
很多人对二级缓存都不太了解,或者是有错误的认识,我一直想写一篇文章介绍一下hibernate的二级缓存的,今天终于忍不住了。
我的经验主要来自hibernate2.1版本,基本原理和3.0、3.1是一样的,请原谅我的顽固不化。
hibernate的session提供了一级缓存,每个session,对同一个id进行两次load,不会发送两条sql给数据库,但是session关闭的时候,一级缓存就失效了。
二级缓存是SessionFactory级别的全局缓存,它底下可以使用不同的缓存类库,比如ehcache、oscache等,需要设置hibernate.cache.provider_class,我们这里用ehcache,在2.1中就是
hibernate.cache.provider_class=net.sf.hibernate.cache.EhCacheProvider
如果使用查询缓存,加上
hibernate.cache.use_query_cache=true
缓存可以简单的看成一个Map,通过key在缓存里面找value。
Class的缓存
对于一条记录,也就是一个PO来说,是根据ID来找的,缓存的key就是ID,value是POJO。无论list,load还是 iterate,只要读出一个对象,都会填充缓存。但是list不会使用缓存,而iterate会先取数据库select id出来,然后一个id一个id的load,如果在缓存里面有,就从缓存取,没有的话就去数据库load。假设是读写缓存,需要设置:
<cache usage="read-write"/>
如果你使用的二级缓存实现是ehcache的话,需要配置ehcache.xml
<cache name="com.xxx.pojo.Foo" maxElementsInMemory="500" eternal="false" timeToLiveSeconds="7200" timeToIdleSeconds="3600" overflowToDisk="true" />
其中eternal表示缓存是不是永远不超时,timeToLiveSeconds是缓存中每个元素(这里也就是一个POJO)的超时时间,如果eternal="false",超过指定的时间,这个元素就被移走了。timeToIdleSeconds是发呆时间,是可选的。当往缓存里面put 的元素超过500个时,如果overflowToDisk="true",就会把缓存中的部分数据保存在硬盘上的临时文件里面。
每个需要缓存的class都要这样配置。如果你没有配置,hibernate会在启动的时候警告你,然后使用defaultCache的配置,这样多个class会共享一个配置。
当某个ID通过hibernate修改时,hibernate会知道,于是移除缓存。
这样大家可能会想,同样的查询条件,第一次先list,第二次再iterate,就可以使用到缓存了。实际上这是很难的,因为你无法判断什么时候是第一次,而且每次查询的条件通常是不一样的,假如数据库里面有100条记录,id从1到100,第一次list的时候出了前50个id,第二次 iterate的时候却查询到30至70号id,那么30-50是从缓存里面取的,51到70是从数据库取的,共发送1+20条sql。所以我一直认为 iterate没有什么用,总是会有1+N的问题。
(题外话:有说法说大型查询用list会把整个结果集装入内存,很慢,而iterate只select id比较好,但是大型查询总是要分页查的,谁也不会真的把整个结果集装进来,假如一页20条的话,iterate共需要执行21条语句,list虽然选择若干字段,比iterate第一条select id语句慢一些,但只有一条语句,不装入整个结果集hibernate还会根据数据库方言做优化,比如使用mysql的limit,整体看来应该还是 list快。)
如果想要对list或者iterate查询的结果缓存,就要用到查询缓存了
查询缓存
首先需要配置hibernate.cache.use_query_cache=true
如果用ehcache,配置ehcache.xml,注意hibernate3.0以后不是net.sf的包名了
<cache name="net.sf.hibernate.cache.StandardQueryCache"
maxElementsInMemory="50" eternal="false" timeToIdleSeconds="3600"
timeToLiveSeconds="7200" overflowToDisk="true"/>
<cache name="net.sf.hibernate.cache.UpdateTimestampsCache"
maxElementsInMemory="5000" eternal="true" overflowToDisk="true"/>
然后
query.setCacheable(true);//激活查询缓存
query.setCacheRegion("myCacheRegion");//指定要使用的cacheRegion,可选
第二行指定要使用的cacheRegion是myCacheRegion,即你可以给每个查询缓存做一个单独的配置,使用setCacheRegion来做这个指定,需要在ehcache.xml里面配置它:
<cache name="myCacheRegion" maxElementsInMemory="10" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200" overflowToDisk="true" />
如果省略第二行,不设置cacheRegion的话,那么会使用上面提到的标准查询缓存的配置,也就是net.sf.hibernate.cache.StandardQueryCache
对于查询缓存来说,缓存的key是根据hql生成的sql,再加上参数,分页等信息(可以通过日志输出看到,不过它的输出不是很可读,最好改一下它的代码)。
比如hql:
from Cat c where c.name like ?
生成大致如下的sql:
select * from cat c where c.name like ?
参数是"tiger%",那么查询缓存的key*大约*是这样的字符串(我是凭记忆写的,并不精确,不过看了也该明白了):
select * from cat c where c.name like ? , parameter:tiger%
这样,保证了同样的查询、同样的参数等条件下具有一样的key。
现在说说缓存的value,如果是list方式的话,value在这里并不是整个结果集,而是查询出来的这一串ID。也就是说,不管是list方法还是iterate方法,第一次查询的时候,它们的查询方式很它们平时的方式是一样的,list执行一条sql,iterate执行1+N条,多出来的行为是它们填充了缓存。但是到同样条件第二次查询的时候,就都和iterate的行为一样了,根据缓存的key去缓存里面查到了value,value是一串id,然后在到class的缓存里面去一个一个的load出来。这样做是为了节约内存。
可以看出来,查询缓存需要打开相关类的class缓存。list和iterate方法第一次执行的时候,都是既填充查询缓存又填充class缓存的。
这里还有一个很容易被忽视的重要问题,即打开查询缓存以后,即使是list方法也可能遇到1+N的问题!相同条件第一次list的时候,因为查询缓存中找不到,不管class缓存是否存在数据,总是发送一条sql语句到数据库获取全部数据,然后填充查询缓存和class缓存。但是第二次执行的时候,问题就来了,如果你的class缓存的超时时间比较短,现在class缓存都超时了,但是查询缓存还在,那么list方法在获取id串以后,将会一个一个去数据库load!因此,class缓存的超时时间一定不能短于查询缓存设置的超时时间!如果还设置了发呆时间的话,保证class缓存的发呆时间也大于查询的缓存的生存时间。这里还有其他情况,比如class缓存被程序强制evict了,这种情况就请自己注意了。
另外,如果hql查询包含select字句,那么查询缓存里面的value就是整个结果集了。
当hibernate更新数据库的时候,它怎么知道更新哪些查询缓存呢?
hibernate在一个地方维护每个表的最后更新时间,其实也就是放在上面net.sf.hibernate.cache.UpdateTimestampsCache所指定的缓存配置里面。
当通过hibernate更新的时候,hibernate会知道这次更新影响了哪些表。然后它更新这些表的最后更新时间。每个缓存都有一个生成时间和这个缓存所查询的表,当hibernate查询一个缓存是否存在的时候,如果缓存存在,它还要取出缓存的生成时间和这个缓存所查询的表,然后去查找这些表的最后更新时间,如果有一个表在生成时间后更新过了,那么这个缓存是无效的。
可以看出,只要更新过一个表,那么凡是涉及到这个表的查询缓存就失效了,因此查询缓存的命中率可能会比较低。
Collection缓存
需要在hbm的collection里面设置
<cache usage="read-write"/>
假如class是Cat,collection叫children,那么ehcache里面配置
<cache name="com.xxx.pojo.Cat.children"
maxElementsInMemory="20" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200"
overflowToDisk="true" />
Collection的缓存和前面查询缓存的list一样,也是只保持一串id,但它不会因为这个表更新过就失效,一个collection缓存仅在这个collection里面的元素有增删时才失效。
这样有一个问题,如果你的collection是根据某个字段排序的,当其中一个元素更新了该字段时,导致顺序改变时,collection缓存里面的顺序没有做更新。
缓存策略
只读缓存(read-only):没有什么好说的
读/写缓存(read-write):程序可能要的更新数据
不严格的读/写缓存(nonstrict-read-write):需要更新数据,但是两个事务更新同一条记录的可能性很小,性能比读写缓存好
事务缓存(transactional):缓存支持事务,发生异常的时候,缓存也能够回滚,只支持jta环境,这个我没有怎么研究过
读写缓存和不严格读写缓存在实现上的区别在于,读写缓存更新缓存的时候会把缓存里面的数据换成一个锁,其他事务如果去取相应的缓存数据,发现被锁住了,然后就直接取数据库查询。
在hibernate2.1的ehcache实现中,如果锁住部分缓存的事务发生了异常,那么缓存会一直被锁住,直到60秒后超时。
不严格读写缓存不锁定缓存中的数据。
使用二级缓存的前置条件
你的hibernate程序对数据库有独占的写访问权,其他的进程更新了数据库,hibernate是不可能知道的。你操作数据库必需直接通过 hibernate,如果你调用存储过程,或者自己使用jdbc更新数据库,hibernate也是不知道的。hibernate3.0的大批量更新和删除是不更新二级缓存的,但是据说3.1已经解决了这个问题。
这个限制相当的棘手,有时候hibernate做批量更新、删除很慢,但是你却不能自己写jdbc来优化,很郁闷吧。
SessionFactory也提供了移除缓存的方法,你一定要自己写一些JDBC的话,可以调用这些方法移除缓存,这些方法是:
void evict(Class persistentClass)
Evict all entries from the second-level cache.
void evict(Class persistentClass, Serializable id)
Evict an entry from the second-level cache.
void evictCollection(String roleName)
Evict all entries from the second-level cache.
void evictCollection(String roleName, Serializable id)
Evict an entry from the second-level cache.
void evictQueries()
Evict any query result sets cached in the default query cache region.
void evictQueries(String cacheRegion)
Evict any query result sets cached in the named query cache region.
不过我不建议这样做,因为这样很难维护。比如你现在用JDBC批量更新了某个表,有3个查询缓存会用到这个表,用evictQueries (String cacheRegion)移除了3个查询缓存,然后用evict(Class persistentClass)移除了class缓存,看上去好像完整了。不过哪天你添加了一个相关查询缓存,可能会忘记更新这里的移除代码。如果你的 jdbc代码到处都是,在你添加一个查询缓存的时候,还知道其他什么地方也要做相应的改动吗?
----------------------------------------------------
总结:
不要想当然的以为缓存一定能提高性能,仅仅在你能够驾驭它并且条件合适的情况下才是这样的。hibernate的二级缓存限制还是比较多的,不方便用jdbc可能会大大的降低更新性能。在不了解原理的情况下乱用,可能会有1+N的问题。不当的使用还可能导致读出脏数据。
如果受不了hibernate的诸多限制,那么还是自己在应用程序的层面上做缓存吧。
在越高的层面上做缓存,效果就会越好。就好像尽管磁盘有缓存,数据库还是要实现自己的缓存,尽管数据库有缓存,咱们的应用程序还是要做缓存。因为底层的缓存它并不知道高层要用这些数据干什么,只能做的比较通用,而高层可以有针对性的实现缓存,所以在更高的级别上做缓存,效果也要好些吧。
导言
从 Spring 1.1.1 开始, EHCache 就作为一种通用缓存解决方案集成进 Spring 。
我将示范拦截器的例子,它能把方法返回的结果缓存起来。
利用 Spring IoC 配置 EHCache
在 Spring 里配置 EHCache 很简单。你只需一个 ehcache.xml 文件,该文件用于配置 EHCache :
|
<ehcache>
<!—设置缓存文件 .data 的创建路径。
如果该路径是 Java 系统参数,当前虚拟机会重新赋值。
下面的参数这样解释:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径 -->
<diskStore path="java.io.tmpdir"/>
<!—缺省缓存配置。CacheManager 会把这些配置应用到程序中。
下列属性是 defaultCache 必须的:
maxInMemory - 设定内存中创建对象的最大值。
eternal - 设置元素(译注:内存中对象)是否永久驻留。如果是,将忽略超
时限制且元素永不消亡。
timeToIdleSeconds - 设置某个元素消亡前的停顿时间。
也就是在一个元素消亡之前,两次访问时间的最大时间间隔值。
这只能在元素不是永久驻留时有效(译注:如果对象永恒不灭,则
设置该属性也无用)。
如果该值是 0 就意味着元素可以停顿无穷长的时间。
timeToLiveSeconds - 为元素设置消亡前的生存时间。
也就是一个元素从构建到消亡的最大时间间隔值。
这只能在元素不是永久驻留时有效。
overflowToDisk - 设置当内存中缓存达到 maxInMemory 限制时元素是否可写到磁盘
上。
-->
<cache name="org.taha.cache.METHOD_CACHE"
maxElementsInMemory="300"
eternal="false"
timeToIdleSeconds="500"
timeToLiveSeconds="500"
overflowToDisk="true"
/>
</ehcache> |
拦截器将使用 ”org.taha.cache.METHOD_CACHE” 区域缓存方法返回结果。下面利用 Spring IoC 让 bean 来访问这一区域。
|
<!-- ====================== 缓存 ======================= -->
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
<property name="configLocation">
<value>classpath:ehcache.xml</value>
</property>
</bean>
<bean id="methodCache" class="org.springframework.cache.ehcache.EhCacheFactoryBean">
<property name="cacheManager">
<ref local="cacheManager"/>
</property>
<property name="cacheName">
<value>org.taha.cache.METHOD_CACHE</value>
</property>
</bean> |
构建我们的 MethodCacheInterceptor
该拦截器实现 org.aopalliance.intercept.MethodInterceptor 接口。一旦 运行起来 (kicks-in) ,它首先检查被拦截方法是否被配置为可缓存的。这将可选择性的配置想要缓存的 bean 方法。只要调用的方法配置为可缓存,拦截器将为该方法生成 cache key 并检查该方法返回的结果是否已缓存。如果已缓存,就返回缓存的结果,否则再次调用被拦截方法,并缓存结果供下次调用。
org.taha.interceptor.MethodCacheInterceptor
|
/*
* Copyright 2002-2004 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.taha.interceptor;
import java.io.Serializable;
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
import org.apache.commons.logging.LogFactory;
import org.apache.commons.logging.Log;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.util.Assert;
import net.sf.ehcache.Cache;
import net.sf.ehcache.Element;
/**
* @author <a href=" mailto:irbouh@gmail.com">Omar Irbouh</a>
* @since 2004.10.07
*/
public class MethodCacheInterceptor implements MethodInterceptor, InitializingBean {
private static final Log logger = LogFactory.getLog(MethodCacheInterceptor.class);
private Cache cache;
/**
* 设置缓存名
*/
public void setCache(Cache cache) {
this.cache = cache;
}
/**
* 检查是否提供必要参数。
*/
public void afterPropertiesSet() throws Exception {
Assert.notNull(cache, "A cache is required. Use setCache(Cache) to provide one.");
}
/**
* 主方法
* 如果某方法可被缓存就缓存其结果
* 方法结果必须是可序列化的(serializable)
*/
public Object invoke(MethodInvocation invocation) throws Throwable {
String targetName = invocation.getThis().getClass().getName();
String methodName = invocation.getMethod().getName();
Object[] arguments = invocation.getArguments();
Object result;
logger.debug("looking for method result in cache");
String cacheKey = getCacheKey(targetName, methodName, arguments);
Element element = cache.get(cacheKey);
if (element == null) {
//call target/sub-interceptor
logger.debug("calling intercepted method");
result = invocation.proceed();
//cache method result
logger.debug("caching result");
element = new Element(cacheKey, (Serializable) result);
cache.put(element);
}
return element.getValue();
}
/**
* creates cache key: targetName.methodName.argument0.argument1...
*/
private String getCacheKey(String targetName,
String methodName,
Object[] arguments) {
StringBuffer sb = new StringBuffer();
sb.append(targetName)
.append(".").append(methodName);
if ((arguments != null) && (arguments.length != 0)) {
for (int i=0; i<arguments.length; i++) {
sb.append(".")
.append(arguments[i]);
}
}
return sb.toString();
}
} |
MethodCacheInterceptor 代码说明了:
- 默认条件下,所有方法返回结果都被缓存了( methodNames 是 null )
- 缓存区利用 IoC 形成
- cacheKey 的生成还包括方法参数的因素(译注:参数的改变会影响 cacheKey )
使用 MethodCacheInterceptor
下面摘录了怎样配置 MethodCacheInterceptor :
|
<bean id="methodCacheInterceptor" class="org.taha.interceptor.MethodCacheInterceptor">
<property name="cache">
<ref local="methodCache" />
</property>
</bean>
<bean id="methodCachePointCut" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor">
<property name="advice">
<ref local="methodCacheInterceptor"/>
</property>
<property name="patterns">
<list>
<value>.*methodOne</value>
<value>.*methodTwo</value>
</list>
</property>
</bean>
<bean id="myBean" class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target">
<bean class="org.taha.beans.MyBean"/>
</property>
<property name="interceptorNames">
<list>
<value>methodCachePointCut</value>
</list>
</property>
</bean> |
译注
如果你要缓存的方法是 findXXX,那么正则表达式应该这样写:“.*find.*”。
夏昕所著《 Hibernate 开发指南》,其中他这样描述 EHCache 配置文件的:
<ehcache>
<diskStore path="java.io.tmpdir"/>
<defaultCache
maxElementsInMemory="10000" //Cache中最大允许保存的数据数量
eternal="false" //Cache中数据是否为常量
timeToIdleSeconds="120" //缓存数据钝化时间
timeToLiveSeconds="120" //缓存数据的生存时间
overflowToDisk="true" //内存不足时,是否启用磁盘缓存
/>
</ehcache> |
请注意!引用、转贴本文应注明原译者:Rosen Jiang 以及出处:http://www.blogjava.net/rosen
<!-- EHCache -->
< bean id ="cacheManager" class ="org.springframework.cache.ehcache.EhCacheManagerFactoryBean" >
< property name ="configLocation" >
< value > classpath:ehcache.xml </ value >
</ property >
</ bean >
< bean id ="methodCache" class ="org.springframework.cache.ehcache.EhCacheFactoryBean" >
< property name ="cacheManager" >
< ref local ="cacheManager" />
</ property >
< property name ="cacheName" >
< value > org.taha.cache.METHOD_CACHE </ value >
</ property >
</ bean >
< bean id ="methodCacheInterceptor" class ="com.cdmcs.util.MethodCacheInterceptor" >
< property name ="cache" >
< ref local ="methodCache" />
</ property >
</ bean >
< bean id ="cleanCacheAdvice" class ="com.cdmcs.util.CleanCacheAdvice" >
< property name ="cache" >
< ref local ="methodCache" />
</ property >
</ bean >
< bean id ="advicePointCut" class ="org.springframework.aop.support.RegexpMethodPointcutAdvisor" >
< property name ="advice" >
< ref local ="cleanCacheAdvice" />
</ property >
< property name ="patterns" >
< list >
< value > .*save.* </ value >
< value > .*update.* </ value >
< value > .*delete.* </ value >
< value > .*valid.* </ value >
</ list >
</ property >
</ bean >
< bean id ="methodCachePointCut" class ="org.springframework.aop.support.RegexpMethodPointcutAdvisor" >
< property name ="advice" >
< ref local ="methodCacheInterceptor" />
</ property >
< property name ="patterns" >
< list >
< value > .*find.* </ value >
</ list >
</ property >
</ bean >
<!-- EHCache End -->
< bean id ="supplyDemandService" parent ="baseTransactionProxy" >
< property name ="target" >
< bean class ="com.cdmcs.webbuilder.service.impl.SupplyDemandServiceImpl" autowire ="byName" />
</ property >
< property name ="preInterceptors" >
< list >
< ref bean ="methodCachePointCut" />
< ref bean ="advicePointCut" />
</ list >
</ property >
</ bean >
摘要: Jeff Johnston
版本1.0.0
本文档允许在遵守以下两条原则的条件下被使用和传播: 1)不能凭借本文档索取任何费用 2)以任何方式(印刷物或电子版)使用和传播时本文档时,必须包含本版权申明
(更新中...)
Table of Contents
前言
eXtremeComponents是一系列提供高级显示的开源JSP定制标...
阅读全文
在 JBoss 下配置 Oracle 数据源
1. 将 %JBOSS_HOME%\docs\examples\jca\oracle-ds.xml 复制到 %JBOSS_HOME%\server\default\deploy 目录下。
2. 打开 oracle-ds.xml,做如下编辑:
- 修改jndi <jndi-name>OracleDS</jndi-name>
- 修改url <connection-url>jdbc:oracle:thin:@localhost:1521:orcl</connection-url>
- 修改驱动 <driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
- 修改用户名和密码 <user-name>root</user-name> <password>123456</password>
<?xml version=”1.0″ encoding=”UTF-8″?>
<datasources>
<local-tx-datasource>
<jndi-name>OracleDS</jndi-name> //jndi名字
<use-java-context>false</use-java-context>
<connection-url>jdbc:oracle:thin:@localhost:1521:orcl</connection-url> //URL地址
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class> //驱动
<user-name>root</user-name> //用户名
<password>123456</password> //密码
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter
</exception-sorter-class-name>
<metadata>
<type-mapping>Oracle9i</type-mapping>
</metadata>
<min-pool-size>10</min-pool-size>
<max-pool-size>30</max-pool-size>
<blocking-timeout-millis>60000</blocking-timeout-millis>
<idle-timeout-minutes>2</idle-timeout-minutes>
<new-connection-sql>SELECT COUNT(*) FROM dual</new-connection-sql>
<check-valid-connection-sql>SELECT COUNT(*) FROM dual</check-valid-connection-sql>
</local-tx-datasource>
</local-tx-datasource>
</datasources>
3. 打开 %JBOSS_HOME%\server\default\conf\standardjbosscmp-jdbc.xml 并编辑:
<jbosscmp-jdbc>
<defaults>
<datasource>java:/DefaultDS</datasource>
……
</defaults>
……
</jbosscmp-jdbc>
4. 打开 %JBOSS_HOME%\server\default\conf\login-config.xml, 将如下内容复制到文件最后:
<application-policy name = “OracleDbRealm”>
<authentication>
<login-module code = “org.jboss.resource.security.ConfiguredIdentityLoginModule” flag = “required”>
<module-option name = “principal”>OracleDS</module-option>
<module-option name = “userName”>root</module-option>
<module-option name = “password”>123456</module-option>
<module-option name = “managedConnectionFactoryName”>
jboss.jca:service=LocalTxCM,name=OracleDS
</module-option>
</login-module>
</authentication>
</application-policy>
5. 将 Oracle 驱动程序复制到 %JBOSS_HOME%\server\default\lib 目录下。
去除jboss的冲突包
由于jboss自身带的hibernate-annotations.jar版本与项目使用的版本存在冲突,因此去除hibernate-annotations.jar包
mv /opt/jboss-4.2.2.GA/server/default/lib/hibernate-annotations.jar /opt/jboss-4.2.2.GA/server/default/lib/hibernate-annotations.jar.bak 10. 部署esales.war到/opt/jboss-4.2.2.GA/server/default/deploy
以上的5步操作,完成了 JBoss 基本的数据源配置,但配置文件中有密码的明码,存在安全隐患。所以请使用如下的方法对密码进行加密的配置:
1. 生成加密密码:
- 进入dos命令行模式
- Set JBOSS_HOME环境变量
- 执行如下命令:
java -cp %JBOSS_HOME%\lib\jboss-jmx.jar;%JBOSS_HOME%\lib\jboss-common.jar;%JBOSS_HOME%\server\default\lib\jboss-jca.jar;%JBOSS_HOME%\server\default\lib\jbosssx.jar org.jboss.resource.security.SecureIdentityLoginModule 123456
- 生成 123456 的加密密码为: 64c5fd2979a86168
2. 修改 %JBOSS_HOME%\server\default\deploy\oracle-ds.xml 文件:
<?xml version=”1.0″ encoding=”UTF-8″?>
<datasources>
<local-tx-datasource>
<jndi-name>OracleDS</jndi-name>
<use-java-context>false</use-java-context>
<connection-url>jdbc:oracle:thin:@localhost:1521:orcl</connection-url>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<security-domain>EncryptDBPassword</security-domain> //这里不用写上你的用户名与密码了,我们可以在 login-config.xml 里做点手脚,就OK了
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter</exception-sorter-class-name>
<metadata>
<type-mapping>Oracle9i</type-mapping>
</metadata>
<min-pool-size>10</min-pool-size>
<max-pool-size>30</max-pool-size>
<blocking-timeout-millis>60000</blocking-timeout-millis>
<idle-timeout-minutes>2</idle-timeout-minutes>
<new-connection-sql>SELECT COUNT(*) FROM dual</new-connection-sql>
<check-valid-connection-sql>SELECT COUNT(*) FROM dual</check-valid-connection-sql>
</local-tx-datasource>
</local-tx-datasource>
</datasources>
3. 打开 %JBOSS_HOME%\server\default\conf\login-config.xml 文件,加上下面这一段配置文件:
<application-policy name=”EncryptDBPassword”> //这里的 name 应该是你在配置数据源时写的 security-domain 里的字符串
<authentication>
<login-module code=”org.jboss.resource.security.SecureIdentityLoginModule”
flag=”required”>
<module-option name=”username”>root</module-option> //数据库的用户名
<module-option name=”password”>64c5fd2979a86168</module-option> //数据库的密码,不过是加密过的了
<module-option name=”managedConnectionFactoryName”>
jboss.jca:service=LocalTxCM,name=OracleDS
</module-option> //注意 name 等于你的数据源的 jndi-name,这里是 OracleDS。
</login-module>
</authentication>
</application-policy>
一. 下载与安装JBoss
在本文中,我们下载的JBoss版本为:4.2.1.GA。
下载地址:
http://sourceforge.net/project/showfiles.php?group_id=22866&package_id=16942&release_id=523619
在如上的下载页中下载JBoss-4.2.1.GA.zip文件。
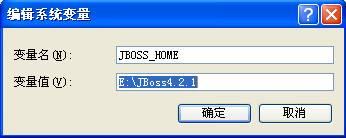
下载完成后,将其解压缩后即可完成安装,解压缩后将其放置到一个不带空格的目录(若目录带有空格,例如:C:"Program Files,日后可能会产生一些莫名的错误),eg:E:"JBoss4.2.1。同时在“环境变量设置”中设置名为JBOSS_HOME的环境变量,值为JBoss的安装路径,如下图所示:
在此,JBoss的安装工作已经结束,可通过如下方式测试安装是否成功:
运行JBoss安装目录"bin"run.bat,如果窗口中没有出现异常,且出现:10:16:19,765 INFO [Server] JBoss (MX MicroKernel) [4.2.1.GA (build: SVNTag=JBoss_4_2_1_GA date=200707131605)] Started in 30s:828ms字样,则表示安装成功。
我们可以通过访问:http://localhost:8080进入JBoss的欢迎界面,点击JBoss Management下的JMX Console可进入JBoss的控制台。
若启动失败,可能由以下原因引起:
1) JBoss所用的端口(8080,1099,1098,8083等)被占用。一般情况下为8080端口被占用(例如,Oracle占用了8080端口),此时需要修改JBoss的端口,方法为进入JBoss安装目录"server"default"deploy"jboss-web.deployer目录,修改其下的server.xml目录,在此文件中搜索8080,将其改成你想要的端口即可(例如8088);
2) JDK安装不正确;
3) JBoss下载不完全。
二. JBoss的目录结构说明
|
目录 |
描述 |
|
bin |
启动和关闭JBoss 的脚本(run.bat为windows系统下的启动脚本,shutdown.bat为windows系统下的关闭脚本)。 |
|
client |
客户端与JBoss 通信所需的Java 库(JARs)。 |
|
docs |
配置的样本文件(数据库配置等)。 |
|
docs/dtd |
在JBoss 中使用的各种XML 文件的DTD。 |
|
lib |
一些JAR,JBoss 启动时加载,且被所有JBoss 配置共享。(不要把你的库放在这里) |
|
server |
各种JBoss 配置。每个配置必须放在不同的子目录。子目录的名字表示配置的名字。JBoss 包含3 个默认的配置:minimial,default 和all,在你安装时可以进行选择。 |
|
server/all |
JBoss 的完全配置,启动所有服务,包括集群和IIOP 。 |
|
server/default |
JBoss 的默认配置。在没有在JBoss 命令行中指定配置名称时使用。(我们下载的4.2.1版本默认采用此配置) 。 |
|
server/default/conf |
JBoss 的配置文件。 |
|
server/default/data |
JBoss 的数据库文件。比如,嵌入的数据库,或者JBossMQ |
|
server/default /deploy |
JBoss 的热部署目录。放到这里的任何文件或目录会被JBoss 自动部署。EJB、WAR 、EAR,甚至服务。 |
|
server/default /lib |
一些JAR,JBoss 在启动特定配置时加载他们。(default 和minimial 配置也包含这个和下面两个目录。) |
|
server/default/log |
JBoss 的日志文件。 |
|
server/default/tmp |
JBoss 的临时文件。 |
三. JBoss的配置
1. 日志文件设置
若需要修改JBoss默认的log4j设置,可修改JBoss安装目录"server"default"conf下的jboss-log4j.xml文件,在该文件中可以看到,log4j的日志输出在JBoss安装目录"server"default"log下的server.log文件中。对于log4j的设置,读者可以在网上搜索更加详细的信息。
2. web服务的端口号的修改
这点在前文中有所提及,即修改JBoss安装目录"server"default"deploy"jboss-web.deployer下的server.xml文件,内容如下:
<Connector port="8080" address="${jboss.bind.address}"
maxThreads="250" maxHttpHeaderSize="8192"
emptySessionPath="true" protocol="HTTP/1.1"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
将上面的8080端口修改为你想要的端口即可。重新启动JBoss后访问:http://localhost:新设置的端口,可看到JBoss的欢迎界面。
3. JBoss的安全设置
1)jmx-console登录的用户名和密码设置
默认情况访问http://localhost:8080/jmx-console就可以浏览jboss的部署管理的一些信息,不需要输入用户名和密码,使用起来有点安全隐患。下面我们针对此问题对jboss进行配置,使得访问jmx-console也必须要知道用户名和密码才可进去访问。步骤如下:
i) 找到JBoss安装目录/server/default/deploy/jmx-console.war/WEB-INF/jboss-web.xml文件,去掉<security-domain>java:/jaas/jmx-console</security-domain>的注释。修改后的该文件内容为:
<jboss-web>
<!-- Uncomment the security-domain to enable security. You will
need to edit the htmladaptor login configuration to setup the
login modules used to authentication users.-->
<security-domain>java:/jaas/jmx-console</security-domain>
</jboss-web>
ii)修改与i)中的jboss-web.xml同级目录下的web.xml文件,查找到<security-constraint/>节点,去掉它的注释,修改后该部分内容为:
<!-- A security constraint that restricts access to the HTML JMX console
to users with the role JBossAdmin. Edit the roles to what you want and
uncomment the WEB-INF/jboss-web.xml/security-domain element to enable
secured access to the HTML JMX console.-->
<security-constraint>
<web-resource-collection>
<web-resource-name>HtmlAdaptor</web-resource-name>
<description>An example security config that only allows users with the
role JBossAdmin to access the HTML JMX console web application
</description>
<url-pattern>/*</url-pattern>
<http-method>GET</http-method>
<http-method>POST</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>JBossAdmin</role-name>
</auth-constraint>
</security-constraint>
在此处可以看出,为登录配置了角色JBossAdmin。
iii) 在第一步中的jmx-console安全域和第二步中的运行角色JBossAdmin都是在login-config.xml中配置,我们在JBoss安装目录/server/default/config下找到它。查找名字为:jmx-console的application-policy:
<application-policy name = "jmx-console">
<authentication>
<login-module code="org.jboss.security.auth.spi.UsersRolesLoginModule"
flag = "required">
<module-option name="usersProperties">props/jmx-console-users.properties</module-option>
<module-option name="rolesProperties">props/jmx-console-roles.properties</module-option>
</login-module>
</authentication>
</application-policy>
在此处可以看出,登录的角色、用户等的信息分别在props目录下的jmx-console-roles.properties和jmx-console-users.properties文件中设置,分别打开这两个文件。
其中jmx-console-users.properties文件的内容如下:
# A sample users.properties file for use with the UsersRolesLoginModule
admin=admin
该文件定义的格式为:用户名=密码,在该文件中,默认定义了一个用户名为admin,密码也为admin的用户,读者可将其改成所需的用户名和密码。
jmx-console-roles.properties的内容如下:
# A sample roles.properties file for use with the UsersRolesLoginModule
admin=JBossAdmin, HttpInvoker
该文件定义的格式为:用户名=角色,多个角色以“,”隔开,该文件默认为admin用户定义了JBossAdmin和HttpInvoker这两个角色。
配置完成后读者可以通过访问:http://localhost:8088/jmx-console/,输入jmx-console-roles.properties文件中定义的用户名和密码,访问jmx-console的页面。
2)web-console登录的用户名和密码设置
默认情况下,用户访问JBoss的web-console时,不需要输入用户名和密码,为了安全起见,我们通过修改配置来为其加上用户名和密码。步骤如下:
i)找到JBoss安装目录"server"default"deploy"management"console-mgr.sar"web-console.war"WEB-INF"jboss-web.xml文件,去掉<security-domain>java:/jaas/web-console</security-domain>的注释,修改后的文件内容为:
<?xml version='1.0' encoding='UTF-8' ?>
<!DOCTYPE jboss-web
PUBLIC "-//JBoss//DTD Web Application 2.3V2//EN"
"http://www.jboss.org/j2ee/dtd/jboss-web_3_2.dtd">
<jboss-web>
<!-- Uncomment the security-domain to enable security. You will
need to edit the htmladaptor login configuration to setup the
login modules used to authentication users.-->
<security-domain>java:/jaas/web-console</security-domain>
<!-- The war depends on the -->
<depends>jboss.admin:service=PluginManager</depends>
</jboss-web>
ii)打开i)中jboss-web.xml同目录下的web.xml文件,去掉<security-constraint>部分的注释,修改后的该部分内容为:
<!-- A security constraint that restricts access to the HTML JMX console
to users with the role JBossAdmin. Edit the roles to what you want and
uncomment the WEB-INF/jboss-web.xml/security-domain element to enable
secured access to the HTML JMX console.-->
<security-constraint>
<web-resource-collection>
<web-resource-name>HtmlAdaptor</web-resource-name>
<description>An example security config that only allows users with the
role JBossAdmin to access the HTML JMX console web application
</description>
<url-pattern>/*</url-pattern>
<http-method>GET</http-method>
<http-method>POST</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>JBossAdmin</role-name>
</auth-constraint>
</security-constraint>
iii)打开JBoss安装目录"server"default"conf下的login-config.xml文件,搜索web-console,可找到如下内容:
<application-policy name = "web-console">
<authentication>
<login-module code="org.jboss.security.auth.spi.UsersRolesLoginModule"
flag = "required">
<module-option name="usersProperties">web-console-users.properties</module-option>
<module-option name="rolesProperties">web-console-roles.properties</module-option>
</login-module>
</authentication>
</application-policy>
在文件中可以看到,设置登录web-console的用户名和角色等信息分别在login-config.xml文件所在目录下的web-console-users.properties和web-console-roles.properties文件中,但因为该目录下无这两个文件,我们在JBoss安装目录"server"default"conf"props目录下建立这两个文件,文件内容可参考在“jmx-console登录的用户名和密码设置”中的两个相应的配置文件的内容,web-console-users.properties文件的内容如下:
# A sample users.properties file for use with the UsersRolesLoginModule
admin=admin
web-console-roles.properties文件的内容如下:
# A sample roles.properties file for use with the UsersRolesLoginModule
admin=JBossAdmin,HttpInvoker
因为此时这两个文件不与login-config.xml同目录,所以login-config.xml文件需进行少许修改,修改后的<application-policy name = "web-console">元素的内容为:
<application-policy name = "web-console">
<authentication>
<login-module code="org.jboss.security.auth.spi.UsersRolesLoginModule"
flag = "required">
<module-option name="usersProperties">props/web-console-users.properties</module-option>
<module-option name="rolesProperties">props/web-console-roles.properties</module-option>
</login-module>
</authentication>
</application-policy>
四. 在MyEclipse中配置JBoss
笔者的MyEclipse版本:5.1.1 GA
JBoss版本:4.2.1 GA
JDK版本:1.5
进入Window-> Preferences-> MyEclipse -> Application Servers -> JBoss4,进行如下设置:
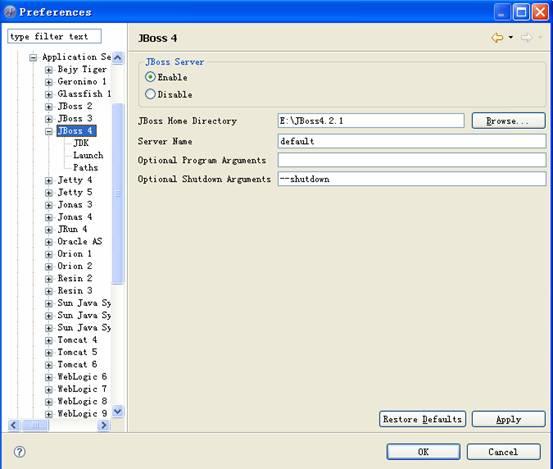
选择JBoss 4下的JDK设置所用的JDK.
设置完成后,部署程序时,会发现多出JBoss 4部署的选择,如下图所示:
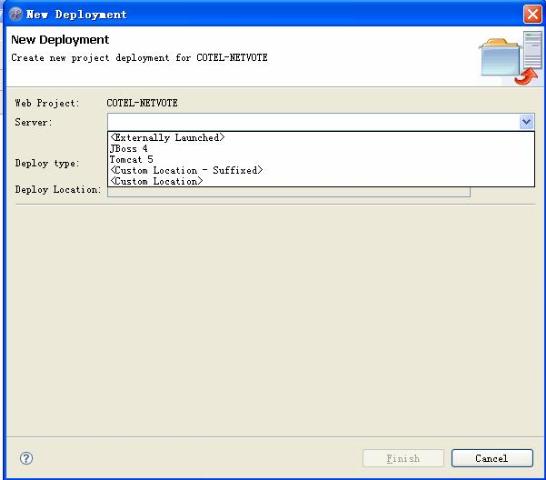
同时在 中展开,可看到JBoss 4的启动图标。
中展开,可看到JBoss 4的启动图标。
参考文档:Jboss4.03 web-console jmx-console 登录安全设置
到了21世纪--准确地说是2003年,UML已经获得了业界的认同。在我所见过的专业人员的简历中,75%都声称具备UML的知识。然而,在同绝大多数求职人员面谈之后,可以明显地看出他们并不真正了解UML。通常地,他们将UML用作一个术语,或对UML一知半解。大家对UML缺乏理解的这种状况,促进我撰写这篇关于UML 1.4的快速入门文章。当阅读完本文时,您还不具备足够的知识可以在简历上声称自己掌握了UML,但是您已具有了进一步钻研该语言的良好起点。
正如前面曾提到过的,UML的本意是要成为一种标准的统一语言,使得IT专业人员能够进行计算机应用程序的建模。UML的主要创始人是Jim Rumbaugh、Ivar Jacobson和Grady Booch,他们最初都有自己的建模方法(OMT、OOSE和Booch),彼此之间存在着竞争。最终,他们联合起来创造了一种开放的标准。(听起来是不是很熟悉?这个现象类似J2EE、SOAP和Linux的诞生。)UML成为"标准"建模语言的原因之一在于,它与程序设计语言无关。(IBM Rational的UML建模工具被广泛应用于J2EE和.NET开发。)而且,UML符号集只是一种语言而不是一种方法学。这点很重要,因为语言与方法学不同,它可以在不做任何更改的情况下很容易地适应任何公司的业务运作方式。
既然UML不是一种方法学,它就不需要任何正式的工作产品(即IBM Rational Unified Process?术语中所定义的"工件")。而且它还提供了多种类型的模型描述图(diagram),当在某种给定的方法学中使用这些图时,它使得开发中的应用程序的更易理解。UML的内涵远不只是这些模型描述图,但是对于入门来说,这些图对这门语言及其用法背后的基本原理提供了很好的介绍。通过把标准的UML图放进您的工作产品中,精通UML的人员就更加容易加入您的项目并迅速进入角色。最常用的UML图包括:用例图、类图、序列图、状态图、活动图、组件图和部署图。
深入讨论每类图的细节问题已超出了这篇入门文章的范围。因此,下面仅给出了每类图的简要说明,更详细的信息将在以后的文章中探讨。
用例图
用例图描述了系统提供的一个功能单元。用例图的主要目的是帮助开发团队以一种可视化的方式理解系统的功能需求,包括基于基本流程的"角色"(actors,也就是与系统交互的其他实体)关系,以及系统内用例之间的关系。用例图一般表示出用例的组织关系--要么是整个系统的全部用例,要么是完成具有功能(例如,所有安全管理相关的用例)的一组用例。要在用例图上显示某个用例,可绘制一个椭圆,然后将用例的名称放在椭圆的中心或椭圆下面的中间位置。要在用例图上绘制一个角色(表示一个系统用户),可绘制一个人形符号。角色和用例之间的关系使用简单的线段来描述,如图1所示。

图1:示例用例图
图字(从上到下):CD销售系统;查看乐队CD的销售统计;乐队经理;查看Billboard 200排行榜报告;唱片经理;查看特定CD的销售统计;检索最新的Billboard 200排行榜报告;排行榜报告服务
用例图通常用于表达系统或者系统范畴的高级功能。如图1所示,可以很容易看出该系统所提供的功能。这个系统允许乐队经理查看乐队CD的销售统计报告以及Billboard 200排行榜报告。它也允许唱片经理查看特定CD的销售统计报告和这些CD在Billboard 200排行榜的报告。这个图还告诉我们,系统将通过一个名为"排行榜报告服务"的外部系统提供Billboard排行榜报告。
此外,在用例图中,没有列出的用例表明了该系统不能完成的功能。例如,它不能提供给乐队经理收听Billboard 200上不同专辑中的歌曲的途径 -- 也就是说,系统没有引用一个叫做"收听Billboard 200上的歌曲"的用例。这种缺少不是一件小事。在用例图中提供清楚的、简要的用例描述,项目赞助商就很容易看出系统是否提供了必须的功能。
类图
类图表示不同的实体(人、事物和数据)如何彼此相关;换句话说,它显示了系统的静态结构。类图可用于表示逻辑类,逻辑类通常就是业务人员所谈及的事物种类--摇滚乐队、CD、广播剧;或者贷款、住房抵押、汽车信贷以及利率。类图还可用于表示实现类,实现类就是程序员处理的实体。实现类图或许会与逻辑类图显示一些相同的类。然而,实现类图不会使用相同的属性来描述,因为它很可能具有对诸如Vector和HashMap这种事物的引用。
类在类图上使用包含三个部分的矩形来描述,如图2所示。最上面的部分显示类的名称,中间部分包含类的属性,最下面的部分包含类的操作(或者说"方法")。

图2:类图中的示例类对象
根据我的经验,几乎每个开发人员都知道这个类图是什么,但是我发现大多数程序员都不能正确地描述类的关系。对于像图3这样的类图,您应该使用带有顶点指向父类的箭头的线段来绘制继承关系1,并且箭头应该是一个完全的三角形。如果两个类都彼此知道对方,则应该使用实线来表示关联关系;如果只有其中一个类知道该关联关系,则使用开箭头表示。

图3:一个完整的类图,包括了图2所示的类对象
在图3中,我们同时看到了继承关系和两个关联关系。CDSalesReport类继承自Report类。一个CDSalesReport类与一个CD类关联,但是CD类并不知道关于CDSalesReport类的任何信息。CD类和Band类都彼此知道对方,两个类彼此都可以与一个或者多个对方类相关联。
一个类图可以整合其他许多概念,这将在本系列文章的后续文章中介绍。
序列图
序列图显示具体用例(或者是用例的一部分)的详细流程。它几乎是自描述的,并且显示了流程中中不同对象之间的调用关系,同时还可以很详细地显示对不同对象的不同调用。
序列图有两个维度:垂直维度以发生的时间顺序显示消息/调用的序列;水平维度显示消息被发送到的对象实例。
序列图的绘制非常简单。横跨图的顶部,每个框(参见图4)表示每个类的实例(对象)。在框中,类实例名称和类名称之间用空格/冒号/空格来分隔,例如,myReportGenerator : ReportGenerator。如果某个类实例向另一个类实例发送一条消息,则绘制一条具有指向接收类实例的开箭头的连线,并把消息/方法的名称放在连线上面。对于某些特别重要的消息,您可以绘制一条具有指向发起类实例的开箭头的虚线,将返回值标注在虚线上。就我而言,我总喜欢绘制出包括返回值的虚线,这些额外的信息可以使得序列图更易于阅读。
阅读序列图也非常简单。从左上角启动序列的"驱动"类实例开始,然后顺着每条消息往下阅读。记住:虽然图4所示的例子序列图显示了每条被发送消息的返回消息,但这只是可选的。

图4:一个示例序列图
通过阅读图4中的示例序列图,您可以明白如何创建一个CD销售报告(CD Sales Report)。其中的aServlet对象表示驱动类实例。aServlet向名为gen的ReportGenerator类实例发送一条消息。该消息被标为generateCDSalesReport,表示ReportGenerator对象实现了这个消息处理程序。进一步理解可发现,generateCDSalesReport消息标签在括号中包括了一个cdId,表明aServlet随该消息传递一个名为cdId的参数。当gen实例接收到一条generateCDSalesReport消息时,它会接着调用CDSalesReport类,并返回一个aCDReport的实例。然后gen实例对返回的aCDReport实例进行调用,在每次消息调用时向它传递参数。在该序列的结尾,gen实例向它的调用者aServlet返回一个aCDReport。
请注意:图4中的序列图相对于典型的序列图来说太详细了。然而,我认为它才是足够易于理解的,并且它显示了如何表示嵌套的调用。对于初级开发人员来说,有时把一个序列分解到这种详细程度是很有必要的,这有助于他们理解相关的内容。
状态图
状态图表示某个类所处的不同状态和该类的状态转换信息。有人可能会争论说每个类都有状态,但不是每个类都应该有一个状态图。只对"感兴趣的"状态的类(也就是说,在系统活动期间具有三个或更多潜在状态的类)才进行状态图描述。
如图5所示,状态图的符号集包括5个基本元素:初始起点,它使用实心圆来绘制;状态之间的转换,它使用具有开箭头的线段来绘制;状态,它使用圆角矩形来绘制;判断点,它使用空心圆来绘制;以及一个或者多个终止点,它们使用内部包含实心圆的圆来绘制。要绘制状态图,首先绘制起点和一条指向该类的初始状态的转换线段。状态本身可以在图上的任意位置绘制,然后只需使用状态转换线条将它们连接起来。

图5:显示类通过某个功能系统的各种状态的状态图
图5中的状态图显示了它们可以表达的一些潜在信息。例如,从中可以看出贷款处理系统最初处于Loan Application状态。当批准前(pre-approval)过程完成时,根据该过程的结果,或者转到Loan Pre-approved状态,或者转到Loan Rejected状态。这个判断(它是在转换过程期间做出的)使用一个判断点来表示--即转换线条间的空心圆。通过该状态图可知,如果没有经过Loan Closing状态,贷款不可能从Loan Pre-Approved状态进入Loan in Maintenance状态。而且,所有贷款都将结束于Loan Rejected或者Loan in Maintenance状态。
活动图
活动图表示在处理某个活动时,两个或者更多类对象之间的过程控制流。活动图可用于在业务单元的级别上对更高级别的业务过程进行建模,或者对低级别的内部类操作进行建模。根据我的经验,活动图最适合用于对较高级别的过程建模,比如公司当前在如何运作业务,或者业务如何运作等。这是因为与序列图相比,活动图在表示上"不够技术性的",但有业务头脑的人们往往能够更快速地理解它们。
活动图的符号集与状态图中使用的符号集类似。像状态图一样,活动图也从一个连接到初始活动的实心圆开始。活动是通过一个圆角矩形(活动的名称包含在其内)来表示的。活动可以通过转换线段连接到其他活动,或者连接到判断点,这些判断点连接到由判断点的条件所保护的不同活动。结束过程的活动连接到一个终止点(就像在状态图中一样)。作为一种选择,活动可以分组为泳道(swimlane),泳道用于表示实际执行活动的对象,如图6所示。

图6:活动图,具有两个泳道,表示两个对象的活动控制:乐队经理,以及报告工具
图字(沿箭头方向):乐队经理;报告工具;选择"查看乐队的销售报告";检索该乐队经理所管理的乐队;显示报告条件选择屏幕;选择要查看其销售报告的乐队;从销售数据库检索销售数据;显示销售报告。
该活动图中有两个泳道,因为有两个对象控制着各自的活动:乐队经理和报告工具。整个过程首先从乐队经理选择查看他的乐队销售报告开始。然后报告工具检索并显示他管理的所有乐队,并要求他从中选择一个乐队。在乐队经理选择一个乐队之后,报告工具就检索销售信息并显示销售报告。该活动图表明,显示报告是整个过程中的最后一步。
组件图
组件图提供系统的物理视图。它的用途是显示系统中的软件对其他软件组件(例如,库函数)的依赖关系。组件图可以在一个非常高的层次上显示,从而仅显示粗粒度的组件,也可以在组件包层次2上显示。
组件图的建模最适合通过例子来描述。图7显示了4个组件:Reporting Tool、Billboard Service、Servlet 2.2 API和JDBC API。从Reporting Tool组件指向Billboard Service、Servlet 2.2 API和JDBC API组件的带箭头的线段,表示Reporting Tool依赖于那三个组件。

图7:组件图显示了系统中各种软件组件的依赖关系
部署图
部署图表示该软件系统如何部署到硬件环境中。它的用途是显示该系统不同的组件将在何处物理地运行,以及它们将如何彼此通信。因为部署图是对物理运行情况进行建模,系统的生产人员就可以很好地利用这种图。
部署图中的符号包括组件图中所使用的符号元素,另外还增加了几个符号,包括节点的概念。一个节点可以代表一台物理机器,或代表一个虚拟机器节点(例如,一个大型机节点)。要对节点进行建模,只需绘制一个三维立方体,节点的名称位于立方体的顶部。所使用的命名约定与序列图中相同:[实例名称] : [实例类型](例如,"w3reporting.myco.com : Application Server")。
图8:部署图。由于Reporting Tool组件绘制在IBM WebSphere内部,后者又绘制在节点w3.reporting.myco.com内部,因而我们知道,用户将通过运行在本地机器上的浏览器来访问Reporting Tool,浏览器通过公司intranet上的HTTP协议与Reporting Tool建立连接。
图8中的部署图表明,用户使用运行在本地机器上的浏览器访问Reporting Tool,并通过公司intranet上的HTTP协议连接到Reporting Tool组件。这个工具实际运行在名为w3reporting.myco.com的Application Server上。这个图还表明Reporting Tool组件绘制在IBM WebSphere内部,后者又绘制在w3.reporting.myco.com节点内部。Reporting Tool使用Java语言通过IBM DB2数据库的JDBC接口连接到它的报告数据库上,然后该接口又使用本地DB2通信方式,与运行在名为db1.myco.com的服务器上实际的DB2数据库通信。除了与报告数据库通信外,Report Tool组件还通过HTTPS上的SOAP与Billboard Service进行通信。
hibernate的session提供了一级缓存,每个session,对同一个id进行两次load,不会发送两条sql给数据库,但是session关闭的时候,一级缓存就失效了。
二级缓存是SessionFactory级别的全局缓存,它底下可以使用不同的缓存类库,比如ehcache、oscache等,需要设置hibernate.cache.provider_class,我们这里用ehcache,在2.1中就是
hibernate.cache.provider_class=net.sf.hibernate.cache.EhCacheProvider
如果使用查询缓存,加上
hibernate.cache.use_query_cache=true
缓存可以简单的看成一个Map,通过key在缓存里面找value。
Class的缓存 对于一条记录,也就是一个PO来说,是根据ID来找的,缓存的key就是ID,value是POJO。无论list,load还是iterate,只要读出一个对象,都会填充缓存。但是list不会使用缓存,而iterate会先取数据库select id出来,然后一个id一个id的load,如果在缓存里面有,就从缓存取,没有的话就去数据库load。假设是读写缓存,需要设置:
<cache usage="read-write"/>
如果你使用的二级缓存实现是ehcache的话,需要配置ehcache.xml
<cache name="com.xxx.pojo.Foo" maxElementsInMemory="500" eternal="false" timeToLiveSeconds="7200" timeToIdleSeconds="3600" overflowToDisk="true" />
其中eternal表示缓存是不是永远不超时,timeToLiveSeconds是缓存中每个元素(这里也就是一个POJO)的超时时间,如果eternal="false",超过指定的时间,这个元素就被移走了。timeToIdleSeconds是发呆时间,是可选的。当往缓存里面put的元素超过500个时,如果overflowToDisk="true",就会把缓存中的部分数据保存在硬盘上的临时文件里面。
每个需要缓存的class都要这样配置。如果你没有配置,hibernate会在启动的时候警告你,然后使用defaultCache的配置,这样多个class会共享一个配置。
当某个ID通过hibernate修改时,hibernate会知道,于是移除缓存。
这样大家可能会想,同样的查询条件,第一次先list,第二次再iterate,就可以使用到缓存了。实际上这是很难的,因为你无法判断什么时候是第一次,而且每次查询的条件通常是不一样的,假如数据库里面有100条记录,id从1到100,第一次list的时候出了前50个id,第二次iterate的时候却查询到30至70号id,那么30-50是从缓存里面取的,51到70是从数据库取的,共发送1+20条sql。所以我一直认为iterate没有什么用,总是会有1+N的问题。
(题外话:有说法说大型查询用list会把整个结果集装入内存,很慢,而iterate只select id比较好,但是大型查询总是要分页查的,谁也不会真的把整个结果集装进来,假如一页20条的话,iterate共需要执行21条语句,list虽然选择若干字段,比iterate第一条select id语句慢一些,但只有一条语句,不装入整个结果集hibernate还会根据数据库方言做优化,比如使用mysql的limit,整体看来应该还是list快。)
如果想要对list或者iterate查询的结果缓存,就要用到查询缓存了
查询缓存 首先需要配置hibernate.cache.use_query_cache=true
如果用ehcache,配置ehcache.xml,注意hibernate3.0以后不是net.sf的包名了
<cache name="net.sf.hibernate.cache.StandardQueryCache"
maxElementsInMemory="50" eternal="false" timeToIdleSeconds="3600"
timeToLiveSeconds="7200" overflowToDisk="true"/>
<cache name="net.sf.hibernate.cache.UpdateTimestampsCache"
maxElementsInMemory="5000" eternal="true" overflowToDisk="true"/>
然后
query.setCacheable(true);//激活查询缓存
query.setCacheRegion("myCacheRegion");//指定要使用的cacheRegion,可选
第二行指定要使用的cacheRegion是myCacheRegion,即你可以给每个查询缓存做一个单独的配置,使用setCacheRegion来做这个指定,需要在ehcache.xml里面配置它:
<cache name="myCacheRegion" maxElementsInMemory="10" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200" overflowToDisk="true" />
如果省略第二行,不设置cacheRegion的话,那么会使用上面提到的标准查询缓存的配置,也就是net.sf.hibernate.cache.StandardQueryCache
对于查询缓存来说,缓存的key是根据hql生成的sql,再加上参数,分页等信息(可以通过日志输出看到,不过它的输出不是很可读,最好改一下它的代码)。
比如hql:
from Cat c where c.name like ?
生成大致如下的sql:
select * from cat c where c.name like ?
参数是"tiger%",那么查询缓存的key*大约*是这样的字符串(我是凭记忆写的,并不精确,不过看了也该明白了):
select * from cat c where c.name like ? , parameter:tiger%
这样,保证了同样的查询、同样的参数等条件下具有一样的key。
现在说说缓存的value,如果是list方式的话,value在这里并不是整个结果集,而是查询出来的这一串ID。也就是说,不管是list方法还是iterate方法,第一次查询的时候,它们的查询方式很它们平时的方式是一样的,list执行一条sql,iterate执行1+N条,多出来的行为是它们填充了缓存。但是到同样条件第二次查询的时候,就都和iterate的行为一样了,根据缓存的key去缓存里面查到了value,value是一串id,然后在到class的缓存里面去一个一个的load出来。这样做是为了节约内存。
可以看出来,查询缓存需要打开相关类的class缓存。list和iterate方法第一次执行的时候,都是既填充查询缓存又填充class缓存的。
这里还有一个很容易被忽视的重要问题,即打开查询缓存以后,即使是list方法也可能遇到1+N的问题!相同条件第一次list的时候,因为查询缓存中找不到,不管class缓存是否存在数据,总是发送一条sql语句到数据库获取全部数据,然后填充查询缓存和class缓存。但是第二次执行的时候,问题就来了,如果你的class缓存的超时时间比较短,现在class缓存都超时了,但是查询缓存还在,那么list方法在获取id串以后,将会一个一个去数据库load!因此,class缓存的超时时间一定不能短于查询缓存设置的超时时间!如果还设置了发呆时间的话,保证class缓存的发呆时间也大于查询的缓存的生存时间。这里还有其他情况,比如class缓存被程序强制evict了,这种情况就请自己注意了。
另外,如果hql查询包含select字句,那么查询缓存里面的value就是整个结果集了。
当hibernate更新数据库的时候,它怎么知道更新哪些查询缓存呢?
hibernate在一个地方维护每个表的最后更新时间,其实也就是放在上面net.sf.hibernate.cache.UpdateTimestampsCache所指定的缓存配置里面。
当通过hibernate更新的时候,hibernate会知道这次更新影响了哪些表。然后它更新这些表的最后更新时间。每个缓存都有一个生成时间和这个缓存所查询的表,当hibernate查询一个缓存是否存在的时候,如果缓存存在,它还要取出缓存的生成时间和这个缓存所查询的表,然后去查找这些表的最后更新时间,如果有一个表在生成时间后更新过了,那么这个缓存是无效的。
可以看出,只要更新过一个表,那么凡是涉及到这个表的查询缓存就失效了,因此查询缓存的命中率可能会比较低。
Collection缓存 需要在hbm的collection里面设置
<cache usage="read-write"/>
假如class是Cat,collection叫children,那么ehcache里面配置
<cache name="com.xxx.pojo.Cat.children"
maxElementsInMemory="20" eternal="false" timeToIdleSeconds="3600" timeToLiveSeconds="7200"
overflowToDisk="true" />
Collection的缓存和前面查询缓存的list一样,也是只保持一串id,但它不会因为这个表更新过就失效,一个collection缓存仅在这个collection里面的元素有增删时才失效。
这样有一个问题,如果你的collection是根据某个字段排序的,当其中一个元素更新了该字段时,导致顺序改变时,collection缓存里面的顺序没有做更新。
缓存策略 只读缓存(read-only):没有什么好说的
读/写缓存(read-write):程序可能要的更新数据
不严格的读/写缓存(nonstrict-read-write):需要更新数据,但是两个事务更新同一条记录的可能性很小,性能比读写缓存好
事务缓存(transactional):缓存支持事务,发生异常的时候,缓存也能够回滚,只支持jta环境,这个我没有怎么研究过
读写缓存和不严格读写缓存在实现上的区别在于,读写缓存更新缓存的时候会把缓存里面的数据换成一个锁,其他事务如果去取相应的缓存数据,发现被锁住了,然后就直接取数据库查询。
在hibernate2.1的ehcache实现中,如果锁住部分缓存的事务发生了异常,那么缓存会一直被锁住,直到60秒后超时。
不严格读写缓存不锁定缓存中的数据。
使用二级缓存的前置条件 你的hibernate程序对数据库有独占的写访问权,其他的进程更新了数据库,hibernate是不可能知道的。你操作数据库必需直接通过hibernate,如果你调用存储过程,或者自己使用jdbc更新数据库,hibernate也是不知道的。hibernate3.0的大批量更新和删除是不更新二级缓存的,但是据说3.1已经解决了这个问题。
这个限制相当的棘手,有时候hibernate做批量更新、删除很慢,但是你却不能自己写jdbc来优化,很郁闷吧。
SessionFactory也提供了移除缓存的方法,你一定要自己写一些JDBC的话,可以调用这些方法移除缓存,这些方法是:
void evict(Class persistentClass)
Evict all entries from the second-level cache.
void evict(Class persistentClass, Serializable id)
Evict an entry from the second-level cache.
void evictCollection(String roleName)
Evict all entries from the second-level cache.
void evictCollection(String roleName, Serializable id)
Evict an entry from the second-level cache.
void evictQueries()
Evict any query result sets cached in the default query cache region.
void evictQueries(String cacheRegion)
Evict any query result sets cached in the named query cache region.
不过我不建议这样做,因为这样很难维护。比如你现在用JDBC批量更新了某个表,有3个查询缓存会用到这个表,用evictQueries(String cacheRegion)移除了3个查询缓存,然后用evict(Class persistentClass)移除了class缓存,看上去好像完整了。不过哪天你添加了一个相关查询缓存,可能会忘记更新这里的移除代码。如果你的jdbc代码到处都是,在你添加一个查询缓存的时候,还知道其他什么地方也要做相应的改动吗?
----------------------------------------------------
总结: 不要想当然的以为缓存一定能提高性能,仅仅在你能够驾驭它并且条件合适的情况下才是这样的。hibernate的二级缓存限制还是比较多的,不方便用jdbc可能会大大的降低更新性能。在不了解原理的情况下乱用,可能会有1+N的问题。不当的使用还可能导致读出脏数据。
如果受不了hibernate的诸多限制,那么还是自己在应用程序的层面上做缓存吧。
在越高的层面上做缓存,效果就会越好。就好像尽管磁盘有缓存,数据库还是要实现自己的缓存,尽管数据库有缓存,咱们的应用程序还是要做缓存。因为底层的缓存它并不知道高层要用这些数据干什么,只能做的比较通用,而高层可以有针对性的实现缓存,所以在更高的级别上做缓存,效果也要好些吧。
Ehcache中不仅可以用配置文件来配置缓存,而在代码中也可以实现同样的功能。
CacheManager singletonManager = CacheManager.create();
Cache memoryOnlyCache = new Cache(“testCache”, 50000, false, false, 8, 2);
Cache test = singletonManager.getCache(“testCache”);
删除只需要调用singletonManager.removeCache(“testCache”);
Shotdown CacheManager
在使用完Ehcache后,必须要shutdown缓存。Ehcache中有自己的关闭机制,不过最好在你的代码中显示调用CacheManager.getInstance().shutdown();
1.EhCache是什么
EhCache是Hibernate的二级缓存技术之一,可以把查询出来的数据存储在内存或者磁盘,节省下次同样查询语句再次查询数据库,大幅减轻数据库压力;
2.EhCache的使用注意点
当用Hibernate的方式修改表数据(save,update,delete等等),这时EhCache会自动把缓存中关于此表的所有缓存全部删除掉(这样能达到同步)。但对于数据经常修改的表来说,可能就失去缓存的意义了(不能减轻数据库压力);
3.EhCache使用的场合
3.1比较少更新表数据
EhCache一般要使用在比较少执行write操作的表(包括update,insert,delete等)[Hibernate的二级缓存也都是这样];
3.2对并发要求不是很严格的情况
两台机子中的缓存是不能实时同步的;
4.在项目做的实现
4.1在工程的src目录下添加ehcache.xml文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<diskStore path="java.io.tmpdir" />
<defaultCache maxElementsInMemory="5"<!--缓存可以存储的总记录量-->
eternal="false"<!--缓存是否永远不销毁-->
overflowToDisk="true"<!--当缓存中的数据达到最大值时,是否把缓存数据写入磁盘-->
timeToIdleSeconds="15"<!--当缓存闲置时间超过该值,则缓存自动销毁-->
timeToLiveSeconds="120"<!--缓存创建之后,到达该缓存自动销毁-->
/>
</ehcache>
4.2在Hibernate.cfg.xml中的mapping标签上面加以下内容:
<property name="show_sql">true</property>
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
<property name="hibernate.cache.use_query_cache">true</property>
4.3在要缓存的bean的hbm.xml文件中的class标签下加入以下内容:
<cache usage="read-only" /><!--也可读写-->
4.4创建DAO,内容如下:
Session s = HibernateSessionFactory.getSession();
Criteria c = s.createCriteria(Xyz.class);
c.setCacheable(true);//这句必须要有
System.out.println("第一次读取");
List l = c.list();
System.out.println(l.size());
HibernateSessionFactory.closeSession();
s = HibernateSessionFactory.getSession();
c = s.createCriteria(Xyz.class);
c.setCacheable(true);//这句必须要有
System.out.println("第二次读取");
l = c.list();
System.out.println(l.size());
HibernateSessionFactory.closeSession();
4.5这时你会看到打印出来的信息为(表示第二次并没有去读库):
第一次读取
Hibernate: *******
13
第二次读取
13
配置Spring+hibernate使用ehcache作为second-level cache
大量数据流动是web应用性能问题常见的原因,而缓存被广泛的用于优化数据库应用。cache被设计为通过保存从数据库里load的数据来减少应用和数据库之间的数据流动。数据库访问只有当检索的数据不在cache里可用时才必要。hibernate可以用两种不同的对象缓存:first-level cache 和 second-level cache。first-level cache和Session对象关联,而second-level cache是和Session Factory对象关联。
缺省地,hibernate已经使用基于每个事务的first-level cache。 Hibernate用first-level cache主要是减少在一个事务内的sql查询数量。例如,如果一个对象在同一个事务内被修改多次,hibernate将只生成一个包括所有修改的 UPDATE SQL语句。为了减少数据流动,second-level cache在Session Factory级的不同事务之间保持load的对象,这些对象对整个应用可用,不只是对当前用户正在运行的查询。这样,每次查询将返回已经load在缓存里的对象,避免一个或更多潜在的数据库事务。
下载ehcache,hibernate3.2必须要ehcache1.2以上才能支持。可以修改log4j配置文件log4j.logger.net.sf.hibernate.cache=debug查看日志
1.在类路径上ehcache.xml:
<ehcache>
<!-- Sets the path to the directory where cache .data files are created.
If the path is a Java System Property it is replaced by
its value in the running VM.
The following properties are translated:
user.home - User's home directory
user.dir - User's current working directory
java.io.tmpdir - Default temp file path -->
<diskStore path="java.io.tmpdir"/>
<!--Default Cache configuration. These will applied to caches programmatically created through
the CacheManager.
The following attributes are required:
maxElementsInMemory - Sets the maximum number of objects that will be created in memory
eternal - Sets whether elements are eternal. If eternal, timeouts are ignored and the
element is never expired.
overflowToDisk - Sets whether elements can overflow to disk when the in-memory cache
has reached the maxInMemory limit.
The following attributes are optional:
timeToIdleSeconds - Sets the time to idle for an element before it expires.
i.e. The maximum amount of time between accesses before an element expires
Is only used if the element is not eternal.
Optional attribute. A value of 0 means that an Element can idle for infinity.
The default value is 0.
timeToLiveSeconds - Sets the time to live for an element before it expires.
i.e. The maximum time between creation time and when an element expires.
Is only used if the element is not eternal.
Optional attribute. A value of 0 means that and Element can live for infinity.
The default value is 0.
diskPersistent - Whether the disk store persists between restarts of the Virtual Machine.
The default value is false.
diskExpiryThreadIntervalSeconds- The number of seconds between runs of the disk expiry thread. The default value
is 120 seconds.
-->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
overflowToDisk="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"/>
<!-- See http://ehcache.sourceforge.net/documentation/#mozTocId258426 for how to configure caching for your objects -->
</ehcache>
2.applicationContext-hibernate.xml里Hibernate SessionFactory配置:
<!-- Hibernate SessionFactory -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation"><value>classpath:hibernate.cfg.xml</value></property>
<!-- The property below is commented out b/c it doesn't work when run via
Ant in Eclipse. It works fine for individual JUnit tests and in IDEA ??
<property name="mappingJarLocations">
<list><value>file:dist/appfuse-dao.jar</value></list>
</property>
-->
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">@HIBERNATE-DIALECT@</prop>
<!--<prop key="hibernate.show_sql">true</prop>-->
<prop key="hibernate.max_fetch_depth">3</prop>
<prop key="hibernate.hibernate.use_outer_join">true</prop>
<prop key="hibernate.jdbc.batch_size">10</prop>
<prop key="hibernate.cache.use_query_cache">true</prop>
<prop key="hibernate.cache.use_second_level_cache">true</prop>
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</prop>
<!--
<prop key="hibernate.use_sql_comments">false</prop>
-->
<!-- Create/update the database tables automatically when the JVM starts up
<prop key="hibernate.hbm2ddl.auto">update</prop> -->
<!-- Turn batching off for better error messages under PostgreSQL
<prop key="hibernate.jdbc.batch_size">0</prop> -->
</props>
</property>
<property name="entityInterceptor">
<ref local="auditLogInterceptor"/>
</property>
</bean>
说明:如果不设置“查询缓存”,那么hibernate只会缓存使用load()方法获得的单个持久化对象,如果想缓存使用findall()、 list()、Iterator()、createCriteria()、createQuery()等方法获得的数据结果集的话,就需要设置 hibernate.cache.use_query_cache true 才行
3.model类里采用Xdoclet生成*.hbm.xml里的cache xml标签,即<cache usage="read-only"/>
/**
* @hibernate.class table="WF_WORKITEM_HIS"
* @hibernate.cache usage="read-write"
*
*/
4.对于"query cache",需要在程序里编码:
getHibernateTemplate().setCacheQueries(true);
return getHibernateTemplate().find(hql);
使用spring和hibernate配置ehcache和query cache
1、applicationContext.xml
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</prop>
<prop key="hibernate.cache.use_query_cache">true</prop>
这两句加到hibernateProperties中
<bean id="hibernateTemplate" class="org.springframework.orm.hibernate3.HibernateTemplate">
<property name="sessionFactory">
<ref bean="sessionFactory" />
</property>
<property name="cacheQueries">
<value>true</value>
</property>
</bean>
添加此bean到applicationcontext.xml中。在各个DAO的bean中,更改如下
<property name="sessionFactory">
<ref bean="sessionFactory" />
</property>
改为
<property name="hibernateTemplate">
<ref bean="hibernateTemplate" />
</property>
2、ehcache.xml文件放在classes根目录即可
3、pojo与ehcache.xml的配置关系
以com.ce.ceblog.pojos.CeblogJournal为例子
在CeblogJournal.hbm.xml中配置:
<class name="CeblogJournal" table="CEBLOG_JOURNAL" lazy="false">
<cache usage="read-write" region="ehcache.xml中的name的属性值"/>
注意:这一句需要紧跟在class标签下面,其他位置无效。
Ehcache.xml文件主体如下
<defaultCache maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="1" timeToLiveSeconds="1" overflowToDisk="true" />
<cache name="com.ce.ceblog.pojos.CeblogJournal" maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="300" timeToLiveSeconds="600" overflowToDisk="true" />
hbm文件查找cache方法名的策略:如果不指定hbm文件中的region="ehcache.xml中的name的属性值",则使用name名为 com.ce.ceblog.pojos.CeblogJournal的cache,如果不存在与类名匹配的cache名称,则用 defaultCache。
如果CeblogJournal包含set集合,则需要另行指定其cache
例如CeblogJournal包含ceblogReplySet集合,则需要
添加如下配置到ehcache.xml中
<cache name="com.ce.ceblog.pojos.CeblogJournal.ceblogReplySet"
maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="300"
timeToLiveSeconds="600" overflowToDisk="true" />
另,针对查询缓存的配置如下:
<cache name="org.hibernate.cache.UpdateTimestampsCache"
maxElementsInMemory="5000"
eternal="true"
overflowToDisk="true"/>
<cache name="org.hibernate.cache.StandardQueryCache"
maxElementsInMemory="10000"
eternal="false"
timeToLiveSeconds="120"
overflowToDisk="true"/>
4、选择缓存策略依据:
<cache usage="transactional|read-write|nonstrict-read-write|read-only" />
ehcache不支持transactional,其他三种可以支持。
read- only:无需修改, 那么就可以对其进行只读 缓存,注意,在此策略下,如果直接修改数据库,即使能够看到前台显示效果,但是将对象修改至cache中会报error,cache不会发生作用。另:删 除记录会报错,因为不能在read-only模式的对象从cache中删除。
read-write:需要更新数据,那么使用读/写缓存 比较合适,前提:数据库不可以为serializable transaction isolation level(序列化事务隔离级别)
nonstrict-read-write:只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情况很不常见),也不需要十分严格的事务隔离,那么比较适合使用非严格读/写缓存策略。
5、调试时候使用log4j的log4j.logger.org.hibernate.cache=debug,更方便看到ehcache的操作过程,主要用于调试过程,实际应用发布时候,请注释掉,以免影响性能。
6、 使用ehcache,打印sql语句是正常的,因为query cache设置为true将会创建两个缓存区域:一个用于保存查询结果集 (org.hibernate.cache.StandardQueryCache);另一个则用于保存最近查询的一系列表的时间戳(org.hibernate.cache.UpdateTimestampsCache)。请注意:在查询缓存中,它并不缓存结果集中所包含的实体的确切状态;它只缓存这些实体的标识符属性的值、以及各值类型的结果。需要将打印sql语句与最近的cache内容相比较,将不同之处修改到cache中,所以查询缓存通常会和二级缓存一起使用。