JSF 是一个页面开发能力极强的技术,又拥有大量的扩展。同时 JSF 提供了一定的 IoC 能力,如果再集成 Spring 强大的 IoC 能力,将会给我们带来更多的方便(其实我是喜欢用 Spring 集成 Hibernate 的 ORM 能力和 Spring 的事物管理 ^_^)。
Spring 本身已经提供了集成 JSF 的能力,只要在 JSF 的 配置文件中增加一个 resolver 就可以了,具体如下:
<faces-config>
<application>
<message-bundle>resources.application</message-bundle>
<locale-config>
<default-locale>zh_CN</default-locale>
</locale-config>
<variable-resolver>
org.springframework.web.jsf.DelegatingVariableResolver
</variable-resolver>
</application>
...
</faces-config>
posted @
2006-04-23 09:16 哈哈的日子 阅读(1897) |
评论 (0) |
编辑 收藏 本文对Java规则引擎与其API(JSR-94)及相关实现做了较详细的介绍,对其体系结构和API应用有较详尽的描述,并指出Java规则引擎,规则语言,JSR-94的相互关系,以及JSR-94的不足之处和展望。
复杂企业级项目的开发以及其中随外部条件不断变化的业务规则(business logic),迫切需要分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时(即商务时间)可以动态地管理和修改从而提供软件系统的柔性和适应性。规则引擎正是应用于上述动态环境中的一种解决方法。
本文第一部分简要介绍了规则引擎的产生背景和基于规则的专家系统,第二部分介绍了什么是规则引擎及其架构和算法,第三部分介绍了商业产品和开源项目实现等各种Java规则引擎,第四部分对Java规则引擎API(JSR-94)作了详细介绍,讲解了其体系结构,管理API和运行时API及相关安全问题,第五部分则对规则语言及其标准化作了探讨,第六部分给出了一个使用Java规则引擎API的简单示例,第七部分给予小结和展望。
1、 介绍
1.1 规则引擎产生背景
企业管理者对企业级IT系统的开发有着如下的要求:(1)为提高效率,管理流程必须自动化,即使现代商业规则异常复杂(2)市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新(3)为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。
而项目开发人员则碰到了以下问题:(1)程序=算法+数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型(2)软件工程要求从需求->设计->编码,然而业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化,业务规则往往嵌在系统各处代码中(3)对程序员来说,系统已经维护、更新困难,更不可能让业务人员来管理。
基于规则的专家系统的出现给开发人员以解决问题的契机。规则引擎由基于规则的专家系统中的推理引擎发展而来。下面简要介绍一下基于规则的专家系统。
1.2 基于规则的专家系统(RBES)
专家系统是人工智能的一个分支,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。专家系统有很多分类:神经网络、基于案例推理和基于规则系统等。
RBES包括三部分:Rule Base(knowledge base)、Working Memory(fact base)和Inference Engine(推理引擎)。它们的结构如下所示:
图1.基于规则的专家系统组成
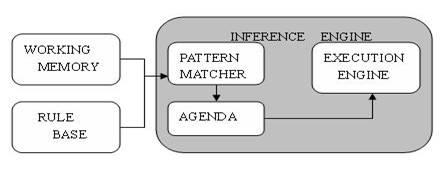
如上图所示,推理引擎包括三部分:Pattern Matcher、Agenda和Execution Engine。Pattern Matcher何时执行哪个规则;Agenda管理PatternMatcher挑选出来的规则的执行次序;Execution Engine负责执行规则和其他动作。
推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。存在两者推理方式:演绎法(Forward-Chaining正向链)和归纳法(Backward-Chaining反向链)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是从假设出发,不断地寻找符合假设的事实。
2、 规则引擎
2.1 业务规则
一个业务规则包含一组条件和在此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。
2.2 规则引擎
什么是规则引擎?规则引擎是如何执行规则的?这可以称之为"什么"与"如何"的问题。到底规则引擎是什么还是目前业界一个比较有争议的问题,在JSR-94种也几乎没有定义。可以这样认为充分定义和解决了"如何"的问题,"什么"问题本质上也迎刃而解。也许这又是一种"先有蛋还是先有鸡"哲学争论。今后标准规则语言的定义和推出及相关标准的制定应该可以给这样的问题和争论划上一个句号。本文中,暂且这样述说什么是规则引擎:规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据规则做出业务决策。
2.3 规则引擎的使用方式
由于规则引擎是软件组件,所以只有开发人员才能够通过程序接口的方式来使用和控制它,规则引擎的程序接口至少包含以下几种API:加载和卸载规则集的API;数据操作的API;引擎执行的API。开发人员在程序中使用规则引擎基本遵循以下5个典型的步骤:创建规则引擎对象;向引擎中加载规则集或更换规则集;向引擎提交需要被规则集处理的数据对象集合;命令引擎执行;导出引擎执行结果,从引擎中撤出处理过的数据。使用了规则引擎之后,许多涉及业务逻辑的程序代码基本被这五个典型步骤所取代。
