
商业智能平台研究(九) ETL 中的数据质量控制 数据质量一直是ETL工具的一个高级特性,为了解释清楚这个问题,让我们看看oracle的商业ETL工具Oracle Warehouse Builder 在数据质量上是如何管理的
oracle在官方网站上有一篇专门介绍如何使用oracle warehouse builder的文章,地址为http://www.oracle.com/technology/pub/articles/rittman-owb.html?
rssid=rss_otn_articles?msgid=4931461 , 是mark
rittman所写,rittman公司本身也是一个专业的oracle 数据仓库 和商业智能方面的顾问公司,在oracle
方面非常的有发言权,如果你对oracle和数据仓库,或者oracle商业智能有兴趣的话,可以看一下上面的这篇文章,本文所有图片引自上面的这篇文
章。
ETL难以成功有以下几个难点:
1 . 数据仓库的数据来自于多个数据源,所以数据的一致性很难得到保证,很多情况下需要一种硬性的标准来决定数据的取舍问题.
2 . 数据格式问题,例如数据缺失,超出数据范围,无效数据格式等等。
3 . 出现错误之后没有正确的处理问题,导致数据的质量不断的下降。
4 . 数据一致性问题,处于数据库性能考虑,有时候可能会有意的去掉一些外间或者检查约束。
5 . 业务逻辑问题.由于数据库在最初设计时就不够严格和谨慎。
我们怎么判断数据的质量好坏的呢,一般用户拿原有系统的显示方式查看某一查询条件的数据与用商业智能报表所产生出来的数据进行对比,看有多大的出入,这个
可能需要原先系统有足够的能力显示这些数据并且商业智能工具的报表有足够强大的查询和报表展示能力,或者是用商业智能的报表与OLAP运行出来的报表进行
对比,看有多大的出入,出入一般都是会存在的,因为数据不可能完全的准确,但是一定要搞清楚哪里数据出现了问题,并且尽量不要让这些误差扩大到用户无法接
受的地步,否则就认为BI失败了。(咋同是一个工具做出来的,数据的出入就这么大呢?)
oracle warehouse builder 提供三个特性来使ETL的过程简单
1 . Graphical Data Profiler 可以查看数据的结构,语义,内容,异常,和大纲,数据规则 ,
这就是在前一篇说的,kettle的数据管理没有oracle warehouse builder
强大的特性.kettle也提供查看表结构,column的结构,但是它不会判断一个column是不是主键或外键,一个字符串的最小长度是多少,最大长
度是多少,一个整数的长度是多少,一个double的精度是多少。
2 . Correction Wizard 把数据规则应用到你的ETL过程中,自动映射并更正,清理,转化数据, 相当于oracle warehouse builder 提供一些默认的值来帮助你更快的创建映射规则,这个功能也比kettle强大。
3 . Data Auditor 获取数据规则并监控数据转换的过程。kettle也提供数据监控的机制,并把log记入下来,并告诉你重复的记录数,读写多少条记录,更新拒绝多少条记录,时间,速度,步骤是否成功等信息.
oracle warehouse builder 提供查看选中表的结构信息和数据信息

数据归档编辑器有很多面板。这些面板显示已归档的对象和归档的结果。为了方便解释,可以将整个面板分成6个部分,分别是左上角的面板(有两个tab)叫做
1号面板,左边中间的property面板,叫做2号面板,左下角的monitor面板,叫做3号面板,右上角的Profile Results
Canvas 面板(有10个tab),叫4号面板,右边中间的Data Grid Panal ,叫5号面板,右下角的Data Rule
Panal ,叫6号面板。
1号面板显示已归档的表、视图、物化视图(oracle 10g新加的特性)、外部表、维度和事实等对象以及已经创建的任何更正模块的详细信息。
2号面板显示与数据归档关联的属性的列表。使用该属性列表,您可以优化数据归档的参数;启用或禁用某些数据归档组件并启用选定表的数据规则归档。
3号面板是监视器面板。该面板显示已提交的所有归档作业的进度。数据归档需要时间,所以可以在后台完成的作业,同时执行其他 Oracle
Warehouse Builder 任务;当作业完成时,Oracle Warehouse Builder 会发出通知,kettle
在执行监控上提供的信息比oracle warehouse builder
多一些,包括速度和时间,还可以看到你启动多少线程组和线程,线程进行到那一步都显示的出来。
4号面板提供最多的信息,所以分成了10格tab,包含大量归档结果汇总的tab,
5号面板显示数据的统计信息,某一个column出现的值,出现的次数,占的百分比,有了这个功能,如果出现了错误的数据,将可以更容易的看到和清除.
6号面板显示数据规则.




其中4号面板有10个tab,其中有几个tab非常有用.(看上面的图)
Data Type
tab详细说明表中每列的列名,数据格式,主要的数据类型,主要的数据类型所占的百分比,数据的长度,最大值和最小值,主要的长度,主要的长度所占的百分
比,类型的精度。其中所谓的主要长度类型在Date那一列为40%,可见有些值为空,它不光列出最小值和最大值,而且还有主要值的长度和它所占百分比,统
计方面功能比较强大,这种初步的数据统计不知道算不算接近于OLAP分析,功能上比kettle强大些.
Unique Key
tab显示检测到唯一键或主键的所有列。该选项卡还显示唯一值的数量多得足以建议删除或更正非唯一行时可以定义唯一键的列。你可以看到图中有Six
Sigma 列。这是一个 1 到 7 之间的数字,它指明“每千个的缺陷”数量,即对象中未能通过唯一约束的行。
Profile Object tab 相当于kettle中的 sql 编辑器 ,显示所有的数据并加上查询条件。
Domain tab 为归档对象的每列显示建议的域,以及数据与该域的一致程度。域就是列的一组允许的值,Oracle Warehouse
Builder 认为出现两次或以上值的列就叫域。从图上看到,PACK_COUNT , PROD_ID , PROD_NAME
都是唯一性比较高的列,所以没有domain,这个面板同样也有 Six Sigma 值。
创建数据转化规则
在它给出的例子中,MANUF_COUNTRY的国家列包含Not Known , Canada ,USA , UK 和 Mexico
,它想把所有的England转化为 UK , 在Product 表中,把所有REORDER_YN为 'N'
的记录删掉,并使MARKET_SEGMENT 表的所有值为 ' Economy ' 或 ' Executive ' .
当你完成了数据规则的建立后,在实际转换的过程中,有可能出现你没有考虑到的情况,oracle warehouse builder 提出了三种操作,
Igore 这个不用解释吧.
Report 在一个新建的ERR$$$表中记录下这条记录。数据继续转化。
Cleanse 应用转化规则来清理数据.
如果没有什么特殊的原因,一般最好不要使用第一种策略,你即不知道有没有数据处错了,也不知道有多少数据出错了,这样很容易让你的数据误差越来越大,第二
种Report策略能让我们知道那些数据出错了,并记录下来,当我们需要找到数据误差原因的时候,或者我们需要更正这些数据误差的时候有依据。当然如果我
们真正的清楚数据转换规则的话,第三种策略是最好的,把这种误差消失在ETL的过程之中.
其中对于应用了数据转化规则的列,oracle warehouse builder 又提供四种策略来使数据达到我们想要的程度,
 1 . Remove ,把我们认为满足特定数据条件的数据删除,例子中就是要把REORDER_YN = Y 的数据删掉。
1 . Remove ,把我们认为满足特定数据条件的数据删除,例子中就是要把REORDER_YN = Y 的数据删掉。
2 . Similarity Match 把不在我们规定的域内的数据自动更改为最接近的值,这个值是oracle
用特定算法算出来的,我不清楚到底是怎么样的规则。不过我猜是不是按照字典的顺序来排序,谁接近就转化成谁,比如有applet,book
,orange ,如果要转化book的话,就把book转化为applet,因为b 开头的单词比o
开头的单词离的近一些,中文的话可能不会支持吧。当然,这只是我猜的.具体是怎么样只有问那些高手了.
3 . Soundex Match oracle有一个函数叫做SOUNDEX , 它是应用以下规则,保留首字母,把所有的元音 a , e , i , o , u 和 w , y 删掉。把剩下的字符串按如下数字相加
b , f , p ,v =1
c, g, j, k, q, s, x, z = 2
d, t = 3
l = 4
m, n = 5
r = 6
如果两个或两个以上有相同的数字接近原来的值(在第一步之前),或者接近除去h 和 w 的值 , 忽略掉除第一个字母以外的数字. 返回4个字节。格式大概如下:
SELECT name, SOUNDEX(namecol) FROM test;
SELECT * FROM test WHERE SOUNDEX(namecol) = SOUNDEX('SMITH');
以上例子摘自http://www.psoug.org/reference/string_func.html,如果你对算法有疑问可以自己去看看。
4 . Custom 使用自定义的转化规则来清理数据,大多数时候都是使用这种方式。例子中的把MANUF_COUNTRY 的 England 转化为 UK 就是这种情况。
在你进行数据转化之后,你对数据的质量满意了,你可以设置Data Auditor 来监控以后传入的数据的质量

