?sfid=${a.sfid }">${a.xm }(${a.sfid })</a></td>
<c:set var="count" value="${vs.count}"/> //${vs.count}只在<c:forEach></c:forEach>的范围内有值 外部引用需要把值传出去
</c:forEach>
<c:if test="${count%5==1}">
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
</tr>
</c:if>
<c:if test="${count%5==2}">
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
</tr>
</c:if>
<c:if test="${count%5==3}">
<td class="table_body_td" width="20%"></td>
<td class="table_body_td" width="20%"></td>
</tr>
</c:if>
<c:if test="${count%5==4}">
<td class="table_body_td" width="20%"></td>
</tr>
</c:if>
<c:if test="${count%5==0}">
</tr>
</c:if>
</table>
不论是对整数还是对集合进行迭代, <c:forEach> 剩余的属性 varStatus 所起的作用相同。和 var 属性一样, varStatus 用于创建限定了作用域的变量。不过,由 varStatus 属性命名的变量并不存储当前索引值或当前元素,而是赋予 javax.servlet.jsp.jstl.core.LoopTagStatus 类的实例。该类定义了一组特性,它们描述了迭代的当前状态,下面列出了这些特性:
| 特性 |
Getter |
描述 |
| current |
getCurrent() |
当前这次迭代的(集合中的)项 |
| index |
getIndex() |
当前这次迭代从 0 开始的迭代索引 |
| count |
getCount() |
当前这次迭代从 1 开始的迭代计数 |
| first |
isFirst() |
用来表明当前这轮迭代是否为第一次迭代的标志 |
| last |
isLast() |
用来表明当前这轮迭代是否为最后一次迭代的标志 |
| begin |
getBegin() |
begin 属性值 |
| end |
getEnd() |
end 属性值 |
| step |
getStep() |
step 属性值 |
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ParameterMetaData;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
/**
* 用户数据库访问的类
*@作者Administrator
*@createTime 2011-12-5 上午11:55:18
*@version 1.0
*/
public class DButil1 {
private Connection conn;
private Statement st;
private PreparedStatement pps;
private ResultSet rs;
public String url="jdbc:oracle:thin:@localhost:1521:orcl";
private String user="hyl";
private String password="hyl";
//加载驱动、放在静态代码块中,保证驱动在整个项目中只加载一次,提高效率
static{
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
* 获取连接的方法
* @return Connection 一个有效的数据库连接
*/
public Connection getConnection()
{
try {
//注意链接时,要换成自己的数据库名,数据库用户名及密码
Connection con=DriverManager.getConnection(url,user,password);
return con;
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
/**
* 用于执行更新的方法,包括(insert delete update)操作
* @param sql String 类型的SQL语句
* @return Integer 表示受影响的行数
*/
public int update(String sql)
{
//定义变量用来判断更新操作是否成功,如果返回-1说明没有影响到更新操作的数据库记录条数,即更新操作失败
int row=-1;
try {
//如果数据库链接被关闭了,就要既得一个新的链接
if(conn==null||conn.isClosed()){
conn=getConnection();
}
//使用Connection对象conn的createStatement()创建Statement(数据库语句对象)st
st=conn.createStatement();
//执行更新操作,返回影响的记录条数row
row=st.executeUpdate(sql);
} catch (SQLException e) {
e.printStackTrace();
}
finally{
close();
}
return row;
}
/**
* 基于PreparedStatement的修改方法 PreparedStatement:表示预编译的 SQL 语句的对象
* @param sql String 类型的SQL语句(insert delete update)
* @param obj 存放动态参数的数组
* @return Integer 表示受影响的行数
*/
public int update(String sql,Object ...obj)
{
try {
//获取链接
if(conn==null||conn.isClosed()){
conn=getConnection();
}
//创建预编译的 SQL 语句对象
pps=conn.prepareStatement(sql);
//定义变量length代表数组长度,也就是预处理的sql语句中的参数个数
int length=0;
//ParameterMetaData:用于获取关于 PreparedStatement 对象中每个参数的类型和属性信息的对象
ParameterMetaData pmd=pps.getParameterMetaData();
length=pmd.getParameterCount();
//循环将sql语句中的?设置为obj数组中对应的值,注意从1开始,所以i要加1
for(int i=0;i<length;i++)
{
pps.setObject(i+1, obj[i]);
}
//执行更新操作
return pps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally{
close();
}
return -1;
}
/**
* 获取一条记录的方法,要依赖于下面的queryToList方法,注意泛型的使用
* @param sql
* @return Map<String,Object>
*/
public Map<String,Object> getOneRow(String sql)
{
//执行下面的queryToList方法
List<Map<String,Object>> list=queryToList(sql);
//三目运算,查询结果list不为空返回list中第一个对象,否则返回null
return list.size()>0?list.get(0):null;
}
/**
* 返回查询结果列表,形如:[{TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}, {TEST_NAME=bbb, TEST_NO=3, TEST_PWD=bbb}...]