一个开放的业务规则引擎应该可以"嵌入"在应用程序的任何位置,不同位置的规则引擎可以使用不同的规则集,用于处理不同的数据对象。此外,对使用引擎的数量没有限制。
2.4 规则引擎架构与推理
规则引擎的架构如下图所示:
图2. 业务规则引擎架构
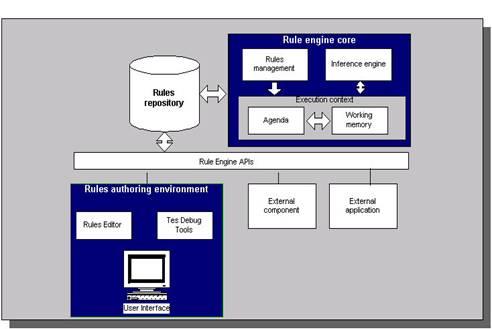
规则引擎的推理步骤如下:a. 将初始数据(fact)输入至工作内存(Working Memory)。b. 使用Pattern Matcher将规则库(Rules repository)中的规则(rule)和数据(fact)比较。c. 如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。d. 解决冲突,将激活的规则按顺序放入Agenda。e. 执行Agenda中的规则。重复步骤b至e,直到执行完毕Agenda中的所有规则。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种"动态"的规则执行链,形成规则的推理机制。这种规则的"链式"反应完全是由工作区中的数据驱动的。
规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基·梅隆大学的Charles L. Forgy发明了一种叫Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用Rete算法。
2.5 规则引擎的算法
大部分规则引擎产品的算法,基本上都来自于Dr. Charles Forgy在1979年提出的RETE算法及其变体,Rete算法是目前效率最高的一个Forward-Chaining推理算法,Drools项目是Rete算法的一个面向对象的Java实现,Rete算法其核心思想是将分离的匹配项根据内容动态构造匹配树,以达到显著降低计算量的效果。
3、 Java规则引擎
目前主流的规则引擎组件多是基于Java和C++程序语言环境,已经有多种Java规则引擎商业产品与开源项目的实现,其中有的已经支持JSR94,有的正朝这个方向做出努力,列出如下:
3.1 Java规则引擎商业产品
Java规则引擎商业产品主要有(Jess不是开源项目,它可以免费用于学术研究,但用于商业用途则要收费):

3.2 Java规则引擎开源项目
开源项目的实现主要包括:
Drools - Drools规则引擎应用Rete算法的改进形式Rete-II算法。从内部机制上讲,它使用了和Forgy的算法相同的概念和方法,但是增加了可与面向对象语言无缝连接的节点类型。
Mandarax 基于反向推理(归纳法)。能够较容易地实现多个数据源的集成。例如,数据库记录能方便地集成为事实集(facts sets),reflection用来集成对象模型中的功能。目前不支持JSR 94
OFBiz Rule Engine - 支持归纳法(Backward chaining).最初代码基于Steven John Metsker的"Building Parsers in Java",不支持JSR 94
JLisa - JLisa是用来构建业务规则的强大框架,它有着扩展了LISP优秀特色的优点,比Clips还要强大.这些特色对于多范例软件的开发是至关重要的.支持JSR 94
其它的开源项目实现有诸如Algernon, TyRuBa, JTP, JEOPS, InfoSapient, RDFExpert, Jena 2, Euler, JLog, Pellet OWL Reasoner, Prova, OpenRules, SweetRules, JShop2等等。
4、 Java规则引擎API(JSR-94)
4.1 简介
过去大部分的规则引擎开发并没有规范化,有其自有的API,这使得其与外部程序交互集成不够灵活。转而使用另外一种产品时往往意味需要重写应用程序逻辑和API调用,代价较大。规则引擎工业中标准的缺乏成为令人关注的重要方面。2003年11月定稿并于2004年8月最终发布的JSR 94(Java规则引擎API)使得Java规则引擎的实现得以标准化。
Java规则引擎API由javax.rules包定义,是访问规则引擎的标准企业级API。Java规则引擎API允许客户程序使用统一的方式和不同厂商的规则引擎产品交互,就像使用JDBC编写独立于厂商访问不同的数据库产品一样。Java规则引擎API包括创建和管理规则集合的机制,在Working Memory中添加,删除和修改对象的机制,以及初始化,重置和执行规则引擎的机制。
4.2 简介Java规则引擎API体系结构
Java规则引擎API分为两个主要部分:运行时客户API(the Runtime client API)和规则管理API(the rules administration API)。
4.2.1规则管理API
规则管理API在javax.rules.admin中定义,包括装载规则以及与规则对应的动作(执行集 execution sets)以及实例化规则引擎。规则可以从外部资源中装载,比如说URI,Input streams, XML streams和readers等等.同时管理API提供了注册和取消注册执行集以及对执行集进行维护的机制。使用admin包定义规则有助于对客户访问运行规则进行控制管理,它通过在执行集上定义许可权使得未经授权的用户无法访问受控规则。
管理API使用类RuleServiceProvider来获得规则管理(RuleAdministrator)接口的实例.规则管理接口提供方法注册和取消注册执行集.规则管理器(RuleAdministrator)提供了本地和远程的RuleExecutionSetProvider.在前面已提及,RuleExecutionSetProvider负责创建规则执行集.规则执行集可以从如XML streams, input streams等来源中创建.这些数据来源及其内容经汇集和序列化后传送到远程的运行规则引擎的服务器上.大多数应用程序中,远程规则引擎或远程规则数据来源的情况并不多见.为了避免这些情况中的网络开销,API规定了可以从运行在同一JVM中规则库中读取数据的本地RuleExecutionSetProvider.