Data Auditor 使用定义的数据规则,生成关于数据的一致程度的统计报告,然后将其存储在错误记录表中。还可以对 Data Auditor
进行编程,指定 Data Auditor 在分数低于一定的阈值后向您发出通知,然后在特定情况运行清理映射来清理数据。运行该清理映射后,可以对
Data Auditor 进行编程,使其仅在设计分数高于特定级别或 Six Sigma 值时才继续进行余下的 ETL
过程,避免将错误数据载入数据仓库,使数据仓库的质量能够得到保证。
ETL是非常重要的一步,往往一个项目的成败就是看ETL过程的成功与否.选用一个好的ETL工具会让项目更加的有信心.
下一篇介绍ETL的各种工具.
商业智能平台研究(八) ETL 之metadata
metadata
网上有很多写metadata的文章,如果觉得我没有写清楚,也可以参考一下其他人的文章,
元数据的定义就是:描述数据的数据,你非要问什么描述元数据,还是元数据本身,UML中也有这种概念,只不过是描述的对象不一样罢了。
让我们解释的更加通俗易懂一些吧,在javaSE中也有metadata的概念,最早的就算是JavaDoc了,在5.0之后,Annotation就是
大量的使用metadata了,这是关于源代码的数据,具体来说就是关于Java的类、方法、字段等关联的附加数据。这些数据可以被Java的编译器或者
其它工具(比如Java IDE 象eclipse+junit一样)来发现和使用。
junit在4.0后也使用了Annotation也算是metadata的一种应用。
可见metadata并不是什么高不可攀的技术,我们时刻都在使用。
再来看看metadata在BI系统上的定义吧 , 如果你觉得下面这段话很无聊,请直接跳过下面这段 。
元数据(Metadata)是关于数据、操纵数据的进程,以及应用程序的结构、意义的描述信息,其主要目标是提供数据资源的全面指南。元数据是描述数据仓
库内数据结构和建立方法的数据,可将其按用途分为两类:技术元数据(Technical Metadata)、业务元数据(Business
Metadata)和内联映射元数据(Inter-Mapping Metadata)。
技术元数据是存储关于数据仓库系统技术细节的数据,是用于开发和管理数据仓库的数据,主要包括数据仓库结构的描述(各个主题的定义,星型模式或雪花型模式
的描述定义等)、ODS层(操作数据存储ODS .Operation Data
Storage)的企业数据模型描述(以描述关系表及其关联关系为形式)、对数据稽核规则的定义、数据集市定义描述与装载描述(包括Cube的维度、层
次、度量以及相应事实表、概要表的抽取规则)。另外,安全认证数据也作为元数据的一个重要部分进行管理。
业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够理解数据仓库中的数据。业
务元数据包括以下信息:使用者的业务术语所表达的数据模型、对象名和属性名;访问数据的原则和数据来源;系统所提供的分析方法及公式、报表信息。
内联映射元数据(Inter-Mapping Metadata)实现技术元数据与业务元数据的层间映射,使得信息系统的概念模型与物理模型相互独立,使企业的概念、业务模型重组,以及物理模型的变化相互透明。
内联映射元数据从技术上为业务需求驱动、企业数据驱动的双驱动建设模型提供了重要保证,使信息系统的建设具有更高的灵活性与适应性
元数据是跟特定的数据对象有关的,换句话说,talend和kettle的元数据就是不一样的。ETL的元数据就和pentaho report
的元数据不一样,因为他们要描述的东西不一样。这些元数据的存储格式可以有多种,可以储存成XML格式的也可以是放在数据库里面的。事实上这两种最通用
的,也是可以互补的两种,没有谁比谁重要之说。
metadata储存在repository的地方,我不知道是不是所有的ETL工具都喜欢这么叫.每个repository都会选用数据库来储存,他们
都是按照一定的格式,这些格式最后也是可以变成XML形式的.这是看每个工具的支持程度,kettle
就支持导出到XML格式,其他的工具我就不知道了.
具体解释到kettle来说,metadata就是你定义的每一个动作.kettle的repository里面有如下一些表,我没有列出全部,从表的结构看一下kettle的metadata有哪些
1. R_DATABASE R_DATABASE_ATIRIBUTE R_DATABASE_CONTYPE R_DATABASE_TYPE
2. R_JOB R_JOB_HOP R_JOBENTRY R_JOBENTRY_ATIRIBUTE R_JOBENTRY_TYPE
3. R_LOG R_LOGLEVEL
4. R_STEP R_STEP_DATABASE
5. R_TRANS_ATIRIBUTE R_TRANS_HOP R_TRANS_CONDITION
6. R_USER R_VALUE R_PERMISSION
7. R_CLUSTER R_CLUSTER_SLAVE R_SLAVE
8. R_PARTITION R_PARTITION_SCHEMA
1 . database的链接信息.在R_DATABASE_TYPE 表里面包含了所有支持的数据库链接信息,一共是25种,算是支持非常的多了.
2. 任务设计部分的表,R_JOB_HOP 是指两个数据之间的链接部分, R_JOBENTRY_TYPE
是目前支持的操作种类,一共有27种,包括Transformation , Job , Shell , Mail , SQL ,FTP
,Table exists ,File Exists , JavaScript , Secure FTP , HTTP , Create
File , Delete File , Wait for File , Put a file with SFTP , File
Compare , BulkLoad into Mysql , Display Msgbox Info , Wait for , Zip
file , XSL Transformatio, BulkLoad from Mysql into File , Abort Job ,
Get mails from POP , Ping a host , Dummy Job Entry .
其中BulkLoad 只跟Mysql有关,我感觉很奇怪,BulkLoad
是数据库批量处理的方式,大型数据库都是支持的,比如oracle就有sqlloader来支持批量处理,其他的大型数据库应该也有吧,而且在
transform里面kettle也有oracle的支持,在任务设计的时候就只有mysql的支持,不知道什么原因.
最后一个Dummy Job Entry 就是什么都不做.
3. Log记录,loglevel 一共有6种,Nothing at all , Minimal loggin , Basic loggin
, Detailed loggin , Debugging , RowLevel(very
detailed).根据你自己的需要来选择log的级别.
4. 每一步操作的表格与你使用的数据库
5. 转换的定义.一共有70种不同的转化,你不会想看到全部列出来的,其中有几种很有用的,比如DimensionLookup , 它的解释就是"在一个数据仓库里更新一个渐变维,或者在这个维里查询信息.
还有基于关键字删除记录,
cuebOutput, 把数据写入一个cube,
从一个excel文件读数据,执行一个sql脚本,调用数据库的储存过程,
OraBulkLoader ,调用oracle 的bulk loader to load data ,(应该是指Oracle的SQLLOADER吧).
ProSAPCONN, 从一个SAP系统取数据.
MergeRows,合并两个数据流, 并根据某个关键字排序. 这两个数据流被比较,以标识相等的、变更的、删除的和新建的记录.
插一句关于merge的概念,从网上copy下来的:
MERGE语句是Oracle9i新增的语法,用来合并UPDATE和INSERT语句。通过MERGE语句,根据一张表或子查询的连接条件对另外一张表
进行查询,连接条件匹配上的进行UPDATE,无法匹配的执行INSERT。这个语法仅需要一次全表扫描就完成了全部工作,执行效率要高于INSERT+
UPDATE。
6. 用户与权限.一开始建立的用户有两种,admin和guest ,权限有5种,Read only access , Administrator , Use transformations , Use Jobs , Use schemas .
7. pentaho官方网站上面有一个新闻是关于在mysql的
Kettle集群新记录:
最近Kettle集群基于 Amazon Elastic Computing Cloud做了一次测试,单台服务器输出4000 rows/sec
,数据库为MySQL. 如果你发送数据通过sockets从一个master到5个slave servers, 你将获得 5x4000 row
inserts/sec。集群的效果非常好.
我个人也做过测试。数据库是oracle 10.2.0.1,内网连接,从一台机器的oracle到本地机器,没有集群,速度也大概是4000 多一点 ,数据量大概是16万。
8 . 数据库分区是数据库的高级特性之一,oracle的XE版和Enterprise版本的有一个差别就是XE版不支持分区。
kettle还支持metadata搜索,可搜索的选项包括步骤,数据库连接和注释
,可见metadata对于ETL的重要性就是它能够更好的管理你的数据,而不只是让你的数据呆在数据库里面。kettle对与数据库的元数据管理并不是
很好,所谓数据库的元数据就比如数据库中表的名字,每一个column的信息,column的长度,每一个表的constrain,index等,而只有
提供这些信息的管理才能够将ETL过程做的更好。下一篇介绍ETL质量控制的时候会看到oracle warehouse builder
对于这些数据管理是多么的强大,目前kettle的能力还不能算是非常的强大的。