* @param sql
* @return List<Map<String,Object>>
*/
public List<Map<String,Object>> queryToList(String sql)
{
//创建集合列表用以保存所有查询到的记录
List<Map<String, Object>> list=new LinkedList<Map<String, Object>>();
try {
if(conn==null||conn.isClosed()){
conn=getConnection();
}
st=conn.createStatement();
rs=st.executeQuery(sql);
//ResultSetMetaData 是结果集元数据,可获取关于 ResultSet 对象中列的类型和属性信息的对象 例如:结果集中共包括多少列,每列的名称和类型等信息
ResultSetMetaData rsmd=rs.getMetaData();
//获取结果集中的列数
int columncount=rsmd.getColumnCount();
//while条件成立表明结果集中存在数据
while(rs.next())
{
//创建一个HashMap用于存储一条数据
HashMap<String, Object> onerow=new HashMap<String, Object>();
//循环获取结果集中的列名及列名所对应的值,每次循环都得到一个对象,形如:{TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}
for(int i=0;i<columncount;i++)
{
//获取指定列的名称,注意orcle中列名的大小写
String columnName=rsmd.getColumnName(i+1);
onerow.put(columnName, rs.getObject(i+1));
}
//将获取到的对象onewrow={TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}放到集合列表中
list.add(onerow);
}
}catch (SQLException e) {
e.printStackTrace();
}
finally{
close();
}
return list;
}
/**
* 返回查询结果列表,使用的是预编绎SQL 语句对象PreparedStatement
* 形如:[{TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}, {TEST_NAME=bbb, TEST_NO=3, TEST_PWD=bbb}]
* @param sql
* @param paramValues
* @return List<Map<String,Object>>
*/
public List<Map<String,Object>> queryWithParam(String sql,Object ...paramValues){
//创建集合列表用以保存所有查询到的记录
List<Map<String, Object>> list=new LinkedList<Map<String, Object>>();
try {
if(conn==null||conn.isClosed()){
conn=getConnection();
}
pps = conn.prepareStatement(sql);
for (int i = 0; i < paramValues.length; i++) {
pps.setObject(i + 1, paramValues[i]);
}
rs = pps.executeQuery();
//ResultSetMetaData 是结果集元数据,可获取关于 ResultSet 对象中列的类型和属性信息的对象 例如:结果集中共包括多少列,每列的名称和类型等信息
ResultSetMetaData rsmd=rs.getMetaData();
//获取结果集中的列数
int columncount=rsmd.getColumnCount();
//while条件成立表明结果集中存在数据
while (rs.next()) {
//创建一个HashMap用于存储一条数据
HashMap<String, Object> onerow=new HashMap<String, Object>();
//循环获取结果集中的列名及列名所对应的值,每次循环都得到一个对象,形如:{TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}
for(int i=0;i<columncount;i++)
{
//获取指定列的名称,注意orcle中列名的大小写
String columnName=rsmd.getColumnName(i+1);
onerow.put(columnName, rs.getObject(i+1));
}
//将获取到的对象onewrow={TEST_NAME=aaa, TEST_NO=2, TEST_PWD=aaa}放到集合列表中
list.add(onerow);
}
}catch (SQLException e) {
e.printStackTrace();
}
finally{
close();
}
return list;
}
/**
* 实现oracle分页功能
* @param sql
* @param pagesize
* @param pagenow
* @return PageBean
*/
public PageBean getPage(String sql,int pagesize,int pagenow)
{
PageBean pb=new PageBean();
int end=pagenow*pagesize;
int start=end-pagesize+1;
String exesql="select a.* from (select t.*,rownum as rowindex from ("+sql+") t where rownum<="+end+" ) a where a.rowindex>="+start;
String countsql="select count(*) as rowcount from ("+sql+")";
pb.setResult(queryToList(exesql));
pb.setPagenow(pagenow);
pb.setPagesize(pagesize);
Map<String,Object> map=this.getOneRow(countsql);
int rows=Integer.parseInt(map.get("ROWCOUNT").toString());