规则执行集接口除了拥有能够获得有关规则执行集的方法,还有能够检索在规则执行集中定义的所有规则对象.这使得客户能够知道规则集中的规则对象并且按照自己需要来使用它们。
4.2.2 运行时API
运行时API定义在javax.rules包中,为规则引擎用户运行规则获得结果提供了类和方法。运行时客户只能访问那些使用规则管理API注册过的规则,运行时API帮助用户获得规则对话并且在这个对话中执行规则。
运行时API提供了对厂商规则引擎API实现的类似于JDBC的访问方法.规则引擎厂商通过类RuleServiceProvider(类RuleServiceProvider提供了对具体规则引擎实现的运行时和管理API的访问)将其规则引擎实现提供给客户,并获得RuleServiceProvider唯一标识规则引擎的URL.
URL推荐标准用法是使用类似"com.mycompany.myrulesengine.rules.RuleServiceProvider"这样的Internet域名空间,这将有助于访问URL的唯一性.类RuleServiceProvider内部实现了规则管理和运行时访问所需的接口.所有的RuleServiceProvider要想被客户所访问都必须用RuleServiceProviderManager进行注册。注册方式类似于JDBC API的DriverManager和Driver。
运行时接口是运行时API的关键部分.运行时接口提供了用于创建规则会话(RuleSession)的方法,规则会话如前所述是用来运行规则的.运行时API同时也提供了访问在service provider注册过的所有规则执行集(RuleExecutionSets).规则会话接口定义了客户使用的会话的类型,客户根据自己运行规则的方式可以选择使用有状态会话或者无状态会话。
无状态会话的工作方式就像一个无状态会话bean.客户可以发送单个输入对象或一列对象来获得输出对象.当客户需要一个与规则引擎间的专用会话时,有状态会话就很有用.输入的对象通过addObject() 方法可以加入到会话当中.同一个会话当中可以加入多个对象.对话中已有对象可以通过使用updateObject()方法得到更新.只要客户与规则引擎间的会话依然存在,会话中的对象就不会丢失。
RuleExecutionSetMetaData接口提供给客户让其查找规则执行集的元数据(metadata).元数据通过规则会话接口(RuleSession Interface)提供给用户。
使用运行时Runtime API的代码片断如下所示:
RuleServiceProvider ruleProvider = RuleServiceProviderManager.getRuleServiceProvider
("com.mycompany.myrulesengine.rules. RuleServiceProvider");
RuleRuntime ruleRuntime = ruleProvider.getRuleRuntime();
StatelessRuleSession ruleSession = (StatelessRuleSession)ruleRuntime.createRuleSession(ruleURL,
null, RuleRuntime.STTELESS_SESSION_TYPE);
List inputRules = new ArrayList();
inputRules.add(new String("Rule 1"));
inputRules.add(new Integer(1));
List resultRules = ruleSession.executeRules(inputRules);
|
4.3 Java规则引擎API安全问题
规则引擎API将管理API和运行时API加以分开,从而为这些包提供了较好粒度的安全控制.规则引擎API并没有提供明显的安全机制,它可以和J2EE规范中定义的标准安全API联合使用.安全可以由以下机制提供,如Java authentication and authorization service (JAAS),the Java cryptography extension (JCE),Java secure Socket Extension (JSSE),或者其它定制的安全API.JAAS能被用来定义规则执行集的许可权限,从而只有授权用户才能访问。
4.4 异常与日志
规则引擎API定义了javax.rules.RuleException作为规则引擎异常层次的根类.所有其它异常都继承于这个根类.规则引擎中定义的异常都是受控制的异常(checked exceptions),所以捕获异常的任务就交给了规则引擎。规则引擎API没有提供明确的日志机制,但是它建议将Java Logging API用于规则引擎API。
4.5 JSR 94 小结
JSR 94 为规则引擎提供了公用标准API,仅仅为实现规则管理API和运行时API提供了指导规范,并没有提供规则和动作该如何定义以及该用什么语言定义规则,也没有为规则引擎如何读和评价规则提供技术性指导.JSR 94规范将上述问题留给了规则引擎的厂商.在下一节我将简要介绍一下规则语言。