pentaho平台本身还有一种metadata , 在官方主页上是这么写的:
pentaho
metadata的能力是让管理员定义一个抽象层来显示数据库信息和商业流程,管理员用关系型数据库的表来表现相互之间的关系,为了复杂和含义模糊的数据
库表和列而创建商用术语,为特性用户而设定权限参数,指定默认的数据格式,为多种语言部署提供翻译,商业用户可以使用pentaho新的ad hoc
query能力查询他们想要的报表,比如订单的数量和按地区排序的客户开销,SQL可以自动取得这些信息。
数据仓库的建模也需要用到metadata, oracle的数据仓库建模就是用的一种叫 Common Warehouse Metamodel
的metadata , CWM提供一个数据仓库的标准让不同的厂商集成和管理他们的数据,CWM建立在开发的标准XMI(XML for
Metadata interchange) XML 和 UML2 作为建模语言。CWM 用UML2
定义一组核心类,这些类分作package(或者叫做子模型submodels),每一个提供一个特定的数据仓库的domain , 比如
Relational , OLAP ,Transformation , CWM 提供一个强大的数据模型来实现数据仓库的Extraction ,
transformation , loading , integration and analysis
,没有一个单独的模型能够满足各种应用程序和开发工具的需求,但是CWM
为这些工具提供特定的扩展,它被设计用来支持关于metadata的快速开发,使用户能够通过扩展来满足他们的需求。(上面这段话翻译自http:
//www.corba.org/vendors/pages/oracleCWM.html , 翻译的不是很好,如果各位有兴趣可以自己去看看)
下一篇介绍ETL的数据质量控制。
商业智能平台研究(七) ETL 的选型
看了一段关于魔兽世界的视频,讲的是4个小孩子被一个人PK,那四个小孩子拼命练级最后打败那个人的故事,其中有一句话翻译的很好,
gentleman ,we are dealing with the guy have absolutely no life .
先生们,我们正在对付一个彻头彻尾的宅男。
总是有很多事情觉得应该去做,总是说等有了时间去做。可真的有了时间又没有去做。想到了eygle (oracle一个很厉害的DBA) 的一篇文章,天道酬勤。
http://www.eygle.com/archives/2006/02/the_sun_repays_industriously.html
一年有四个计划,然后又加了一个计划,如以上目标不能实现,则顺延至下一年.
希望自己的计划列表上也不要有这一条吧,加油加油。
引用steve jobs 在stanford上的最后一句话
Stay Hungry. Stay Foolish
求知若飢,虛心若愚。
openI : openI 并没有指定的ETL 工具
spagoBI : spagoBI 官方是支持多种ETL工具的,但他们的合作伙伴是 talend . talend 最近刚刚发布了2.0版本
,
自己声称是业绩第一个开源的ETL工具.基于eclipse平台。1.1版最后处理数据的方式是用perl,2.0版刚刚加了用java处理的方式,不过
支持的数据源比较少.
jaspersoft : jasperETL ,一个基于talend的工具,不知道有什么不一样,大概是购买了talend的二次开发许可证。
pentaho : kettle ,现在已经改名叫pentaho data integration 了,不过一样可以叫kettle ,是pentaho独立的一个子项目,最近刚刚发布了2.5版本,非常容易安装和使用,跟pentaho一样,人气很旺。
让我们先看看ETL过程的设计是如何的定义的:
1 .数据抽取、 转换和加载,是数据仓库实现过程中,数据由数据源系统向数据仓库加载的主要方法,整个数据处理过程如下:
2 .数据抽取 :
从数据源系统抽取数据仓库系统所需的数据,数据抽取采用统一的接口,可以从数据库抽取数据,也可以从文件抽取。对于不同数据平台、源数据形式、性能要求的
业务系统,以及不同数据量的源数据,可能采用的接口方式不同,为保证抽取效率,减少对生产运营的影响,对于大数据量的抽取,采取“数据分割、缩短抽取周
期”的原则,对于直接的数据库抽取,采取协商接口表的方式,保障生产系统数据库的安全。
3 . 数据转换 : 数据转换是指对抽取的源数据根据数据仓库系统模型的要求,进行数据的转换、清洗、拆分、汇总等,保证来自不同系统、不同格式的数据和信息模型具有一致性和完整性,并按要求装入数据仓库。
4 . 数据加载 :
数据加载是将转换后的数据加载到数据仓库中,可以采用数据加载工具,也可以采用API编程进行数据加载。数据加载策略包括加载周期和数据追加策略,对于电
信企业级应用,采用对ETL工具进行功能封装,向上提供监控与调度接口的方式。数据加载周期要综合考虑经营分析需求和系统加载的代价,对不同业务系统的数
据采用不同的加载周期,但必须保持同一时间业务数据的完整性和一致性。
ETL的功能。
ETL 功能的强弱很难用一个指标来评价,大概从以下几个方面可以粗略的考虑
支持的平台,支持数据源,流程设计,Metadata管理,可扩展性 , API , 数据验证,数据质量管理 ,
*支持的平台
很多的服务器不是运行在Windows系统上,所以平台的支持非常的重要,Windows,Linux, Solaris,HP-UX , IBM
AIX ,都是服务器常用的操作系统,至于Applet
OSX我就不敢说了,如果哪个ETL工具只绑定在Windows平台上,恐怕支持的程度会很低,所以用java做的东西会占一点点的上风,企业用的东西还
是要有一点跨平台的能力滴。
*支持的数据源
这里把数据源分为三种,数据库,文件,第三方应用程序
主流的数据库如 Mysql , Oracle , MS SQL Server , IBM DB2 , Sybase
还包括各种各样的数据库比如MS Access , PostgreSQL , Informix , Firebird SQL ,
Hypersonic , SAP DB , CA Ingres , SAP R/3 System 和任何支持ODBC的数据库,有人会对MS
Access 和 Hypersonic 数据库上榜有疑问,我承认他们不是商业型数据库,可是我们不能否认他们的存在。这里要提一下JDBC
的好处了,JDBC的标准使数据库的通用性提高了很多。
支持的文件格式也算是ETL数据源一种很重要的输入,其中有两种是必须支持的,普通文本格式文件和CSV文件,另外还包括zip文件,XML文件,当然是
按照一定格式输出的,有的是数据库本身输出的比如oracle的,有的是第三方工具输出的,也有是自身的ETL工具输出的格式,对文件格式支持又分为
Read和Write,Read就是输入,要求支持的格式尽可能的多,而Write则因工具而不同,可能有的特性包括:按照field分隔数据,多种文件
格式输出,追加的方式输出,按照文件大小或指定的行数自动分割文件等等。
支持的第三方应用程序也是ETL的附加特性,比如支持SAP 或者一些流行的ERP 数据格式的处理,但是并不是每个ETL工具都会有的特性,这个因工具而异。
*流程设计
ETL数据处理是非常复杂的,一个好的ETL流程设计工具不是凭一两个功能就算是成功的工具,流程设计也不可能因为一两个步骤就完成,我只是尽量挑些我知道的说吧,如果大家有补充的话,也欢迎留言或给我发email: jj12tt@yahoo.com.cn
由于ETL过程的复杂性,为了方便的管理,高性能,可扩展性,大多采用象多线程,分布式架构,来提高管理和性能,所以GUI设计工具也要有相应的支持才能更好的完成工作.
输入和输出的时候要能够备份和恢复,你也可以认为这是数据流向临时表.
要能够方便的更改数据的结构,最好还有版本控制支持,不一定要非常的强大,至少要记录下每次更改的过程.
字段的转化功能要尽可能的强大,talend的转化设置还可以支持正则表达式.最好很多转换都有默认值,能够支持公式.
可以自定义函数,当然函数本身不能大复杂,跟公式转化能够搭配.
支持复杂的过滤,分组,查询.能够按照行或列进行聚合.
能够有基于时间的调度方式,事实上这也是必须的.
要有好的性能,能够批量的处理请求,并且这些性能是可视化的,也就是要有一个度量.每次转化多少数据用了多少秒或分钟,kettle官方上写的性能指标是
4000/s,如果一条数据算1k 的话,一秒钟就是4M
的数据量,1GB就是256秒,大约4分钟多,应该算是非常可以接受的值了,不然别人也不会写在官方网站上了.
所有的任务都是能够集中管理的.也就是说,多个不同的客户端ETL工具有一个共用的服务器来设计任务,每个人可以设计自己的部分,但是执行的时候是一个整体在执行.
要有好的异常处理方式.出错是在所难免的,问题是出错了之后你怎么处理的问题.
是否支持集群,大型的数据库可能都会避免不了使用集群,如果转化的时候支持集群速度可能会提高非常之多,而且集群的特点就是只读服务器比较多,而ETL本身就是只读的,所以和集群也是非常和的来的.
流程是分步骤的,一个步骤又有可能是由多个任务来组成的,所以一个好的GUI是必不可少的,所以我们也说说GUI的特性:
1 . drag and drop 特性是必不可少的。而且有的时候需要一些对话框和向导来收集用户的行为。
2 . 任务是可以复制和剪切的。
3 . 每一个动作都是可以描述的。也是可以取消和重做的。取消和重做的次数不说是无限次数,也要尽可能的大。
4 . 每一个任务都是必须要有起点和终点的,起点只有一个,但是终点就不一定了。
5 . 要有图形化建立数据库链接的方式。能用图形化建立每一步,每个任务的方式。
6 . 界面的可定制性要好,颜色要选鲜艳一点的,字体可以调的,图形化界面要可以放大和缩小的,(不是吧,这也算)。当你要面对数十个任务的时候,数据错综复杂,颜色鲜艳一点不至于让你睡着了,你就知道为什么需要了。
7 . 支持多条路线,也就是一个数据点可以把数据分散到多个不同的下一级数据点,多个下一级数据点又可以把数据汇集到同一个数据点。