pb.setRows(rows);
int pages=rows%pagesize==0?rows/pagesize:rows/pagesize+1;
pb.setPages(pages);
pb.setSql(sql);
return pb;
}
/**
* 关闭数据库各种资源Connection Statement PreparedStatement ResultSet的方法
*/
private void close()
{
if(rs!=null)
{
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(st!=null)
{
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(pps!=null){
try {
pps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
try {
if(conn!=null&&!conn.isClosed())
{
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
首先写一个计数的类OnlineCounter
package accp.onlinecounter;
public class OnlineCounter {
private static long online = 0;
public static long getOnline() {
return online;
}
public static void raise() {
online++;
}
public static void reduce() {
online--;
}
}
之后写一个实现HttpSessionEvent的类OnlineCounterListener
package accp.onlinecounter;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
public class OnlineCounterListener implements HttpSessionListener {
public void sessionCreated(HttpSessionEvent hse) {
OnlineCounter.raise();
}
public void sessionDestroyed(HttpSessionEvent hse) {
OnlineCounter.reduce();
}
}
在web.xml中写listener的注册信息
<listener>
<listener-class>
accp.onlinecounter.OnlineCounterListener
</listener-class>
</listener>
前台界面写上
<body>
在线人数: <%=OnlineCounter.getOnline() %><br/>
<a href="adcourse.jsp">添加课程add course</a><br/>
<a href="adds.jsp">添加学生add stu</a><br/>
<a href="findallcourse.jsp">查询课程信息 select course</a><br/>
<a href="findallstudent.jsp">查询学生信息 select student</a><br/>
<a href="addstudentcourse.jsp">添加选课信息add student course</a><br/>
<a href="querystucourse.jsp">查询选课信息query student course</a><br/>
</body>
注意引入包即可
方法一、 解决的办法自然是用相对路径代替绝对路径,其实log4j的FileAppender本身就有这样的机制,如:log4j.appender.logfile.File=${WORKDIR}/logs/app.log
其中“${WORKDIR}/”是个变量,会被System Property中的“WORKDIR”的值代替。这样,我们就可以在log4j加载配置文件之前,先用System.setProperty ("WORKDIR", WORKDIR);设置好根路径,此操作可通过一初始的servlet进行。
方法二、可以使用服务器环境变量
log4j的配置文件支持服务器的vm的环境变量,格式类似${catalina.home}
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=${catalina.home}/logs/logs_tomcat.log
log4j.appender.R.MaxFileSize=10KB
其中的${catalina.home}并非windows系统的环境变量,这个环境变量就不需要在Windows系统的环境变量中设置。之所以这样,你可以看看tomcat\bin\catalina.bat(startup,shutdown都是调用这个)里面自带有-Dcatalina.home= "%CATALINA_HOME%" 。继承这个思想,所以你也可以自己设定一个参数-Dmylog.home="D:/abc/log"到对应的服务器java启动的vm参数中
方法三、通过servlet初始化init()方法中加载file属性实现相对路径
具体实现:做一个servlet,在系统加载的时候,就把properties的文件读到一个properties文件中.那个file的属性值(我使用的是相对目录)改掉(前面加上系统的根目录),让后把这个properties对象设置到propertyConfig中去,这样就初始化了log的设置.在后面的使用中就用不着再配置了
一般在我们开发项目过程中,log4j日志输出路径固定到某个文件夹,这样如果我换一个环境,日志路径又需要重新修改,比较不方便,目前我采用了动态改变日志路径方法来实现相对路径保存日志文件
(1).在项目启动时,装入初始化类:
public class Log4jInit extends HttpServlet {
static Logger logger = Logger.getLogger(Log4jInit.class);
public Log4jInit() {
}
public void init(ServletConfig config) throws ServletException {
String prefix = config.getServletContext().getRealPath("/");
String file = config.getInitParameter("log4j");
String filePath = prefix + file;
Properties props = new Properties();