5、 规则语言 JSR 94中没有涉及用来创建规则和动作的语言.规则语言是规则引擎应用程序的重要组成部分,所有的业务规则都必须用某种语言定义并且存储于规则执行集中,从而规则引擎可以装载和处理他们。
由于没有关于规则如何定义的公用规范,市场上大多数流行的规则引擎都有其自己的规则语言,目前便有许多种规则语言正在应用,因此,当需要将应用移植到其他的Java规则引擎实现时,可能需要变换规则定义,如将Drools私有的DRL规则语言转换成标准的ruleML,Jess规则语言转换成ruleML等。这个工作一般由XSLT转换器来完成。
规则语言的详情这里不作详细介绍,名称及其网址列出如下:
Rule Markup language (RuleML)
http://www.ruleml.org/ Simple Rule Markup Language (SRML)
http://xml.coverpages.org/srml.html Business Rules Markup Language (BRML)
http://xml.coverpages.org/brml.html SWRL: A Semantic Web Rule Language Combining OWL and RuleML
http://www.daml.org/2003/11/swrl/
多种规则语言的使用使得不同规则引擎实现之间的兼容性成为问题.通用的规则引擎API或许可以减轻不同厂家API之间的问题,但公用规则语言的缺乏将仍然阻碍不同规则引擎实现之间的互操作性.尽管业界在提出公用规则语言上做出了一些努力, 比如说RuleML,SRML的出现,但距离获得绝大部分规则引擎厂商同意的公用标准还有很长的路要走。
6、 Java规则引擎API使用示例
6.1 设置规则引擎
Java规则引擎的管理活动阶段开始于查找一个合适的javax.rules.RuleServiceProvider对象,这个对象是应用程序访问规则引擎的入口。在J2EE环境中,你可能可以通过JNDI获得RuleServiceProvider。否则,你可以使用javax.rules.RuleServiceProviderManager类:
javax.rules.RuleServiceProviderManager class:
String implName = "org.jcp.jsr94.ri.RuleServiceProvider";
Class.forName(implName);
RuleServiceProvider serviceProvider = RuleServiceProviderManager.getRuleServiceProvider(implName); |
拥有了RuleServiceProvider对象,你就可以获得一个javax.rules.admin.RuleAdministrator类。从RuleAdministrator类中,你可以得到一个RuleExecutionSetProvider,从类名可以知道,它用于创建javax.rules.RuleExecutionSets对象。RuleExecutionSet基本上是一个装入内存的,准备好执行的规则集合。
包javax.rules.admin包括两个不同的RuleExecutionSetProvider类。RuleExecutionSetProvider类本身包括了从Serializable对象创建RuleExecutionSets的方法,因此在规则引擎位于远程服务器的情况下,仍然可以使用RuleExecutionSetProvider类,构造器的参数可以通过RMI来传递。另一个类是LocalRuleExecutionSetProvider,包含了其他方法,用于从非Serializable资源(如java.io.Reader-本地文件)创建RuleExectionSets。假设拥有了一个RuleServiceProvider对象,你可以从本地文件rules.xml文件创建一个RuleExectionSet对象。如以下的代码所示:
RuleAdministrator admin = serviceProvider.getRuleAdministrator();
HashMap properties = new HashMap();
properties.put("name", "My Rules");
properties.put("description", "A trivial rulebase");
FileReader reader = new FileReader("rules.xml");
RuleExecutionSet ruleSet = null;
try {
LocalRuleExecutionSetProvider lresp =admin.getLocalRuleExecutionSetProvider(properties);
ruleSet = lresp.createRuleExecutionSet(reader, properties);