8 . 可以预览,所谓的预览就是把指定数量的数据而不是全部数据进行处理,查看结果是否满意。
9 . 可以在数据运行的时候动态的pause , cancel , redo .尤其是在进行耗时很长的动作的时候,或者你发现前一个步骤出错的时候。
10 . 显示数据处理时的状态要清楚。你正在链接到一个database ,你正在读8000条记录,你正在更新这些记录而不是新建记录,每一步操作所处的状态要明确。
11 . 要支持缓存 .这应该算是提高性能的好方法,但是缓存不能丢失。
12 . 所有的操作可以存储。不论你是存储成XML格式的,还是用元数据储存在database里面。
13 . 存储的操作可以读取。并且是不丢失任何数据的读取。
14 . 识别不同的数据库数据类型。long , String , data , text ,还包括table , index, sequence 等等。
15 . 对数据库要有编辑器的支持。要有可视化图形的建立 query 的方式。旁边应该有group , order by , sum , avg 等标准函数的支持。
下一篇介绍ETL 的metadata .
四个开源商业智能平台比较(六)
roadmap是一个项目的计划表,个人认为任何一个项目都应该有的,这样你的developer能够知道自己工作的项目处在什么状态,也不至于每天都在没日没夜的忙,却不知道自己在忙什么,这样更能够提高团队的士气。
openI的roadmap我好像是看到过了的,但是等我去找的时候却没有了,所以直接跳过,如果有哪位朋友看到了,也请麻烦告诉我一声。
JasperSoft
我找到的这一篇是November 2006的,找了半天也没找到最新的,它是分各个不同组件的,我挑一些说一下:
1 。 Many components of JasperIntelligence are localizable. We are doing
a pass through to make sure localization works at all levels.
2 。 Dashboards Multiple reports and OLAP components displayed in a single screen
3 . Portal (JSR168) integration: portlets, security
4 . Report data sources in all JR query languages, including Mondrian and XML/A
5 . Scheduling Enhanced UI for scheduling management
6 . JasperAnalysis Filtering views according to user profile, not just role
7. JasperAnalysis Visual Schema Builder
Visual MDX builder
JasperETL是基于talend的,所以不在我讨论之列。
1 可以看出jaspersoft的全球化的意图,实际这也是每一个成熟项目都需要面对的。
2 DashBoard是BI展现层技术比较集中的一个地方。我本身没有看过jaspersoft的DashBoard。
3 . portal是BI展现层不可避免要用到的技术,后面我也会就portal专门有一个篇比较的
4. data warehouse 也是支持越来越广泛。
5. 任务调度必不可少
6. 基于profile的参数控制也算是基于权限控制的另一种途径。因为普通的权限控制不可能满足BI的要求,太多的参数要管理了
7. Visual , Visual , Visual 不知道它的MDX怎么做的,如果跟JPivot一样就..................
pentaho的roadmap,官方甚至说没有commitment(许诺),仍然挑几条:
1. Accelerate dashboard creation by delivering a dashboard design tool.
2. Business users will be able to select from subject areas predefined
by administrator and apply filters (for example, certain time periods
or product lines) to select the subset of information they need.
3. Wizard-driven interfaces to streamline the deployment and optimization of OLAP cubes .
4. Easily incorporate data from multiple sources into Pentaho Data Mining solutions via Pentaho Data Integration.
5. Offer integration with Content Management Systems (CMS) to store and manage access to generated reports.
这是一个总的它的roadmap,它的各个组件还有各自自己的roadmap.
1. 用DashBoard Design tool来做Dashboard,易用性又提高不少,pentaho喜欢把tool做成基于eclipse的tools,spagoBI则是喜欢模块化的设计,都基于web + plugin模式.
2. 预定义的filter,最后大家都可以共享和分发filter,有点像社交社区的功能
3. 用wizard-driven的方式来建cube,OLAP的功能会越来越厉害的,JPivot的不爽的另一种表现(挑拨离间我最在行,开玩笑的,大家别当真)
4. 我也不懂什么意思,pentaho论坛上也有人问了,没有回答
怎么集成的,怎样data mining , 集成到哪了,kettle吗?只有等release才知道
5. 终于还是要动用CMS来解决问题了,spagoBI在这点上领先一点.
spagoBI
spagoBI的roadmap看了会让你非常的惊讶,为了表示我对spagoBI这个雄心勃勃的项目的尊敬,贴出全部roadmap(加了数字)
First half 2007
Analytical engines and end-user functions
1 ETL: integration of Talend OS tool
2 OLAP: new OLAP engine for web based analysis or local spreadsheet elaboration - Integration of Palo/JPalo OS tool
3 OLAP: new XMLA engine, to integrate MS Analysis Services
4 QbE: profiling and filtering over data according to the behavioural model
5 Dashboard: enrichment and new components
6 Personal folders to storage private documents and the possibility of sharing them
7 Personal menus of quick access to all kind of documents
Developer/administrator functions
8 Scheduler: production, distribution and storage of off-line
reporting, deferred execution of documentary Dossiers, Mining or ETL
processes
9 Search engine
10 Predefined set of metadata to implement frequently used time parameters (ex. current month, current year, current date)
11 Self-analysis: analytical model developed with the SpagoBI
platform on its own metadata. This model offers the
developer/administrator the full visibility on the behavioural model
and on the analytical metamodel managed by the platform.
12 Rich client (Ajax) for the developer and administrator functions
13 Designers: enrichment and simplification of the interactions
with the platform for the development of the analytical documents
14 Evolution of the platform towards SOA architecture
15 Metamodel
Second half 2007
Analytical engines and end-user functions
16 Dashboard: new engine
17 Subscription: capability for the end-user to enter himself to the periodic delivery of predefined reporting.
18 Alerts and notifications