try {
FileInputStream istream = new FileInputStream(filePath);
props.load(istream);
istream.close();
//toPrint(props.getProperty("log4j.appender.file.File"));
String logFile = prefix + props.getProperty("log4j.appender.file.File");//设置路径
props.setProperty("log4j.appender.file.File",logFile);
PropertyConfigurator.configure(props);//装入log4j配置信息
} catch (IOException e) {
toPrint("Could not read configuration file [" + filePath + "].");
toPrint("Ignoring configuration file [" + filePath + "].");
return;
}
}
public static void toPrint(String content) {
System.out.println(content);
}
}
实际上log4j的配置文件log4j.properties如为默认名,可放置在JVM能读到的classpath里的任意地方,一般是放在WEB- INF/classes目录下。当log4j的配置文件不再是默认名,则需要另外加载并给出参数,如上 “ropertyConfigurator.configure(props);//装入log4j配置信息”
(2).Web.xml中的配置
<servlet>
<servlet-name>log4j-init</servlet-name>
<servlet-class>Log4jInit</servlet-class>
<init-param>
<param-name>log4j</param-name>
<param-value>WEB-INF/classes/log4j.properties</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
注意:上面的load-on-startup设为0,以便在Web容器启动时即装入该Servlet。log4j.properties文件放在根的properties子目录中,也可以把它放在其它目录中。应该把.properties文件集中存放,这样方便管理。
(3).log4j.properties中即可配置log4j.appender.file.File为当前应用的相对路径.
以上是网上log4j日志文件的相对路径配置的三种方法(我能找到的就三种),分析:
方法一主要是扩展了log4j的RollingFileAppender类,其他的FileAppender同样道理。扩展的方法,就是用一个子类去覆盖setFile方法,这个方法在log4j读取配置文件生成appender的时候调用,传入的就是配
置文件中的路径,这样我就可以按照自己的想法在路径前面加上根路径了。这种方法可以在log4j.properties中用相对路径自由配置log4j.appender.A1.File属性来决定生成的日志相对web应用根
目录的位置。
方法二是利用服务器vm中已经存在的环境变量如${catalina.home}来设置相对于${catalina.home}的日志路径,日志只能放到服务器子目录里,而且如果是用的其它服务器,则要改对应的环境变量。此方法平台移植不方便。
方法三是扩展ActionServlet类,覆盖其init()方法,新方法中载入log4j.properties位置的参数,可以自由配置log4j的配置文件的名字和存放位置。也可自由配置log4j日志文件的相对于当前应用的路径。详
细代码如下:
程序代码
package wbb.bysxxglxt.util;
import org.apache.struts.action.*;
import org.apache.commons.logging.LogFactory;
import org.apache.commons.logging.Log;
import javax.servlet.ServletException;
import java.util.Properties;
import java.io.InputStream;
import org.apache.log4j.PropertyConfigurator;
import java.io.FileInputStream;
import java.io.IOException;
public class ExtendedActionServlet extends ActionServlet {
private Log log = LogFactory.getLog(this.getClass().getName());
public ExtendedActionServlet() {}
public void init() throws ServletException {
log.info(
"Initializing, My MyActionServlet init this System's Const Variable");
String prefix = this.getServletConfig().getServletContext().getRealPath(
"/");
String file = this.getServletConfig().getInitParameter("log4j");
String filePath = prefix + file;
Properties props = new Properties();
System.out.println(prefix);
System.out.println(file);
System.out.println(filePath);
try {
FileInputStream log4jStream = new FileInputStream(filePath);
props.load(log4jStream);
log4jStream.close();
String logFile = prefix +
props.getProperty("log4j.appender.A1.File"); //设置路径
System.out.println(logFile);
props.setProperty("log4j.appender.A1.File", logFile);
PropertyConfigurator.configure(props); //装入log4j配置信息