} finally {
reader.close();
} |
接下来,你可以使用RuleAdministrator注册获得的RuleExecutionSet,并给它分配一个名称。在运行时,你可以用同一个名称创建一个RuleSession;该RuleSession使用了这个命名的RuleExecutionSet。参见下面的用法:admin.registerRuleExecutionSet("rules", ruleSet, properties);
6.2 执行规则引擎
在运行时阶段,你可以参见一个RuleSession对象。RuleSession对象基本上是一个装载了特定规则集合的规则引擎实例。你从RuleServiceProvider得到一个RuleRuntime对象,接下来,从javax.rules.RuleRuntime得到RuleSession对象。
RuleSession分为两类:stateful和stateless。它们具有不同的功能。StatefulRuleSession的Working Memory能够在多个方法调用期间保存状态。你可以在多个方法调用期间在Working Memory中加入多个对象,然后执行引擎,接下来还可以加入更多的对象并再次执行引擎。相反,StatelessRuleSession类是不保存状态的,为了执行它的executeRules方法,你必须为Working Memory提供所有的初始数据,执行规则引擎,得到一个内容列表作为返回值。
下面的例子中,我们创建一个StatefulRuleSession实例,添加两个对象(一个Integer和一个String)到Working Memory,执行规则,然后得到Working Memory中所有的内容,作为java.util.List对象返回。最后,我们调用release方法清理RuleSession:
RuleRuntime runtime = rsp.getRuleRuntime();
StatefulRuleSession session = (StatefulRuleSession)runtime.createRuleSession("rules",
properties,RuleRuntime.STATEFUL_SESSION_TYPE);
session.addObject(new Integer(1));
session.addObject("A string");
session.executeRules();
List results = session.getObjects();
session.release(); |
7、 结束语 Java规则引擎API(JSR-94)允许客户程序使用统一的方式和不同厂商的规则引擎产品交互,一定程度上给规则引擎厂商提供了标准化规范。但其几乎没有定义什么是规则引擎,当然也没有深入到规则是如何构建和操纵的,规则调用的效用,规则与Java语言的绑定等方面。并且JSR-94在对J2EE的支持上也不足。规则语言的标准化,JSR-94的进一步的充实深化都有待研究。
转载自
http://www.javajia.com/modules.php?op=modload&name=News&file=article&sid=1545&mode=thread&order=0&thold=0
posted @
2006-03-29 22:43 哈哈的日子 阅读(568) |
评论 (0) |
编辑 收藏
业务规则管理系统的基本原理是:用一个或多个规则引擎替换以程序代码“固化”在应用系统中的业务逻辑。一个完善的BRMS可以对业务规则的整个生命周期实现全程管理。
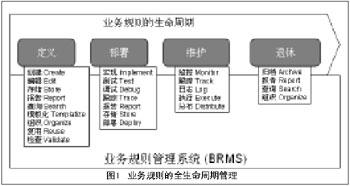
业务规则的全生命周期管理如图1所示。BRMS在应用系统中的地位与数据库管理系统(DBMS)类似,处于比较基础的位置,是其他高端应用的基石。图2是GIGA Information Group 给出的IT架构中BRMS的位置图。
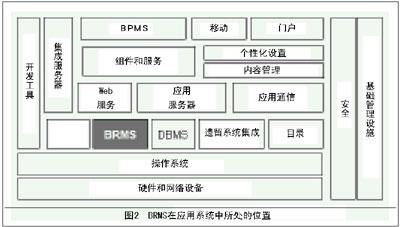
业务规则管理如何实现?
业务规则
一个业务规则包含一组条件和在此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。
规则引擎
这是一种嵌入在应用程序中的组件,它的任务是把当前提交给引擎的数据对象与加载在引擎中的业务规则进行测试和比对,激活那些符合当前数据状态下的业务规则,根据业务规则中声明的执行逻辑,触发应用程序中对应的操作。
目前主流的规则引擎组件多是基于Java和C++程序语言环境。在2000年11月,Java Community Process(简称JCP) 组织开始着手起草Java规则引擎的API标准,即JSR 94 规范。参与JSR 94起草的有BEA、IBM、ILOG、甲骨文、Novell、ATG、Unisys、Fujitsu等著名的软件企业。JSR 94 在2003年11月25日正式定稿,支持JSR 94标准的规则引擎也几乎同时推向市场,包括ILOG 的JRules和Blaze的Advisor。
规则引擎的使用方式
由于规则引擎是软件组件,所以只有开发人员才能够通过程序接口的方式来使用和控制它,规则引擎的程序接口至少包含以下几种API:加载和卸载规则集的API;数据操作的API;引擎执行的API。开发人员在程序中使用规则引擎基本遵循以下5个典型的步骤:创建规则引擎对象;向引擎中加载规则集或更换规则集;向引擎提交需要被规则集处理的数据对象集合;命令引擎执行;导出引擎执行结果,从引擎中撤出处理过的数据。使用了规则引擎之后,许多涉及业务逻辑的程序代码基本被这五个典型步骤所取代。
一个开放的业务规则引擎应该可以“嵌入”在应用程序的任何位置,不同位置的规则引擎可以使用不同的规则集,用于处理不同的数据对象。此外,对使用引擎的数量没有限制。
规则引擎的内部实现
规则引擎的基本机制是:对提交给引擎的数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般,规则引擎内部由下面几个部分构成:工作内存,用于存放被引擎引用的数据对象集合;规则执行队列,用于存放被激活的规则执行实例;静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。规则引擎的结构示意图如图3所示。
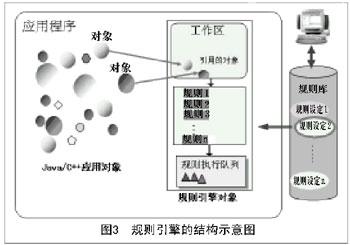
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种“动态”的规则执行链,形成规则的推理机制。这种规则的“链式”反应完全是由工作区中的数据驱动的。
规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基·梅隆大学的Charles L. Forgy发明了一种叫Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用Rete算法。
BOM赋予规则行业特性
业务规则一定是针对某种业务的,不同的业务有自己特有的业务模型——业务对象模型(Business Object Mode,简称BOM)。BOM为业务规则语言提供了绝大多数的词汇,多由业务系统分析员设计,由开发人员具体实现。从面向对象的编程角度来看,BOM就是一个简化的类图,类图中有类名、类的属性、类的方法等。这些要素都将是业务规则语言中的基本“词汇”。BOM的来源可以是Java对象模型、C++对象模型、XML Schema、Web服务定义等。
假定我们有一个简单的宠物商店购物车应用程序,在这个应用程序中,顾客能够在购物车中放入各种宠物和相关物品对象。这个应用程序的业务对象集合就可以有ShoppingCart(购物车)、Customer(用户)、Item (条目)和ItemType(条目类型)这几个类。
表述业务规则的语法就是业务规则语言。由于规则语言的使用者主要有两类:业务人员和技术人员,所以规则语言一般也分为两类:“面向程序技术”的规则语言,它技术性很强,可读性较弱,比较适合IT 技术人员使用,一般每个规则引擎开发商都有自己的一套“面向程序技术”的规则语言语法,不过OASIS组织定义了不同应用情况下的规则语言规范,包括SRML(Simple Rule Markup Language),BMRL(Business Markup Rule Language)和RuleML(Rule Markup Language)等;“面向业务”的规则语言,它是业务人员使用的语言,必须具备非技术性和可定制性,通常它需要经过“翻译”之后才能被规则引擎解析。BRMS必须提供这种“翻译”机制,而开发人员要实现从“面向业务”规则语言到“面向程序”规则语言的映射。
“面向业务”的规则语言无论从语法上还是语句结构上都可能千变万化,不同行业可能有自己的“行话”。一个好的BRMS应该提供一个完善的规则语言框架,能够迅速地为业务人员定制不同的“行话”,否则业务人员还是无法真正成为业务规则的主人。
“单纯”的规则如何互连?
业务规则有一个非常明显的特性:单纯性。每个业务规则只描述自己特有的条件和满足条件的操作,业务规则本身并不关心它与其他规则的关系,如优先关系、互斥关系、包含关系等。每个业务规则本身可以有自己的属性,称元信息,可以用来处理规则之间相关性,例如引擎可以使用规则的优先级来依序执行规则的操作。
有些BRMS还提供一种称为“规则流”的定制功能。规则流是一个图表,定义了解决问题或执行业务流程的顺序。类似于统一建模语言(UML)的活动图,由一组任务以及定义这些任务之间执行顺序的转换逻辑组成。一个转换由条件控制,只有当该限制条件为“真”时才能完成这种转换。
这些任务可以是规则任务、函数任务或子规则流任务。规则任务包含一组要作为任务主体执行的规则,规则的执行逻辑由用户设置的任务属性严格控制。这些属性决定规则的排序、规则触发策略、执行算法等;函数任务包含要作为任务主体执行的脚本代码;子规则流任务则包含任务开始后将依次执行的子规则流。
为了方便开发人员和业务人员管理业务规则,BRMS必须提供具有直观用户界面的工具来实现业务规则管理。规则管理工具至少应该具备以下功能:规则的定制和编辑、规则流的定制、决策表形式的规则定制、规则的查询、规则有效期限的控制、规则的组织结构、规则模板的定制、规则库访问权限的控制、规则变更历史的记录、规则文档的管理等。
·小资料2·
业务规则管理系统其实是一组工具集,它包括:规则引擎、规则库、规则语言框架、规则管理集成开发环境。业务规则管理系统的基本工作原理如图所示。
规则引擎(Rules Engine)
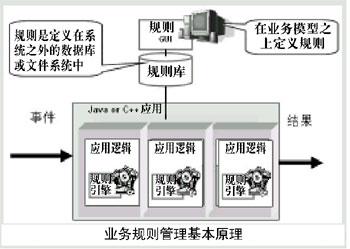
是执行业务规则的软件组件,它嵌入在程序中,是业务规则管理系统的核心元素。规则引擎的类型有:简单型、数据中心型和面向事务型。
规则库(Rules Repository)及其服务机制
用于存储规则和规则元数据(Meta Data)以及与规则有关的属性。它提供一组工具用于存储、分类、查询、版本控制、权限控制、测试、提交等,规则的状态和有效性可以跟踪。规则库可以依托文件系统或数据库管理系统。
规则语言框架(Rules Language Framework)
规则语言一般分为两类:“面向程序技术”的规则语言,使用者是技术人员;“面向业务”的规则语言,使用者是业务人员。规则语言框架则为定制“面向业务”的规则语言提供支持。
规则管理工具(Rules Management Tool)
用于管理、创建、修改和部署业务规则的图形化工具,易用性强,除了开发人员外,业务人员也可以使用这套图形化工具实现对规则的管理。
规则集成开发环境(Rules IDE)
一般规则集成开发环境只有规则编辑器,而高级的规则集成开发环境可以实现对规则和规则库的管理:如规则的创建、分类、检索、修改、版本控制、权限管理等;甚至可以实现对多个规则引擎的“在线”调试;对规则集合进行冲突检查等。
一个完整的BRMS应该提供规则管理(Rules Management)、规则部署(ules Deployment)、规则分析(Rules Analysis)、规则定制和设计(Rules Design and Authoring)等功能。
(计算机世界报 第14期 B6、B7)
posted @
2006-03-26 19:11 哈哈的日子 阅读(1427) |
评论 (0) |
编辑 收藏
Maven 在第一次运行的时候会在网上下载一些 plugin ,可是找了好久都找不到在什么位置。
而且我在安装的 maven 中运行,下载了一次,在 maven 的 eclipse plugin 中运行又下载了一次,很是奇怪。
寻找解决方法中……
找到原因了,%MAVEN_HOME%/conf/settings.xml 文件中写了位置,如下:
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ~/.m2/repository
<localRepository>/path/to/local/repo</localRepository>
-->
因为对 maven 机制不熟悉,没注意到这个。
默认存放的位置是你的 Document and Settings 下面用户目录的 .m2/repository 这个目录下。
也可以在这个地方配置。
另外一个就是 maven 可以在 settings.xml 文件中配置代理服务器,以方便访问 internet ,我在公司的时候就需要配置代理服务器才行。
但是,现在还是不知道为什么要下载这么多的 plugin
posted @
2006-03-16 23:29 哈哈的日子 阅读(3534) |
评论 (2) |
编辑 收藏
性能的区别我觉得主要在 View 这一层上。
Struts 将 JavaBean 转至 JSP 页面,来处理页面显示,比较直接,而 Struts 本身也是关注的是 MVC 的分离,在页面处理方面并没有给予过多的关注。直接的显示让 Struts 在 View 层的性能有比较好的表现。
而 JSF 在 View 这一层:一、需要维护组件树的状态。二、需要使用渲染器来将组件渲染。性能就会比 Struts 差一些。
从生命周期的角度上来看
Struts 请求的基本周期是。经过 front servlet 的请求分发,然后生成 command 对象,由 action 调用 Model 直至转向 View。
JSF 的基本周期是,经过 front servlet 请求分发(这一步同 struts),然后 restore view , apply request value, process validations , update model 这些生命周期相当于 struts 生成 command 对象阶段,invoke application 相当于调用 model ,render response 相当于转向 view 阶段。
对比来看,请求分发阶段不会产生更多的性能差异,然后对比其它阶段
struts 生成 command 对象阶段包含 conversion 和部分 validation ,相当于 JSF 的 apply request value 和 process validations 阶段,但 JSF 还需要 restore view 和 update model(保持 Managed Bean 的状态),性能会差一点,但要补充的是 restore view 在 myfaces 的实现中,会将 view 对象放在客户端保存(好象可以配置不保存),下一次请求如果有 view 对象,会直接反序列化得到 view root ,相当于在客户端 cache了,而 update model 只会在部分与数据相关的组件会使用。最后的 invoke application 与 struts 的调用 action ,然后 lifecycle 中的 render response 阶段会找到对应的 view 并转向,然后由页面的 tag 调用 render 来渲染出页面。最后调用 tag 渲染页面阶段相当于 struts 的前台显示,但由于更大粒度和更精细的渲染,在这个阶段会与 struts 有一定的性能差。
总体来说,JSF 使用了大量的 cache 手段,尽量减少一些性能开销,但比 struts 增强的 backing bean 管理、事件处理能力和丰富的组件能力会让 JSF 在生命周期性能上比 struts 略逊一筹。
但这并不是所有的应用场景性能上都要比 struts 差,比如:同样是后台数据验证的情况下,JSF 在验证错误时立即会返回用户页面,而没有经验其它生命周期,可 struts 还是一样会走完全部生命周期,这种情况 JSF 就会达到比 struts 更好的性能。
瑕不掩瑜,性能上部分的劣势并不能掩盖 JSF 强大的功能和为我们省下的大量的时间,我相信 JSF 肯定会在将来的开发中得到更多开发者的青睐。
posted @
2006-03-07 23:22 哈哈的日子 阅读(2302) |
评论 (1) |
编辑 收藏
知道java,是因为我有个傻瓜老公,他会这个。
几天前,他告诉我买了个网址(不要挑剔我的用词,外行不是我一个人的错),把他的blog连到那上面去。看他天天回家就“抱”着电脑,嘴角还傻傻地向上翘,我就纳闷呀,blog我也知道,不就是一些闷骚的人说一些感性在先理性在后的话吗?至于置我这个“掌门”于不顾吗?趁他起身如厕之际,我急忙跑到电脑前,探个究竟。
BlogJava?
就是这个东东呀!
恍然大悟,然后挠头,累不累呀!
他在华为做研发,每天就用这个什么Java干活。华为那个可憎的XX公司,老总是个典型的资本家,天天要加班到很晚(九、十点钟是正常),而且每四个星期还要有一个星期六义务奉献。动辄罚款降薪,而且还要连带你的上司一同受惩!置《劳动法》于不顾,大大的坏!!可是为什么这样的辛苦,休息的时候还弄这个鬼鬼Java呀?哎呀,男人心,海底针呀!
我就在这个Blog上逛了逛,哦,这样的人还真不少啊!难怪这家伙像看到亲人了似的。
呵,呵呵,简单的浏览之后,我确定这里有多个我老公的copy版。每天起来做的第一件事就是打开信箱收发邮件;电脑桌面要简单,源文件里密密麻麻的才叫“眩”;上厕所双击开关,坐在马桶上用《程序员》来打发时间。
不过我现在不会再抱怨了,虽然他依然听不见我的问话,即使我站在电脑旁边。我知道这是他唯一的心血,唯一的爱好,唯一的执着,唯一的事业,那么,我为什么不支持呢?
现在的我还是不懂得什么是Java,但是我骄傲,因为老公是个出色的“程序员”。他不理我并不是我的魅力不及电脑,不然怎么会把所有的薪水花在我这边?没有时间理我,算了。因为我也没有那么多时间,我要收拾房间,搞好个人和“他”人卫生,还要花大量时间研究营养学,都说长久用电脑的人要多多补充的!
祝愿所有用Java赚钱的人身体健康,一生平安!
posted @
2006-03-03 10:33 哈哈的日子 阅读(1262) |
评论 (17) |
编辑 收藏
仅仅是跑了 myfaces 的 example ,我已经被 JSF 的强大所打动。
myfaces 对 JSF 的 component 有着非常多的扩展,其中主要有 dataTable 、navigation 和 tree 。
其中比较吸引人的还有 js listener、panelTable 等一些很
“眩”的特性。
JSF+AJAX 肯定是既能提高用户体验又能大大降低开发维护难度的一个很好的中间点。
在集成 AJAX 方面 ajaxanywhere 可以很容易的和 JSF 集成起来,效果也非常不错。是一个主要的研究方向,其它的尝试并不多,试了一下 DWR ,效果很不好,基本放弃。
推荐一篇文章
http://wiki.apache.org/myfaces/Integrating_Ajaxanywhere
posted @
2006-03-01 22:26 哈哈的日子 阅读(645) |
评论 (0) |
编辑 收藏
终于想认认真真的写点东西了,让自己也有点回忆,于是就找到了这个地方。
还和老婆为样式争吵了半天,最终嘛,还是听了我的,就用这个比较简单的吧。
老婆不知道受了什么刺激,拿了本 DW 的书自己学做网页去了,hoho。她人就这样,直来直去的,看到别人弄什么,自己就想弄,小孩子脾气。
希望将来幸福快乐的日子更多!
posted @
2006-02-27 21:25 哈哈的日子 阅读(268) |
评论 (0) |
编辑 收藏