19 Geo-referenced analysis: improvement of the current engine and integration of GIS solutions
20 Navigation profile, to inherit settings during the vertical and
cross navigation between the analytical areas and documents
Developer/administrator functions
21 Installer and end-user interface for the configuration of the environment
22 Rich client (Ajax) for the developer and administrator functions
23 Designers: enrichment and simplification of the interactions
with the platform for the development of the analytical documents
24 Evolution of the platform towards SOA architecture
25 Metamodel
Applicatory development areas
* What-if
* BPM
有很多人认为 pentaho有多么多么厉害,证据呢?能告诉我厉害在哪些方面吗?这个roadmap也许会给你一个不一样的答案pentaho宣传做的很好,有microsoft的风格,有什么都展现出来
spagoBI更像是一个默默努力的developer,技术一流,不懂的展现自己。
2和3是支持新的OLAP Server的,Mondrian可不是唯一的选择。
4. 跟pentaho一样基于profiling,只不过spagoBI有自己的behavioural model(行为模式) ,比pentaho厉害一点
5 . pentaho的DashBoard注重在易用性方面,spagoBI 则是强调在功能上
6 和 7.pentaho的cms只是一个plan,spagoBI已经在做private folder和共享文档了,还有导航,技术又高一点.
8. mining ETLprocess ,后面我会在ETL的部分提到的
9 . Search Engine 基于lucene的search,cms一部分
10 .跟pentaho一样,常用的查询预先定义
18. 用户通知方式的加强.不知道会不会有 RSS的方式
19 . GEO 的查询快要和GIS集成了,十分期待,不知道会不会一样引用Google的API或是仍然基于原先的SVG.
21 - 25都是为用户易用性和更好的用户体验做的增强.
这篇文档有很多的英文,英文不好的朋友可以下载一个星际译王,emule上面有个绿色版,如果你不想麻烦的话,这也是个不错的选择.还是建议大家学好英文
呀,看英文文档很方便的,最近跟美国那边的客户交流要搞死我了,长期不知道是他们的口音重还是我的词汇不够,同事也跟我一样一头的包,努力努力再努力,睡
觉是为了努力工作,努力工作是为了安心的睡觉.
睡觉去了,ZZZZZzzzzzzzzzz..............
下一篇介绍ETL的选型,敬请期待.
四个开源商业智能平台比较(五)
lumi问JPivot能否单独使用,不能,根据其主页上的描述, JPivot is a JSP custom tag library that renders an OLAP table and let users perform typical OLAP navigations like slice and dice, drill down and roll up. It uses Mondrian as its OLAP Server. JPivot also supports XMLA datasource access.
换句话说,它必须使用一个OLAP的服务器做后台,大多数选择Mondrian,当然,JPivot也支持XMLA的数据源,我不太清楚除了SQLServer外还有谁是的。
要使用JPivot就必须使用多维数据表,我想你们公司应该是普通OLTP的数据表,那么就需要ETL工具了,工作量恐怕也非常之大。
JPivot在展示向上钻取和向下钻取的功能需求时是否比较方便?
是的,非常的方便,JPivot是一个JSP custom tag,你要需要指定数据源和写一个xml的描述文件就可以了,它本身是很简单,问题是前面的步骤。
你说你们的SQL有40M我一点也不惊讶,我们公司小的也差不多有10多M,从20多个表取数据,如果什么都选的话,会有50多M,顺便问一句,你计算出有40多M是用的P6SPY吗?我是用这计算的,用TOAD格式化的时候没有死机,其实这个大小很平常的,不过速度倒是差到了不行,最近我当了回DBA把oracle优化了一下,硬盘空间只给我30G,没空间你叫我怎么做优化,我们公司developer用的机器是512M内存跑oracle,eclipse ,tomcat,toad,这种配置的确让我很无奈。不过报表最后速度还算可以接受,大概1分钟不到可以Run出一个Excel的报表6 worksheet,每个worksheet数据大概在6K到2W左右,哦,对了,我们还使用了线程,run excel的时候,是弹出一个单独的窗口来run的。
普通的报表跟BI的报表是完全不一样的,所以不知道还有什么能帮你的,希望你早日脱离苦海,也祝我自己早日脱离苦海。阿弥陀佛
这次要比较的是四个平台的体系结构,
首先看openI的体系结构:
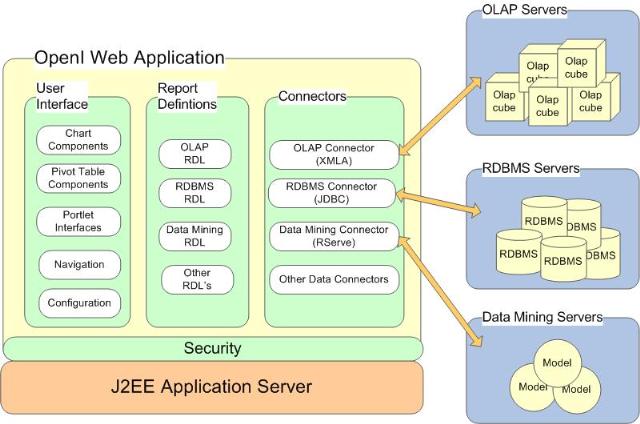
RDL是Report Define Language
openI具有一个BI应有的大部分特性了,
report : jasperreport ,JFreeChart
olap : mondrian + JPivot
data mining: weka
它的各层衔接的非常的紧,好像用了eigenbase做数据管理,不是很清楚这部分,openI在做数据挖掘的时候它没有调度器,它的Portlet Interface 主要是指在用JPivot的时候JPivot可以到处使用
openI没有自己的开发专属工具,入门门槛也相对较低。
JasperSoft
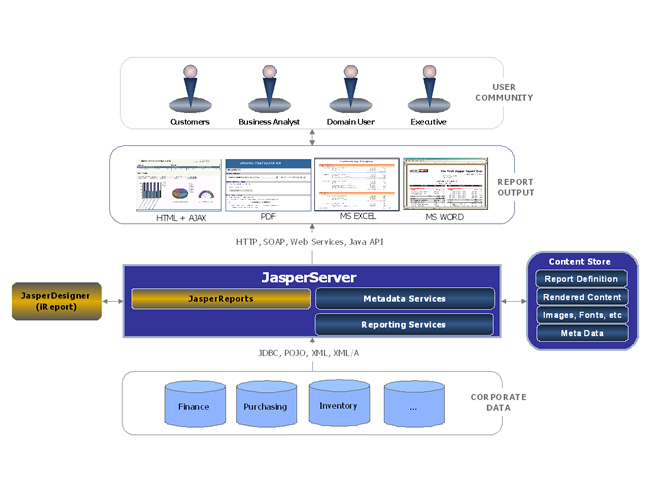
JasperSoft最重要的就是它的报表,但是它支持输出的格式很多,管理的方式也很多,也用了eigenbase做数据管理。
有比较完善的权限控制,用的acegi,
支持多种数据源,只要有JDBC驱动。
它的产品已经形成了一个产品线,最著名当然还是它的JasperReport。
你可以看到它为了更好的管理各种报表和数据,有自己专属的展现平台JasperServer,这个平台是 06/26/2006才创建的,完全是JasperSoft为了实现BI而迈出的重要一步。jasper没有数据挖掘。
有任务调度器,用了quartz。
有自己专属的ETL: JasperETL
它有自己的OLAP SERVER : jasperAnalysis
展示层用到了AJAX和applet, 也有DashBoard。
查询语句支持SQL, Hibernate (HQL), XPath (XML), EJBQL, MDX(多维查询语言,OLAP专用,SQLSERVER用的是XMLA)
SpagoBI
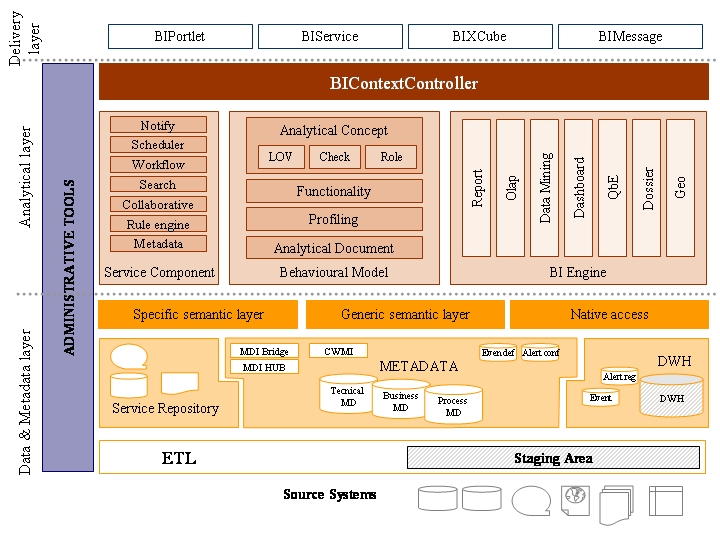
spagoBI平台厉害很多,也复杂了很多。
它的各个组件之间模块化很好,Plugin加载,来看一下它的各个组件:
report : BirtReportDriver , BirtReportEngine , JasperReportDriver ,JasperReportEngine
GEO : GeoDriver , GeoEngine(用地图显示数据和查询的)
OLAP : JPivotDriver , JPivotEngine
QBE : QbeDriver, QbeEngine (以前学Hibernat的时候记得总是说QBE功能很弱,不知道这个这么说 )
Data Mining : WekaDriver , WekaEngine
Security : ExoPortalSecurityProvider
Booklet (小册子) : BookletsComponent: it is a component for booklets generation.主要包括文件上传,工作流,OpenOffice支持。
它还有文档管理,用的是apache的JackRabbit,有搜索功能,用的lucene.不愧是做cms,portlet,workflow出身的,技术就是牛。
spagoBI的使用的工具也比较多:
Report : Bird , JasperReport
ETL : Octupus 和 talend (talend是官方合作伙伴,顺便说一句,官方主页好像打不开,www.talend.com ,我是直接在sf.net上搜索然后下载下来的)
OLAP : Mondrian 和 JPivot
Data Mining : Weka
Portal : eXoPortal
它的展现层也使用了AJAX特性,另外它在DashBoard也使用了openlaszlo,(一个用Java code 生成Flash的框架,主页是http://www.openlaszlo.org/。新版的4.0好像也要支持生成DHTML) 所以spagoBI的DashBoard看上去很爽.
spagoBI的ETL是非常之牛的。你可以看到它下面的数据处理层是单独分出来的,至于为什么牛,我在后面ETL部分会专门提到的。
还有一些很细节的东西,想BIPortlet,BIMessage , Notify ,Schedule , Workflow ,Rule Engine ,Profiling ,Analytical Document 我会在后面尽量把我知道的说一下。
pentaho

pentaho的体系结构跟spagoBI非常相像,我甚至都没看出来有上面很大的区别,
不过pentaho喜欢把自己的东西称作solution,以下引用自pentaho的whitepaper:
pentaho BI 平台不同于传统的BI产品。它是一个以流程为中心的,面向解决方案的(Solution)的框架,具有商业智能(BI)组件,使得公司可以开发商业智能问题的完整解决方案
pentaho一样把数据处理层看的很重要,多种数据显示方式,甚至有RSS输出。
pentaho是有各种开源组件组成的。
ETL : Kettle (界面上显示的是pentaho Data Integration ,previously Kettle)
Report : Pentaho Report (它也支持Birt 和 JasperReport 的集成 ,还有专门的文档)
OLAP : Mondrian 和 JPivot (Mondrian已经加入了pentaho , 估计pentaho跟JPivot有仇,双方互看对方不爽,所以JPivot没有加入pentaho,呵呵,看玩笑)
Platform : Pentaho Planform
Data Mining: Weka (Weka也加入了pentaho)
下一篇介绍他们的roadmap ,你一定会发现惊奇的事情的。
四个开源商业智能平台比较(四)
昨天晚上回家就收到了javaeye的管理员发给我的开专栏的邮件,效率之高令人佩服,前几天发错了东西要管理员删除也很快就删了,再次谢过了。专栏地址http://www.javaeye.com/subject/Business-AI
谢谢大家关注。如果有比较相关的文章也请大家推荐一下。还不是很会用专栏。也希望能和大家一起成长进步。
eyejava朋友(主页http://eyejava.javaeye.com/)有个评论:
更关心的这些项目能帮助我们做什么,而不是他们的文档、demo、网站做得多好。
那我想问,如果贵公司是一家汽车公司(包括汽车研发,制造,销售,售后等),最近准备部署一个BI系统,而公司又没有人对这一块有了解,大家应该怎么办。你如果从搜索引擎或者新闻网站上了解到有这么四个开源的BI系统,还包括一些其他的商业BI公司,包括国内的和国外的,你应该这么评估的呢?
如果是我,我会先到一个网站上浏览一下,看一下人家主页是什么样子,有什么成功的产品,有哪些客户,大客户总是让人放心一点点,mysql好像都是他们的合作伙伴,这个项目有没有体系结构图,screenshot,roadmap,我最喜欢看图了,一开始我就说了我只是一个粗人。网站上面有没有技术白皮书,如果有文档,我会挑一些文档下下来看一下,screenshot总能给人一个直观的映像。 eXoPortal给我的映像就很深,因为他们网站上有一个51.5M的Flash演示篇,我心目中的最佳开源Portal平台就从Liferay变成了 eXoPortal了.文档的质量好坏标准由是不是能让人看懂为标准。我们没有时间把所有东西都试到,所以这些东西是客户了解产品的最初途径,最原始的客户宣传了。可能你的技术很好,但是客户看不到,你要人家这么选择你的产品呢?人家客户不懂什么Spring,Hibernate,EJB,SOA的,我管你春天冬不冬眠的。看你的screenshot上界面漂亮一点就选漂亮的了。
我个人更喜欢站在不同的角度看问题,从测试者的角度我喜欢用firefox的Selenium来录制脚本回放,虽然我们公司自己的项目是不会用到的,但这也是一种用户体验,喜欢用eclipse的TPTP来做JUnit的test和性能test。(不知道TPTP的Block问题解决了没有,不然总是让我卡机),也喜欢站在一个客户的角度来看一个系统,为什么JasperSoft的网站导航没有pentaho的做的方便和漂亮,而不仅仅是技术的角度,developer的角度。当然后面也会讲到很多细节上面的东西。
lumi说到报表的问题,我们公司做交叉报表是先定好每一栏,然后统计,用sql凑起来的,生成excel的文件,模板也是excel的,没有任何图形化的界面,改一点东西痛苦的要死,没有人知道sql凑的对不对,出错了就是该你加班的时候了。BI的报表之所以不一样是因为它本身是不知道你的数据库是什么样子的,所有的东西都是动态生成的,所以跟我们的普通设计的报表不一样,这也是为什么需要报表设计器。而且BI做的报表是先把数据导进OLAP服务器,所以查询的时候会比普通的报表强大很多,这就是普通的数据库和专业的数据仓库的区别,它们有自己的多维查询语言。pentaho的交叉报表后面也会提到的,其他的自己不了解,不敢乱讲话。
sonic_yj觉得我的评分比较笼统一点,的确是,所以我说了是个人评分,主要考虑到的是功能的强弱,文档的清晰程度,没有考虑到性能的问题,主要是我没有办法用大数据来测。而我最怕的是我因为自己的不了解而给一个系统妄下结论,所以不敢乱写(实际上我已经妄下了结论)。
jaspersoft的VMware的Demo 让我很奇怪,848M的东西,里面的只有一个SugarCRM的Report的Demo,跟我看他们宣传的Flash那个版本不一样。
相信JasperSoft本身的能力绝对不是这个Demo里面的这样,


pentaho的Demo:
主页

点左边饼状图,右边的数据会跟着变,pentaho认为这个就是它们的DashBoard了,跟SpagoBI的比差了一些。
本次的主角登场了。pentaho里面的JPivot,一样的灰色,一样的菜单。

不得不把技术最牛奖颁发给JPivot了,连pentaho这么爱美的项目都拿它没辙,当当当当(如果你不能用有旋律的声音念出这四个当,证明你很久没看电视了)
JPivot声泪俱下的说:感谢pentaho给与我这个机会,感谢开源社区给于我一贯的支持,感谢CCTV,MTV,还有千千万万的关注朋友,没有你们的支持就没有我今天的JPivot了.............
JFreeReport

pentaho认为的DashBoard
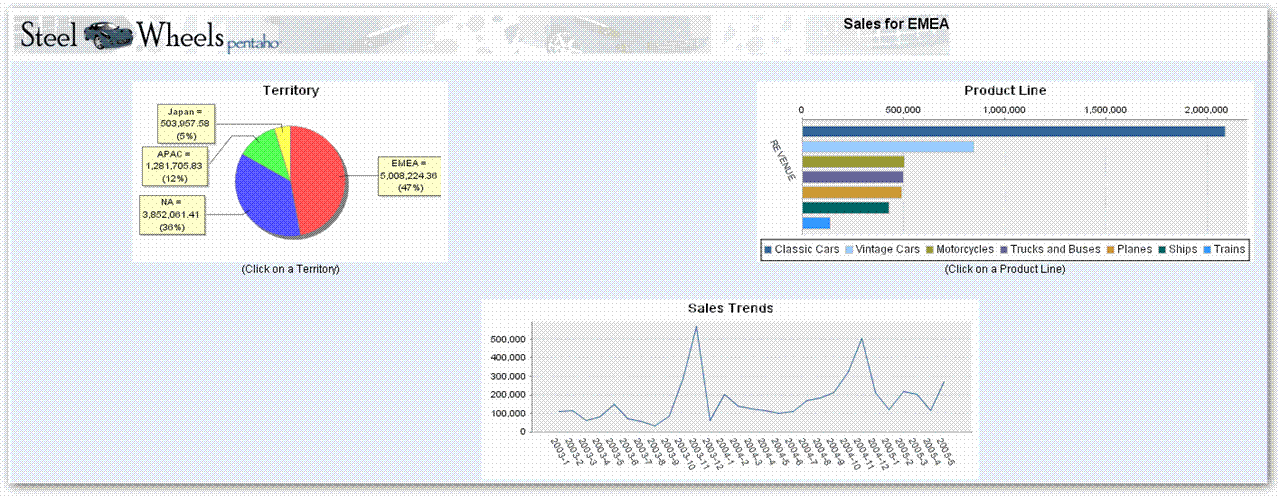
GEO的搜索,spagoBI也有,不过好像没有这么强大。还跟google map的API 结合了,易用性又高了一点,

各种不同的报表,毕竟报表是BI的最初也是最重要的一环。

pentaho的杀手应用,Mondrian + JFreeReport .数字没对好。要扣分的。

Demo的BI Platform是在JBoss Portal上的。不过要说明的是pentaho本身是平台无关的,无论你是在tomcat,jboss,weblogic,你选用哪种portal都一样,数据库支持的很多,Hibernate做的,只要你有JDBC驱动。
中间空的会不会太大了一点,下面倒是中规中矩的portal

换了个theme后的portal,漂亮多了,平台的颜色是一致的。

后台管理界面,跟SpagoBI一样,有耗时比较长的任务都是放在后台运行,运行完了才有提示,都是用quartz做的。

运行报表时的sql,Demo是在HSQL平台。SQL也是中规中矩的SQL
如果你想更快与我交流的话,可以发邮件到我邮箱,jj12tt@yahoo.com.cn 。
不过有三点要说的:
1 . 我不是专家 (绝对不是)
2 . 我不是水王 (希望不是)
3 . 我是个粗人 (绝对就是)
所以有什么写错了的地方还请大家指正。
四个开源商业智能平台比较(三)
先回答一下各位的评论,blogjava上的江南白衣 朋友(主页: http://www.blogjava.net/calvin/)有个评论,说openI项目不怎么更新了。我查了一下sf.net上的消息,
2月份倒到现在也没过多长时间,算是正常更新速度。
另外他说Jaspersoft还是偏重报表而不是BI,个人觉得BI是由很多步骤组成的,后面的文章会提到的,报表是一种初级的BI,也是最重要的一环。另外jaspersoft也有自己的JasperAnalysis还有自己的ETL工具,(说实话,看Demo的时候,硬是没看出来和talend有什么区别,自己没有用过)产品线也算是比较广了。
javaeye的sonic_yj朋友(主页http://sonicyj.javaeye.com/)想我给出一个个人评分。如下
openI 65分, openI项目本身很小,是适合小规模快速部署的。
JasperSoft 75分, JasperSoft的报表本身没什么好说的。产品线也的确算是正规的商业公司
spagoBI 80分 spagoBI平台比JasperSoft的大,它自己也不是什么都自己做,和pentaho一样,应用了一些其他开源平台的东西。
pentaho 89分 pentaho的名气很大。野心也不小,之所以这么高分,我很多都是给在了它的文档。文档质量非常之高,而且还有几份是中文的,可见其全球化的野心呀。国 内的厂商要小心了。为什么是89分,而没有90或90以上呢,就是觉得pentaho现在的差别并没有把spagoBI或着JasperSoft耍到哪 去。基本还算同等级的。
不过,我们做软件的都是很聪明的,看一个人要看他的志向,看一个项目的前途要看它的趋势,pentaho的野心已经有了,气势也有了,相信在2,3年之后才可能真正的看出差别来。自己也非常的期待这个项目的发展。
刚才用openoffice的时候copy/paste上面标题的时候,竟然掉了 “开”字,上一次是掉了 “平” 字,退出然后重copy/paste就好了.打引号的时候,老是出现右引号,非要空一格才能出现左引号,不知道是bug还是自己不会用.郁闷
好了,开始介绍它们各自的Demo
这一次是要比较它们各自的demo:
OpenI提供下载的demo只有一个,在线演示的有两个,下载的一个是叫foodmart
需要mysql.部署起来相对比较麻烦.至少花了我十分钟.然而在实际的生产环境中.部署openI是最快的,因为它的组件相对较少,贴两张在线演示的图片.


下面的灰色比较难看的表格就是JPivot的,的确是很牛的一个项目,不光是技术,关键是界面的颜色,后面介绍pentaho的时候也会提到的.呵呵
JasperSoft的Demo要先注册才能下载
Welcome
to the JasperReports demo. JasperSoft and VMware have partnered
together to create a virtual application showcasing JasperReports, the
world's most popular open source reporting engine. The VMWare image
contains a sample web application showing how JasperReports can be used
to add reporting to any application. This sample is using SugarCRM as a
data source, but can be used with other applications data as well.
To get started, please fill out the brief form below and you will be taken to the download area.
做成VMware的,那Demo部署起来就不用一分钟了,只要你装好了VMware.放就是了
它自己本身还有一个宣传片.是做成Flash的.贴几张图 顺便查了一下Ad Hoc是点对点的意思


本来想多帖几张的,但上传空间只有10M,后面还要用的。所以只贴两张
VMware的Demo会放在后面一篇。
spagoBI的Demo部署起来也非常之快.下载spagoBI demo和eXoPortal-tomcat-1.1.3.别先启动tomcat.把一个往另一个覆盖.启动sbidata里面的HSQL,启动eXoPortal,按照Readme里面的网址打开浏览器就够了,我个人部署的时候是没问题.可是OLAP进去就报错,其他的都没问题,幸好它还有一个在线的Demo.
而且难能可贵的是它还有十个tutorials,是Flash的,而且还是分阶段介绍的,
不得不说这给我留下了太深的印象了,一千个字也许没有一个图片更能介绍清楚的,一百个图片也许没有一个Flash更能介绍清楚的了,也许SpagoBI的平台知名度比JasperSoft的和Pentaho的要少的多.但是这十个Flash的确证明了他们团队对于平台的推广下了很多的功夫的.
技术再好,也要让别人知道才有用.
如果你用firefox浏览器的话,观看完Flash之后,flash会在
C:\Documents and Settings\<>\Local Settings\Application Data\Mozilla\Firefox\Profiles\<<随即号>>\Cache里面,查看文件大小,大概在597KB到3502KB之间,把文件名改为以.rmvb为后缀的就可以保存下来看了
还是贴几张图
JPivot的多维查询,SpagoBI也拿界面没办法.呵呵

jfreereport和jaspersoft报表,也有BIRT的

DashBoard

Data Mining

多维查询条件选择

下一篇是pentaho的demo和JasperSoft的
四个开源商业智能平台比较(二)
一个好的项目总是有很多的文档,一个失败的项目总是有各种理由没有文档或很少的文档。所有我们有理由来比较一下四个平台的文档。
openI的项目相对来说比较的小,文档可能也少一些,
文档虽少,主要的都有了,
实际上,这也是每个项目都应该有的文档了,java
doc文档实际还是很必要的,方便查询API
jaspersoft的文档
Jaspersoft的文档不可谓不多,而且集中在report上,大家也都知道,JasperSoft的jasperreport是业界领先的一种报表方式。而iReport则是jasperReport的设计器,好的report都是
有自己的设计器的,因为报表的种类很多,不可能把所有的情况都考虑到,所以想要需要自己的设计器。相对于国内的智能平台,光报表这方面来说的话,就没有自己的设计器,所以要想开发一些新的报表样式就得定做,而且不容易管理,修改。所以设计器还是很必要的,无论是做成RCP还是web形式。
SpagoBI的文档
How_To—1.6.doc.zip
How_To—1.6.pdf.zip
QuickStart—0.9.2.doc.zip
QuickStart—0.9.2.pdf.zip
SpagoBI_JBoss_Installation_Manual-1.4.3.doc.zip
SpagoBI_JBoss_Installation_Manual-1.4.3.pdf.zip
SpagoBI_JOnAS_Installation_Manual-1.4.3.doc.zip
SpagoBI_JOnAS_Installation_Manual-1.4.3.pdf.zip
SpagoBI_eXoTomcat_Installation_Manual_1.4.3.doc.zip
SpagoBI_eXoTomcat_Installation_Manual_1.4.3.pdf.zip
spagoBI的文档只有怎么安装的,关于它的组件的文档相对就少了,可能是开发着文档只有在进入他们的社区或者是在社区开发者内部才有的吧。顺便说一下,spago本身还有自己的cms
, portlet , workflow.实力绝对不容小看
pentaho的文档也非常的丰富
Pentaho
Getting Started Guide
Pentaho
AJAX Guide
Pentaho
Security Guide
Pentaho
Subscriptions
Software
Quality Reports for Bugzilla Getting Started Guide
Software
Quality Reports for Bugzilla Solution Documentation
Pentaho
Cube Designer User Guide
Pentaho
Creating Solutions
Pentaho
Data Mining Experimenter Tutorial
Pentaho
Data Mining Explorer Guide
Pentaho
SDK
Pentaho
Advanced Installation Guide
Pentaho
Customizing Deployments
Pentaho
Advanced Reporting Guide
Pentaho
Component Builder's Guide
Pentaho
Dashboard Builder's Guide
Pentaho
Internationalization Guide
Pentaho
BI Design Studio User Guide
Pentaho
Report Design Wizard User Guide
Pentaho
Report Designer User Guide
Pentaho
Report Bursting Guide
Pentaho
Jasper Report and BIRT Integration
Pentaho
Using System Actions to Control Data Access
Session
and Global Filter Guide
从文档的丰富程度也看出pentaho的体系相对较大,不过文档倒是覆盖的面比较广。其中的Pentaho
Report Design Wizard User Guide 和
Pentaho
Report Designer User Guide 是针对Pentaho
Report
Design的,一个基于eclipse平台的报表设计器。和jaspersoft一样,它把报表跟报表设计器飞开了,spagoBI好像是没有单独的报表设计器。它都是集成在一个WEB平台里面的。
Pentaho
AJAX Guide
是它自己的一个AJAX工具包的开发文档,从pentaho网站的漂亮程度看的出来。Pentaho对于美观还是非常的注重的。
Pentaho
Cube Designer ,Pentaho
Data Mining ,
Pentaho
Dashboard Builder's ,Pentaho
Internationalization ,
Pentaho
BI Design Studio 则是它的各个组件的开发文档。对于国际话还有专门的文档,看来pentaho
在开发的一开始就没打算之针对英语市场,spagoBI也有国际话,
cms和portlet都应该有吧,jaspersoft有没有我就不知道了,
pentaho也和另外的报表有集成,Jasper
Report and BIRT Integration ,也算是业界主流的报表吧,spagoBI也跟其他有集成,后面会介绍的。
下一篇将会介绍各自的Demo。
摘要: 四个开源商业智能平台比较
本人最近花了一些时间研究了一下开源的商业智能平台,想和大家交流一下。
在开始本blog之前,我想先说一句话:其实,我只是一个粗人
所以如果有什么写的不好,还请见量。
阅读全文