} catch (IOException e) {
e.printStackTrace();
}
log.info("Initializing, end My Init");
super.init();//应用了struts,此方法不能省,ActionServlet覆盖了的此方法中有很多重要操作
}
}
**********************应用web.xml 关键部分***************************
程序代码
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>wbb.bysxxglxt.util.ExtendedActionServlet</servlet-class>
<init-param>
<param-name>config</param-name>
<param-value>/WEB-INF/struts-config.xml</param-value>
</init-param>
<init-param>
<param-name>log4j</param-name>
<param-value>properties\log4j.properties</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>application</param-name>
<param-value>ApplicationResources</param-value>
</init-param>
<load-on-startup>0</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
注意log4j参数中相对路径的斜杠线的写法,而且log4j属性文件如放置在web-inf/classes目录或web-inf等目录中最好改名,因为在加载此Servlet之前,服务器如tomcat启动时会自动搜索web-inf目录和web-inf/classes目录中log4j.properties文件,如有则自动加载。log4j属性文件加载后,由于该属性文件中log4j.appender.A1.File的值用的是相对路径,自动加载配置便会出错:
log4j:ERROR setFile(null,true) call failed.
java.io.FileNotFoundException: WEB-INF\logs\bysxxglxt.log (系统找不到指定的路径。)
不知道log4j为什么会这么早自动启动。尽管后面加载扩展的ActionServlet中正确设置了log4j属性文件并正常加载了,但报的这个错还是怪不爽的,于是只有更改log4j属性文件名字或者更改其存放位置,让其不能自动加载了,不过还是有两个警告:
log4j:WARN No appenders could be found for logger (org.apache.commons.digester.Digester.sax).
log4j:WARN Please initialize the log4j system properly.
这样做就算是掩耳盗铃了,如果你有更好的解决办法,希望能在此贴出来,大家一起研究。
********************log4j.properties*****************************
### 设置logger级别 ###
程序代码
log4j.rootLogger=DEBUG,stdout,A1
### appender.stdout输出到控制台 ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern= [%5p] [BYSXXGLXT] %d{yyyy-MM-dd HH:mm:ss}: %-4r [%-5p] [%t] ( %F,%L ) - %m%n
### appender.A1输出到日志文件 ###
log4j.appender.A1=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A1.File=WEB-INF\\logs\\bysxxglxt.log
##注意上面日志文件相对应用根目录路径的写法
log4j.appender.A1.DatePattern='.'yyyy-MM-dd'.log'
log4j.appender.A1.Append=true
## 输出DEBUG级别以上的日志
log4j.appender.A1.Threshold=DEBUG
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern= [%5p] [BYSXXGLXT] %d{yyyy-MM-dd HH:mm:ss}: %-4r [%t] ( %F,%L ) - %m%n
首先导入两个包: commons-logging.jar log4j-1.2.12.jar
在src下编写3个 properties文件
1.log4j.properties 下面是内容
##LOGGERS
#define a logger
log4j.rootLogger=INFO,console,file
##APPENDERS
#define an appender named console
log4j.appender.console=org.apache.log4j.ConsoleAppender
#define an appender named file
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=d:/demo_log.txt
#set the log's size
log4j.appender.file.MaxFileSize=1000KB
log4j.appender.file.MaxBackupIndex=20
##LAYOUTS
#assign a SimpleLayout to console appender
log4j.appender.console.layout=org.apache.log4j.SimpleLayout
#assign a PatternLayout to file appender
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%-5p][%d{yyyy-MM-dd HH:mm:ss}]%m%n
2.
simplelog.properties下面是内容
log.apache.commons.logging.simplelog.defaultlog=info
3.
commons-logging.properties下面是内容
##set Log as Log4J
org.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger